在本指南中,你将了解到:
- 为何 Perplexity 是 AI 驱动网页爬取的优秀选择
- 如何通过分步教程在 Python 中爬取网站
- 这种网页爬取方法的主要局限,以及如何绕过它
让我们开始吧!
为什么使用 Perplexity 进行网页爬取?
Perplexity 是一个利用大型语言模型的大数据搜索引擎,可以实时检索信息并对其进行总结,还能提供引用来源。
使用 Perplexity 进行网页爬取,可以将从非结构化 HTML 内容中提取数据的过程简化为一个简单的提示,从而不再需要手动数据解析,极大地简化了提取相关信息的过程。
除此之外,Perplexity 在高级网络爬取场景中表现出色,因其能够发现并探索网页。
欲了解更多信息,可参考我们关于使用 AI 进行网页爬取的指南。
使用案例
以下是一些使用 Perplexity 进行爬取的示例:
- 结构频繁变化的页面:它可以适应布局和数据元素经常变动的动态页面,例如电商网站(如亚马逊)。
- 爬取大型网站:它能帮助发现和导航页面,或使用 AI 驱动的搜索引导爬取流程。
- 从复杂页面提取数据:对于结构难以解析的网站,Perplexity 可以自动化数据提取,而无需大量定制化的解析逻辑。
场景
以下是一些使用 Perplexity 进行爬取的典型场景:
- 检索增强型生成(RAG):通过整合实时数据爬取来增强 AI 的洞察力。若想了解使用类似 AI 模型的实际示例,请阅读我们关于使用搜索引擎结果页数据创建 RAG 聊天机器人的指南。
- 内容聚合:从多个来源收集新闻、博客或文章,用于生成摘要或进行分析。
- 社交媒体爬取:从动态或频繁更新的社交平台提取结构化数据。
如何使用 Perplexity 在 Python 中进行网页爬取
在本节中,我们将使用 “Ecommerce Test Site to Learn Web Scraping” 示例沙盒中的某个产品页面:
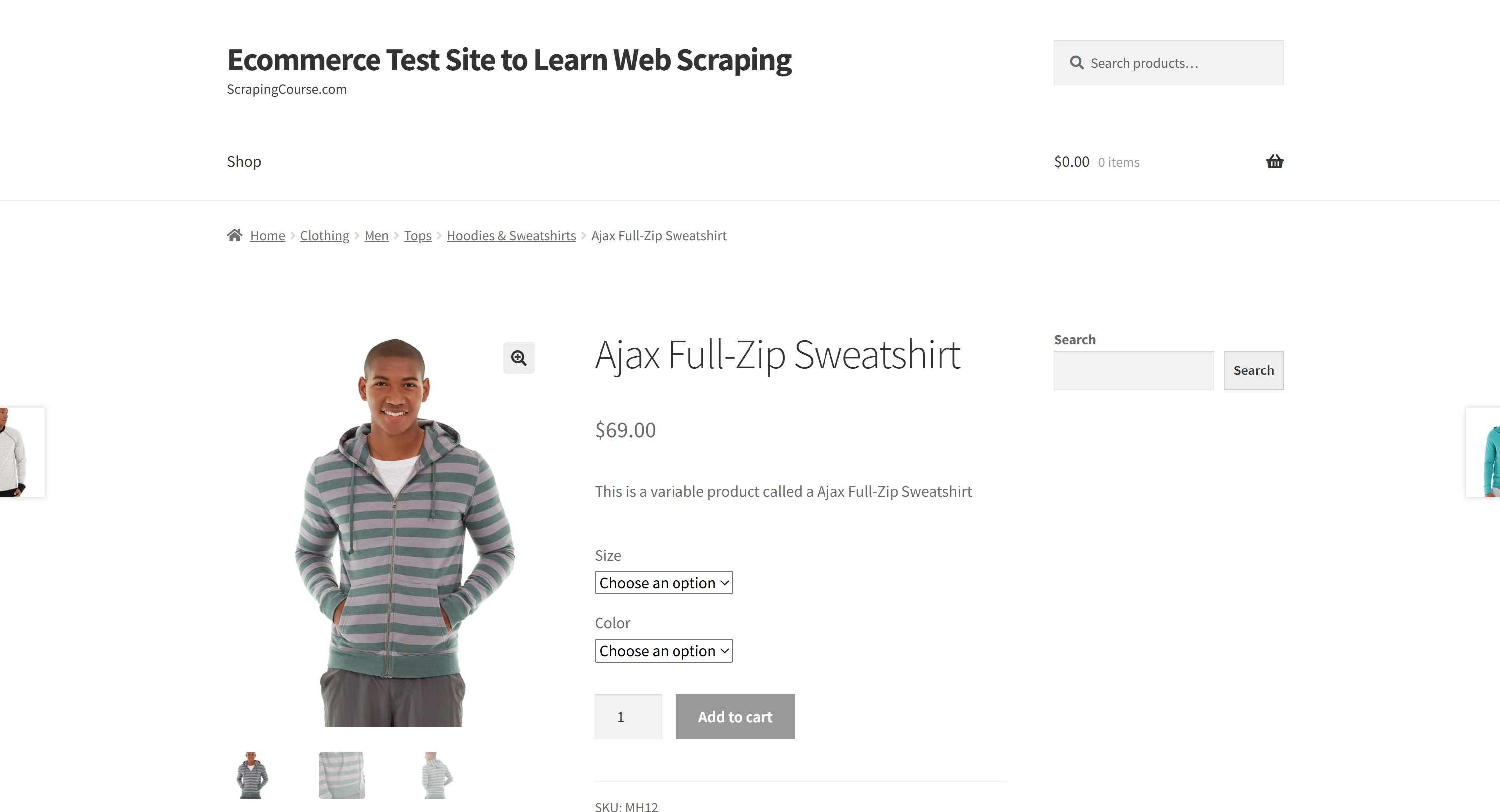
此页面是一个很好的目标示例,因为电商产品页面往往具有不同的结构,包含各种类型的数据。这也是电商网页爬取面临的主要挑战之一,而这正是 AI 能够提供帮助的地方。
在这里,使用 Perplexity 驱动的爬虫将利用 AI 从该页面提取如下产品详情,而无需手动编写解析逻辑:
- SKU
- 名称
- 图片
- 价格
- 描述
- 尺码
- 颜色
- 分类
注意:下面的示例将使用 Python,只是因为它比较简单且相关 SDK 更普及。使用 JavaScript 或其他编程语言也能实现相同的效果。
按照下面的步骤,学习如何使用 Perplexity 来爬取网页数据吧!
第 1 步:设置项目
在开始前,确保你的机器上安装了 Python 3。如果尚未安装,点击此处下载并按照说明进行安装。
然后,使用以下命令来初始化一个文件夹作为爬取项目:
mkdir perplexity-scraperperplexity-scraper 目录将作为使用 Perplexity 进行网页爬取的项目根目录。
在终端进入该文件夹,并创建一个 Python虚拟环境:
cd perplexity-scraper
python -m venv venv使用你常用的 Python IDE 打开此项目文件夹。Visual Studio Code + Python 扩展或PyCharm 社区版都是不错的选择。
在项目文件夹中创建一个名为 scraper.py 的文件,项目结构大致如下所示:
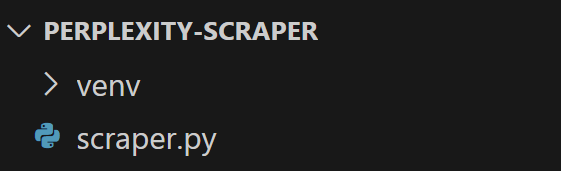
此时,scraper.py 只是一个空的 Python 脚本,但它很快就会包含LLM 网页爬取的逻辑。
接下来,在你的 IDE 终端中激活虚拟环境。Linux 或 macOS 上可执行:
source venv/bin/activate在 Windows 上,可执行:
venv/Scripts/activate太好了!现在你的 Python 环境已经准备好进行 Perplexity 网页爬取了。
第 2 步:获取你的 Perplexity API Key
和大多数 AI 服务商一样,Perplexity 也通过其 API 提供模型访问。若要以编程方式调用它们,首先需获取 Perplexity API Key。你可以参考官方的“Initial Setup”或者按照下面的提示操作。
如果你还没有 Perplexity 账户,注册并登录。随后,进入 “API” 页面,如果你还没有添加支付方式,点击 “Setup” 来添加:
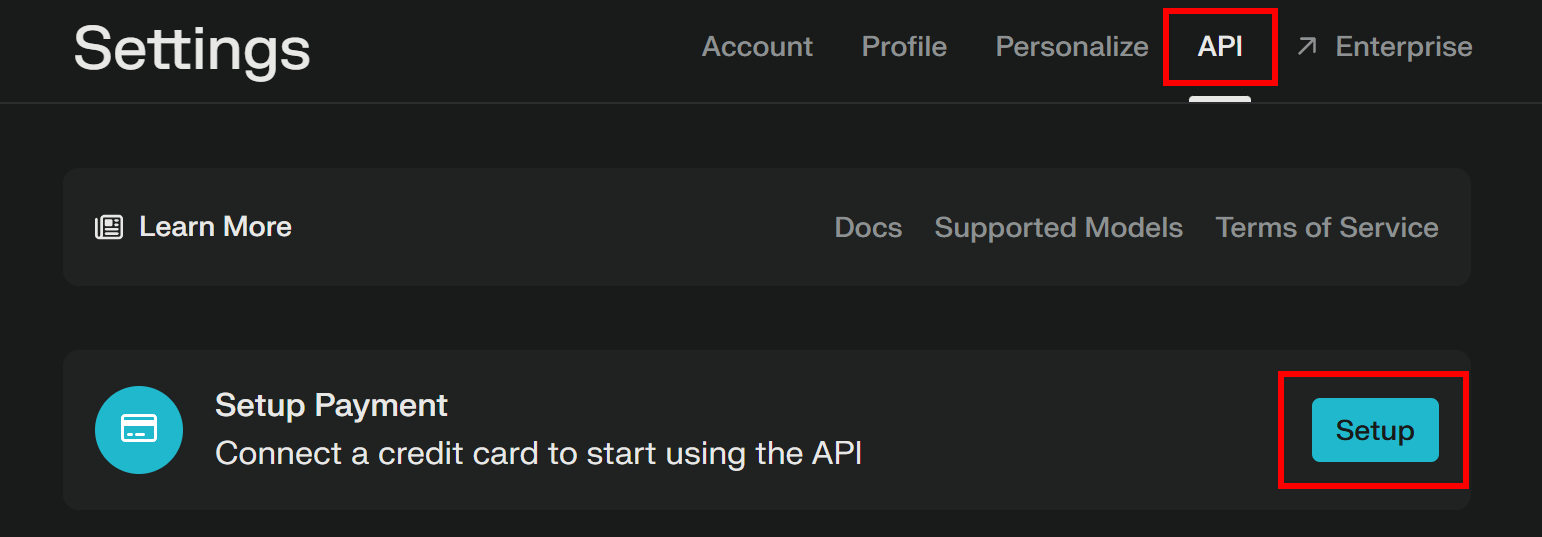
注意:在此步骤不会扣费。Perplexity 只是提前保存你的支付信息,用于未来的 API 使用。你可以使用信用卡/借记卡、Google Pay 等支持的方式。
一旦支付方式设置完成,就会看到如下所示的版面:

点击 “+ Buy Credits” 购买一些额度,并等待它们入账。一旦额度可用,“+ Generate” 按钮(位于 API Keys 区域下方)会变为可点击。按下它即可生成你的 Perplexity API Key:
你将看到一个 API Key:
复制该 Key 并妥善保存。为了方便,我们可在 scraper.py 中将其定义为一个常量:
PERPLEXITY_API_KEY="<YOUR_PERPLEXITY_API_KEY>"重要:在生产环境的 Perplexity 爬虫脚本中,不要将 API Key 以明文形式存储。应将此类密钥保存在环境变量或 .env 文件中,并使用 python-dotenv 之类的库进行管理。
很好!接下来你可以使用 OpenAI 的 SDK 在 Python 中向 Perplexity 的模型发起 API 请求。
第 3 步:在 Python 中配置 Perplexity
上一节最后一句话中提到使用 OpenAI SDK,其实并没有打错字——Perplexity API 与 OpenAI 完全兼容。实际上,Perplexity 给出的推荐方式就是通过 OpenAI Python SDK在 python 中进行对接。
首先,安装 OpenAI Python SDK。在激活的虚拟环境下,执行:
pip install openai然后,在 scraper.py 中导入:
from openai import OpenAI接着,以如下方式配置客户端来连接到 Perplexity,而不是连接到 OpenAI:
client = OpenAI(api_key=PERPLEXITY_API_KEY, base_url="https://api.perplexity.ai")完成!现在你已在 Python 中完成 Perplexity 的配置,可随时进行 API 调用。
第 4 步:获取目标页面的 HTML
现在,你需要获取目标页面的 HTML。可以使用 稳定的 Python HTTP 客户端,例如 Requests。
在激活的虚拟环境下,安装 Requests:
pip install requests然后,在 scraper.py 中导入该库:
import requests使用 get() 方法对目标页面 URL 发起 GET 请求:
url = "https://www.scrapingcourse.com/ecommerce/product/ajax-full-zip-sweatshirt/"
response = requests.get(url)目标服务器将返回该页面的原始 HTML。
如果你打印 response.content,你将看到完整的 HTML 文档:
<!DOCTYPE html>
<html lang="en-US">
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<link rel="profile" href="https://gmpg.org/xfn/11">
<link rel="pingback" href="https://www.scrapingcourse.com/ecommerce/xmlrpc.php">
<!-- omitted for brevity... -->
<title>Ajax Full-Zip Sweatshirt – Ecommerce Test Site to Learn Web Scraping</title>
<!-- omitted for brevity... -->
</head>
<body>
<!-- omitted for brevity... -->
</body>
</html>现在,你已经在 Python 中拿到了目标页面的完整 HTML。下面我们来解析并提取所需数据!
第 5 步:将页面 HTML 转换为 Markdown(可选)
警告:此步骤从技术上来说并不是必需的,但它能为你节省大量时间和费用,因此非常值得考虑。
若你观察其他 AI 驱动的网页爬取技术,如 Crawl4AI 和 ScrapeGraphAI 等,你会发现它们都提供了在将内容发送到相应的大模型前,将 HTML 转换为 Markdown 的选项。
为什么这么做?主要有两个原因:
- 成本效率:将 HTML 转换为 Markdown 可以减少发送给 AI 的 token 总数,进而帮助你节省费用。
- 更快的处理速度:减少输入数据量意味着更低的计算成本和更快的响应。
想了解更多,可查看我们关于为什么新出现的 AI Agent 更偏爱 Markdown 而非 HTML的文章。
是时候通过 HTML-to-Markdown 转换逻辑来减少 token 使用了!
首先,以无痕模式(Incognito)访问目标网页(确保处于全新会话状态)。右键点击页面任意位置并选择“Inspect”,打开开发者工具。
检查页面结构后,你会发现与爬取需求最相关的数据都位于 CSS 选择器 #main 标识的 HTML 元素中:
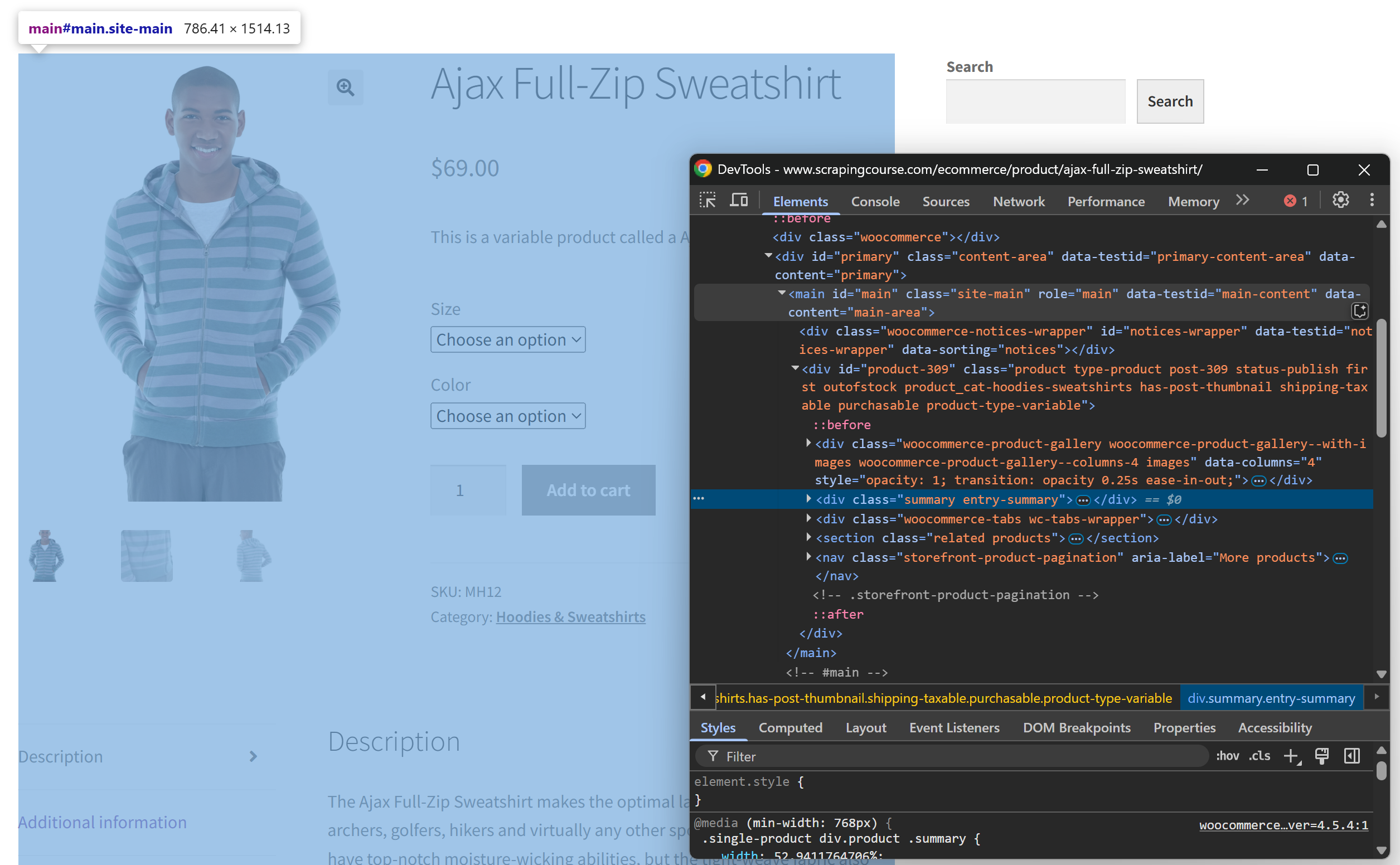
从技术上讲,你可以将整份原始 HTML 发送给 Perplexity 来进行数据解析。然而,这样会包含大量无用的信息——比如页头、页脚等。只使用 #main 中的内容作为输入,可以保证仅处理最关键的数据,这能减少噪音并降低 AI 产生幻觉的可能性。
若要仅提取 #main 元素,可使用 Python HTML 解析库(如 Beautiful Soup)。在激活的 Python 虚拟环境中,安装:
pip install beautifulsoup4若你对其 API 不太熟悉,可阅读我们对Beautiful Soup 网页爬取的相关介绍。
在 scraper.py 文件中导入:
from bs4 import BeautifulSoup,然后使用 Beautiful Soup:
- 解析从 Requests 获取的原始 HTML
- 选择
#main元素 - 获取其 HTML 内容
代码示例如下:
# Parse the HTML of the page with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Select the #main element
main_element = soup.select_one("#main")
# Get its outer HTML
main_html = str(main_element)如果打印 main_html,你会看到如下内容:
<main id="main" class="site-main" role="main" data-testid="main-content" data-content="main-area">
<div class="woocommerce-notices-wrapper"
id="notices-wrapper"
data-testid="notices-wrapper"
data-sorting="notices">
</div>
<div id="product-309"
class="product type-product post-309 status-publish first outofstock
product_cat-hoodies-sweatshirts has-post-thumbnail
shipping-taxable purchasable product-type-variable">
<!-- omitted for brevity... -->
</div>
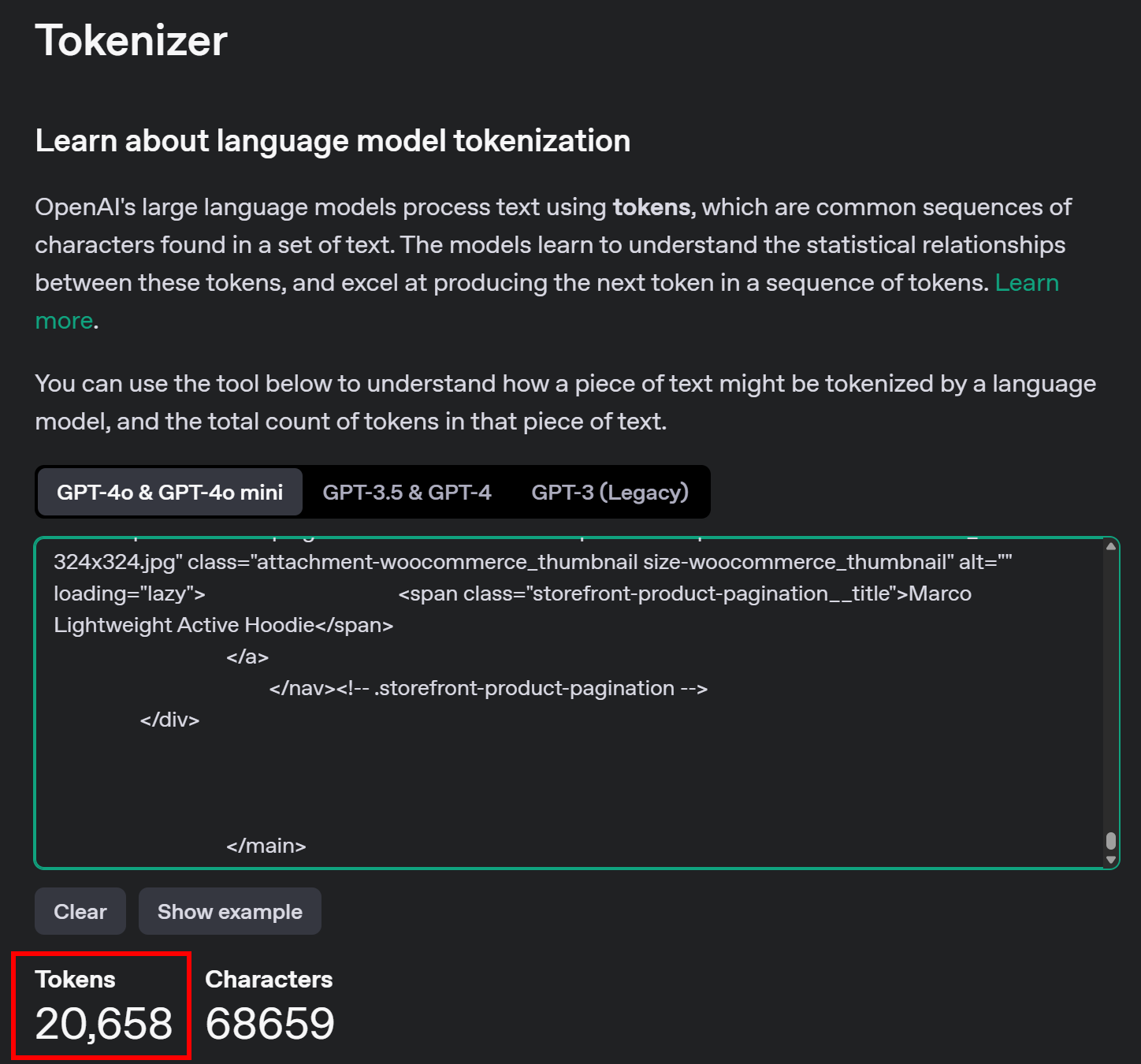
</main>可使用 OpenAI Tokenizer 工具来查看 #main 这部分 HTML 所使用的 token 数量:
接着,可以用 LLM API Pricing Calculator 估算传递这些 token 所需的 Perplexity API 费用:
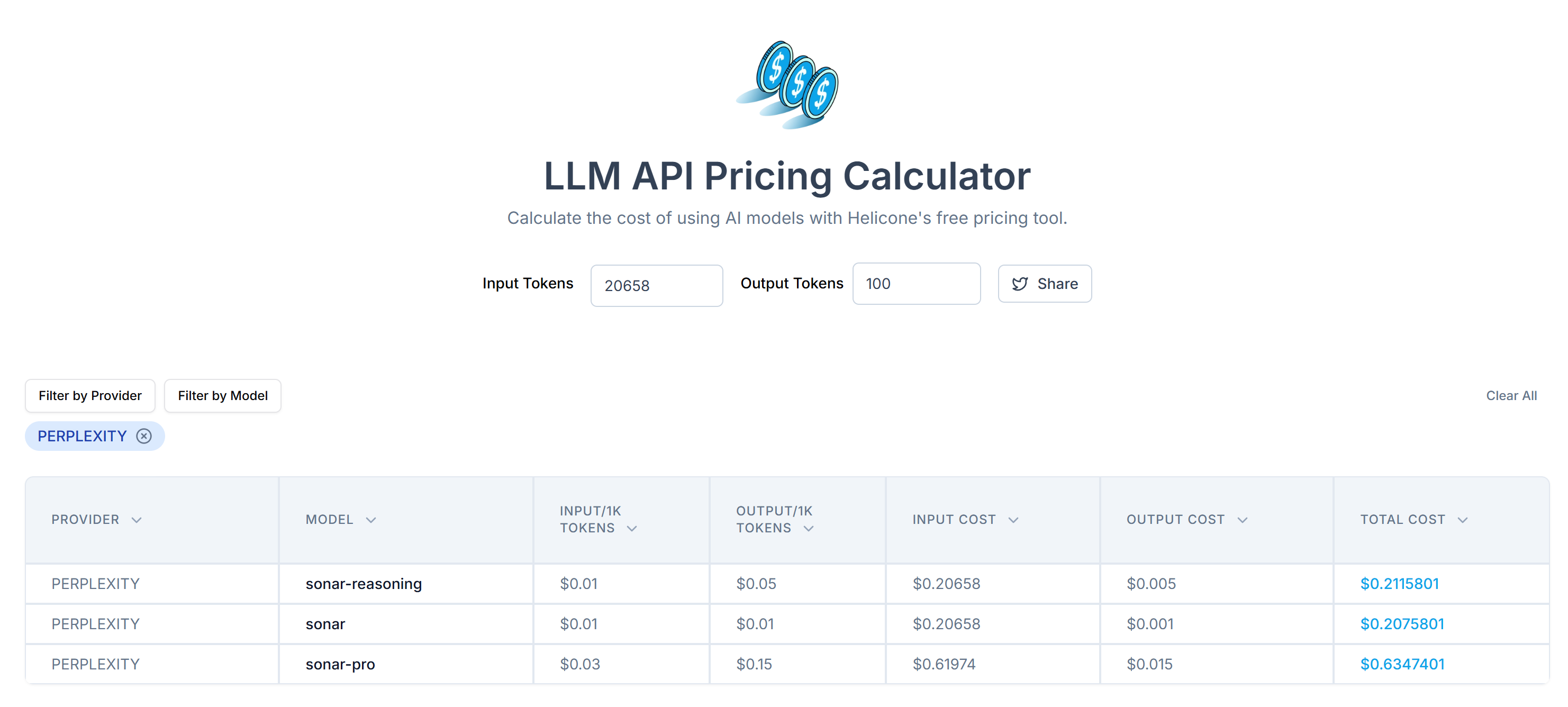
如图,这样的调用大约需要 20,000 多个 token,相当于每次请求花费 0.21~0.63 美元不等。如果要大规模爬取上千个页面,花费就相当高了!
为减少 token 消耗,可使用 markdownify 将提取到的 HTML 转换为 Markdown。安装:
pip install markdownify在 scraper.py 中导入:
from markdownify import markdownify然后,将 #main 的 HTML 转换为 Markdown:
main_markdown = markdownify(main_html)转换后,你将得到类似如下的输出:
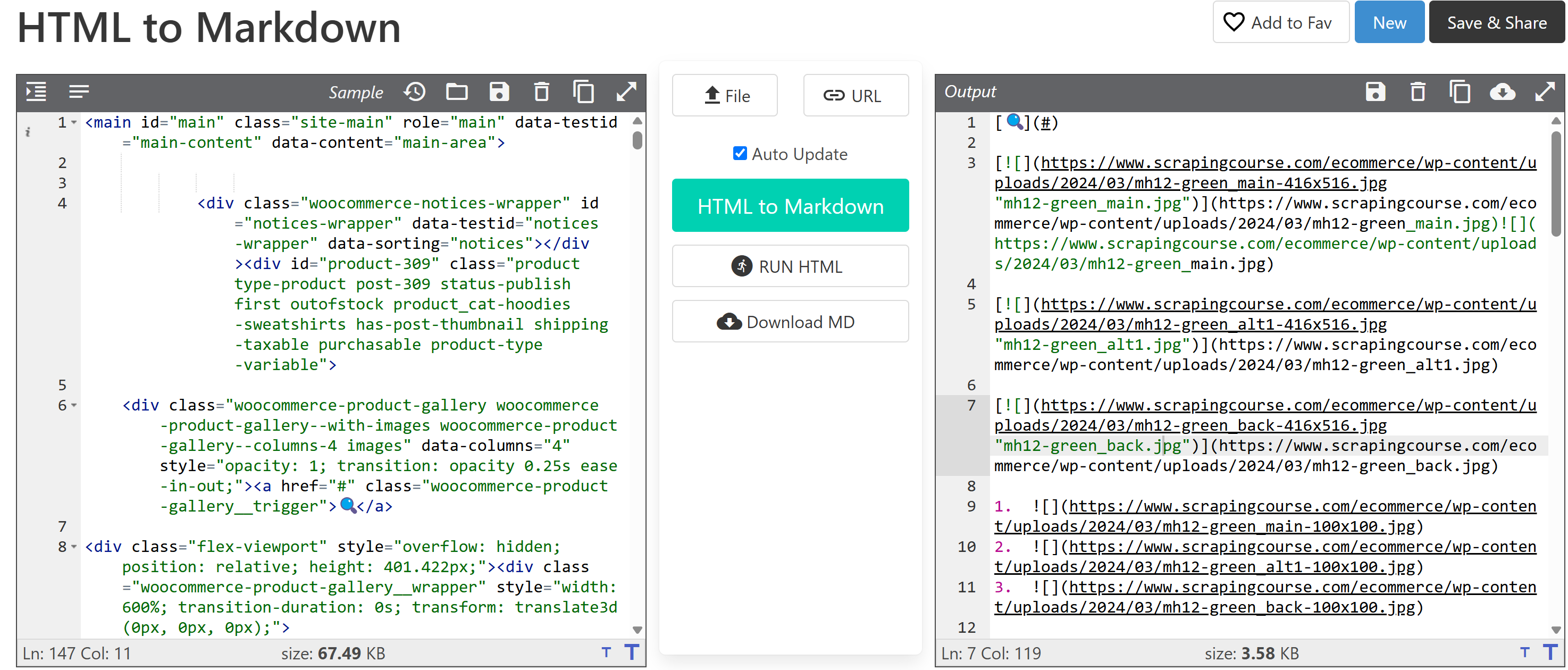
从图中文本区域末尾的“size”元素可见,Markdown 格式比原始 HTML 简洁得多,同时仍保留了所有关键数据。
再次使用 OpenAI 的 Tokenizer 查看转换后 Markdown 的 token 数量:
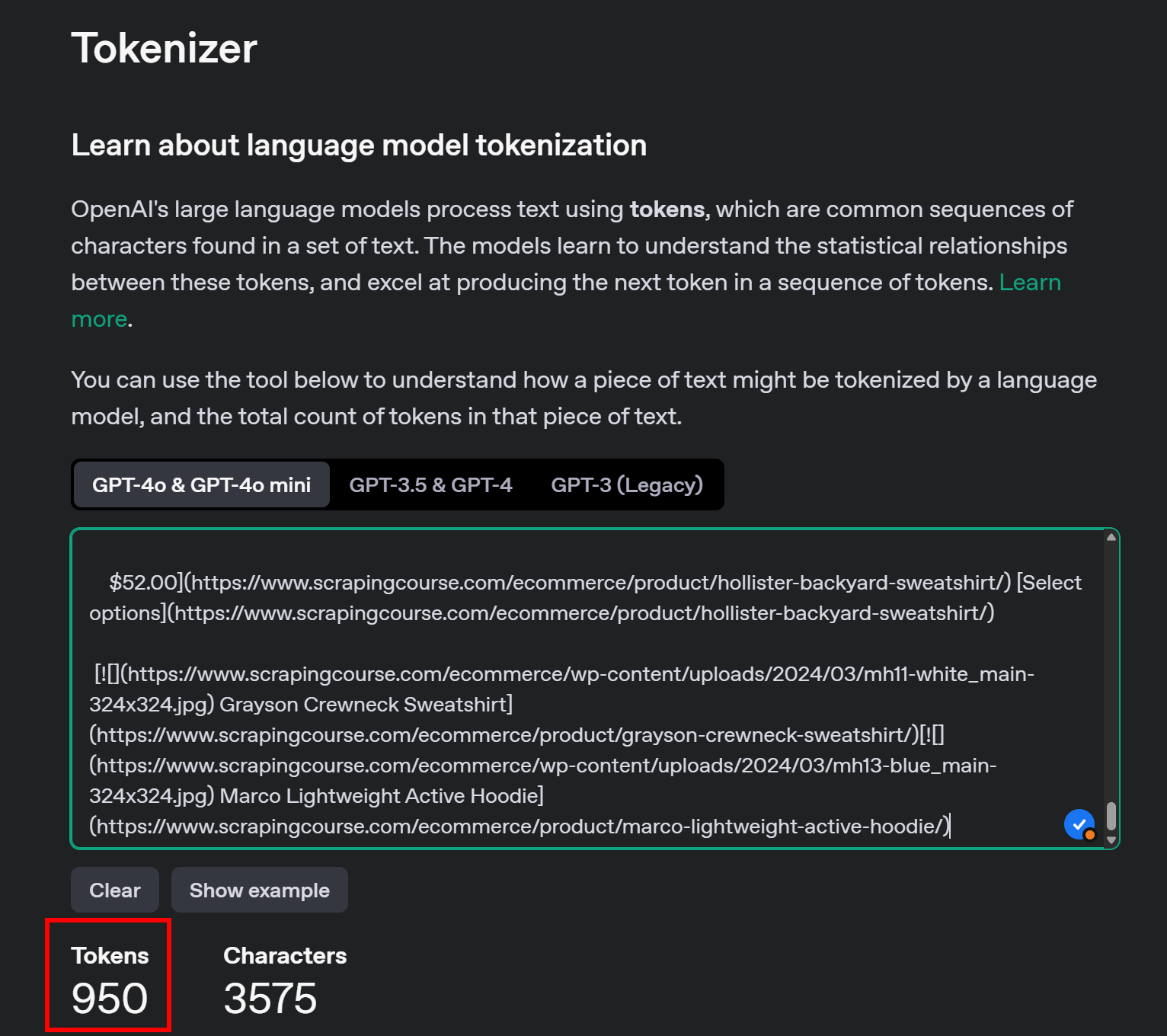
通过这一简单处理,你将 20,658 个 token 减少到约 950 个,缩减幅度超过 95%。费用也相应大幅下降:
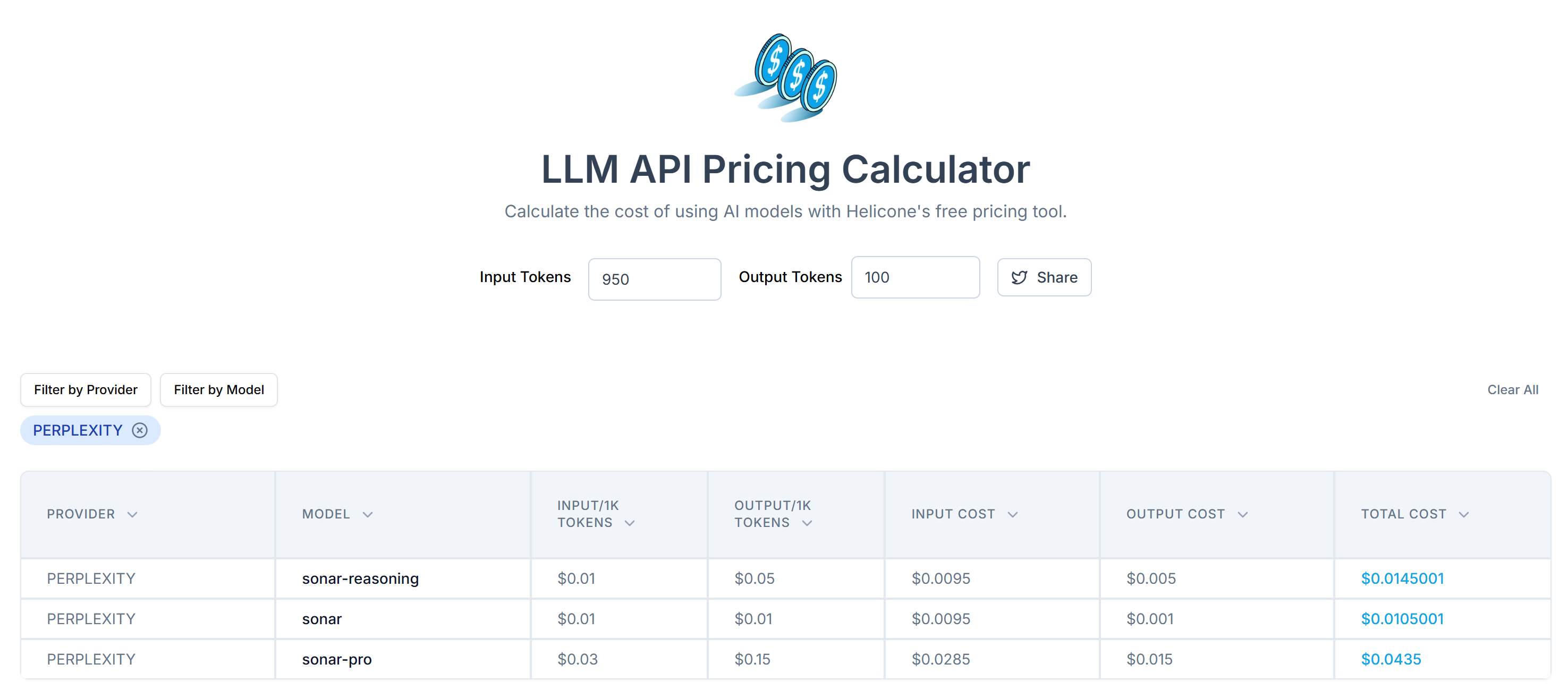
相比最初 0.21~0.63 美元/次请求,现在仅需 0.014~0.04 美元/次请求!
第 6 步:使用 Perplexity 进行数据解析
此处概括了大致步骤:
- 编写格式良好的 Prompt,要求从 Markdown 中提取所需 JSON 数据
- 使用 OpenAI Python SDK 向 Perplexity 模型发起请求
- 解析返回的 JSON
实现前两步的示例代码如下:
# Prepare the Perplexity scraping API request body
prompt = f"""
Extract data from the content below and return JSON string with the specified attributes:nn
sku, name, images, price, description, sizes, colors, category
CONTENT:n
{main_markdown}
"""
messages = [
{
"role": "system",
"content": (
"""
You are a scraping agent that returns scraped data in raw JSON format with no other content.
You only return a JSON string with the scraped data, as instructed.
Do not explain what you did whatsoever and only return the JSON string in raw format.
"""
),
},
{
"role": "user",
"content": (
prompt
),
},
]
# Perform the request to Perplexity
completion = client.chat.completions.create(
model="sonar",
messages=messages,
)
# Get the returned raw JSON data
product_raw_string = completion.choices[0].message.contentprompt 变量用来告诉 Perplexity 从 main_markdown 中提取结构化数据。为了获得更精准的结果,推荐在 system 中给出清晰提示,说明你的意图和所需要做的操作。
注意:Perplexity 目前仍基于 OpenAI 的旧版调用语法。如果你尝试使用新的 responses.create() 语法,会出现以下错误:
httpx.HTTPStatusError: Client error '404 Not Found' for url 'https://api.perplexity.ai/responses'此时,product_raw_string 应含有如下格式的 JSON 数据:
"```json
{
"sku": "MH12",
"name": "Ajax Full-Zip Sweatshirt",
"images": [
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_main.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_alt1.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_back.jpg"
],
"price": "$69.00",
"description": "The Ajax Full-Zip Sweatshirt makes the optimal layering or outer piece for archers, golfers, hikers and virtually any other sportsmen. Not only does it have top-notch moisture-wicking abilities, but the tight-weave fabric also prevents pilling from repeated wash-and-wear cycles.nnMint striped full zip hoodie.n• 100% bonded polyester fleece.n• Pouch pocket.n• Rib cuffs and hem.n• Machine washable.",
"sizes": ["XS", "S", "M", "L", "XL"],
"colors": ["Blue", "Green", "Red"],
"category": "Hoodies & Sweatshirts"
}
```"如你所见,Perplexity 返回的数据通常会被包含在 Markdown 代码块中。
为了实现前面所说的第三步,需要先通过正则表达式提取原始 JSON,再用 json.loads() 将其解析为 Python 字典:
# Check if the string contains "```json" and extract the raw JSON if present
match = re.search(r'```jsonn(.*?)n```', product_raw_string, re.DOTALL)
if match:
# Extract the JSON string from the matched group
json_string = match.group(1)
else:
# Assume the returned data is already in JSON format
json_string = product_raw_string
Try to parse the extracted JSON string into a Python dictionary
product_data = json.loads(json_string)别忘了从 Python 标准库 导入 json 和 re:
import json
import re注意:如果你是 Perplexity Tier-3 用户,可跳过正则提取环节,直接配置 API 以结构化 JSON 格式返回数据。详情可见 Perplexity “Structured Outputs” 指南。
完成 JSON 解析后,你就能通过操作 product_data 来进行下一步处理,例如:
price = product_data["price"]
price_eur = price * USD_EUR
# ...太好了!这就完成了 Perplexity 的网页爬取功能。接下来只需根据需求导出即可。
第 7 步:导出爬取到的数据
目前,你的爬取结果以 Python 字典的形式存储。要将其保存成 JSON 文件,可使用:
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)这样会在项目文件夹里生成一个 product.json 文件,包含爬取到的数据。
干得好!你基于 Perplexity 的网页爬虫已经完成。
第 8 步:整合所有步骤
下面是完整的爬取脚本,使用 Perplexity 进行数据解析:
from openai import OpenAI
import requests
from bs4 import BeautifulSoup
from markdownify import markdownify
import re
import json
# Your Perplexity API key
PERPLEXITY_API_KEY = "<YOUR_PERPLEXITY_API_KEY>" # replace with your API key
# Conffigure the OpenAI SDK to connect to Perplexity
client = OpenAI(api_key=PERPLEXITY_API_KEY, base_url="https://api.perplexity.ai")
# Retrieve the HTML content of the target page
url = "https://www.scrapingcourse.com/ecommerce/product/ajax-full-zip-sweatshirt/"
response = requests.get(url)
# Parse the HTML of the page with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Select the #main element
main_element = soup.select_one("#main")
# Get its outer HTML
main_html = str(main_element)
# Convert the #main HTML to Markdown
main_markdown = markdownify(main_html)
# Prepare the Perplexity scraping API request body
prompt = f"""
Extract data from the content below and return JSON string with the specified attributes:nn
sku, name, images, price, description, sizes, colors, category
CONTENT:n
{main_markdown}
"""
messages = [
{
"role": "system",
"content": (
"""
You are a scraping agent that returns scraped data in raw JSON format with no other content.
You only return a JSON string with the scraped data, as instructed.
Do not explain what you did whatsoever and only return the JSON string in raw format.
"""
),
},
{
"role": "user",
"content": (
prompt
),
},
]
# Perform the request to Perplexity
completion = client.chat.completions.create(
model="sonar",
messages=messages,
)
# Get the returned raw JSON data
product_raw_string = completion.choices[0].message.content
# Check if the string contains "```json" and extract the raw JSON if present
match = re.search(r'```jsonn(.*?)n```', product_raw_string, re.DOTALL)
if match:
# Extract the JSON string from the matched group
json_string = match.group(1)
else:
# Assume the returned data is already in JSON format
json_string = product_raw_string
# Try to parse the extracted JSON string into a Python dictionary
product_data = json.loads(json_string)
# Futher data processing... (optional)
# Export the scraped data to JSON
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)使用以下命令运行该爬取脚本:
python scraper.py执行结束后,项目文件夹中会生成名为 product.json 的文件,内容大致如下:
{
"sku": "MH12",
"name": "Ajax Full-Zip Sweatshirt",
"images": [
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_main.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_alt1.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/mh12-green_back.jpg"
],
"price": "69.00",
"description": "The Ajax Full-Zip Sweatshirt makes the optimal layering or outer piece for archers, golfers, hikers and virtually any other sportsmen. Not only does it have top-notch moisture-wicking abilities, but the tight-weave fabric also prevents pilling from repeated wash-and-wear cycles.n• Mint striped full zip hoodie.n• 100% bonded polyester fleece.n• Pouch pocket.n• Rib cuffs and hem.n• Machine washable.",
"sizes": [
"XS",
"S",
"M",
"L",
"XL"
],
"colors": [
"Blue",
"Green",
"Red"
],
"category": "Hoodies & Sweatshirts"
}大功告成!脚本已成功将 HTML 中的非结构化数据转换为整理完善的 JSON 文件,而一切都归功于 Perplexity 支持的网页爬取。
后续步骤
若想进一步强化基于 Perplexity 的爬虫,可考虑以下改进:
- 使其可复用:通过命令行参数接收提示和目标 URL,让脚本可灵活应用于不同项目和场景。
- 安全存储 API 凭证:在 .env 文件中保存你的 Perplexity API Key,并使用 python-dotenv 来安全加载,避免在脚本中硬编码敏感信息。
- 实现网页爬取功能:结合 Perplexity 的 AI 搜索与爬取功能,进行智能化、优化的链接抓取。可配置脚本自动导航到相关链接页面,提取各来源的结构化数据。
突破此网页爬取方法较大局限的关键
这种基于 AI 的网页爬取方法最大的局限是什么?答案就在我们用到的那一句 HTTP 请求:requests!
上文的示例虽然运行良好,因为目标站点是专门给网页爬取练习的平台。但在真实场景中,大多数企业或网站主都清楚,即使数据是公共可见的,也具备相当的价值,因此会实施各种反爬虫措施,它们能很轻易地阻断普通的自动化请求。
此时,你的脚本可能会出现 403 Forbidden 错误:
requests.exceptions.HTTPError: 403 Client Error: Forbidden for url: <YOUR_TARGET_URL>此外,该方法并不适用于 动态网页,那些依赖 JavaScript 进行渲染或异步获取数据的页面可能根本不需要复杂的反爬虫手段,就能阻止你的 LLM 爬虫。
如何解决这些问题?答案是——网络解锁器 API!
Bright Data 的网络解锁器 API 是一个爬虫端点,可以通过任意 HTTP 客户端调用。它会返回任何指定 URL 已解锁的完整 HTML,无论目标站点具有多么复杂的反爬虫机制,只要简单地向 Web Unlocker 发起请求,你就能轻松获取想要的页面内容。
开始使用前,先查看官方文档来获取你的 API Key。然后,将“第 4 步”中关于 requests 的逻辑替换为:
WEB_UNLOCKER_API_KEY = "<YOUR_WEB_UNLOCKER_API_KEY>"
# Set up authentication headers for Web Unlocker
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {WEB_UNLOCKER_API_KEY}"
}
# Define the request payload
payload = {
"zone": "unblocker",
"url": "https://www.scrapingcourse.com/ecommerce/product/ajax-full-zip-sweatshirt/", # Replace with your target URL
"format": "raw"
}
# Fetch the unlocked HTML of the target page
response = requests.post("https://api.brightdata.com/request", json=payload, headers=headers)这样就没有封锁与限制的烦恼了!使用 Perplexity 进行网页爬取时,再也不用担心被阻止。
总结
在本教程中,你学习了如何结合 Perplexity、Requests 以及其他辅助工具,构建一个 AI 驱动的爬虫。我们还探讨了在遇到反爬虫机制时,如何使用 Bright Data 的网络解锁器 API 解决问题。
通过将 Perplexity 与 Web Unlocker API 组合,你可以在无需编写自定义解析逻辑的情况下从任何网站提取数据。这只是 Bright Data 产品与服务支持的多种应用场景之一,助力你高效实现 AI 驱动的网页爬取。
下方是我们其他网页爬取工具介绍:
- 代理服务:四种类型的代理,可绕过地理位置限制,包括超过 7200 万的住宅 IP 库。
- 网络抓取 API:针对 100+ 常见域名的专用爬取端点,用于提取实时、结构化网页数据。
- 搜索引擎结果页 API:专为搜索引擎结果页解锁和单个页面解析而设计的 API。
- 抓取浏览器:一个可搭配 Puppeteer、Selenium、Playwright 的云端浏览器,内置解锁能力。
立即注册 Bright Data,免费试用我们的代理服务与爬取产品吧!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。