在这个分步教程中,你将了解到:
- RAG的概念及其工作机制
- 通过RAG将SERP数据集成到GPT-4o中的优势
- 如何使用OpenAI GPT模型和SERP数据在Python中实现RAG聊天机器人
让我们开始吧!
什么是RAG?
RAG 即 Retrieval-Augmented Generation的缩写,是一种将信息检索与文本生成相结合的AI方法。在RAG的工作流程中,应用程序首先从外部资源(例如文档、网页或数据库)检索相关数据。然后,它将这些数据传递给AI模型,使得生成的回答具有更贴切的上下文。
RAG可以让GPT这样的大型语言模型(LLM)访问并引用其原始训练数据之外的最新信息。这种方法对于需要准确、上下文相关信息的场景尤为关键,因为它能显著提升AI生成回复的质量和准确度。
为什么要用SERP数据来喂AI模型
GPT-4o的知识截止日期是 2023年10月,也就是说它无法访问这个时间点之后的新事件或新信息。然而,GPT-4o模型可以通过Bing搜索集成功能实时获取互联网数据,让它能够提供更为及时更新的信息。
但如果你想让AI模型使用特定的数据源,或者希望使用更可靠的搜索引擎,该怎么办?这时RAG就发挥作用了!
尤其是通过RAG将SERP(搜索引擎结果页)数据输入AI模型,可以显著提升回答质量。这在需要当前信息或专业见解的任务中尤其有益。
简而言之,将高排名搜索结果中的数据传递给GPT-4o或GPT-4o mini,可以得到更详实、精准且含有丰富上下文的回复。
使用Python在GPT模型中进行RAG结合SERP数据:分步教程
在本教程中,你将学习如何使用OpenAI的GPT模型构建RAG聊天机器人。其核心思路是:针对某个搜索关键词,自Google搜索结果中获取排名前列网页上的文本,并将其作为发送给GPT的上下文。
最大的挑战在于爬取SERP数据。因为大部分搜索引擎都有高阶的防爬虫机制,以阻止程序化访问其页面。详情可参考我们关于 如何使用Python爬取Google的指南。
为了简化爬虫过程,我们将使用 Bright Data的SERP API:
这个高级SERP抓取器允许你通过简单的HTTP请求获取Google、DuckDuckGo、Bing、Yandex、Baidu以及其他搜索引擎的SERP。
接下来,我们会使用无头浏览器从SERP搜索结果中的URL提取文本数据。然后把这些信息作为GPT模型的上下文,以完成RAG工作流程。如果你想通过AI直接抓取在线数据,可以参考我们的文章:使用ChatGPT进行Web Scraping。
如果你希望查看示例代码,或者在阅读本教程时手头留一份,可以克隆本文的GitHub仓库:
git clone https://github.com/Tonel/rag_gpt_serp_scraping按照README.md文件中的说明来安装项目依赖并启动该项目。
请注意,本文介绍的方法也可以轻松地适配到任何其他搜索引擎或LLM上。
注意:本指南在Unix和macOS环境下演示示例。如果你正在使用Windows,也可以通过 Windows Subsystem for Linux(WSL)来执行。
步骤 #1:初始化Python项目
确保你的机器上已经安装了Python 3。如果没有,请从 Python官网下载安装。
创建一个项目文件夹并在终端进入:
mkdir rag_gpt_serp_scraping
cd rag_gpt_serp_scraping在rag_gpt_serp_scraping文件夹中将存放你的Python RAG项目。
然后,用你的常用Python IDE加载这个项目文件夹。比如PyCharm Community Edition或带有Python扩展的Visual Studio Code。
在rag_gpt_serp_scraping文件夹里,创建一个空的app.py文件。后续我们会在这个文件里编写爬取和RAG逻辑。
接下来,在项目目录下初始化一个 Python虚拟环境:
python3 -m venv env使用下面的命令激活虚拟环境:
source ./env/bin/activate太好了!环境已经就绪。
步骤 #2:安装所需的库
本教程使用的依赖库如下:
python-dotenv:用于从.env文件中加载环境变量。可用来安全地管理敏感凭证,如Bright Data的密钥和OpenAI API密钥。requests:用来向Bright Data的SERP API发起HTTP请求。更多用法信息见 如何与Requests配合代理。langchain-community:这是 LangChain框架的一部分。LangChain是一个用于构建LLM应用的工具集,包含可交互使用的组件。这里将它用于从Google SERP页面获取文本,并对其进行清洗,生成对RAG有用的内容。openai:这是 OpenAI API的官方Python客户端库。我们使用它与GPT模型交互,并基于输入和RAG上下文生成自然语言回应。streamlit:一个用Python快速搭建交互式Web应用的框架。我们将用它来搭建一个UI,让用户输入Google搜索关键词和AI请求,并动态查看结果。
在激活的虚拟环境里,运行以下命令安装所有依赖:
pip install python-dotenv requests langchain-community openai streamlit细分而言,我们将使用AsyncChromiumLoader(隶属于langchain-community),这需要额外安装以下依赖:
pip install --upgrade --quiet playwright beautifulsoup4 html2textPlaywright在正常工作时还需要安装浏览器:
playwright install安装所有这些库需要一点时间,请耐心等待。
棒极了!现在我们可以开始编写项目逻辑了。
步骤 #3:项目初始化
在app.py文件中,先加入如下导入语句:
from dotenv import load_dotenv
import os
import requests
from langchain_community.document_loaders import AsyncChromiumLoader
from langchain_community.document_transformers import BeautifulSoupTransformer
from openai import OpenAI
import streamlit as st然后,在项目文件夹下新建一个.env文件,用于存储你的各项密钥。此时你的项目结构大致如下所示:
在app.py中,用下面这行代码来调用python-dotenv从.env加载环境变量:
load_dotenv()这样就可以通过如下方式获取.env或系统环境变量:
os.environ.get("<ENV_NAME>")这也是我们导入os标准库的原因。
步骤 #4:配置SERP API
正如在介绍中所述,我们将依赖Bright Data的SERP API来获取搜索引擎结果页,并把这些内容用在Python RAG逻辑中。具体而言,我们要抓取SERP结果中URL的网页文本。
要配置SERP API,请参考官方文档,或根据下述步骤进行。
如果你还没有创建账户,点此注册Bright Data。注册完成后,进入你的账号控制台:
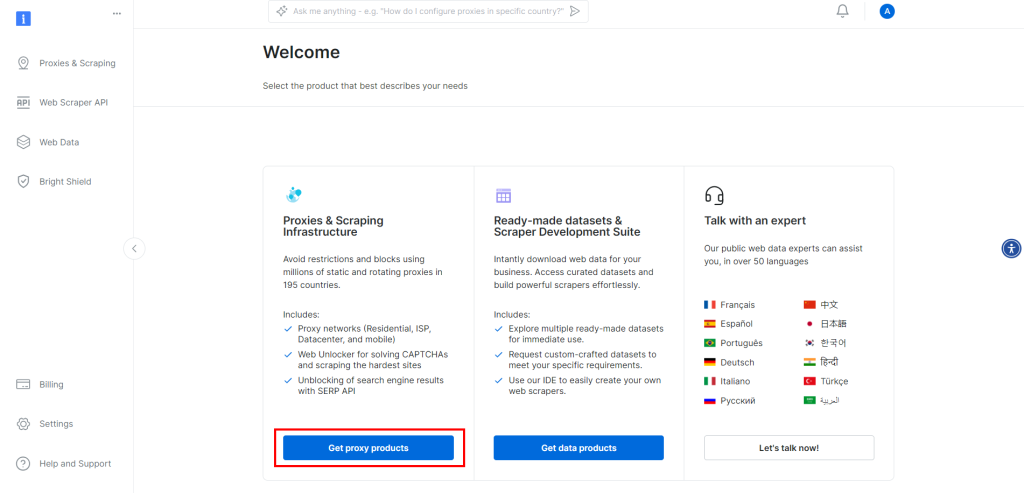
点击“Get proxy products”按钮。
然后会进入下图所示的页面,在这里点击“SERP API”一行:
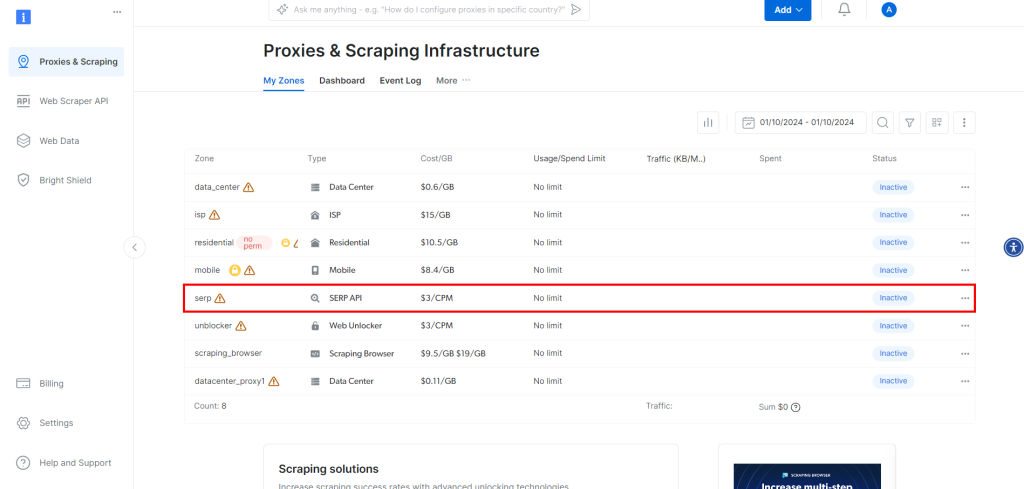
在SERP API产品页面,切换“Activate zone”到开启状态:
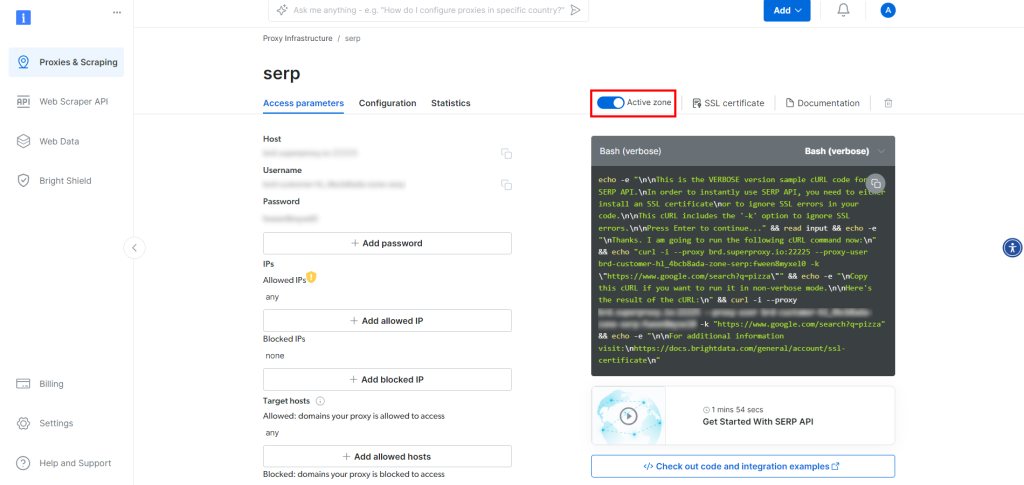
现在,在“Access parameters”区域复制SERP API的host、port、username和password,并添加到.env文件中:
BRIGHT_DATA_SERP_API_HOST="<YOUR_HOST>"
BRIGHT_DATA_SERP_API_PORT=<YOUR_PORT>
BRIGHT_DATA_SERP_API_USERNAME="<YOUR_USERNAME>"
BRIGHT_DATA_SERP_API_PASSWORD="<YOUR_PASSWORD>"将<YOUR_XXXX>替换为Bright Data提供的SERP API页面上对应的参数值。
注意,“Access parameters”中显示的host格式类似:
brd.superproxy.io:33335需要拆分成:
BRIGHT_DATA_SERP_API_HOST="brd.superproxy.io"
BRIGHT_DATA_SERP_API_PORT=33335非常好!现在可以在Python中使用SERP API了。
步骤 #5:实现SERP爬取逻辑
在app.py中,添加如下函数,用于获取Google SERP页面前number_of_urls条URL:
def get_google_serp_urls(query, number_of_urls=5):
# perform a Bright Data's SERP API request
# with JSON autoparsing
host = os.environ.get("BRIGHT_DATA_SERP_API_HOST")
port = os.environ.get("BRIGHT_DATA_SERP_API_PORT")
username = os.environ.get("BRIGHT_DATA_SERP_API_USERNAME")
password = os.environ.get("BRIGHT_DATA_SERP_API_PASSWORD")
proxy_url = f"http://{username}:{password}@{host}:{port}"
proxies = {"http": proxy_url, "https": proxy_url}
url = f"https://www.google.com/search?q={query}&brd_json=1"
response = requests.get(url, proxies=proxies, verify=False)
# retrieve the parsed JSON response
response_data = response.json()
# extract a "number_of_urls" number of
# Google SERP URLs from the response
google_serp_urls = []
if "organic" in response_data:
for item in response_data["organic"]:
if "link" in item:
google_serp_urls.append(item["link"])
return google_serp_urls[:number_of_urls]这个函数会使用传入的query对SERP API发起HTTP GET请求,并传入brd_json=1参数,确保SERP API返回JSON格式的解析结果,结构大致如下:
{
"general": {
"search_engine": "google",
"results_cnt": 1980000000,
"search_time": 0.57,
"language": "en",
"mobile": false,
"basic_view": false,
"search_type": "text",
"page_title": "pizza - Google Search",
"code_version": "1.90",
"timestamp": "2023-06-30T08:58:41.786Z"
},
"input": {
"original_url": "https://www.google.com/search?q=pizza&brd_json=1",
"user_agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_12) AppleWebKit/608.2.11 (KHTML, like Gecko) Version/13.0.3 Safari/608.2.11",
"request_id": "hl_1a1be908_i00lwqqxt1"
},
"organic": [
{
"link": "https://www.pizzahut.com/",
"display_link": "https://www.pizzahut.com",
"title": "Pizza Hut | Delivery & Carryout - No One OutPizzas The Hut!",
"image": "omitted for brevity...",
"image_alt": "pizza from www.pizzahut.com",
"image_base64": "omitted for brevity...",
"rank": 1,
"global_rank": 1
},
{
"link": "https://www.dominos.com/en/",
"display_link": "https://www.dominos.com › ...",
"title": "Domino's: Pizza Delivery & Carryout, Pasta, Chicken & More",
"description": "Order pizza, pasta, sandwiches & more online for carryout or delivery from Domino's. View menu, find locations, track orders. Sign up for Domino's email ...",
"image": "omitted for brevity...",
"image_alt": "pizza from www.dominos.com",
"image_base64": "omitted for brevity...",
"rank": 2,
"global_rank": 3
},
// omitted for brevity...
],
// omitted for brevity...
}本函数的最后几行会将获取到的SERP返回JSON中的搜索结果链接,取前number_of_urls个并返回一个列表。
接下来我们就要从这些URL中提取文本了!
步骤 #6:从SERP URL中提取文本
定义一个函数,用于从SERP返回的每个URL中抽取文本:
def extract_text_from_urls(urls, number_of_words=600):
# instruct a headless Chrome instance to visit the provided URLs
# with the specified user-agent
loader = AsyncChromiumLoader(
urls,
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36",
)
html_documents = loader.load()
# process the extracted HTML documents to extract text from them
bs_transformer = BeautifulSoupTransformer()
docs_transformed = bs_transformer.transform_documents(
html_documents,
tags_to_extract=["p", "em", "li", "strong", "h1", "h2"],
unwanted_tags=["a"],
remove_comments=True,
)
# make sure each HTML text document contains only a number
# number_of_words words
extracted_text_list = []
for doc_transformed in docs_transformed:
# split the text into words and join the first number_of_words
words = doc_transformed.page_content.split()[:number_of_words]
extracted_text = " ".join(words)
# ignore empty text documents
if len(extracted_text) != 0:
extracted_text_list.append(extracted_text)
return extracted_text_list这个函数的主要流程:
- 用无头Chrome浏览器访问传入的URL列表。
- 用BeautifulSoupTransformer处理每个页面的HTML,提取指定标签(例如<p>、<h1>、<strong>等)中的文本,忽略不需要的标签(例如<a>)和注释。
- 将每个页面提取的文本限制在
number_of_words个单词之内。 - 将提取到的文本列表返回。
请注意,[“p”, “em”, “li”, “strong”, “h1”, “h2”]这几个标签通常足以提取大部分网页内容。但在某些特定场景,你可能需要自定义HTML标签列表。此外,你也可以根据需要调整每篇文章保留的字数大小。
例如,考虑这个页面:
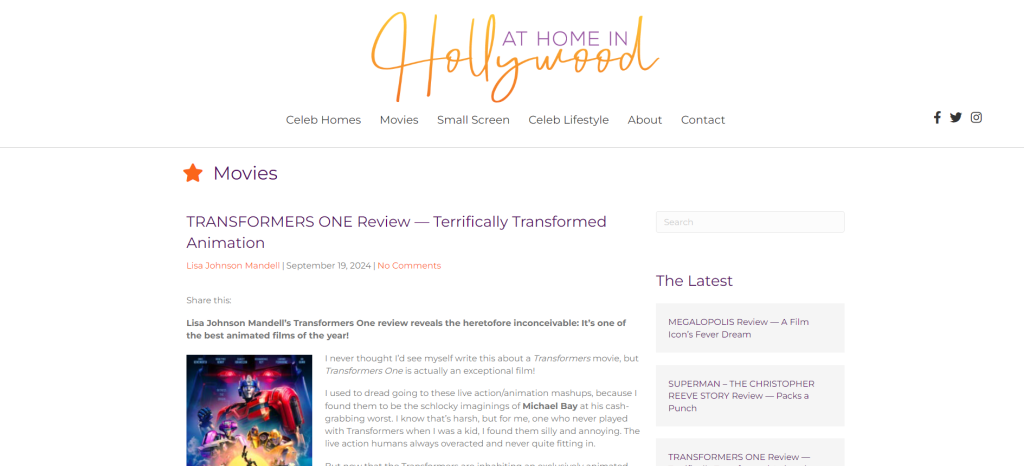
用上述函数处理该页面得到的结果将是类似这样的文本列表:
["Lisa Johnson Mandell’s Transformers One review reveals the heretofore inconceivable: It’s one of the best animated films of the year! I never thought I’d see myself write this about a Transformers movie, but Transformers One is actually an exceptional film! ..."]虽然并不完美,但对AI模型来说已经相当可用。
extract_text_from_urls()返回的字符串列表就是RAG要提供给OpenAI模型的上下文。
步骤 #7:生成RAG提示词(Prompt)
定义一个函数,用于将AI请求内容和文本上下文合并为最终的RAG提示词:
def get_openai_prompt(request, text_context=[]):
# default prompt
prompt = request
# add the context to the prompt, if present
if len(text_context) != 0:
context_string = "nn--------nn".join(text_context)
prompt = f"Answer the request using only the context below.nnContext:n{context_string}nnRequest: {request}"
return prompt如果包含RAG上下文的话,上述函数返回的Prompt格式为:
Answer the request using only the context below.
Context:
Bla bla bla...
--------
Bla bla bla...
--------
Bla bla bla...
Request: <YOUR_REQUEST>步骤 #8:完成GPT请求
首先,在app.py顶部初始化OpenAI客户端:
openai_client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))这里使用了OPENAI_API_KEY环境变量,你可以直接在系统中设置,也可以在.env文件中设置:
OPENAI_API_KEY="<YOUR_API_KEY>"
将<YOUR_API_KEY>替换为你在OpenAI API页面获取的API密钥。如果你不了解如何获取,可参考OpenAI官方指南。
然后,写一个函数使用OpenAI官方客户端调用 GPT-4o mini模型:
def interrogate_openai(prompt, max_tokens=800):
# interrogate the OpenAI model with the given prompt
response = openai_client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
max_tokens=max_tokens,
)
return response.choices[0].message.content当然你也可以设置为OpenAI API所支持的其他GPT模型。
如果在调用interrogate_openai()时传入的是get_openai_prompt()返回的带有文本上下文的prompt,就能实现正常的RAG。
步骤 #9:创建应用UI
使用Streamlit创建一个表单,让用户可以输入:
- 提交给SERP API的Google搜索关键词
- 要发送给GPT-4o mini的AI请求
实现代码如下:
with st.form("prompt_form"):
# initialize the output results
result = ""
final_prompt = ""
# textarea for user to input their Google search query
google_search_query = st.text_area("Google Search:", None)
# textarea for user to input their AI prompt
request = st.text_area("AI Prompt:", None)
# button to submit the form
submitted = st.form_submit_button("Send")
# if the form is submitted
if submitted:
# retrieve the Google SERP URLs from the given search query
google_serp_urls = get_google_serp_urls(google_search_query)
# extract the text from the respective HTML pages
extracted_text_list = extract_text_from_urls(google_serp_urls)
# generate the AI prompt using the extracted text as context
final_prompt = get_openai_prompt(request, extracted_text_list)
# interrogate an OpenAI model with the generated prompt
result = interrogate_openai(final_prompt)
# dropdown containing the generated prompt
final_prompt_expander = st.expander("AI Final Prompt:")
final_prompt_expander.write(final_prompt)
# write the result from the OpenAI model
st.write(result)就是这些!你的Python RAG脚本已经完成。
步骤 #10:整合所有代码
最终你的app.py文件应该如下所示:
from dotenv import load_dotenv
import os
import requests
from langchain_community.document_loaders import AsyncChromiumLoader
from langchain_community.document_transformers import BeautifulSoupTransformer
from openai import OpenAI
import streamlit as st
# load the environment variables from the .env file
load_dotenv()
# initialize the OpenAI API client with your API key
openai_client = OpenAI(api_key=os.environ.get("OPENAI_API_KEY"))
def get_google_serp_urls(query, number_of_urls=5):
# perform a Bright Data's SERP API request
# with JSON autoparsing
host = os.environ.get("BRIGHT_DATA_SERP_API_HOST")
port = os.environ.get("BRIGHT_DATA_SERP_API_PORT")
username = os.environ.get("BRIGHT_DATA_SERP_API_USERNAME")
password = os.environ.get("BRIGHT_DATA_SERP_API_PASSWORD")
proxy_url = f"http://{username}:{password}@{host}:{port}"
proxies = {"http": proxy_url, "https": proxy_url}
url = f"https://www.google.com/search?q={query}&brd_json=1"
response = requests.get(url, proxies=proxies, verify=False)
# retrieve the parsed JSON response
response_data = response.json()
# extract a "number_of_urls" number of
# Google SERP URLs from the response
google_serp_urls = []
if "organic" in response_data:
for item in response_data["organic"]:
if "link" in item:
google_serp_urls.append(item["link"])
return google_serp_urls[:number_of_urls]
def extract_text_from_urls(urls, number_of_words=600):
# instruct a headless Chrome instance to visit the provided URLs
# with the specified user-agent
loader = AsyncChromiumLoader(
urls,
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36",
)
html_documents = loader.load()
# process the extracted HTML documents to extract text from them
bs_transformer = BeautifulSoupTransformer()
docs_transformed = bs_transformer.transform_documents(
html_documents,
tags_to_extract=["p", "em", "li", "strong", "h1", "h2"],
unwanted_tags=["a"],
remove_comments=True,
)
# make sure each HTML text document contains only a number
# number_of_words words
extracted_text_list = []
for doc_transformed in docs_transformed:
# split the text into words and join the first number_of_words
words = doc_transformed.page_content.split()[:number_of_words]
extracted_text = " ".join(words)
# ignore empty text documents
if len(extracted_text) != 0:
extracted_text_list.append(extracted_text)
return extracted_text_list
def get_openai_prompt(request, text_context=[]):
# default prompt
prompt = request
# add the context to the prompt, if present
if len(text_context) != 0:
context_string = "nn--------nn".join(text_context)
prompt = f"Answer the request using only the context below.nnContext:n{context_string}nnRequest: {request}"
return prompt
def interrogate_openai(prompt, max_tokens=800):
# interrogate the OpenAI model with the given prompt
response = openai_client.chat.completions.create(
model="gpt-4o-mini",
messages=[{"role": "user", "content": prompt}],
max_tokens=max_tokens,
)
return response.choices[0].message.content
# create a form in the Streamlit app for user input
with st.form("prompt_form"):
# initialize the output results
result = ""
final_prompt = ""
# textarea for user to input their Google search query
google_search_query = st.text_area("Google Search:", None)
# textarea for user to input their AI prompt
request = st.text_area("AI Prompt:", None)
# button to submit the form
submitted = st.form_submit_button("Send")
# if the form is submitted
if submitted:
# retrieve the Google SERP URLs from the given search query
google_serp_urls = get_google_serp_urls(google_search_query)
# extract the text from the respective HTML pages
extracted_text_list = extract_text_from_urls(google_serp_urls)
# generate the AI prompt using the extracted text as context
final_prompt = get_openai_prompt(request, extracted_text_list)
# interrogate an OpenAI model with the generated prompt
result = interrogate_openai(final_prompt)
# dropdown containing the generated prompt
final_prompt_expander = st.expander("AI Final Prompt")
final_prompt_expander.write(final_prompt)
# write the result from the OpenAI model
st.write(result)难以置信的是,不到150行Python代码,就可以实现RAG了!
步骤 #11:测试应用
使用以下命令启动Python RAG应用:
streamlit run app.py在终端,你会看到类似如下输出:
You can now view your Streamlit app in your browser.
Local URL: http://localhost:8501
Network URL: http://172.27.134.248:8501根据提示,在浏览器中访问http://localhost:8501。你应该能看到如下界面:
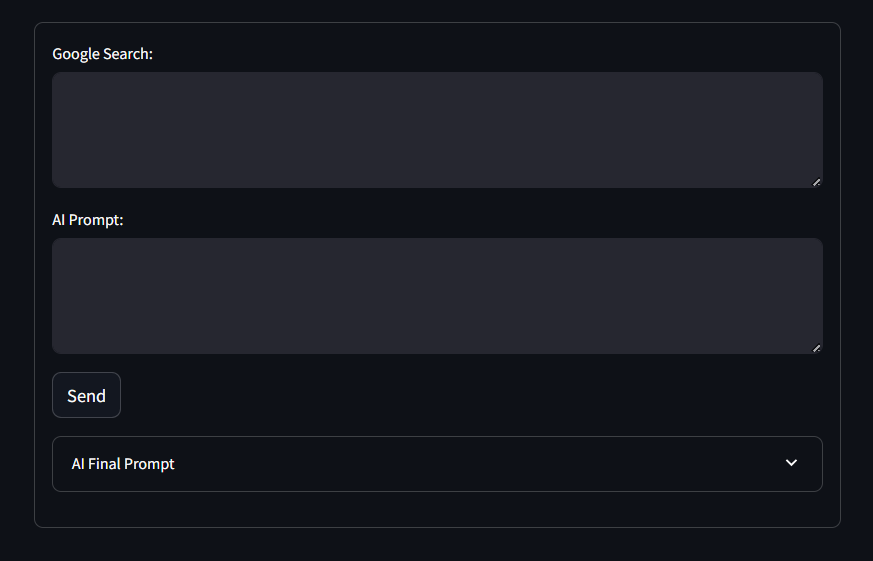
可以看到,与之前代码一致,表单包含了“Google Search:”和“AI Prompt:”的文本区域,以及“Send”按钮和“AI Final Prompt”下拉框。
现在来测试一下。在“Google Search:”里输入:
Transformers One review在“AI Prompt:”里输入:
Write a review for the movie Transformers One点击“Send”后,等待应用执行。过几秒钟,你会看到类似这样的结果:
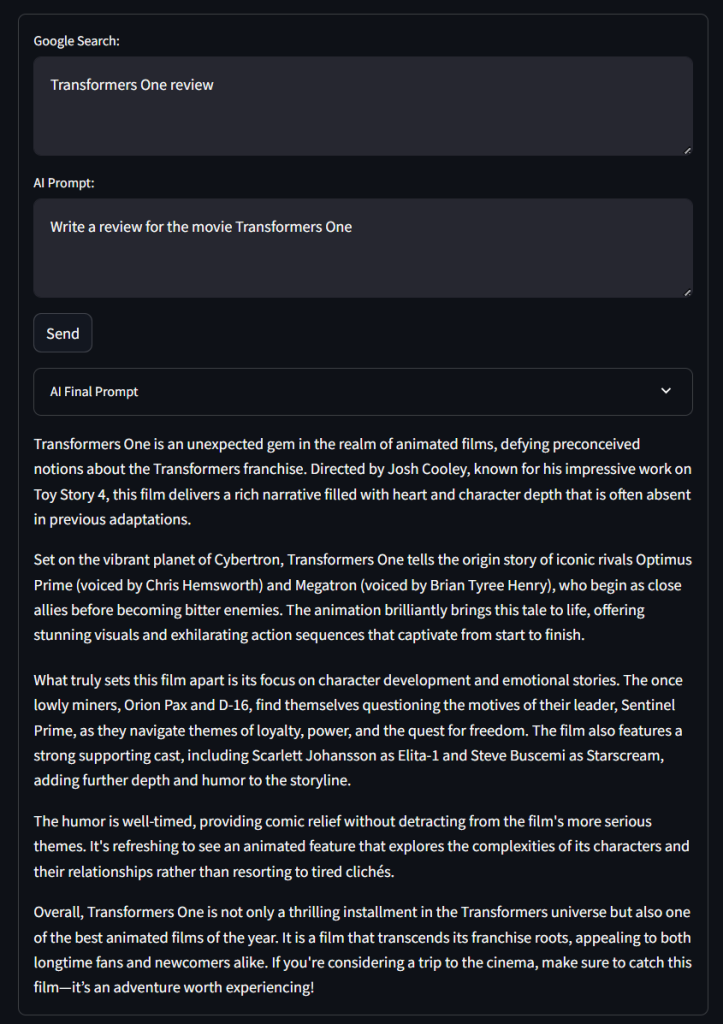
非常棒!出来的影评虽然简短,但还不错……
如果展开“AI Final Prompt”,你将看到本程序用于RAG的完整提示词。
就这样!你用Python结合SERP数据,为GPT-4o mini实现了一个RAG聊天机器人。
结论
本教程介绍了RAG的概念以及通过SERP数据向AI模型输入信息,以实现更准确回复的方法。尤其演示了如何构建一个Python RAG聊天机器人,通过爬取搜索引擎数据并将其用于GPT模型,以提升结果准确度。
这里最大的挑战是对Google这类搜索引擎的爬取:
- 它们常常改变SERP页面的结构。
- 它们拥有最复杂的反爬虫措施之一。
- 并发获取大量SERP数据既复杂又有潜在的成本问题。
正如文中所示,Bright Data的SERP API能帮助你轻松获取各种搜索引擎的实时SERP数据,非常适合做RAG和其他多种应用。赶快来试用一下吧!
马上注册,探索Bright Data的各种代理服务或爬取产品,看看哪一种更适合你的需求。先试用再下决定!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。