





- 基于 API 的采集器
使用我们的界面构建你的 API 请求 - 可规模化自动化
搭建你自己的调度器来控制采集频率 - 交付
将数据交付到你偏好的存储,或直接下载
- 通过 API 或无代码爬虫按需抓取
- 仅为成功交付的结果付费
- 批量请求处理,最多 5,000 个 URL
- 以多种格式获取结果
值得信赖 全球 超20000 位客户
![]()
![]()
全球 超20000 位客户信赖

网页爬虫 API
网页爬虫 API 库
无需开发和维护基础设施。只需使用网页爬虫 API,轻松提取大规模网页数据,并确保可扩展性和可靠性。
LinkedIn people profiles
ID, Name, City, Country code, Position, About, Posts, Current company, and more.
 9.8K+
9.8K+Amazon products
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Amazon products - Collects products by best sellers category URL
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Amazon products - Collects products by specific category URL
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Amazon products - Collects products by specific keywords
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Amazon products - find products by using upc numbers
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
LinkedIn company information
ID, Name, Country code, Locations, Followers, Employees in linkedin, About, Specialties, and more.
Instagram - Profiles
Account, Fbid, ID, Followers, Posts count, Is business account, Is professional account, Is verified, and more.
Instagram - Profiles - Collect profile information by user name
Account, Fbid, ID, Followers, Posts count, Is business account, Is professional account, Is verified, and more.
Crunchbase companies information
Name, URL, ID, Cb rank, Region, About, Industries, Operating status, and more.
Crunchbase companies information - Searching data by keyword
Name, URL, ID, Cb rank, Region, About, Industries, Operating status, and more.
Linkedin job listings information
URL, Job posting id, Job title, Company name, Company id, Job location, Job summary, Job seniority level, and more.
Linkedin job listings information - Discover new jobs by keyword
URL, Job posting id, Job title, Company name, Company id, Job location, Job summary, Job seniority level, and more.
Linkedin job listings information - Discover jobs by company URL
URL, Job posting id, Job title, Company name, Company id, Job location, Job summary, Job seniority level, and more.
Instagram - Posts
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Photos, and more.
Instagram - Posts - Collects posts from a specific URLs by using profile URL
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Photos, and more.
Zillow properties listing information
Zpid, City, State, HomeStatus, Address, IsListingClaimedByCurrentSignedInUser, IsCurrentSignedInAgentResponsible, Bedrooms, and more.
Zillow properties listing information - Discover by custom filters - location, home type and status
Zpid, City, State, HomeStatus, Address, IsListingClaimedByCurrentSignedInUser, IsCurrentSignedInAgentResponsible, Bedrooms, and more.
Zillow properties listing information - Search by parameters on zillow and use the direct link as input
Zpid, City, State, HomeStatus, Address, IsListingClaimedByCurrentSignedInUser, IsCurrentSignedInAgentResponsible, Bedrooms, and more.
Google Maps full information
Place id, URL, Country, Name, Category, Address, Description, Business details, and more.
Google Maps full information - discover records by location search
Place id, URL, Country, Name, Category, Address, Description, Business details, and more.
Google Maps full information - Collect Google Maps Businesses data by place id
Place id, URL, Country, Name, Category, Address, Description, Business details, and more.
Google Maps full information - Discover new records by Customer ID
Place id, URL, Country, Name, Category, Address, Description, Business details, and more.
LinkedIn posts
URL, ID, User id, Use url, Title, Headline, Post text, Date posted, and more.
LinkedIn posts - Discover user's articles by URL
URL, ID, User id, Use url, Title, Headline, Post text, Date posted, and more.
LinkedIn posts - Discover posts by Profile URL
URL, ID, User id, Use url, Title, Headline, Post text, Date posted, and more.
LinkedIn posts - Discover new posts company URL
URL, ID, User id, Use url, Title, Headline, Post text, Date posted, and more.
X (formerly Twitter) - Posts
ID, User posted, Name, Description, Date posted, Photos, URL, Quoted post, and more.
X (formerly Twitter) - Posts - Collecting Twitter posts URLs
ID, User posted, Name, Description, Date posted, Photos, URL, Quoted post, and more.
X (formerly Twitter) - Posts - It collects the latest posts from the profile URL.
ID, User posted, Name, Description, Date posted, Photos, URL, Quoted post, and more.
X (formerly Twitter) - Posts - Getting x posts by array of profiles
ID, User posted, Name, Description, Date posted, Photos, URL, Quoted post, and more.
TikTok - Profiles
Account id, Nickname, Biography, Awg engagement rate, Comment engagement rate, Like engagement rate, Bio link, Predicted lang, and more.
TikTok - Profiles - Discover by search URL and country
Account id, Nickname, Biography, Awg engagement rate, Comment engagement rate, Like engagement rate, Bio link, Predicted lang, and more.
Youtube - Videos posts
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Search new youtube videos by keyword
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Discover videos by channel URL
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Search videos by keyword and then apply relevant video filters
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Collect YouTube posts by hashtags
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Discovery records by Explore page URL
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Youtube - Videos posts - Discovery videos by podcast url
URL, Title, Youtuber, Youtuber md5, Video url, Video length, Likes, Views, and more.
Amazon Reviews
URL, Product name, Product rating, Product rating object, Product rating max, Rating, Author name, Asin, and more.
Facebook - Pages Posts by Profile URL
URL, Post id, User url, User username raw, Content, Date posted, Hashtags, Num comments, and more.
Facebook - Pages Posts by Profile URL - Collect profile information by user name
URL, Post id, User url, User username raw, Content, Date posted, Hashtags, Num comments, and more.
TikTok - Posts
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
TikTok - Posts - Input specific profile URL to get posts published by it
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
TikTok - Posts - Search posts by specific keyword or hashtag
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
TikTok - Posts - discover new records by TikTok discover URL
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
Indeed job listings information
Jobid, Company name, Date posted parsed, Job title, Description text, Benefits, Qualifications, Job type, and more.
Indeed job listings information - Collect new jobs by keyword search in specific location
Jobid, Company name, Date posted parsed, Job title, Description text, Benefits, Qualifications, Job type, and more.
Indeed job listings information - Discover jobs by company URL
Jobid, Company name, Date posted parsed, Job title, Description text, Benefits, Qualifications, Job type, and more.
Walmart - products
URL, Final price, Sku, Currency, Gtin, Specifications, Image urls, Top reviews, and more.
Walmart - products - Find new products by using specific category URL
URL, Final price, Sku, Currency, Gtin, Specifications, Image urls, Top reviews, and more.
Walmart - products - Collects products by specific keywords
URL, Final price, Sku, Currency, Gtin, Specifications, Image urls, Top reviews, and more.
Walmart - products - Discover products by using sku numbers
URL, Final price, Sku, Currency, Gtin, Specifications, Image urls, Top reviews, and more.
TikTok Shop
URL, Title, Available, Description, Currency, Initial price, Final price, Discount percent, and more.
TikTok Shop - category
URL, Title, Available, Description, Currency, Initial price, Final price, Discount percent, and more.
TikTok Shop - Collect TikTok shop products by keywords search
URL, Title, Available, Description, Currency, Initial price, Final price, Discount percent, and more.
TikTok Shop - discover records by shop url
URL, Title, Available, Description, Currency, Initial price, Final price, Discount percent, and more.
YouTube - Channels
URL, Handle, Handle md5, Banner img, Profile image, Name, Subscribers, Description, and more.
YouTube - Channels - Collects channel by keyword related to the channel or video's of the channel
URL, Handle, Handle md5, Banner img, Profile image, Name, Subscribers, Description, and more.
Glassdoor companies overview information
ID, Company, Ratings overall, Details size, Details founded, Details type, Country code, Company type, and more.
Glassdoor companies overview information - Search for companies by keyword
ID, Company, Ratings overall, Details size, Details founded, Details type, Country code, Company type, and more.
Glassdoor companies overview information - discover new companies by input filters
ID, Company, Ratings overall, Details size, Details founded, Details type, Country code, Company type, and more.
Glassdoor companies overview information - discover by search url
ID, Company, Ratings overall, Details size, Details founded, Details type, Country code, Company type, and more.
Reddit- Posts
Post id, URL, User posted, Title, Description, Num comments, Date posted, Community name, and more.
Reddit- Posts - Discover Reddit posts by Subreddit URL
Post id, URL, User posted, Title, Description, Num comments, Date posted, Community name, and more.
Reddit- Posts - Discovery by keyword of Reddit posts
Post id, URL, User posted, Title, Description, Num comments, Date posted, Community name, and more.
Reddit- Posts - Discover posts by author
Post id, URL, User posted, Title, Description, Num comments, Date posted, Community name, and more.
Google maps reviews
URL, Place id, Place name, Country, Address, Review id, Reviewer name, Reviews by reviewer, and more.
Airbnb Properties Information
Name, Price, Image, Description, Category, Availability, Discount, Reviews, and more.
Airbnb Properties Information - Search Airbnb by location
Name, Price, Image, Description, Category, Availability, Discount, Reviews, and more.
Airbnb Properties Information - Discover by search url
Name, Price, Image, Description, Category, Availability, Discount, Reviews, and more.
X (formerly Twitter) - Profiles
X id, URL, ID, Profile name, Biography, Is verified, Profile image link, External link, and more.
X (formerly Twitter) - Profiles - Collect profile information by user name
X id, URL, ID, Profile name, Biography, Is verified, Profile image link, External link, and more.
Instagram - Reels
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Views, and more.
Instagram - Reels - Discover reels video from Instagram profile or direct search url
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Views, and more.
Instagram - Reels - Collect all Reels from Instagram profiles (without the post timestamp)
URL, User posted, Description, Hashtags, Num comments, Date posted, Likes, Views, and more.
Google News
URL, Title, Publisher, Date, Category, Keyword, Country, Image, and more.
Yahoo Finance business information
Name, Company id, Entity type, Summary, Stock ticker, Currency, Earnings date, Exchange, and more.
Yahoo Finance business information - Discover records by keyword
Name, Company id, Entity type, Summary, Stock ticker, Currency, Earnings date, Exchange, and more.
Glassdoor companies reviews
Overview id, Review id, Review url, Rating date, Count helpful, Count unhelpful, Employee job end year, Employee length, and more.
Booking Hotel Listings
URL, Hotel id, Title, Location, Country, City, Metro railway access, Images, and more.
Booking Hotel Listings -
URL, Hotel id, Title, Location, Country, City, Metro railway access, Images, and more.
pitchbook companies information
URL, ID, Company name, Company socials, Year founded, Status, Employees, Latest deal type, and more.
Yelp businesses overview
Business id, Yelp biz id, Name, Updates from business, Overall rating, Reviews count, Is claimed, Categories, and more.
Yelp businesses overview - Collect Yelp businesses by url
Business id, Yelp biz id, Name, Updates from business, Overall rating, Reviews count, Is claimed, Categories, and more.
Facebook - Comments
URL, Post id, Post url, Comment id, User name, User id, User url, Date created, and more.
Instagram - Comments
URL, Comment user, Comment user url, Comment date, Comment, Likes number, Replies number, Replies, and more.
Zoominfo companies information
URL, ID, Name, Description, Revenue, Revenue currency, Revenue text, Stock symbol, and more.
Zoominfo companies information - discover records by search url
URL, ID, Name, Description, Revenue, Revenue currency, Revenue text, Stock symbol, and more.
Glassdoor job listings information
URL, Company url overview, Company name, Company rating, Job title, Job location, Job overview, Company headquarters, and more.
Glassdoor job listings information - Collect new jobs by keyword search like the job title
URL, Company url overview, Company name, Company rating, Job title, Job location, Job overview, Company headquarters, and more.
Glassdoor job listings information - Discover jobs by company URL
URL, Company url overview, Company name, Company rating, Job title, Job location, Job overview, Company headquarters, and more.
Amazon sellers info
Seller id, URL, Seller name, Description, Detailed info, Stars, Feedbacks, Return policy, and more.
eBay
URL, Product id, Title, Seller name, Seller rating, Seller reviews, Breadcrumbs, Root category, and more.
eBay - Gather data on products using specified keywords
URL, Product id, Title, Seller name, Seller rating, Seller reviews, Breadcrumbs, Root category, and more.
eBay - Collect products from shops on eBay
URL, Product id, Title, Seller name, Seller rating, Seller reviews, Breadcrumbs, Root category, and more.
eBay - Collect records by category
URL, Product id, Title, Seller name, Seller rating, Seller reviews, Breadcrumbs, Root category, and more.
Google Shopping
URL, Product id, Title, Product description, Rating, Reviews count, Images, Variations, and more.
Google Shopping - collects products from web using keywords
URL, Product id, Title, Product description, Rating, Reviews count, Images, Variations, and more.
Amazon products global dataset
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Amazon products global dataset - Collects products by specific category URL
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Amazon products global dataset - Collecting products by keyword search
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Amazon products global dataset - Collect Amazon products by seller URL
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Amazon products global dataset - Collect products from Brands URLs
Title, Seller name, Brand, Description, Initial price, Currency, Availability, Reviews count, and more.
Github repository
URL, ID, Code language, Code, Num lines, User name, User url, Size, and more.
Github repository - Discover github code by repository URL
URL, ID, Code language, Code, Num lines, User name, User url, Size, and more.
Github repository - discover new records by search url
URL, ID, Code language, Code, Num lines, User name, User url, Size, and more.
Home Depot US
URL, Domain, Country code, Model number, Sku, Product id, Product name, Manufacturer, and more.
Home Depot US - Gather data on products using specified keywords
URL, Domain, Country code, Model number, Sku, Product id, Product name, Manufacturer, and more.
Home Depot US - Discover products by specified URL
URL, Domain, Country code, Model number, Sku, Product id, Product name, Manufacturer, and more.
Home Depot US - Discover products by specified UPC
URL, Domain, Country code, Model number, Sku, Product id, Product name, Manufacturer, and more.
Home Depot US - Discovery products by specific category URL
URL, Domain, Country code, Model number, Sku, Product id, Product name, Manufacturer, and more.
Facebook - Posts by group URL
URL, Post id, User url, User username raw, Content, Date posted, Hashtags, Num comments, and more.
Facebook Marketplace
URL, Title, Initial price, Final price, Currency, Product id, Breadcrumbs, Condition, and more.
Facebook Marketplace - Collect Facebook marketplace listings by keyword
URL, Title, Initial price, Final price, Currency, Product id, Breadcrumbs, Condition, and more.
Facebook Marketplace - discover by url
URL, Title, Initial price, Final price, Currency, Product id, Breadcrumbs, Condition, and more.
Facebook - Posts by post URL
URL, Post id, User url, User username raw, Content, Date posted, Hashtags, Num comments, and more.
Etsy
URL, Product id, Listing inventory id, Title, Rating, Reviews count shop, Reviews count item, Initial price, and more.
Etsy - Collect data on products using specified keywords
URL, Product id, Listing inventory id, Title, Rating, Reviews count shop, Reviews count item, Initial price, and more.
Etsy - Collects data from shop's URL
URL, Product id, Listing inventory id, Title, Rating, Reviews count shop, Reviews count item, Initial price, and more.
Australia real estate properties
Rea property id, Property type, State, Postcode, Year built, Last sold date, Last sold agency, Bedrooms, and more.
Australia real estate properties - discover records by search url
Rea property id, Property type, State, Postcode, Year built, Last sold date, Last sold agency, Bedrooms, and more.
Australia real estate properties - Discover records by Listing type
Rea property id, Property type, State, Postcode, Year built, Last sold date, Last sold agency, Bedrooms, and more.
Google Play Store
URL, Title, Developer, Monetization features, Images, About, Data safety, Rating, and more.
TikTok - Comments
URL, Post url, Post id, Post date created, Date created, Comment text, Num likes, Num replies, and more.
Trustpilot business reviews
Company name, Review id, Review date, Review rating, Review title, Review content, Is verified review, Review date of experience, and more.
G2 software - product reviews
Review id, Author id, Author, Position, Company size, Stars, Date, Title, and more.
Amazon products search
Asin, URL, Name, Sponsored, Initial price, Final price, Currency, Sold, and more.
Booking Listings Search
URL, Location, Check in, Check out, Adults, Children, Rooms, ID, and more.
Reddit - Comments
URL, Comment id, User posted, Comment, Date posted, Post url, Post id, Community name, and more.
Yelp businesses reviews
Business id, Review auther, Rating, Date, Content, Review image, Reactions, Replies, and more.
Yelp businesses reviews - Search for Yelp businesses by country, category and location
Business id, Review auther, Rating, Date, Content, Review image, Reactions, Replies, and more.
Facebook - Profiles
URL, Name, ID, Profile photo, Cover photo, Work, College, High school, and more.
Zillow price history
URL, Zpid, Date, Event, Posting is rental, Price, Price change rate, Price per squarefoot, and more.
Zara - Products
Category id, Product id, Product name, Price, Currency, Colour code, Colour, Description, and more.
Zara - Products - discovery by category url
Category id, Product id, Product name, Price, Currency, Colour code, Colour, Description, and more.
Wikipedia articles
URL, Title, Table of contents, Raw text, Cataloged text, Images, See also, References, and more.
Wikipedia articles - Discover new articles by searching keywords in Wikipedia
URL, Title, Table of contents, Raw text, Cataloged text, Images, See also, References, and more.
Target
URL, Product id, Title, Product description, Rating, Reviews count, Initial price, Discount, and more.
Target - Gather data on products using specified keywords
URL, Product id, Title, Product description, Rating, Reviews count, Initial price, Discount, and more.
Target - Discover products by category url
URL, Product id, Title, Product description, Rating, Reviews count, Initial price, Discount, and more.
Target - Discover products by specified UPC
URL, Product id, Title, Product description, Rating, Reviews count, Initial price, Discount, and more.
Indeed companies info
Name, Description, URL, Work happiness, Jobs categories, Website, Industry, Company size, and more.
Indeed companies info - By company list
Name, Description, URL, Work happiness, Jobs categories, Website, Industry, Company size, and more.
Indeed companies info - Discover companies by Industries and location (State) in US
Name, Description, URL, Work happiness, Jobs categories, Website, Industry, Company size, and more.
Indeed companies info - Search company by company name
Name, Description, URL, Work happiness, Jobs categories, Website, Industry, Company size, and more.
Pinterest - Posts
URL, Post id, Title, Content, Date posted, User name, User url, User id, and more.
Pinterest - Posts - Collects posts by specific keywords
URL, Post id, Title, Content, Date posted, User name, User url, User id, and more.
Pinterest - Posts - Discover posts by using specific profile url
URL, Post id, Title, Content, Date posted, User name, User url, User id, and more.
Youtube - Comments
Comment id, Comment text, Likes, Replies, Username, Username md5, User channel, Date, and more.
Zoopla properties listing information
URL, Property type, Property title, Address, Google map location, Virtual tour, Street view, URL property, and more.
Zoopla properties listing information - Discover by custom filters - location and property type
URL, Property type, Property title, Address, Google map location, Virtual tour, Street view, URL property, and more.
Facebook - Pages and Profiles
ID, URL, Page name, Username, Entity type, Summary text, Primary category, Work, and more.
Best Buy products
URL, Product id, Title, Images, Final price, Currency, Discount, Initial price, and more.
Best Buy products - Collect data on products using specified keywords
URL, Product id, Title, Images, Final price, Currency, Discount, Initial price, and more.
Lowes.com
URL, Domain, Marketplace pn, Sku, Other pn, Model number, Gtin ean pn, Product name, and more.
Lowes.com - Gather data on products using specified keywords
URL, Domain, Marketplace pn, Sku, Other pn, Model number, Gtin ean pn, Product name, and more.
Lowes.com - Collect records by category
URL, Domain, Marketplace pn, Sku, Other pn, Model number, Gtin ean pn, Product name, and more.
Lazada - Products
URL, Title, Rating, Reviews, Initial price, Final price, Currency, Stock, and more.
Lazada - Products - Discover products by keyword
URL, Title, Rating, Reviews, Initial price, Final price, Currency, Stock, and more.
Lazada - Products - Discover products by category URL or brand URL
URL, Title, Rating, Reviews, Initial price, Final price, Currency, Stock, and more.
Lazada - Products - Discover products by seller URL
URL, Title, Rating, Reviews, Initial price, Final price, Currency, Stock, and more.
Lazada - Products - Discover products by brand URL
URL, Title, Rating, Reviews, Initial price, Final price, Currency, Stock, and more.
Facebook Events
Event id, URL, Main image, Event date, Title, People responded, Event by, Location, and more.
Facebook Events - discover Facebook events search URL
Event id, URL, Main image, Event date, Title, People responded, Event by, Location, and more.
Facebook Events - Discover events by venue URL
Event id, URL, Main image, Event date, Title, People responded, Event by, Location, and more.
Walmart sellers info
Seller id, URL, Catalog seller id, Seller name, Seller display name, Seller email, Seller phone, Seller about us, and more.
Sephora products
URL, ID, Name, Sku, In stock, Regular price, Actual price, Unit price, and more.
Ikea - Products
Description, In stock, Color, Size, Reviews count, Main image, Category url, Category, and more.
Ikea - Products - Discovery new products by category URL
Description, In stock, Color, Size, Reviews count, Main image, Category url, Category, and more.
OLX Brazil - marketplace ads
Body, Subject, Currency, PriceValue, ProfessionalAnnouncement, Category, ParentCategoryName, CategoryName, and more.
BBC news
ID, URL, Author, Headline, Topics, Publication date, Content, Videos, and more.
BBC news - Discover BBC articles by keyword
ID, URL, Author, Headline, Topics, Publication date, Content, Videos, and more.
Xing social network
Account id, FamilyName, Gender, Membership, Country code, Experience, Education, Languages, and more.
Ozon.ru products
URL, Sku, Breadcrumbs, Name, Rating, Review count, Description, Image, and more.
Facebook - Reels by profile URL
URL, Post id, User url, User username raw, Content, Date posted, Hashtags, Num comments, and more.
Google Shopping products search US
URL, Product id, Title, Final price, Initial price, Currency, Rating, Reviews count, and more.
Wayfair products
URL, Product id, Title, Rating, Reviews count, Initial price, Discount, Final price, and more.
Wayfair products - Gather data on products using specified keywords
URL, Product id, Title, Rating, Reviews count, Initial price, Discount, Final price, and more.
Wayfair products - discover records by category url
URL, Product id, Title, Rating, Reviews count, Initial price, Discount, Final price, and more.
Digikey - Products
Product url, Category url, Part number, Description, Manufacturer, Manufacturer url, Datasheet url, Rohs compliant, and more.
Digikey - Products - Discover by category url
Product url, Category url, Part number, Description, Manufacturer, Manufacturer url, Datasheet url, Rohs compliant, and more.
Google Play Store reviews
URL, Review id, Reviewer name, Review date, Review rating, Review, Found helpful, App url, and more.
Naver products
URL, Product id, Title, Original price, Final price, Discount rate, Currency, Description, and more.
Naver products - Discover products by category
URL, Product id, Title, Original price, Final price, Discount rate, Currency, Description, and more.
Facebook Company Reviews
Company name, Company id, Company url, URL, Review time, Recommends, Review content, Review attachments, and more.
Owler companies information
CompanyID, Ownership, IndustrySectors, Revenue, Founded, CompanyName, Country, EmployeeCount, and more.
Myntra products
URL, Product id, Title, Product description, Rating, Ratings count, Initial price, Discount, and more.
Myntra products - Collect products by category URL
URL, Product id, Title, Product description, Rating, Ratings count, Initial price, Discount, and more.
Myntra products - Collect products by keyword
URL, Product id, Title, Product description, Rating, Ratings count, Initial price, Discount, and more.
Myntra products - Collect products by brand URL
URL, Product id, Title, Product description, Rating, Ratings count, Initial price, Discount, and more.
US lawyers directory
URL, Address, Admission, Areas of practice, Isln, Law school attended, Location, Name, and more.
US lawyers directory - Search on the website by attorney name, practice area, school, articles, or location
URL, Address, Admission, Areas of practice, Isln, Law school attended, Location, Name, and more.
Webmotors Brasil - Cars Listings
ID SELLER, ID, URL, Tipo, Marca, Modelo, Ano, Variante, and more.
Webmotors Brasil - Cars Listings - Discover new records by category URL
ID SELLER, ID, URL, Tipo, Marca, Modelo, Ano, Variante, and more.
H&M - Products
Category tree, Color, Country code, County of origin, Currency, Delivery, Description, Domain, and more.
H&M - Products - Discovery new products by category URL
Category tree, Color, Country code, County of origin, Currency, Delivery, Description, Domain, and more.
Mouser - Products
Product url, Category url, Mouser part num, Mfr part number, Manufacturer, Image, Image high, Manufacturer url, and more.
Mouser - Products - Discovery new products by category URL
Product url, Category url, Mouser part num, Mfr part number, Manufacturer, Image, Image high, Manufacturer url, and more.
CNN news
ID, URL, Author, Headline, Topics, Publication date, Updated last, Content, and more.
CNN news - Discover CNN articles by search URL
ID, URL, Author, Headline, Topics, Publication date, Updated last, Content, and more.
CNN news - Discovery article by the publishing date and time
ID, URL, Author, Headline, Topics, Publication date, Updated last, Content, and more.
Agoda Properties Listings
URL, Hotel id, Title, Location, Country, City, Metro railway access, Images, and more.
Agoda Properties Listings - collect properties by country
URL, Hotel id, Title, Location, Country, City, Metro railway access, Images, and more.
Agoda Properties Listings - collect properties by filter url
URL, Hotel id, Title, Location, Country, City, Metro railway access, Images, and more.
Tokopedia Products
Product id, Title, URL, Currency, Delivery, Final price, Initial price, Seller name, and more.
Tokopedia Products - Search products by keyword
Product id, Title, URL, Currency, Delivery, Final price, Initial price, Seller name, and more.
Tokopedia Products - Collect URLs of products by category URLs
Product id, Title, URL, Currency, Delivery, Final price, Initial price, Seller name, and more.
Tokopedia Products - Collect Tokopedia's products by seller URL
Product id, Title, URL, Currency, Delivery, Final price, Initial price, Seller name, and more.
Apple App Store reviews
URL, Review id, Review title, Review rating, Reviewer name, Review date, Review, Developer response, and more.
Wildberries.ru products
URL, Sku, Breadcrumbs, Name, Rating, Review count, Image, Brand, and more.
Zonaprop Argentina - Properties Listing
URL, Title, GeneratedTitle, Imagenes, Numero de imagenes, Description, Precio, Currency, and more.
Zonaprop Argentina - Properties Listing - Discover products by domain
URL, Title, GeneratedTitle, Imagenes, Numero de imagenes, Description, Precio, Currency, and more.
VentureRadar company information
URL, Location, Name, Country code, Ownership, Score, Auto analyst score, Website popularity, and more.
Quora posts
URL, Post id, Author name, Title, Post date, Originally answered, Over all answers, Post text, and more.
Quora posts - Search url of a question on Quora to discover answers given
URL, Post id, Author name, Title, Post date, Originally answered, Over all answers, Post text, and more.
Pinterest - Profiles
URL, Profile picture, Name, Nickname, Website, Bio, Following count, Follower count, and more.
Pinterest - Profiles - Discover profiles by Keyword in profile name and profile posts
URL, Profile picture, Name, Nickname, Website, Bio, Following count, Follower count, and more.
Chileautos Chile - Cars Listings
URL, Marca, Modelo, Ano, Variante, Kilometraje, Condicion, Combustible, and more.
Inmuebles24 Mexico - Properties Listings
URL, Title, GeneratedTitle, Description, Seller, Precio, Publicado hace, CreatedDate, and more.
Zalando products
Domain, Country code, URL, Sku, Condition, Gender, Product name, Brand, and more.
Zalando products - Discover products by domain
Domain, Country code, URL, Sku, Condition, Gender, Product name, Brand, and more.
Zalando products - Discover records by search keyword
Domain, Country code, URL, Sku, Condition, Gender, Product name, Brand, and more.
Zalando products - Discover products by category URL
Domain, Country code, URL, Sku, Condition, Gender, Product name, Brand, and more.
Zalando products - Collect products by brand URL
Domain, Country code, URL, Sku, Condition, Gender, Product name, Brand, and more.
mercadolivre.com.br products
URL, Product id, Title, Breadcrumbs, Category, Tags, Final price, Original price, and more.
Trustradius product reviews
URL, Product id, Product name, Review id, Review url, Review title, Review rating, Review date, and more.
Trustradius product reviews - discover all reviews by product url
URL, Product id, Product name, Review id, Review url, Review title, Review rating, Review date, and more.
Yapo Chile - marketplace ads
Title, Description, Seller name, Root category id, Root category name, Parent category id, Parent category name, Active, and more.
Asos - Products
URL, Name, Brand, Description, About me, Availability, Buy the look, Category, and more.
Asos - Products - Collect products by category URL
URL, Name, Brand, Description, About me, Availability, Buy the look, Category, and more.
Asos - Products - Collect products by keyword
URL, Name, Brand, Description, About me, Availability, Buy the look, Category, and more.
Asos - Products - Collect products by brand URL
URL, Name, Brand, Description, About me, Availability, Buy the look, Category, and more.
carsales.com.au - Cars Listings
Car id, URL, Manufacturer, Model, Badge, Colour, Year, Price, and more.
carsales.com.au - Cars Listings - Collect car listings by keyword
Car id, URL, Manufacturer, Model, Badge, Colour, Year, Price, and more.
Vimeo - Videos posts
Video id, Title, URL, Uploader, Video url, Video length, Views, Likes, and more.
Vimeo - Videos posts - focus on licensed videos with "common creative" license
Video id, Title, URL, Uploader, Video url, Video length, Views, Likes, and more.
Vimeo - Videos posts - scrape videos by URL
Video id, Title, URL, Uploader, Video url, Video length, Views, Likes, and more.
Hermes- Products
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Hermes- Products - Discovery new products by category URL
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Lazada - Reviews
URL, Title, Rating, Reviews, Seller name, Sku, Mpn, Is super seller, and more.
Bluesky - Posts
URL, Post id, Post date, Posted by, Post text, Comments, Reposts, Likes, and more.
Bluesky - Posts - Collect posts from profile URL
URL, Post id, Post date, Posted by, Post text, Comments, Reposts, Likes, and more.
Lego - Products
Product name, Category, Description, Initial price, Final price, Currency, In stock, Availability, and more.
Lego - Products - Discovery new products by category URL
Product name, Category, Description, Initial price, Final price, Currency, In stock, Availability, and more.
Home Depot CA
Domain, Country code, URL, Model number, Sku, Product name, Manufacturer, Description, and more.
Home Depot CA - Gather data on products using specified keywords
Domain, Country code, URL, Model number, Sku, Product name, Manufacturer, Description, and more.
Home Depot CA - discover records by category url
Domain, Country code, URL, Model number, Sku, Product name, Manufacturer, Description, and more.
Kroger.com - Discovery by category
Sku, Variant id, URL, Rootdomain, Name, Brand, Currency, Price, and more.
Kroger.com - Discovery by keyword
Sku, Variant id, URL, Rootdomain, Name, Brand, Currency, Price, and more.
Metrocuadrado - Properties Listings
URL, ID, Precio, Habitaciones, Banos, Dimension propiedad, Dimension terreno, Comuna Ciudad, and more.
Chanel Products
Product name, Product description, Country, Currency, Color, Variations, Free sample, Image slider, and more.
Chanel Products - Discover new products in Chanel by category URL
Product name, Product description, Country, Currency, Color, Variations, Free sample, Image slider, and more.
Lazada products search (GMV)
URL, Name, Price, Currency, Number sold, Sku, Image url, Rating, and more.
Dior - Products
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Dior - Products - Discovery new products by category URL
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Toctoc - Properties Listings
Imagen, No de imagenes, Descripcion, Precio, Currency, Ubicacion, Habitaciones, Banos, and more.
Costco products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Infocasas Uruguay - Properties Listings
URL, ID, Imagen, Descripcion, Precio, Ubicacion, Habitaciones, Banos, and more.
Properati Argentina and Colombia - Properties Listings
Type, Name, Estrato, Habitaciones, Banos, M2, Descripcion, Precio, and more.
Ashleyfurniture - Products
Product name, Brand, Initial price, Final price, Currency, In stock, Availability, Color, and more.
Ashleyfurniture - Products - sitemap
Product name, Brand, Initial price, Final price, Currency, In stock, Availability, Color, and more.
Ashleyfurniture - Products - Discovery new products by category URL
Product name, Brand, Initial price, Final price, Currency, In stock, Availability, Color, and more.
AE.com - Complete Products
Product name, Brand, Description, Initial price, Final price, Currency, In stock, Availability, and more.
AE.com - Complete Products - Discovery new products by category URL
Product name, Brand, Description, Initial price, Final price, Currency, In stock, Availability, and more.
Apple App Store
URL, Title, Sub title, Developer, Top charts, Monetization features, Image, Screenshots, and more.
Westelm products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Westelm products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Macys.com
URL, Star rating distribution, Quantity sold, Is promo, Sku, Rootdomain, Name, Brand, and more.
Macys.com - By category url
URL, Star rating distribution, Quantity sold, Is promo, Sku, Rootdomain, Name, Brand, and more.
Macys.com - Search by keyword
URL, Star rating distribution, Quantity sold, Is promo, Sku, Rootdomain, Name, Brand, and more.
Aliexpress products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Aliexpress products - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Mango Products
Product name, Price, Image, Size, Product article, Availability, Description, Colour code, and more.
Crateandbarrel - Products
Product name, Brand, Description, Initial price, Final price, Currency, In stock, Availability, and more.
Crateandbarrel - Products - Discovery new products by category URL
Product name, Brand, Description, Initial price, Final price, Currency, In stock, Availability, and more.
Fanatics.com - Products
Product name, Brand, Description, Initial price, Final price, Currency, In stock, Color, and more.
Fanatics.com - Products - Discovery new products by category URL
Product name, Brand, Description, Initial price, Final price, Currency, In stock, Color, and more.
Mediamarkt.de products
Brand, Description, Manufacturer, Ean, Sku, Initial price, Final price, In stock, and more.
Snapchat posts
URL, Post id, Profile name, Profile handle, Profile link, Num comments, Num shares, Num views, and more.
Snapchat posts - Discover posts by profile url
URL, Post id, Profile name, Profile handle, Profile link, Num comments, Num shares, Num views, and more.
Snapchat posts - Discover new posts by search url
URL, Post id, Profile name, Profile handle, Profile link, Num comments, Num shares, Num views, and more.
Balenciaga.com - Products
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Balenciaga.com - Products - Discovery new products by category URL
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
apple shop products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Rona.ca products
URL, Title, Description, Currency, Final price, Initial price, Product specifications, Domain, and more.
Rona.ca products - Discover records by category URL
URL, Title, Description, Currency, Final price, Initial price, Product specifications, Domain, and more.
Rona.ca products - Discover records by search URL
URL, Title, Description, Currency, Final price, Initial price, Product specifications, Domain, and more.
Toysrus - Products
Product name, Brand, Description, Initial price, Final price, Currency, In stock, Reviews count, and more.
Toysrus - Products - Discovery new products by category URL
Product name, Brand, Description, Initial price, Final price, Currency, In stock, Reviews count, and more.
Autozone - products
URL, Item id, Title, Description, Product category, Category tree, Brand, Image url, and more.
ChatGPT Search
URL, Prompt, Answer html, Answer text, Links attached, Citations, Recommendations, Country, and more.
Carters.com - Products
Product name, Description, In stock, Availability, Color, Size, Reviews count, Category url, and more.
Carters.com - Products - Discovery new products by category URL
Product name, Description, In stock, Availability, Color, Size, Reviews count, Category url, and more.
Loewe.com - Products
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Loewe.com - Products - Discovery new products by category URL
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Zara Home Products
Category id, Category key, Category name, Product id, Product name, Price, Price discount, Price with fillings, and more.
Prada.com - Products
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Prada.com - Products - Discovery new products by category URL
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Fendi Products
Product id, URL, Product name, Product description, Short description, Image, Price, Currency, and more.
Fendi Products - Discover products by category URL
Product id, URL, Product name, Product description, Short description, Image, Price, Currency, and more.
Twitch - streams dataset
URL, Stream id, Streamer name, Verified partner, Stream title, Tags, Viewers number, Stream time, and more.
Twitch - streams dataset - Discover stream by a search term
URL, Stream id, Streamer name, Verified partner, Stream title, Tags, Viewers number, Stream time, and more.
Twitch - streams dataset - Discover stream by category url
URL, Stream id, Streamer name, Verified partner, Stream title, Tags, Viewers number, Stream time, and more.
llbean.com - Products
IDentity, Product name, URL, Description, Category tree, Color, Country code, County of origin, and more.
llbean.com - Products - Discovery new products by category URL
IDentity, Product name, URL, Description, Category tree, Color, Country code, County of origin, and more.
Micro Center Products
URL, Item id, Title, Description, Product category, Category tree, Brand, Image url, and more.
Massimo Dutti - Products
URL, Title, Price, Product type, Family name, Subfamily name, Images, Size, and more.
Massimo Dutti - Products - Discovery new products by category URL
URL, Title, Price, Product type, Family name, Subfamily name, Images, Size, and more.
Alibaba
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Alibaba - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Sephora Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Sephora Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Delvaux - Products
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Delvaux - Products - Discovery new products by category URL
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Ysl.com - Products
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Bottegaveneta.com - Products
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Bottegaveneta.com - Products - Discovery new products by category URL
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Google SERP - 100 Results
URL, Keyword, General, Related, Pagination, Organic, People also ask, Navigation, and more.
Dick’s Sporting Goods
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
chewy products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
adidas products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Nike products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Nike products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
B&H Products
URL, Item id, Title, Description, Product category, Category tree, Brand, Image url, and more.
Harbor Freight Products
URL, Item id, Title, Description, Product category, Category tree, Brand, Image url, and more.
Harbor Freight Products - Collect products by category URL
URL, Item id, Title, Description, Product category, Category tree, Brand, Image url, and more.
Raymourflanigan.com - Products
Product name, Seller name, Brand, Description, Initial price, Final price, Currency, In stock, and more.
Montblanc - Products
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Montblanc - Products - Discovery new products by category URL
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Celine.com - Products
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Celine.com - Products - Discover new products by category URL
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Mybobs.com - Products
Product name, Initial price, Final price, Currency, In stock, Main image, Category tree, Country code, and more.
Mybobs.com - Products - Discovery new products by category URL
Product name, Initial price, Final price, Currency, In stock, Main image, Category tree, Country code, and more.
Hoka products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Hoka products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
LLBean
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
 249+
249+LLBean - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
249+Mattressfirm - Products
Product name, Brand, Description, Initial price, Final price, Currency, In stock, Color, and more.
Mattressfirm - Products - Discovery new products by category URL
Product name, Brand, Description, Initial price, Final price, Currency, In stock, Color, and more.
La-z-boy.com - Products
Product name, Description, Initial price, Final price, Currency, In stock, Size, Reviews count, and more.
La-z-boy.com - Products - Discovery new products by category URL
Product name, Description, Initial price, Final price, Currency, In stock, Size, Reviews count, and more.
Berluti.com - Products
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Berluti.com - Products - Discovery new products by category URL
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Google AI Mode Search
URL, Prompt, Answer html, Answer text, Links attached, Citations, Index, Country, and more.
Sleepnumber.com - Products
Description, Initial price, Final price, Currency, In stock, Color, Size, Reviews count, and more.
Sleepnumber.com - Products - Discovery new products by category URL
Description, Initial price, Final price, Currency, In stock, Color, Size, Reviews count, and more.
Dell Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
OLD NAVY Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
OLD NAVY Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Moynat.com - Products
Product name, Description, Country, Currency, In stock, Size, Color, Main image, and more.
Bass Pro Shops
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Sally Beauty Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Sally Beauty Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Walmart - products zipcodes
URL, Final price, Sku, Currency, Gtin, Specifications, Image urls, Top reviews, and more.
Walmart - products zipcodes - Collect data by category URL
URL, Final price, Sku, Currency, Gtin, Specifications, Image urls, Top reviews, and more.
Walmart - products zipcodes - Collect data by Keyword
URL, Final price, Sku, Currency, Gtin, Specifications, Image urls, Top reviews, and more.
Mercari Products
URL, Item id, Title, Description, Product category, Category tree, Brand, Image url, and more.
Sweetwater
URL, Item id, Title, Description, Product category, Category tree, Brand, Image url, and more.
Lululemon products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Lululemon products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Instacart Products unified schema
URL, Item id, Title, Description, Product category, Category tree, Brand, Image url, and more.
Instacart Products unified schema - Collect products by category URL
URL, Item id, Title, Description, Product category, Category tree, Brand, Image url, and more.
Williams sonoma products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Rei
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Rei - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Samsung
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Samsung - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Nordstrom
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Nordstrom - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
ACE products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
ACE products - Sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
hp products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Grainger
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
241+Grainger - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
241+Poshmark.com
URL, Is promo, Seller id, Other price options, Sku, Rootdomain, Name, Brand, and more.
Poshmark.com - Discovery by category
URL, Is promo, Seller id, Other price options, Sku, Rootdomain, Name, Brand, and more.
Poshmark.com - Discovery by keyword
URL, Is promo, Seller id, Other price options, Sku, Rootdomain, Name, Brand, and more.
Barnes & Noble Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Neiman Marcus
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Neiman Marcus - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Ulta
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Ulta - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Overstock Products unified schema
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Overstock Products unified schema - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Bath & Body Works
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Quince Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Quince Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Free people
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Free people - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Rona.ca products unified schema
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
237+Rona.ca products unified schema - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
237+Suumo.jp
URL, Property name, Type, Rent fee, Management Fees common Expenses, Shikikin, Key money, Security deposit, and more.
236+Suumo.jp - Discovery records by category
URL, Property name, Type, Rent fee, Management Fees common Expenses, Shikikin, Key money, Security deposit, and more.
236+Vevor Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Vevor Products - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Flipkart Products unified schema
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Flipkart Products unified schema - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Garmin Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Garmin Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Ferguson Home Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Ferguson Home Products - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Crateandbarrel - Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
235+Crateandbarrel - Products - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
235+Poshmark Products unified schema
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
OUAI Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
OUAI Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Guitar Center Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Victoria's Secret products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
American Eagle
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
American Eagle - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Tatcha Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
234+Gemini Search
URL, Prompt, Answer html, Answer text, Links attached, Citations, Country, Index, and more.
iherb products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Zillow Full Properties Information
URL, Photos, Responsive photos, Has vr model, Description, Home status, Contingent listing type, What i love, and more.
Zillow Full Properties Information - Discover zillow records by zillow search url
URL, Photos, Responsive photos, Has vr model, Description, Home status, Contingent listing type, What i love, and more.
Threads - Posts
Post id, URL, Post time, Profile name, Profile url, Post content, Number of likes, Number of comments, and more.
Threads - Posts - Discover posts by profile URL
Post id, URL, Post time, Profile name, Profile url, Post content, Number of likes, Number of comments, and more.
Summit Racing Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
232+Saks Fifth Avenue products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
232+Saks Fifth Avenue products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
232+Perplexity Search
URL, Prompt, Answer html, Answer text, Answer text markdown, Sources, Source html, Is shopping data, and more.
Overstock.com
URL, Star rating distribution, Is promo, Other price options, Sku, Rootdomain, Name, Brand, and more.
Overstock.com - Discovery by category
URL, Star rating distribution, Is promo, Other price options, Sku, Rootdomain, Name, Brand, and more.
Overstock.com - keyword
URL, Star rating distribution, Is promo, Other price options, Sku, Rootdomain, Name, Brand, and more.
Staples
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Abercrombie & Fitch
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Anthropologie Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Anthropologie Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Sears Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Advance Auto Parts
URL, Item id, Title, Description, Product category, Category tree, Brand, Image url, and more.
Advance Auto Parts - Collect products by category URL
URL, Item id, Title, Description, Product category, Category tree, Brand, Image url, and more.
Lenovo Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
229+ON Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
ON Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Pottery barn products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
229+Pottery barn products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
229+Parts Geek
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
229+Parts Geek - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
229+Flipkart.com - Discovery by category
Sku, Variant id, URL, Rootdomain, Name, Brand, Currency, Price, and more.
Flipkart.com - Discovery by keyword
Sku, Variant id, URL, Rootdomain, Name, Brand, Currency, Price, and more.
Newegg Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Urban Outfitters
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
228+Zales
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Zales - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
J.Crew Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
J.Crew Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Theordinary products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Theordinary products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Newbalance products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Newbalance products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Fragrance Net Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Fragrance Net Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Paula's Choice Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
227+Paula's Choice Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
227+H&M products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
227+Underarmour Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Bed Bath & Beyond
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Athome products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
226+Athome products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
226+Editorialist products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
226+Samsclub products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
226+Samsclub products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
226+Kohl's Products unified schema
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
226+Kohl's Products unified schema - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
226+Sony Electronics Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Sony Electronics Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Grok Search
URL, Prompt, Answer text, Answer html, Index, Answer text markdown, Citations, Response raw, and more.
Flipkart - Reviews
Rootdomain, Sku, Variant sku, Review id, Author, Rating, Date, Purchased date, and more.
Flipkart - Reviews - Collect reviews by SKU
Rootdomain, Sku, Variant sku, Review id, Author, Rating, Date, Purchased date, and more.
vitamin shoppe products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
225+academy products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
thorne products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
225+Vitacost products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Vitacost products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
AT&T Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
AT&T Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Backcountry products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
225+Backcountry products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
225+Zara Home products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
225+Zara Home products - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
225+Falabella.com - Reviews
Rootdomain, Sku, Variant sku, Review id, Author, Rating, Date, Purchased date, and more.
Falabella.com - Reviews - Collect reviews data by SKU
Rootdomain, Sku, Variant sku, Review id, Author, Rating, Date, Purchased date, and more.
Markandgraham products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
224+Markandgraham products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
224+Cabelas products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
224+Cabelas products - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
224+Macys Products unified schema
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
224+Falabella.com
URL, Star rating distribution, Is promo, Seller id, Store id, Other price options, Sku, Rootdomain, and more.
Falabella.com - Discovery by category
URL, Star rating distribution, Is promo, Seller id, Store id, Other price options, Sku, Rootdomain, and more.
Falabella.com - Discovery by keyword
URL, Star rating distribution, Is promo, Seller id, Store id, Other price options, Sku, Rootdomain, and more.
Oscaro products - Global
URL, Is promo, Other price options, Sku, Rootdomain, Name, Brand, Currency, and more.
Oscaro products - Global - Discovery by category
URL, Is promo, Other price options, Sku, Rootdomain, Name, Brand, Currency, and more.
Oscaro products - Global - Discovery by keyword
URL, Is promo, Other price options, Sku, Rootdomain, Name, Brand, Currency, and more.
Office Depot Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Office Depot Products - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
tractor supply products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
223+World Market products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
223+World Market products - Collect products URLs by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
223+Walgreens
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
223+Walgreens - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
223+Stradivarius Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
223+Stradivarius Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
223+Hobbylobby
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
223+Hobbylobby - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
223+Napa Online
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
223+Napa Online - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
223+Bloomingdale's
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
223+Bloomingdale's - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
223+Sharkninja
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
223+Sharkninja - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
223+Massimodutti
URL, Item id, Variant id, Title, Description, Brand, Image url, Price, and more.
223+Massimodutti - Collect products by category URL
URL, Item id, Variant id, Title, Description, Brand, Image url, Price, and more.
223+Bershka Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
223+Bershka Products - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
223+Michaels Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
223+Michaels Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
223+Terrain Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
223+Terrain Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
223+Bing Copilot Search
URL, Prompt, Answer text, Answer html, Answer text markdown, Sources, Index, Answer section html, and more.
LinkedIn people search
URL, Name, Subtitle, Location, Experience, Education, Avatar, and more.
Agoda Listings Search
URL, Location, Check in, Check out, Adults, Children, Rooms, ID, and more.
222+Snapchat profile
URL, Profile id, Profile name, Profile username, Profile alternate name, Profile description, Profile address, Profile image url, and more.
Threads - Profiles
URL, Profile name, Profile id, About formatted, Number of followers, Website, Instagram profile url, Threads, and more.
GameStop Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
222+scheels products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
222+Containerstore products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
222+Containerstore products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
222+Greenrow
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
222+Greenrow - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
222+Adorama
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
222+Adorama - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
222+Pottery Barn Kids products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
222+Pottery Barn Kids products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
222+Dollar General Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
222+Dollar General Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
222+Bjs Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
222+Bjs Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
222+Trip Listings Search
URL, Location, Check in, Check out, Adults, Children, Rooms, ID, and more.
Google Flights - Collect flights by input filters
URL, Itinerary id, Search, Pricing, Providers, Legs, and more.
Kroger.com - Search - Discovery by category
Rank, Page, Sku, URL, Rootdomain, Name, Brand, Currency, and more.
Kroger.com - Search - Discovery by keyword
Rank, Page, Sku, URL, Rootdomain, Name, Brand, Currency, and more.
Flipkart.com - Search
Rank, Page, Sku, Variant id, URL, Rootdomain, Name, Brand, and more.
Flipkart.com - Search - Discovery by category
Rank, Page, Sku, Variant id, URL, Rootdomain, Name, Brand, and more.
Flipkart.com - Search - Discovery by keyword
Rank, Page, Sku, Variant id, URL, Rootdomain, Name, Brand, and more.
Myfood4less.com
URL, Is promo, Other price options, Sku, Rootdomain, Name, Brand, Currency, and more.
Myfood4less.com - Discovery by category
URL, Is promo, Other price options, Sku, Rootdomain, Name, Brand, Currency, and more.
Myfood4less.com - Discovery by keyword
URL, Is promo, Other price options, Sku, Rootdomain, Name, Brand, Currency, and more.
Motointegrator.de
URL, Sku, Rootdomain, Name, Brand, Currency, Price, Image urls, and more.
Motointegrator.de - Discovery by category
URL, Sku, Rootdomain, Name, Brand, Currency, Price, Image urls, and more.
Motointegrator.de - Discovery by keyword
URL, Sku, Rootdomain, Name, Brand, Currency, Price, Image urls, and more.
L'oreal Paris Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+L'oreal Paris Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+Pull & Bear Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+Pull & Bear Products - Collect by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+Belk products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+Belk products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+Lyst
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+Lyst - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+Pottery Barn Teen
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+Pottery Barn Teen - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+Peoples Jewellers products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+Peoples Jewellers products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+Zara.com products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+LA Roche Posay Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+LA Roche Posay Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+Clinique Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+Clinique Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+Blick Art Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+Blick Art Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+Asics Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+Oxo Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
221+Naver hotels
URL, Hotel id, Hotel name, Rating, Review count, Star classification, Address, District, and more.
221+Naver hotels - Discover records by filter URL
URL, Hotel id, Hotel name, Rating, Review count, Star classification, Address, District, and more.
221+Naver hotels - Discovery records by search
URL, Hotel id, Hotel name, Rating, Review count, Star classification, Address, District, and more.
221+Naver hotels - Discover all hotel listings on Naver Hotels by country
URL, Hotel id, Hotel name, Rating, Review count, Star classification, Address, District, and more.
221+Macys.com - Reviews
URL, Rootdomain, Sku, Review id, Author, Rating, Date, Location, and more.
Macys.com - Reviews - In/out collector
URL, Rootdomain, Sku, Review id, Author, Rating, Date, Location, and more.
Dillard's
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+Nintendo products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+Oysho
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+Oysho - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+Rocksbox
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+Rocksbox - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+LG Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+LG Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+Converse Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Converse Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Kiehl's Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+Kiehl's Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+Flooranddecor Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
220+Zillow properties search page
URL, Zpid, Zipcode, Description, City, Country, State, Address, and more.
Walmart products search
ID, URL, Typename, Buy box suppression, Similar items, Us item id, Is bad split, Name, and more.
Trip Hotel Listings
URL, Hotel id, Title, Location, Country, City, Metro railway access, Images, and more.
Trip Hotel Listings - Collect hotels listings by location
URL, Hotel id, Title, Location, Country, City, Metro railway access, Images, and more.
Falabella.com - Search
Rank, Page, Sku, Variant id, URL, Rootdomain, Name, Brand, and more.
219+Falabella.com - Search - Discovery by category
Rank, Page, Sku, Variant id, URL, Rootdomain, Name, Brand, and more.
219+Falabella.com - Search - Discovery by keyword
Rank, Page, Sku, Variant id, URL, Rootdomain, Name, Brand, and more.
219+Instacart products
URL, Product id, Product name, Brand, Description, Category path, Size unit, Price, and more.
Instacart products - Collect products by category URL
URL, Product id, Product name, Brand, Description, Category path, Size unit, Price, and more.
Vinted - Global
URL, Seller id, Sku, Rootdomain, Name, Brand, Currency, Price, and more.
Vinted - Global - Discovery by category URL
URL, Seller id, Sku, Rootdomain, Name, Brand, Currency, Price, and more.
Vinted - Global - Discovery by search
URL, Seller id, Sku, Rootdomain, Name, Brand, Currency, Price, and more.
Pet Smart Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Pet Smart Products - Collect by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Rejuvenation
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Rejuvenation - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+WebstaurantStore
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
WebstaurantStore - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
Nature Made Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Nature Made Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Famousfootwear Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Naturium Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
219+Kohls.com - Reviews
URL, Rootdomain, Sku, Variant sku, Review id, Author, Rating, Date, and more.
Kohls.com - Reviews - Discovery by SKU
URL, Rootdomain, Sku, Variant sku, Review id, Author, Rating, Date, and more.
Therealreal.com
URL, Is promo, Other price options, Sku, Rootdomain, Name, Brand, Currency, and more.
218+Therealreal.com - Discovery by category
URL, Is promo, Other price options, Sku, Rootdomain, Name, Brand, Currency, and more.
218+Therealreal.com - Discovery by keyword
URL, Is promo, Other price options, Sku, Rootdomain, Name, Brand, Currency, and more.
218+Sayweee.com
URL, Quantity sold, Is promo, Sku, Rootdomain, Name, Brand, Currency, and more.
218+Sayweee.com - Discovery by category
URL, Quantity sold, Is promo, Sku, Rootdomain, Name, Brand, Currency, and more.
218+Sayweee.com - Discovery by keyword
URL, Quantity sold, Is promo, Sku, Rootdomain, Name, Brand, Currency, and more.
218+Ashley Furniture
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Ashley Furniture - Collect products by category URL
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Sur La Table Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Sur La Table Products - Collect products by sitemap
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Dior Products Unified Schema
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+Dermalogica Products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
218+TikTok - Posts by Profile Fast API
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
Kohls.com
URL, Star rating distribution, Quantity sold, Views, Is promo, Seller id, Store id, Other price options, and more.
Kohls.com - Discovery PDPs by category URL
URL, Star rating distribution, Quantity sold, Views, Is promo, Seller id, Store id, Other price options, and more.
Kohls.com - Discovery by keyword
URL, Star rating distribution, Quantity sold, Views, Is promo, Seller id, Store id, Other price options, and more.
Idealo Global - Discovery by category URL
Sku, Variant id, URL, Rootdomain, Name, Brand, Currency, Price, and more.
Idealo Global - Discovery by keyword
Sku, Variant id, URL, Rootdomain, Name, Brand, Currency, Price, and more.
Idealo Global - Discovery by category URL and keyword
Sku, Variant id, URL, Rootdomain, Name, Brand, Currency, Price, and more.
Canon USA products
URL, Item id, Variant id, Title, Description, Product category, Category tree, Brand, and more.
217+TikTok - Posts by URL Fast API
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
Agoda Properties Listings with Pricing
URL, Listing id, Title, Location, Country, City, Metro railway access, Images, and more.
Agoda Properties Listings with Pricing - Collect properties listings by search inputs
URL, Listing id, Title, Location, Country, City, Metro railway access, Images, and more.
Google Hotel
URL, Hotel id, Hotel name, Rating, Review count, Star classification, Address, Phone number, and more.
Google Hotel - Discovery records by search
URL, Hotel id, Hotel name, Rating, Review count, Star classification, Address, Phone number, and more.
Google Hotel - Discover records by filter URL
URL, Hotel id, Hotel name, Rating, Review count, Star classification, Address, Phone number, and more.
Reddit - Profiles
URL, Profile id, Name, Followers, Social links, Karma, Contributions, Reddit age, and more.
Overstock.com - Reviews
Rootdomain, Sku, Variant sku, Review id, Author, Rating, Date, Title, and more.
216+Overstock.com - Reviews - Collect reviews data by SKU
Rootdomain, Sku, Variant sku, Review id, Author, Rating, Date, Title, and more.
216+TikTok - Posts by Search URL Fast API
URL, Post id, Description, Create time, Digg count, Share count, Collect count, Comment count, and more.
Coupang products
URL, ID, Title, Rating, Reviews, Initial price, Final price, Discount, and more.
Coupang products - Collect products by category
URL, ID, Title, Rating, Reviews, Initial price, Final price, Discount, and more.
Coupang products - Collect product by brand URL
URL, ID, Title, Rating, Reviews, Initial price, Final price, Discount, and more.
Coupang products - Collect products by seller URL
URL, ID, Title, Rating, Reviews, Initial price, Final price, Discount, and more.
TikTok Shop Category Products
URL, Product id, Category url, Category name, Sub categories, Title, Initial price, Final price, and more.
Booking Hotel Listings with Pricing
URL, Listing id, Title, Location, Country, City, Metro railway access, Images, and more.
Booking Hotel Listings with Pricing - Collect listings by search input
URL, Listing id, Title, Location, Country, City, Metro railway access, Images, and more.
可用的交付方式


定价
网页抓取API订阅计划

25% OFF

Records 510K
$1.3
$0.98 /1K Records
$499
月付计划
免费试用
Use this coupon code:
APIS25
专为寻求扩大运营的团队量身定制
25% OFF

Records 1M
$1.1
$0.83 /1K Records
$999
月付计划
免费试用
Use this coupon code:
APIS25
为具有广泛运营需求的大型团队设计
25% OFF

Records 2.5M
$1
$0.75 /1K Records
$1999
月付计划
免费试用
Use this coupon code:
APIS25
为关键操作提供高级支持和功能
- 专属客户经理
- 定制套餐
- 高级服务水平协议
- 优先支持
- 个性化的使用流程引导
- 单点登录 (SSO)
- 定制化
- 审核日志
我们接受这些支付方式:
基于代理的爬虫 与 Web Scraper API 对比
 监控及维护
监控及维护 抓取基础设施
抓取基础设施 解析
解析 数据获取时间
数据获取时间 成本效益
成本效益代码示例
为 100 多个域名提供专用端点。
输入
JSON
curl -H "Authorization: Bearer API_TOKEN" -H "Content-Type: application/json" -d '[{"url":"https://www.linkedin.com/in/elad-moshe-05a90413/"},{"url":"https://www.linkedin.com/in/jonathan-myrvik-3baa01109"},{"url":"https://www.linkedin.com/in/aviv-tal-75b81/"},{"url":"https://www.linkedin.com/in/bulentakar/"},{"url":"https://www.linkedin.com/in/nnikolaev/"}]' "https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_l1viktl72bvl7bjuj0&format=json&uncompressed_webhook=true"
输出
JSON
[
{
"db_source": "1775517198994",
"timestamp": "2026-04-06",
"id": "max***rub***hik*********9",
"name": "Maxim R*******k",
"city": "Brooklyn, New York, United States",
"country_code": "US",
"position": "Pharmacist at NewYork-Presbyterian Brooklyn Methodist Hospital",
"about": "I a*** pa***nt *********rie*********************ove******************************"
},
{
"db_source": "1775517198994",
"timestamp": "2026-04-06",
"id": "kir***gan***8b1******",
"name": "Kiran G***i",
"city": "Michigan, United States",
"country_code": "US",
"position": "Principal Technical Program Manager at GE Renewable Energy",
"about": "Pas***nat***Dri*********wor*********************k l************************************"
},
{
"db_source": "1775517198994",
"timestamp": "2026-04-06",
"id": "ms-***rie***427******",
"name": "Ms. H*****t",
"city": "Largo, Florida, United States",
"country_code": "US",
"position": "Adjunct Librarian at St. Petersburg College",
"about": "Hav***ive***nst*********n A*********************log******************"
},
{
"db_source": "1775517198994",
"timestamp": "2026-04-06",
"id": "ale***lin***-51*********",
"name": "Alex S*****r",
"city": "Little Falls, New Jersey, United States",
"country_code": "US",
"position": null,
"about": "Res***ch *** De********* Pr*********************Pro******************************************"
},
{
"db_source": "1775517198994",
"timestamp": "2026-04-06",
"id": "bil***uth***-73******",
"name": "Bill G*****e",
"city": "Santa Clara, California, United States",
"country_code": "US",
"position": "CEO at PwP, Inc.",
"about": "Ent***ren***ial*********and*********************in ******************************************"
}
]
输入
JSON
curl -H "Authorization: Bearer API_TOKEN" -H "Content-Type: application/json" -d '[{"url":"https://www.amazon.com/Quencher-FlowState-Stainless-Insulated-Smoothie/dp/B0CRMZHDG8","asin":"B0CRMZHDG8","origin_url":"https://www.amazon.com/Quencher-FlowState-Stainless-Insulated-Smoothie/dp/B0CRMZHDG8","zipcode":"94107","language":""},{"url":"https://www.amazon.com/KitchenAid-Protective-Dishwasher-Stainless-8-72-Inch/dp/B07PZF3QS3","asin":"B07PZF3QS3","zipcode":"","language":""},{"url":"https://www.amazon.com/TruSkin-Naturals-Vitamin-Topical-Hyaluronic/dp/B01M4MCUAF","asin":"","origin_url":"https://www.amazon.com/TruSkin-Naturals-Vitamin-Topical-Hyaluronic/dp/B01M4MCUAF","zipcode":"94124","language":""}]' "https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_l7q7dkf244hwjntr0&format=json&uncompressed_webhook=true"
输出
JSON
[
{
"db_source": "1775505381244",
"timestamp": "2026-04-06",
"title": "14 Pockets Wrench Roll Up Pouch Organizer Bag for Handyman Electrician, Brown",
"seller_name": null,
"brand": "Aginkgo",
"description": "Features:Effortless Tool Access: This 14-Pocket Black Oxford Wrench Holder makes tool access a breeze. Grab what you nee...",
"initial_price": null,
"currency": "USD"
},
{
"db_source": "1775505381244",
"timestamp": "2026-04-06",
"title": "Mad Evil Clown Face T-Shirt Scary Horror Insane Joker Tee Shirt",
"seller_name": "Tee H**t",
"brand": "Tee Hunt",
"description": "This men\u0027s short sleeve graphic t-shirt is made from soft, breathable fabric designed for comfort and durability. The sh...",
"initial_price": 18.96,
"currency": "USD"
},
{
"db_source": "1775505381244",
"timestamp": "2026-04-06",
"title": "Nickel Plated Lighting fixtures and controls Steel Bead Ball Chain Keychain 12 Inches 2.4mm Size 4pcs",
"seller_name": null,
"brand": "Aexit",
"description": "Nickel plated steel beaded ball chain, wonderful replacement for your broken ones.Suitable for hanging nail files, label...",
"initial_price": null,
"currency": "USD"
},
{
"db_source": "1775505381244",
"timestamp": "2026-04-06",
"title": "Halloween Garage Door Decorations Halloween Banner 13X6 ft\/16X6.5ft,Scary Halloween Decorations Outside Garage Door Cove...",
"seller_name": null,
"brand": "DBPBToU",
"description": null,
"initial_price": null,
"currency": "USD"
},
{
"db_source": "1775505381244",
"timestamp": "2026-04-06",
"title": "Custom Bowling Shirts for Men and Women Funny Bowling Team League Jersey Bowling Polo \u0026 Quarter-Zip Shirts BDT45",
"seller_name": null,
"brand": "PIONAMZIOZ",
"description": "Specially designed for proud bowlers. Let\u0027s wear this awesome shirt and be bold.✔️ Product Features:- Comfortable, chic ...",
"initial_price": null,
"currency": "USD"
}
]
输入
JSON
curl -H "Authorization: Bearer API_TOKEN" -H "Content-Type: application/json" -d '[{"url":"https://www.zillow.com/homedetails/2506-Gordon-Cir-South-Bend-IN-46635/77050198_zpid/?t=for_sale"}]' "https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_lfqkr8wm13ixtbd8f5&format=json&uncompressed_webhook=true"
输出
JSON
[
{
"db_source": "1775499300155",
"timestamp": "2026-04-06",
"zpid": 122847621,
"city": "Louisville",
"state": "KY",
"homeStatus": "OTHER",
"address:city": "Louisville",
"address:streetAddress": "4300 Creekton Ct"
},
{
"db_source": "1775499300155",
"timestamp": "2026-04-06",
"zpid": 2095487842,
"city": "Wilbraham",
"state": "MA",
"homeStatus": "OTHER",
"address:city": "Wilbraham",
"address:streetAddress": "133 High Pine Cir #133"
},
{
"db_source": "1775499300155",
"timestamp": "2026-04-06",
"zpid": 59709057,
"city": "New Prague",
"state": "MN",
"homeStatus": "SOLD",
"address:city": "New Prague",
"address:streetAddress": "1313 Science Ave NW"
},
{
"db_source": "1775499300155",
"timestamp": "2026-04-06",
"zpid": 209007537,
"city": "Geneva",
"state": "NY",
"homeStatus": "OTHER",
"address:city": "Geneva",
"address:streetAddress": "23 Grant Ave"
},
{
"db_source": "1775499300155",
"timestamp": "2026-04-06",
"zpid": 28455579,
"city": "Houston",
"state": "TX",
"homeStatus": "OTHER",
"address:city": "Houston",
"address:streetAddress": "1701 Upland Dr APT 129"
}
]
输入
JSON
curl -H "Authorization: Bearer API_TOKEN" -H "Content-Type: application/json" -d '[{"url":"https://www.instagram.com/p/Cuf4s0MNqNr"},{"url":"https://www.instagram.com/p/DP861NijuwE"}]' "https://api.brightdata.com/datasets/v3/trigger?dataset_id=gd_lk5ns7kz21pck8jpis&format=json&uncompressed_webhook=true"
输出
JSON
[
{
"db_source": "1760661776360",
"timestamp": "2025-10-17",
"url": "https:\/\/www.instagram.com\/p\/DJcjyiQKB_u",
"user_posted": "aytolosrealejos",
"description": "🛠💦 OBRAS DE RENOVACIÓN RED DE AGUAS LA CARTAYA - TIERRA DE ORO l La empresa pública de aguas de #LosRealejos #Aquare a...",
"hashtags": [
"#LosRealejos",
"#Aquare",
"#red",
"#aguas",
"#LaCartaya",
"#TierradeOro",
"#obras,",
"#tráfico"
],
"num_comments": 0,
"date_posted": "2025-05-09T20:28:44.000Z"
},
{
"db_source": "1767283133835",
"timestamp": "2026-01-01",
"url": "https:\/\/www.instagram.com\/p\/CV_ER10PGg-",
"user_posted": "thevegansclubfruit",
"description": "🌟Berry Fusion Smoothie by @theallnaturalvegan\nSmoothie recipe:\n-3 frozen bananas \n- 1 cup frozen raspberries \n- 2 cups ...",
"hashtags": [
"#coconutbowls",
"#coconutbowl",
"#raspberrysmoothie",
"#veganbowls",
"#smoothie",
"#smoothiebowl",
"#smoothierecipes",
"#smoothiebowls"
],
"num_comments": 2,
"date_posted": "2021-11-07T18:54:17.000Z"
},
{
"db_source": "1760670997564",
"timestamp": "2025-10-17",
"url": "https:\/\/www.instagram.com\/reel\/DKIn27ISM8A",
"user_posted": "tvaztecaqueretaro",
"description": "VARIOS DÍAS PARA CONTROLAR INCENDIO🔥📆\n\nPasaron varios días para que pudiera ser controlado el incendio en una bodega d...",
"hashtags": null,
"num_comments": 0,
"date_posted": "2025-05-26T23:13:49.000Z"
},
{
"db_source": "1760879597325",
"timestamp": "2025-10-19",
"url": "https:\/\/www.instagram.com\/p\/DJlBPaDhkLG",
"user_posted": "tumbetoritori_kediri",
"description": "Dunia terlalu ada-ada aja, untuk aku yang gini-gini aja deerr_____________.Klik\u0022\n#pemburubesitua #vespatouring #kehidupu...",
"hashtags": [
"#pemburubesitua",
"#vespatouring",
"#kehidupunk",
"#vespa",
"#scooterbajajindonesia",
"#kebalwirang",
"#vespasprint150",
"#vespalover"
],
"num_comments": 2,
"date_posted": "2025-05-13T03:19:59.000Z"
},
{
"db_source": "1773938628296",
"timestamp": "2026-03-19",
"url": "https:\/\/www.instagram.com\/p\/DFs1QjHtB90\/?__a=1\u0026__d=dis",
"user_posted": "arkxplug",
"description": "Damn they not leaving the unc alone 😭\n\n#foryoupage💙 #foryou #grammyawards #kaicenat #meme #grammys #taylorswift #drake...",
"hashtags": [
"#foryoupage",
"#foryou",
"#grammyawards",
"#kaicenat",
"#meme",
"#grammys",
"#taylorswift",
"#drake"
],
"num_comments": 3,
"date_posted": "2025-02-05T18:04:40.000Z"
}
]
顶级用户体验
易于开始,更易扩展。
无与伦比的稳定性
依靠全球领先的代理基础设施,确保一致的性能并将故障降至最低。
简化的网页抓取
使用可投入生产的API将您的抓取任务自动化,节省资源并减少维护。
无限扩展性
轻松扩展您的抓取项目以满足数据需求,同时保持最佳性能。
更快部署
一次API调用,大量数据。
数据发现
检测数据结构和模式,以确保高效、针对性的数据提取。
批量请求处理
降低服务器负载,并为大规模抓取任务优化数据采集。
数据解析
高效地将原始 HTML 转换为结构化数据,简化数据集成与分析。

数据验证
确保数据可靠性,节省人工检查与预处理时间。
底层能力
再也不用担心代理和 CAPTCHA 了
- 自动 IP 轮换
- CAPTCHA 识别/破解
- User Agent 轮换
- 自定义请求头
- JavaScript 渲染
- 住宅代理
每15分钟,我们的客户就能抓取足够的数据来
从头开始训练ChatGPT。
用于无缝访问 网页 数据的 API
全面、可扩展、且合规的网页数据提取
用于无缝访问 网页 数据的 API
全面、可扩展、且合规的网页数据提取
贴合你的工作流
通过 Webhook 或 API 交付,以 JSON、NDJSON 或 CSV 文件获取结构化数据。
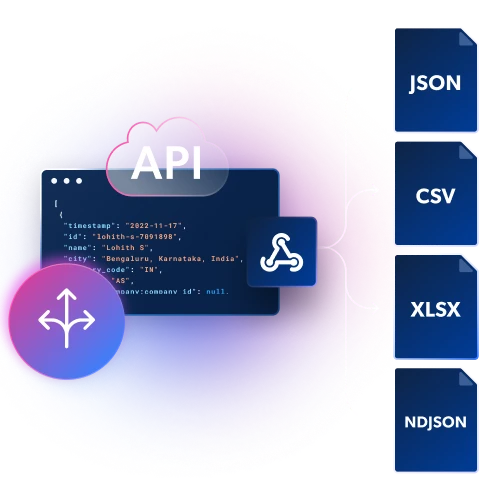
内置基础设施与自动解封
无需维护代理与解封基础设施,即可获得最大的控制力与灵活性。轻松从任何地理位置抓取数据,同时规避验证码与封锁。

经实战验证的基础设施
Bright Data 平台为全球 20,000+ 家公司提供支持,以 99.99% 的在线率带来安心体验,并可访问覆盖 195 个国家/地区的 1.5 亿+ 真实用户 IP。

行业领先的合规标准
我们的隐私实践遵守包括欧盟数据保护监管框架、GDPR 和 CCPA 在内的数据保护法律。

使用案例
适用于每个使用场景的抓取器API







热门抓取API
适用于各种使用场景的抓取API
无需开发和维护网页抓取工具。使用网页抓取API轻松提取大量网页数据。
网页爬虫API常见问题解答
什么是爬虫API?
爬虫API是一种基于云的服务,可以简化网页数据提取,提供自动处理IP轮换、CAPTCHA解决方案,并将数据解析为结构化格式。它可以高效、可扩展地收集数据,专为需要无缝访问有价值网页数据的企业量身定制。
谁可以从使用爬虫API中受益?
数据分析师、科学家、工程师和开发人员,特别是那些寻求高效方法来收集和分析AI、机器学习、大数据应用等领域的网页数据的人,将会发现爬虫API特别有利。
为什么选择爬虫API而不是手动爬取方法?
爬虫API克服了手动网页爬取的局限性,例如应对网站结构变化、遭遇封锁和验证码,以及与基础设施维护相关的高成本。它提供了一种自动化、可扩展且可靠的数据提取解决方案,大大降低了运营成本和时间。
是什么让Bright Data的爬虫API在市场上独树一帜?
爬虫API的独特性在于其专门功能,如批量请求处理、数据发现和自动验证,并由包括住宅代理和JavaScript渲染等先进技术支持。这些功能确保广泛访问、高数据完整性和整体效率,使爬虫API在竞争激烈的市场中脱颖而出。
如何开始使用爬虫API?
通过Bright Data的控制面板,开始使用爬虫API非常简单。该面板提供了全面的文档和用户友好的仪表板,用于API密钥管理和设置。这种方法减少了设置要求,允许用户立即访问一个高度可扩展且可靠的网页数据提取平台。
爬虫API优化的具体用例是什么?
爬虫API支持一系列开发需求,包括竞争基准分析、市场趋势分析、动态定价算法、情感提取以及将数据输入机器学习管道。对于电子商务、金融科技和社交媒体分析,这些API为开发人员有效实施数据驱动的战略提供了强大支持。
爬虫API如何管理大规模数据提取任务?
爬虫API具备高并发和批量处理能力,在大规模数据提取场景中表现出色。这确保了开发人员可以高效扩展其爬虫操作,满足大量请求的高吞吐量需求。
爬虫API可以以哪种数据格式提供提取的信息?
爬虫API以多种格式提供提取的数据,包括NDJSON和CSV,确保与各种分析工具和数据处理工作流程的无缝集成,从而在开发者环境中便于采用。