

随着数字经济的持续快速增长,从各种来源(如API、网站和数据库)收集数据变得比以往任何时候都更为重要。
一种常见的数据提取方法是通过网页抓取。网页抓取涉及使用自动化工具获取网页并解析其内容,以提取特定信息以供进一步分析和使用。常见的用例包括市场研究、价格监控和数据聚合。
实施网页抓取需要处理动态内容、管理会话和Cookie、应对反抓取措施,并确保合法合规。这些挑战需要先进的工具和技术来实现有效的数据提取。ChatGPT可以通过其自然语言处理能力生成代码并解决错误,从而帮助应对这些复杂性。
在本文中,您将学习如何使用ChatGPT生成用于抓取主要依赖静态HTML内容的网站的抓取代码,以及应对采用更复杂页面生成技术的网站的抓取代码。
先决条件
在开始本教程之前,请确保您具备以下条件:
- 熟悉Python
- 在您的机器上安装并配置了Python环境(使用Visual Studio Code)
- 拥有一个ChatGPT账户
当您使用ChatGPT生成您的网页抓取脚本时,有两个主要步骤:
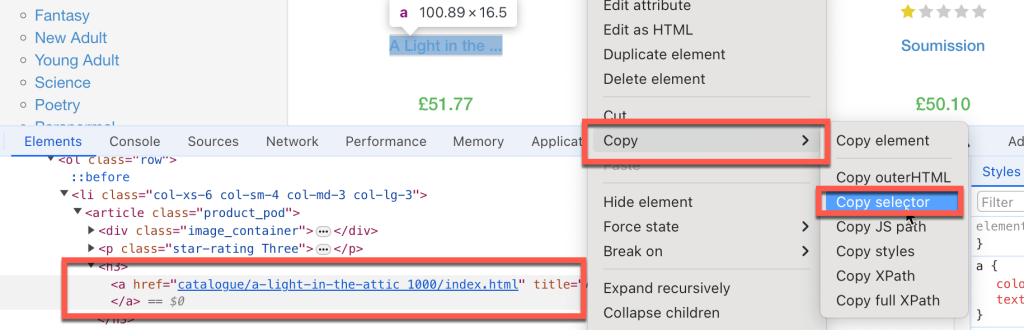
- 记录代码需要遵循的每一步骤以查找要抓取的信息,例如要定位的HTML元素、要填写的文本框以及要点击的按钮。通常,您需要复制特定的HTML元素选择器。为此,右键单击您要抓取的特定页面元素,然后单击检查;Chrome会突出显示特定的DOM元素。右键单击它并选择复制>复制选择器,这样HTML选择器路径就会复制到剪贴板中:

- 撰写具体且详细的ChatGPT提示以生成抓取代码。
- 执行并测试生成的代码。
使用ChatGPT抓取静态HTML网站
现在您已经熟悉了基本工作流程,让我们使用ChatGPT抓取一些包含静态HTML元素的网站。首先,您将从https://books.toscrape.com抓取书名和价格。
首先,您需要识别包含您所需数据的HTML元素:
- 书名选择器为
#default > div.container-fluid.page > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > h3 > a。 - 书价选择器为
#default > div.container-fluid.page > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > div.product_price > p.price_color。
接下来,您需要撰写具体且详细的ChatGPT提示以生成抓取代码。为此,您需要告诉ChatGPT安装任何需要的Python包,指导它通过提取HTML选择器(您之前已识别)来抓取数据,然后要求它将数据保存为Excel文件。
不要忘记将ChatGPT版本设置为GPT-4。
您可以向ChatGPT输入如下内容:
您是一位使用Python的Beautiful Soup库进行网页抓取的专家,并使用任何必要的自动化工具。我希望您生成一个详细的逐步脚本来抓取https://books.toscrape.com,请执行以下操作:
- 安装所有必要的Python包。
- 提取书名,其HTML选择器为
#default > div.container-fluid.page > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > h3 > a,以及书价(仅提取数字部分),其选择器为#default > div.container-fluid.page > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > div.product_price > p.price_color。- 提取所有书名和价格的列表并将其存储在Excel文件中。
- 仅抓取第一页。
请注意:您可能会收到略有不同的回复。
在回复中,ChatGPT会指示您运行以下命令以安装用于网页抓取的Beautiful Soup库以及用于将数据存储为Excel文件的pandas库:
pip3 install requests beautifulsoup4 pandas openpyxl您会注意到,ChatGPT还建议安装openpyxl,但在此场景中并不需要。
ChatGPT还提供了以下网页抓取代码:
import requests
from bs4 import BeautifulSoup
import pandas as pd
# URL of the website
url = 'https://books.toscrape.com'
# Send a GET request to the website
response = requests.get(url)
if response.status_code == 200:
# Parse the HTML content of the page
soup = BeautifulSoup(response.content, 'html.parser')
# Initialize lists to store the titles and prices
book_titles = []
book_prices = []
# Extract the first book title and price using the provided selectors
book_title_selector = "#default > div.container-fluid.page > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > h3 > a"
book_price_selector = "#default > div.container-fluid.page > div > div > div > section > div:nth-child(2) > ol > li:nth-child(1) > article > div.product_price > p.price_color"
title_element = soup.select_one(book_title_selector)
price_element = soup.select_one(book_price_selector)
if title_element and price_element:
book_titles.append(title_element.get('title'))
book_prices.append(price_element.text.strip()[1:])
# Extract all book titles and prices on the first page
books = soup.select('section > div:nth-child(2) > ol > li')
for book in books:
title = book.select_one('h3 > a')
price = book.select_one('div.product_price > p.price_color')
if title and price:
book_titles.append(title.get('title'))
book_prices.append(price.text.strip()[1:])
# Create a DataFrame from the lists
df = pd.DataFrame({
'Title': book_titles,
'Price': book_prices
})
# Save the DataFrame to an Excel file
df.to_excel('books_scraped.xlsx', index=False)
print('Data has been successfully scraped and saved to books_scraped.xlsx')
else:
print('Failed to retrieve the webpage')此代码导入了requests模块,该模块用于对要抓取的网站执行HTTP调用。它还导入了pandas包,用于将抓取的数据存储在Excel文件中。代码定义了网站的基本URL以及要提取的特定HTML选择器,以获取所需的数据。
然后,代码调用该网站并将网站内容作为名为soup的BeautifulSoup对象存储。代码使用HTML选择器从soup对象中提取书名和价格的列表。最后,代码从书名和价格列表创建pandas DataFrame并将其保存为Excel文件。
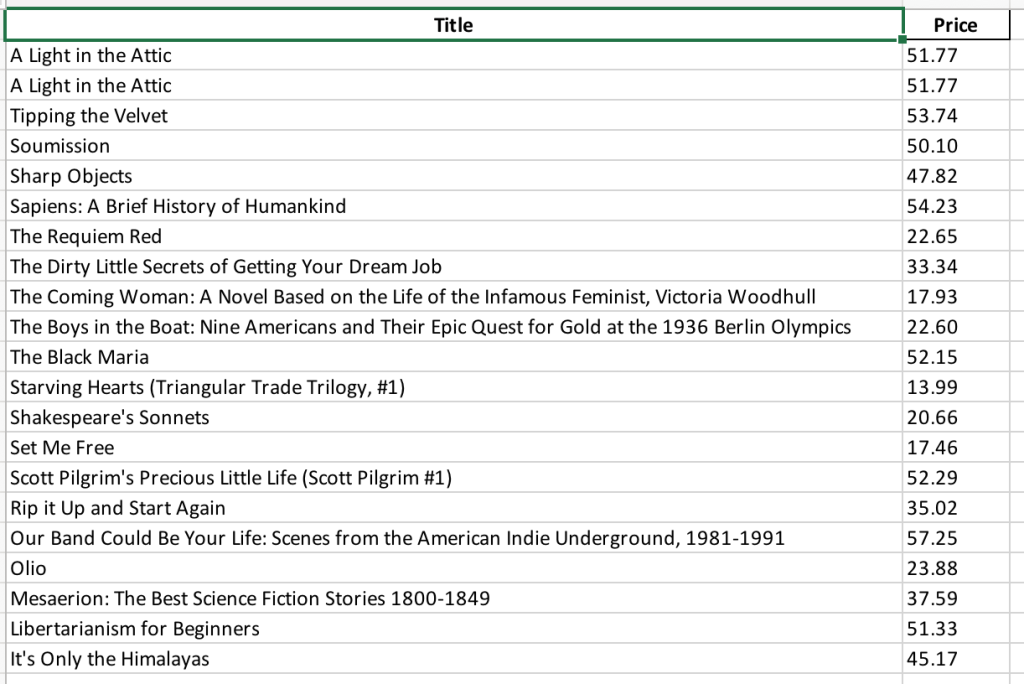
接下来,您需要将代码保存为名为books_scraping.py的文件,并从命令行运行命令python3 books_scraping.py。此代码将在与books_scraping.py文件相同的目录中生成名为books_scraped.xlsx的Excel文件:
现在,您已经完成了一个示例,让我们进一步学习如何抓取另一个简单的网站:https://quotes.toscrape.com,该网站包含了一系列名言。
再次,让我们从确定步骤开始。
如果您使用的是Chrome,请找到以下HTML选择器:
- 用于抓取名言的选择器为
body > div.container > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span.text - 用于识别作者的选择器为
body > div.container > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span:nth-child(2) > small
一旦您确定了要抓取的HTML选择器,您可以撰写详细的提示,如下所示,以生成抓取代码:
您是一位使用Python的Beautiful Soup库进行网页抓取的专家,并使用任何必要的自动化工具。我希望您生成一个详细的逐步脚本来抓取https://quotes.toscrape.com。请执行以下操作:
- 安装所有必要的Python包。
- 提取名言,其HTML选择器为
body > div.container > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span.text,以及作者名,其选择器为body > div.container > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span:nth-child(2) > small。- 提取所有名言和作者的列表,并将其存储在Excel文件中。
- 仅抓取第一页。
在输入此信息后,ChatGPT应该会提供以下命令,用于安装Beautiful Soup、pandas和openpyxl库:
pip3 install requests beautifulsoup4 pandas openpyxlChatGPT还应提供以下网页抓取代码:
import requests
from bs4 import BeautifulSoup
import pandas as pd
# Step 1: Fetch the web page content
url = "https://quotes.toscrape.com"
response = requests.get(url)
html_content = response.text
# Step 2: Parse the HTML content using BeautifulSoup
soup = BeautifulSoup(html_content, 'html.parser')
# Step 3: Extract the specific quote and author
quote_selector = "body > div.container > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span.text"
author_selector = "body > div.container > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span:nth-child(2) > small"
specific_quote = soup.select_one(quote_selector).get_text()
specific_author = soup.select_one(author_selector).get_text()
print(f"Specific Quote: {specific_quote}")
print(f"Specific Author: {specific_author}")
# Step 4: Extract all quotes and authors
quotes = soup.find_all('div', class_='quote')
all_quotes = []
for quote in quotes:
text = quote.find('span', class_='text').get_text()
author = quote.find('small', class_='author').get_text()
all_quotes.append({"quote": text, "author": author})
# Step 5: Save the quotes to an Excel file
df = pd.DataFrame(all_quotes)
df.to_excel('quotes.xlsx', index=False)
print("Quotes have been saved to quotes.xlsx")
soup = BeautifulSoup(html_content, 'html.parser')
# Step 3: Extract the specific quote and author
quote_selector = "body > div.container > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span.text"
author_selector = "body > div.container > div:nth-child(2) > div.col-md-8 > div:nth-child(1) > span:nth-child(2) > small"
specific_quote = soup.select_one(quote_selector).get_text()
specific_author = soup.select_one(author_selector).get_text()
print(f"Specific Quote: {specific_quote}")
print(f"Specific Author: {specific_author}")
# Step 4: Extract all quotes and authors
quotes = soup.find_all('div', class_='quote')
all_quotes = []
for quote in quotes:
text = quote.find('span', class_='text').get_text()
author = quote.find('small', class_='author').get_text()
all_quotes.append({"quote": text, "author": author})
# Step 5: Save the quotes to an Excel file
df = pd.DataFrame(all_quotes)
df.to_excel('quotes.xlsx', index=False)
print("Quotes have been saved to quotes.xlsx")将此代码保存为名为quotes_scraping.py的文件,并从命令行运行命令python3 books_scraping.py。此代码将在与quotes_scraping.py文件相同的目录中生成名为quotes_scraped.xlsx的Excel文件。打开生成的Excel文件,应该如下所示:

抓取复杂网站
抓取复杂的网站可能具有挑战性,因为动态内容通常通过JavaScript加载,而像requests和BeautifulSoup这样的工具无法处理这些内容。这些网站可能需要点击按钮或滚动等交互才能访问所有数据。为了解决这一挑战,您可以使用WebDriver,该工具像浏览器一样渲染页面并模拟用户交互,确保所有内容像普通用户一样可访问。
例如,Yelp是一个面向企业的众包评论网站。Yelp依赖于动态页面生成,并且需要模拟多种用户交互。在这里,您将使用ChatGPT生成一个抓取代码,获取斯德哥尔摩的企业列表及其评级。
要抓取Yelp,让我们先记录以下步骤:
- 找到脚本将使用的定位文本框的选择器;在本例中,它是
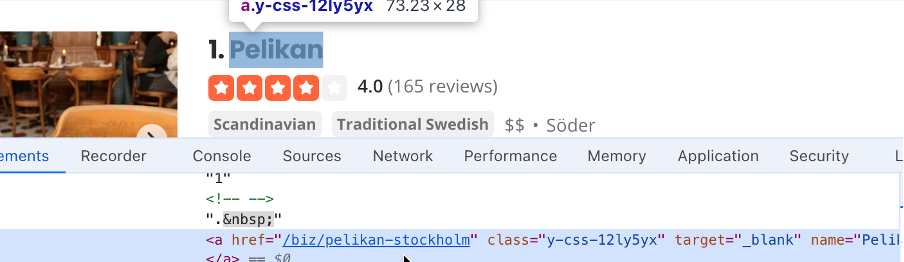
#search_location。在定位搜索框中输入“Stockholm”,然后找到搜索按钮的选择器;在本例中,它是#header_find_form > div.y-css-1iy1dwt > button。点击搜索按钮以查看搜索结果。这可能需要几秒钟。找到包含企业名称的选择器(例如#main-content > ul > li:nth-child(3) > div.container_\_09f24_\_FeTO6.hoverable_\_09f24_\__UXLO.y-css-way87j > div > div.y-css-cxcdjj > div:nth-child(1) > div.y-css-1iy1dwt > div:nth-child(1) > div > div > h3 > a):
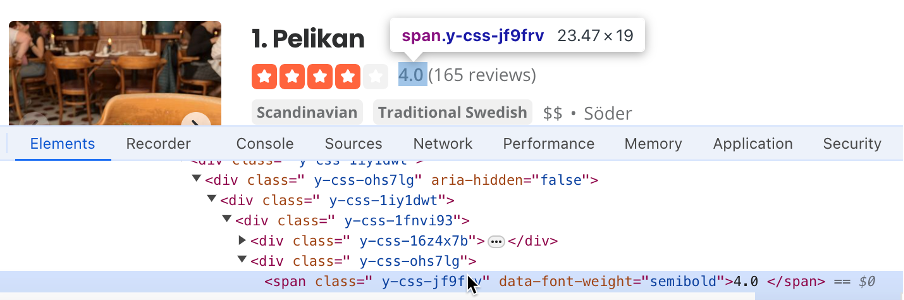
- 找到包含企业评分的选择器(例如
#main-content > ul > li:nth-child(3) > div.container_\_09f24_\_FeTO6.hoverable_\_09f24_\__UXLO.y-css-way87j > div > div.y-css-cxcdjj > div:nth-child(1) > div.y-css-1iy1dwt > div:nth-child(2) > div > div > div > div.y-css-ohs7lg > span.y-css-jf9frv):
- 找到立即营业按钮的选择器;这里是
#main-content > div.stickyFilterOnSmallScreen_\_09f24_\_UWWJ3.hideFilterOnLargeScreen_\_09f24_\_ilqIP.y-css-9ze9ku > div > div > div > div > div > span > button:nth-child(3) > span:
- 保存网页的副本,以便稍后上传到ChatGPT的提示中,帮助ChatGPT理解提示的上下文。在Chrome中,您可以点击右上角的三点,然后点击保存并共享>另存为:

接下来,使用之前提取的选择器值,您需要撰写详细的提示来指导ChatGPT生成抓取脚本:
您是一位网页抓取专家。我希望您抓取https://www.yelp.com/以提取特定信息。在抓取之前请遵循以下步骤:
- 清除选择器为
#search_location的框。- 在选择器为
#search_location的搜索框中输入“Stockholm”。- 点击选择器为
#header_find_form > div.y-css-1iy1dwt > button的按钮。- 等待几秒钟,页面加载搜索结果。
- 点击立即营业按钮,该按钮的选择器为
#main-content > div.stickyFilterOnSmallScreen_\_09f24_\_UWWJ3.hideFilterOnLargeScreen_\_09f24_\_ilqIP.y-css-9ze9ku > div > div > div > div > div > span > button:nth-child(3) > span,以筛选当前营业的企业。- 创建一个企业名称列表;企业名称的选择器为
#main-content > ul > li:nth-child(3) > div.container_\_09f24_\_FeTO6.hoverable_\_09f24_\__UXLO.y-css-way87j > div > div.y-css-cxcdjj > div:nth-child(1) > div.y-css-1iy1dwt > div:nth-child(1) > div > div > h3 > a。- 创建一个企业评论列表;评论的选择器为
#main-content > ul > li:nth-child(3) > div.container_\_09f24_\_FeTO6.hoverable_\_09f24_\__UXLO.y-css-way87j > div > div.y-css-cxcdjj > div:nth-child(1) > div.y-css-1iy1dwt > div:nth-child(2) > div > div > div > div.y-css-ohs7lg > span.y-css-jf9frv。- 创建一个包含企业名称及其评论的Excel文件。
- 确保安装所有相关的Python包。
- 使用Selenium中的WebDriver来自动化该过程。
- 参考附上的结果HTML页面副本,以便为您提供有关HTML格式的上下文信息。
在输入此信息后,ChatGPT会告诉您安装Selenium(支持WebDriver的Web自动化框架)和pandas:
pip3 install selenium pandasChatGPT还会提供一些抓取代码及其解释:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import pandas as pd
import time
# Initialize the WebDriver
driver = webdriver.Chrome()
try:
# Open Yelp
driver.get('https://www.yelp.com/')
# Clear the location search box
location_box = driver.find_element(By.CSS_SELECTOR, '#search_location')
location_box.clear()
# Enter "Stockholm" in the location search box
location_box.send_keys('Stockholm')
# Click the search button
search_button = driver.find_element(By.CSS_SELECTOR, '#header_find_form > div.y-css-1iy1dwt > button')
search_button.click()
# Wait for search results to load
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, '#main-content'))
)
# Click on "Open Now" filter
open_now_button = driver.find_element(By.CSS_SELECTOR, '#main-content > div.stickyFilterOnSmallScreen__09f24__UWWJ3.hideFilterOnLargeScreen__09f24__ilqIP.y-css-9ze9ku > div > div > div > div > div > span > button:nth-child(3) > span')
open_now_button.click()
# Wait for the filter results to load
time.sleep(5)
# Extract business names and reviews
business_names = []
business_reviews = []
businesses = driver.find_elements(By.CSS_SELECTOR, '#main-content > ul > li')
for business in businesses:
try:
name = business.find_element(By.CSS_SELECTOR, 'div.container__09f24__FeTO6.hoverable__09f24___UXLO.y-css-way87j > div > div.y-css-cxcdjj > div:nth-child(1) > div.y-css-1iy1dwt > div:nth-child(1) > div > div > h3 > a').text
review = business.find_element(By.CSS_SELECTOR, 'div.container__09f24__FeTO6.hoverable__09f24___UXLO.y-css-way87j > div > div.y-css-cxcdjj > div:nth-child(1) > div.y-css-1iy1dwt > div:nth-child(2) > div > div > div > div.y-css-ohs7lg > span.y-css-jf9frv').text
business_names.append(name)
business_reviews.append(review)
except Exception as e:
print(f"Error extracting data for a business: {e}")
# Create a DataFrame and save to Excel
df = pd.DataFrame({'Business Name': business_names, 'Reviews': business_reviews})
df.to_excel('stockholm_businesses.xlsx', index=False)
print("Data saved to stockholm_businesses.xlsx")
finally:
# Close the WebDriver
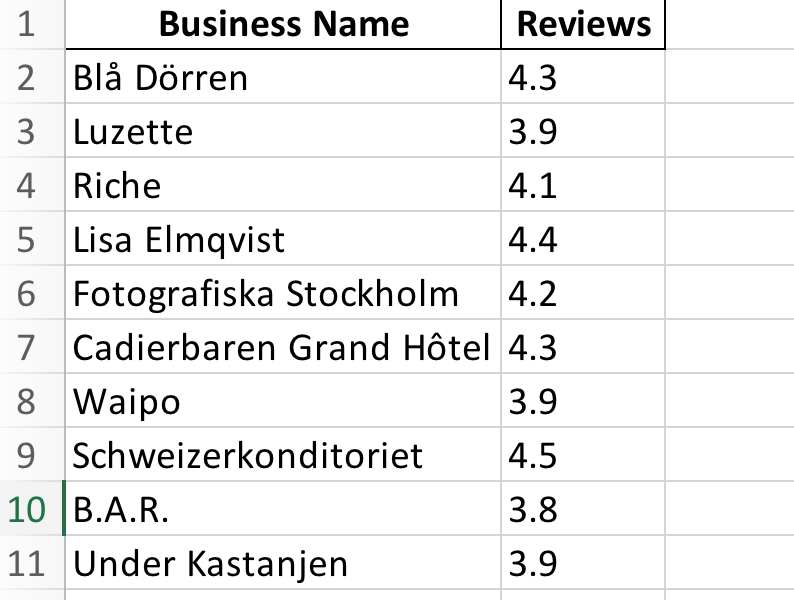
driver.quit()保存此脚本并使用Visual Studio Code中的Python运行。您会注意到代码启动了Chrome浏览器,导航到Yelp,清除位置文本框,输入“Stockholm”,点击搜索按钮,筛选当前营业的企业,然后关闭页面。之后,抓取结果保存到Excel文件stockholm_bussinsess.xlsx中:
本教程的所有源代码可在GitHub上找到。
结论
在本教程中,您学习了如何使用ChatGPT从静态HTML渲染的网站和具有更复杂页面生成、外部JavaScript链接和用户交互的网站中提取特定信息。
虽然抓取像Yelp这样的网站很简单,但实际上,抓取复杂的HTML结构可能具有挑战性,您可能会遇到IP封禁和CAPTCHA。
为了简化过程,Bright Data提供了多种数据收集服务,包括高级代理服务以帮助绕过IP封禁、Web Unlocker绕过并解决CAPTCHA、Web Scraping API用于自动化数据提取,以及Scraping Browser以高效提取数据。
立即注册并探索Bright Data提供的所有产品。今天就开始免费试用吧!



