

网络爬虫是通过脚本或软件工具自动从网站提取数据的过程,通常用于分析或聚合信息。
Beautiful Soup是一个流行的Python库,用于高效解析HTML和XML文档。
在这个全面的指南中,您将学习如何使用Beautiful Soup进行网络爬虫。文章中充满了代码示例和实用建议,在学习过程中提供了宝贵的见解。
使用Beautiful Soup进行网络爬虫
通常,HTML和XML语言用于构建网页内容,文档对象模型(DOM)树将文档表示为对象树。您可以使用自动化脚本或库,通过导航其DOM从网页内容中提取有意义的信息。
Beautiful Soup Python库可以解析HTML和XML文档并导航DOM树。该库会自动选择设备上最佳的HTML解析器,或者您可以指定一个自定义的HTML解析器。然后该库将HTML文档转换为一个可导航的Python对象树。
Beautiful Soup还可以使用快速高效的lxml解析器解析XML内容。与HTML文档类似,该库会从XML文档生成一个Python对象树,您可以使用Beautiful Soup选择器遍历该文档。
Beautiful Soup的HTML或XML解析器可用于解析网页内容并生成类似于DOM树的Python对象。生成的Python对象可以用于高效地从文档的不同部分提取数据,通过选择相关元素。有几种选择元素的方法,包括find(),它接受一个选择器条件并返回第一个匹配的HTML元素,以及find_all(),它接受一个选择器条件并返回所有匹配的HTML元素列表。例如,您可以使用find_all('p')选择器查找所有段落(<p>)标签中的内容。
使用Beautiful Soup进行网络爬虫
在开始从网页抓取数据之前,您需要确定要抓取页面上的哪些数据以及如何抓取它们。
您可以使用网页浏览器的开发者工具检查网页上的元素。例如,以下截图显示了Quotes to Scrape网页上的引文块的DOM元素:
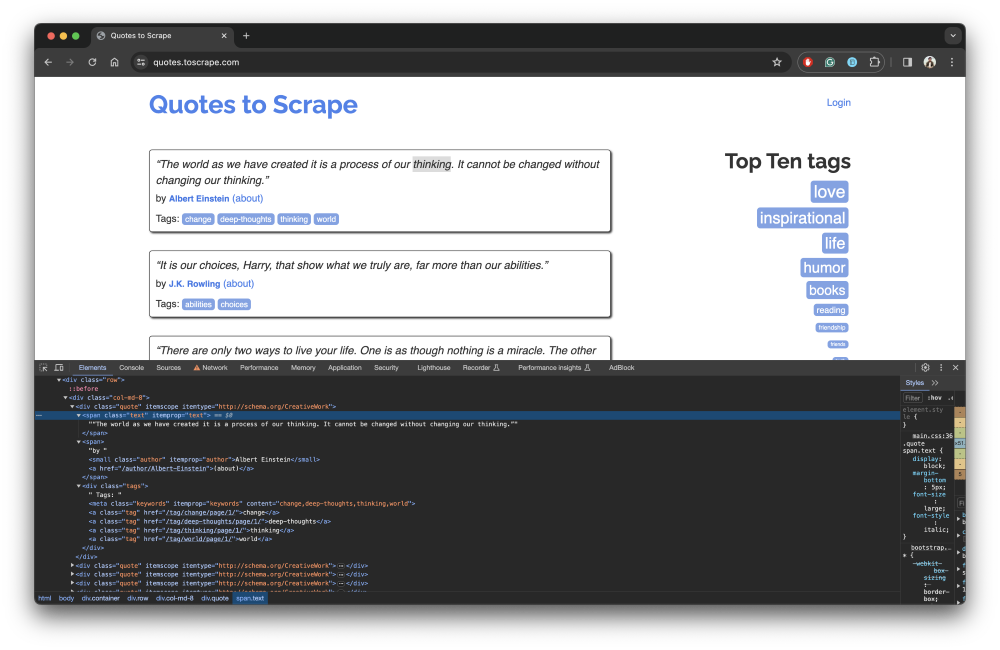
请注意,引文文本在标签内,作者姓名在标签内。除了标签外,您还可以使用HTML属性和CSS选择器的组合来选择某些元素。在本指南中,您将从Quotes to Scrape页面抓取引文和作者姓名。
创建一个新项目
首先,创建一个名为beautifulsoup-scraping-example的新项目目录,用于存放爬虫脚本,并使用以下命令导航到该目录:
mkdir beautifulsoup-scraping-example
cd beautifulsoup-scraping-example在进行网络爬虫时,首先需要使用HTTPGET请求从URL获取网页内容。使用以下命令安装requests库:
pip install requests您将使用该库稍后进行GET请求。
对于实际的网络爬虫任务,使用以下命令安装beautifulsoup4 Python库:
pip install beautifulsoup4您还可以将依赖项列表存储在文件中,以便与他人协作编写脚本或将其存入版本控制系统。在项目根目录中创建一个requirements.txt文件,内容如下:
requests
beautifulsoup4然后使用以下命令安装之前在文件中定义的依赖项:
pip install -r requirements.txt定义您的网络爬虫脚本
接下来,您需要定义一个Python脚本,该脚本将获取网页内容并使用BeautifulSoup解析它以生成一个soup对象。您可以使用不同的选择器与soup对象来查找网页上的元素并从中提取所需信息。
首先在项目根目录中创建一个名为main.py的Python脚本文件,并添加requests和beautifulsoup4的import语句:
import requests
from bs4 import BeautifulSoup接下来,定义一个方法,该方法接受一个网页URL并返回页面内容:
def get_page_contents(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/107.0.0.0 Safari/537.36'
}
page = requests.get(url, headers=headers)
if page.status_code == 200:
return page.text
return None请注意,get_page_contents方法使用requests库调用GET方法并返回text响应。此外,请注意,该方法随GET请求一起传递User-Agent头请求,以避免从Web服务器接收到错误响应。传递User-Agent头是可选的,但如果Web服务器接收到未知的用户代理,有些服务器可能会拒绝请求。
要从页面内容中抓取引文和作者,定义一个使用BeautifulSoup解析原始HTML数据并返回所需数据的方法:
def get_quotes_and_authors(page_contents):
soup = BeautifulSoup(page_contents, 'html.parser')
quotes = soup.find_all('span', class_='text')
authors = soup.find_all('small', class_='author')
return quotes, authors这里,该方法接受从get_page_contents方法获得的page_contents。
它使用页面内容创建一个BeautifulSoup实例,并指定要使用的解析器类型。如果省略第二个参数,Beautiful Soup会根据页面内容自动使用设备上安装的最佳解析器。
然后它使用soup实例查找所有引文和作者的元素,并使用find_all方法根据标签选择元素。最后,它指定了一个CSS选择器来优化搜索条件。
现在,将所有内容组合在一起,并在main.py文件末尾添加以下代码片段:
if __name__ == '__main__':
url = 'http://quotes.toscrape.com'
page_contents = get_page_contents(url)
if page_contents:
quotes, authors = get_quotes_and_authors(page_contents)
for i in range(len(quotes)):
print(quotes[i].text)
print(authors[i].text)
print()
else:
print('Failed to get page contents.')此代码使用get_page_contents获取页面内容,并使用页面内容获取所有quotes和authors,使用get_quotes_and_authors方法。最后,它遍历引文列表 并打印结果。
通过执行以下命令测试脚本:
python main.py您的输出应如下所示:
"The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking."
Albert Einstein
--- OUTPUT OMITTED ---
"A day without sunshine is like, you know, night."
Steve Martin正如您所见,您现在已经成功创建了一个爬虫脚本。如果您有兴趣了解更多,请查看Python网络爬虫指南,其中包括一些更高级的爬虫技术。
所有使用的代码可在此GitHub仓库中找到。
处理常见挑战
根据您要抓取的网页的复杂程度,您可能会在爬虫过程中遇到一些挑战,包括以下内容:
动态内容
有些网站使用JavaScript动态加载内容,而不是静态渲染(如您在此处使用的Quotes to Scrape网页)。例如,Scraping Sandbox主页列出了一个动态渲染的相同网页的JavaScript版本。现在,看看您创建的脚本是否适用于此动态内容。
将main.py脚本中的url替换为以下内容:
# update URL in the main.py script
url = 'https://quotes.toscrape.com/js/'然后执行脚本。您会注意到输出为空。
如果您想渲染和抓取动态内容,您必须使用一个无头浏览器,如Selenium。无头浏览器在没有图形用户界面(GUI)的情况下运行,通过在类似于常用Web浏览器的环境中允许自动操作网页来工作。Selenium让您可以利用真正的浏览器渲染网页,从而抓取依赖JavaScript的网页。
分页
除了动态内容外,网页还可以以多种不同方式实现分页。在抓取任何数据之前,您需要了解您要抓取的网站如何实现分页。
常见的分页技术包括以下内容:
标记或URL模式
网页可能包含上一页和下一页的标记及其URL。此外,网站可能遵循特定模式进行分页内容。例如,Quotes to Scrape页面在底部有一个下一页标记。
您可以使用Beautiful Soup库find下一个页面标记并获取其相对链接以构建下一个页面的URL并抓取其数据。
无限滚动
无限滚动是指当您向下滚动时网页加载更多内容。例如,ToScrape网站有一个Quotes to Scrape页面的滚动版本,向下滚动时加载更多引文。对于这种网页,您必须使用具有滚动功能的无头浏览器。您可以使用Selenium的滚动轮操作来滚动网页并加载更多内容。
错误处理
有时在进行网络爬虫时,所需元素可能丢失或包含脏数据。处理这些情况对于确保一致的结果至关重要。
将爬虫代码包装在try-catch块中可以防止脚本在遇到意外错误时崩溃。例如,在Quotes to Scrape网站上,某些引文可能没有作者姓名。您可以修改get_quotes_and_authors方法,添加一个try-catch块来捕获和记录错误:
def get_quotes_and_authors(page_contents):
soup = BeautifulSoup(page_contents, 'html.parser')
try:
quotes = soup.find_all('span', class_='text')
authors = soup.find_all('small', class_='author')
except Exception as e:
print(e)
return None, None
return quotes, authors附加部分 – 提示和技巧
在本节中,我们将介绍一些有助于优化使用Beautiful Soup进行爬虫过程的技巧。
查找文档中使用的所有标签
要查找HTML标签,您可以利用Python中的Beautiful Soup库。一种方法是使用Beautiful Soup读取HTML文件,然后通过迭代其后代提取文件中所有标签的列表。通过使用Beautiful Soup提供的soup.descendants生成器,您可以访问并打印HTML结构中每个标签的名称。这个过程包括打开HTML文件,使用Beautiful Soup解析它,然后迭代其后代以识别和显示文档中遇到的HTML标签名称。
从HTML标签中提取完整内容
以下是执行此操作的逐步指南:
- 首先导入必要的库BeautifulSoup,它用于解析HTML和XML文档。
- 打开包含您要提取内容的HTML文件。您可以使用Python的文件处理功能来完成此操作。读取文件的内容并将其存储在变量中。
- 通过提供HTML文件的内容和指定的解析器(在本例中为“html.parser”)创建一个BeautifulSoup对象。
- 一旦创建了BeautifulSoup对象,您可以使用其标签名称作为属性访问文档中的特定HTML标签。例如,如果您想提取h2标签内的内容,可以使用
soup.h2访问它。 - 同样,您可以通过
soup.p和soup.li访问段落(<p>)和列表项(<li>)内的内容。 - 最后,通过执行这些指令,您将能够按文档中出现的顺序输出指定HTML标签的完整内容。
通过遵循这些步骤并利用BeautifulSoup库,您可以有效地从HTML文档中提取HTML标签的完整内容。
伦理考虑
在抓取任何数据之前,您必须审查并遵守网站的服务条款,并根据定义的限制编写您的脚本。在抓取过程中,您应遵守目标网站的robot.txt规则。
此外,请确保在没有获得同意的情况下不收集个人信息,因为这可能会侵犯隐私法规。
您还应避免过于激进的爬虫,以免导致服务器过载并影响网站性能。Web服务器可能会实施保护措施,如强制执行速率限制,显示CAPTCHA或阻止您的IP地址。如果可能,请向源网站提供署名,以承认该网站提供的努力和内容。
优化网络爬虫
要提高您的网络爬虫脚本的可靠性和效率,请考虑实施以下一些技术:
使用并行化
考虑在您的脚本中使用多线程并行处理嵌套数据。例如,在Quotes to Scrape网页上,您可以修改脚本以查找所有引文div块,并并行处理这些div块。如果DOM树复杂,此技术可以显著提高脚本的执行速度。
添加重试逻辑
在脚本中为网络调用添加重试逻辑可以提高其可靠性。例如,在本用例中,您可以为get_page_contents添加重试逻辑,以确保脚本在第一次尝试无法获取页面内容时不会失败。
轮换用户代理
如果Web服务器从同一用户代理接收到大量请求,可能会阻止您的请求。要解决此问题,您可以通过每次请求生成一个新的User-agent来轮换用户代理。注意,get_page_contents方法传递静态User-agent头到requests.getAPI调用。您可以定义 一个方法get_random_user_agent,生成一个动态的用户代理。
实施速率限制
如果您在短时间内发送太多请求,Web服务器可能会阻止或拒绝您的请求。要解决此问题,您可以在请求之间实施手动延迟。
使用代理服务器
您可以使用代理服务器作为您的爬虫脚本与目标页面之间的中介。代理服务器有助于在请求网页内容时轮换IP地址,避免IP被封禁。了解更多关于Python IP轮换的信息。
Bright Data提供多种代理网络,强大的Web爬虫工具和可下载的现成数据集。Bright Data还提供多种代理服务,包括住宅、数据中心、ISP和移动代理,以满足您的网络爬虫需求。如果您希望将网络爬虫提升到新的水平,请考虑使用Bright Data。
结论
Beautiful Soup是一个进行网络爬虫的有价值工具,并且它与几种不同的XML和HTML解析器无缝集成。一旦您确定了要抓取的数据并了解网页的结构,您可以快速使用Beautiful Soup Python库编写脚本。但是,根据网页的复杂程度,您可能需要处理与动态内容、分页和错误相关的挑战。
如果您希望减少开发工作并扩大您的爬虫规模,请考虑使用基于解除封锁代理基础设施构建的无服务器函数产品。它包括从流行网站获取的预构建JavaScript函数和代码模板。想要一个简单的自动驾驶解决方案,并带有生产就绪的API?请试试新的Web爬虫API。
此外,Bright Data代理服务提供了高效性能的高级代理基础设施,并能通过来自195个国家的代理绕过位置限制。它符合通用数据保护条例(GDPR)和加利福尼亚消费者隐私法案(CCPA),并且适用于所有流行的编程语言。



