

在本教程中,你将了解:
- 电子商务爬虫的定义以及它为何有用
- 电子商务爬虫工具的类型
- 你可以从电子商务平台爬虫的数据
- 如何使用 Python 创建电子商务爬虫脚本
- 爬虫电子商务网站的挑战
让我们开始吧!
什么是电子商务网页爬虫?
电子商务网页爬虫是从 Amazon、Walmart、eBay 和类似网站等在线零售平台提取数据的过程。虽然可以通过手动复制数据来完成,但通常使用自动化工具或脚本来执行。
从电子商务网站提取的数据可以帮助企业、研究人员和开发者:
- 分析产品价格波动
- 跟踪评论评分
- 识别市场趋势
- 研究竞争对手
这些洞察支持明智决策和战略规划。
请注意,电子商务数据爬虫工具通常被称为 电子商务爬虫工具。
电子商务爬虫工具的类型
以下是一些最受欢迎的电子商务爬虫工具类型列表:
- 自定义脚本:使用 Python 或 JavaScript 等 网页爬虫编程语言 提取特定电子商务数据的定制脚本。
- 无代码爬虫工具:用户友好的工具,允许无需编码即可提取数据,非常适合非技术用户。探索 最佳无代码爬虫工具。
- 网页爬虫 API:以编程方式提供结构化电子商务数据的接口,通常支持实时或大规模提取。
- 爬虫扩展程序:基于浏览器的附加组件,可在你浏览电子商务网页时直接简化数据收集。
在本文中,我们将专门关注构建自定义电子商务网页爬虫机器人。
从电子商务网站爬虫的数据
电子商务网页爬虫通常帮助你检索以下数据:
- 产品详情:名称、描述、规格和图片。
- 价格信息:当前价格、折扣和历史价格趋势。
- 客户评论:评分、评论内容和客户反馈。
- 类别和标签:产品的分类和归类。
- 卖家信息:卖家名称、评分和联系方式。
- 配送详情:费用、配送时间和配送政策。
- 库存可用性:库存水平和缺货通知。
- 营销数据:产品列表、定价策略、促销和季节性折扣。
现在,学习如何构建 Python 电子商务爬虫!
如何构建电子商务爬虫工具
要手动构建电子商务爬虫工具,你首先需要熟悉目标网站。使用 DevTools 检查目标页面,以:
- 了解其结构
- 确定你可以提取哪些数据
- 决定使用哪些爬虫库
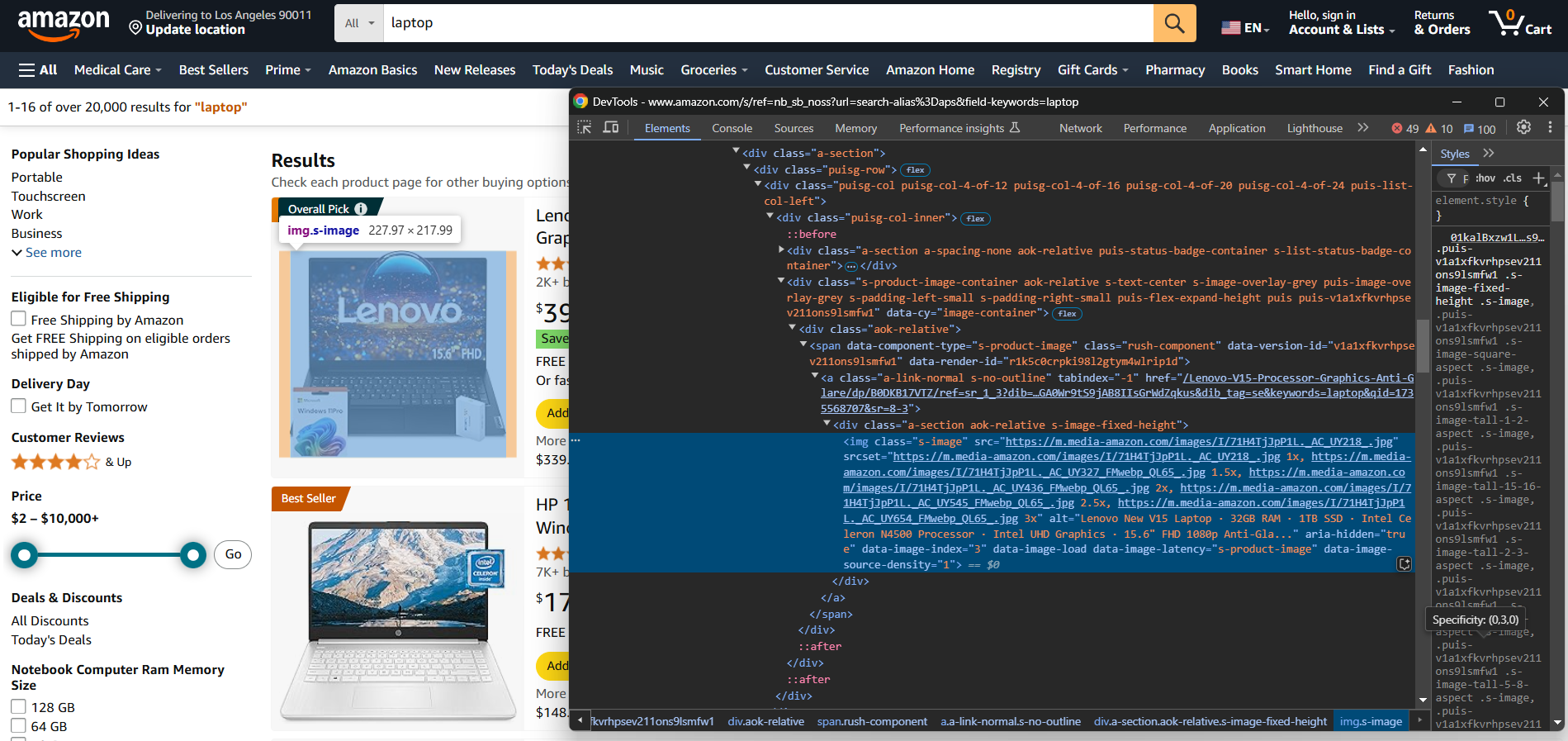
对于较简单的电子商务网站,以下两个 Python 库就足够了:
- Requests:用于发送 HTTP 请求。它帮助你获取网页的原始 HTML 内容。
- Beautiful Soup:用于解析 HTML 和 XML 文档。它简化了从页面 HTML 结构中进行导航和数据提取的过程。在我们的 Beautiful Soup 抓取 指南中了解更多。
你可以使用以下命令安装它们:
pip install requests beautifulsoup4对于动态加载数据或严重依赖 JavaScript 渲染的电子商务平台,你将需要像 Selenium 这样的浏览器自动化工具。有关更多信息,请参阅我们关于 Selenium 抓取 的教程。
你可以使用以下命令安装 Selenium:
pip install selenium接下来,网页爬虫过程如下:
- 连接到目标网站:使用 Requests 或 Selenium 检索并解析页面的 HTML。
- 选择感兴趣的元素:在 HTML 结构中定位特定元素(例如,产品图片、价格、描述),并使用 CSS 选择器或 XPath 表达式 选择它们。
- 提取数据:从这些 HTML 元素中提取所需信息。
- 清理数据:处理提取的数据以删除不必要的内容或在需要时重新格式化。
- 导出数据:将清理后的数据保存为首选格式,例如 JSON 或 CSV。
这种方法的优势包括对数据提取过程拥有完全控制权,并能够根据特定需求进行自定义。然而,它确实需要用于设计和维护的技术专业知识。此外,每个电子商务网站都需要自己的脚本。
在接下来的章节中,你将看到用于从 Amazon、Walmart 和 eBay 提取数据的 Python 电子商务爬虫脚本示例!
Amazon 爬虫
- 目标页面:Amazon 上的“laptop”搜索页面
- 目标页面 URL: https://www.amazon.com/s?k=laptop&ref=nb_sb_noss
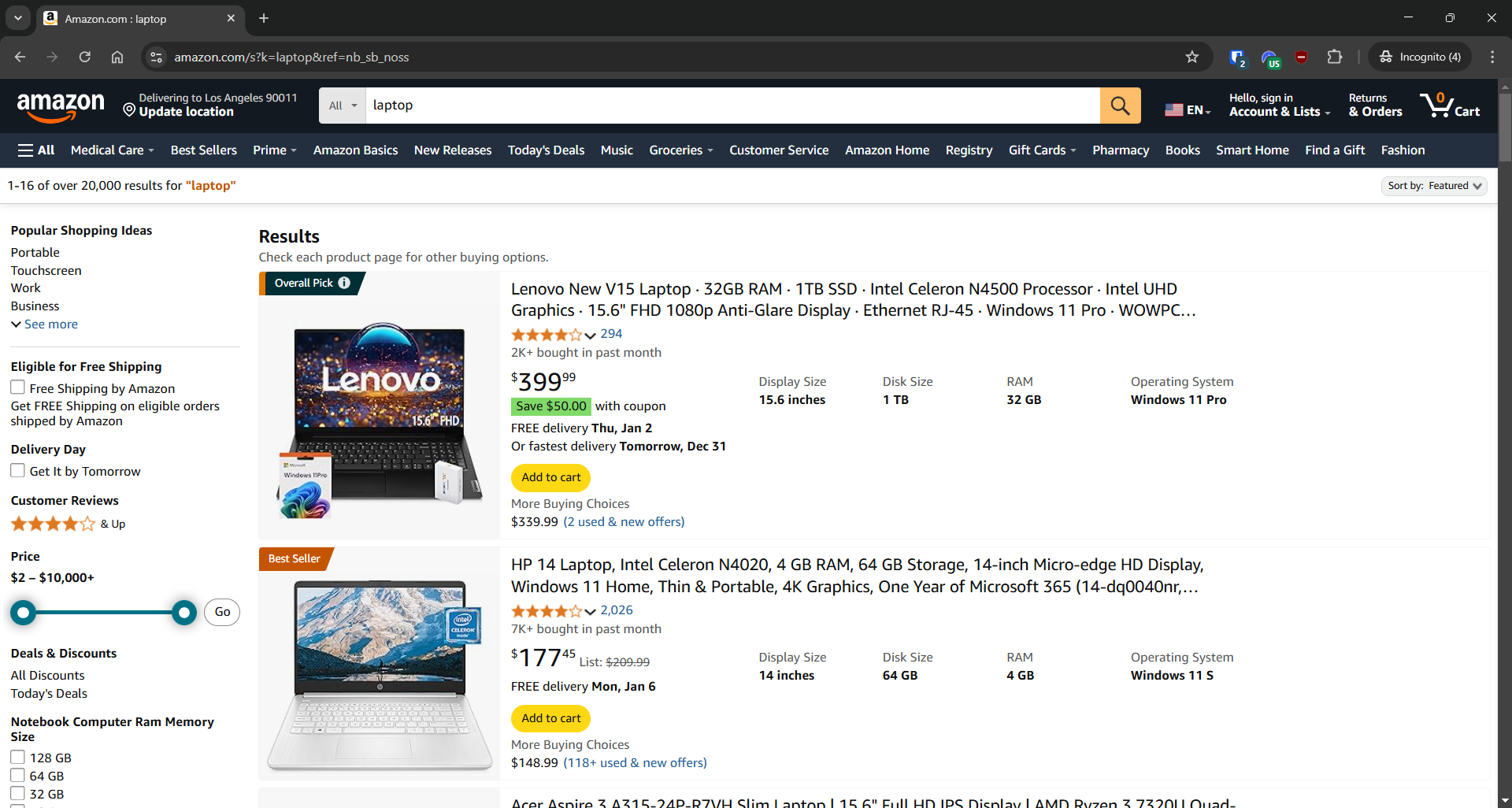
Amazon 有 反爬虫措施 旨在阻止并非来自浏览器的请求。要绕过这些限制,你需要使用像 Selenium 这样的浏览器自动化工具:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
import json
# Initialize the WebDriver
driver = webdriver.Chrome(service=Service())
# Open the Amazon home page in the browser
driver.get("https://amazon.com/")
# Fill out the search form
search_input_element = driver.find_element(By.ID, "twotabsearchtextbox")
search_input_element.send_keys("laptop")
# Locate the search button and click it
search_button_element = driver.find_element(By.ID, "nav-search-submit-button")
search_button_element.click()
# You are now on the target page
# Where to store the scraped data
products = []
# Select all product elements on the page
product_elements = driver.find_elements(By.CSS_SELECTOR, "[role="listitem"][data-asin]")
# Iterate over them
for product_element in product_elements:
# Scraping logic
url_element = product_element.find_element(By.CSS_SELECTOR, ".a-link-normal")
url = url_element.get_attribute("href")
name_element = product_element.find_element(By.CSS_SELECTOR, "h2")
name = name_element.text
image_element = product_element.find_element(By.CSS_SELECTOR, "img[data-image-load]")
image = image_element.get_attribute("src")
# Populate a new object with the scraped data
product = {
"url": url,
"name": name,
"image": image
}
# Add it to the list of scraped products
products.append(product)
# Export data to a JSON file
with open("products.json", "w", encoding="utf-8") as json_file:
json.dump(products, json_file, indent=4)运行上面的 Amazon 电子商务爬虫工具,如果 Amazon 没有显示 CAPTCHA,它将生成以下结果:
[
{
"url": "https://www.amazon.com/A315-24P-R7VH-Display-Quad-Core-Processor-Graphics/dp/B0BS4BP8FB/ref=sr_1_3?crid=1W7R6D59KV9L1&dib=eyJ2IjoiMSJ9.iBCtzwnCm6CE8Bx8hKmQ8ez6PkzMg3asWNhAxvflBg3pKVi5IxQUSDpcaksihO-jEO1nyLGkdoGk_2hNyQ7EWOa6epS_hZHxqV7msqdtcEZv4irFZRnYHcP5YnEwKu17BjsYS_IPI1tFVDS65v_roSCu_IiBNfotAEHSx4zOwQ4u1CRKfvnLjIX4VlECydRjsKaAQ-mErT89tyBUCfEGjzKPPZxwHi3Y0MoieuPceL8.jIuIrqzxNYISYPLHifRJq289Vy9Z6hqT8vmMcUQw9HY&dib_tag=se&keywords=laptop&qid=1735572968&sprefix=l%2Caps%2C271&sr=8-3",
"name": "Acer Aspire 3 A315-24P-R7VH Slim Laptop | 15.6" Full HD IPS Display | AMD Ryzen 3 7320U Quad-Core Processor | AMD Radeon Graphics | 8GB LPDDR5 | 128GB NVMe SSD | Wi-Fi 6 | Windows 11 Home in S Mode",
"image": "https://m.media-amazon.com/images/I/61gKkYQn6lL._AC_UY218_.jpg"
},
// omitted for brevity...
{
"url": "https://www.amazon.com/Lenovo-Newest-Flagship-Chromebook-HubxcelAccesory/dp/B0CBJ46QZX/ref=sr_1_8?crid=1W7R6D59KV9L1&dib=eyJ2IjoiMSJ9.iBCtzwnCm6CE8Bx8hKmQ8ez6PkzMg3asWNhAxvflBg3pKVi5IxQUSDpcaksihO-jEO1nyLGkdoGk_2hNyQ7EWOa6epS_hZHxqV7msqdtcEZv4irFZRnYHcP5YnEwKu17BjsYS_IPI1tFVDS65v_roSCu_IiBNfotAEHSx4zOwQ4u1CRKfvnLjIX4VlECydRjsKaAQ-mErT89tyBUCfEGjzKPPZxwHi3Y0MoieuPceL8.jIuIrqzxNYISYPLHifRJq289Vy9Z6hqT8vmMcUQw9HY&dib_tag=se&keywords=laptop&qid=1735572968&sprefix=l%2Caps%2C271&sr=8-8",
"name": "Lenovo Newest Flagship Chromebook, 14'' FHD Touchscreen Slim Thin Light Laptop Computer, 8-Core MediaTek Kompanio 520 Processor, 4GB RAM, 64GB eMMC, WiFi 6,Chrome OS+HubxcelAccesory, Abyss Blue",
"image": "https://m.media-amazon.com/images/I/61KlKRdsQ7L._AC_UY218_.jpg"
}
]请注意,即使你通过 Selenium 发出请求,Amazon 仍可能显示 CAPTCHA 并阻止你的请求。在这种情况下,你应该查看 SeleniumBase 作为替代方案。否则,请继续阅读本文,因为我们将介绍一个最终解决方案。
如需全面演示,请查看我们关于 Amazon 网页抓取 的详细教程。
Walmart 抓取
- 目标页面:Walmart 上的“keyboard”搜索页面
- 目标页面 URL: https://www.walmart.com/search?q=keyboard
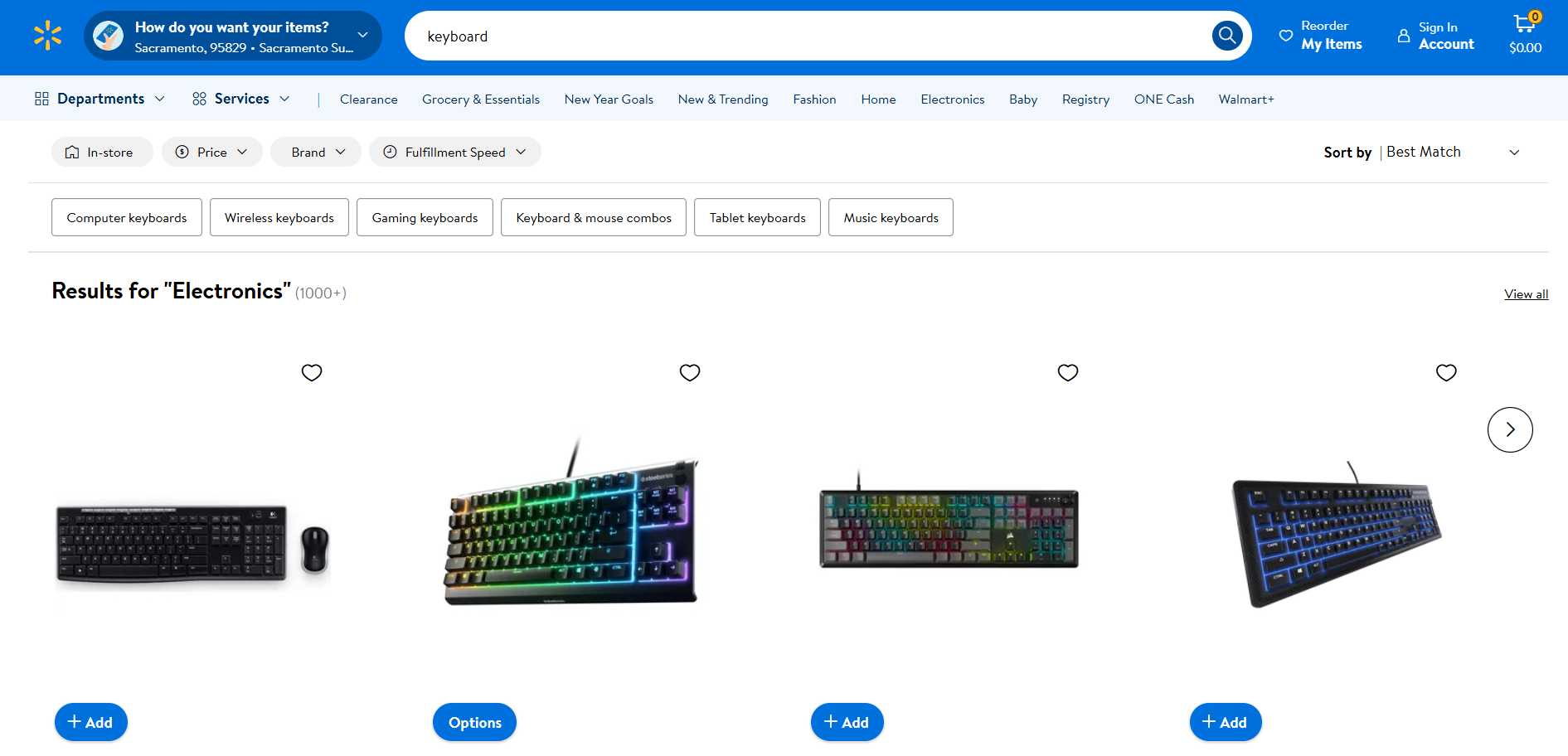
就像 Amazon 一样,Walmart 使用反机器人解决方案来阻止来自自动化 HTTP 客户端的请求。因此,你可以按如下方式使用 Selenium 抓取它:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
import json
# Initialize the WebDriver
driver = webdriver.Chrome(service=Service())
# Navigate to the target page
driver.get("https://www.walmart.com/search?q=keyboard")
# Where to store the scraped data
products = []
# Select all product elements on the page
product_elements = driver.find_elements(By.CSS_SELECTOR, ".carousel-4[data-testid="carousel-container"] li")
# Iterate over them
for product_element in product_elements:
# Scraping logic
url_element = product_element.find_element(By.CSS_SELECTOR, "a")
url = url_element.get_attribute("href")
name_element = product_element.find_element(By.CSS_SELECTOR, "h3")
name = name_element.get_attribute("innerText")
image_element = product_element.find_element(By.CSS_SELECTOR, "img[data-testid="productTileImage"]")
image = image_element.get_attribute("src")
# Populate a new object with the scraped data
product = {
"url": url,
"name": name,
"image": image
}
# Add it to the list of scraped products
products.append(product)
# Export data to a JSON file
with open("products.json", "w", encoding="utf-8") as json_file:
json.dump(products, json_file, indent=4)执行 Walmart 电子商务抓取工具,你将得到:
[
{
"url": "https://www.walmart.com/sp/track?bt=1&eventST=click&plmt=sp-search-middle~desktop~Results%20for%20%22Electronics%22&pos=1&tax=3944_1089430_132959_1008621_7197407&rdf=1&rd=https%3A%2F%2Fwww.walmart.com%2Fip%2FLogitech-920-004536-Mk270-Keyboard-Mouse-USB-Wireless-Combo-Black%2F28540111%3FclassType%3DREGULAR%26adsRedirect%3Dtrue&adUid=094fb4ae-62f3-4954-ae99-b2938550d72c&mloc=sp-search-middle&pltfm=desktop&pgId=keyboard&pt=search&spQs=sAX_0l4wzWXzBji34bVpmheXU7_ETXGbDXcA9LhcshG_YbqBx24VWzt7yesHivpt1lpckuNhxQqbLidA-d8L4agqx_YPQVlj2EfM_TnEyfsSWiTEkvBaqgkaMzy6bgIZ4eC8t9-qqz7qtb7uXMz3cH92UCf5EEgQlfKwnxJ-SAF1EW1ouCjC10Ur3hELs3143xQPjxNUSUoN8FIF12fxJmTlSlTe4makoj1s2NoubYTqnlJLs3pohowJCRFT76Vl&storeId=3081&couponState=na&bkt=ace1_default%7Cace2_default%7Cace3_default%7Ccoldstart_off%7Csearch_default&classType=REGULAR",
"name": "Logitech Wireless Combo MK270",
"image": "https://i5.walmartimages.com/seo/Logitech-920-004536-Mk270-Keyboard-Mouse-USB-Wireless-Combo-Black_99591453-341e-4c5b-937e-b2ab9b321519.3860011d84a23ccd0732e46474590b15.jpeg?odnHeight=784&odnWidth=580&odnBg=FFFFFF"
},
{
"url": "https://www.walmart.com/sp/track?bt=1&eventST=click&plmt=sp-search-middle~desktop~Results%20for%20%22Electronics%22&pos=2&tax=3944_1089430_132959_1008621_7197407&rdf=1&rd=https%3A%2F%2Fwww.walmart.com%2Fip%2FSteelSeries-Apex-3-TKL-RGB-Gaming-Keyboard-Tenkeyless-Water-Dust-Resistant-PC-and-USB-A%2F996783321%3FclassType%3DVARIANT%26adsRedirect%3Dtrue&adUid=094fb4ae-62f3-4954-ae99-b2938550d72c&mloc=sp-search-middle&pltfm=desktop&pgId=keyboard&pt=search&spQs=Dp3ons-xIcmPw9Ze7UUZuW3PD9Dto_vYCLjglme5vSy5Ze1p4NXg3uzApRy4mgfB-dGDchsq6FDoaZeMy6Dmeagqx_YPQVlj2EfM_TnEyfv_0r9GA9WwEd1cWbcx63Diahe72Zw6lw8suSf-OFKKH6UaiJl_8Qtpar-x0VhgrMsbqG7gDKh5DkQZql3HeMLncWSwburhSEjvpT1dXlDoWKxUrZwxZhOMry-uCqhuSb7Y6B-xZGrNPjYyel0nw11Z&storeId=3081&couponState=na&bkt=ace1_default%7Cace2_default%7Cace3_default%7Ccoldstart_off%7Csearch_default&classType=VARIANT",
"name": "SteelSeries Apex 3 TKL RGB Gaming Keyboard - Tenkeyless - Water & Dust Resistant - PC and USB-A",
"image": "https://i5.walmartimages.com/seo/SteelSeries-Apex-3-TKL-RGB-Gaming-Keyboard-Tenkeyless-Water-Dust-Resistant-PC-and-USB-A_876430c2-eed8-404a-aa55-1c66193daf8e.8c617e57ba48bc49d003f917f85cb535.jpeg?odnHeight=784&odnWidth=580&odnBg=FFFFFF"
},
// omittd for brevity...
{
"url": "https://www.walmart.com/ip/DEP-06-Portable-Digital-Piano-with-X-Stand/7598762909?classType=REGULAR",
"name": "Donner Portable Digital Piano 88-key Synth Action Keyboard with X Stand, Pedal, Auto-accompaniment for Beginner, 128 Tones, 83 Rhythms, Support USB/MIDI/Melodics, Wireless Connection",
"image": "https://i5.walmartimages.com/seo/DEP-06-Portable-Digital-Piano-with-X-Stand_1175fc1e-c191-4c71-9e9a-7e4a13274487.6673e0430c23d122744cfb63ccc8c155.jpeg?odnHeight=784&odnWidth=580&odnBg=FFFFFF"
}
]如需更多指导,请阅读我们关于 Walmart 网页抓取 的文章。
eBay 抓取
- 目标页面:eBay 上的“mouse”搜索页面
- 目标页面 URL: https://www.ebay.com/sch/i.html?_from=R40&_trksid=m570.l1313&_nkw=mouse&_sacat=0
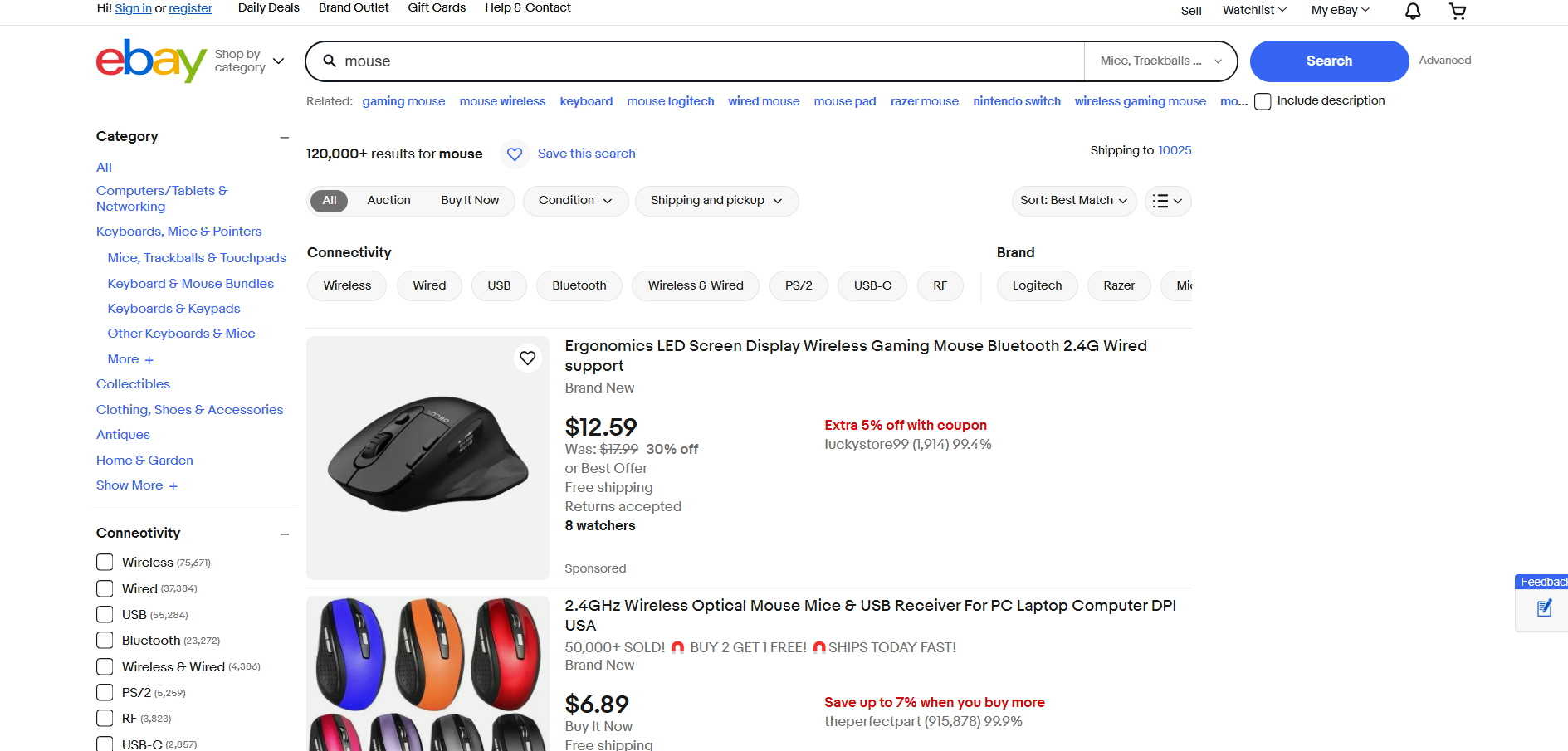
eBay 不使用 JavaScript 来渲染产品或动态加载数据。因此,可以按如下方式使用 Requests 和 Beautiful Soup 抓取它:
import requests
from bs4 import BeautifulSoup
import json
# Target page
url = "https://www.ebay.com/sch/i.html?_from=R40&_trksid=m570.l1313&_nkw=mouse&_sacat=0"
# Send a GET request to the eBay search page
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36"
}
response = requests.get(url, headers=headers)
# Parse the page content with BeautifulSoup
soup = BeautifulSoup(response.text, "html.parser")
# Where to store the scraped data
products = []
# Select all product elements on the page
product_elements = soup.select("li.s-item")
# Iterate over them
for product_element in product_elements:
# Scraping logic
url_element = product_element.select("a[data-interactions]")[0]
url = url_element["href"]
name_element = product_element.select("[role="heading"]")[0]
name = name_element.text
image_element = product_element.select("img")[0]
image = image_element["src"]
# Populate a new object with the scraped data
product = {
"url": url,
"name": name,
"image": image
}
# Add it to the list of scraped products
products.append(product)
# Export data to a JSON file
with open("products.json", "w", encoding="utf-8") as json_file:
json.dump(products, json_file, indent=4)启动 eBay 电子商务网页抓取脚本,它将产生:
[
{
"url": "https://www.ebay.com/itm/193168148815?_skw=mouse&itmmeta=01JGC679WKT327K11R9YCGMQAN&hash=item2cf9b8094f:g:8F4AAOSw3B1drMr-&itmprp=enc%3AAQAJAAAAwHoV3kP08IDx%2BKZ9MfhVJKlr8NKoodwElhyHbl4CwcBMRqdGJme95%2F3tIll4uI7QYBk4%2BUBpwVvwiXdAl2%2BcILZ9axc%2BdHSZStWWMxWVyq4JdZ6r52PrRP2aS1jUoFoJ11vL4KyH2S8R5ha71xBtDFcGA2%2BtzhTzcR7J25kxuxbyd%2Frd4YnKbTPKwhn2Q0TP8qL30BJKcj4FnJYP0zhgO4WOGgOCHQhM21%2BanVk%2Fl0eg1H8mqCU91mkgKAt8KghFmw%3D%3D%7Ctkp%3ABlBMULSenYaDZQ",
"name": "2.4GHz Wireless Optical Mouse Mice & USB Receiver For PC Laptop Computer DPI USA",
"image": "https://i.ebayimg.com/images/g/8F4AAOSw3B1drMr-/s-l500.webp"
},
{
"url": "https://www.ebay.com/itm/356159975164?_skw=mouse&itmmeta=01JGC679WKE9V782ZXT15SEPHP&hash=item52ecc9eefc:g:0ikAAOSwHStnD33Q&itmprp=enc%3AAQAJAAAAwHoV3kP08IDx%2BKZ9MfhVJKlZ7pO0lYrvftkZhnT7ja625fcsjcktK0eaub2HNzEgsmo3b2VehoA4tffYdt0xiTXwHb%2BzYU4NBZ5onBh68cyKWhhMJowbRvnCwuwy2IQIRlkeijpbRtJNJPuaaiDZdV0eabGGkps8433kCR6fcX1xEodUxujoeYUjp0VP81OWcl%2BbBGd70%2Fq45HC3SXg4k%2FlK0%2FqR80yJYexSEfzUq7%2BN3Sa6Y01uCo5XPWFLHzRoSw%3D%3D%7Ctkp%3ABlBMULSenYaDZQ",
"name": "Ergonomics LED Screen Display Wireless Gaming Mouse Bluetooth 2.4G Wired support",
"image": "https://i.ebayimg.com/images/g/0ikAAOSwHStnD33Q/s-l500.webp"
},
// omitted for brevity...
{
"url": "https://www.ebay.com/itm/116250548048?_skw=mouse&itmmeta=01JGC679WN076MJ17QJ9P4FA5J&hash=item1b11129750:g:gr8AAOSwsSFmkXG3&itmprp=enc%3AAQAJAAAAwHoV3kP08IDx%2BKZ9MfhVJKkArX38iC0VVXTpfv4BzqCegsh22yxmsDAwZAmd4RxM9JlEMfuVRoYGVZFVCeurJYwAjWd2YK3%2BNs6m5rQHZXISyWtev1lEvfVVKP4Rd5QeC2KzLgqXOvp1lWiK5b31kfujkmKjF%2BEaR1kplulwrgUvzMO%2F78F%2BFukgIAoL8dE4nRD9jo%2BieiAgIpLBUcs8AmCy5vk65gt1JGonUOncRksGYciF%2FJg6arB9%2FVOYYq7N8A%3D%3D%7Ctkp%3ABlBMULyenYaDZQ",
"name": "Razer x Sanrio Kuromi DeathAdder Gaming Mouse and Mouse Pad Combo",
"image": "https://i.ebayimg.com/images/g/gr8AAOSwsSFmkXG3/s-l500.webp"
}
]太棒了!你刚刚看到了几个 Python 电子商务数据抓取脚本示例!
电子商务网页抓取中的挑战以及如何克服它们
在上面的示例中,我们重点从几个电子商务网站提取产品名称、URL 和图片 URL 等基本详情。虽然这种简单性让电子商务抓取看起来很直接,但现实由于几个原因要复杂得多:
- 动态页面结构:电子商务平台经常更新其页面设计,需要持续维护脚本。
- 多样化的产品页面:不同产品可能显示不同的数据集,并使用完全不同的布局。
- 动态定价:由于临时优惠、折扣或特定区域报价,抓取准确的价格数据可能具有挑战性。
此外,像 Amazon 这样的主要电子商务网站采用高级反爬虫措施,例如 CAPTCHA:
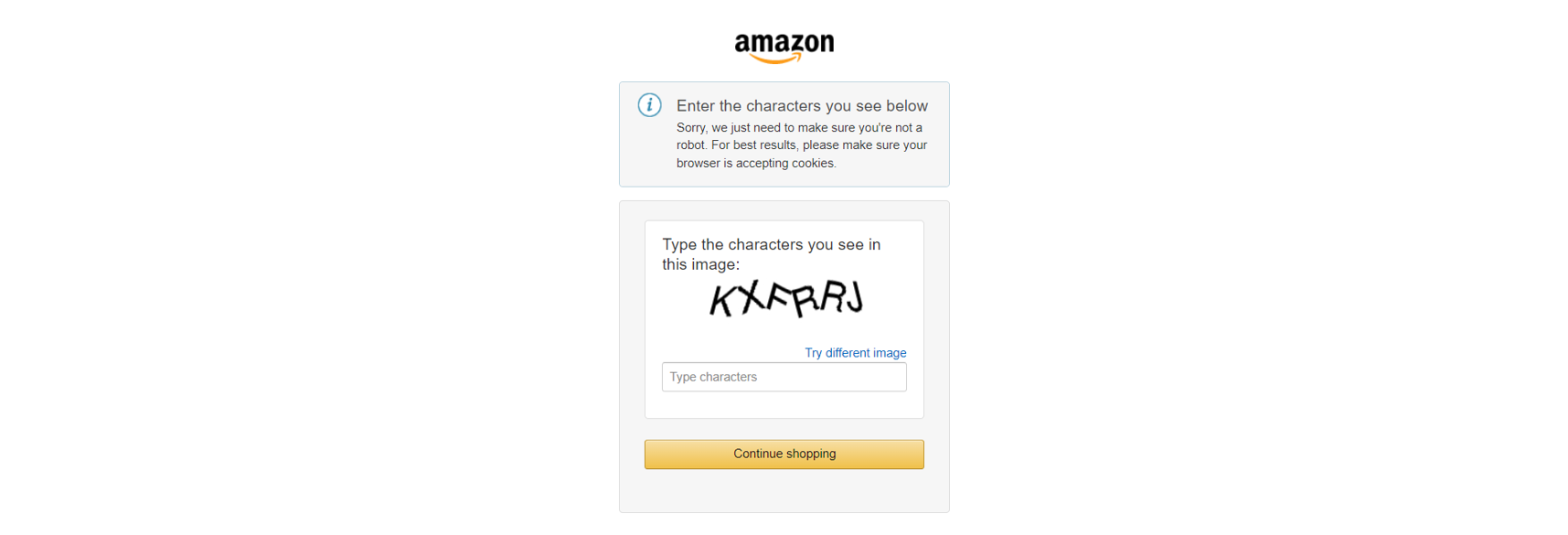
或者,类似地, JavaScript 挑战:

要克服这些阻止,你可以:
- 学习高级爬虫技术:阅读我们关于 使用 Python 绕过 CAPTCHA 的指南,并查看深入的爬虫教程以获取实用技巧。
- 使用高级自动化工具:利用像 Playwright Stealth 这样强大的工具来爬虫带有反机器人机制的网站。
不过,最高效的解决方案是使用专用的 电子商务爬虫 API。
Bright Data 的电子商务爬虫工具 API 是一个可靠的解决方案,用于从 Amazon、Target、Walmart、Lazada、Shein、Shopee 等电子商务平台提取数据。主要优势包括:
- 检索结构化详情,例如产品标题、卖家名称、品牌、描述、评论、初始价格、货币、可用性、类别等。
- 消除关于管理服务器、代理或避免网站阻止的顾虑。
- 避免 CAPTCHA 或 JavaScript 挑战造成的中断。
立即简化你的电子商务爬虫流程!
结论
在本文中,你了解了什么是电子商务爬虫工具,以及它可以从电子商务网页提取的数据类型。无论你的电子商务网页爬虫脚本多么复杂,大多数网站仍然可以检测到自动化活动并阻止你。
解决方案是一个功能强大的电子商务爬虫工具 API,专门设计用于从各种平台可靠地检索电子商务数据。这些 API 提供结构化且全面的数据,包括:
- Amazon 爬虫 API:爬虫 Amazon 并收集标题、卖家名称、品牌、描述、评论、初始价格、货币、可用性、类别、ASIN、卖家数量等数据。
- eBay 爬虫工具 API:收集 ASIN、卖家名称、商家 ID、URL、图片 URL、品牌、产品概览、描述、尺寸、颜色、最终价格等数据。
- Walmart 爬虫工具 API:收集 URL、SKU、价格、图片 URL、相关页面、是否可配送和自提、品牌、类别、产品 ID 和描述等数据。
- Target 爬虫 API:收集 URL、产品 ID、标题、描述、评分、评论数量、价格、折扣、货币、图片、卖家名称、优惠、配送政策等数据。
- Lazada 爬虫 API:爬虫 URL、标题、评分、评论、初始和最终价格、货币、图片、卖家名称、产品描述、SKU、颜色、促销、品牌等数据。
- Shein 爬虫工具 API:检索产品名称、描述、价格、货币、颜色、是否有库存、尺寸、评论数量、主图、国家/地区代码、域名等数据。
- Shopee 爬虫工具 API:爬虫 URL、ID、标题、评分、评论、价格、货币、库存、收藏、图片、店铺 URL、评分、加入日期、关注者、已售、品牌等数据。
对于从特定产品爬虫数据,请考虑我们的 网页爬虫工具 API。如果构建爬虫工具不是你的强项,请探索我们的 即用型电子商务数据集。
立即创建免费的 Bright Data 账户,试用我们的爬虫 API 或探索我们的数据集。



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




