

传统的 网络爬虫(web scraping) 通常需要针对特定网站结构编写复杂且耗时的代码,当网站结构发生变化时,这些代码往往会失效。 ScrapeGraphAI 利用大型语言模型(LLM)来像人类一样提取并理解信息,让你将精力集中在数据本身,而不是网站布局上。通过将 LLM 与 ScrapeGraphAI 相结合,你可以增强数据提取能力,实现内容聚合自动化并进行实时分析。
在本文中,你将学习如何使用 ScrapeGraphAI 进行网络爬虫。在此之前,让我们先介绍 Bright Data 的解决方案,帮助你节省时间和成本。
Bright Data 的网络爬虫解决方案
Bright Data 提供了全面的网络爬虫解决方案,旨在高效、可扩展且合规地进行数据提取:
- Web Scraper API:一个稳定的 API,可自动从多个流行网站中提取结构化数据,即使面对动态内容、JavaScript 和 CAPTCHA 这类复杂元素也毫无压力。它利用内置的代理管理和轮换功能来保证可扩展性,避免 IP 被阻,同时保持高请求成功率,非常适合大规模自动化数据采集。
- Ready-to-Use Datasets:即时访问从主流网站中采集的海量预先收集数据集,并持续更新以确保准确性和时效性。使用这些数据集可以省去定制爬虫的成本和时间,快速获得高质量数据。
- Custom Datasets:如果有特定需求,Bright Data 提供可定制的数据采集服务。无论你需要实时数据、历史记录或从小众网站采集数据,这些定制数据集都能灵活调整并精确获取你所需的数据点。该定制数据集可以由你自己管理,也可由 Bright Data 代为管理。
这些解决方案能够快速、准确且可扩展地采集数据,无论项目规模大小,都能满足需求。
一体化爬虫解决方案
借助 Bright Data 功能强大的爬虫工具和现成数据集,轻松提取网络数据。
使用 ScrapeGraphAI 实现 LLM 网络爬虫
在开始该教程之前,你需要满足以下条件:
- 已安装 Python 3.x。
- 拥有 OpenAI 帐号。本教程使用 OpenAI 的 LLM 来配合 ScrapeGraphAI 进行数据爬取。尽管也可以使用其他模型(如 Anthropic、Google或开源模型 Llama、Mistral AI 等),但本教程使用 GPT-4 是因为它流行且易于设置。
如果你不熟悉 Python 进行网络爬虫,可以参考这篇 Python 网络爬虫教程 开始学习。
环境搭建
首先,你需要创建一个虚拟环境。打开终端并导航到你的项目目录:
python -m venv venv然后,激活该虚拟环境。macOS 和 Linux 系统可以使用以下命令:
source venv/bin/activateWindows 系统则使用:
venv\Scripts\activate在激活虚拟环境后,你需要安装 ScrapeGraphAI 及其依赖:
pip install scrapegraphai
playwright installplaywright install 命令会为 Chromium、Firefox 和 WebKit 安装所需的浏览器。
要安全地管理环境变量,可以安装 python-dotenv:
pip install python-dotenv保护敏感信息(如 API 密钥)很重要,推荐将环境变量存放在独立的 .env 文件中。
在项目目录中创建一个名为 .env 的新文件,并在其中添加以下内容来指定你的 OpenAI 密钥:
OPENAI_API_KEY="your-openai-api-key"该文件不应被提交到版本控制系统中。请在 .gitignore 文件中添加 .env,以保证其不会被上传到仓库。
使用 ScrapeGraphAI 进行数据爬取
在本教程中,你将从 Books to Scrape 爬取产品数据,这个示例网站专门用于练习网络爬虫技术。它模拟了一个在线书店,提供不同类型的图书、价格、评级和库存状态等信息:
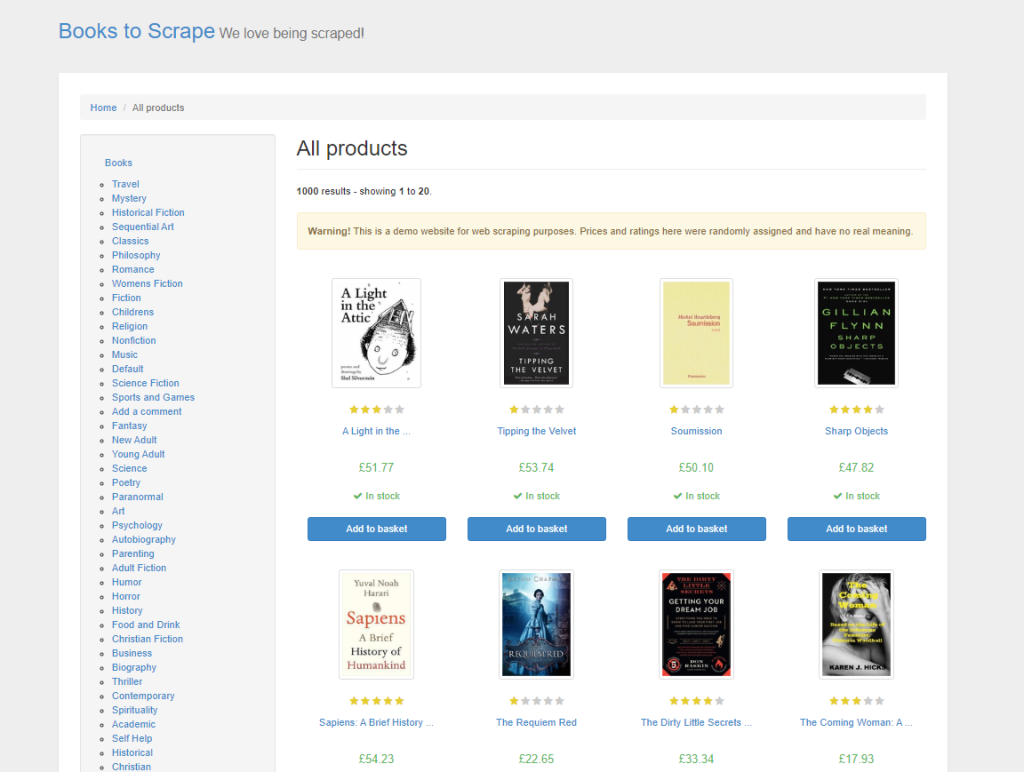
在 传统 HTML 网络爬虫中,你需要分析页面的 HTML,手动检查元素和标签,以找到想要抓取的数据。这不仅耗时,还需要对网页结构有深入了解。使用 ScrapeGraphAI,只需在提示中说明需要提取的数据内容,LLM 会智能地完成提取。
ScrapeGraphAI 提供了不同类型的 “Graph” 来处理不同的爬取需求。这些 Graph 定义了爬取流程的结构以及目标。例如:
- SmartScraperGraph:适用于单页面爬取。只需提供提示和一个 URL(或本地文件),它就能利用 LLM 提取指定信息。
- SearchGraph:适用于多页面爬取,从搜索引擎结果中提取与你的提示相关的信息。
- SpeechGraph:SmartScraperGraph 的扩展版本,加入了文本转语音功能,可生成所提取内容的音频文件。
- ScriptCreatorGraph:基于给定的提示和 URL,生成可用于爬取该 URL 的 Python 脚本,而非直接返回结果。
如果这些 Graph 类型都无法满足需求,你还可以自定义 Graph,通过组合不同的节点来灵活地定制爬虫流程。
除选择合适的 Graph 类型外,爬虫配置也很重要,尤其是提示和模型的选择。提示会告诉 LLM 你想提取什么数据,要确保提示清晰明确。选择合适的 LLM 模型会影响爬虫对网页内容的处理和理解能力。你还可以配置其他选项,比如代理(proxy),用来爬取受地理限制的内容;或使用无头模式(headless mode)来提升效率。合理的配置最终决定了数据提取的准确性和相关性。
相关阅读:如何使用 AI 进行网络爬虫
编写爬虫代码
新建一个名为 app.py 的文件,并写入以下代码:
from dotenv import load_dotenv
import os
from scrapegraphai.graphs import SmartScraperGraph
# Load environment variables from .env file
load_dotenv()
# Access the OpenAI API key
OPENAI_API_KEY = os.getenv('OPENAI_API_KEY')
# Configuration for ScrapeGraphAI
graph_config = {
"llm": {
"api_key": OPENAI_API_KEY,
"model": "openai/gpt-4o-mini",
}
}
# Define the prompt and source
prompt = "Extract the title, price and availability of all books on this page."
source = "http://books.toscrape.com/"
# Create the scraper graph
smart_scraper_graph = SmartScraperGraph(
prompt=prompt,
source=source,
config=graph_config
)
# Run the scraper
result = smart_scraper_graph.run()
# Output the results
print(result)上述代码导入了处理环境变量的 os、dotenv 模块,以及 ScrapeGraphAI 提供的 SmartScraperGraph 类。然后通过 dotenv 加载环境变量,保证像 API 密钥此类敏感信息的安全。接着,代码基于指定的模型和密钥构建了 LLM 配置。通过给出网站 URL 和爬取数据的提示内容,定义了一个 SmartScraperGraph,并在 run() 方法执行后收集到所需数据。
在终端中运行 python app.py,你会看到如下输出:
{
"books": [
{
"title": "A Light in the Attic",
"price": "£51.77",
"availability": "In stock"
},
{
"title": "Tipping the Velvet",
"price": "£53.74",
"availability": "In stock"
}, ...
]
}注意: 如果在运行代码时遇到问题,你可能需要手动安装
grpcio,这是 ScrapeGraphAI 的底层依赖。可通过以下命令安装:
pip install grpcio虽然 ScrapeGraphAI 简化了数据提取,本质上网络爬虫仍可能面临一些常见挑战,例如遇到 CAPTCHA 或 IP 被封等。
为了模拟真实用户浏览行为,你可以在代码中引入适当的延时。也可以使用轮换代理来避免被检测。此外,你还可以整合 Bright Data 的 CAPTCHA 破解服务或 Anti Captcha 等服务,实现自动化地处理 CAPTCHA。
请注意:在进行网络爬虫时一定要遵守相关网站的服务条款。个人用途通常没问题,但如果要重新分发数据,可能会涉及法律问题。
自动化解决 CAPTCHA
使用 CAPTCHA Solver 的先进 AI 逻辑自动绕过验证码。
在 ScrapeGraphAI 中使用代理
ScrapeGraphAI 支持配置代理服务来避免 IP 被封并访问地理限制内容。你可以 使用免费代理服务或配置自己的自定义代理。
如果要使用免费代理服务,只需在 graph_config 中添加以下内容:
graph_config = {
"llm": {
"api_key": OPENAI_API_KEY,
"model": "openai/gpt-4o-mini",
},
"loader_kwargs": {
"proxy": {
"server": "broker",
"criteria": {
"anonymous": True,
"secure": True,
"countryset": {"US"},
"timeout": 10.0,
"max_tries": 3
},
},
}
}以上配置会告诉 ScrapeGraphAI 使用符合你设定条件的免费代理服务。
若想使用像 Bright Data 提供的自定义代理服务器,只需在 graph_config 中更改为以下方式,并填入你的代理服务器地址、用户名和密码:
graph_config = {
"llm": {
"api_key": OPENAI_API_KEY,
"model": "openai/gpt-4o-mini",
},
"loader_kwargs": {
"proxy": {
"server": "http://your_proxy_server:port",
"username": "your_username",
"password": "your_password",
},
}
}
使用自定义代理服务器对大规模网络爬虫更为有利,因为你可以选择代理的地理位置,从而爬取受地域限制的内容;同时自定义代理比免费代理更可靠和安全,也更少出现 IP 被封或限速等问题。
» 进一步了解什么是代理服务器以及如何选择服务商。
清洗并准备数据
在完成数据爬取后,如果计划将数据用于 AI 模型的训练或推理,则需要对数据进行清洗和预处理。干净的数据能确保模型学习到准确、一致的信息,这对于模型的性能和可靠性尤为重要。常见的数据清洗步骤包括处理缺失值、更正数据类型、规范化文本以及去除重复项。
下面是一个使用 pandas 清洗先前爬取数据的示例:
import pandas as pd
# Convert the result to a DataFrame
df = pd.DataFrame(result["books"])
# Remove currency symbols and convert prices to float
df['price'] = df['price'].str.replace('£', '').astype(float)
# Standardize availability text
df['availability'] = df['availability'].str.strip().str.lower()
# Handle missing values if any
df.dropna(inplace=True)
# Preview the cleaned data
print(df.head())这段代码通过去除价格中的货币符号,将库存状态文本转换成小写,来对数据进行清洗,并且处理了可能存在的缺失值。
在运行代码之前,你需要安装 pandas:
pip install pandas然后在终端执行 python app.py,示例结果如下:
title price availability
0 A Light in the Attic 51.77 in stock
1 Tipping the Velvet 53.74 in stock
2 Soumission 50.10 in stock
3 Sharp Objects 47.82 in stock
4 Sapiens: A Brief History of Humankind 54.23 in stock如何清洗数据需要根据具体需求而定,尤其在为 LLM 训练或推理做准备时,必须保证输入数据结构合理、含义清晰。若想了解更多如何将数据应用于 AI 项目,请参阅 数据与 AI的资料。
本教程的全部代码可在 此 GitHub 仓库中找到。
无障碍爬取,避免被发现
处理 Cookie,自动解决 CAPTCHA,并模拟真实用户流量来获取所需数据。
总结
ScrapeGraphAI 通过 LLM 提供了一种自适应的网络爬虫方式,能随网站结构变化而灵活应对并智能提取数据。然而,当你需要扩展网络爬虫规模时,往往会遇到 IP 封禁、验证码以及合规的问题。
为帮助解决这些问题,Bright Data 提供了全面的 AI 和机器学习场景下的网络爬虫解决方案,包括 Bright Data 的 Web Scraper APIs、代理服务、以及 无服务器爬取(Serverless Scraping)。此外,Bright Data 还提供来自上百家热门网站的现成数据集。
立即开始免费试用吧!



