
如果你对网络爬虫感兴趣,那么了解HTML是关键,因为每个网站都是用HTML构建的。网络爬虫可以用于各种场景,帮助你从没有API的网站收集数据,监控产品价格,构建潜在客户名单,进行学术研究等等。
在本文中,你将学习HTML的基础知识,以及如何使用Python提取、解析和处理数据。
对深入的Python网络爬虫指南感兴趣吗?点击这里。
如何爬取网站并提取HTML
在开始本教程之前,让我们先回顾一下HTML的基本组成部分。
HTML简介
HTML是一组告诉浏览器关于网站结构和元素的标签。例如,<h1> 文字 </h1>告诉浏览器该标签后的文字是标题,而<a href=""> 链接 </a>标识了一个超链接。
HTML属性为标签提供了额外的信息。例如,<a> </a>标签中的href属性告诉你该属性指向的页面的URL。
类和ID是准确识别页面元素的重要属性。类将相似的元素分组,以便使用CSS统一样式或用JavaScript统一操作。类通过.class-name来定位。
在W3Schools网站上,类组如下所示:
<div class="city">
<h2>London</h2>
<p>London is the capital of England.</p>
</div>
<div class="city">
<h2>Paris</h2>
<p>Paris is the capital of France.</p>
</div>
<div class="city">
<h2>Tokyo</h2>
<p>Tokyo is the capital of Japan.</p>
</div>你可以看到每个标题和城市块都被一个具有相同city类的div包裹着。
相比之下,ID对每个元素都是唯一的(即两个元素不能有相同的ID)。例如,以下的H1标签具有唯一的ID,可以被唯一地样式化或操作:
<h1 id="header1">Hello World!</h1>
<h1 id="header2">Lorem Ipsum Dolor</h1>使用ID定位元素的语法是#id-name。
现在你已经了解了HTML的基础知识,让我们开始进行网络爬虫。
设置你的爬虫环境
本教程使用Python,因为它提供了许多HTML爬虫库,而且语言易于学习。要检查你的计算机上是否安装了Python,请在PowerShell(Windows)或终端(macOS)中运行以下命令:
python3如果安装了Python,你将看到你的版本号;如果没有,你将收到错误信息。如果你尚未安装,请安装Python。
接下来,创建一个名为WebScraper的文件夹,并在WebScraper文件夹内创建一个名为scraper.py的文件。然后在你选择的集成开发环境(IDE)中打开它。这里使用Visual Studio Code:
IDE是一种多功能应用程序,允许程序员编写代码、调试、测试程序、构建自动化等。在这里,你将使用它来编写你的HTML爬虫。
接下来,你需要通过创建一个虚拟环境来将全局Python安装与爬虫项目分开。这有助于避免依赖冲突,并使整个应用程序井然有序。
为此,使用以下命令安装virtualenv库:
pip3 install virtualenv导航到你的项目文件夹:
cd WebScraper然后创建一个虚拟环境:
python<version> -m venv <virtual-environment-name>此命令在你的项目文件夹内创建一个包含所有包和脚本的文件夹:
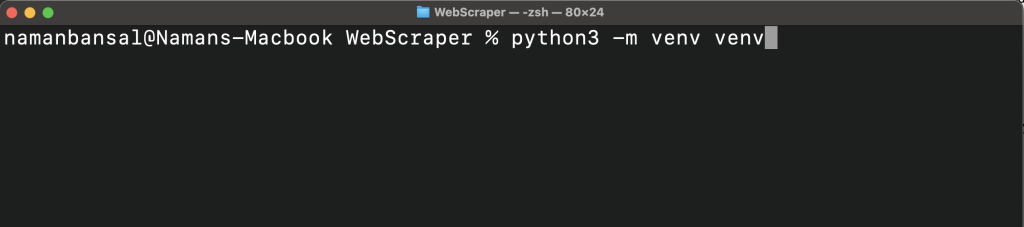
现在,你需要使用以下命令之一(基于你的平台)激活虚拟环境:
source <virtual-environment-name>/bin/activate #In MacOS and Linux
<virtual-environment-name>/Scripts/activate.bat #In CMD
<virtual-environment-name>/Scripts/Activate.ps1 #In Powershell成功激活后,你将在屏幕左侧看到虚拟环境的名称:
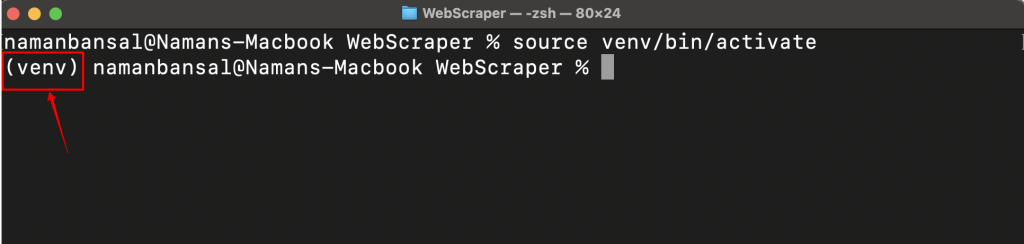
现在你的虚拟环境已经激活,你需要安装一个网络爬虫库。有许多选项,包括Playwright、Selenium、Beautiful Soup和Scrapy。在这里,你将使用Playwright,因为它易于使用,支持多种浏览器,能够处理动态内容,并提供无头模式(无图形用户界面(GUI)的爬取)。
运行pip install pytest-playwright来安装Playwright;然后使用playwright install安装所需的浏览器。
安装Playwright后,你就可以开始网络爬虫了。
从网站提取HTML
任何网络爬虫项目的第一步是确定你要爬取的网站。在这里,你将使用这个测试站点。
接下来,你需要确定要从页面中爬取的信息。在本例中,是页面的全部HTML内容。
一旦确定了要爬取的信息,你就可以开始编写爬虫程序了。在Python中,第一步是导入Playwright所需的库。Playwright允许你导入两种类型的API:同步和异步库。在编写异步代码时使用异步库,因此你需要使用以下命令导入同步库:
from playwright.sync_api import sync_playwright导入同步库后,你需要使用以下代码片段声明一个Python函数:
def main():
#Rest of the code will be inside this function如上所述,你将把你的网络爬虫代码写在此函数内。
通常,要从网站获取信息,你需要打开一个浏览器,创建一个新标签页,并访问该网站。要爬取该站点,你需要将这些操作转换为代码,这就是你将使用Playwright的地方。他们的文档显示,你可以调用之前导入的sync_api并使用以下代码片段打开一个浏览器:
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)通过在括号内添加headless=False,你可以看到网站的内容。
打开浏览器后,打开一个新标签页并访问目标URL:
page = browser.new_page()
try:
page.goto("https://webscraper.io/test-sites/e-commerce/static")
except:
print("Error")注意:前面的几行代码需要添加在启动浏览器的代码后。所有这些代码都放在main函数内和一个文件中。
此代码片段将goto()函数包装在一个try-except块中,以实现更好的错误处理。
当你在搜索栏中输入站点的URL时,你需要等待它加载。为了在代码中模拟这一点,你可以使用以下代码:
page.wait_for_timeout(7000) #括号中的值是毫秒注意:前面的几行代码需要添加在启动浏览器的代码后。
最后,使用以下代码行从页面提取所有HTML内容:
print(page.content())完整的代码如下所示:
from playwright.sync_api import sync_playwright
def main():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
try:
page.goto("https://webscraper.io/test-sites/e-commerce/static")
except:
print("Error")
page.wait_for_timeout(7000)
print(page.content())
main()在Visual Studio Code中,提取的HTML如下所示:
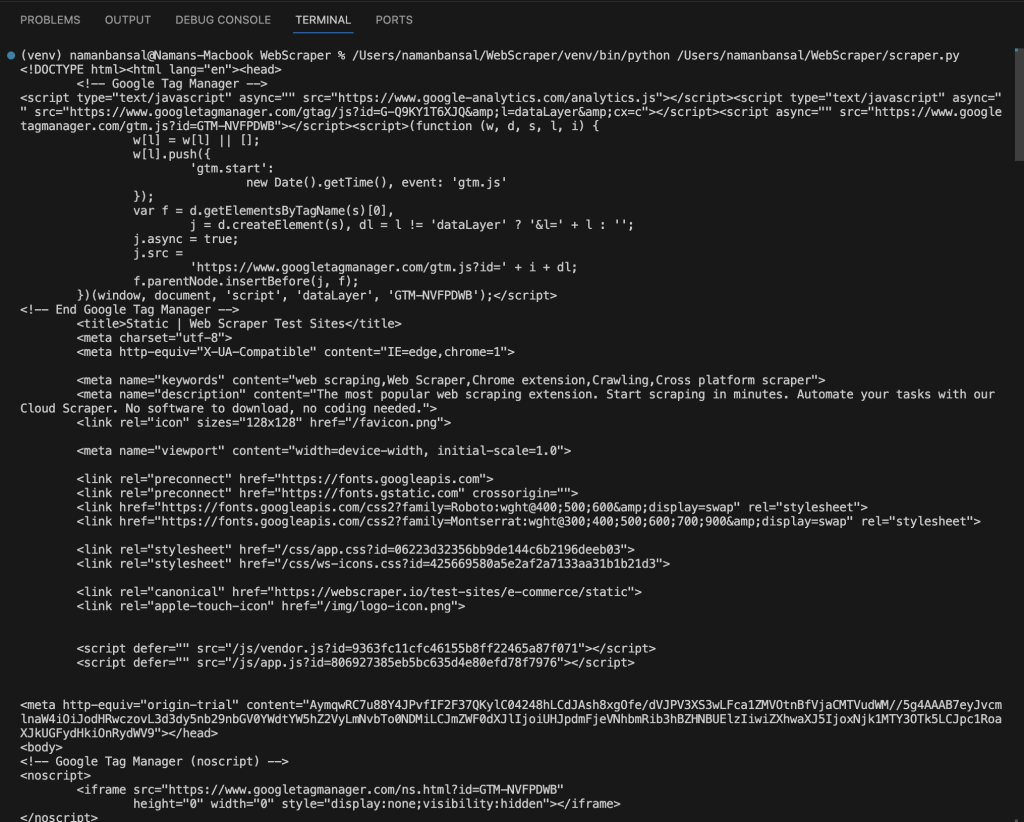
使用特定属性提取HTML
前面你提取了Web Scraper网页的所有元素;然而,如果你不限制自己只爬取所需的信息,网络爬虫是没有用的。在本节中,你将只提取网站首页上所有笔记本电脑的标题:
要提取特定元素,你需要了解目标网站的结构。你可以右键单击并选择检查选项来查看:
或者,你可以使用以下快捷键:
- 对于macOS,使用Cmd + Option + I
- 对于Windows,使用Control + Shift + C
这是目标页面的结构:
你可以使用检查窗口左上角的选择工具查看页面上特定项目的代码:

选择检查窗口中的一个笔记本电脑标题:
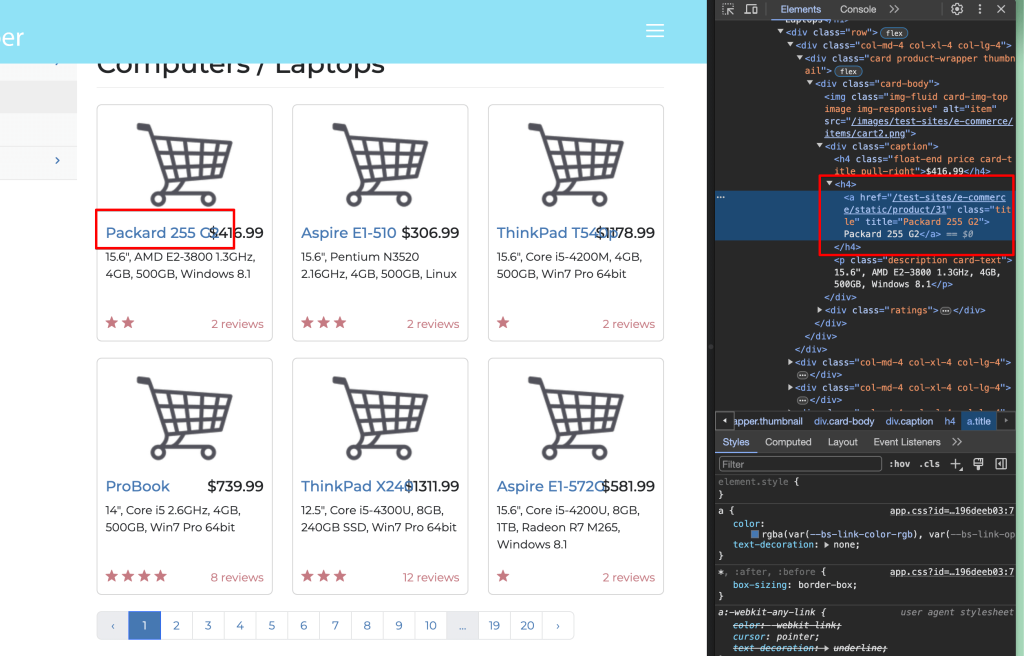
你可以看到标题在一个<a> </a>标签内,该标签被一个h4标签包裹,并且链接具有title类。这意味着你正在寻找具有title类的<h4>标签中的<a href>标签(URL)。
为了创建一个准确定位这些元素的爬虫程序,你需要导入库,创建一个Python函数,启动浏览器,并导航到目标网站:
from playwright.sync_api import sync_playwright
def main():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
try:
page.goto("https://webscraper.io/test-sites/e-commerce/static/computers/laptops")
except:
print("Error")
page.wait_for_timeout(7000)请注意,page.goto()函数内的目标URL已更新为指向包含笔记本电脑列表的第一页。
一旦创建了爬虫程序,你需要根据网站结构分析来定位目标元素。Playwright有一个名为定位器的工具,可以根据各种属性定位页面上的元素,例如:
get_by_label():使用与元素关联的标签定位目标元素。get_by_text():使用元素包含的文本定位目标元素。get_by_alt_text():使用图片的alt文本定位目标元素并对其执行操作。get_by_test_id():使用元素的测试ID定位目标元素。
你可以参考官方文档,了解更多定位元素的方法。
要爬取所有笔记本电脑标题,你需要定位所有包含笔记本电脑标题的<h4>标签。你可以使用get_by_role()定位器来根据功能定位元素,例如按钮、复选框和标题。这意味着要在页面上查找所有标题,你需要编写以下代码:
titles = page.get_by_role("heading").all()然后,你可以使用以下代码将其打印到控制台:
print(titles)打印后,你会注意到它给出了一个元素数组:
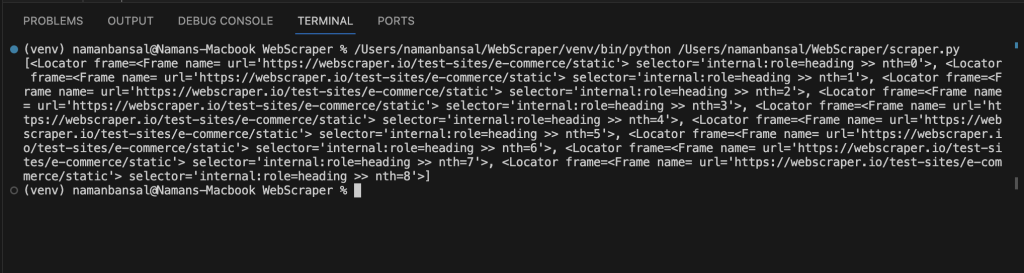
此输出不包括标题,但它确实引用了与选择器条件匹配的元素。你必须遍历这些元素,查找具有title类的<a>标签及其内部文本。
建议使用CSS定位器来根据路径和类查找元素,并可以使用all_inner_texts()函数提取元素的内部文本,如下所示:
for title in titles:
laptop = title.locator("a.title").all_inner_texts()运行此代码后,你的输出应如下所示:
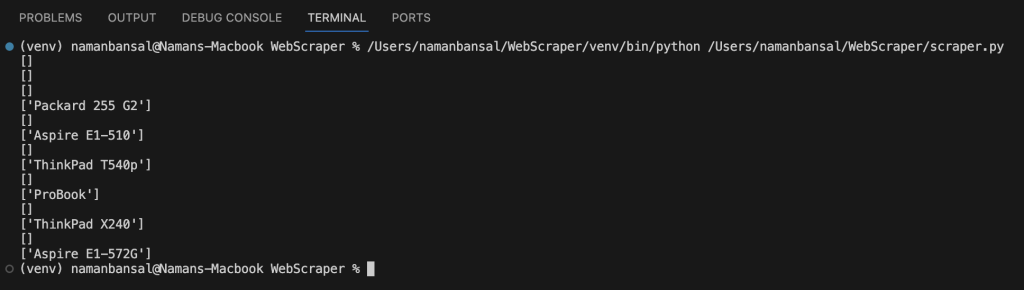
要排除没有值的数组,请编写以下代码:
if len(laptop) == 1:
print(laptop[0])一旦排除了没有值的数组,你就成功构建了一个只提取特定元素的爬虫程序。
以下是该爬虫的完整代码:
from playwright.sync_api import sync_playwright
def main():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
try:
page.goto("https://webscraper.io/test-sites/e-commerce/static/computers/laptops")
except:
print("Error")
page.wait_for_timeout(7000)
titles = page.get_by_role("heading").all()
for title in titles:
laptop = title.locator("a.title").all_inner_texts()
if len(laptop) == 1:
print(laptop[0])
main()与元素互动
现在让我们提升一下,构建一个程序,从包含笔记本电脑的第一页提取标题,导航到第二页,并提取这些标题。
由于你已经知道如何从页面提取标题,因此只需弄清楚如何导航到笔记本电脑的下一页即可。
你可能已经注意到当前页面上的分页按钮。
你必须使用爬虫程序找到2并点击它。检查页面后,你会看到所需的元素是一个列表元素(<li>标签),并且内部文本为2:
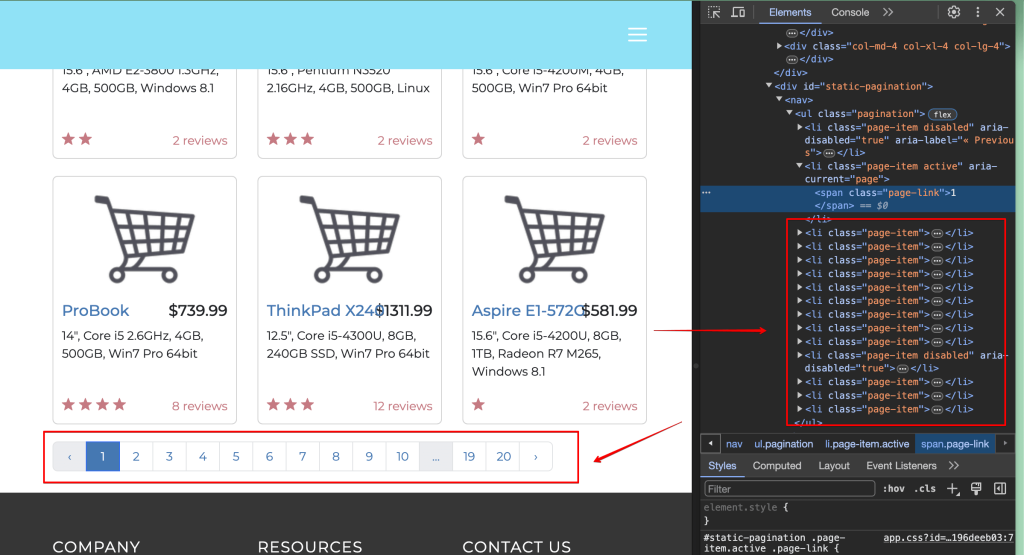
这意味着你可以使用get_by_role()选择器找到列表项,使用get_by_text()选择器找到文本为2的元素。
在文件中编写如下代码:
page.get_by_role("listitem").get_by_text("2", exact=True)这将找到满足两个条件的元素:首先,它必须是一个列表项;其次,它应该有2的文本。
exact=True是一个函数参数,用于查找具有给定文本的元素。
要点击按钮,请修改之前的代码,使其如下所示:
page.get_by_role("listitem").get_by_text("2", exact=True).click()在此代码中,click()函数点击给定的元素。
等待页面加载并再次提取所有标题:
page.wait_for_timeout(5000)
titles = page.get_by_role("heading").all()
for title in titles:
laptop = title.locator("a.title").all_inner_texts()
if len(laptop) == 1:
print(laptop[0])你的完整代码块应如下所示:
from playwright.sync_api import sync_playwright
def main():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
try:
page.goto("https://webscraper.io/test-sites/e-commerce/static/computers/laptops")
except:
print("Error")
page.wait_for_timeout(7000)
titles = page.get_by_role("heading").all()
for title in titles:
laptop = title.locator("a.title").all_inner_texts()
if len(laptop) == 1:
print(laptop[0])
page.get_by_role("listitem").get_by_text("2", exact=True).click()
page.wait_for_timeout(5000)
titles = page.get_by_role("heading").all()
for title in titles:
laptop = title.locator("a.title").all_inner_texts()
if len(laptop) == 1:
print(laptop[0])
main()提取HTML并将其写入CSV文件
如果你不存储和分析爬取的数据,它是没有用的。在本节中,你将创建一个高级程序,该程序接受用户输入爬取笔记本电脑的页数,提取标题,并将其存储在项目文件夹中的CSV文件中。
对于此程序,你需要预先安装CSV库,可以使用以下命令导入:
import csv安装CSV库后,你需要弄清楚如何根据用户的输入访问可变数量的页面。
如果查看网站的URL结构,你会注意到每个笔记本电脑页面都由URL参数表示。例如,笔记本电脑目录中第二页的URL是https://webscraper.io/test-sites/e-commerce/static/computers/laptops?page=2。
你可以通过更改URL参数?page=2的数值访问不同的页面。这意味着你需要使用以下命令询问用户要爬取的页面数:
pages = int(input("输入要爬取的页数:"))要从1到用户输入的页数访问每个页面,你可以使用for循环,如下所示:
for i in range(1, pages+1):在此range函数中,你使用1和pages+1作为函数参数来表示循环的开始和结束值。第二个函数参数被排除在循环之外。例如,如果range函数是range(1,5),则程序只会从1循环到4。
接下来,你需要通过在迭代中输入i值作为URL参数来访问每个页面。你可以使用Python f-strings将变量添加到字符串中。
在输出字符串时,你可以在引号前加上f,以表示它是一个f-string。在引号内,你可以使用花括号来表示变量。
以下是如何使用f-strings打印变量和字符串的示例:
print(f"变量的值是{variable_name_goes_here}")回到爬虫程序,你可以通过在文件中编写此代码块来利用f-strings:
try:
page.goto(f"https://webscraper.io/test-sites/e-commerce/static/computers/laptops?page={i}")
except:
print("Error")使用超时函数等待页面加载,并提取标题:
page.wait_for_timeout(7000)
titles = page.get_by_role("heading").all()一旦拥有所有标题元素,你需要打开CSV文件,遍历每个标题,提取所需的文本,并将其写入文件中。
要打开CSV文件,请使用以下语法:
with open("laptops.csv", "a") as csvfile:在这里,你以追加模式(a)打开laptops.csv文件。你在此处使用追加模式,因为你不希望每次打开文件时丢失旧数据。如果 文件不存在,库会在项目文件夹中创建一个文件。CSV提供了几种模式供你打开文件,包括:
- r是默认选项,如果未指定任何选项,它将以只读模式打开文件。
- w仅用于写入文件。每次打开文件时,之前的数据都会被覆盖。
- a用于追加数据,不会覆盖之前的数据。
- r+用于读取和写入文件。
- x创建一个新文件。
在之前的代码下,你需要声明一个writer对象,允许你操作CSV文件:
writer = csv.writer(csvfile)接下来,遍历每个标题元素,并使用以下代码提取文本:
for title in titles:
laptop = title.locator("a.title").all_inner_texts()这将为你提供多个数组,每个数组包含单个笔记本电脑的标题。要排除空数组,请将以下条件代码写入CSV文件:
if len(laptop) == 1:
writer.writerow([laptop[0]])writerow函数允许你在CSV文件中写入新行。
以下是程序的完整代码:
from playwright.sync_api import sync_playwright
import csv
def main():
with sync_playwright() as p:
browser = p.chromium.launch(headless=False)
page = browser.new_page()
pages = int(input("enter the number of pages to scrape: "))
for i in range(1, pages+1):
try:
page.goto(f"https://webscraper.io/test-sites/e-commerce/static/computers/laptops?page={i}")
except:
print("Error")
page.wait_for_timeout(7000)
titles = page.get_by_role("heading").all()
with open("laptops.csv", "a") as csvfile:
writer = csv.writer(csvfile)
for title in titles:
laptop = title.locator("a.title").all_inner_texts()
if len(laptop) == 1:
writer.writerow([laptop[0]])
browser.close()
main()运行此代码后,你的CSV文件应如下所示:
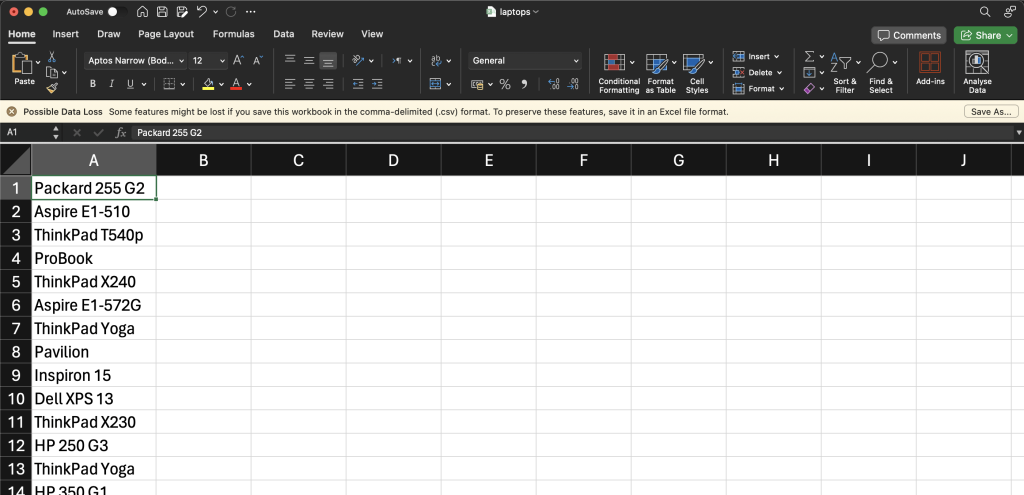
总结
在本文中,你学习了如何使用Python提取、解析和存储HTML。
虽然本教程相对简单,但在实际场景中,你在爬取过程中可能会遇到各种障碍,包括验证码、速率限制、网站布局变化或法规要求。幸运的是,Bright Data可以提供帮助。Bright Data提供的工具包括高级住宅代理来改进你的爬虫、Web Scraper IDE来大规模构建爬虫、以及Web Unblocker来解锁公共网站,包括解决验证码。这些工具可以帮助你在大规模收集准确数据并克服障碍。此外,Bright Data致力于道德爬虫,确保你遵守网站服务条款和法律法规。
通过Bright Data功能丰富的平台,你可以专注于提取所需的有价值数据,而无需担心网络爬虫的复杂性。今天就开始你的免费试用吧!







