

在本教程中,你将学习:
- 什么是 Crawl4AI 以及它在网页爬取方面提供了什么
- 在使用 Crawl4AI 搭配类 DeepSeek 的大型语言模型(LLM)时的理想场景
- 如何在引导式环节中构建一个由 DeepSeek 驱动的 Crawl4AI 爬虫。
让我们开始吧!
什么是 Craw4AI?
Crawl4AI 是一个开源、支持 AI 的网络爬虫和抓取器,旨在与大型语言模型(LLM)、AI 代理和数据管线实现无缝集成。它提供高速、实时的数据提取,同时具备灵活性且易于部署。
它在AI 网页爬取方面的主要功能包括:
- 专为 LLM 设计:可生成结构化的 Markdown 格式,适用于检索增强生成(RAG)和微调。
- 灵活的浏览器控制:支持会话管理、代理和自定义钩子。
- 启发式智能:使用智能算法来优化数据解析。
- 完全开源:无需 API 密钥,可通过 Docker 和云平台部署。
可在官方文档了解更多信息。
何时使用 Crawl4AI 和 DeepSeek 进行网页爬取
DeepSeek 提供了强大的、开源且免费的 LLM 模型,由于其高效率与高效性,在 AI 社区引起了广泛关注。这些模型也能与 Crawl4AI 无缝衔接。
通过在 Crawl4AI 中利用 DeepSeek,你可以从最复杂和结构不一致的网页中提取结构化数据,而无需预先定义的解析逻辑。
以下是 DeepSeek + Crawl4AI 组合特别有用的一些关键场景:
- 网站结构频繁变动:当网站更新其 HTML 结构时,传统的爬虫往往会失效,而 AI 能够动态适配。
- 页面布局不一致:例如 Amazon 等平台的商品页面设计各不相同。LLM 可以智能地提取数据,不受版面差异的影响。
- 非结构化内容解析:在处理自由文本的评论、博客帖子或论坛讨论时,借助 LLM 可以轻松提取所需信息。
使用 Craw4AI 和 DeepSeek 爬取网页:分步指南
在本引导式教程中,你将学习如何使用 Crawl4AI 构建一个由 AI 驱动的网页爬虫。我们将使用 DeepSeek 作为 LLM 引擎。
具体来说,你将看到如何创建一个 AI 爬虫,从G2 的 Bright Data 页面中提取数据:
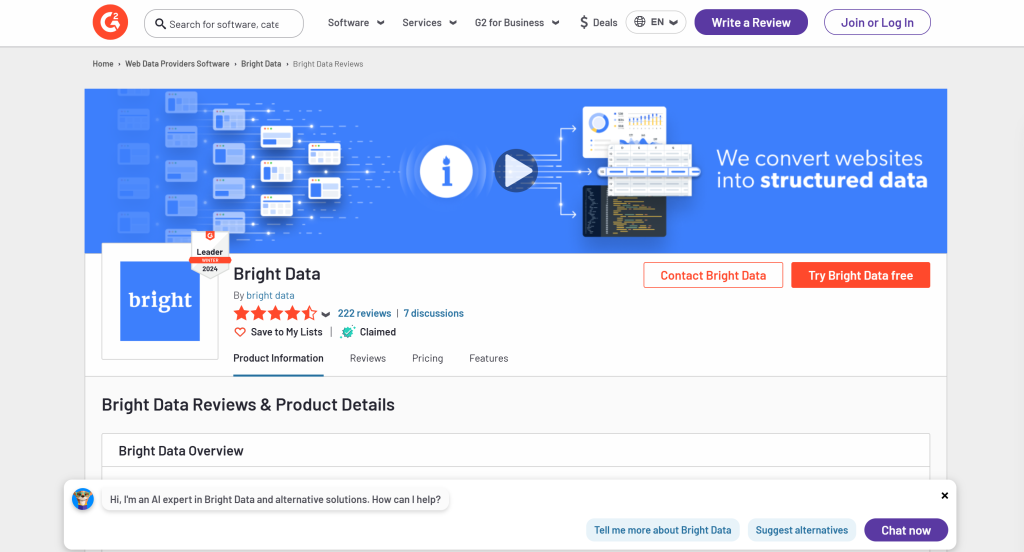
请按照以下步骤操作,学习如何利用 Crawl4AI 和 DeepSeek 进行网页爬取!
先决条件
如果你想跟着本教程一起实践,请先确保满足以下条件:
- 本地已安装 Python 3+
- 拥有 一个 GroqCloud 账户
- 拥有 一个 Bright Data 账户
如果你还没有 GroqCloud 或 Bright Data 账户,不必担心。在接下来的步骤中,你将看到如何进行相关设置。
第 1 步:项目设置
运行以下命令,为你的 Crawl4AI DeepSeek 爬虫项目创建一个文件夹:
mkdir crawl4ai-deepseek-scraper进入该项目文件夹并创建一个虚拟环境:
cd crawl4ai-deepseek-scraper
python -m venv venv现在,在你喜欢的 Python IDE 中打开 crawl4ai-deepseek-scraper 文件夹。比如 Visual Studio Code(配合 Python 扩展) 或者 PyCharm 社区版 都是不错的选择。
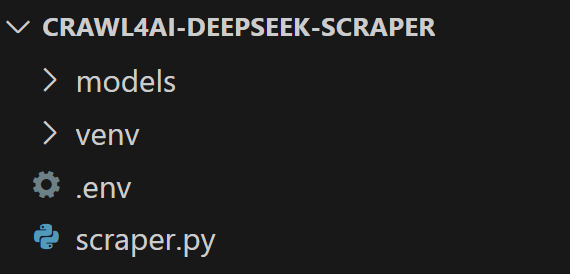
在项目文件夹下,创建:
scraper.py:存放 AI 驱动的爬虫逻辑的文件。models/:存储基于 Pydantic 的 Crawl4AI LLM 数据模型的文件夹。.env:安全存储环境变量的文件。
接着,你的项目结构应如下所示:
然后,在 IDE 的终端中激活虚拟环境。
在 Linux 或 macOS 中,运行:
./env/bin/activate在 Windows 中,运行:
env/Scripts/activate好了!你现在拥有了一个用于使用 DeepSeek 进行 Crawl4AI 爬取的 Python 环境。
第 2 步:安装 Craw4AI
在激活虚拟环境的情况下,通过 crawl4ai pip 包来安装 Crawl4AI:
pip install crawl4ai需注意该库依赖的安装包可能较多,安装过程可能需要一点时间。
安装完成后,在终端中运行以下命令:
crawl4ai-setup过程如下:
- 安装或更新所需的 Playwright 浏览器(Chromium、Firefox 等)。
- 执行操作系统级别检查(如在 Linux 上确认所需的系统库是否已安装)。
- 确认环境已正确设置以进行网络爬取。
执行完成后,你应能看到类似下面的输出:
[INIT].... → Running post-installation setup...
[INIT].... → Installing Playwright browsers...
[COMPLETE] ● Playwright installation completed successfully.
[INIT].... → Starting database initialization...
[COMPLETE] ● Database backup created at: C:\Users\antoz\.crawl4ai\crawl4ai.db.backup_20250219_092341
[INIT].... → Starting database migration...
[COMPLETE] ● Migration completed. 0 records processed.
[COMPLETE] ● Database initialization completed successfully.
[COMPLETE] ● Post-installation setup completed!太好了!Crawl4AI 已安装完毕,可以使用。
第 4 步:初始化 scraper.py
由于 Crawl4AI 需要异步代码,我们先创建一个基本的 asyncio 脚本:
import asyncio
async def main():
# Scraping logic...
if __name__ == "__main__":
asyncio.run(main())回想一下,我们这个项目会整合 DeepSeek 等第三方服务,需要依赖 API 密钥和其他机密信息。我们会把它们存放在 .env 文件里。
安装 python-dotenv 用于加载环境变量:
pip install python-dotenv然后,在定义 main() 之前,通过 load_dotenv() 从 .env 文件加载环境变量:
load_dotenv()从 python-dotenv 库中导入 load_dotenv:
from dotenv import load_dotenvPerfect!scraper.py 已准备好编写 AI 驱动的爬虫逻辑。
第 5 步:创建你的第一个 AI 爬虫
在 scraper.py 的 main() 函数中,使用一个基本的 Crawl4AI 爬虫添加如下逻辑:
# Browser configuration
browser_config = BrowserConfig(
headless=True
)
# Crawler configuration
crawler_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS
)
# Run the AI-powered crawler
async with AsyncWebCrawler(config=browser_config) as crawler:
result = await crawler.arun(
url="https://www.g2.com/products/bright-data/reviews",
config=crawler_config
)
# print the first 1000 characters
print(f"Parsed Markdown data:\n{result.markdown[:1000]}")在上面这段代码中,关键点包括:
BrowserConfig:用于控制浏览器的启动和行为,包括无头模式和自定义User-Agent等设置。CrawlerRunConfig:定义爬取时的行为,比如缓存策略、数据选择规则、超时等。headless=True:以无头模式运行浏览器,节约资源。CacheMode.BYPASS:表示爬虫直接从网站获取新内容,而不是使用缓存。crawler.arun():异步调用爬虫,对指定 URL 执行数据提取。result.markdown:将提取到的内容转为Markdown格式,方便解析和分析。
别忘了添加以下导入:
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig, CacheMode当前的 scraper.py 应如下所示:
import asyncio
from dotenv import load_dotenv
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig, CacheMode
# Load secrets from .env file
load_dotenv()
async def main():
# Browser configuration
browser_config = BrowserConfig(
headless=True
)
# Crawler configuration
crawler_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS
)
# Run the AI-powered crawler
async with AsyncWebCrawler(config=browser_config) as crawler:
result = await crawler.arun(
url="https://www.g2.com/products/bright-data/reviews",
config=crawler_config
)
# print the first 1000 characters
print(f"Parsed Markdown data:\n{result.markdown[:1000]}")
if __name__ == "__main__":
asyncio.run(main())如果你现在执行该脚本,你会看到类似:
[INIT].... → Crawl4AI 0.4.248
[FETCH]... ↓ https://www.g2.com/products/bright-data/reviews... | Status: True | Time: 0.83s
[SCRAPE].. ◆ Processed https://www.g2.com/products/bright-data/reviews... | Time: 1ms
[COMPLETE] ● https://www.g2.com/products/bright-data/reviews... | Status: True | Total: 0.83s
Parsed Markdown data:结果却很可疑,因为解析到的 Markdown 内容是空的。你可以打印一下响应状态:
print(f"Response status code: {result.status_code}")这回输出会包括:
Response status code: 403返回 Markdown 为空,是因为 Crawl4AI 请求被 G2 的反爬系统拦截了。由服务器返回的403 Forbidden 状态码可以看出。
这并不奇怪,因为 G2 有严格的反爬措施,甚至在普通浏览器访问时也可能出现 CAPTCHA:
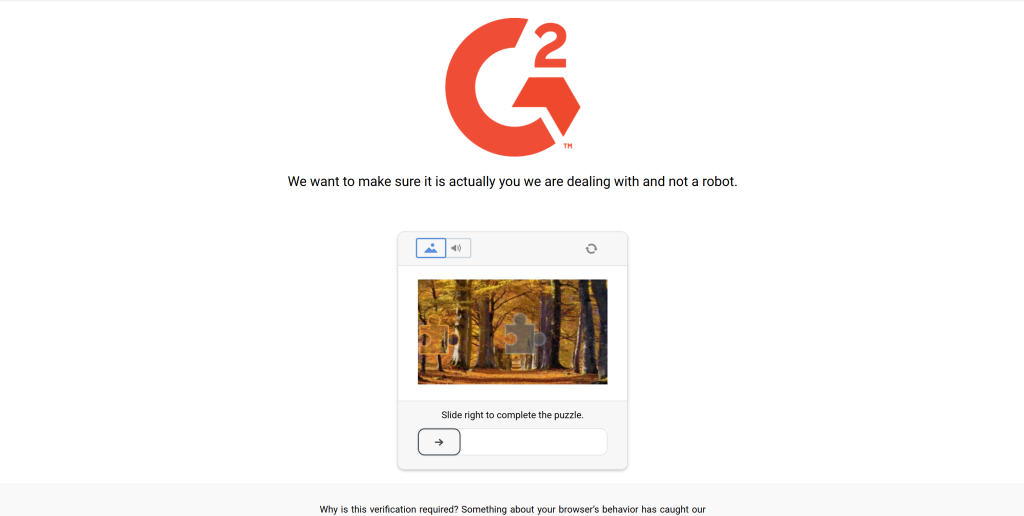
在这种情形下,Crawl4AI 并未收到任何有效的页面内容,因此无法转换为 Markdown。下一步,我们将学习如何绕过这一限制。如果你想进一步了解,请查看我们关于如何在 Python 中绕过 CAPTCHA的指南。
第 6 步:配置网络解锁器 API
Crawl4AI 是一款功能强大的工具,内置机器人绕过机制。然而,它无法绕过像 G2 这样防护力度极高的网站,这些网站采用了严格且顶级的反机器人与反爬措施。
针对这些网站,最佳的解决方案是专门用于解锁任何网页的工具,无论其保护等级如何。Bright Data 的 网络解锁器 就是这样一款爬取 API:
- 通过模拟真实用户行为绕过反爬检测
- 自动处理代理管理及 CAPTCHA 求解
- 可无缝扩展,无需自行管理基础设施
以下说明将指导你将网络解锁器 API 集成到 Crawl4AI DeepSeek 爬虫中。
或者,你也可以查看官方文档。
首先,登录 Bright Data 账户(或者先创建一个新账户)。为你的账户充值或使用所有产品都可以试用的免费额度。
然后,在仪表盘里选择 “Proxies & Scraping”,再在表格中选择 “unblocker”:
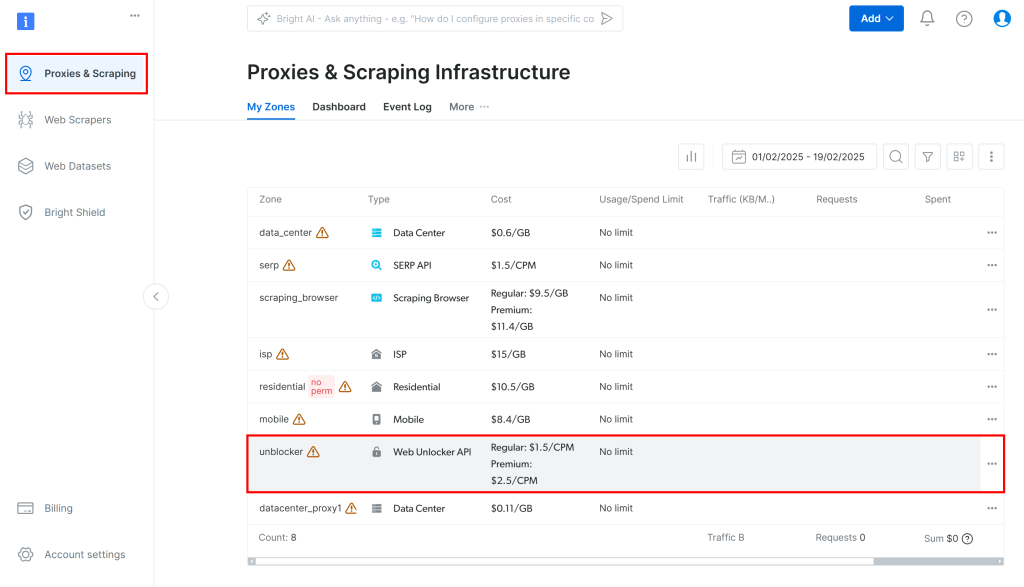
这样会进入以下所示的 Web Unlocker API 设置页面:
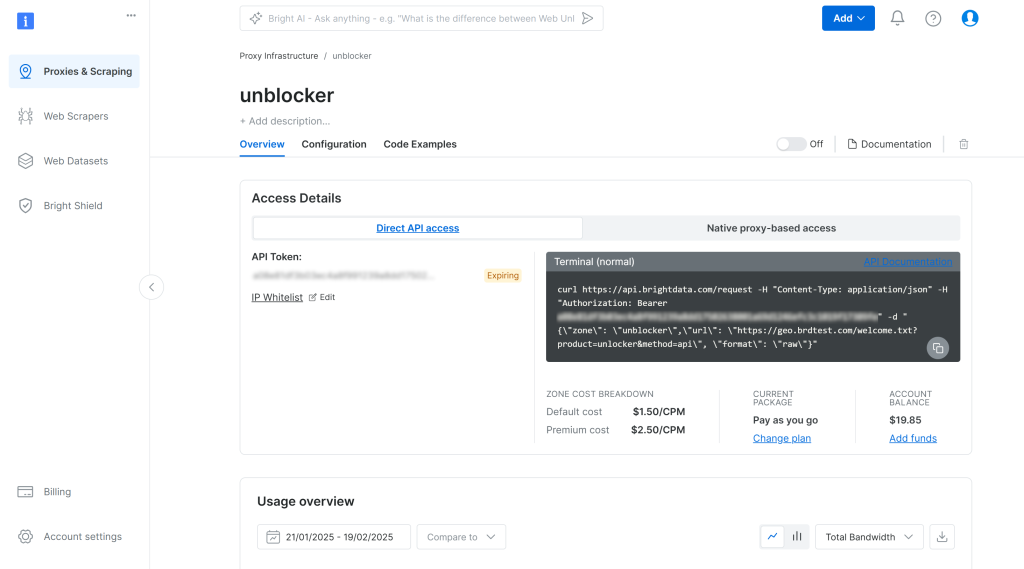
在此处点击开关以启用 Web Unlocker API:

G2 由于采用高级反爬措施(包含 CAPTCHA),因此在 “Configuration” 页面请确保下列两个开关已启用:
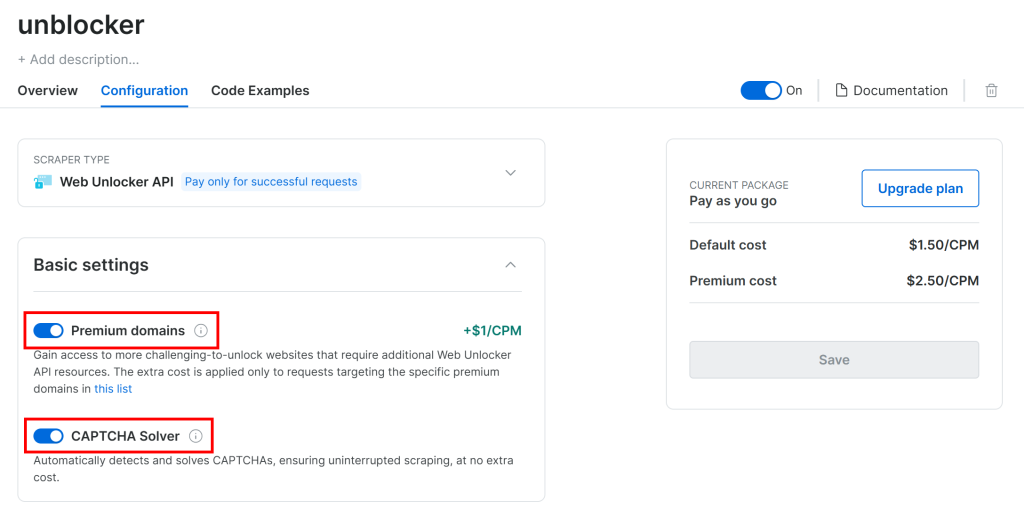
Crawl4AI 是通过一个受控的浏览器来访问页面,本质上依赖 Playwright 的 goto() 函数,这会发送 HTTP GET 请求到目标网页。而 Web Unlocker API 通过 POST 请求来工作。
不过,这并不冲突。你可以将 Web Unlocker API 的服务配置为代理,如此一来,Crawl4AI 的浏览器通过 Bright Data 的产品发送请求,得到已经解锁的 HTML 页面。
要获取你的 Web Unlocker API 代理凭证,请进入仪表盘 “Overview” 页里的 “Native proxy-based access” 标签:
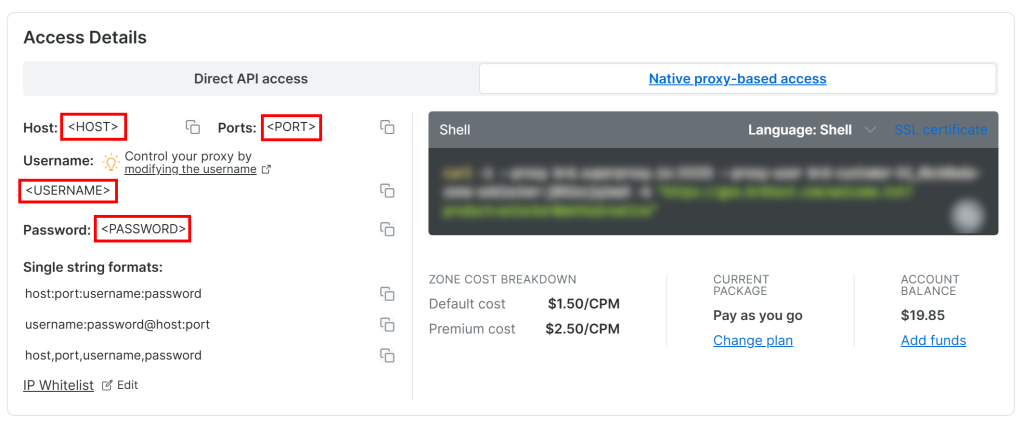
从页面中复制以下凭证:
<HOST><PORT><USERNAME><PASSWORD>
然后,将它们添加到 .env 文件中:
PROXY_SERVER=https://<HOST>:<PORT>
PROXY_USERNAME=<USERNAME>
PROXY_PASSWORD=<PASSWORD>非常好!网络解锁器已可与 Crawl4AI 集成使用。
第 7 步:集成网络解锁器 API
BrowserConfig 支持通过 proxy_config 对象来设置代理。想要使用 Crawl4AI 调用网络解锁器 API,只需将环境变量填入 os 中并传给 BrowserConfig:
# Bright Data's Web Unlocker API proxy configuration
proxy_config = {
"server": os.getenv("PROXY_SERVER"),
"username": os.getenv("PROXY_USERNAME"),
"password": os.getenv("PROXY_PASSWORD")
}
# Browser configuration
browser_config = BrowserConfig(
headless=True,
proxy_config=proxy_config,
)记得从 Python 标准库中导入 os:
import os需要注意,由于 Web Unlocker API 要进行代理 IP 切换以及 CAPTCHA 求解,所以可能会带来一定的时间开销。为确保能抓取到完整结果,你应该:
- 将页面加载超时增至 3 分钟
- 在页面解析前保证 DOM 已完全加载
可通过以下方式配置 CrawlerRunConfig:
crawler_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
wait_until="domcontentloaded", # wait until the DOM of the page has been loaded
page_timeout=180000, # wait up to 3 mins for page load
)需注意,即使使用了 Web Unlocker API,对于 G2 这样复杂的网站也不能保证 100% 成功。有时,爬取 API 可能无法成功解锁页面,脚本会报错:
Error: Failed on navigating ACS-GOTO:
Page.goto: net::ERR_HTTP_RESPONSE_CODE_FAILURE at https://www.g2.com/products/bright-data/reviews但请放心,对于请求失败的情况,你不会被收取费用,重试即可。在生产环境中,可以考虑实现自动重试逻辑。
当请求成功时,你会看到类似的输出:
Response status code: 200
Parsed Markdown data:
* [Home](https://www.g2.com/products/bright-data/</>)
* [Write a Review](https://www.g2.com/products/bright-data/</wizard/new-review>)
* Browse
* [Top Categories](https://www.g2.com/products/bright-data/<#>)
Top Categories
* [AI Chatbots Software](https://www.g2.com/products/bright-data/<https:/www.g2.com/categories/ai-chatbots>)
* [CRM Software](https://www.g2.com/products/bright-data/<https:/www.g2.com/categories/crm>)
* [Project Management Software](https://www.g2.com/products/bright-data/<https:/www.g2.com/categories/project-management>)
* [Expense Management Software](https://www.g2.com/products/bright-data/<https:/www.g2.com/categories/expense-management>)
* [Video Conferencing Software](https://www.g2.com/products/bright-data/<https:/www.g2.com/categories/video-conferencing>)
* [Online Backup Software](https://www.g2.com/products/bright-data/<https:/www.g2.com/categories/online-backup>)
* [E-Commerce Platforms](https://www.g2.com/products/brig太好了!这次 G2 返回了200 OK 状态码,表示没有被拦截,Crawl4AI 成功将 HTML 解析为 Markdown。
第 8 步:Groq 设置
GroqCloud 是少数支持 DeepSeek AI 模型且提供 OpenAI 兼容 API 的平台之一,它还提供免费套餐。因此,我们可用它来在 Crawl4AI 中集成 LLM。
如果你还没有 Groq 账户,可以新建一个。或者直接登录。在用户仪表盘里,左侧边栏选择 “API Keys”,然后点击 “Create API Key” 按钮:
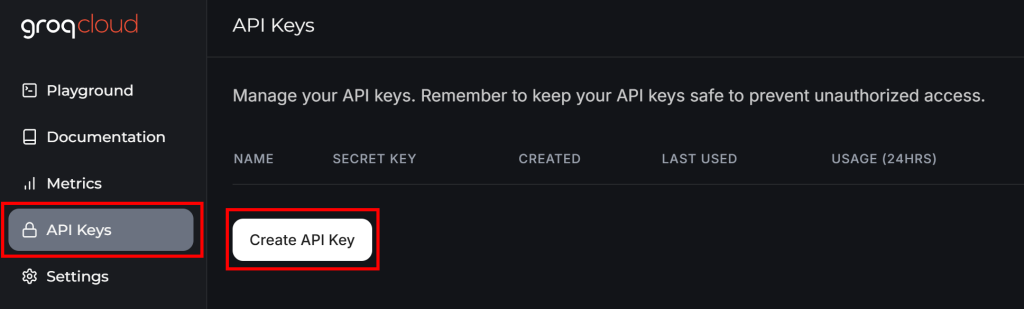
会弹出一个窗口:
给你的 API Key 命名(比如 “Crawl4AI Scraping”),等待 Cloudflare 的反机器人验证。通过后点击 “Submit” 生成你的 API Key:
复制该密钥,并将其存入 .env:
LLM_API_TOKEN=<YOUR_GROK_API_KEY>将 <YOUR_GROQ_API_KEY> 替换成真正的 Groq API Key。
完美!现在你可以在 Crawl4AI 中使用 DeepSeek 进行 LLM 爬取了。
第 9 步:为爬取的数据定义 Schema
Crawl4AI 使用一种基于 JSON Schema 的方式进行 LLM 数据提取。在该模式下,Schema 是一个用于描述目标数据结构的 JSON 数据结构,包含:
- 页面中用于识别“容器”元素的基础选择器(例如,一个产品卡片或博客帖子卡片的 DOM 元素)。
- 对应数据字段的 CSS/XPath 选择器(例如文本、属性、HTML 块)。
- 备注:可包含嵌套或列表类型,以处理重复或层级结构。
我们先要在目标页面上确认需要提取哪些数据。先在浏览器的无痕/隐身模式中打开目标页面:
假设我们想要获取以下字段:
name:产品/公司的名称image_url:产品/公司图片的 URLdescription:产品/公司的简介review_score:产品/公司的平均评分number_of_reviews:评论总数claimed:布尔值,表示该公司页面是否已被官方认领
现在,在 models 文件夹下创建 g2_product.py 文件,并用一个名为 G2Product 的基于 Pydantic 的类来描述此数据结构:
# ./models/g2_product.py
from pydantic import BaseModel
class G2Product(BaseModel):
"""
Represents the data structure of a G2 product/company page.
"""
name: str
image_url: str
description: str
review_score: str
number_of_reviews: str
claimed: bool好的!LLM 爬取流程将会返回符合 G2Product 这种 Schema 的对象。
第 10 步:准备将 DeepSeek 整合进来
在把 DeepSeek 与 Crawl4AI 完整结合前,可以先查看一下 GroqCloud 帐号中的 “Settings > Limits” 页面:
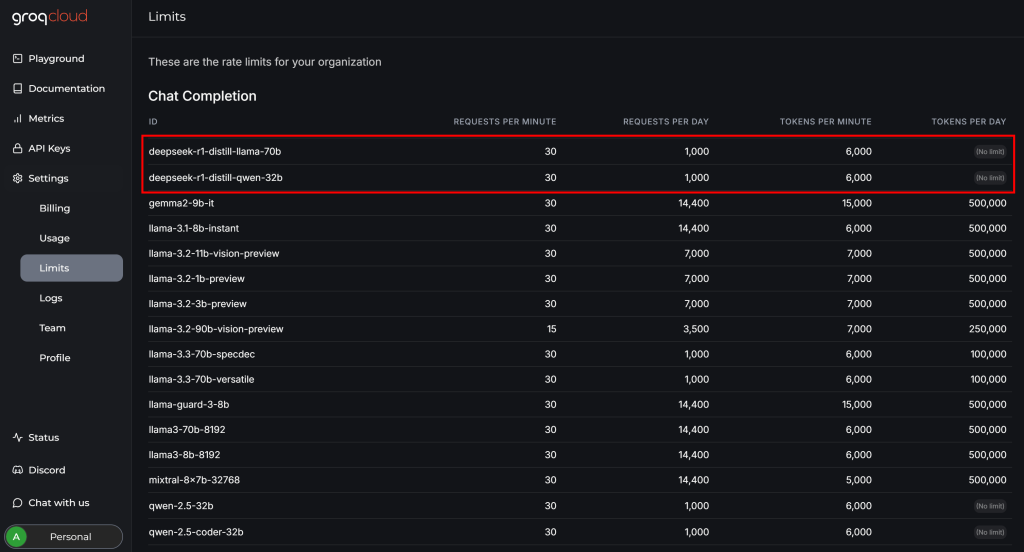
可以看到,GroqCloud 对可用的两个 DeepSeek 模型在免费套餐中有限制:
- 每分钟最多 30 个请求
- 每天最多 1,000 个请求
- 每分钟最多 6,000 个 Token
前两个限制对本示例影响不大,但最后一个限制就成了问题。一个典型的网页可能包含数百万字符,转换成 Token 可能是几万甚至几十万。
换言之,你没法直接把整页 G2 的内容全部丢给 Groq 的 DeepSeek 模型,因为会超出 Token 限制。为此,Crawl4AI 允许你只选取页面中的特定部分,然后只将这些内容转成 Markdown 并传给 LLM。元素选取过程基于CSS 选择器。
确定要选取的页面部分时,可以在浏览器里访问目标页面,右键想要抓取的数据所在元素并选择 “Inspect”:
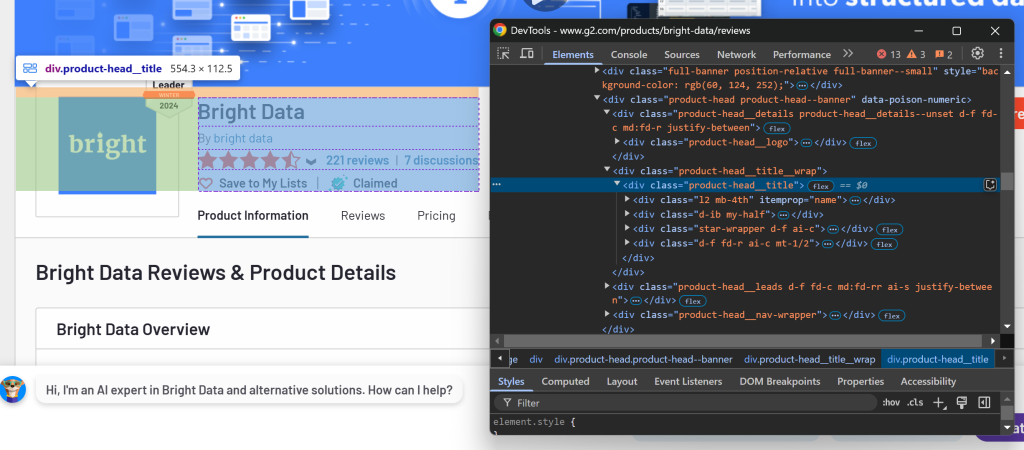
你会发现 .product-head__title 元素包含了产品/公司名称、评分、评论数以及是否被认领等信息。
接着检查 logo 区域:
可以通过 .product-head__logo 这个 CSS 选择器来获取。
最后检查简介:
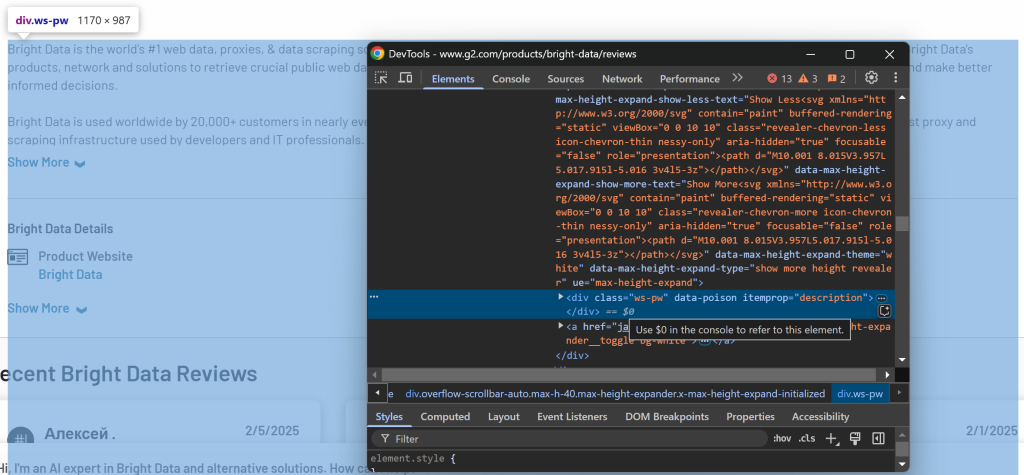
通过 [itemprop="description"] 选择器即可获取描述信息。
在 CrawlerRunConfig 中配置这些 CSS 选择器:
crawler_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
wait_until="domcontentloaded",
page_timeout=180000,
css_selector=".product-head__title, .product-head__logo, [itemprop=\"description\"]", # the CSS selectors of the elements to extract data from
)如果再次运行 scraper.py,将得到如下输出:
Response status code: 200
Parsed Markdown data:
[](https:/www.g2.com/products/bright-data/reviews)
[Editedit](https:/my.g2.com/bright-data/product_information)
[Bright Data](https:/www.g2.com/products/bright-data/reviews)
By [bright data](https:/www.g2.com/sellers/bright-data)
Show rating breakdown
4.7 out of 5 stars
[5 star78%](https:/www.g2.com/products/bright-data/reviews?filters%5Bnps_score%5D%5B%5D=5#reviews)
[4 star19%](https:/www.g2.c现在只会包含和我们关心的内容相关的部分,而不是整页 HTML。这样可以大幅减少 Token 用量,让你在 Groq 的免费额度内就能成功处理这些内容。
第 11 步:定义基于 DeepSeek 的 LLM 提取策略
Crawl4AI 通过 LLMExtractionStrategy 对象来支持基于 LLM 的数据提取。以下示例展示了如何使用 DeepSeek:
extraction_strategy = LLMExtractionStrategy(
provider=os.getenv("LLM_MODEL"),
api_token=os.getenv("LLM_API_TOKEN"),
schema=G2Product.model_json_schema(),
extraction_type="schema",
instruction=(
"Extract the 'name', 'description', 'image_url', 'review_score', and 'number_of_reviews' "
"from the content below. "
"'review_score' must be in \"x/5\" format. Get the entire description, not just the first few sentences."
),
input_format="markdown",
verbose=True
)我们通过给 .env 文件添加环境变量来指定要用的 LLM 模型:
LLM_MODEL=groq/deepseek-r1-distill-llama-70b这样就告诉 Crawl4AI 使用 GroqCloud 中的 deepseek-r1-distill-llama-70b 模型执行 LLM 数据提取。
在 scraper.py 中导入 LLMExtractionStrategy 和 G2Product:
from crawl4ai.extraction_strategy import LLMExtractionStrategy
from models.g2_product import G2Product然后,将 extraction_strategy 对象传给 crawler_config:
crawler_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
wait_until="domcontentloaded",
page_timeout=180000, # 3 mins
css_selector=".product-head__title, .product-head__logo, [itemprop=\"description\"]",
extraction_strategy=extraction_strategy
)脚本执行时,Crawl4AI 会:
- 通过 Web Unlocker API 代理连接目标页面。
- 抓取页面 HTML 并基于给定的 CSS 选择器过滤需要保留的部分。
- 将选定的 HTML 元素转换成 Markdown 格式。
- 将这些 Markdown 发送给 DeepSeek 进行数据提取。
- 根据传入的
instruction,让 DeepSeek 处理这些内容并返回提取结果。
在运行 crawler.arun() 后,你可用以下命令查看 Token 的使用情况:
print(extraction_strategy.show_usage())然后可通过以下方式获取并打印结果:
result_raw_data = result.extracted_content
print(result_raw_data)执行脚本后,你将看到如下输出:
=== Token Usage Summary ===
Type Count
------------------------------
Completion 525
Prompt 2,002
Total 2,527
=== Usage History ===
Request # Completion Prompt Total
------------------------------------------------
1 525 2,002 2,527
None
[
{
"name": "Bright Data",
"image_url": "https://images.g2crowd.com/uploads/product/image/large_detail/large_detail_9d7645872b9abb68923fb7e2c07c9d834/bright-data.png",
"description": "Bright Data is the world's #1 web data, proxies, & data scraping solutions platform. Fortune 500 companies, academic institutions and small businesses all rely on Bright Data's products, network and solutions to retrieve crucial public web data in the most efficient, reliable and flexible manner, so they can research, monitor, analyze data and make better informed decisions. Bright Data is used worldwide by 20,000+ customers in nearly every industry. Its products range from no-code data solutions utilized by business owners, to a robust proxy and scraping infrastructure used by developers and IT professionals. Bright Data products stand out because they provide a cost-effective way to perform fast and stable public web data collection at scale, effortless conversion of unstructured data into structured data and superior customer experience, while being fully transparent and compliant.",
"review_score": "4.7/5",
"number_of_reviews": "221",
"claimed": true
}
]前半部分(Token 使用情况)由 show_usage() 打印,证明 Token 用量远低于每分钟 6,000 的限制。后面返回的数据是一个符合 G2Product 结构要求的 JSON 字符串。
实在是太棒了!
第 12 步:处理结果数据
从上一步的输出可见,DeepSeek 通常会返回一个数组而不是单个对象。若要处理,请先用 JSON 进行解析,然后再取第一个元素:
# Parse the extracted data from JSON
result_data = json.loads(result.extracted_content)
# If the returned data is an array, access its first element
if result_data:
result_data = result_data[0]记得从 Python 标准库中导入json:
import json这样 result_data 就会成为一个与 G2Product 匹配的字典对象。最后,我们可以将数据输出到 JSON 文件中。
第 13 步:将爬取到的数据导出为 JSON
通过 json 将 result_data 写到 g2.json:
with open("g2.json", "w", encoding="utf-8") as f:
json.dump(result_data, f, indent=4)大功告成!
第 14 步:整合所有步骤
你的最终 scraper.py 文件应如下所示:
import asyncio
from dotenv import load_dotenv
from crawl4ai import AsyncWebCrawler, BrowserConfig, CrawlerRunConfig, CacheMode
import os
from crawl4ai.extraction_strategy import LLMExtractionStrategy
from models.g2_product import G2Product
import json
# Load secrets from .env file
load_dotenv()
async def main():
# Bright Data's Web Unlocker API proxy configuration
proxy_config = {
"server": os.getenv("PROXY_SERVER"),
"username": os.getenv("PROXY_USERNAME"),
"password": os.getenv("PROXY_PASSWORD")
}
# Browser configuration
browser_config = BrowserConfig(
headless=True,
proxy_config=proxy_config,
)
# LLM extraction strategy for data extraction using DeepSeek
extraction_strategy = LLMExtractionStrategy(
provider=os.getenv("LLM_MODEL"),
api_token=os.getenv("LLM_API_TOKEN"),
schema=G2Product.model_json_schema(),
extraction_type="schema",
instruction=(
"Extract the 'name', 'description', 'image_url', 'review_score', and 'number_of_reviews' "
"from the content below. "
"'review_score' must be in \"x/5\" format. Get the entire description, not just the first few sentences."
),
input_format="markdown",
verbose=True
)
# Crawler configuration
crawler_config = CrawlerRunConfig(
cache_mode=CacheMode.BYPASS,
wait_until="domcontentloaded",
page_timeout=180000, # 3 mins
css_selector=".product-head__title, .product-head__logo, [itemprop=\"description\"]",
extraction_strategy=extraction_strategy
)
# Run the AI-powered crawler
async with AsyncWebCrawler(config=browser_config) as crawler:
result = await crawler.arun(
url="https://www.g2.com/products/bright-data/reviews",
config=crawler_config
)
# Log the AI model usage info
print(extraction_strategy.show_usage())
# Parse the extracted data from JSON
result_data = json.loads(result.extracted_content)
# If the returned data is an array, access its first element
if result_data:
result_data = result_data[0]
# Export the scraped data to JSON
with open("g2.json", "w", encoding="utf-8") as f:
json.dump(result_data, f, indent=4)
if __name__ == "__main__":
asyncio.run(main())同时,models/g2_product.py 文件如下:
from pydantic import BaseModel
class G2Product(BaseModel):
"""
Represents the data structure of a G2 product/company page.
"""
name: str
image_url: str
description: str
review_score: str
number_of_reviews: str
claimed: bool而 .env 文件应包含:
PROXY_SERVER=https://<WEB_UNLOCKER_API_HOST>:<WEB_UNLOCKER_API_PORT>
PROXY_USERNAME=<WEB_UNLOCKER_API_USERNAME>
PROXY_PASSWORD=<WEB_UNLOCKER_API_PASSWORD>
LLM_API_TOKEN=<GROQ_API_KEY>
LLM_MODEL=groq/deepseek-r1-distill-llama-70b使用以下命令运行你的 DeepSeek Crawl4AI 爬虫:
python scraper.py终端输出将类似:
[INIT].... → Crawl4AI 0.4.248
[FETCH]... ↓ https://www.g2.com/products/bright-data/reviews... | Status: True | Time: 56.13s
[SCRAPE].. ◆ Processed https://www.g2.com/products/bright-data/reviews... | Time: 397ms
[LOG] Call LLM for https://www.g2.com/products/bright-data/reviews - block index: 0
[LOG] Extracted 1 blocks from URL: https://www.g2.com/products/bright-data/reviews block index: 0
[EXTRACT]. ■ Completed for https://www.g2.com/products/bright-data/reviews... | Time: 12.273853100006818s
[COMPLETE] ● https://www.g2.com/products/bright-data/reviews... | Status: True | Total: 68.81s
=== Token Usage Summary ===
Type Count
------------------------------
Completion 524
Prompt 2,002
Total 2,526
=== Usage History ===
Request # Completion Prompt Total
------------------------------------------------
1 524 2,002 2,526
None同时,你的项目文件夹下会生成一个 g2.json 文件,内容如下:
{
"name": "Bright Data",
"image_url": "https://images.g2crowd.com/uploads/product/image/large_detail/large_detail_9d7645872b9abb68923fb7e2c7c9d834/bright-data.png",
"description": "Bright Data is the world's #1 web data, proxies, & data scraping solutions platform. Fortune 500 companies, academic institutions and small businesses all rely on Bright Data's products, network and solutions to retrieve crucial public web data in the most efficient, reliable and flexible manner, so they can research, monitor, analyze data and make better informed decisions. Bright Data is used worldwide by 20,000+ customers in nearly every industry. Its products range from no-code data solutions utilized by business owners, to a robust proxy and scraping infrastructure used by developers and IT professionals. Bright Data products stand out because they provide a cost-effective way to perform fast and stable public web data collection at scale, effortless conversion of unstructured data into structured data and superior customer experience, while being fully transparent and compliant.",
"review_score": "4.7/5",
"number_of_reviews": "221",
"claimed": true
}恭喜!你已经成功从一个带有严密反爬保护的 G2 页面提取出结构化数据,并使用了 Crawl4AI、DeepSeek 以及 Web Unlocker API,全程不需要编写任何手动解析逻辑。
总结
在本教程中,你了解了什么是 Crawl4AI,以及如何在其基础上结合 DeepSeek 来构建一个由 AI 驱动的爬虫。我们也演示了如何使用 Bright Data 的网络解锁器 API 绕过无法轻松访问的目标网站。
如教程所示,将 Crawl4AI、DeepSeek 和 Web Unlocker API 三者结合,仅需极少量的配置即可在无需手动解析逻辑的情况下对 G2 这样防护更严的网站进行数据提取。这只是 Bright Data 产品和服务支持的诸多场景之一,它们能帮助你实现高效的 AI 驱动网页爬取。
以下是其他可以与 Crawl4AI 集成的爬取工具:
- 代理服务:拥有四种代理类型,涵盖 72,000,000+ 的住宅 IP,用于突破地域限制
- 网络抓取 API:针对超过 100 个热门域名提供专用端点,用来提取实时、结构化网页数据
- 搜索引擎 API:无需额外解锁管理,即可抓取搜索引擎结果页面并提取一个页面数据
- 抓取浏览器:与 Puppeteer、Selenium 和 Playwright 兼容,同时集成了自动解锁能力
快来注册 Bright Data 账户,免费试用我们的代理服务和爬取产品吧!



