现在,你可能会问,为什么要关注亚马逊?作为世界上最大的电子商务平台之一,亚马逊是宝贵数据的丰富来源。这些数据包括产品、价格、客户反馈和新兴趋势等各种详细信息。例如,卖家可以利用这些数据来监控竞争对手,研究人员可以研究市场趋势,消费者可以做出明智的购买决策。可能性是无穷无尽的。
在本教程中,你将学习如何使用工具抓取亚马逊数据,例如Beautiful Soup和Playwright。通过逐步操作,你还会了解Bright Data的解决方案,它可以显著加快这一过程。
使用Python手动抓取亚马逊数据
在开始从亚马逊网站提取数据之前,你需要确保你的计算机上安装了所有必需的库。对网页抓取和HTML有基本了解也是有帮助的。
重要提示:本教程纯粹用于教育目的,展示技术能力。需要认识到,从亚马逊抓取数据涉及使用条款和合法性问题。未经授权的抓取可能导致严重后果,包括法律诉讼和账户暂停。始终谨慎操作并遵守道德规范。
先决条件
为了继续本教程,你需要在计算机上安装Python。如果你是Python新手,请阅读这篇如何使用Python进行网页抓取的指南以获得详细说明。如果你已经在使用Python,请确保它的版本是3.7.9或更新版本。
准备好Python后,打开你的终端或shell,使用以下命令创建一个新的项目目录:
mkdir scraping-amazon-python && cd scraping-amazon-python建立项目目录后,下一步是安装一组额外的库,这些库对有效的网页抓取是必不可少的。具体来说,你将使用Requests,这是一个用于处理Python中HTTP请求的库;pandas,这是一个用于数据操作和分析的强大库;Beautiful Soup (BS4)用于解析HTML内容;Playwright用于自动化与网页浏览相关的任务。
要安装这些库,打开你的终端或shell并运行以下命令:
pip3 install beautifulsoup4
pip3 install requests
pip3 install pandas
pip3 install playwright
playwright install确保安装过程没有任何问题,然后再继续下一步。
请注意:最后一个命令(即
playwright install)是至关重要的,因为它确保必要的浏览器二进制文件已正确安装。
了解亚马逊的布局和数据组件
安装好必要的库后,你需要熟悉其网站结构。亚马逊的主页提供了一个用户友好的搜索栏,使你能够探索从电子产品到书籍的各种产品。
输入搜索条件后,结果会以列表形式展示,列出带有标题、价格、评级和其他相关详细信息的产品。这些搜索结果可以通过各种过滤器进行排序,如价格范围、产品类别和客户评论:
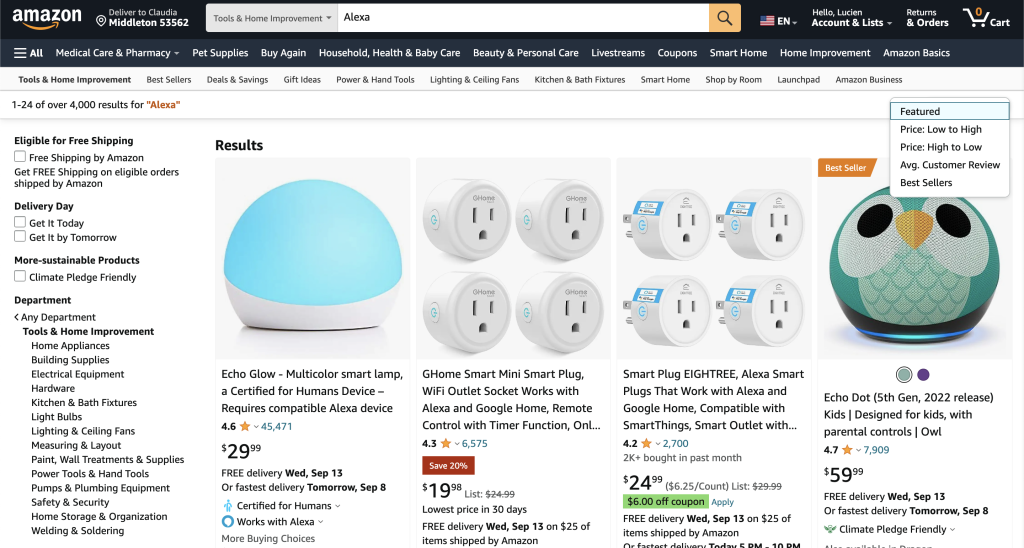
如果你希望看到更长的结果列表,可以利用页面底部的分页按钮。每页通常包含许多列表,给你机会浏览更多产品。页面顶部的过滤器提供了根据你的需求细化搜索的机会。
要了解亚马逊的HTML结构,请按以下步骤操作:
- 访问亚马逊网站。
- 在搜索栏中输入你想要的产品或从推荐列表中选择一个类别。
- 右键点击一个产品并选择检查元素以打开浏览器的开发者工具。
- 探索HTML布局以识别你打算提取的数据的标签和属性。
抓取亚马逊产品数据
现在你已经熟悉了亚马逊的产品结构,在本节中,你将收集产品名称、评级、评论数量和价格等详细信息。
在你的项目目录中,创建一个名为amazon_scraper.py的新Python脚本,并添加以下代码:
import asyncio
from playwright.async_api import async_playwright
import pandas as pd
async def scrape_amazon():
async with async_playwright() as pw:
# Launch new browser
browser = await pw.chromium.launch(headless=False)
page = await browser.new_page()
# Go to Amazon URL
await page.goto('https://www.amazon.com/s?i=fashion&bbn=115958409011')
# Extract information
results = []
listings = await page.query_selector_all('div.a-section.a-spacing-small')
for listing in listings:
result = {}
# Product name
name_element = await listing.query_selector('h2.a-size-mini > a > span')
result['product_name'] = await name_element.inner_text() if name_element else 'N/A'
# Rating
rating_element = await listing.query_selector('span[aria-label*="out of 5 stars"] > span.a-size-base')
result['rating'] = (await rating_element.inner_text())[0:3]await rating_element.inner_text() if rating_element else 'N/A'
# Number of reviews
reviews_element = await listing.query_selector('span[aria-label*="stars"] + span > a > span')
result['number_of_reviews'] = await reviews_element.inner_text() if reviews_element else 'N/A'
# Price
price_element = await listing.query_selector('span.a-price > span.a-offscreen')
result['price'] = await price_element.inner_text() if price_element else 'N/A'
if(result['product_name']=='N/A' and result['rating']=='N/A' and result['number_of_reviews']=='N/A' and result['price']=='N/A'):
pass
else:
results.append(result)
# Close browser
await browser.close()
return results
# Run the scraper and save results to a CSV file
results = asyncio.run(scrape_amazon())
df = pd.DataFrame(results)
df.to_csv('amazon_products_listings.csv', index=False)在这段代码中,你使用了Python的异步功能与Playwright库结合,抓取特定亚马逊时尚页面上的产品列表。一旦启动一个新的浏览器实例并导航到目标亚马逊URL,你将提取产品信息,如产品名称、评级、评论数量和价格。在遍历页面上的每个列表后,你过滤掉没有数据的列表(即标记为“N/A”)。抓取的结果存入一个Pandas数据框,并随后导出为名为amazon_products_listings.csv的CSV文件。
要运行脚本,请在终端或shell中执行python3 amazon_scraper.py。你的输出应如下所示:
product_name,rating,number_of_reviews,price
Crocs Women's Kadee Ii Sandals,4.2,17.5K+,$29.99
Teva Women's W Flatform Universal Sandal,4.7,7K+,$58.80
"OOFOS OOriginal Sport Sandal - Lightweight Recovery Footwear - Reduces Stress on Feet, Joints & Back - Machine Washable - Hand-Painted Graphics",4.5,9.4K+,N/A
"Crocs Women's Brooklyn Low Wedges, Platform Sandals",4.6,11.7K+,N/A
Teva Women's Original Universal Sandal,4.7,18.7K+,$35.37
Reef Women's Water Vista Sandal,4.5,1.9K+,$59.95
Crocs Women's Brooklyn Platform Slides Sandal,4.2,376,N/A
…output omitted…请注意:如果脚本第一次运行时不起作用,请再试一次。亚马逊有复杂的反抓取措施,可能会阻止或拦截你的数据抓取尝试。
亚马逊高级抓取技术
当你开始在亚马逊上进行抓取时,你会很快发现,这个以其复杂网页著称的电商巨头,提出了需要超越基本抓取方法的挑战。看看一些可以帮助确保顺利高效抓取的高级技术:
处理分页
亚马逊展示了多个产品,通常跨越多个页面。为了捕获所有数据,你的脚本应该能够无缝地导航这些页面。一种常见方法是定位产品列表底部的下一页按钮。通过识别其唯一的选择器,你可以编程你的脚本点击这个按钮,进入下一页。不过,确保你的抓取器在继续操作前等待所有元素加载完毕。
绕过广告
广告通常会在亚马逊产品列表中弹出。这些广告可能与常规产品结构略有不同,可能会导致抓取过程中的问题。为了解决这个问题,你需要检测表示广告的元素或标签。例如,寻找带有Sponsored或Ad标签的标签。一旦检测到,你可以指示你的脚本跳过这些条目,确保只收集真实的产品数据。
缓解封锁
亚马逊对其内容非常警惕,可能会封锁或暂时暂停它认为是机器人或可疑的活动。让你的抓取器看起来尽可能像人类是至关重要的。
为了避免被封锁,你需要在请求之间引入延迟或随机间隔,使用如asyncio.sleep(random.uniform(1, 5))的函数。这使得你的抓取模式看起来不那么像机器人。另外,考虑轮换用户代理和IP地址以减少被检测的风险。如果遇到验证码挑战,使用验证码解决服务也会有帮助。
处理动态内容
亚马逊的某些内容,如评论或问答部分,是动态加载的,基本的抓取器可能会遗漏这些数据。你需要确保你的抓取器可以执行JavaScript并等待动态内容加载。使用如Playwright或Selenium的工具,你可以使用显式等待,确保特定元素加载完毕后再进行抓取。
设置抓取限制
不幸的是,发送大量并发请求可能导致IP被列入黑名单。为了防止这种情况发生,你需要限制发送请求的速率。
设计你的脚本,使其不会轰炸亚马逊的服务器。前面提到的设置合理的请求间隔是必不可少的。
通过实施这些高级技术,你不仅可以提高在亚马逊上抓取的效率,还可以确保抓取的持久性,减少抓取器被检测或封锁的机会。
考虑使用Bright Data抓取亚马逊数据
虽然手动网页抓取可以为较小的任务提供结果,但在扩大规模时可能会变得繁琐且效率低下。为了更高效地从亚马逊收集大量数据,考虑使用Bright Data。
使用Bright Data的Scraping Browser,你可以无缝地与动态网站如亚马逊进行交互,因为它能够巧妙地处理JavaScript、AJAX请求和其他复杂情况。或者,如果你急需结构化的亚马逊数据,无论是产品列表、评论还是卖家资料,你可以立即使用他们的亚马逊数据集,直接从他们的平台下载和访问整理好的数据。
创建Bright Data账户
要开始使用Bright Data,你需要创建和设置你的账户。请按照以下步骤操作:
打开浏览器并访问Bright Data官网。点击免费试用并按提示进行操作。
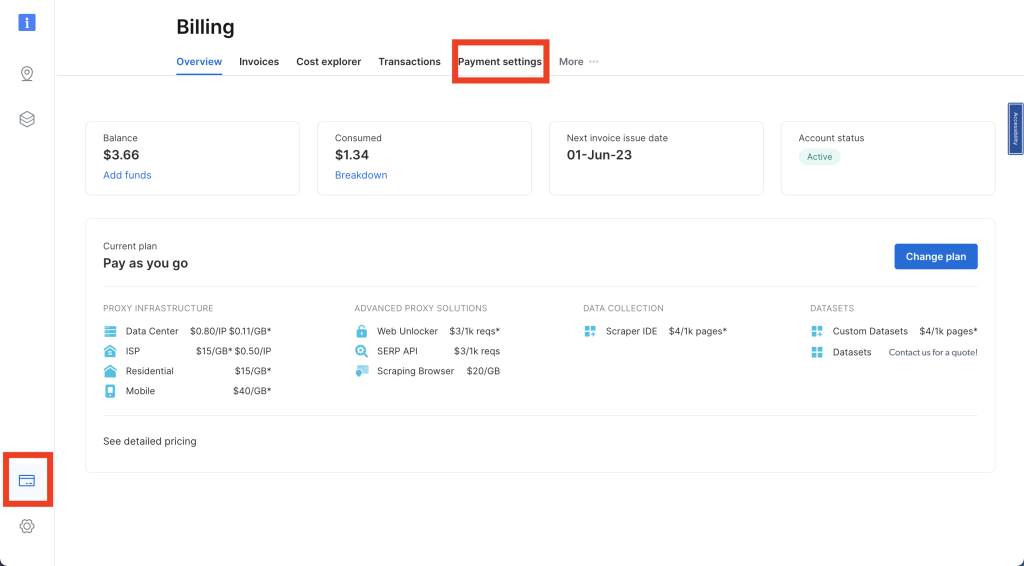
进入仪表板后,在左侧栏找到信用卡图标,进入账单页面。这里,输入有效的支付方式以激活你的账户:
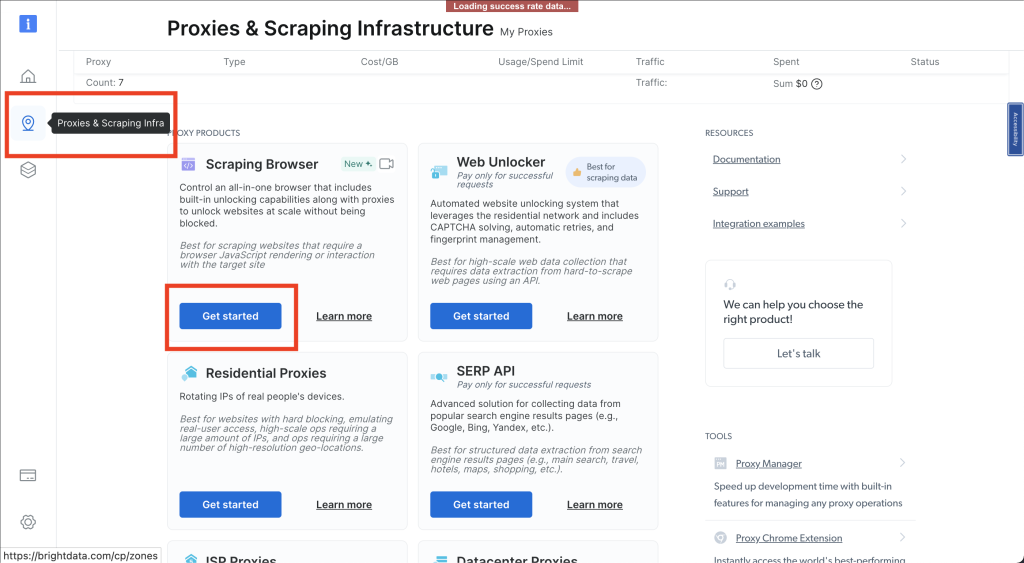
接下来,通过选择相应的图标进入代理和抓取基础设施部分。选择Scraping Browser > Get started:
相应命名你的解决方案并确认添加:
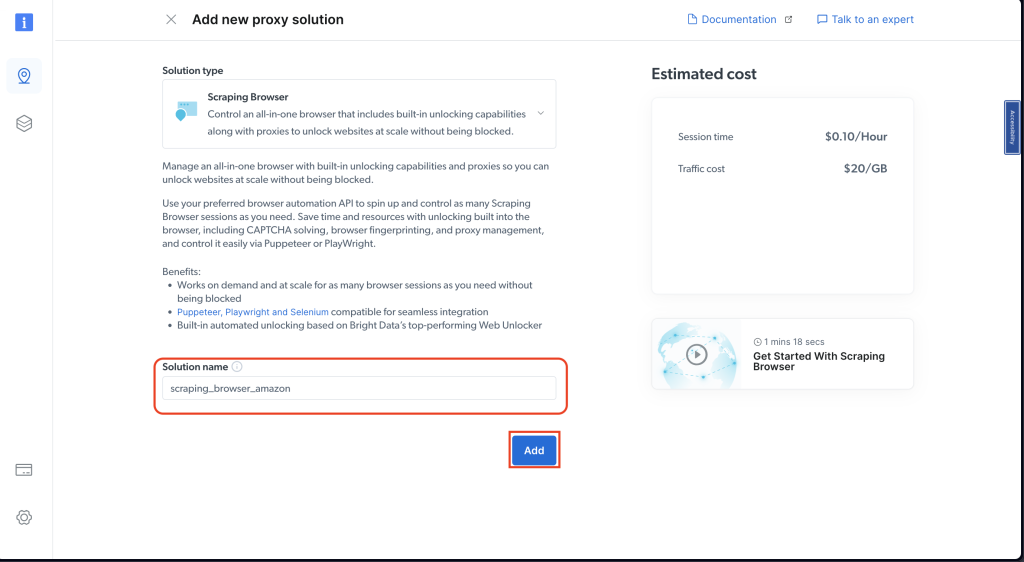
在访问参数下,花一点时间记下你的用户名、主机(默认)和密码。稍后你需要这些:
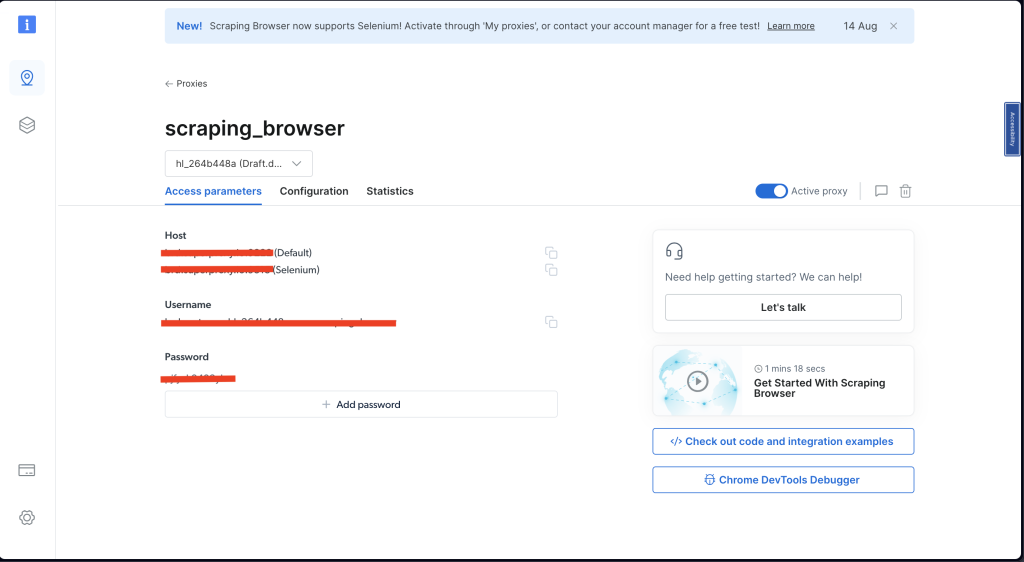
完成这些步骤后,你就可以提取数据了。
使用Scraping Browser提取亚马逊产品数据
要使用Bright Data从亚马逊抓取产品数据,请创建一个名为amazon_scraper_bdata.py的新文件,并添加以下代码:
import asyncio
from playwright.async_api import async_playwright
import pandas as pd
username='YOUR_BRIGHTDATA_USERNAME'
password='YOUR_BRIGHTDATA_PASSWORD'
auth=f'{username}:{password}'
host = 'YOUR_BRIGHTDATA_DEFAULT_HOST'
browser_url = f'wss://{auth}@{host}'
async def scrape_amazon_bdata():
async with async_playwright() as pw:
print('connecting')
# Launch new browser
browser = await pw.chromium.connect_over_cdp(browser_url)
print('connected')
page = await browser.new_page()
print('navigating')
# Go to Amazon URL
await page.goto('https://www.amazon.com/s?i=fashion&bbn=115958409011', timeout=600000)
print('data extraction in progress')
# Extract information
results = []
listings = await page.query_selector_all('div.a-section.a-spacing-small')
for listing in listings:
result = {}
# Product name
name_element = await listing.query_selector('h2.a-size-mini > a > span')
result['product_name'] = await name_element.inner_text() if name_element else 'N/A'
# Rating
rating_element = await listing.query_selector('span[aria-label*="out of 5 stars"] > span.a-size-base')
result['rating'] = (await rating_element.inner_text())[0:3]await rating_element.inner_text() if rating_element else 'N/A'
# Number of reviews
reviews_element = await listing.query_selector('span[aria-label*="stars"] + span > a > span')
result['number_of_reviews'] = await reviews_element.inner_text() if reviews_element else 'N/A'
# Price
price_element = await listing.query_selector('span.a-price > span.a-offscreen')
result['price'] = await price_element.inner_text() if price_element else 'N/A'
if(result['product_name']=='N/A' and result['rating']=='N/A' and result['number_of_reviews']=='N/A' and result['price']=='N/A'):
pass
else:
results.append(result)
# Close browser
await browser.close()
return results
# Run the scraper and save results to a CSV file
results = asyncio.run(scrape_amazon_bdata())
df = pd.DataFrame(results)
df.to_csv('amazon_products_bdata_listings.csv', index=False)在这段代码中,你利用了Playwright库与asyncio结合,异步抓取亚马逊网页上的产品详细信息。你设置了Bright Data的认证详细信息(一个代理服务),然后使用该服务连接到浏览器。
连接成功后,脚本会导航到指定的亚马逊URL,提取产品信息,如名称、评级、评论数量和价格,然后将这些详细信息编译成一个列表。如果某个产品没有任何上述数据,它将被跳过。
抓取完成后,浏览器将关闭,抓取的产品详细信息将保存到一个名为amazon_products_bdata_listings.csv的CSV文件中。
重要提示:请记住将
YOUR_BRIGHTDATA_USERNAME、YOUR_BRIGHTDATA_PASSWORD和YOUR_BRIGHTDATA_HOST替换为你的Bright Data帐户详细信息(可在“访问参数”选项卡中找到)。
使用以下命令在终端或shell中运行代码:
python3 amazon_scraper_bdata.py你的输出应如下所示:
product_name,rating,number_of_reviews,price
Women's Square Neck Bodice Dress Sleeveless Tank Top Stretch Flare Mini Dresses,N/A,131,$32.99
"Women's Swiftwater Sandal, Lightweight and Sporty Sandals for Women",N/A,"35,941",$19.95
Women's Elegant Sleeveless Off Shoulder Bodycon Long Formal Party Evening Dress,N/A,"3,122",$49.99
Women 2023 Summer Sleeveless Tank Dresses Crew Neck Slim Fit Short Casual Ruched Bodycon Party Club Mini Dress,N/A,"40,245",$33.99
"Infinity Dress with Bandeau, Convertible Bridesmaid Dress, Long, Plus Size, Multi-Way Dress, Twist Wrap Dress",N/A,"11,412",$49.99
…output omitted…虽然手动抓取亚马逊可能会遇到如验证码和访问限制等问题,但Bright Data Scraping Browser提供了应对这些挑战的弹性和灵活性,确保不间断的数据提取。
Bright Data亚马逊数据集
如果你不想手动抓取数据,Bright Data还提供现成的亚马逊数据集。这些数据集中包含了从产品详细信息到用户评论的所有内容。使用这些数据集意味着你不需要自己抓取网站,数据已经为你整理好。
要找到这些数据集,请进入你的Bright Data仪表板,点击左侧的数据集和Web抓取IDE。然后点击从数据集市场获取数据:
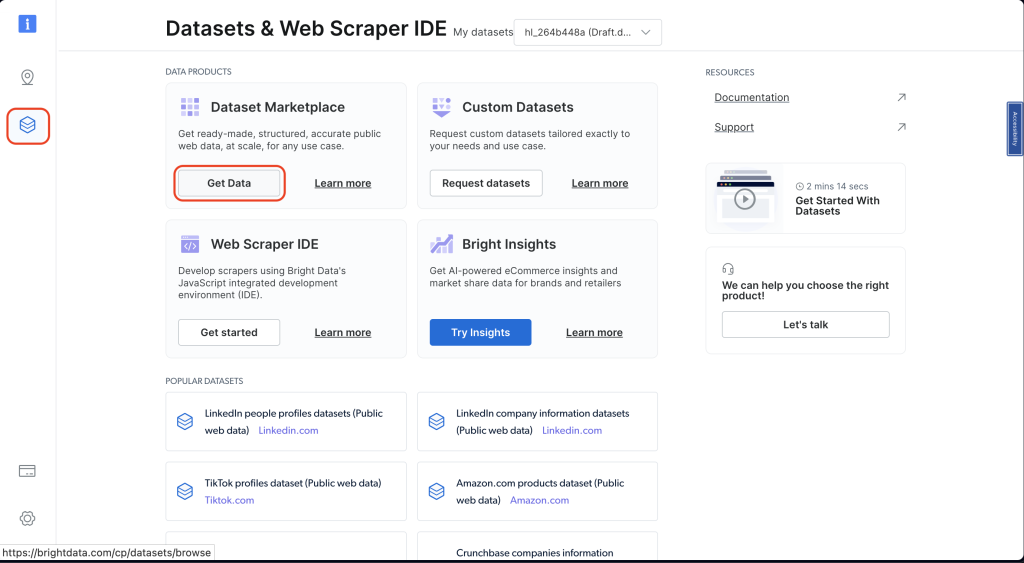
接下来,在搜索栏中搜索“amazon”。然后点击查看数据集:
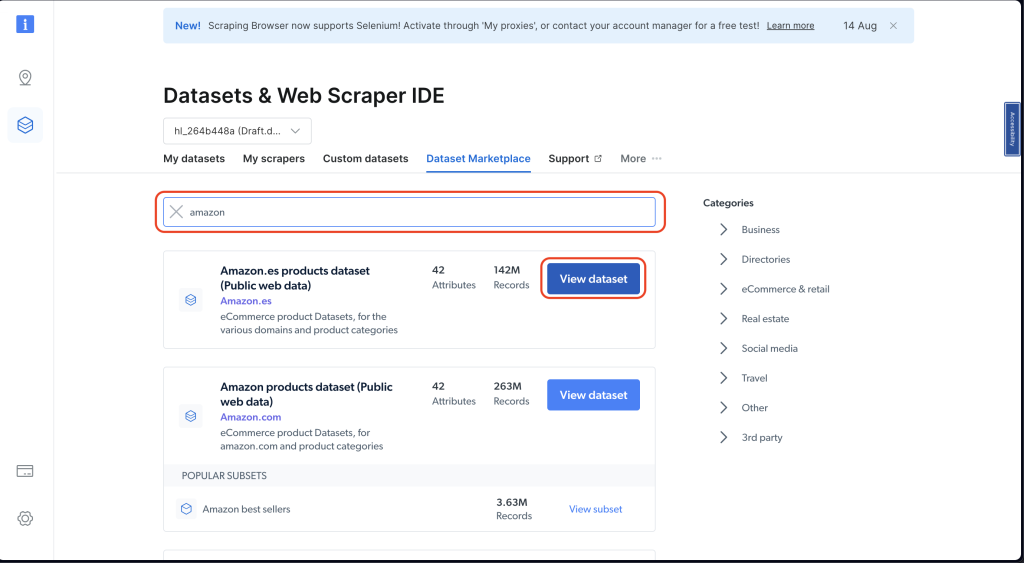
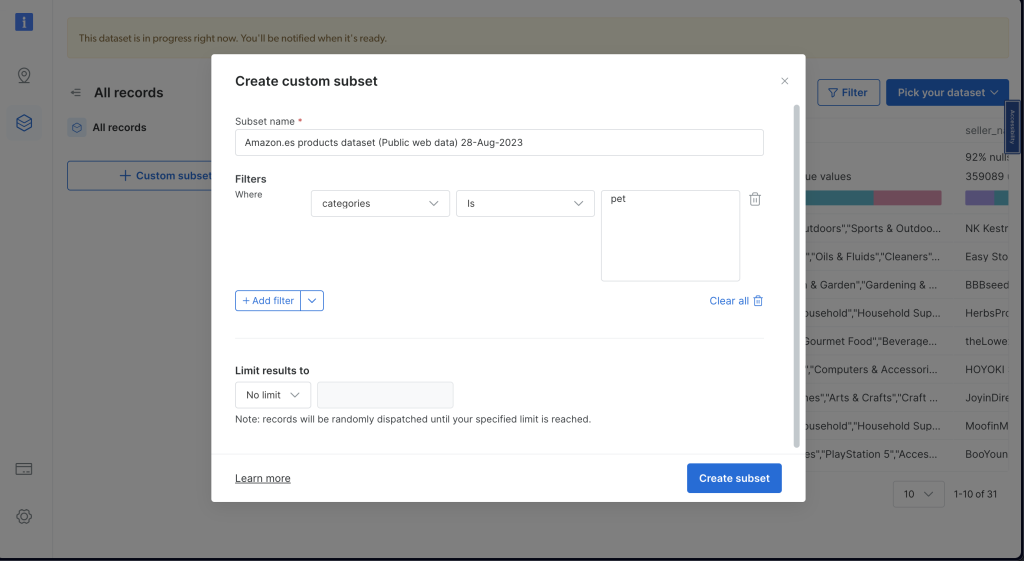
选择适合你需求的数据集。你可以使用过滤器来缩小选择范围。记住,费用取决于你需要的数据量,因此你可以根据需求和预算进行选择:
你可以在GitHub仓库找到本教程中使用的代码。
结论
在本教程中,你学习了如何使用Python手动收集亚马逊数据,这面临如验证码和限速等挑战,这些挑战可能会妨碍高效的数据抓取。然而,利用Bright Data的工具和他们的Scraping Browser可以简化这一过程并减轻这些问题。
Bright Data提供了简化从网站(包括亚马逊)收集数据的工具。这些工具将具有挑战性的网页抓取任务变得简单,节省了你的时间和精力。
此外,Bright Data还提供现成的数据集,特别是亚马逊的数据集。这意味着你不必从头开始;你可以直接访问大量的亚马逊数据。
通过使用Bright Data的工具,数据收集变得轻而易举,开启了新的见解和知识的大门。开始探索,发现Bright Data带来的新数据可能性!