

在本指南中,你将了解:
- Scrapy 是什么
- Playwright 是什么
- 它们为网络爬虫提供了哪些功能以及彼此间的差异
- 如何使用这两种工具进行网络爬虫的基础介绍
- 如何使用 Playwright 构建爬虫
- 如何使用 Scrapy 编写网络爬虫脚本
- 哪种工具更适合做网络爬虫
- 它们常见的局限性以及应对方法
让我们开始吧!
Scrapy 是什么?
Scrapy 是一个用 Python 编写的开源网络爬虫框架,旨在高效地进行数据提取。它内置支持并发请求、链式跟踪链接,以及以 JSON、CSV 等格式导出数据。它还提供中间件、代理集成和自动重试请求等功能。Scrapy 采用异步方式,主要针对静态 HTML 页面。
Playwright 是什么?
Playwright 是一个用于浏览器端端到端测试及网络爬虫的开源自动化框架。它支持多种浏览器,如 Chrome、Firefox 和 WebKit,可分别以带界面或无头模式运行。Playwright 的浏览器自动化 API 同时支持多种编程语言,包括 TypeScript/JavaScript、Python、Java 和 C#。
Scrapy vs Playwright:网络爬虫功能对比
接下来我们将针对五个不同方面来对比 Scrapy 和 Playwright 在网络爬虫领域的表现。
如需了解更多工具对比,参阅:
- Scrapy vs. Beautiful Soup
- Scrapy vs Pyspider:哪一个更适合网络爬虫?
- Scrapy vs. Selenium 网络爬虫比较
- Scrapy vs. Puppeteer 网络爬虫比较
- Scrapy vs. Requests:哪一个更适合网络爬虫?
现在,开始 Scrapy 与 Playwright 的对比吧!
安装与配置的便捷度
Scrapy 的安装和配置简单明了。通过其内置 CLI,你可以很快地创建项目、定义爬虫并导出数据。相反,使用 Playwright 前需要安装浏览器依赖并确认配置已正确完成,所需步骤会相对多一些。
学习曲线
对初学者来说,Scrapy 的学习曲线更为陡峭,因为它的模块化结构、功能丰富,以及许多独特的配置需要掌握,像蜘蛛(spiders)、中间件(middlewares)和管道(pipelines)等概念都需要时间去理解。Playwright 相对于有一定浏览器自动化经验的人来说会容易上手,因为它的 API 对他们更为熟悉。
动态内容处理
Scrapy 对使用 JavaScript 渲染的页面比较力不从心,只能处理静态 HTML 文档。如果需要处理动态内容,就必须与 Splash 或类似工具配合使用。Playwright 在处理动态或 JavaScript 渲染的页面方面有着天然优势,因为它会在浏览器中渲染页面。这意味着它可以抓取依赖 React、Angular 或 Vue 等客户端框架的网站。
定制与可扩展性
Scrapy 可通过中间件、扩展和管道实现高度定制,还有众多可用的插件与附加组件。Playwright 本身则没有提供类似的原生可扩展机制,但社区提供了 Playwright Extra 项目,弥补了这一不足。
其他爬虫功能
Scrapy 内置了代理集成、自动重试和可配置数据导出等功能,也为 IP 轮换和其他高级应用场景提供了集成方法。Playwright 也可支持代理集成及其他关键的爬虫功能,但需要更手动的配置才能达到与 Scrapy 类似的效果。
Playwright vs Scrapy:爬虫脚本示例对比
下面两个部分分别演示如何使用 Playwright 和 Scrapy 从同一个网站抓取数据。由于 Playwright 并非为爬虫专门设计,编写脚本的流程会较长,所以我们先从 Playwright 开始。
目标网站是 Books to Scrape 爬虫练习站点:
两个爬虫脚本都将抓取该站中所有“Fantasy”分类的书籍,这就需要处理分页。
Scrapy 会将页面视为静态网页并直接解析 HTML 文档;Playwright 则会在浏览器中渲染页面并与页面元素进行交互,模拟用户操作。
我们将用 Python 为 Scrapy 编写脚本,Playwright 则使用 JavaScript——这分别是这两个工具最常用的语言。当然,你也可利用playwright-python库,把 Playwright 的 JavaScript 代码转换为 Python,因为两者使用的 API 相同。
最后,这两个脚本都会将 Books to Scrape 上 Fantasy 分类下的所有书籍信息导出到一个 CSV 文件。
现在,让我们开始 Playwright vs Scrapy 的爬虫之战吧!
如何使用 Playwright 进行网络爬虫
按照下面步骤,用 JavaScript 编写一个简单的 Playwright 爬虫脚本。如果你对整个流程并不熟悉,可以先阅读我们的Playwright 爬虫指南。
步骤 #1:项目搭建
在开始之前,确保本地已安装最新版 Node.js,如果没有,请下载并按照向导进行安装。
然后创建一个 Playwright 爬虫项目文件夹并进入:
mkdir playwright-scraper
cd playwright-scraper在该文件夹中,通过以下命令初始化 npm 项目:
npm init -y现在可以用你喜欢的 JavaScript IDE(如 IntelliJ IDEA 或 Visual Studio Code)打开该文件夹,并创建一个 script.js 文件来存放爬虫逻辑:
好!此时你已完成 Node.js 下运行 Playwright 爬虫的基本搭建。
步骤 #2:安装与配置 Playwright
在项目文件夹中,运行以下命令安装 Playwright:
npm install playwright接着,安装浏览器及其他依赖:
npx playwright install然后在 script.js 中加入以下代码,以导入 Playwright 并启动一个 Chromium 浏览器实例:
const { chromium } = require("playwright");
(async () => {
// initialize a Chromium browser
const browser = await chromium.launch({
headless: false, // comment out in production
});
// scraping logic goes here...
// close the browser and release resources
await browser.close();
})();其中 headless: false 选项用于带界面启动浏览器,方便观察脚本的执行过程,常用于调试。
步骤 #3:连接到目标页面
创建一个新页面,并用 goto() 函数导航到目标页面:
const page = await browser.newPage();
await page.goto("https://books.toscrape.com/catalogue/category/books/fantasy_19/index.html");如果在关闭浏览器前打个断点并运行脚本,你就会看到浏览器被自动打开并转到该页面:
完美!Playwright 成功控制浏览器执行了相应操作。
步骤 #4:实现数据解析逻辑
在编写爬虫逻辑前,先要分析页面结构。用浏览器的隐私模式打开目标网站,右键点击某一本书的区域并选择“检查(Inspect)”。
在开发者工具(DevTools)里你会看到如下内容:
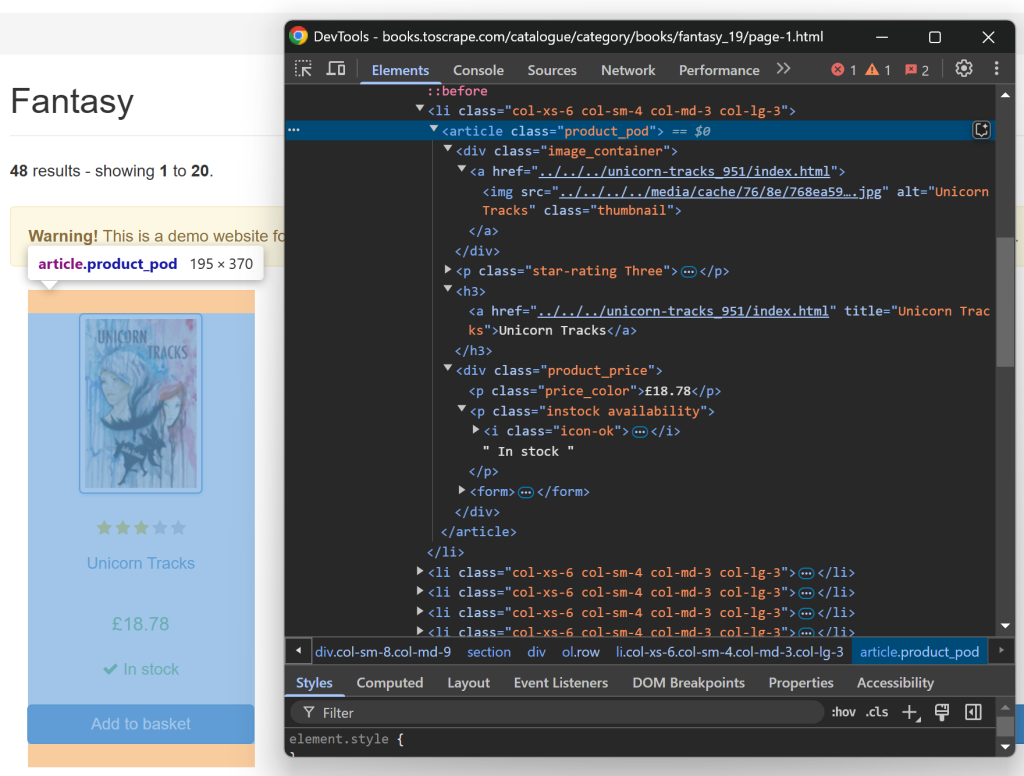
可以看到,每个书本元素的 CSS 选择器都是“.product_pod”。
由于页面包含多个书籍元素,先定义一个数组存储爬取的数据:
books = []接着选中页面上的这些元素并遍历:
const bookElements = await page.locator(".product_pod").all();
for (const bookElement of bookElements) {
// extract book details...
}从上图可以知道,每个书本区域中可提取的内容包括:
- 链接(从
<a>标签) - 书名(从
h3 a标签) - 封面(从
.thumbnail元素) - 评分(从
.star-rating元素) - 价格(从
.product_price .price_color元素) - 库存信息(从
.availability元素)
现在实现循环内的爬取逻辑:
const urlElement = await bookElement.locator("a").first();
const url = makeAbsoluteURL(
await urlElement.getAttribute("href"),
"https://books.toscrape.com/catalogue/"
);
const titleElement = await bookElement.locator("h3 a");
const title = await titleElement.getAttribute("title");
const imageElement = await bookElement.locator(".thumbnail");
const image = makeAbsoluteURL(
await imageElement.getAttribute("src"),
"https://books.toscrape.com/"
);
const ratingElement = await bookElement.locator(".star-rating");
const ratingClass = await ratingElement.getAttribute("class");
let rating;
switch (true) {
case ratingClass.includes("One"):
rating = 1;
break;
case ratingClass.includes("Two"):
rating = 2;
break;
case ratingClass.includes("Three"):
rating = 3;
break;
case ratingClass.includes("Four"):
rating = 4;
break;
case ratingClass.includes("Five"):
rating = 5;
break;
default:
rating = null;
}
const priceElement = await bookElement.locator(
".product_price .price_color"
);
const price = (await priceElement.textContent()).trim();
const availabilityElement = await bookElement.locator(".availability");
const availability = (await availabilityElement.textContent()).trim();上述代码中,getAttribute() 和 textContent() 用于提取节点属性和文本内容。需要注意的是,这里还针对评分实现了自定义的取值逻辑。
由于链接是相对路径,我们可以用以下函数把它转换为绝对路径:
function makeAbsoluteURL(url, baseURL) {
// use a regular expression to remove any ../ or ../../ patterns
const cleanURL = url.replace(/(../)+/, "");
// combine the base URL with the cleaned relative URL
return baseURL + cleanURL;
}
最后,将各字段写入一个对象并推入 books 数组:
const book = {
"url": url,
"title": title,
"image": image,
"rating": rating,
"price": price,
"availability": availability,
};
books.push(book);至此,Playwright 的数据解析逻辑已完成。
步骤 #4:实现爬取逻辑
如果你查看目标网站,会发现部分页面底部带有“next”按钮:
点击它即可跳转到下一页。如果已经是最后一页,“next”按钮就不会出现。
因此,你可以通过 while (true) 来实现爬取逻辑:
- 抓取当前页面的数据
- 如果“next”按钮存在,就点击并等待加载下一页
- 如果找不到“next”按钮,就退出循环
下面是具体实现:
while (true) {
// select the book elements ...
// select the "next" button and check if it is on the page
const nextElement = await page.locator("li.next a");
if ((await nextElement.count()) !== 0) {
// click the "next" button and go to the next page
await nextElement.click();
// wait for the page to have been loaded
await page.waitForLoadState("domcontentloaded")
} else {
break;
}
}好极了,爬取(翻页)逻辑完成。
步骤 #5:导出为 CSV
最后,将数据写入 CSV 文件。虽然可以用原生 Node.js 来操作,但借助 fast-csv 库会更简单。
先安装 fast-csv:
npm install fast-csv在脚本中导入:
const { writeToPath } = require("fast-csv");
然后在脚本末尾将数据写出到 CSV:
writeToPath("books.csv", books, { headers: true });
这样就完成了 Playwright 爬虫脚本的全部功能。
步骤 #6:完整脚本
你的 script.js 文件最终应如下所示:
const { chromium } = require("playwright");
const { writeToPath } = require("fast-csv");
(async () => {
// initialize a Chromium browser
const browser = await chromium.launch({
headless: false, // comment out in production
});
// initialize a new page in the browser
const page = await browser.newPage();
// visit the target page
await page.goto(
"https://books.toscrape.com/catalogue/category/books/fantasy_19/index.html"
);
// where to store the scraped data
books = [];
while (true) {
// select the book elements
const bookElements = await page.locator(".product_pod").all();
// iterate over them to extract data from them
for (const bookElement of bookElements) {
// data extraction logic
const urlElement = await bookElement.locator("a").first();
const url = makeAbsoluteURL(
await urlElement.getAttribute("href"),
"https://books.toscrape.com/catalogue/"
);
const titleElement = await bookElement.locator("h3 a");
const title = await titleElement.getAttribute("title");
const imageElement = await bookElement.locator(".thumbnail");
const image = makeAbsoluteURL(
await imageElement.getAttribute("src"),
"https://books.toscrape.com/"
);
const ratingElement = await bookElement.locator(".star-rating");
const ratingClass = await ratingElement.getAttribute("class");
let rating;
switch (true) {
case ratingClass.includes("One"):
rating = 1;
break;
case ratingClass.includes("Two"):
rating = 2;
break;
case ratingClass.includes("Three"):
rating = 3;
break;
case ratingClass.includes("Four"):
rating = 4;
break;
case ratingClass.includes("Five"):
rating = 5;
break;
default:
rating = null;
}
const priceElement = await bookElement.locator(
".product_price .price_color"
);
const price = (await priceElement.textContent()).trim();
const availabilityElement = await bookElement.locator(".availability");
const availability = (await availabilityElement.textContent()).trim();
// populate a new book item with the scraped data and
// then add it to the array
const book = {
"url": url,
"title": title,
"image": image,
"rating": rating,
"price": price,
"availability": availability,
};
books.push(book);
}
// select the "next" button and check if it is on the page
const nextElement = await page.locator("li.next a");
if ((await nextElement.count()) !== 0) {
// click the "next" button and go to the next page
await nextElement.click();
// wait for the page to have been loaded
await page.waitForLoadState("domcontentloaded");
} else {
break;
}
}
// export the scraped data to CSV
writeToPath("books.csv", books, { headers: true });
// close the browser and release resources
await browser.close();
})();
function makeAbsoluteURL(url, baseURL) {
// use a regular expression to remove any ../ or ../../ patterns
const cleanURL = url.replace(/(../)+/, "");
// combine the base URL with the cleaned relative URL
return baseURL + cleanURL;
}可以通过以下命令来运行:
node script.js脚本将会生成名为 books.csv 的文件:
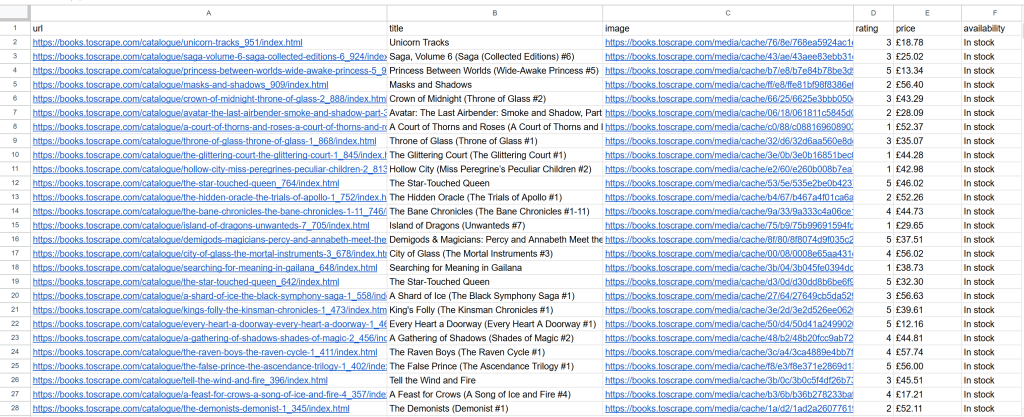
大功告成!接下来看看如何使用 Scrapy 实现同样的目标。
如何使用 Scrapy 进行网络爬虫
按照下述步骤,用 Scrapy 来构建一个简单的网络爬虫。想获取更详细的入门指导,可阅读我们的 Scrapy 爬虫教程。
步骤 #1:项目搭建
开始之前,确定本地已经安装了 Python 3。如果没有,请从 官网 下载并按安装向导操作。
创建一个项目文件夹,并在其中初始化 虚拟环境:
mkdir scrapy-scraper
cd scrapy-scraper
python -m venv venv在 Windows 上,使用以下命令激活虚拟环境:
venvScriptsactivate在类 Unix 或 macOS 上,运行:
source venv/bin/activate接着在激活的环境中安装 Scrapy:
pip install scrapy运行下面命令创建名为 “books_scraper” 的 Scrapy 项目:
scrapy startproject books_scraper至此,你已经完成了使用 Scrapy 进行网络爬虫的项目搭建。
步骤 #2:创建 Scrapy Spider
进入 Scrapy 项目文件夹,并为目标站点生成一个新的 spider:
cd books_scraper
scrapy genspider books books.toscrape.comScrapy 会自动生成所有需要的文件。books_scraper 文件夹下的整体结构现在应该像这样:
books_scraper/
│── __init__.py
│── items.py
│── middlewares.py
│── pipelines.py
│── settings.py
└── spiders/
│── __init__.py
└── books.py将 books_scraper/spiders/books.py 中的内容替换为以下代码:
import scrapy
class BooksSpider(scrapy.Spider):
name = "books"
allowed_domains = ["books.toscrape.com"]
start_urls = ["https://books.toscrape.com/catalogue/page-1.html"]
def parse(self, response):
# Extract book details
for book in response.css(".product_pod"):
yield {
"title": book.css("h3 a::attr(title)").get(),
"url": response.urljoin(book.css("h3 a::attr(href)").get()),
"image": response.urljoin(book.css(".thumbnail::attr(src)").get()),
"rating": book.css(".star-rating::attr(class)").get().split()[-1],
"price": book.css(".product_price .price_color::text").get(),
"availability": book.css(".availability::text").get().strip(),
}
# Handle pagination
next_page = response.css("li.next a::attr(href)").get()
if next_page:
yield response.follow(next_page, callback=self.parse)步骤 #3:运行 Spider
在 books_scraper 文件夹内,并且在已经激活的虚拟环境下,运行以下命令执行爬虫并将数据导出到 CSV:
scrapy crawl books -o books.csv这条命令将会生成一个名为 books.csv 的文件,其中包含了和 Playwright 版本相同的数据。再次大功告成!
Scrapy vs Playwright:该选哪个?
Playwright 的脚本需要六个较为复杂的步骤,而 Scrapy 只用三步就能完成。其原因在于 Scrapy 专为网络爬虫而生,而 Playwright 是通用的浏览器自动化工具,同时适用于测试和爬虫。
其中最大的差异表现在网页爬取(爬行)逻辑上:Playwright 需要手动编写与页面交互的逻辑(如翻页),而 Scrapy 只需简短几行代码即可完成自动化爬取。
简而言之,以下情况中更推荐使用 Scrapy:
- 你需要大规模的数据提取,并需要内置的爬取功能。
- 对性能和速度要求较高,因为 Scrapy 针对并发请求做了性能优化。
- 你更希望使用一个能自动处理分页、重试、数据格式导出及并行爬取的“三合一”框架。
而当以下情况出现时,可考虑 Playwright:
- 需要从大量依赖 JavaScript 渲染的网页提取数据。
- 需要处理诸如无限滚动等动态交互。
- 想对用户行为进行更深入的模拟(例如在复杂页面导航场景中)。
最后,我们用一张总结表格来进行对比:
| 功能 | Scrapy | Playwright |
|---|---|---|
| 开发方 | Zyte + 社区 | 微软 + 社区 |
| GitHub Stars | 54k+ | 69k+ |
| 下载量 | 每周约 38 万+ | 每周约 1200 万+ |
| 支持的编程语言 | Python | Python、JavaScript、TypeScript、C# |
| 主要用途 | 网络爬虫和爬取 | 浏览器自动化、测试及网络爬虫 |
| JavaScript 渲染 | ❌(可通过插件实现) | ✔️ |
| 浏览器交互 | ❌(可通过插件实现) | ✔️ |
| 自动化爬取 | ✔️ | ❌(需手动实现) |
| 代理集成 | 支持 | 支持 |
| 并行请求 | 并发高效,易于配置 | 有一定限制,但可实现 |
| 数据导出 | 内置支持 CSV、JSON、XML 等 | 需要编写自定义逻辑 |
Playwright 与 Scrapy 的局限性
虽然 Scrapy 与 Playwright 都是非常强大的爬虫工具,但它们也有其各自局限。
Scrapy 主要无法直接处理依赖 JavaScript 的动态内容,这对许多现代网站而言是个挑战;且在面对常见的反爬机制时也更脆弱。而 Playwright 虽能对 JS 渲染网站游刃有余,却仍可能遇到 IP 封锁的问题。
当发起过多请求时,很可能触发目标站点的限流机制,包括拒绝请求或封锁 IP。应对之道是集成网络代理轮换 IP。
若需要可靠的代理服务,Bright Data 的代理网络受到众多世界五百强企业及 2 万多位客户信赖,其网络包括:
- 数据中心代理:拥有超 770,000 个数据中心 IP。
- 住宅代理:覆盖超过 72 百万(千万级)住宅 IP 遍布 195+ 国家。
- ISP 代理:拥有超 700,000 个 ISP IP。
- 移动代理:超过 7 百万(千万级)移动 IP。
另外,Playwright 在遇到 CAPTCHA 时也会面临挑战,因为 CAPTCHA 旨在阻断在浏览器中执行的自动化脚本。为了解决这个问题,你可以使用Playwright 绕过 CAPTCHA 的方法。
结论
在本篇 Playwright vs Scrapy 博客中,我们了解了这两个库在网络爬虫中的不同作用、解析功能,并对比了它们在实际翻页场景中的表现。
Scrapy 为数据解析和网站爬取提供了完整的功能集,而 Playwright 则更专注于模拟用户操作。
我们也了解了它们在高并发爬取和 JavaScript 动态渲染、IP 封禁及 CAPTCHA 等方面的差异和面对的局限性。好在这些问题可通过代理或如 Bright Data 的CAPTCHA Solver 等专业反爬解决方案来应对。
立即注册一个免费 Bright Data 账号,探索我们的代理与爬虫解决方案吧!
支持支付宝等多种支付方式


