

在本指南中,你将了解到以下内容:
- Scrapy 和 Pyspider 是什么
- Scrapy 与 Pyspider 在网页抓取方面的对比
- 如何使用 Scrapy 和 Pyspider 进行网页抓取
- Scrapy 和 Pyspider 在实际场景中的共同局限性
让我们开始吧!
什么是 Scrapy?
Scrapy 是一个用 Python 编写的开源网页抓取框架。它的主要目标是快速高效地从网站提取数据。具体来说,Scrapy 能够:
- 定义如何在一个或多个网页之间导航并收集信息。
- 处理 HTTP 请求、链接追踪以及数据提取等方面的问题。
- 通过限速和异步请求来避免在抓取中被禁止访问。
- 通过自定义中间件或 代理轮换 以及
scrapy-rotating-proxies库管理代理和代理轮换。
什么是 Pyspider?
Pyspider 是一个用 Python 编写的开源网页爬虫框架。它的目标是在易用性和灵活性方面帮助你从网站提取数据,并提供了以下功能:
- 通过命令行或友好的 Web 界面来定义如何在一个或多个网页之间导航并采集信息。
- 处理任务调度、重试以及数据存储等方面的内容。
- 通过支持分布式抓取和任务优先级来限制阻塞。
- 通过内置对数据库和消息队列的支持来管理复杂的工作流和数据处理。
Scrapy vs Pyspider:网页抓取功能对比
现在你已经了解了 Scrapy 和 Pyspider 的基本概念,下面来对它们在网页抓取方面进行比较:
| 功能 | Scrapy | Pyspider |
|---|---|---|
| 适用场景 | 大规模、复杂的爬虫项目 | 定时抓取任务 |
| 抓取管理 | 命令行(CLI) | CLI 和 UI |
| 解析方式 | XPath 和 CSS 选择器 | CSS 选择器 |
| 数据保存 | 可导出数据到 CSV 等文件格式 | 自动保存到数据库 |
| 重试机制 | 需要手动干预进行重试 | 自动重试失败任务 |
| 任务调度 | 需要外部集成 | 原生支持 |
| 代理轮换 | 通过中间件支持代理轮换 | 需要手动干预 |
| 社区 | 拥有庞大社区,目前在 GitHub 上已获得 54k+ star,并有活跃贡献 | 有较多用户,目前在 GitHub 上收获了 16k+ star,但已于 2024 年 6 月 11 日存档 |
从上述对比表可见,这两个库在很多方面都很相似。它们在高层次上有以下主要差异:
- Scrapy 只能通过 CLI 使用,而 Pyspider 同时提供了 UI。
- Scrapy 能解析 XPath 和 CSS 选择器,而 Pyspider 只支持 CSS 选择器。
- Scrapy 能通过自定义中间件逻辑自动支持代理轮换。
但是,需要特别注意的是,Pyspider 已不再维护:

Scrapy vs Pyspider:直接抓取对比
在比较 Scrapy 与 Pyspider 之后,你会发现二者都提供了类似的网页抓取功能。因此,最好的方式就是通过实际的代码示例来进行对比。
接下来两个章节展示如何使用 Scrapy 和 Pyspider 抓取同一个网站。具体来说,目标页面是 Scrape This Site 上的 “Hokey Teams” 页面。该页面包含以表格形式呈现的曲棍球数据:
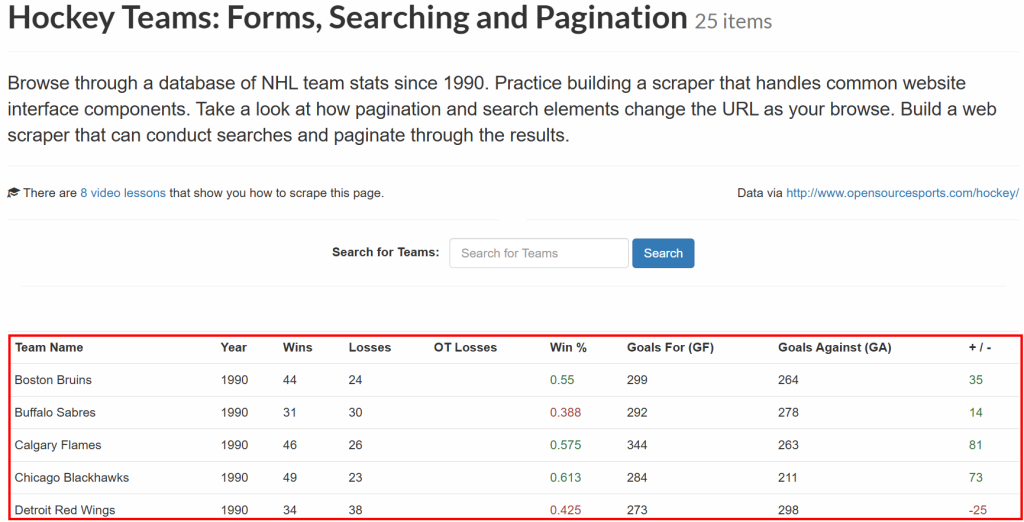
本节的目标是获取该表格里的所有数据,并将其保存在本地。让我们来看看如何操作吧!
如何使用 Scrapy 进行网页抓取
本段将演示如何使用 Scrapy 抓取目标网站中的所有表格数据。
环境要求
确认你的机器上安装了 Python 3.7 及以上版本。
步骤 #1:建立环境并安装依赖
假设你将项目的主文件夹命名为 hockey_scraper/。本步骤结束后,该文件夹结构如下:
hockey_scraper/
└── venv/
你可以使用如下命令创建 venv/ 虚拟环境目录:
python -m venv venv在 Windows 上,激活该虚拟环境的方法为:
venvScriptsactivate在 macOS/Linux 上,则执行:
source venv/bin/activate现在,可以使用以下命令安装 Scrapy:
pip install scrapy步骤 #2:创建一个新的项目
现在,你可以启动一个新的 Scrapy 项目。在 hockey_scraper/ 主文件夹下,输入:
scrapy startproject hockey
运行此命令后,Scrapy 会在当前目录下创建一个名为 hockey/ 的文件夹,并自动生成所有所需文件。此时文件夹结构如下:
hockey_scraper/
├── hockey/ # Scrapy 项目主体文件夹
│ ├── __init__.py
│ ├── items.py # 定义爬取数据的结构
│ ├── middlewares.py # 自定义中间件
│ ├── pipelines.py # 处理爬取后的数据
│ ├── settings.py # 项目配置
│ └── spiders/ # 放置所有爬虫文件的文件夹
├── venv/
└── scrapy.cfg # Scrapy 配置文件
步骤 #3:生成爬虫
要生成一个新的爬虫文件来抓取目标网站,先进入 hockey/ 文件夹:
cd hockey然后使用以下命令生成一个新的爬虫:
scrapy genspider data https://www.scrapethissite.com/pages/forms/在此命令中,data 是爬虫的名字。Scrapy 会自动在 spiders/ 文件夹内创建一个名为 data.py 的文件,并在其中包含抓取 “Hokey Teams” 数据的爬虫逻辑。
步骤 #4:定义抓取逻辑
现在开始编写爬虫逻辑。首先,在浏览器里查看包含目标数据的表格。可以看到,这些数据都包含在 .table 元素中:

要获取所有数据,可在 data.py 文件中添加以下代码:
import scrapy
class DataSpider(scrapy.Spider):
name = "data"
allowed_domains = ["www.scrapethissite.com"]
start_urls = ["https://www.scrapethissite.com/pages/forms/"]
def parse(self, response):
for row in response.css("table.table tr"):
yield {
"name": row.css("td.name::text").get(),
"year": row.css("td.year::text").get(),
"wins": row.css("td.wins::text").get(),
"losses": row.css("td.losses::text").get(),
"ot_losses": row.css("td.ot-losses::text").get(),
"pct": row.css("td.pct::text").get(),
"gf": row.css("td.gf::text").get(),
"ga": row.css("td.ga::text").get(),
"diff": row.css("td.diff::text").get(),
}
注意,name、allowed_domains 和 start_urls 这几个变量都是 Scrapy 在前一步自动创建的。
同理,parse() 方法也是 Scrapy 自动生成的,你只需在其中的 for 循环里添加上面展示的抓取逻辑即可。
代码中,response.css() 方法用于选择表格,然后循环所有行并抓取每一行的数据。
步骤 #5:运行爬虫并将数据保存为 CSV 文件
要运行爬虫并将结果保存到 CSV 文件,可执行:
scrapy crawl data -o output.csv通过这个命令,Scrapy 将:
- 运行包含抓取逻辑的
data.py文件 - 将抓取到的数据保存到名为
output.csv的文件中
爬虫产生的 output.csv 文件应当如下所示:
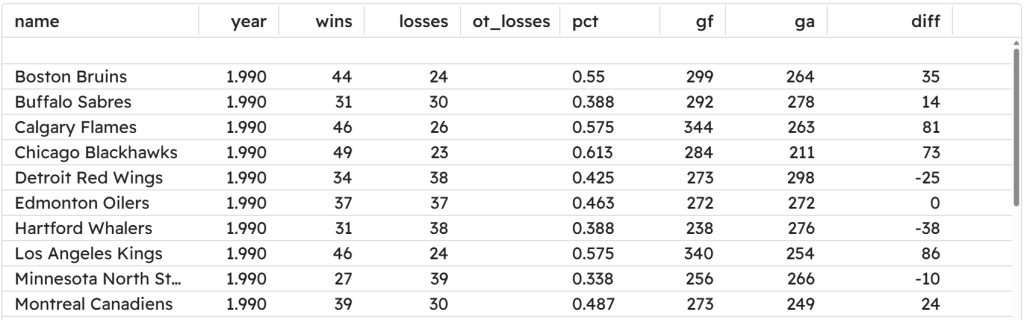
需要注意的是,上述用法是最简洁的方式,Scrapy 还提供了更多的定制化配置。如果需要,你可以在我们的文章 Scrapy vs Requests 中了解更多相关信息。
如何使用 Pyspider 进行网页抓取
下面我们来看看如何使用 Pyspider 抓取同样的目标网站。
环境要求
Pyspider 最多只支持 Python3.6。如果你安装了更新的 Python 版本,请阅读下一步,了解如何针对 Python 3.6 进行操作。
步骤 #1:建立环境并安装依赖
假设你将项目的主文件夹依旧命名为 hockey_scraper/。
如果你的系统上是 Python 3.7 或以上版本,可使用 pyenv 来安装 Python 3.6。
在命令行中使用 pyenv 安装 Python 3.6:
pyenv install 3.6.15然后将它设为本地 Python 版本,以便不会影响系统全局 Python:
pyenv local 3.6.15通过以下命令验证你正在使用的 Python 版本:
python --version输出应该是:
Python 3.6.15接下来使用带有 Python 3.6 的命令创建虚拟环境:
python3.6 -m venv venv和前面一样,激活该虚拟环境后,你就可以安装 Pyspider:
pip install pyspider然后运行以下命令启动 Pyspider 的 UI:
pyspider由于该仓库已被归档,同时你使用的是 Python 3.6,可能会出现一些错误。你可以用以下命令安装一些特定版本的依赖,以解决问题:
pip install tornado==4.5.3 requests==2.25.1如果依旧出现 webdav.py 相关错误,请在此文件中进行以下修改:
- 在
ScriptProvider()类中,将方法getResourceInst()重命名为get_resource_inst()。 - 在文件底部找到
config = DEFAULT_CONFIG.copy(),将后续内容替换为:
config = DEFAULT_CONFIG.copy()
config.update({
"mount_path": "/dav",
"provider_mapping": {
"/": ScriptProvider(app)
},
"domaincontroller": NeedAuthController(app),
"verbose": 1 if app.debug else 0,
"dir_browser": {"davmount": False,
"enable": True,
"msmount": False,
"response_trailer": ""},
})
dav_app = WsgiDAVApp(config)完成上述修改后,Pyspider 的 Web UI 应该可以正常启动了。访问 http://localhost:5000/,你应看到如下界面:
步骤 #2:创建新项目
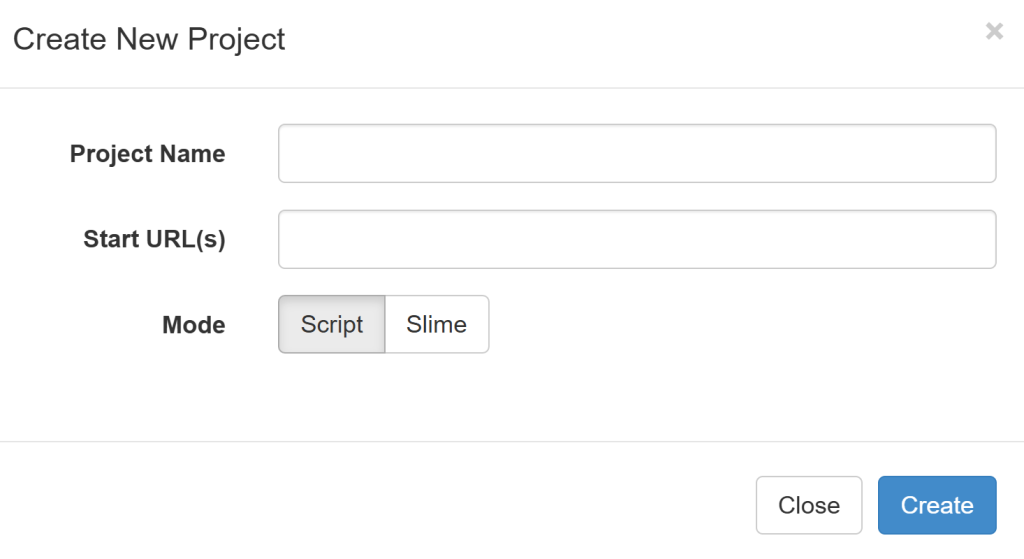
点击 “Create” 按钮以创建一个新项目,并填写相关字段:
- 你可以任意设置项目名称,例如
Hockey_scraper。 - 在 start URL(s) 中填写
https://www.scrapethissite.com/pages/forms/。
最终结果如下所示:
步骤 #3:定义抓取逻辑
直接在右侧编辑器里书写爬虫逻辑:
from pyspider.libs.base_handler import *
from pyspider.libs.base_handler import *
class Handler(BaseHandler):
crawl_config = {}
@every(minutes=24 * 60)
def on_start(self):
self.crawl("https://www.scrapethissite.com/pages/forms/", callback=self.index_page)
@config(age=10 * 24 * 60 * 60)
def index_page(self, response):
for each in response.doc("table.table tr").items():
self.crawl(each.attr.href, callback=self.detail_page)
@config(priority=2)
def detail_page(self, response):
return {
"name": row.css("td.name::text").get(),
"year": row.css("td.year::text").get(),
"wins": row.css("td.wins::text").get(),
"losses": row.css("td.losses::text").get(),
"ot_losses": row.css("td.ot-losses::text").get(),
"pct": row.css("td.pct::text").get(),
"gf": row.css("td.gf::text").get(),
"ga": row.css("td.ga::text").get(),
"diff": row.css("td.diff::text").get(),
}
上面与默认代码的区别在于:
- 使用
response.doc()方法找到目标表格。 detail_page()返回通过row.css()方法采集到的表格行数据。
点击 “Save” 和 “Run” 即可启动抓取流程。最终得到的数据与使用 Scrapy 抓取的结果类似。
不错!你已经学会了如何使用 Scrapy 和 Pyspider 进行网页抓取。
Scrapy vs Pyspider:该用哪个?
通过比较,你已经了解了如何使用 Scrapy 和 Pyspider,但二者谁更好?让我们来选出适合你的场景吧!
在以下情况选择 Scrapy:
- 需要高性能的项目,要求并行爬取和高级功能(如限速)。
- 需要与外部管道或其他工具集成。
- 熟悉命令行操作并有一定的抓取经验,倾向于使用一个随时保持更新的框架。
在以下情况选择 Pyspider:
- 你更喜欢使用 UI 而不是命令行。
- 你想使用分布式架构,并且偏好简单的配置。
- 你想 定时安排抓取任务。
总的来说,并没有绝对意义上的最佳选择——具体选哪个要看你的需求和使用场景。
Scrapy 和 Pyspider 的局限性
Scrapy 和 Pyspider 都是强大的网页抓取框架,但它们也都有局限性。
首先,对于使用 JavaScript 渲染或获取数据的 动态网站,二者都比较吃力。尽管可以使用扩展来抓取动态内容,但从底层看,它们并非为此而设计,这也让它们更容易被 反爬措施所阻挡。
其次,这两个框架都需要进行大量自动化请求,容易导致 IP 被禁(禁止访问)。如果超出网站的抓取频率限制,就可能触发封禁。解决办法是在代码中 集成代理。
关于代理轮换的更多信息,可见我们关于 在 Python 中使用代理轮换 IP 地址 的教程。
最后,如果你需要稳定可靠的代理服务器,不妨试试 Bright Data 的代理网络。它拥有多种类型,被世界 500 强企业和超过 20,000 家用户所信赖,包括:
- 数据中心代理:超过 770,000 个数据中心 IP
- 住宅代理:超过 72,000,000 个住宅 IP,覆盖全球 195+ 国家
- ISP 代理:超过 700,000 个 ISP IP
- 移动代理:超过 7,000,000 个移动端 IP
结论
通过这篇 Scrapy vs Pyspider 的文章,你已经了解了这两个库在网页抓取中的角色;也学到了它们在数据提取中的各种特性,以及在实际生产场景中的一些对比。
Pyspider 虽提供了友好的可视化界面,但已停止维护;而 Scrapy 适合大规模项目,且通常集成了大部分需要的工具,并始终保持与新版 Python 的兼容。
同时,你也知道了它们共同的局限性,如可能被 IP 封禁。不过,可以通过 代理 或者像 Bright Data 的 网络抓取API 此类专注于网页抓取的解决方案来解决这些问题。Bright Data 的 Web Scraper API 能够无缝集成到 Scrapy、Pyspider 或任何其他 HTTP 客户端和爬虫工具中,实现不受限制的数据抓取。
立即注册免费的 Bright Data 账户,探索我们的代理和爬虫 API 吧!
支持支付宝等多种支付方式



