

在这篇 XPath 与 CSS 选择器指南中,您将了解到:
- XPath 表达式是什么、如何工作及其优点和缺点。
- CSS 选择器是什么、如何工作及其优缺点。
- XPath 表达式与 CSS 选择器在性能、简洁性和使用案例方面的比较。
现在开始深入了解吧!
XPath:全面分析
让我们从比较的第一个元素 XPath 开始,深入了解这篇 XPath 与 CSS 选择器指南。
定义
XPath 是 XML 路径语言的缩写,是一种用于导航和查询 DOM 的查询语言。它提供了一种强大的方法来定位和提取 XML/HTML 文档中的信息。
XPath 的语法类似于文件系统,依赖表达式来定位 XML/HTML 树中的节点。XPath 表达式定义了文档层次结构中特定元素和属性的路径。
语法
以下是 XPath 语法的关键组件的详细说明:
/:从根节点开始选择节点。//:选择匹配选择的当前节点及其所有子节点,无论它们的位置。.:选择当前节点。..:选择当前节点的父节点。@:选择节点属性。element:基于特定标签选择节点(例如div)。[condition]:基于指定条件选择节点(例如[@type="submit"])。function():在表达式上应用特定的 XPath 函数(例如text()返回所选节点的文本内容)。
以下是一些示例,以更好地理解 XPath 的语法:
//a:选择文档中的所有<a>元素。//ul/li:选择所有<li>元素,这些元素是<ul>元素的子元素。//ul/..:选择所有<ul>元素的父节点。//ul/li[@category='fiction']:选择所有<ul>标签下的<li>元素,这些元素的category属性值为'fiction'。//title[@lang='en']:选择文档中所有<title>元素,这些元素的lang属性值为'en'。//title/text():检索文档中所有<title>元素的文本内容。//div[contains(@class, 'post')]/following-sibling::div[1]:选择每个包含类'post'的<div>元素的第一个兄弟<div>元素。
请注意,XPath 表达式还支持布尔和算术运算符,以组合多个函数和条件。
优点
- 高灵活性:它允许您导航 XML 和 HTML 结构,精确定位元素、属性和文本节点。它还支持 DOM 的前后遍历以及父节点和兄弟节点的选择。
- 丰富的函数和运算符:它具有一套丰富的内置函数(例如
contains()、concat()、count()等)和 运算符 (例如+、or、and等)用于操作和比较 XML/HTML 文档中的数据。 - 支持绝对路径和相对路径:XPath 表达式描述从文档根目录(绝对路径)或特定元素(相对路径)到所需节点的路径。
- 支持文本节点选择:它允许直接选择文本节点,从 XML/HTML 文档中提取文本内容,无需额外处理或解析。
- 平台独立性:它不依赖于特定的编程语言或平台,支持广泛的环境、库、浏览器和操作系统。
缺点
- 复杂且冗长的语法:XPath 的语法可能很复杂,尤其是对于初学者来说。编写一个深度嵌套在 DOM 中的特定节点的路径可能会导致一个长表达式,可能涉及一些函数和运算符。这使得 XPath 表达式容易出错且难以调试。
- 支持和流行度有限:并非所有的 HTML 解析库 都支持 XPath。因为 CSS 选择器在 Web 开发者中更受欢迎,库往往会专注于它们。此外,大多数基于 XPath 的库(如 HtmlAgilityPack)仍依赖于 1999 年发布的 XPath 1.0。目前的版本是 2017 年发布的 XPath 3.1。阅读我们的 HtmlAgilityPack 指南,成为 使用 C# 进行 Web 抓取的专家。
技巧和窍门
Chrome 允许您直接在浏览器中测试和检索 XPath 表达式。
假设您有兴趣选择网页上的特定元素。在 Chrome 中访问它,右键单击感兴趣的节点,然后选择“检查”:
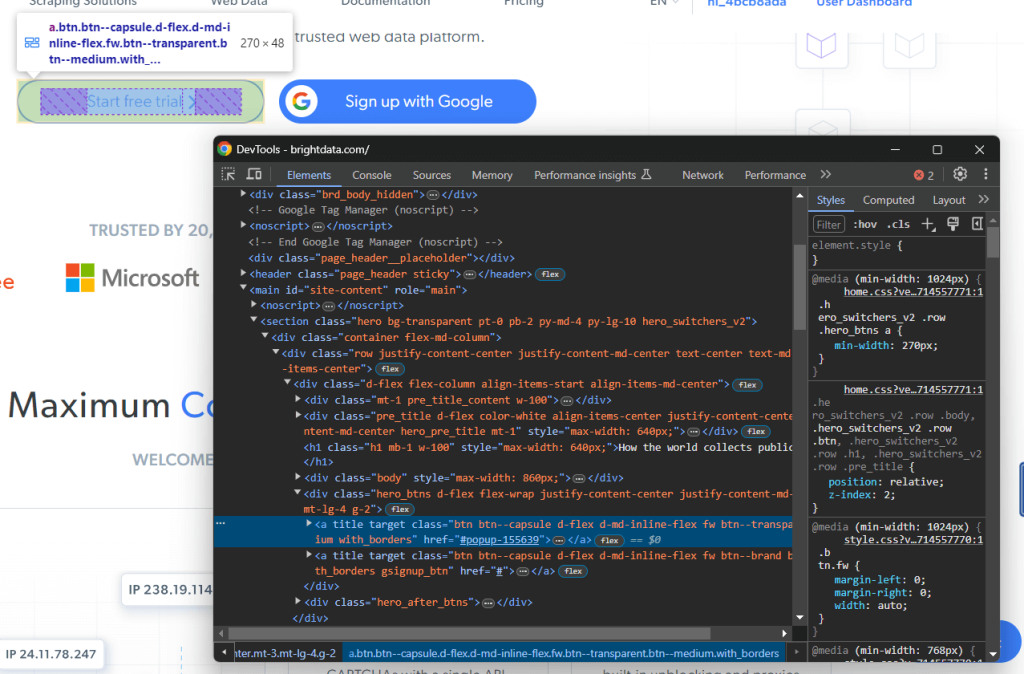
右键单击特定的 DOM 元素,然后选择“复制 > 复制 XPath”以获取它的 XPath 表达式。在上面的示例中,您将获得:
//*[@id="site-content"]/section[1]/div/div/div[1]/div[4]/a[1]
注意:这对于构建有效的 XPath 选择策略非常有用。同时,自动生成的 XPath 表达式往往过长且面向实现。因此,不能在生产中依赖它们。
现在,您想要在页面上测试一个 XPath 表达式。在 Chrome 中,有两种方法可以做到这一点。
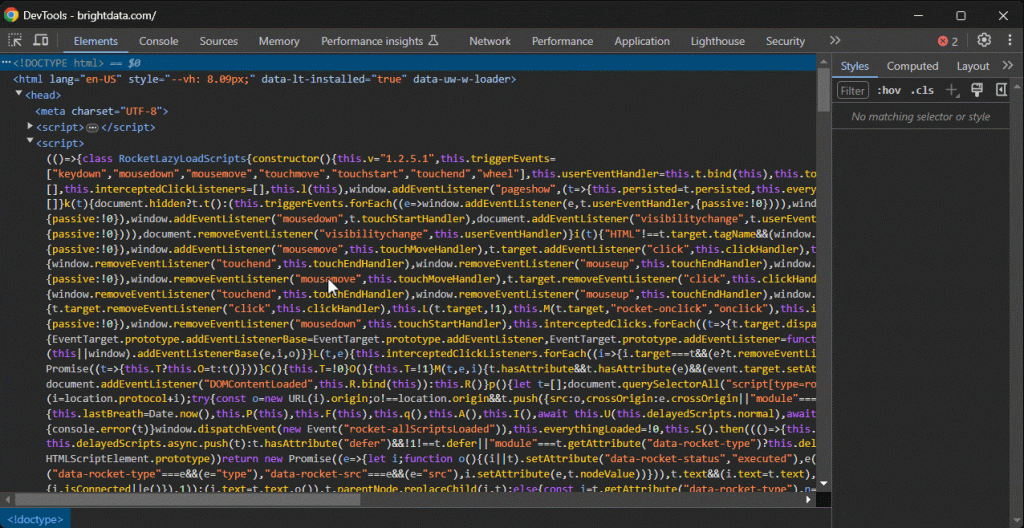
首先,将 XPath 表达式粘贴到 DevTools 的“元素”部分的搜索栏中,可以通过 CTRL/Command + F启用:
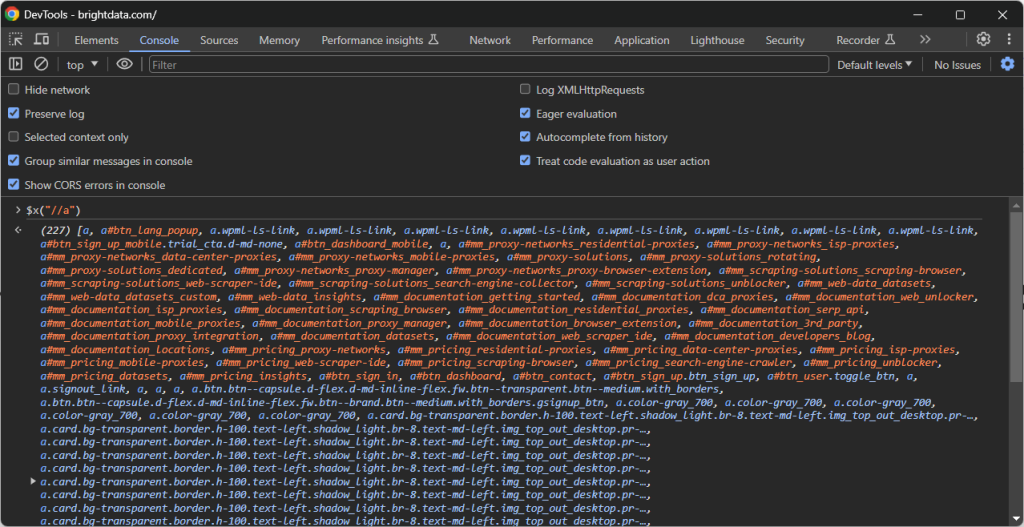
第二种方法是在控制台中调用特殊函数 $x():
CSS 选择器:深入评测
继续这篇 XPath 与 CSS 选择器文章,探索比较的第二个元素 CSS 选择器。
定义
CSS 选择器 使您能够选择网页中的 HTML 元素。它们是 CSS 的一部分,用于定位网页上的 HTML 元素。同样,无头浏览器工具 和 HTML 解析库也支持它们作为选择 DOM 上的节点的一种方式。
CSS 选择器可以根据元素的 ID、类、属性和在文档树中的位置来定位单个元素或元素组。虽然 CSS 选择器在应用样式和格式化网页时发挥着重要作用,但在 网络抓取 时它们也是一个很好的工具。
语法
解释 CSS 选择器语法的最佳方法是通过一些示例来展示:
- 元素选择器:根据标签名称选择元素。例如,
p选择 DOM 中的所有<p>元素。 - 类选择器:选择具有特定类属性的元素。例如,
.highlight选择所有带有class="highlight <other_classes>"HTML 属性的元素。 - ID 选择器:选择具有特定 ID 属性的元素。例如,
#navbar选择 ID 为navbar的元素。 - 属性选择器:根据属性选择元素。例如,
input[type="text"]选择所有<input>元素,这些元素具有type="text"属性。 - 后代选择器:选择作为另一个元素的后代的元素。例如,
div a选择所有作为<div>元素后代的<a>元素。 - 子选择器:选择作为另一个元素的直接子元素的元素。例如,
ul > li选择所有作为<ul>元素直接子元素的<li>元素。 - 相邻兄弟选择器:选择紧接在指定兄弟元素之后的元素。例如,
h2 + p选择紧接在<h2>元素之后的<p>元素。
请记住,不同浏览器对 CSS 标准的实现不同。请访问 caniuse.com 等网站,了解特定 CSS 操作符或语法的兼容性。
优点
- 性能优异:大多数浏览器都有一个专用的 CSS 选择器引擎,确保高性能。此引擎主要用于样式,但在通过浏览器自动化工具在页面上使用 CSS 选择器时也很有用。
- 易于学习:掌握 CSS 选择器的曲线非常平缓,即使是初学者也能轻松掌握其直观的语法。
- 简洁且广为人知的语法:它们具有简洁的语法,不涉及复杂的操作符或函数。此外,大多数 Web 开发人员都知道如何使用它们,这使得它们不仅可以用于样式。
- 易于维护:CSS 选择器设计为易于阅读和更新,简化了代码维护。
- 总体兼容性:现代 Web 浏览器和最佳网络抓取工具 支持它们。这确保了在不同平台、设备和用例中一致的节点选择,而无需特定环境的变通方法。
缺点
- 不支持高级函数和操作符:与 XPath 相比,CSS 选择器非常简单,没有许多函数或操作符。例如,您不能使用它们选择文本节点或从 DOM 中提取数据。
- 不支持向上遍历 DOM 树:它们只能从根节点向下查找 DOM 中的元素。
技巧和窍门
与 XPath 类似,Chrome 可以直接在页面上测试和生成 CSS 选择器。
假设您有兴趣编写一个 CSS 选择器来定位特定节点。在 Chrome 中访问目标页面,右键单击感兴趣的元素,然后选择“检查”:
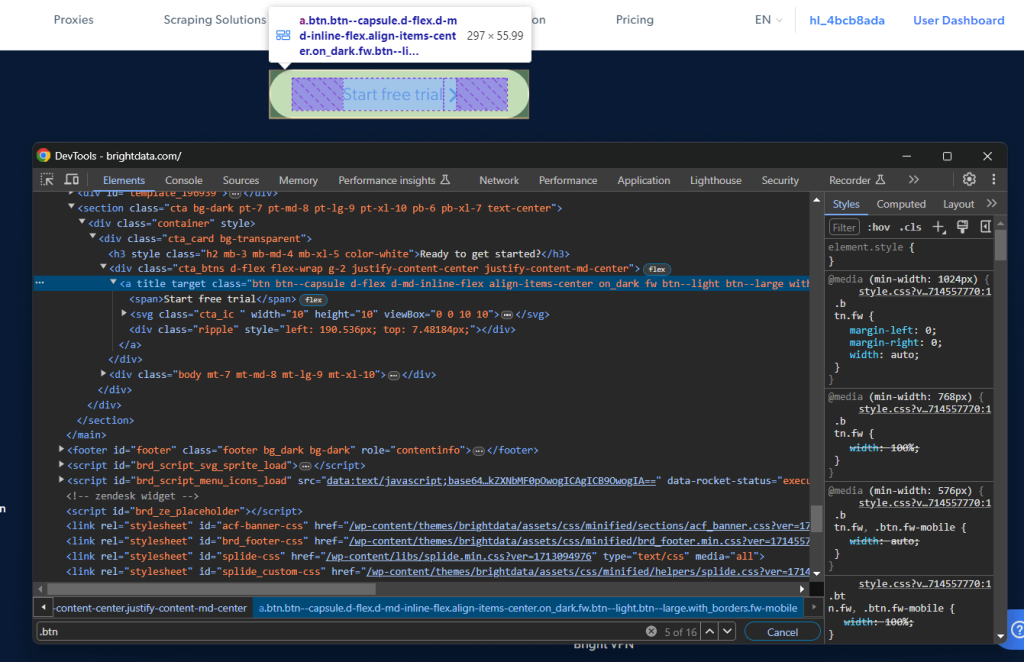
右键单击特定的 DOM 元素,然后选择“复制 > 复制选择器”以获取它的完整 CSS 选择器。在上面的示例中,您将收到:
#site-content > section.cta.bg-dark.pt-7.pt-md-8.pt-lg-9.pt-xl-10.pb-6.pb-xl-7.text-center > div > div > div.cta_btns.d-flex.flex-wrap.g-2.justify-content-center.justify-content-md-center > a
如您所见,它过长且面向实现。虽然它有助于了解如何构建有效的 CSS 选择策略,但请不要在生产中使用此功能生成的 CSS 选择器。
假设您需要在网页上测试一个 CSS 选择器。在 Chrome 中,有几种方法可以 做到这一点。
第一种方法是将 CSS 选择器粘贴到搜索栏中,如下所示,可以通过 CTRL/Command + F 快捷键启用:
第二种方法是在控制台中使用这些特殊函数测试它们:
像下面的示例一样使用它们:
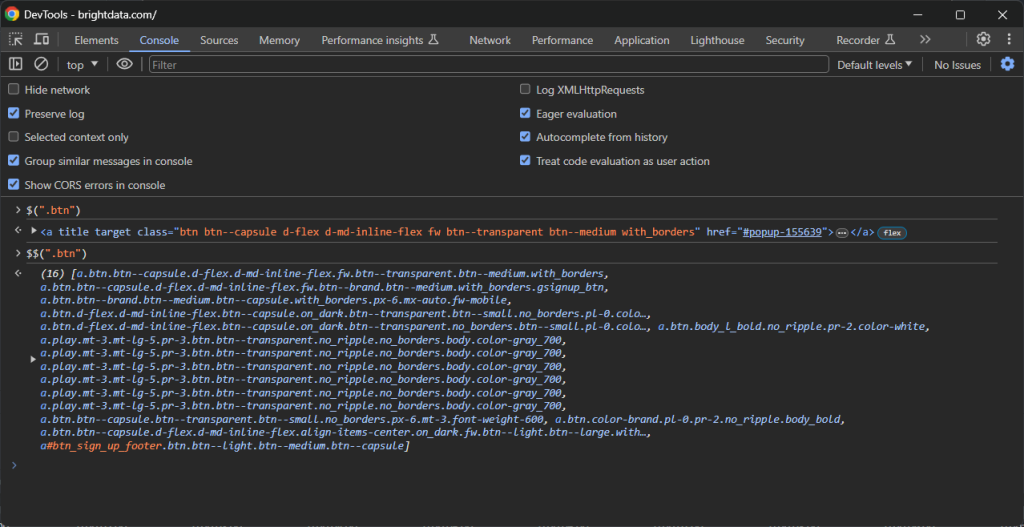
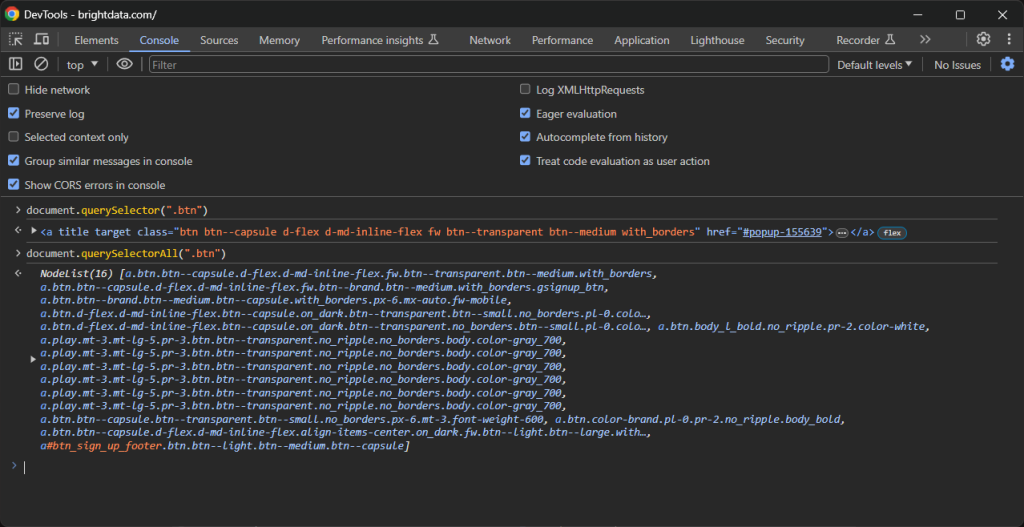
同样,您可以使用 querySelector() 和 querySelectorAll() JavaScript 函数:
XPath 与 CSS 选择器:直接比较
现在您已经知道了 XPath 和 CSS 选择器是什么,您可以深入了解 XPath 与 CSS 选择器的分析了。
要一目了然地进行对比,请查看下面的总结表:
| 方面 | XPath | CSS 选择器 |
| W3C 标准 | 是 | 是 |
| 最新规范 | XPath 3.1 (2017) | CSS Level 4(不断更新) |
| 兼容性 | 大多数浏览器和抓取工具仍支持 XPath 1.0 | 大多数浏览器和抓取工具支持其最新规范 |
| 语法 | 复杂且冗长 | 简单且简洁 |
| 函数和运算符 | 很多 | 很少 |
| 文本节点选择 | 支持 | 不支持 |
| 浏览器中的性能 | 中等/慢 | 快 |
| 库支持 | 通常由 XML 解析库支持 | 通常由大多数 HTML 解析库支持 |
简洁性
与 CSS 选择器相比,XPath 语法通常显得更加复杂。其语法类似于基于路径的查询语言,对于不熟悉它的开发人员来说,学习曲线较陡。然而,XPath 提供了对元素选择和遍历的精确控制。
CSS 选择器在选择 DOM 元素时通常更简单、更直观。它们使用熟悉的模式,如标签名称、类和 ID,使其易于理解和使用,即使是初学者。CSS 选择器在 Web 开发中被广泛采用,使得其语法非常熟悉。
速度
如基准测试所示,在浏览器中应用于 DOM 树的 XPath 表达式往往比 CSS 选择器慢。原因是 XPath 引擎通常需要执行比 CSS 选择器引擎更复杂的遍历操作。此外,大多数现代浏览器都有高度优化的 CSS 选择器引擎,使得 HTML 元素选择效率很高。至于 HTML 解析库,性能差异取决于底层实现。
使用案例
XPath 适用于使用 XSLT 查询和导航 XML 文档或简单的数据提取。其高级功能在特定的抓取场景中可能很有用,例如在定位父节点时。CSS 选择器主要用于样式化 HTML 文档和在现代 Web 抓取脚本中选择节点。
结论
XPath 还是 CSS 选择器?在这篇 XPath 和 CSS 选择器指南中,您了解到它们都是选择 DOM 元素的有效方法。XPath 更侧重于 XML 文档,并提供高级功能,而 CSS 选择器在 HTML 页面上表现出色且更简单。
在网络抓取中使用 XPath 表达式和 CSS 选择器时,真正的问题是被反爬虫技术阻止。无论您采用哪种节点选择策略,这些系统都可以检测并阻止您的自动抓取脚本。幸运的是,Bright Data 为您提供了几种顶级解决方案:
- Web Scraper API:易于使用的 API,可编程访问来自数十个热门域的结构化 Web 数据。
- Scraping Browser:一个基于云的可控浏览器,提供 JavaScript 渲染功能,同时处理 CAPTCHA、浏览器指纹、自动重试等。它集成了最流行的自动化浏览器库,如 Playwright 和 Puppeteer。
- Web Unlocker:一个解锁 API,可以无缝返回任何页面的原始 HTML,绕过任何反爬措施。
不想处理网络抓取,但仍然对在线数据感兴趣? 探索我们的即用数据集!


