

当你在抓取网页时,你经常会遇到分页的情况,即内容分布在多个页面上。处理这种分页可能具有挑战性,因为不同的网站使用不同的分页技术。
在本文中,我将解释常见的分页技术,并通过一个实用的代码示例展示如何处理它们。
什么是分页?
像电子商务平台、招聘网站和社交媒体等网站使用分页来管理大量数据。如果将所有内容显示在一个页面上,会显著增加加载时间并消耗过多内存。分页将内容分布在多个页面上,并提供诸如“下一页”、页码或滚动时自动加载的导航选项。这使得浏览更快、更有组织。
分页类型
分页的复杂性各不相同,从简单的数字分页到更高级的技术,如无限滚动或动态内容加载。根据我的经验,我遇到了三种主要的分页类型,我认为它们是网站上最常用的:
- 数字分页:用户通过数字链接导航到不同的页面。
- 点击加载分页:用户点击一个按钮(例如“加载更多”)来加载更多内容。
- 无限滚动:用户向下滚动页面时内容自动加载。
让我们更详细地探讨一下每种分页方式!
数字分页
这是最常见的分页技术,通常称为“下一页和上一页分页”、“箭头分页”或“基于 URL 的分页”。尽管名称不同,但核心思想相同——页面通过数字链接进行连接。你可以通过更改 URL 中的页码来导航。要知道何时停止分页,你可以检查“下一页”按钮是否被禁用或是否没有新数据可用。
通常看起来是这样的:

`让我们举个例子!我们将浏览网站 Scrapethesite 上的所有页面。该网站的分页栏共有 24 页。

你会注意到,当你点击“>>”按钮时,URL 会发生如下变化:
- 第一页:https://www.scrapethissite.com/pages/forms/
- 第二页:https://www.scrapethissite.com/pages/forms/?page_num=2
- 第三页:https://www.scrapethissite.com/pages/forms/?page_num=3
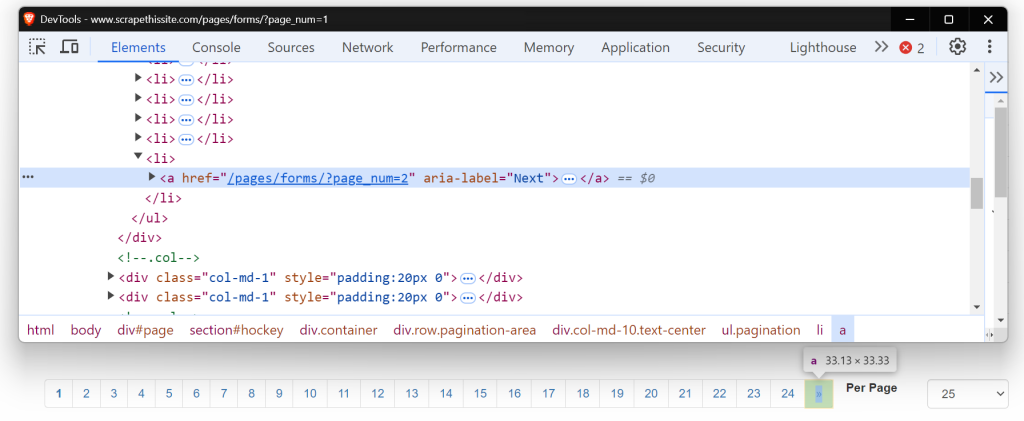
现在,看看这个“下一页”按钮的 HTML。它是一个带有 href 属性的锚标签(<a>),链接到下一页。aria-label 属性显示“下一页”按钮仍然是活动的。
当没有更多页面时,aria-label 将缺失,显示分页的结束。
让我们从编写一个基本的网页抓取器开始,导航这些页面。首先,通过安装所需的包来设置你的环境。有关使用 Python 进行网页抓取的详细指南,你可以查看深入的博客文章 这里。
pip install requests beautifulsoup4 lxml以下是分页浏览每个页面的代码:
import requests
from bs4 import BeautifulSoup
base_url = "https://www.scrapethissite.com/pages/forms/?page_num="
# Start with page 1
page_num = 1
while True:
url = f"{base_url}{page_num}"
response = requests.get(url)
soup = BeautifulSoup(response.content, "lxml")
print(f"Currently on page: {page_num}")
# Check if 'Next' button exists
next_button = soup.find("a", {"aria-label": "Next"})
if next_button:
# Move to the next page
page_num += 1
else:
# No more pages, exit loop
print("Reached the last page.")
break这段代码通过检查是否存在带有 aria-label="Next" 的“下一页”按钮来导航页面。如果按钮存在,它会增加 page_num 并使用更新后的 URL 发送新的请求。循环将继续,直到不再找到“下一页”按钮,表明已经到达最后一页。
运行代码,你会看到我们已成功浏览了所有页面。

一些网站的“下一页”按钮不会更改 URL,但仍在同一页面上加载新内容。在这种情况下,传统的网页抓取方法可能效果不佳。像 Selenium 或 Playwright 这样的工具更适合,因为它们可以与页面交互并模拟点击按钮等操作,以检索动态加载的内容。有关使用 Selenium 进行此类任务的更多信息,你可以阅读详细指南 这里。
当你尝试抓取 NGINX 博客页面时,你会遇到类似的情况。
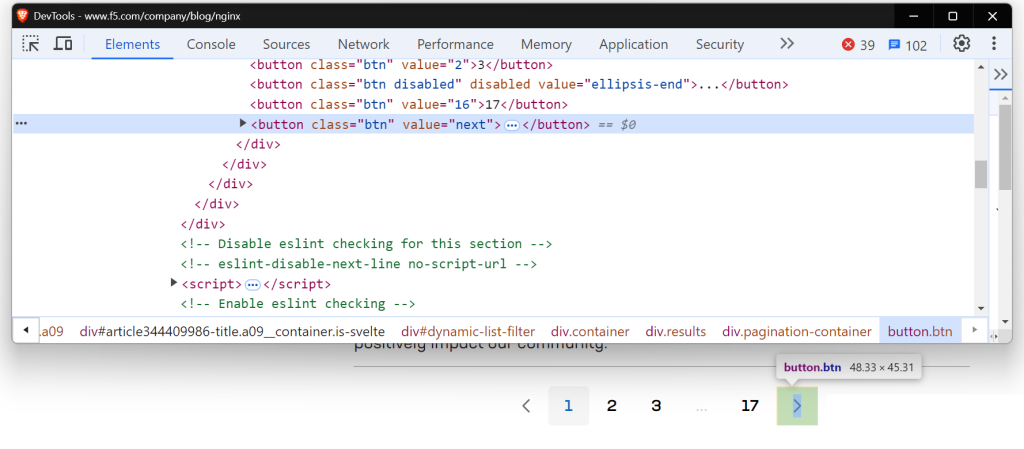
让我们使用 Playwright 来处理动态加载的内容。如果你是 Playwright 新手,可以查看这个有用的 入门指南。
现在,在编写代码之前,运行以下命令在你的机器上设置 Playwright:
pip install playwright
playwright install以下是代码:
import asyncio
from playwright.async_api import async_playwright
# Define an asynchronous function
async def scrape_nginx_blog():
async with async_playwright() as p:
# Launch a Chromium browser instance in headless mode
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
# Navigate to the NGINX blog page
await page.goto("https://www.f5.com/company/blog/nginx")
page_num = 1
while True:
print(f"Currently on page {page_num}")
# Locate the 'Next' button using a button locator with value "next"
next_button = page.locator('button[value="next"]')
# Check if the 'Next' button is enabled
if await next_button.is_enabled():
await next_button.click() # Click the 'Next' button to go to the next page
await page.wait_for_timeout(
2000
) # Wait for 2 seconds to allow new content to load
page_num += 1
else:
print("No more pages. Scraping finished.")
break # Exit the loop if no more pages are available
await browser.close() # Close the browser
# Run the asynchronous scraping function
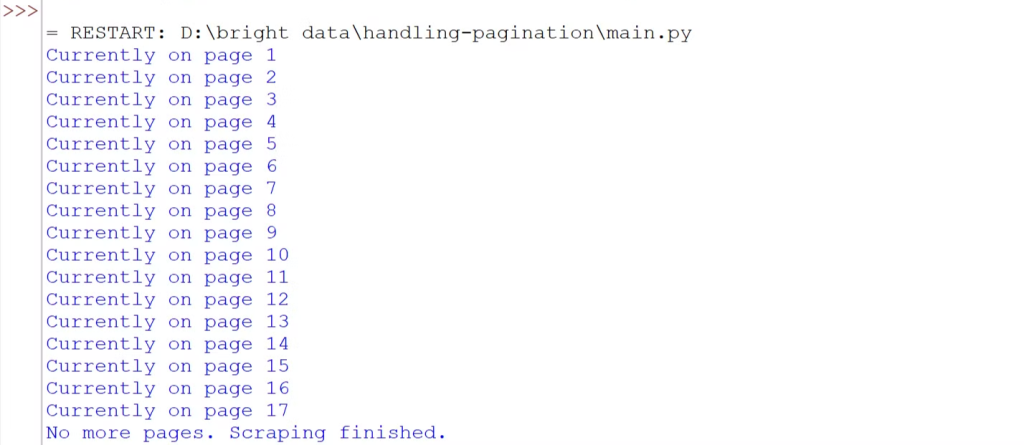
asyncio.run(scrape_nginx_blog())该代码使用异步 Playwright 浏览所有页面。它进入一个循环,检查“下一页”按钮是否存在。如果按钮被启用,它会点击以转到下一页并等待内容加载。这个过程会重复,直到没有更多页面可用。最后,抓取完成后,浏览器将被关闭。
运行代码,你会看到我们已成功浏览了所有页面。
点击加载分页
在许多网站上,你可能见过“加载更多”、“显示更多”或“查看更多”等按钮。这些都是点击加载分页的例子,通常用于现代网站。这些按钮通过 JavaScript 动态加载内容。这里的关键挑战是模拟用户交互——自动化点击按钮以加载更多内容的过程。
以 Bright Data 博客 部分为例。当你访问并向下滚动时,你会注意到一个“查看更多”按钮,点击它会加载博客文章。
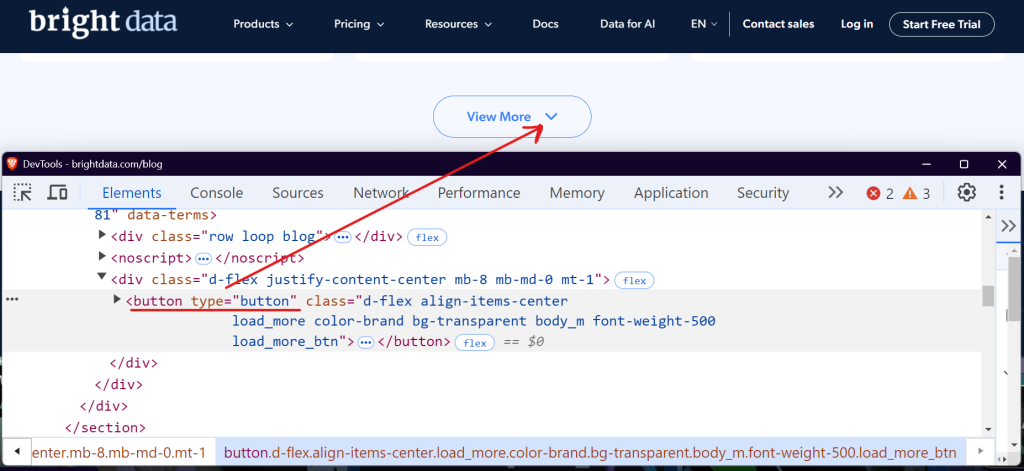
你可以使用 Selenium 或 Playwright 等工具,通过反复点击“加载更多”按钮,直到没有更多内容可用,来自动化这个过程。让我们看看如何使用 Playwright 轻松处理这个问题。
import asyncio
from playwright.async_api import async_playwright
async def scrape_brightdata_blog():
async with async_playwright() as p:
# Launch a headless browser
browser = await p.chromium.launch(headless=True)
page = await browser.new_page()
# Navigate to the Bright Data blog
await page.goto("https://brightdata.com/blog")
page_num = 1
while True:
print(f"Currently on page {page_num}")
# Locate the "View More" button
view_more_button = page.locator("button.load_more_btn")
# Check if the button is visible and enabled
if (
await view_more_button.count() > 0
and await view_more_button.is_visible()
):
await view_more_button.click()
await page.wait_for_timeout(2000)
page_num += 1
else:
print("No more pages to load. Scraping finished.")
break
# Close the browser
await browser.close()
# Run the scraping function
asyncio.run(scrape_brightdata_blog())该代码使用 CSS 选择器 button.load_more_btn 定位“查看更多”按钮。然后,它通过使用 count() > 0 和 is_visible() 检查按钮是否存在且可见。如果按钮可见,它使用 click() 方法与其交互,并等待 2 秒以允许新内容加载。这个过程在循环中重复,直到按钮不再可见。
运行代码,你会看到我们已成功浏览了所有页面。

我们已成功从 Bright Data 博客部分抓取了所有 52 页。这表明该网站共有 52 页,我们是在抓取过程后才发现的。然而,在抓取之前知道总页数是可能的。
要做到这一点,打开开发者工具,导航到“网络”选项卡,并通过选择“Fetch/XHR”来筛选请求。然后,再次点击“查看更多”按钮,你会注意到触发了一个 AJAX 请求。
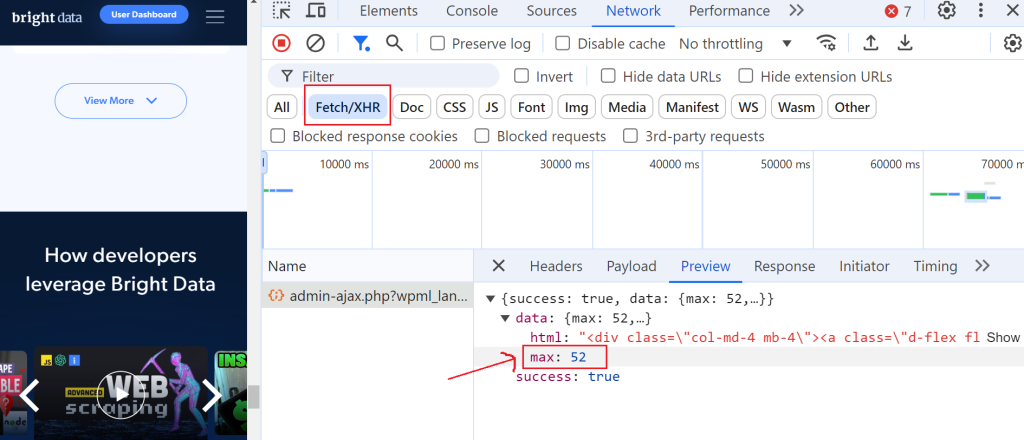
点击这个请求并导航到“预览”部分,你会看到最大页数是 52。然后,前往“负载”部分,你会发现每页有 6 篇博客文章,我们当前在第 3 页。
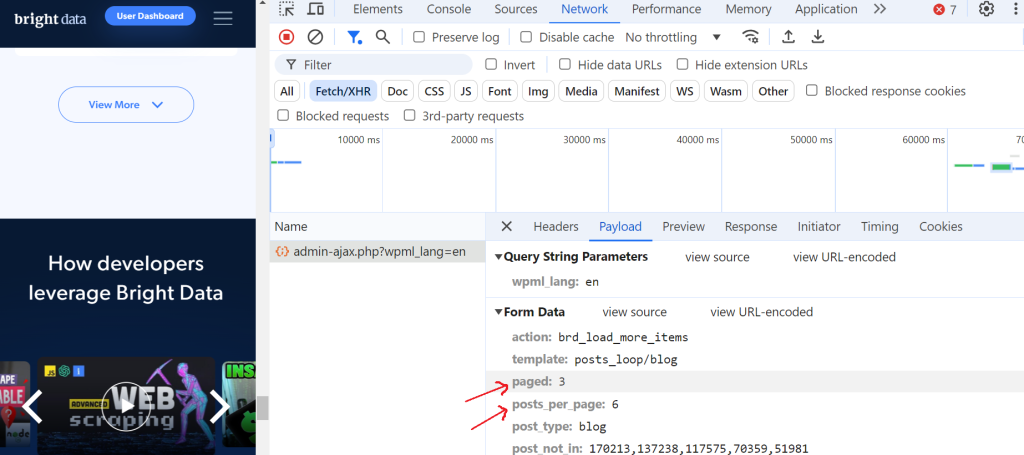
这太棒了!
无限滚动分页
许多网站现在使用无限滚动,而不是“上一页/下一页”按钮,这通过消除点击多个页面的需求来改善用户体验。这种技术会在用户向下滚动时自动加载新内容。然而,它为网页抓取器带来了独特的挑战,因为它需要监控 DOM 变化和处理 AJAX 请求。
让我们举一个现实生活中的例子。当你访问 Nike 网站时,你会注意到鞋子在你向下滚动时会自动加载。每次滚动时,一个加载图标会短暂出现,转眼间,更多鞋子就会显示出来,如下图所示:
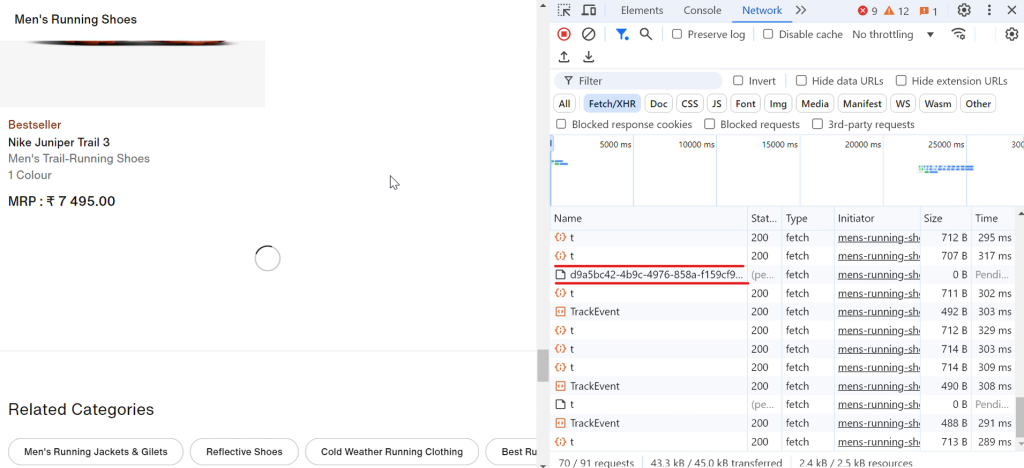
当你点击请求 (d9a5bc) 时,你可以在“响应”选项卡中找到当前页面的所有数据。
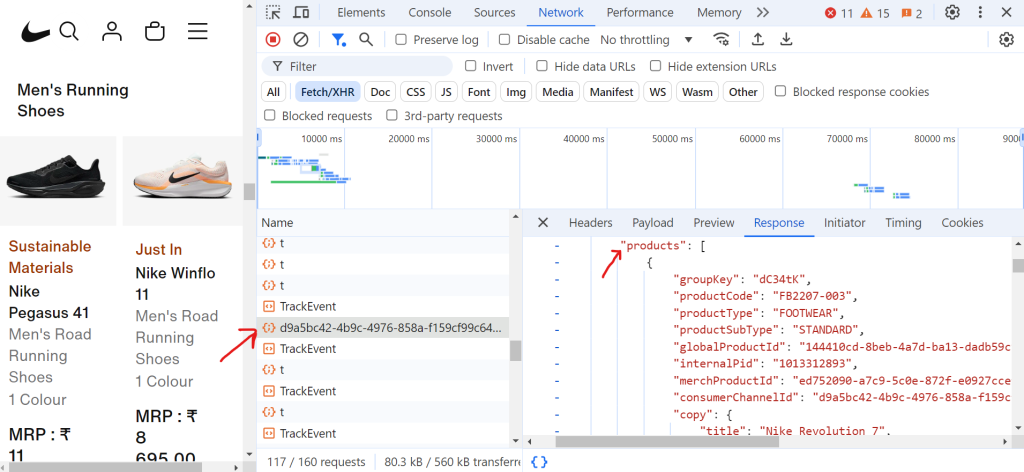
现在,要处理分页,你需要不断向下滚动页面,直到到达页面底部。随着滚动,浏览器会发出许多请求,但这些 Fetch/XHR 请求中只有一些会包含你需要的实际数据。
以下是处理分页并提取鞋子标题的代码:
import asyncio
from urllib.parse import parse_qs, urlparse
from playwright.async_api import async_playwright
async def scroll_to_bottom(page) -> None:
"""Scroll to the bottom of the page until no more content is loaded."""
last_height = await page.evaluate("document.body.scrollHeight")
scroll_count = 0
while True:
# Scroll down
await page.evaluate("window.scrollTo(0, document.body.scrollHeight);")
await asyncio.sleep(2) # Wait for new content to load
scroll_count += 1
print(f"Scroll iteration: {scroll_count}")
# Check if scroll height has changed
new_height = await page.evaluate("document.body.scrollHeight")
if new_height == last_height:
print("Reached the bottom of the page.")
break # Exit if no new content is loaded
last_height = new_height
async def extract_product_data(response, extracted_products) -> None:
"""Extract product data from the response."""
parsed_url = urlparse(response.url)
query_params = parse_qs(parsed_url.query)
if "queryType" in query_params and query_params["queryType"][0] == "PRODUCTS":
data = await response.json()
for grouping in data.get("productGroupings", []):
for product in grouping.get("products", []):
title = product.get("copy", {}).get("title")
extracted_products.append({"title": title})
async def scrape_shoes(target_url: str) -> None:
async with async_playwright() as playwright:
browser = await playwright.chromium.launch(headless=True)
page = await browser.new_page()
extracted_products = []
# Set up listener for product data responses
page.on(
"response",
lambda response: extract_product_data(
response, extracted_products),
)
# Navigate to the page and scroll to the bottom
print("Navigating to the page...")
await page.goto(target_url, wait_until="domcontentloaded")
await asyncio.sleep(2)
await scroll_to_bottom(page)
# Save product titles to a text file
with open("product_titles.txt", "w") as title_file:
for product in extracted_products:
title_file.write(product["title"] + "n")
print(f"Scraping completed!")
await browser.close()
if __name__ == "__main__":
asyncio.run(
scrape_shoes(
"https://www.nike.com/in/w/mens-running-shoes-37v7jznik1zy7ok")
)
在代码中,scroll_to_bottom 函数不断滚动到页面底部以加载更多内容。它首先记录当前的滚动高度,然后反复向下滚动。每次滚动后,它会检查新的滚动高度是否与最后记录的高度不同。如果高度保持不变,它会得出没有更多内容被加载的结论并退出循环。这种方法确保在抓取过程继续之前,所有可用的产品都已完全加载。
当你运行代码时,会发生以下情况:

代码成功执行后,将创建一个包含所有 Nike 鞋子标题的新文本文件。
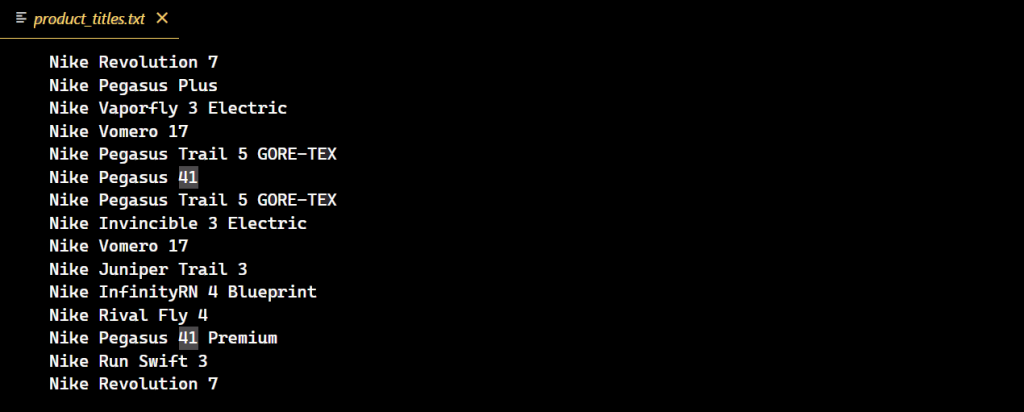
分页中的挑战
在处理分页内容时,被 封锁 的风险增加,一些网站可能会在仅一页后就封锁你。例如,如果你试图 抓取 Glassdoor,你可能会遇到各种 网页抓取挑战,其中之一就是我所经历的 Cloudflare CAPTCHA 挑战。
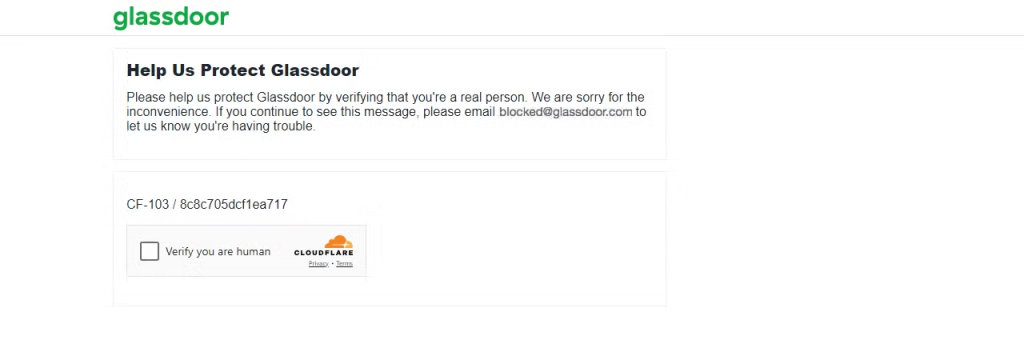
让我们向 Glassdoor 页面发起请求,看看会发生什么。
import requests
url = "https://www.glassdoor.com/"
response = requests.get(url)
print(f"Status code: {response.status_code}")结果是一个 403 状态码。
这表明 Glassdoor 已检测到你的请求来自机器人或抓取器,导致 CAPTCHA 挑战。如果你继续发送多个请求,你的 IP 可能会立即被封锁。
要绕过这些封锁并有效地提取所需数据,你可以使用 Python Requests 中的代理 来 避免 IP 封锁,或通过 轮换用户代理 模仿真实浏览器。然而,重要的是要注意,这些方法都不能保证避免高级机器人检测。
那么,最终的解决方案是什么?让我们接下来深入探讨一下!
集成 Bright Data 解决方案
Bright Data 是绕过复杂反机器人措施的优秀解决方案。它只需几行代码即可无缝集成到你的项目中,并提供一系列针对任何高级反机器人机制的解决方案。
其中一个解决方案是 网页抓取器 API,它通过自动处理 IP 轮换和 CAPTCHA 解决 简化了从任何网站提取数据。这使你能够专注于数据分析,而不是数据检索的复杂细节。
例如,在我们的案例中,当尝试绕过 Glassdoor 上的 CAPTCHA 时遇到了挑战。为了解决这个问题,你可以使用 Bright Data 的 Glassdoor 抓取器 API,它专门设计用于绕过这些障碍并无缝地从网站提取数据。
要开始使用 Glassdoor 抓取器 API,请按照以下步骤操作:
首先,创建一个账户。访问 Bright Data 网站,点击 开始免费试用,并按照注册说明操作。登录后,你将被重定向到你的 仪表板,在那里你将获得一些免费积分。
现在,进入 Web Scraper API 部分,在 B2B 数据类别下选择 Glassdoor。你会找到各种数据收集选项,例如通过 URL 收集公司信息或通过 URL 收集职位列表。
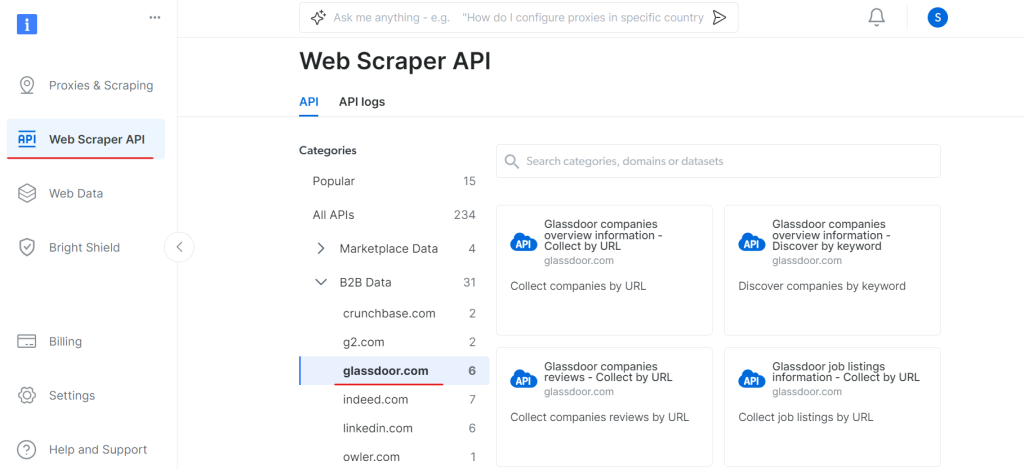
在“Glassdoor 公司概述信息”下,获取你的 API 令牌并复制你的数据集 ID(例如,gd_l7j0bx501ockwldaqf)。
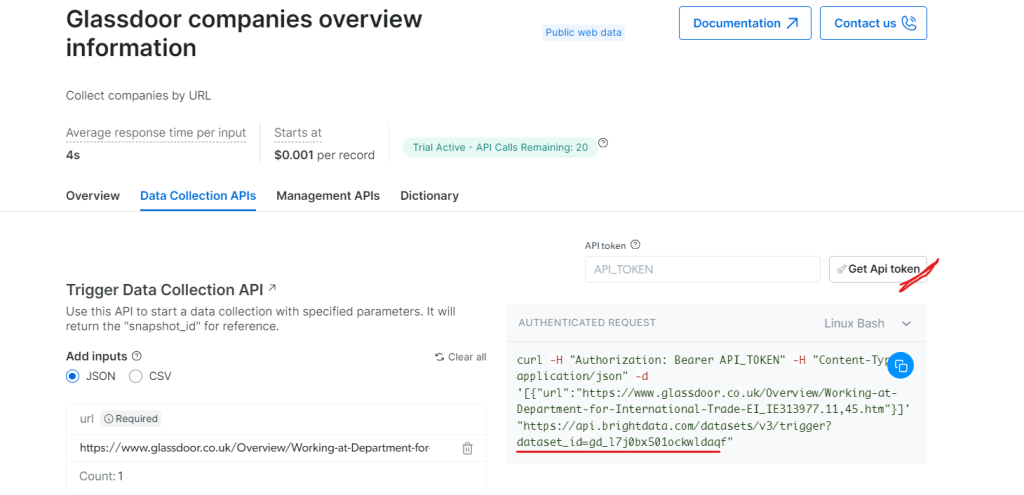
现在,以下是一个简单的代码片段,展示如何通过提供 URL、API 令牌和数据集 ID 来提取公司数据。
import requests
import json
def trigger_dataset(api_token, dataset_id, company_url):
"""
Triggers a dataset using the BrightData API.
Args:
api_token (str): The API token for authentication.
dataset_id (str): The dataset ID to trigger.
company_url (str): The URL of the company page to analyze.
Returns:
dict: The JSON response from the API.
"""
headers = {
"Authorization": f"Bearer {api_token}",
"Content-Type": "application/json",
}
payload = json.dumps([{"url": company_url}])
response = requests.post(
"https://api.brightdata.com/datasets/v3/trigger",
headers=headers,
params={"dataset_id": dataset_id},
data=payload,
)
return response.json()
api_token = "API_Token"
dataset_id = "DATASET_ID"
company_url = "https://www.glassdoor.com/"
response_data = trigger_dataset(api_token, dataset_id, company_url)
print(response_data)运行代码后,你将收到如下所示的快照 ID:

使用快照 ID 来检索公司的实际数据。在终端中运行以下命令。对于 Windows,使用:
curl.exe -H "Authorization: Bearer API_TOKEN"
"https://api.brightdata.com/datasets/v3/snapshot/s_m0v14wn11w6tcxfih8?format=json"对于 Linux:
curl -H "Authorization: Bearer API_TOKEN"
"https://api.brightdata.com/datasets/v3/snapshot/s_m0v14wn11w6tcxfih8?format=json"运行命令后,你将获得所需的数据。
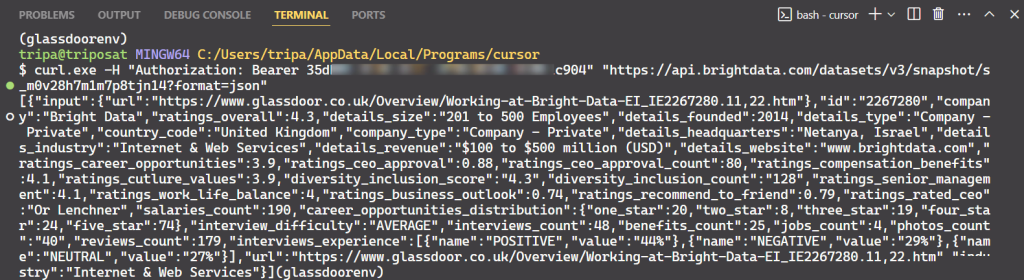
就这么简单!
同样,你可以通过修改代码从 Glassdoor 提取各种类型的数据。我已经解释了一种方法,但还有五种其他方法。因此,我建议探索这些选项来抓取你想要的数据。每种方法都针对特定的数据需求,帮助你获取所需的精确数据。
结论
本文讨论了现代网站常用的各种分页方法,如数字分页、“加载更多”按钮和无限滚动。还提供了有效实施这些分页技术的代码示例。然而,尽管处理分页是网页抓取的一部分,但克服反机器人检测是一个重大挑战。
逃避高级反机器人检测可能相当复杂,且成功率各不相同。Bright Data 的工具提供了一种简化且具有成本效益的解决方案,包括 Web Unlocker、Scraping Browser 和 Web Scraper APIs,满足你所有的网页抓取需求。只需几行代码,你就可以实现更高的成功率,而无需麻烦地管理复杂的反机器人措施。
完全不想参与抓取过程?看看我们的 数据集市场!
今天就注册,享受免费试用。



技术写作者
 5 years experience
5 years experience
Satyam Tripathi 帮助 SaaS 和数据初创公司将复杂技术转化为可执行的内容,提升开发者采用度并增强用户理解。




