代理是来自代理服务器的IP地址,代表您连接到互联网。当您通过代理连接到互联网时,您的请求将经由代理服务器传输,而不是直接传输到您访问的网站。使用代理服务器,是保护您的在线隐私和增强安全性的好方法:
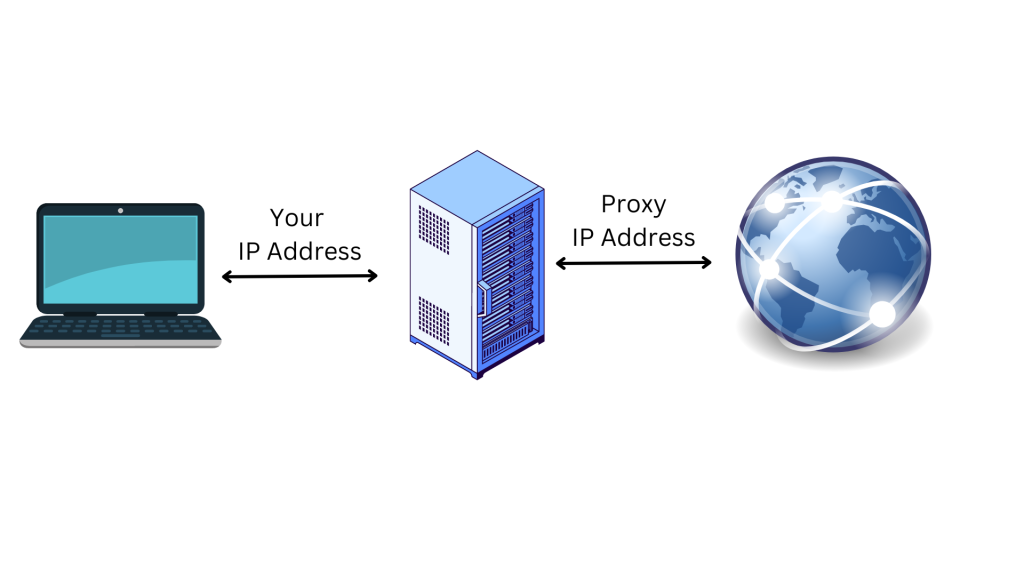
代理服务器充当中间人计算机,这意味着您的原始IP地址和位置是隐藏的,网站不会知道。这有助于保护您,可避免在线跟踪、定向广告以及被您试图访问的网站屏蔽。代理还能对在设备和代理服务器之间传输的数据进行加密,从而提供一层额外的安全保护。
在本文中,您将会了解更多有关代理的信息,以及如何在Python Requests中使用代理。您还将了解到,为何此操作对网页抓取项目很有帮助。
为什么在进行网页抓取时需要代理
网页抓取是一个自动化过程,旨在从网站提取数据以用于不同目的,包括数据汇总、市场研究和数据分析。然而,这些网站许多都设有限制,使您难以访问所需信息。
值得庆幸的是,代理可以帮助您规避基于IP和位置的限制。例如,在某些情况下,网站会为特定位置(例如国家或州)提供不同的信息。如果您不在那个特定的位置,没有代理就无法访问您要找的信息;代理可以改变您的位置,规避IP限制。
此外,大多数网站都会屏蔽参与网页抓取活动的设备的IP地址。在这种情况下,您可以使用代理来隐藏您的IP地址和位置,使网站较难识别和屏蔽您。
您还可以同时使用多个代理,将网页抓取活动分配到不同的IP地址,让抓取工具可以同时发出多个请求,以加快网页抓取过程。
现在您已经知道代理在网页抓取项目中能起到什么作用,接下来您将会了解到,在使用Python的Requests包时,如何在您的项目中设置代理。
如何在Python Requests中使用代理
要在Python Requests中使用代理,您需要在计算机上建立一个新的Python项目,以编写和运行用于网页抓取的Python脚本。创建用于存储源代码文件的目录(例如web_scrape_project)。
本教程的所有代码都可以在这个GitHub存储库中找到。
安装软件包
创建目录后,您需要安装以下Python包来向网页发送请求和收集链接:
- Requests:Python的Requests包会向您想抓取数据的网站发送HTTP请求。HTTP请求会返回一个包含所有响应数据(例如状态、编码和内容)的响应对象。请在终端运行以下
pip命令,以安装软件包:pip install requests - Beautiful Soup:Beautiful Soup是强大的Python库,用于解析HTML和XML文档。您可使用该库来浏览Bright Data网页上的HTML文档,并提取所有链接。要安装 Beautiful Soup,请在终端运行以下
pip命令:pip install beautifulsoup4
代理IP地址的组成部分
在使用代理之前,最好先了解其组成部分。以下是代理服务器的三个主要组成部分:
- 协议显示您可以在互联网上访问的内容类型。最常见的协议是HTTP和HTTPS。
- 地址显示代理服务器的位置。地址可以是IP(例如
192.167.0.1)或DNS主机名(例如proxyprovider.com)。 - 端口的作用是,当有多个服务在一台机器上运行时,将流量引导到正确的服务器进程(例如端口号
2000)。
使用这三个组成部分的代理IP地址示例如下:192.167.0.1:2000或proxyprovider.com:2000。
如何直接在Requests中设置代理
有几种在Python Requests中设置代理的方法,本文会介绍三种不同的情况。在第一个示例中,您将会了解到如何直接在Requests模块中设置代理。
首先,您需要把Requests和Beautiful Soup包导入到用于网页抓取的Python文件中。然后,请创建一个名为proxies的目录,此目录包含代理服务器信息,用于在抓取网页时隐藏您的IP地址。在这里,代理URL的HTTP和HTTPS连接均必须定义。
您还需要定义一个Python变量来设置您想抓取数据的网页的URL。在本教程中,URL是https://www.bright.cn/
接下来,您需要使用request.get()方法,向网页发送GET请求。这个方法需要两个参数:网站的URL和代理。然后,网页返回的响应会存储在响应变量中。
要收集链接,请将参数response.content和html.parser传递到BeautifulSoup()方法,以使用Beautiful Soup包解析网页的HTML内容。
然后,使用find_all()方法(参数为a)查找网页上的所有链接。最后,使用get()方法提取每个链接的href属性。
以下是在Requests中直接设置代理的完整源代码:
# import packages.
import requests
from bs4 import BeautifulSoup
# Define proxies to use.
proxies = {
'http': 'http://proxyprovider.com:2000',
'https': 'http://proxyprovider.com:2000',
}
# Define a link to the web page.
url = "https://brightdata.com/"
# Send a GET request to the website.
response = requests.get(url, proxies=proxies)
# Use BeautifulSoup to parse the HTML content of the website.
soup = BeautifulSoup(response.content, "html.parser")
# Find all the links on the website.
links = soup.find_all("a")
# Print all the links.
for link in links:
print(link.get("href"))
当您运行这段代码时,它会使用代理IP地址向所定义的网页发送请求,然后返回包含该网页所有链接的响应:
如何通过环境变量设置代理
有时,您必须使用同一个代理来向不同的网页发送所有请求。在这种情况下,为代理设置环境变量是有意义的。
要每次在shell中运行脚本时都有代理环境变量可用,请在终端运行以下命令:
export HTTP_PROXY='http://proxyprovider.com:2000'
export HTTPS_PROXY='https://proxyprovider.com:2000'
在这里,HTTP_PROXY变量为HTTP请求设置代理服务器,HTTPS_PROXY变量为HTTPS请求设置代理服务器。
此时,您的Python代码有几行,每当您向网页发出请求时,就会使用环境变量:
# import packages.
import requests
from bs4 import BeautifulSoup
# Define a link to the web page.
url = "https://brightdata.com/"
# Send a GET request to the website.
response = requests.get(url)
# Use BeautifulSoup to parse the HTML content of the website.
soup = BeautifulSoup(response.content, "html.parser")
# Find all the links on the website.
links = soup.find_all("a")
# Print all the links.
for link in links:
print(link.get("href"))
如何使用自定义方法和代理阵列来进行代理轮换
代理轮换至关重要,因为当网站收到来自同一IP地址的大量请求时,往往会阻止或限制机器人和抓取工具的访问。发生这种情况时,网站可能会怀疑有恶意抓取活动,因而采取阻止或限制访问的措施。
轮换不同的代理IP地址,您会显示为多个自然用户,可以避免被检测到,并绕过网站上实施的大多数反抓取措施。
要轮换代理,您需要导入几个Python库:Requests、Beautiful Soup和Random。
然后,创建在轮换过程中使用的代理列表。此列表必须包含以下格式的代理服务器URL:http://proxyserver.com:port:
# List of proxies
proxies = [
"http://proxyprovider1.com:2010", "http://proxyprovider1.com:2020",
"http://proxyprovider1.com:2030", "http://proxyprovider2.com:2040",
"http://proxyprovider2.com:2050", "http://proxyprovider2.com:2060",
"http://proxyprovider3.com:2070", "http://proxyprovider3.com:2080",
"http://proxyprovider3.com:2090"
]
然后,创建一个名为get_proxy()的自定义方法。此方法使用random.choice()方法,从代理列表中随机选择一个代理,并以字典格式(包括HTTP和HTTPS键)返回所选代理。每当您发送新请求时,都是使用这个方法:
# Custom method to rotate proxies
def get_proxy():
# Choose a random proxy from the list
proxy = random.choice(proxies)
# Return a dictionary with the proxy for both http and https protocols
return {'http': proxy, 'https': proxy}
创建get_proxy()方法后,您需要创建一个循环,使用轮换的代理发送一定数量的GET请求。在每个请求中,get()方法都会使用由get_proxy()方法指定的随机选择的代理。
然后,您需要使用Beautiful Soup包,从网页的HTML内容中收集链接,如第一个示例中所述。
最后,Python代码会捕获请求过程中发生的任何异常,并将错误信息输出到控制台。
以下是此示例的完整源代码:
# import packages
import requests
from bs4 import BeautifulSoup
import random
# List of proxies
proxies = [
"http://proxyprovider1.com:2010", "http://proxyprovider1.com:2020",
"http://proxyprovider1.com:2030", "http://proxyprovider2.com:2040",
"http://proxyprovider2.com:2050", "http://proxyprovider2.com:2060",
"http://proxyprovider3.com:2070", "http://proxyprovider3.com:2080",
"http://proxyprovider3.com:2090"
]
# Custom method to rotate proxies
def get_proxy():
# Choose a random proxy from the list
proxy = random.choice(proxies)
# Return a dictionary with the proxy for both http and https protocols
return {'http': proxy, 'https': proxy}
# Send requests using rotated proxies
for i in range(10):
# Set the URL to scrape
url = 'https://brightdata.com/'
try:
# Send a GET request with a randomly chosen proxy
response = requests.get(url, proxies=get_proxy())
# Use BeautifulSoup to parse the HTML content of the website.
soup = BeautifulSoup(response.content, "html.parser")
# Find all the links on the website.
links = soup.find_all("a")
# Print all the links.
for link in links:
print(link.get("href"))
except requests.exceptions.RequestException as e:
# Handle any exceptions that may occur during the request
print(e)
在Python中使用Bright Data代理服务
如果您正在为网页抓取任务寻找可靠、快速和稳定的代理,那么Bright Data就是您的最佳选择;这是一个网络数据平台,提供不同类型的代理,適合多种需求。
Bright Data的大型网络由超过7200万个住宅IP和超过77万个数据中心代理组成,能够提供可靠和快速的代理解决方案。其代理产品旨在帮助您克服挑战,顺利进行网页抓取、广告验证等需要匿名和高效网络数据收集的在线活动。
将Bright Data的代理集成到您的Python Requests中,是易如反掌的事。例如,使用数据中心代理向前面示例中所使用的URL发送请求。
如果您还没有账户,请注册免费试用Bright Data,然后添加您的详细信息,在平台上注册您的账户。
完成后,请按照以下步骤创建您的第一个代理:
在欢迎页面上点击查看代理产品,查看Bright Data提供的不同类型代理:
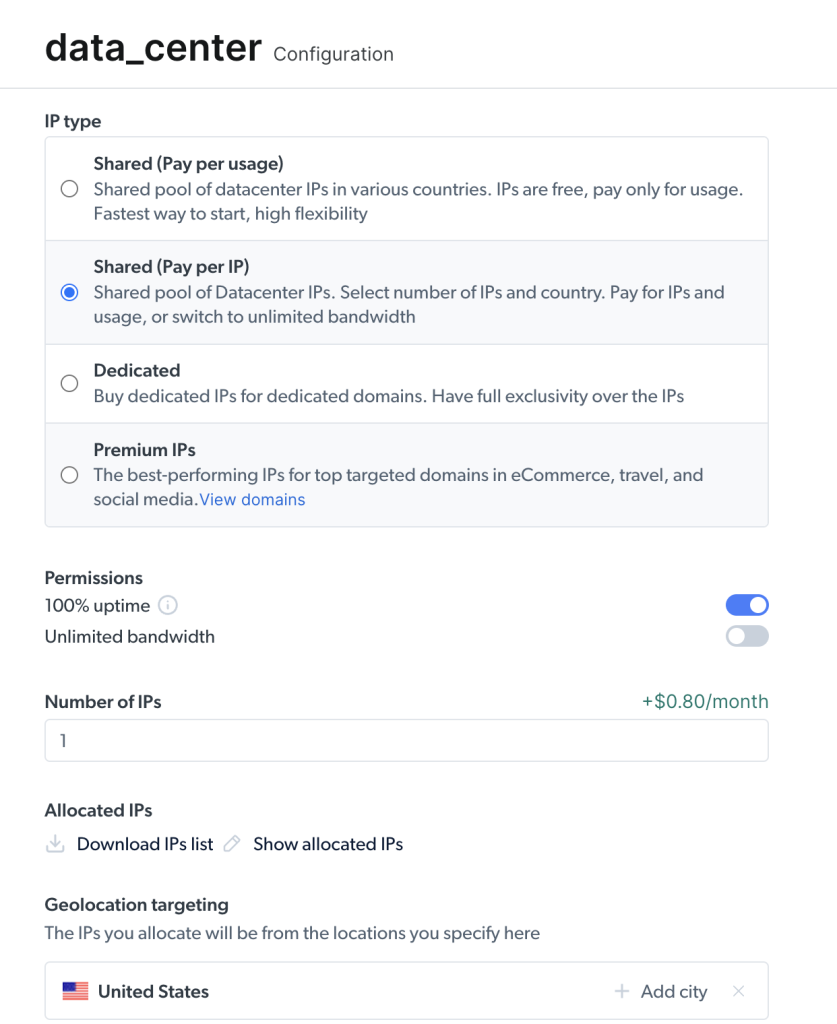
选择数据中心代理创建新代理,在随后的页面上添加并保存您的详细信息:
创建代理后,您可以查看重要参数(即主机、端口、用户名和密码)以开始访问和使用它:
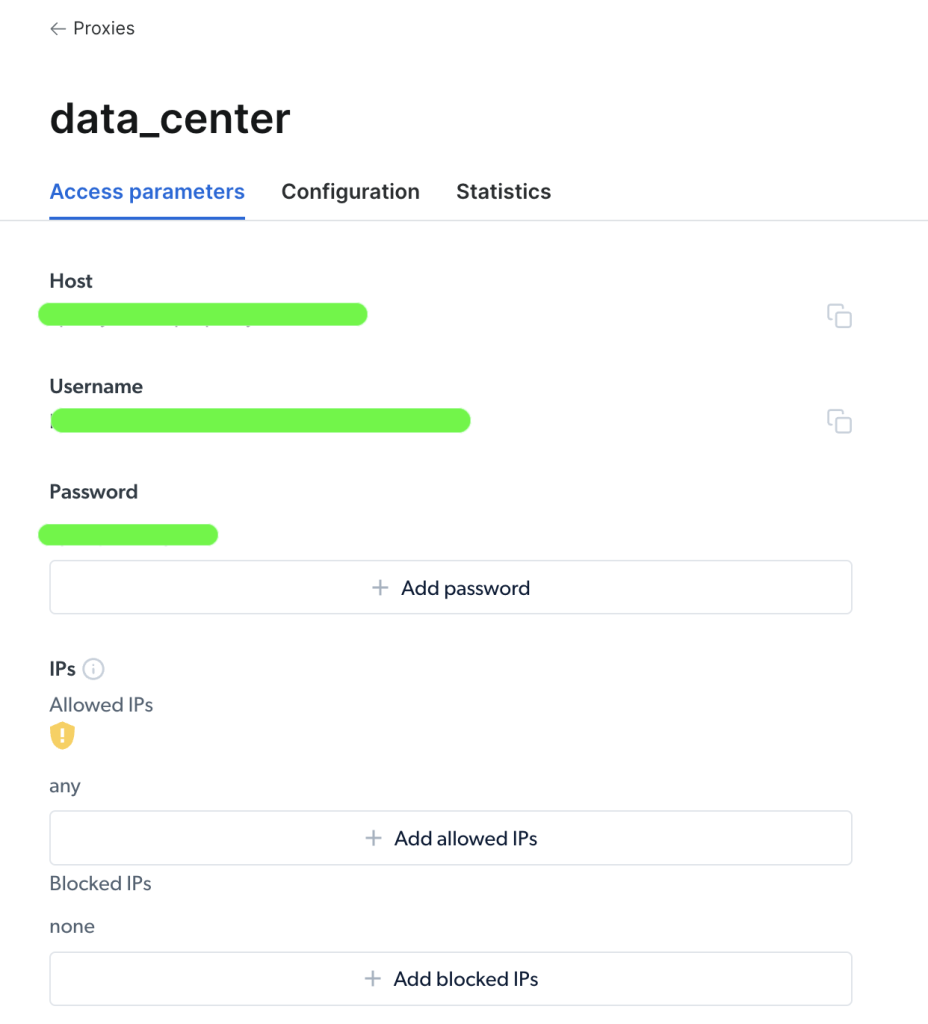
访问代理后,您可以使用参数信息来配置代理URL,并使用Python的Requests包发送请求。代理URL的格式为username-(session-id)-password@host:port。
注意:
session-id是使用名为Random的Python软件包创建的随机数。
以下是在Python请求中通过Bright Data设置代理的代码示例:
import requests
from bs4 import BeautifulSoup
import random
# Define parameters provided by Brightdata
host = 'zproxy.lum-superproxy.io'
port = 22225
username = 'username'
password = 'password'
session_id = random.random()
# format your proxy
proxy_url = ('http://{}-session-{}:{}@{}:{}'.format(username, session_id,
password, host, port))
# define your proxies in dictionary
proxies = {'http': proxy_url, 'https': proxy_url}
# Send a GET request to the website
url = "https://brightdata.com/"
response = requests.get(url, proxies=proxies)
# Use BeautifulSoup to parse the HTML content of the website
soup = BeautifulSoup(response.content, "html.parser")
# Find all the links on the website
links = soup.find_all("a")
# Print all the links
for link in links:
print(link.get("href"))
在这里,请导入软件包,并定义代理主机、端口、用户名、密码和session_id变量。然后,使用http和https键以及代理凭据创建一个代理字典。最后,请将代理参数传递给requests.get()函数,以发出HTTP请求,并收集URL中的链接。
就是这样了!您刚刚使用Bright Data的代理服务成功发出了请求。
结语
在本文中,您了解了为什么需要代理,以及使用Python的Requests包经由代理向网页发送请求的不同方式。
通过Bright Data的网络平台,您能够获得位于世界上任何国家或城市的可靠代理,以进行您的项目。该平台提供多种方法,让您可通过各种类型的代理和工具进行网页抓取,以获得所需的数据,满足您的特定需求。
无论您是想收集市场研究数据、监控在线评论还是跟踪竞争对手的定价,Bright Data都能为您提供所需的资源,让您能快速而高效地完成工作。




