

在本次实践教程中,您将学习如何使用Bright Data的Glassdoor抓取工具和Playwright Python从Glassdoor抓取数据。您还将了解Glassdoor所使用的反抓取技术以及Bright Data如何提供帮助。此外,您还会了解一种使抓取Glassdoor数据更快的Bright Data解决方案。
跳过抓取,直接获取数据
想要跳过抓取过程,直接访问数据?请考虑查看我们的Glassdoor数据集。
Glassdoor数据集提供完整的公司概览,包括评论和常见问题,提供关于工作和公司的见解。您可以使用我们的Glassdoor数据集查找市场趋势、公司商业信息以及当前和过去的员工对公司的看法和评级。根据您的需求,您可以选择购买整个数据集或定制的子集。
数据集提供JSON、NDJSON、JSON Lines、CSV或Parquet等格式,且可选地压缩成.gz文件。
抓取Glassdoor是否合法?
是的,从Glassdoor抓取数据是合法的,但必须以道德的方式进行,并遵守Glassdoor的服务条款、robots.txt文件和隐私政策。一个最大的误区是抓取像公司评论和职位列表这样的公共数据是不合法的。然而,这不是真的。抓取应在合法和道德的范围内进行。
如何抓取Glassdoor数据
Glassdoor使用JavaScript来渲染其内容,这可能使抓取变得更复杂。为了解决这个问题,您需要一个能够执行JavaScript并像浏览器一样与网页交互的工具。一些流行的选择有Playwright、Puppeteer和Selenium。在本教程中,我们将使用Playwright Python。
让我们从头开始构建Glassdoor抓取工具!无论您是Playwright的新手还是已有经验,本教程都将帮助您使用Playwright Python构建一个网络抓取工具。
设置工作环境
在开始之前,请确保您的计算机上已设置以下内容:
- Python:从官方下载页面下载并安装最新版本。在本教程中,我们使用Python 3.12。
- 代码编辑器:选择一个代码编辑器,如Visual Studio Code。
接下来,打开终端,创建一个用于Python项目的新文件夹,然后导航到该文件夹:
mkdir glassdoor-scraper
cd glassdoor-scraper创建并激活一个虚拟环境:
python -m venv glassdoorenv
glassdoorenv\Scripts\activate安装Playwright:
pip install playwright然后,安装浏览器二进制文件:
playwright install此安装可能需要一些时间,请耐心等待。
完整的设置过程如下所示:
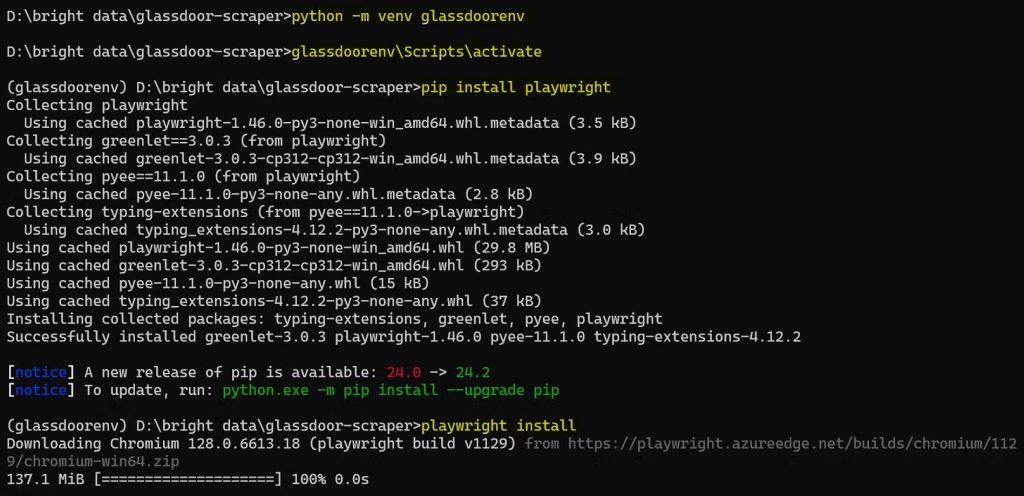
现在,您已经设置完毕,准备开始编写Glassdoor抓取工具的代码!
理解Glassdoor网站结构
在开始抓取Glassdoor之前,了解其结构非常重要。对于本教程,我们将重点抓取具有特定职位的特定位置的公司。
例如,如果您想查找纽约市具有机器学习职位且总体评级高于3.5的公司,您需要对搜索应用适当的过滤器。
请查看Glassdoor公司页面:
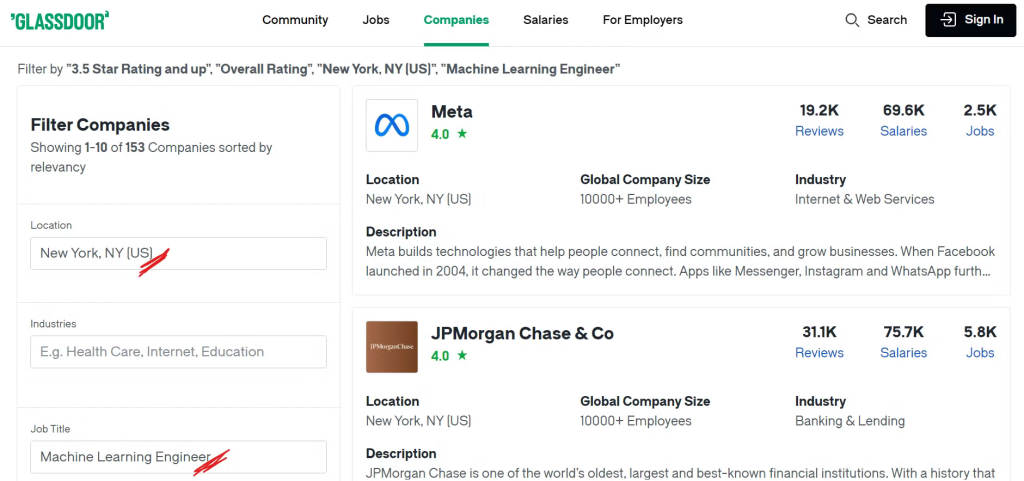
现在,您可以看到通过应用我们想要的过滤器列出了许多公司,您可能想知道我们将要抓取哪些具体数据。让我们接着看看!
确定关键数据点
为了有效地收集Glassdoor的数据,您需要确定要抓取的内容。
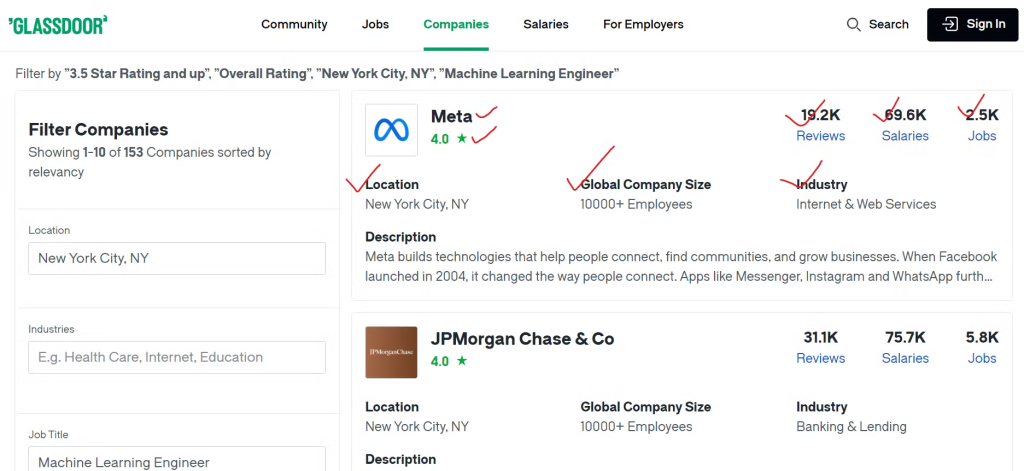
我们将提取每个公司的各种细节,如公司名称、其职位列表的链接和职位空缺总数。此外,我们将抓取员工评论数量、报告的薪资数和公司所处的行业。我们还将提取公司的地理位置和全球员工总数。
构建Glassdoor抓取工具
现在您已经确定了要抓取的数据,是时候使用Playwright Python构建抓取工具了。
首先,检查Glassdoor网站以找到公司名称和评级的元素,如下图所示:
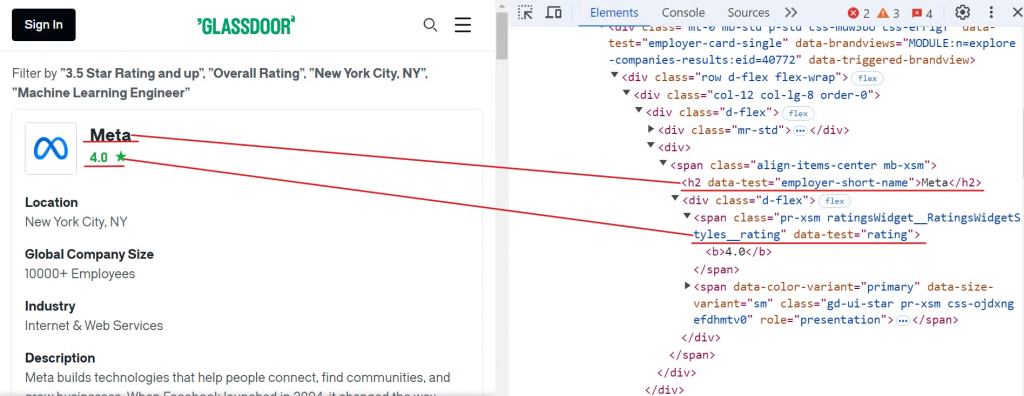
要提取这些数据,您可以使用以下CSS选择器:
[data-test="employer-short-name"]
[data-test="rating"]同样,您可以使用简单的CSS选择器提取其他相关数据,如下图所示:
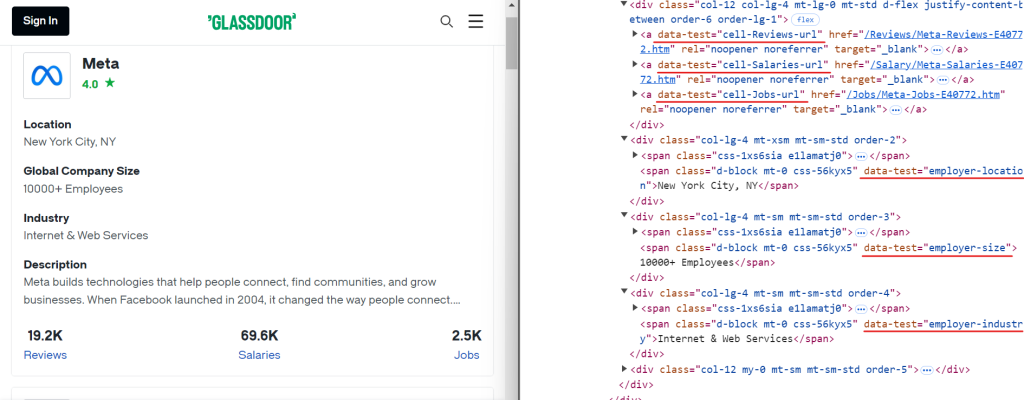
以下是您可以用于提取附加数据的CSS选择器:
[data-test="employer-location"] /* Geographical location of the company */
[data-test="employer-size"] /* Number of employees worldwide */
[data-test="employer-industry"] /* Industry the company operates in */
[data-test="cell-Jobs-url"] /* Link to the company's job listings */
[data-test="cell-Jobs"] h3 /* Total number of job openings */
[data-test="cell-Reviews"] h3 /* Number of employee reviews */
[data-test="cell-Salaries"] h3 /* Count of reported salaries */接下来,创建一个名为glassdoor.py的新文件,并添加以下代码:
import asyncio
from urllib.parse import urlencode, urlparse
from playwright.async_api import async_playwright, Playwright
async def scrape_data(playwright: Playwright):
# Launch a Chromium browser instance
browser = await playwright.chromium.launch(headless=False)
page = await browser.new_page()
# Define the base URL and query parameters for the Glassdoor search
base_url = "https://www.glassdoor.com/Explore/browse-companies.htm?"
query_params = {
"overall_rating_low": "3.5",
"locId": "1132348",
"locType": "C",
"locName": "New York, NY (US)",
"occ": "Machine Learning Engineer",
"filterType": "RATING_OVERALL",
}
# Construct the full URL with query parameters and navigate to it
url = f"{base_url}{urlencode(query_params)}"
await page.goto(url)
# Initialize a counter for the records extracted
record_count = 0
# Locate all company cards on the page and iterate through them to extract data
company_cards = await page.locator('[data-test="employer-card-single"]').all()
for card in company_cards:
try:
# Extract relevant data from each company card
company_name = await card.locator('[data-test="employer-short-name"]').text_content(timeout=2000) or "N/A"
rating = await card.locator('[data-test="rating"]').text_content(timeout=2000) or "N/A"
location = await card.locator('[data-test="employer-location"]').text_content(timeout=2000) or "N/A"
global_company_size = await card.locator('[data-test="employer-size"]').text_content(timeout=2000) or "N/A"
industry = await card.locator('[data-test="employer-industry"]').text_content(timeout=2000) or "N/A"
# Construct the URL for job listings
jobs_url_path = await card.locator('[data-test="cell-Jobs-url"]').get_attribute("href", timeout=2000) or "N/A"
parsed_url = urlparse(base_url)
jobs_url_path = f"{parsed_url.scheme}://{parsed_url.netloc}{jobs_url_path}"
# Extract additional data about jobs, reviews, and salaries
jobs_count = await card.locator('[data-test="cell-Jobs"] h3').text_content(timeout=2000) or "N/A"
reviews_count = await card.locator('[data-test="cell-Reviews"] h3').text_content(timeout=2000) or "N/A"
salaries_count = await card.locator('[data-test="cell-Salaries"] h3').text_content(timeout=2000) or "N/A"
# Print the extracted data
print({
"Company": company_name,
"Rating": rating,
"Jobs URL": jobs_url_path,
"Jobs Count": jobs_count,
"Reviews Count": reviews_count,
"Salaries Count": salaries_count,
"Industry": industry,
"Location": location,
"Global Company Size": global_company_size,
})
record_count += 1
except Exception as e:
print(f"Error extracting company data: {e}")
print(f"Total records extracted: {record_count}")
# Close the browser
await browser.close()
# Entry point for the script
async def main():
async with async_playwright() as playwright:
await scrape_data(playwright)
if __name__ == "__main__":
asyncio.run(main())此代码设置了一个Playwright脚本,通过应用特定的过滤器来抓取公司数据。例如,它应用了位置(纽约,NY)、评级(3.5+)和职位名称(机器学习工程师)等过滤器。
然后,它启动一个Chromium浏览器实例,导航到包含这些过滤器的Glassdoor URL,并从页面上的每个公司卡片中提取数据。收集数据后,它将提取的信息打印到控制台。
以下是输出结果:

做得好!
但仍然有一个问题。目前,代码只提取了10条记录,而页面上大约有150条记录。这表明脚本只捕获了第一页的数据。为了提取更多记录,我们需要实现分页处理,这将在下一节中介绍。
处理分页
Glassdoor的每一页大约显示10家公司的数据。要提取所有可用的记录,您需要通过导航每一页来处理分页,直到到达最后一页。要处理分页,您需要定位“下一页”按钮,检查其是否可用,然后点击它以进入下一页。重复此过程,直到没有更多的页面可用。
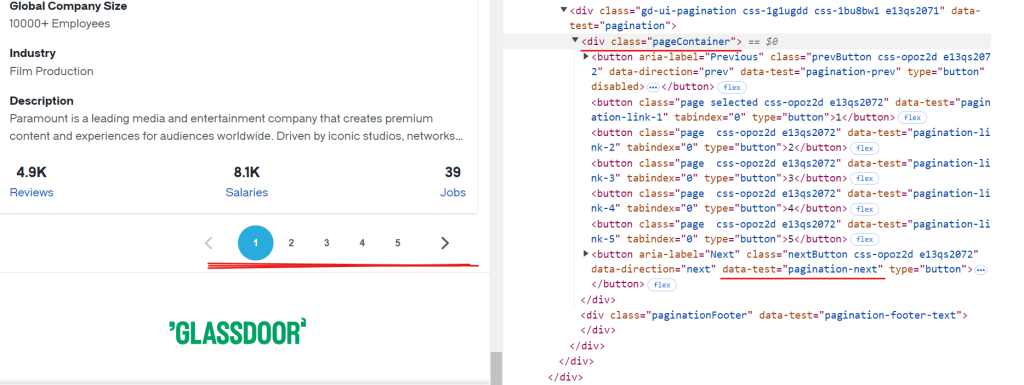
“下一页”按钮的CSS选择器是[data-test="pagination-next"],它位于类名为pageContainer的<div>标签内,如上图所示。
以下是处理分页的代码片段:
while True:
# Ensure the pagination container is visible before proceeding
await page.wait_for_selector(".pageContainer", timeout=3000)
# Identify the "next" button on the page
next_button = page.locator('[data-test="pagination-next"]')
# Determine if the "next" button is disabled, showing no further pages
is_disabled = await next_button.get_attribute("disabled") is not None
if is_disabled:
break # Stop if there are no more pages to navigate
# Navigate to the next page
await next_button.click()
await asyncio.sleep(3) # Allow time for the page to fully load以下是修改后的代码:
import asyncio
from urllib.parse import urlencode, urlparse
from playwright.async_api import async_playwright, Playwright
async def scrape_data(playwright: Playwright):
# Launch a Chromium browser instance
browser = await playwright.chromium.launch(headless=False)
page = await browser.new_page()
# Define the base URL and query parameters for the Glassdoor search
base_url = "https://www.glassdoor.com/Explore/browse-companies.htm?"
query_params = {
"overall_rating_low": "3.5",
"locId": "1132348",
"locType": "C",
"locName": "New York, NY (US)",
"occ": "Machine Learning Engineer",
"filterType": "RATING_OVERALL",
}
# Construct the full URL with query parameters and navigate to it
url = f"{base_url}{urlencode(query_params)}"
await page.goto(url)
# Initialize a counter for the records extracted
record_count = 0
while True:
# Locate all company cards on the page and iterate through them to extract data
company_cards = await page.locator('[data-test="employer-card-single"]').all()
for card in company_cards:
try:
# Extract relevant data from each company card
company_name = await card.locator('[data-test="employer-short-name"]').text_content(timeout=2000) or "N/A"
rating = await card.locator('[data-test="rating"]').text_content(timeout=2000) or "N/A"
location = await card.locator('[data-test="employer-location"]').text_content(timeout=2000) or "N/A"
global_company_size = await card.locator('[data-test="employer-size"]').text_content(timeout=2000) or "N/A"
industry = await card.locator('[data-test="employer-industry"]').text_content(timeout=2000) or "N/A"
# Construct the URL for job listings
jobs_url_path = await card.locator('[data-test="cell-Jobs-url"]').get_attribute("href", timeout=2000) or "N/A"
parsed_url = urlparse(base_url)
jobs_url_path = f"{parsed_url.scheme}://{parsed_url.netloc}{jobs_url_path}"
# Extract additional data about jobs, reviews, and salaries
jobs_count = await card.locator('[data-test="cell-Jobs"] h3').text_content(timeout=2000) or "N/A"
reviews_count = await card.locator('[data-test="cell-Reviews"] h3').text_content(timeout=2000) or "N/A"
salaries_count = await card.locator('[data-test="cell-Salaries"] h3').text_content(timeout=2000) or "N/A"
# Print the extracted data
print({
"Company": company_name,
"Rating": rating,
"Jobs URL": jobs_url_path,
"Jobs Count": jobs_count,
"Reviews Count": reviews_count,
"Salaries Count": salaries_count,
"Industry": industry,
"Location": location,
"Global Company Size": global_company_size,
})
record_count += 1
except Exception as e:
print(f"Error extracting company data: {e}")
try:
# Ensure the pagination container is visible before proceeding
await page.wait_for_selector(".pageContainer", timeout=3000)
# Identify the "next" button on the page
next_button = page.locator('[data-test="pagination-next"]')
# Determine if the "next" button is disabled, showing no further pages
is_disabled = await next_button.get_attribute("disabled") is not None
if is_disabled:
break # Stop if there are no more pages to navigate
# Navigate to the next page
await next_button.click()
await asyncio.sleep(3) # Allow time for the page to fully load
except Exception as e:
print(f"Error navigating to the next page: {e}")
break # Exit the loop on navigation error
print(f"Total records extracted: {record_count}")
# Close the browser
await browser.close()
# Entry point for the script
async def main():
async with async_playwright() as playwright:
await scrape_data(playwright)
if __name__ == "__main__":
asyncio.run(main())结果是:

太好了!现在,您可以从所有可用的页面中提取数据,而不仅仅是第一页。
将数据保存为CSV
既然您已经提取了数据,让我们将其保存到CSV文件中以便进一步处理。为此,您可以使用Python的csv模块。下面是更新的代码,将抓取的数据保存到CSV文件中:
import asyncio
import csv
from urllib.parse import urlencode, urlparse
from playwright.async_api import async_playwright, Playwright
async def scrape_data(playwright: Playwright):
# Launch a Chromium browser instance
browser = await playwright.chromium.launch(headless=False)
page = await browser.new_page()
# Define the base URL and query parameters for the Glassdoor search
base_url = "https://www.glassdoor.com/Explore/browse-companies.htm?"
query_params = {
"overall_rating_low": "3.5",
"locId": "1132348",
"locType": "C",
"locName": "New York, NY (US)",
"occ": "Machine Learning Engineer",
"filterType": "RATING_OVERALL",
}
# Construct the full URL with query parameters and navigate to it
url = f"{base_url}{urlencode(query_params)}"
await page.goto(url)
# Open CSV file to write the extracted data
with open("glassdoor_data.csv", mode="w", newline="", encoding="utf-8") as file:
writer = csv.writer(file)
writer.writerow([
"Company", "Jobs URL", "Jobs Count", "Reviews Count", "Salaries Count",
"Industry", "Location", "Global Company Size", "Rating"
])
# Initialize a counter for the records extracted
record_count = 0
while True:
# Locate all company cards on the page and iterate through them to extract data
company_cards = await page.locator('[data-test="employer-card-single"]').all()
for card in company_cards:
try:
# Extract relevant data from each company card
company_name = await card.locator('[data-test="employer-short-name"]').text_content(timeout=2000) or "N/A"
rating = await card.locator('[data-test="rating"]').text_content(timeout=2000) or "N/A"
location = await card.locator('[data-test="employer-location"]').text_content(timeout=2000) or "N/A"
global_company_size = await card.locator('[data-test="employer-size"]').text_content(timeout=2000) or "N/A"
industry = await card.locator('[data-test="employer-industry"]').text_content(timeout=2000) or "N/A"
# Construct the URL for job listings
jobs_url_path = await card.locator('[data-test="cell-Jobs-url"]').get_attribute("href", timeout=2000) or "N/A"
parsed_url = urlparse(base_url)
jobs_url_path = f"{parsed_url.scheme}://{parsed_url.netloc}{jobs_url_path}"
# Extract additional data about jobs, reviews, and salaries
jobs_count = await card.locator('[data-test="cell-Jobs"] h3').text_content(timeout=2000) or "N/A"
reviews_count = await card.locator('[data-test="cell-Reviews"] h3').text_content(timeout=2000) or "N/A"
salaries_count = await card.locator('[data-test="cell-Salaries"] h3').text_content(timeout=2000) or "N/A"
# Write the extracted data to the CSV file
writer.writerow([
company_name, jobs_url_path, jobs_count, reviews_count, salaries_count,
industry, location, global_company_size, rating
])
record_count += 1
except Exception as e:
print(f"Error extracting company data: {e}")
try:
# Ensure the pagination container is visible before proceeding
await page.wait_for_selector(".pageContainer", timeout=3000)
# Identify the "next" button on the page
next_button = page.locator('[data-test="pagination-next"]')
# Determine if the "next" button is disabled, showing no further pages
is_disabled = await next_button.get_attribute("disabled") is not None
if is_disabled:
break # Stop if there are no more pages to navigate
# Navigate to the next page
await next_button.click()
await asyncio.sleep(3) # Allow time for the page to fully load
except Exception as e:
print(f"Error navigating to the next page: {e}")
break # Exit the loop on navigation error
print(f"Total records extracted: {record_count}")
# Close the browser
await browser.close()
# Entry point for the script
async def main():
async with async_playwright() as playwright:
await scrape_data(playwright)
if __name__ == "__main__":
asyncio.run(main())此代码现在将抓取的数据保存到名为glassdoor_data.csv的CSV文件中。
结果是:
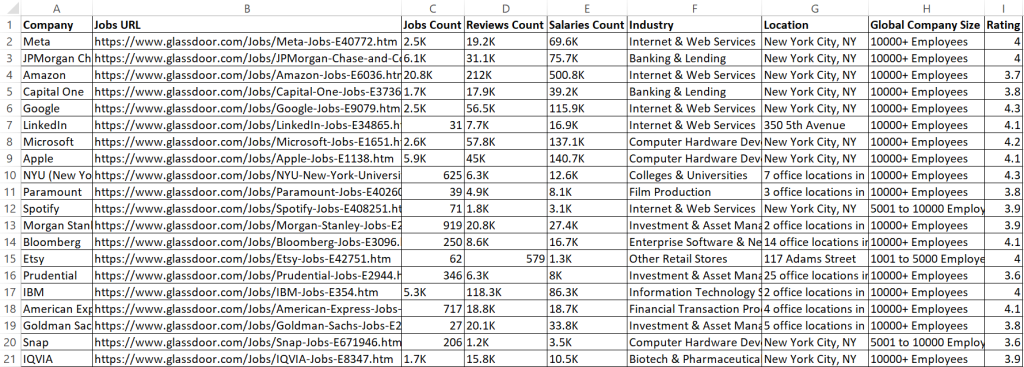
太棒了!现在,数据看起来更加整洁,易于阅读。
Glassdoor采用的反抓取技术
Glassdoor监控一定时间内来自某个IP地址的请求数量。如果请求超过设定的限制,Glassdoor可能会暂时或永久封锁该IP地址。此外,如果检测到异常活动,Glassdoor可能会呈现CAPTCHA挑战,正如我所经历的那样。
上述方法适用于抓取几百家公司的数据。但是,如果您需要抓取数千家,公司数量较大,Glassdoor的反机器人机制可能会标记您的自动抓取脚本,就像我在抓取大量数据时遇到的那样。
从Glassdoor抓取数据可能很困难,因为它的反抓取机制。绕过这些反机器人机制可能令人沮丧且资源密集。然而,有一些策略可以帮助您的抓取工具模拟人类行为,并降低被封锁的可能性。一些常见的技术包括轮换代理、设置真实的请求头、随机化请求速率等等。虽然这些技术可以提高您成功抓取的机会,但不能保证100%的成功率。
因此,尽管Glassdoor有反机器人措施,抓取Glassdoor的最佳方法是使用Glassdoor抓取API 🚀
更好的替代方案:Glassdoor抓取API
Bright Data提供了一个Glassdoor数据集,如前所述,已预先收集并结构化,便于分析。如果您不想购买数据集,正在寻找更有效的解决方案,请考虑使用Bright Data的Glassdoor抓取API。
这个强大的API旨在无缝抓取Glassdoor数据,轻松处理动态内容并绕过反机器人措施。使用此工具,您可以节省时间,确保数据准确性,专注于从数据中提取可行的见解。
要开始使用Glassdoor抓取API,请按照以下步骤操作:
首先,创建一个账户。访问Bright Data网站,点击免费试用,并按照注册说明进行操作。登录后,您将被重定向到您的仪表板,您将获得一些免费积分。
现在,转到Web Scraper API部分,在B2B数据类别下选择Glassdoor。您将找到各种数据收集选项,例如按URL收集公司信息或按URL收集职位列表。
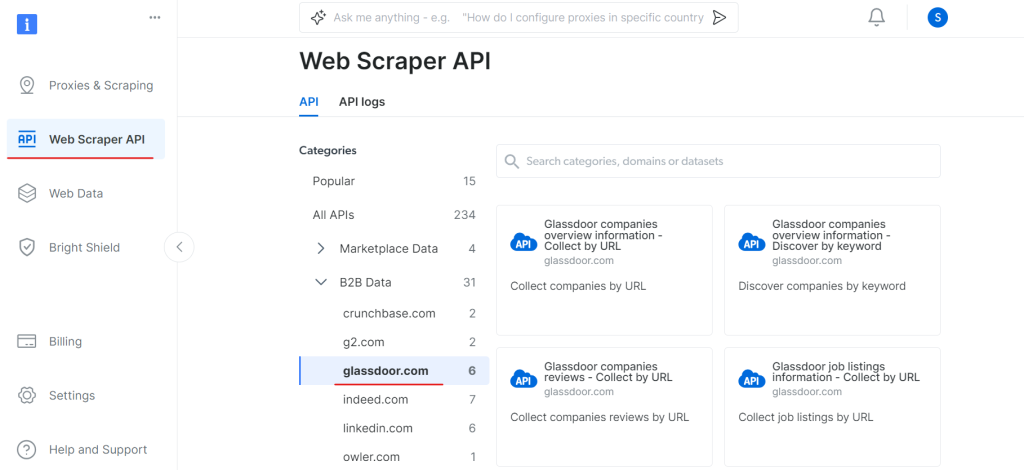
在“Glassdoor公司概览信息”下,获取您的API令牌并复制您的数据集ID(例如gd_l7j0bx501ockwldaqf)。
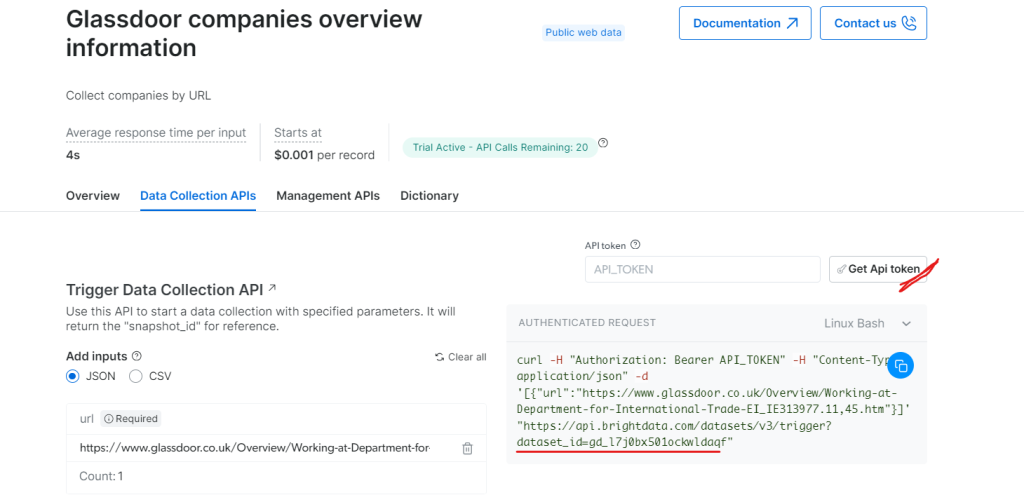
现在,下面是一个简单的代码片段,展示了如何通过提供URL、API令牌和数据集ID来提取公司数据。
import requests
import json
def trigger_dataset(api_token, dataset_id, company_url):
"""
Triggers a dataset using the BrightData API.
Args:
api_token (str): The API token for authentication.
dataset_id (str): The dataset ID to trigger.
company_url (str): The URL of the company page to analyze.
Returns:
dict: The JSON response from the API.
"""
headers = {
"Authorization": f"Bearer {api_token}",
"Content-Type": "application/json",
}
payload = json.dumps([{"url": company_url}])
response = requests.post(
"https://api.brightdata.com/datasets/v3/trigger",
headers=headers,
params={"dataset_id": dataset_id},
data=payload,
)
return response.json()
api_token = "API_Token"
dataset_id = "DATASET_ID"
company_url = "COMPANY_PAGE_URL"
response_data = trigger_dataset(api_token, dataset_id, company_url)
print(response_data)运行代码后,您将收到一个快照ID,如下所示:

使用快照ID来检索公司的实际数据。在终端中运行以下命令。对于Windows,使用:
curl.exe -H "Authorization: Bearer API_TOKEN" \
"https://api.brightdata.com/datasets/v3/snapshot/s_m0v14wn11w6tcxfih8?format=json"对于Linux:
curl -H "Authorization: Bearer API_TOKEN" \
"https://api.brightdata.com/datasets/v3/snapshot/s_m0v14wn11w6tcxfih8?format=json"运行命令后,您将获得所需的数据。
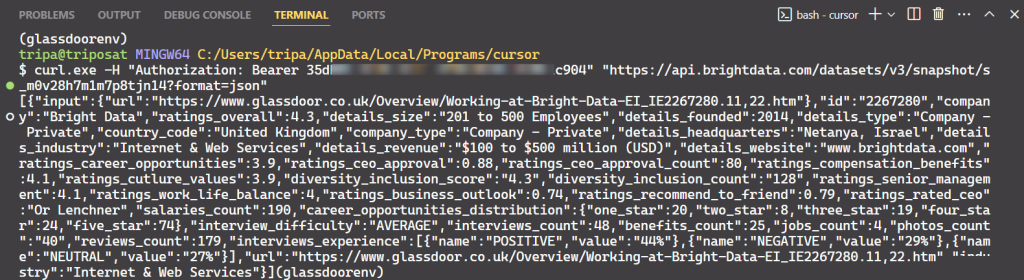
就是这么简单!
同样,您可以通过修改代码从Glassdoor提取各种类型的数据。我已经解释了一种方法,但还有其他五种方法可以做到。因此,我建议探索这些选项以抓取您想要的数据。每种方法都针对特定的数据需求,帮助您获得所需的确切数据。
结论
在本教程中,您学习了如何使用Playwright Python抓取Glassdoor数据。您还了解了Glassdoor采用的反抓取技术以及如何绕过它们。为了解决这些问题,我们介绍了Bright Data的Glassdoor抓取API,它可以帮助您克服Glassdoor的反抓取措施,轻松提取所需的数据。
您还可以尝试Scraping Browser,这是一种新一代浏览器,可以与任何其他浏览器自动化工具集成。Scraping Browser可以轻松绕过反机器人技术,同时避免浏览器指纹识别。它依赖于用户代理轮换、IP轮换和CAPTCHA解决等功能。
立即注册,免费试用Bright Data的产品。



