uppeteer 是一个浏览器测试和自动化库,非常适合网页抓取。与 Axios 和 cheerio等其它简单工具相比,Puppeteer 赋予开发人员抓取动态数据内容的便利(即根据用户操作更改的内容)。
就是说,可以使用它来抓取使用 JavaScript 加载内容的 Web 应用程序(单页应用程序),以下为详尽介绍。
使用Puppeteer抓取网页数据
该指南将教你如何使用 Puppeteer 抓取静态和动态数据(即来自亮数据Bright Data 博客 的帖子标题和链接)。
配置
在开始之前,您需要确保计算机上安装了Node.js,点击他们的官方下载页面下载它。
然后为项目创建一个新目录,并使用以下命令导航到该目录:
mkdir puppeteer_tutorial
cd puppeteer_tutorial
npm init -y接下来,使用以下命令安装 Puppeteer:
npm i puppeteer --save此命令还会让你下载专用浏览器,稍后库会用到。
抓取静态网站数据
与所有网页抓取工具一样,Puppeteer 可以让您抓取网页的 HTML 代码。
您可以按照以下步骤使用 Puppeteer 从 Bright Data 的博客中抓取帖子的首页:
创建一个index.js文件并导入Puppeteer:
const puppeteer = require('puppeteer');然后插入运行 Puppeteer 所需的样板:
(async () => {
const browser = await puppeteer.launch({
headless: false,
defaultViewport: null
});
const page = await browser.newPage();
await page.goto('https://brightdata.com/blog');
// all the web scraping will happen here
await browser.close();
})();此函数打开浏览器,导航到页面以抓取它,然后关闭浏览器。
剩下要做的就是从页面中抓取数据了。
在 Puppeteer 中,访问 HTML 数据的最简单方法是通过page.evaluate 方法。虽然 Puppeteer 有用于获取元素包装器的 $ 和 $$ 方法,但从 page.evaluate获取所有数据更简单。
在亮数据 Bright Data 博客中,所有博客文章数据都在<a> 标记中,包含在类为 brd_post_entry 的。帖子的标题位于类为 brd_post_title 的 <h3> 元素中。帖子的链接是 brd_post_entry 的 href 值。
提取这些值的 page.evaluate 函数如下所示:
const data = await page.evaluate( () => {
let data = [];
const titles = document.querySelectorAll('.brd_post_entry');
for (const title of titles) {
const titleText = title.querySelector('.brd_post_title').textContent;
const titleLink = title.href;
const article = { title: titleText, link: titleLink };
data.push(article);
}
return data;
})然后可以在控制台打印出数据:
console.log(data);完整的脚本如下所示:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({
headless: false,
defaultViewport: null
});
const page = await browser.newPage();
await page.goto('https://brightdata.com/blog');
const data = await page.evaluate(() => {
let data = [];
const titles = document.querySelectorAll('.brd_post_entry');
for (const title of titles) {
const titleText = title.querySelector('.brd_post_title').textContent;
const titleLink = title.href;
const article = { title: titleText, link: titleLink };
data.push(article);
}
return data;
})
console.log(data);
await browser.close();
})();通过在终端中调用 node index.js 来运行它。该脚本应返回帖子标题和链接的列表:
[
{
title: 'APIs for Dummies: Learning About APIs',
link: 'https://brightdata.com/blog/web-data/apis-for-dummies'
},
{
title: 'Guide to Using cURL with Python',
link: 'https://brightdata.com/blog/how-tos/curl-with-python'
},
{
title: 'Guide to Scraping Walmart',
link: 'https://brightdata.com/blog/how-tos/guide-to-scraping-walmart'
},
…抓取动态网页内容
抓取静态内容是一项简单的任务,可以使用简单的工具轻松完成。值得庆幸的是,Puppeteer 可用于完成多种操作,例如单击、键入和滚动。您可以使用所有这些与动态页面交互并模拟用户操作。
类似库的常见网络抓取任务是搜索页面上的特定数据集。例如,您可能想要使用 Puppeteer 搜索有关 Puppeteer 的所有 Bright Data 帖子。
以下为操作步骤:
第1步:接受 Cookies
当用户访问 Bright Data 博客时,有时会弹出一个 cookie 横幅:
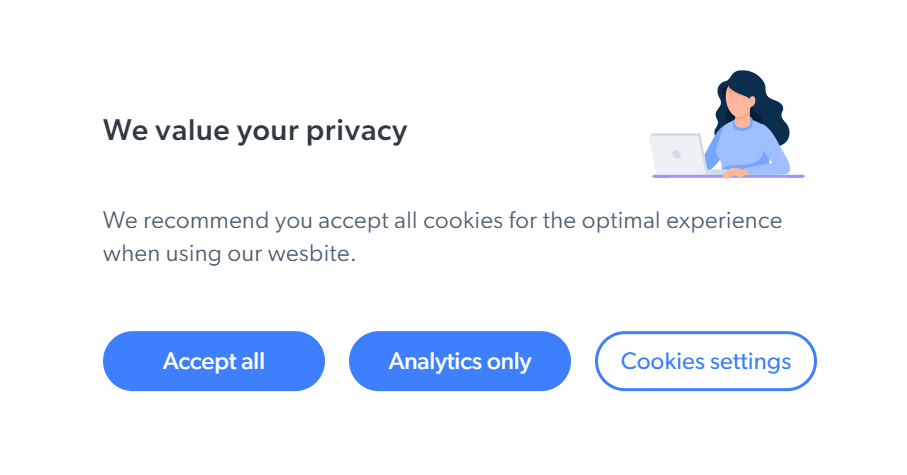
正确的处理方法是使用以下代码单击接受全部按钮:
await page.waitForSelector('#brd_cookies_bar_accept', {timeout: 5000})
.then(element => element.click())
.catch(error => console.log(error));代码的第一行等待带有 #brd_cookies_bar_accept 的项目出现 5 秒。第二行单击该元素。第三行确保如果 cookie 栏不出现,脚本不会崩溃。
请注意,Puppeteer 中的等待是通过设置一些您想要等待的条件来实现的,而不是为要执行的上一个操作设置特定的等待时间。前者称为隐式等待,后者称为显式等待。
在 Puppeteer 中通常不推荐显式等待,因为它会导致执行问题。如果您提供明确的等待时间,那么它肯定会太长(效率低下)或太短(这意味着脚本将无法正确执行)。
第2步:搜索帖子
然后,脚本需要单击搜索图标。输入“Puppeteer”并再次按搜索图标以触发搜索:

该操作可以通过以下代码完成:
await page.click('.search_icon');
await page.waitForSelector('.search_container.active');
const search_form = await page.waitForSelector('#blog_search');
await search_form.type('puppeteer');
await page.click('.search_icon');
await new Promise(r => setTimeout(r, 2000));此例子的操作方式与 cookie 横幅示例类似。单击按钮后,您需要等待搜索容器出现,这就是代码等待与 .search_container.active 的 CSS 选择器匹配的元素的原因。
此外,您还需要为要加载的项目添加两秒的停止。虽然 Puppeteer 不鼓励显式等待,但目前没有其他好的选择。
在大多数网站中,如果 URL 发生更改,您可以使用 waitForNavigation 方法。如果出现新元素,可以使用 waitForSelector 方法。确定某些元素是否已刷新不太容易,并且超出了本文的范围。
如果您想自己尝试一下,点击 Stack Overflow 答案 可以找到相关内容。
第3步:搜集帖子
搜索帖子后,您可以使用已用于静态页面抓取的代码来获取博客帖子的标题:
const data = await page.evaluate( () => {
let data = [];
const titles = document.querySelectorAll('.brd_post_entry');
for (const title of titles) {
const titleText = title.querySelector('.brd_post_title').textContent;
const titleLink = title.href;
const article = { title: titleText, link: titleLink };
data.push(article);
}
return data;
})
console.log(data);以下为该脚本的完整代码:
const puppeteer = require('puppeteer');
(async () => {
const browser = await puppeteer.launch({
headless: false,
defaultViewport: null
});
const page = await browser.newPage();
await page.goto('https://brightdata.com/blog');
const cookie_bar_accept = await page.waitForSelector('#brd_cookies_bar_accept');
await cookie_bar_accept.click();
await new Promise(r => setTimeout(r, 500));
await page.click('.search_icon');
await page.waitForSelector('.search_container.active');
const search_form = await page.waitForSelector('#blog_search');
await search_form.type('puppeteer');
await page.click('.search_icon');
await new Promise(r => setTimeout(r, 2000));
const data = await page.evaluate( () => {
let data = [];
const titles = document.querySelectorAll('.brd_post_entry');
for (const title of titles) {
const titleText = title.querySelector('.brd_post_title').textContent;
const titleLink = title.href;
const article = { title: titleText, link: titleLink };
data.push(article);
}
return data;
})
console.log(data);
await browser.close();
})();有更好的其它方法吗?
虽然可以使用 Puppeteer 抓取网页脚本,但这并不理想。 Puppeteer 是为测试自动化而设计的,因而完成网页数据抓取有点尴尬。
例如,如果您想在脚本中实现规模和效率,那么能够在不被阻止的情况下进行抓取非常重要。为此,您可以使用代理网络,它是您和您抓取的网站之间的网关。虽然 Puppeteer 支持使用代理网络,但您需要自行查找代理网络 并与其签订合同(了解有关Puppeteer与亮数据Bright Data 代理网络集成 更多信息)。
此外,优化 Puppeteer 以实现并行使用并不容易。如果您想抓取大量数据,则需要投入大量时间才能获得最佳性能。
这些缺点意味着 Puppeteer 是业余爱好使用的小型脚本的不错选择,但如果正式使用它,则需要花费大量时间来扩展操作。
如果您想要更容易使用且高速快捷的工具,亮数据 Bright Data 这样的网络数据平台是不错的选择。它使公司企业拥有简单快捷的工具,实现大量从网络采集结构化数据,例如专门为抓取而设计的数据抓取浏览器(与 Puppeteer/Playwright 兼容)。
总结
在本文中,您学习了如何使用 Puppeteer 抓取静态和动态网页。
Puppeteer 可以执行的大部分浏览器的操作功能,包括单击项目、键入文本和执行 JavaScript。而且由于使用了隐式等待,用 Puppeteer 编写的脚本快速且易于编写。
缺陷是,Puppeteer 并不是最有效的网页数据抓取工具,而且它的文档不太适合初学者。如果您还没有熟练使用 Puppeteer,那么使用 Puppeteer 来扩展抓取操作也很困难。
厌倦了自己抓取数据? 点击这里获取预先收集好的或按需定制的数据集。