网络上有大量数据,对于研究和商业决策来说非常宝贵。这就是为什么知道如何使用像 Playwright 这样的工具非常重要。
Playwright是一个由微软开发的强大的 Node.js 库,可以从网站抓取数据。在这篇文章中,你将看到使用Playwright从 Bright Data首页抓取数据的实际、详细示例。然后,你可以将这些示例应用到任何你想要使用Playwright抓取的网站。
为什么使用Playwright
网页抓取不是一个新概念。在JavaScript生态系统中,工具如 Cheerio、 Selenium、 Puppeteer和Playwright都帮助简化了网页抓取。
作为一个较新的网页抓取库,Playwright特别吸引人,因为它具有以下特点:
强大的定位器
Playwright使用 定位器,它们内置了自动等待和重试逻辑,用于选择网页上的元素。自动等待逻辑简化了你的网页抓取代码,因为你不必手动等待网页加载。
重试逻辑也使Playwright成为抓取现代单页应用程序(SPA)的合适库,这些应用程序在初始页面加载后动态加载数据。
多种定位方法
使用定位器时,Playwright允许你使用多种不同的语法指定网页上要定位的元素,包括 CSS选择器语法、 XPath语法和元素文本内容。你还可以对定位器应用 过滤器 进一步精炼定位器。
使用Playwright进行网页抓取
在本节中,你将创建一个Node.js项目,安装Playwright,并学习如何使用Playwright定位、与网页元素交互和提取数据。
前提条件
本文中的代码片段运行在最新的长期支持(LTS)版本的Node.js上,本文撰写时为v18.15.0。在开始之前,请确保你已经 安装了Node.js。
还强烈推荐使用能够突出显示JavaScript语法和自动完成代码的编辑器,如 Visual Studio Code。
创建新项目
打开一个新的终端窗口,为你的Node.js项目创建一个新文件夹并使用以下命令进入该文件夹:
mkdir playwright-demo
cd playwright-demo接下来,通过运行以下npm命令创建你的Node.js项目:
npm init -y安装Playwright
创建Node.js项目后,在终端窗口中使用以下命令安装 Playwright库:
npm install playwright因为Playwright会在安装过程中下载必要的浏览器,库的安装可能需要一段时间。
打开Bright Data首页
安装Playwright库后,在项目文件夹中创建一个名为 index.js的新文件。然后将以下代码复制到其中:
// Import the Playwright library to use it
const playwright = require("playwright");
(async () => {
// Launch a new instance of a Chromium browser
const browser = await playwright.chromium.launch({
// Set headless to false so you can see how Playwright is
// interacting with the browser
headless: false,
});
// Create a new Playwright context
const context = await browser.newContext();
// Create a new page/tab in the context.
const page = await context.newPage();
// Navigate to the Bright Data home page.
await page.goto("https://brightdata.com/");
// Wait 10 seconds (or 10,000 milliseconds)
await page.waitForTimeout(10000);
// Close the browser
await browser.close();
})();在终端中使用以下命令运行代码片段:
node index.js一个 Chromium 浏览器应该会打开并加载Bright Data首页:
定位元素
现在你已经使用Playwright导航到Bright Data首页,你可以使用定位器选择网页上的特定元素。Playwright有几种定位器,以下部分将演示每个定位器的工作方式。
使用CSS选择器定位元素
Playwright让你可以使用 CSS选择器定位网页上的元素,这是一种在CSS中用于对网页上的特定HTML元素应用样式的简洁而强大的语法。
例如,Bright Data的标志是页眉中的一个 <svg> 元素,附有 page_header_logo_svg 类:

使用这些信息,你可以使用CSS选择器定位SVG元素:
const logoSvg = page.locator(".page_header_logo_svg");定位器存储在 logoSvg 变量中,可以稍后用于与元素交互或从中提取信息。
使用XPath查询定位元素
XPath 是另一种选择器语法,你可以使用它在XML文档中定位元素。由于HTML是XML,你可以使用该语法在网页上找到HTML元素。
例如,你可以使用以下XPath查询选择上节中看到的同一个SVG标志:
const logoSvg = page.locator("//*[@class='page_header_logo_svg']");该查询查找附有 page_header_logo_svg 类的任何元素,并将其位置存储在 logoSvg 变量中。
按角色定位元素
HTML元素可以附有不同的角色。这些 角色为网页提供语义意义,使屏幕阅读器和其他工具更容易支持该网页。你可以在 此处 阅读更多关于角色的信息。
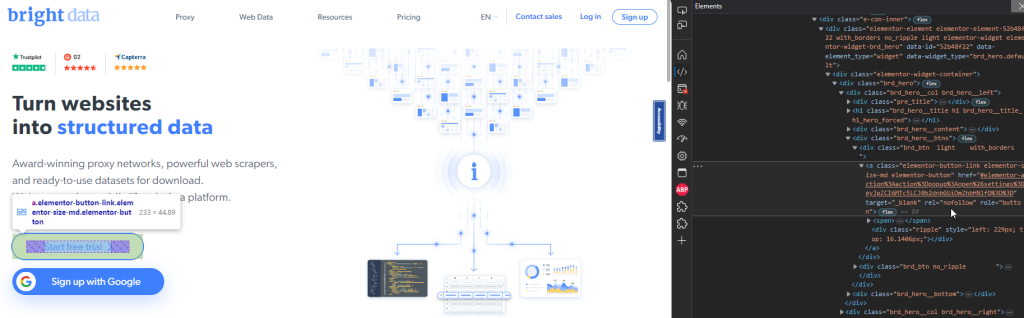
以下代码片段展示了如何使用角色和名称找到 注册 按钮:
const signupButton = page.getByRole("button", {
name: "Start free trial",
});此代码片段将在首页找到 开始免费试用 按钮:
按文本定位元素
如果HTML元素没有有意义的标识符属性,例如 id 或 class 属性,你可以使用 getByText 方法按其文本选择该元素。
例如,Bright Data首页在英雄部分有一个标题,其中包含蓝色的“结构化数据”字样:

你可以使用以下Playwright代码片段选择包含这些字样的 <span> 元素:
const structuredData = page.getByText("structured data");按标签定位元素
在HTML表单中,输入元素通常有标签。Playwright可以使用这些标签通过 getByLabel 方法识别与该标签关联的输入元素。
例如,Bright Data 登录 页面有一个标签中包含“工作邮箱”字样的输入元素:
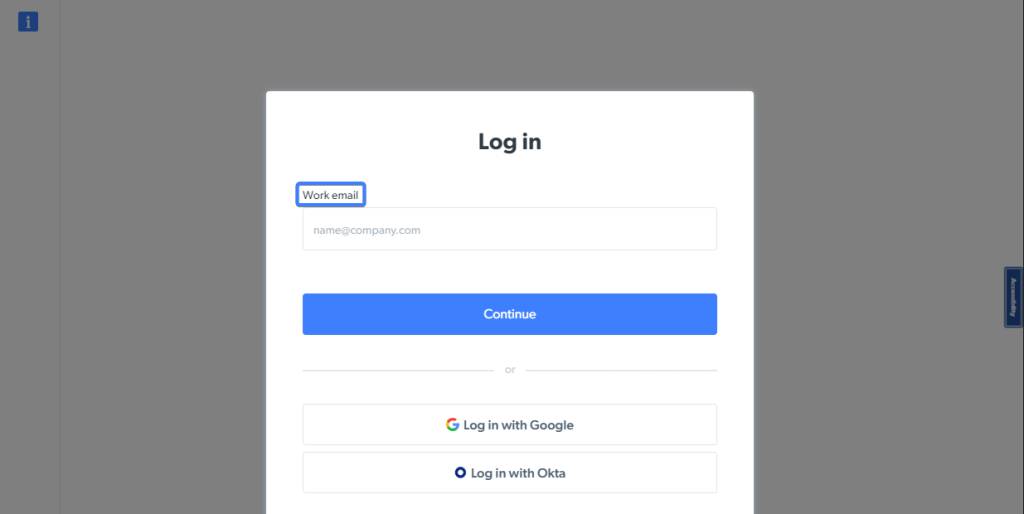
你可以使用以下代码片段在页面上定位输入元素并将其存储在一个变量中以备后用:
// Navigate to the Bright Data login page.
await page.goto("https://brightdata.com/cp/start");
// Locate the <input> using the label
const emailInput = page.getByLabel("Work email");按占位符定位元素
你还可以基于显示的占位符值使用 getByPlaceholder 方法定位输入元素。
你会注意到Bright Data 登录 页面的邮箱字段有占位符文本,以便为用户提供有关输入信息的上下文。
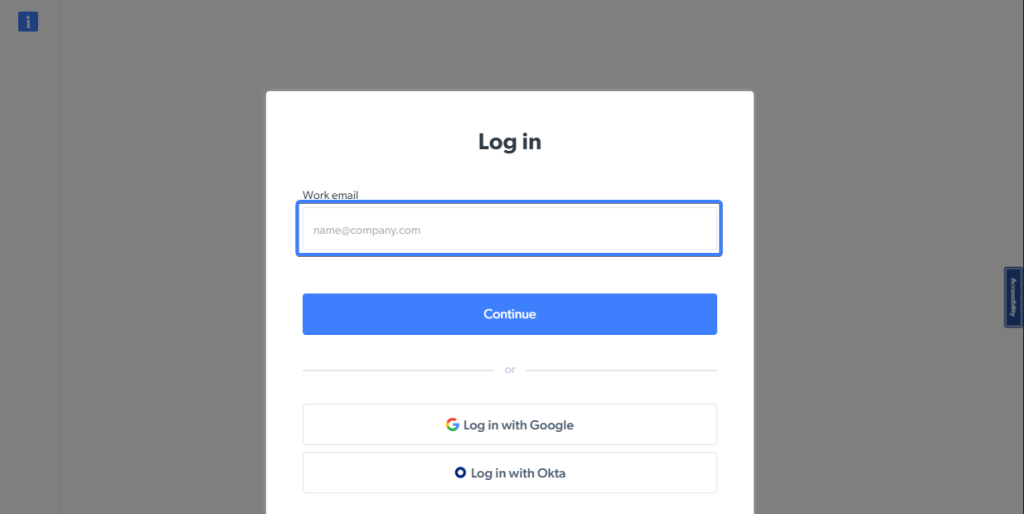
以下代码片段将基于输入的占位符值定位该元素:
// Navigate to the Bright Data login page.
await page.goto("https://brightdata.com/cp/start");
// Locate the <input> using the placeholder
const emailInput = page.getByPlaceholder("[email protected]");按替代文本定位元素
HTML允许你使用 alt 属性为图像添加文本描述,当图片未加载时会显示此文本,并且屏幕阅读器会朗读它来描述图像。Playwright的 getByAltText 方法让你可以通过其 alt 属性定位 img 元素。
例如,Bright Data列出了使用其数据的行业。你可以使用其替代值 "healthcare use case" 来检索用于医疗保健行业的图像:
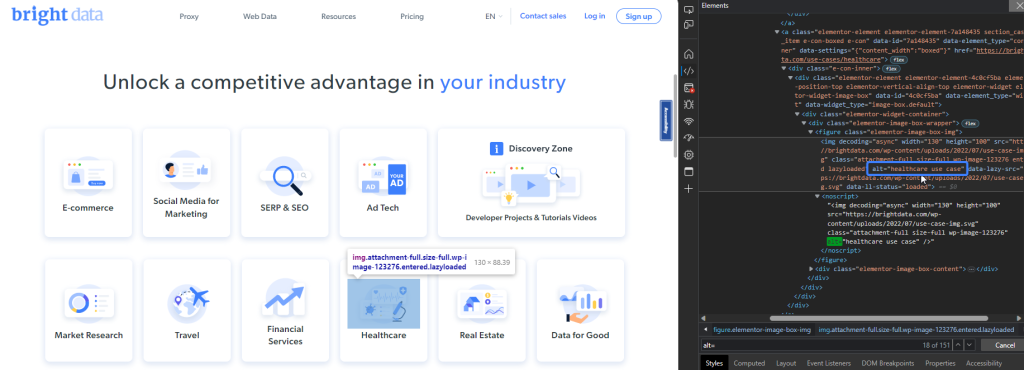
以下代码片段将基于替代值定位图像元素:
const healthcareImage = page.getByAltText("healthcare use case");按标题定位元素
最后一个你可以用于抓取的Playwright选择器是 getByTitle 方法,该方法通过其标题属性定位HTML元素。当你将指针悬停在HTML组件上时,你会看到标题值。
例如,Bright Data帮助台网站包含一个带有 标题属性的登录链接:

你可以使用以下Playwright代码片段通过其标题属性定位该链接:
// Navigate to the Bright Data helpdesk webpage.
await page.goto("https://help.brightdata.com/hc/en-us");
// Locate the Sign in link using its title attribute
const signInLink = page.getByTitle("Opens a dialog");现在你已经看到几种使用Playwright定位网页上元素的方法,接下来学习如何与这些元素交互并提取数据。
与元素交互
在网页上定位元素后,你可以与之交互。例如,你可能需要在抓取受保护的页面之前登录网站。
此代码片段展示了不同的Playwright方法来与网页上的元素交互。以下代码中的每个函数都有解释:
// Import the Playwright library to use it
const playwright = require("playwright");
(async () => {
// Launch a new instance of a Chromium browser
const browser = await playwright.chromium.launch({
// Set headless to false so you can see how Playwright is
// interacting with the browser
headless: false,
});
// Create a new Playwright context
const context = await browser.newContext();
// Create a new page/tab in the context.
const page = await context.newPage();
// Navigate to the Bright Data login page.
await page.goto("https://brightdata.com/");
// Locate and click on the signup button
await page
.locator("#hero_new")
.getByRole("button", {
name: "Start free trial",
})
.click();
// Locate the first name field and FILL in a first name
await page.locator(".hs_firstname input").fill("John");
// Locate the last name field and FILL in a last name
await page.locator(".hs_lastname input").fill("Smith");
// Locate the email field and TYPE in an email address
await page.locator(".hs_email input").type("[email protected]");
// Locate the company size field and SELECT an option
await page.locator(".hs_numemployees select").selectOption("1-9 employees");
// Locate the terms and conditions checkbox and CHECK it.
await page.locator(".legal-consent-container input").check();
// Wait 10 seconds so you can see the result.
await page.waitForTimeout(10000);
// Close the browser
await browser.close();
})();将此代码片段粘贴到 index.js 文件中,并使用以下命令重新运行它:
node index.jsBright Data首页将短暂显示,然后显示一个注册对话框。接下来,你将看到Playwright如何使用此代码片段中的不同方法填充 注册 表单:
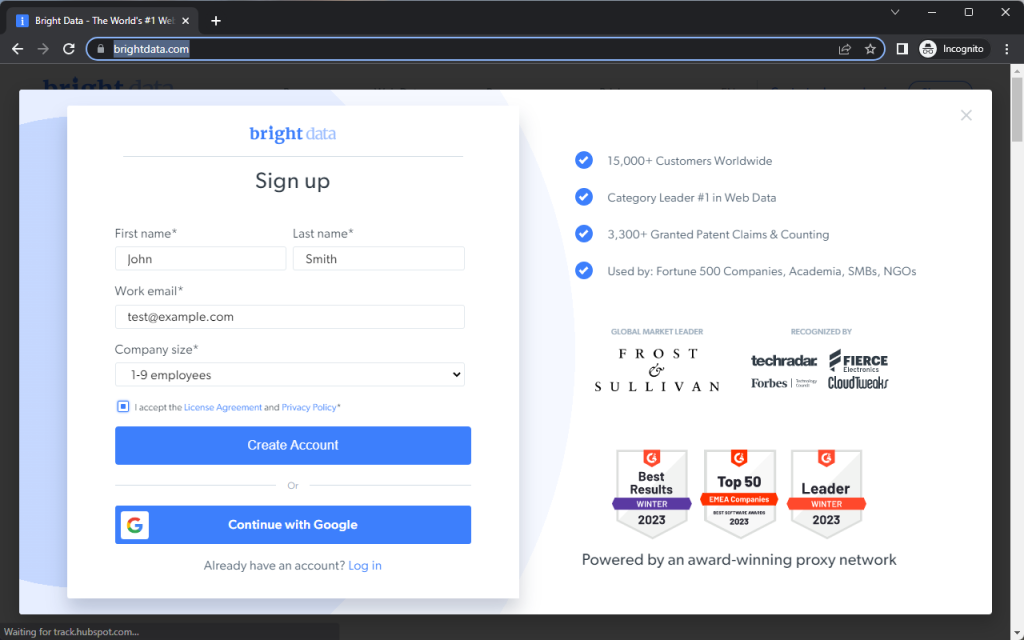
点击元素
在上一个代码片段中,Playwright首先点击了 注册 按钮以便显示对话框:
// Locate and click on the signup button
await page
.getByRole("button", {
name: "Start free trial",
})
.click();Playwright有两种方法 点击 元素:
click方法 模拟单击元素。dblclick方法 模拟双击元素。
在此示例中,你只需要单击 注册 按钮,因此代码片段使用了 click 方法。
填写文本字段
在此示例中,代码片段使用了两种方法填写 注册 表单上的文本字段:
// Locate the first name field and FILL in a first name
await page.locator(".hs_firstname input").fill("John");
// Locate the last name field and FILL in a last name
await page.locator(".hs_lastname input").fill("Smith");
// Locate the email field and TYPE in an email address
await page.locator(".hs_email input").type("[email protected]");代码片段在不同字段上使用了 fill 和 type 方法。两者都填充了文本字段,但它们的工作方式略有不同:
你可能会在大多数情况下使用 fill 方法,但在必要时可以使用 type 方法模拟手动输入值。
选择下拉选项
注册 表单有一个下拉字段用于选择公司规模,Playwright用“1–9员工”填充了该字段:
// Locate the company size field and SELECT an option
await page.locator(".hs_numemployees select").selectOption("1-9 employees");Playwright允许你使用 selectOption 方法 填充表单上的下拉字段。该函数允许你根据值或标签选择下拉项,并在多选中选择多个选项。
勾选单选按钮和复选框
在提交表单之前,你需要接受条款和条件。以下代码片段勾选了相应的复选框:
// Locate the terms and conditions checkbox and CHECK it.
await page.locator(".legal-consent-container input").check();要修改复选框,你可以使用 check 和 uncheck 方法:
check方法 确保复选框被选中。uncheck方法 确保复选框未被选中。
现在你已经看到Playwright如何让你与网页上的HTML元素交互,下一节将展示如何从这些元素中提取数据。
从元素中提取数据
提取 数据是网页抓取的关键。Playwright让你可以使用几种方法从定位到的元素中提取不同的数据类型。以下部分将介绍一些这些方法。
提取内部文本
innerText 方法让你可以提取元素内部的文本。例如,Bright Data首页顶部有一个英雄元素:
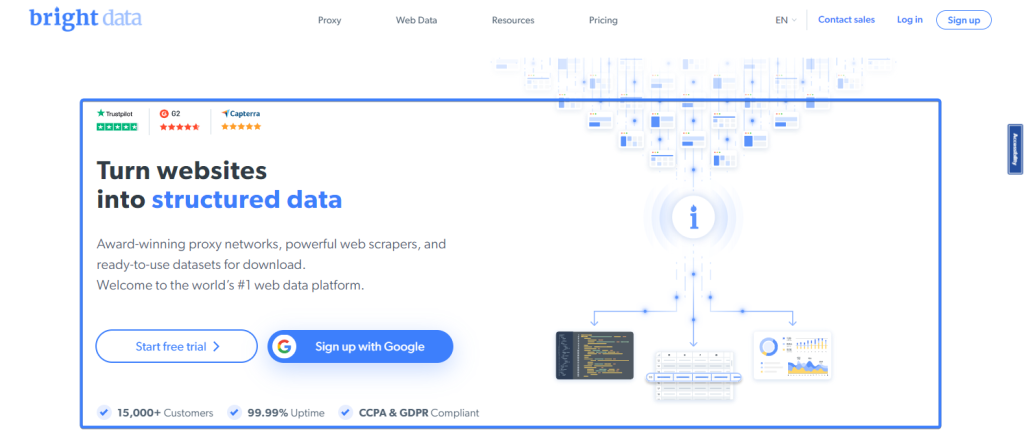
你可以使用以下代码片段提取Bright Data首页英雄部分的标题:
const headerText = await page.locator(".brd_hero__title.h1").innerText();
// headerText = "Turn websitesninto structured data"如果你的定位器指向多个元素,你可以使用 allInnerTexts 方法将所有元素中的文本作为数组字符串提取。例如,Bright Data首页有一列表举了其数据的使用案例:
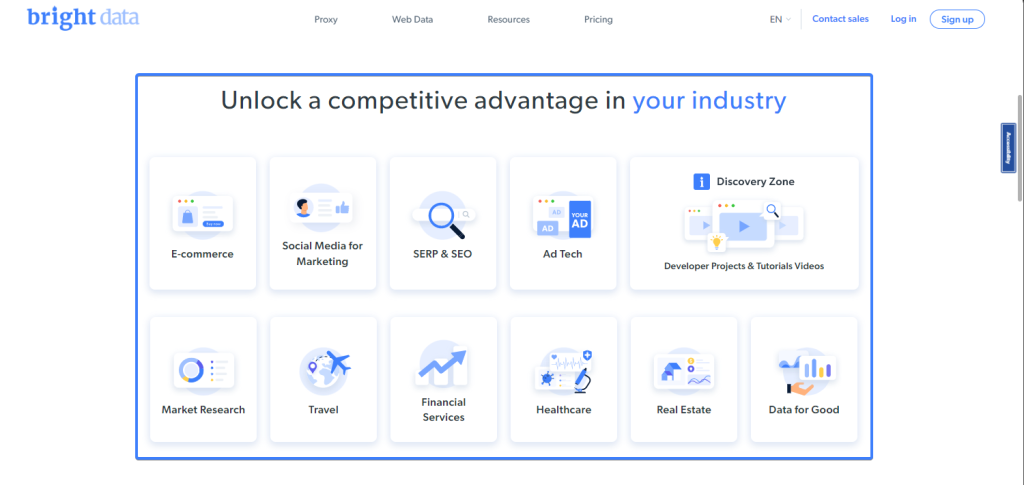
你可以使用以下代码片段提取所有Bright Data使用案例的列表:
cconst useCases = await page
.locator(".section_cases_row_col .elementor-image-box-title")
.allInnerTexts();
// useCases = [
// 'E-commerce',
// 'Social Media for Marketing',
// 'SERP & SEO',
// 'Ad Tech',
// 'Market Research',
// 'Travel',
// 'Financial Services',
// 'Healthcare',
// 'Real Estate',
// 'Data for Good'
// ]提取内部HTML
Playwright还允许你使用 innerHTML 方法提取元素的内部HTML。例如,你可以使用以下代码片段获取Bright Data首页的页脚HTML:
const footerHtml = await page.locator("#footer").innerHTML();
// footerHtml = '<div class="container"><div class="footer__logo">...'提取属性值
你可能需要从HTML元素的属性中提取数据,例如链接的 href 属性。以下Playwright代码片段演示了如何抓取 登录 链接的 href 属性:
const signUpHref = await page.getByText("Log in").getAttribute("href");
// signUpHref = '/cp/start'截图页面
在抓取数据时,你可能需要截图以进行审核。你可以使用 screenshot 方法来完成此操作。该函数允许你配置多个选项,例如保存截图文件的位置以及是否进行全页面截图。
以下代码片段将截取Bright Data首页的全页面截图并保存:
await page.screenshot({
// Save the screenshot to the "homepage.png" file
path: "homepage.png",
// Take a screenshot of the entire page
fullPage: true,
});使用自动抓取服务
前面的代码片段详细介绍了如何定位、与网页元素交互和提取数据。这些方法可以让你从网页上抓取几乎任何数据。然而,这些方法需要付出努力,因为你必须在定位元素之前识别适当的元素。在抓取单个网站的多个页面时,你还需要注意CAPTCHA和速率限制。
Bright Data提供了几种解决方案,让你专注于数据提取。Bright Data提供了一个 网页抓取IDE (无服务器函数),其中包含现成的JavaScript函数和模板,帮助你从热门网站抓取数据。你还可以使用 网页解锁器 绕过CAPTCHA,并使用Bright Data的 代理服务 避免速率限制和地理位置阻拦。这些服务可以消除Playwright中的许多障碍,帮助你更快、更轻松地抓取数据。
想让抓取变得更简单吗?选择 网页抓取API 或购买一个 新鲜的数据集!
总结
本文介绍了Playwright,这是一个由微软开发的库,可以帮助从网站抓取数据。你还学习了如何使用Playwright定位、与网页元素交互和提取数据。最后,你看到了Bright Data等自动抓取服务如何简化你的网页抓取过程。
立即开始你的免费试用吧!