

网络爬虫是一个自动化过程,用于从网站上收集大量以不同格式(如文本、数字、图像、音频或视频等)呈现的 HTML 数据。大多数网站(包括 YouTube 或 eBay)通过根据用户交互显示动态内容。
如果你对网络爬虫感兴趣,可能听说过 Selenium。它是一个开源的网络爬虫工具,提供了从动态网站抓取数据的高级技术。它可以通过执行各种操作模拟用户交互,如填写表单、导航网页和选择由 JavaScript 渲染的特定内容。
本教程将教你如何使用 Selenium Python 包开始抓取数据。
设置 Selenium 和 Python 环境
在使用 Selenium 进行网络爬虫之前,你需要设置 Python 环境并安装 Selenium Python 包 和 webdriver_manager Python 包。webdriver_manager 是一个 Python 包,用于下载和管理不同浏览器(包括 Chrome、Firefox 和 Edge)的二进制驱动程序。
安装这些包后,还需要在环境中 配置环境变量和代理服务器。安装所有需要的包后,你就可以启动浏览器并开始抓取数据了。
要自动启动 Chrome 浏览器并访问特定 URL 的网页,请在终端中的 Python 脚本文件(如 web_scrape.py)中运行以下代码:
# import module
from selenium import webdriver
#setup chrome webdriver
driver = webdriver.Chrome()
#load the web page
driver.get('https://yourwebsite.com')
# print page source
print(driver.page_source)
# close the driver
driver.quit()要运行上述代码,请在终端中使用以下命令:
python web_scrape.py该代码将启动 Chrome 浏览器,访问提供的 URL 的网页,显示加载的网页的 HTML,并关闭 Chrome 驱动实例。
理解 HTML 和定位元素
HTML 使用标签包围的元素来结构化网页内容(如 <h1>内容</h1>)。这些元素将内容组织成层次结构,定义网页的布局、格式和交互性。
要在浏览器中定位网页上的 HTML 标签,可以右键单击要查找的元素并选择检查(或类似的选项,具体取决于你的浏览器)。这将打开浏览器的开发者工具,你可以在其中查看 HTML 代码并定位特定标签:
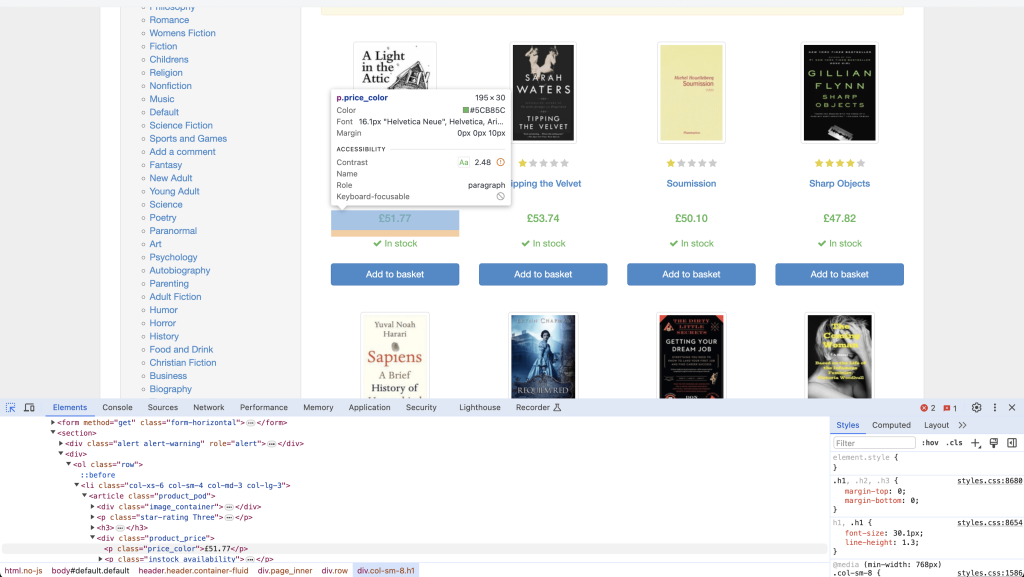
定位到元素后,可以在检查器中右键单击该元素并复制其标签、类、CSS 选择器或绝对 XPath 表达式。
Selenium 提供了两种定位网页 HTML 元素的方法:find_element 和 find_elements。find_element 方法查找网页上的特定单个元素,而 find_elements 方法则检索包含网页上发现的所有元素的列表。
这些方法兼容 Selenium 定义的各种定位器,包括以下内容:
By.Name根据名称属性定位元素。By.ID根据 ID 定位元素。By.XPATH根据 XPath 表达式定位元素。By.TAG_NAME根据标签名称定位元素。By.CLASS_NAME根据类定位元素。By.CSS_SELECTOR根据 CSS 选择器定位元素。
假设你想根据可用的 HTML 元素收集数据,并且有一个这样的 HTML 文档:
<!DOCTYPE html>
<html>
<head>
<title>Sample HTML Page</title>
</head>
<body>
<div id="content">
<h1 class="heading">Welcome to my website!</h1>
<p>This is a sample paragraph.</p>
</div>
</body>
</html>你可以使用 Selenium 的 By.Name 定位器来定位 h1 标签:
h1 = driver.find_element(By.NAME, 'h1')要从 HTML 文档中定位 ID,可以使用 By.ID 定位器:
content = driver.find_element(By.ID, 'content')你还可以使用 By.CLASS_NAME 来定位所有类为 "heading" 的 HTML 元素:
classes = driver.find_elements(By.CLASS_NAME, 'heading')使用 Selenium 进行网络爬虫
在定位到 HTML 标签后,Selenium 提供了不同的提取方法,你可以使用这些方法从网站收集数据。最常用的方法如下:
text从 HTML 标签中提取文本。get_attributes()提取 HTML 标签中的属性值。
以下示例演示了如何使用定位器(如 ID、CSS 选择器和标签名称)和提取方法与页面交互并从以下Amazon 页面抓取页面标题和其他详细信息:
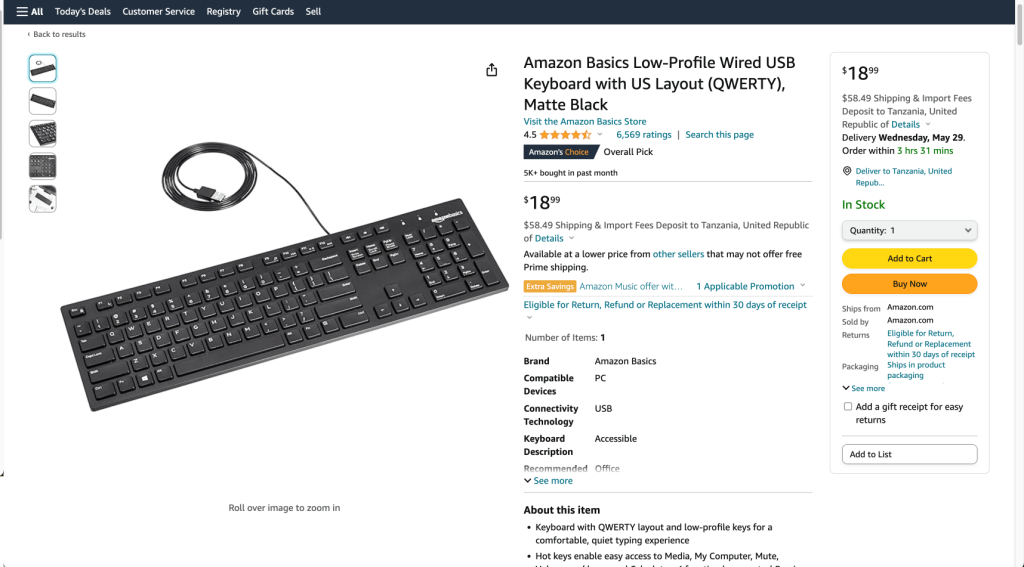
要抓取页面,首先需要创建一个新的 Python 脚本文件(如 selenium_scraping.py)来编写抓取代码。接下来,导入 Python 包并实例化 WebDriver。
导入 Python 包并实例化 WebDriver
要导入所需模块,请在 selenium_scraping.py 顶部添加以下代码:
# import libraries
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from webdriver_manager.chrome import ChromeDriverManager
from selenium.webdriver.common.keys import Keys
from selenium.webdriver.common.action_chains import ActionChains
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import time
from selenium.webdriver.chrome.options import Options此代码导入了 Selenium 和 WebDriver 所需的不同模块以抓取数据。
要自动浏览 Amazon URL 并抓取数据,需要实例化与 Selenium 交互的Chrome WebDriver。
粘贴以下代码,它会安装 ChromeDriver 二进制文件(如果尚未安装),然后实例化它:
driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()))注意:如果不想使用 Chrome,Selenium 还支持其他浏览器的驱动程序。
定义 URL 并抓取产品标题
要自动加载网页,需要在 Python 变量(如 url)中定义 Amazon URL,然后传递给驱动程序的 get() 方法:
#Define the URL
url = "https://www.amazon.com/AmazonBasics-Matte-Keyboard-QWERTY-Layout/dp/B07WJ5D3H4/"
#load the web page
driver.get(url)
#set the maximum time to load the web page in seconds
driver.implicitly_wait(10)运行此代码时,Selenium 会自动在 ChromeDriver 中加载 Amazon 页面链接。指定的时间范围确保网页上的所有内容和 HTML 元素完全加载。
要从 Amazon 链接中抓取产品标题,需要使用网页上显示的 ID。为此,请在浏览器中打开 Amazon URL,然后右键单击并选择检查以识别包含产品标题的 ID(如 productTitle):
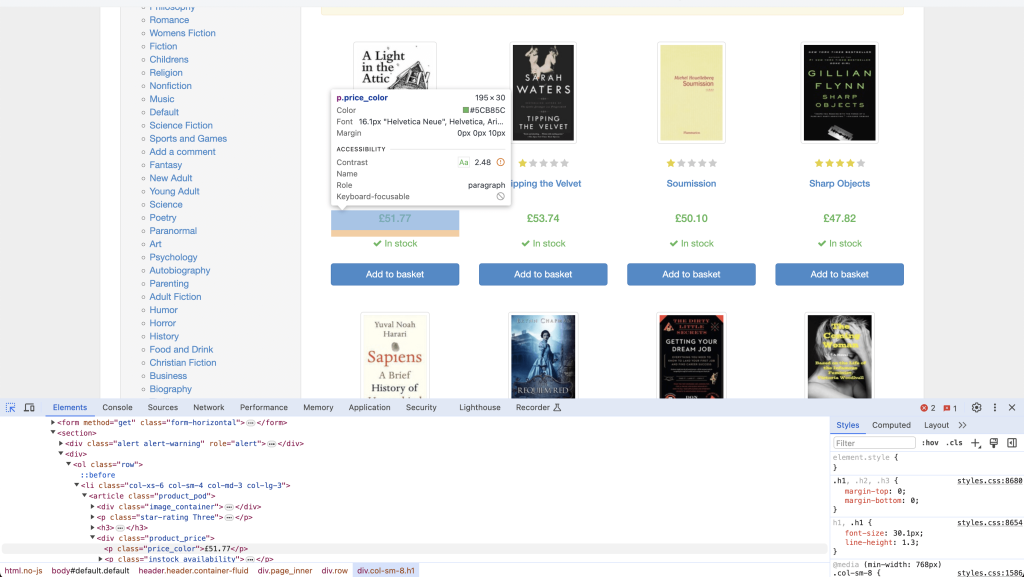
接下来,调用 Selenium 的 find_element() 方法查找具有已识别 ID 值的 HTML 元素。需要传递 By.ID 作为第一个参数,ID 作为第二个参数,因为这是 find_element() 方法接受的参数:
# collect data that are within the ID of contents
title_element = driver.find_element(By.ID, "productTitle")
# extract the title
title = title_element.text
# show the title of the product
print(title)此代码块收集 ID 属性为 productTitle 的数据,然后使用 text 属性提取产品标题。最后显示产品标题。
在终端中运行以下 Python 脚本文件以抓取产品标题:
python selenium_scraping.py提取的标题如下所示:
Amazon Basics Low-Profile Wired USB Keyboard with US Layout (QWERTY), Matte Black使用 CSS 选择器和标签名称抓取产品详细信息
现在你知道如何抓取标题,让我们使用 CSS 选择器和 HTML 标签从名为 About this item 的部分抓取其他详细信息:
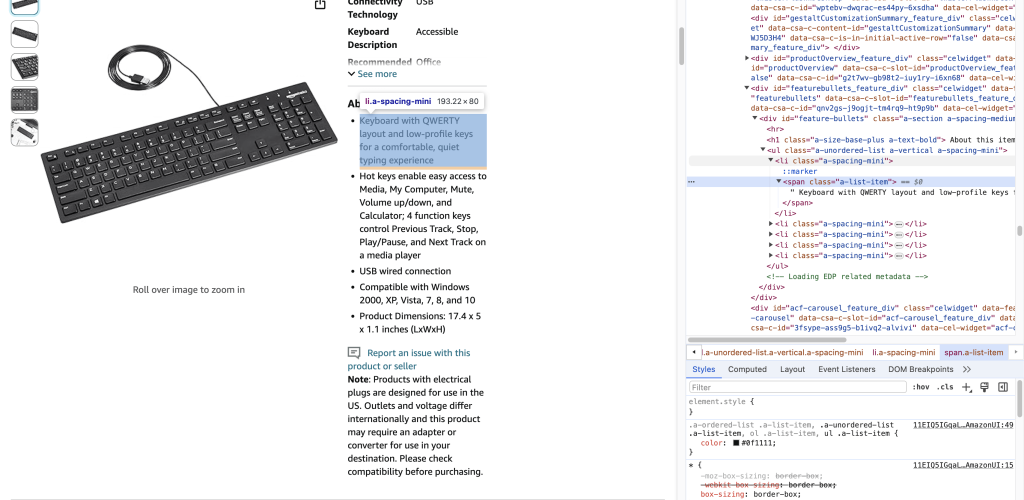
要提取产品详细信息,需要收集 Amazon 链接上具有名为 li.a-spacing-mini 的 CSS 选择器的所有 HTML 元素,然后从具有 <span> 标签名称的 HTML 元素中收集数据:
# Locate the outer span by using css selector
details_elements = driver.find_elements(By.CSS_SELECTOR, 'li.a-spacing-mini')
# Loop through all located details elements
for detail_element in details_elements:
try:
# Extract the detail from the inner span
detail = detail_element.find_element(By.TAG_NAME, 'span')
print(detail.text)
except Exception as e:
print("Could not extract detail:", e)此代码从 WebElement contents 对象中收集所有具有名为 li.a-spacing-mini 的 CSS 选择器的 HTML 元素,并将元素存储在 details_elements 列表中。然后循环遍历 detail_elements 中的所有元素,使用 find_element 方法查找标签名称为 span 的 HTML 元素,使用 text 属性提取 span HTML 元素中的文本数据。
以下是从 span HTML 元素中提取的数据:
Keyboard with QWERTY layout and low-profile keys for a comfortable, quiet typing experience
Hot keys enable easy access to Media, My Computer, Mute, Volume up/down, and Calculator; 4 function keys control Previous Track, Stop, Play/Pause, and Next Track on a media player
USB wired connection
Compatible with Windows 2000, XP, Vista, 7, 8, and 10
Product Dimensions: 17.4 x 5 x 1.1 inches (LxWxH)执行 JavaScript 代码
如果你想在动态网站的当前窗口中执行 JavaScript 代码,可以使用 execute_script() 函数。例如,你可以执行以下 JavaScript 代码来返回 https://quotes.toscrape.com/ 页面上提供的所有链接:
# import libraries
from selenium import webdriver
from pprint import pprint
# Setup Chrome WebDriver
driver = webdriver.Chrome()
# Define the URL
url = "https://quotes.toscrape.com/"
# load the web page
driver.get(url)
# set maximum time to load the web page in seconds
driver.implicitly_wait(10)
# Execute JavaScript to collect all links
javascript_code = "return Array.from(document.getElementsByTagName('a'), a => a.href);"
links = driver.execute_script(javascript_code)
print(links)
# Close the WebDriver
driver.quit()此代码导入所需库,初始化 Chrome WebDriver 实例,并导航到指定的 URL。然后执行 JavaScript 代码,使用 execute_script() 函数收集页面上的所有链接。最后,它将链接保存在 links 变量中,打印收集到的链接,并关闭 WebDriver 实例。
输出如下所示:
['https://quotes.toscrape.com/',
'https://quotes.toscrape.com/login',
'https://quotes.toscrape.com/author/Albert-Einstein',
'https://quotes.toscrape.com/tag/change/page/1/',
'https://quotes.toscrape.com/tag/deep-thoughts/page/1/',
'https://quotes.toscrape.com/tag/thinking/page/1/',
'https://quotes.toscrape.com/tag/world/page/1/',
'https://quotes.toscrape.com/author/J-K-Rowling',
.....
]注意:如果你打算异步执行 JavaScript 代码,请改用
execute_async_script()函数。
使用 Selenium 处理挑战和高级爬虫技术
从动态网站抓取数据通常会遇到各种挑战,包括处理分页、身份验证或 CAPTCHA。
分页需要浏览网站的多个页面以收集所有所需数据。然而,处理分页可能很困难,因为不同的网站使用不同的分页技术。你需要处理转到下一页的逻辑,并处理没有更多页面的情况。此外,有些网站有登录表单,需要身份验证才能访问受限内容,然后你才能执行任何网络爬虫任务。
如果你不熟悉 CAPTCHA,它们是一种挑战响应测试,旨在确定用户是人类还是机器人。这种安全措施通常用于防止自动化程序(机器人)访问网站或执行某些操作。然而,如果 CAPTCHA 未能自动处理,它们可能会阻止你从动态网站抓取所需的数据。
幸运的是,Selenium 提供了高级技术,可以帮助你克服这些挑战。
从多个页面提取数据
电子商务网站的各种产品详细信息,包括产品信息、价格、评论或库存情况,通常分页显示在多个产品列表页面上。
在以下示例中,你将从 books.toscrape.com 抓取书籍的标题和价格。该网站在五十个网页上列出了许多书籍:
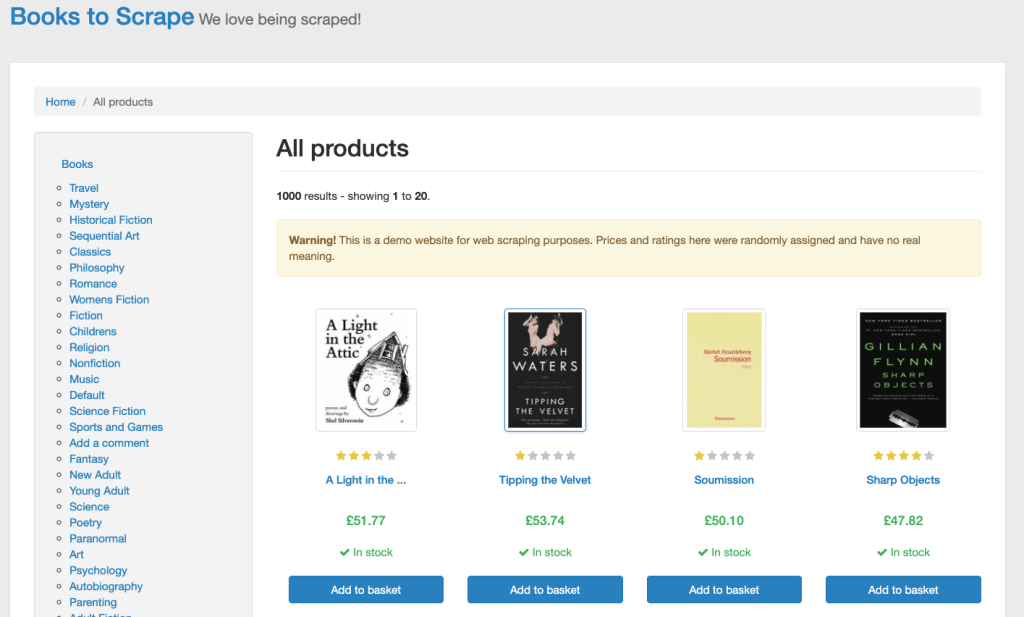
要从多个页面提取数据,需要在 Python 变量中定义网站 URL,并使用 driver 对象的 get() 方法加载网页:
# Define the URL
url = "https://books.toscrape.com/"
# load the web page
driver.get(url)要抓取数据,需要使用CSS 选择器查找包含每本书标题和价格的 HTML 标签。定位书籍标题的 CSS 选择器是 h3 > a,而查找书籍价格的 CSS 选择器是 price_color:
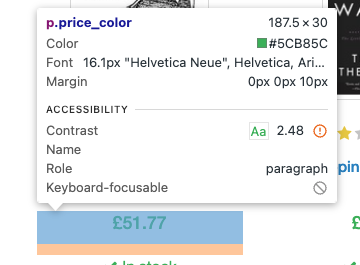
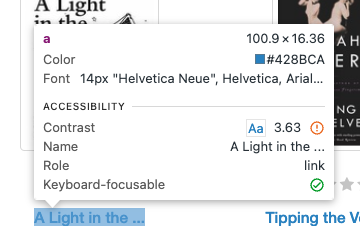
以下是抓取每本书标题和价格的代码:
# Initialize empty list to store scraped data
books_results = []
while True:
# Extract data
for selector in driver.find_elements(By.CSS_SELECTOR, "article.product_pod"):
try:
title_element = selector.find_element(By.CSS_SELECTOR, "h3 > a")
title = title_element.get_attribute("title")
price_element = selector.find_element(By.CSS_SELECTOR, ".price_color")
price = price_element.text
books_results.append({"title": title, "price": price})
except NoSuchElementException:
# Handle the case where either title or price element is not found
print("Title or price element not found.")
continue
# Check for next page link
try:
next_page_link_element = driver.find_element(By.CSS_SELECTOR, "li.next a")
next_page_link = next_page_link_element.get_attribute("href")
if next_page_link == "https://books.toscrape.com/catalogue/page-50.html":
print("Reached the last page. Scraping process terminated.")
break
else:
driver.get(next_page_link)
except NoSuchElementException:
# Handle the case where the next page link element is not found
print("Next page link element not found.")
break
# Close WebDriver
driver.quit()
print(books_results)此代码使用一个名为 books_results 的空列表存储抓取的数据。它进入一个循环,从当前网页上显示的每本书提取标题和价格。循环遍历 CSS 选择器 article.product_pod 中的元素以定位每本书条目。在每本书条目中,使用 CSS 选择器 "h3 > a" 查找标题,使用 ".price_color" 查找价格。如果未找到标题或价格元素,则处理异常并继续。
在抓取完页面上的所有书籍后,检查指向下一页的链接是否存在,使用 CSS 选择器 li.next a。如果找到,则导航到下一页并继续抓取。如果没有下一页或到达最后一页(第 50 页),则抓取过程终止。最后,使用 pprint 打印存储在 books_results 列表中的抓取数据,并关闭 WebDriver。
从五十个网页上提取的数据如下所示:
[{'title': 'A Light in the Attic', 'price': '£51.77'},
{'title': 'Tipping the Velvet', 'price': '£53.74'},
{'title': 'Soumission', 'price': '£50.10'},
{'title': 'Sharp Objects', 'price': '£47.82'},
{'title': 'Sapiens: A Brief History of Humankind', 'price': '£54.23'},
{'title': 'The Requiem Red', 'price': '£22.65'},
{'title': 'The Dirty Little Secrets of Getting Your Dream Job', 'price': '£33.34'},
{'title': 'The Coming Woman: A Novel Based on the Life of the Infamous Feminist, Victoria Woodhull', 'price': '£17.93'},
{'title': 'The Boys in the Boat: Nine Americans and Their Epic Quest for Gold at the 1936 Berlin Olympics', 'price': '£22.60'}
.....
]自动处理登录表单
许多网站,包括社交媒体平台,需要登录或用户身份验证才能访问某些数据。幸运的是,Selenium 可以自动化登录过程,使你能够访问和抓取身份验证墙后的数据。
在以下示例中,你将使用 Selenium 自动登录Quotes to Scrape 网站(一个沙盒网站),该网站列出各种名人名言。
要登录 Quotes to Scrape 网站,需要在 Python 变量中定义网站 URL,并使用 driver 对象的 get() 方法加载网页。等待十秒钟以确保页面完全加载,然后提取数据:
# Define the URL
url = "https://quotes.toscrape.com/login"
# load the web page
driver.get(url)
# set maximum time to load the web page in seconds
driver.implicitly_wait(10)接下来,使用 XPath 查找并输入用户名和密码到登录表单中。在网页的检查页面中,用户名的输入字段名为 username,密码的输入字段名为 password:
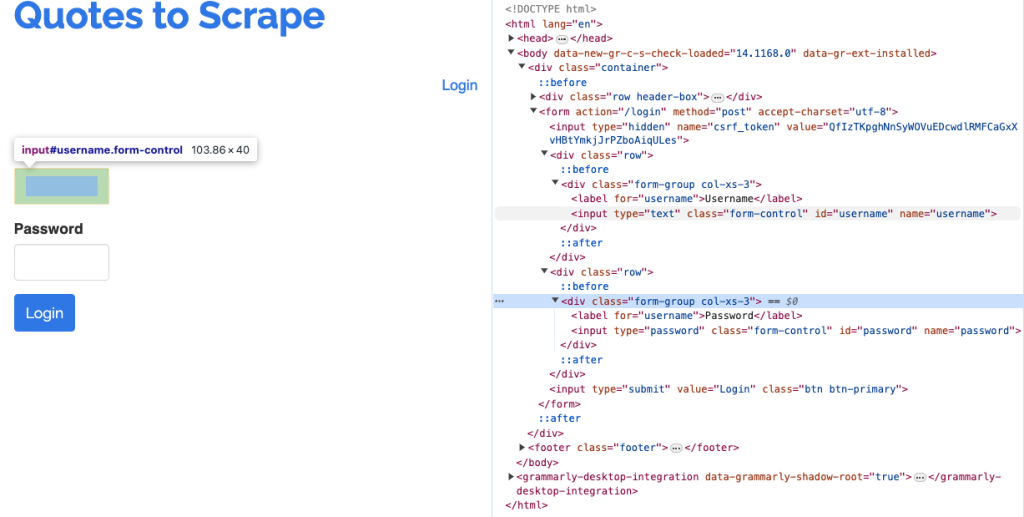
从此截图中可以看到用户名和密码的输入字段代码。以下是查找并填写用户名和密码,然后点击提交按钮提交表单的代码:
# Find the username field
username_field = driver.find_element(By.XPATH, "//input[@name='username']")
# Enter username
username_field.send_keys("[email protected]")
# Find the password field
password_field = driver.find_element(By.XPATH, "//input[@name='password']")
# Enter password
password_field.send_keys("secret1234")
# Submit the form
submit_button = driver.find_element(By.XPATH, "//input[@type='submit']")
submit_button.click()
# Wait for the logout link to appear
try:
logout_link = WebDriverWait(driver, 15).until(
EC.visibility_of_element_located((By.XPATH, "//a[contains(text(), 'Logout')]"))
)
print("Login successful! Logout link was found.")
except:
print("Login failed or logout link was not found.")
# Close the browser
driver.quit()此代码使用带有 name='username' 属性的 XPath 查找网页上的用户名输入字段://input[@name='username']。使用 send_keys() 方法将用户名 [email protected] 输入到定位的用户名字段中。然后使用带有 name='password' 属性的 XPath 查找网页上的密码输入字段://input[@name='password']。
使用 send_keys() 方法将密码 secret1234 输入到定位的密码字段中。然后查找并点击登录表单的提交按钮,使用带有 type='submit' 属性的 XPath://input[@type='submit']。
在成功登录后,等待最多十五秒钟以等待注销链接出现。然后使用 WebDriverWait 等待由包含“Logout”文本的 XPath 定位的元素的可见性://a[contains(text(), 'Logout')]。如果注销链接在指定时间内出现,则打印 "登录成功!找到了注销链接。"。如果注销链接未出现或登录失败,则打印 "登录失败或未找到注销链接。"。
在登录过程完成后关闭浏览器会话。
输出如下所示:
登录成功!找到了注销链接。处理 CAPTCHA
一些网站添加了 CAPTCHA,以在访问内容之前验证你是人类还是机器人。为了在抓取动态网站的数据时避免与 CAPTCHA 交互,可以实现Selenium 的无头模式。无头模式允许你在不显示浏览器的情况下运行浏览器实例。这意味着浏览器在后台运行,你可以使用 Python 脚本与其进行编程交互:
from selenium.webdriver.chrome.options import Options
# Set Chrome options for headless mode
chrome_options = Options()
chrome_options.add_argument("--headless")
# Setup Chrome WebDriver
driver = webdriver.Chrome(options=chrome_options)此代码从 selenium.webdriver.chrome.options 导入 Options。然后配置 Chrome 选项以无头模式运行,并初始化带有这些选项的 Chrome WebDriver 实例 driver。它使你能够在不显示浏览器界面的情况下执行网络爬虫任务。
使用 Cookie
Cookie 是从你访问的网站传输并存储在你计算机上的一段数据。它包含名称、值、过期时间和路径,用于识别用户身份并加载存储的信息,包括你的登录和搜索历史。
Cookie 可以通过维护会话状态增强你的爬虫能力,这对于导航经过身份验证或个性化的部分网站至关重要。应用 Cookie 可以避免重复登录并继续抓取,从而自动减少执行时间。
网站也经常将 Cookie 作为其反爬虫机制的一部分。当你保留并使用合法浏览会话中的 Cookie 时,可以使你的请求看起来更像是普通用户的请求,并减少被屏蔽的风险。
你可以使用 WebDriver API 提供的内置方法与 Cookie 进行交互。
要将 Cookie 添加到当前浏览上下文中,请使用 add_cookie() 方法,并以字典格式提供名称和值:
# Import package
from selenium import webdriver
# Initialize the WebDriver
driver = webdriver.Chrome()
# Navigate to the base URL
driver.get("http://www.example.com")
# Adds the cookie into the WebDriver Session
driver.add_cookie({'name': 'session_id', 'value': 'abc123', 'domain': 'example.com', 'path': '/', 'expiry': None})
# Refresh the page to apply the cookies
driver.refresh()
# Wait for a few seconds to ensure cookies are applied and the page is loaded
time.sleep(5)
# Now you can proceed with any scraping task that require the cookies to be set在这里,你使用 add_cookie() 方法将 Cookie 添加到你的网络爬虫任务中。然后使用 refresh() 方法刷新页面以应用 Cookie,并等待五秒钟以确保应用 Cookie,然后再继续任何需要设置 Cookie 的爬虫任务。
可以使用 get_cookies() 方法返回所有可用的 Cookie。如果你想返回特定 Cookie 的详细信息,需要传递 Cookie 的名称,如下所示:
# import package
from selenium import webdriver
# Initialize the WebDriver
driver = webdriver.Chrome()
# Navigate to url
driver.get("http://www.example.com")
# Adds the cookie into current browser context
driver.add_cookie({"name": "foo", "value": "bar"})
# Get cookie details with named cookie 'foo'
print(driver.get_cookie("foo"))此代码块返回名为 foo 的 Cookie 的详细信息。
注意:如果你想了解更多处理 Cookie 的方法,请访问 Selenium 文档页面这里。
网络爬虫的最佳实践和道德考虑
在进行网络爬虫时,遵循旨在确保从网站负责任地提取数据的最佳实践非常重要。这包括遵守 robots.txt 文件,该文件概述了爬行和抓取网站的规则。
确保避免过多的请求而使服务器过载,这会破坏网站的功能并对用户体验产生负面影响。这种过载可能导致拒绝服务(DoS)攻击。
网络爬虫还会引发法律和道德问题。例如,未经许可抓取受版权保护的材料可能导致法律后果。至关重要的是,在进行网络爬虫之前,仔细评估法律和道德影响。你可以通过阅读网站提供的数据隐私政策、知识产权和条款与条件来做到这一点。
结论
从动态网站抓取数据的过程需要努力和计划。使用 Selenium,可以自动与任何动态网站进行交互并收集数据。
在本文中,你学习了如何使用 Selenium Python 包从 YouTube 和其他沙盒网站上显示的各种 HTML 元素中抓取数据。你还学习了如何使用高级技术处理分页、登录表单和 CAPTCHA 等不同的挑战。所有教程的源代码都可以在这个GitHub 仓库中找到。
虽然可以使用 Selenium 抓取数据,但这很耗时,并且很快变得复杂。因此,建议使用 Bright Data。其爬虫浏览器支持 Selenium 和各种类型的代理,你可以立即开始提取数据。考虑开始免费试用并利用 Bright Data 提供的爬虫 API,而不是维护你的服务器和代码。







