

随着互联网数据量的不断增长,网页抓取(自动导航和从网站提取信息的过程)成为开发者必须掌握的一项重要技能。这个过程是通过向网络服务器发送 HTTP 请求并解析 HTML 响应来提取所需数据来完成的。
网页抓取过程可能复杂且耗时,但正确的工具和技术可以提供帮助。凭借其灵活性和易用性,Python已成为构建网页抓取工具的流行语言,允许开发人员快速编写脚本以自动执行数据提取过程。
本文将教您如何使用 Scrapy 库进行 Python 网页抓取。
为什么需要网页抓取
在我们开始教程之前,有必要了解网页抓取和网页爬取之间的区别。虽然两者相似,但网页抓取是从网页中提取特定数据,而网页爬取是浏览网页以进行索引并为搜索引擎收集信息。
网页抓取在各种场景中都很有用,包括以下情况:
- 数据提取:网页抓取可用于从网站提取特定数据,然后用于分析或研究。
- 网站索引:搜索引擎经常使用网页抓取来索引网站,使用户可以搜索到它们。
- 监控:网页抓取可用于监控网站的变化或更新。此信息通常用于跟踪竞争对手。
- 内容聚合:网页抓取可用于从多个网站收集内容并将其聚合到一个位置,便于访问。
- 安全测试:网页抓取可用于安全测试,以识别网站和网络应用程序中的漏洞或弱点。
使用 Python 进行网页抓取
由于其编码易用性和直观的语法,Python 是进行网页抓取的流行选择。此外,Scrapy 是最流行的网页抓取框架之一,它基于 Python 构建。这个强大而灵活的框架使得从网站提取数据、跟随链接以及存储结果变得容易。
Scrapy 旨在处理大量数据,并可用于各种网页抓取任务。Scrapy 中包含的工具,如 HTTP 下载器、用于抓取网站的蜘蛛、用于管理抓取频率的调度器和用于处理抓取数据的项目管道,使其非常适合各种网页抓取任务。
要开始使用 Python 进行网页抓取,您需要在系统上安装 Scrapy 框架。
打开终端并运行以下命令:
pip install scrapy运行此命令后,您的系统中将安装 scrapy。Scrapy 为您提供了一些称为蜘蛛的类,这些类定义了如何执行网页抓取任务。这些蜘蛛负责导航网站、发送请求和从网站的 HTML 中提取数据。
创建一个 Scrapy 项目
本文中,您将抓取一个名为 Books to Scrape 的网站,并将每本书的名称、类别和价格保存到一个 CSV 文件中。该网站是为抓取项目作为沙盒环境创建的。
安装 Scrapy 后,您需要使用以下命令创建一个新的项目结构:
scrapy startproject bookcrawler(注意:如果出现“command not found”错误,请重新启动终端)
默认目录结构提供了一个清晰且有组织的框架,其中包含网页抓取过程的每个组件的单独文件和目录。这使得编写、测试和维护蜘蛛代码以及以您喜欢的方式处理和存储提取的数据变得容易。目录结构如下所示:
bookcrawler
│ scrapy.cfg
│
└───bookcrawler
│ items.py
│ middlewares.py
│ pipelines.py
│ settings.py
│ __init__.py
│
└───spiders
__init__.py要在 Scrapy 项目中启动抓取过程,必须在 bookcrawler/spiders 目录中创建一个新的蜘蛛文件,因为这是 Scrapy 查找任何要执行代码的蜘蛛的标准目录。为此,请导航到 bookcrawler/spiders 目录并创建一个名为 bookspider.py 的新文件。然后在文件中编写以下代码以定义您的蜘蛛并指定其行为:
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class BookCrawler(CrawlSpider):
name = 'bookspider'
start_urls = [
'https://books.toscrape.com/',
]
rules = (
Rule(LinkExtractor(allow='/catalogue/category/books/')),
)这段代码定义了一个 BookCrawler,它是从内置的 CrawlSpider 子类化的,并提供了一种方便的方法来定义跟随链接和提取数据的规则。start_urls 属性指定了要开始抓取的一组 URL。在这种情况下,它只包含一个 URL,即网站的主页。
rules 属性指定了一组规则来确定蜘蛛应该跟随哪些链接。在这种情况下,只定义了一个规则,它是使用 scrapy.spiders 模块中的 Rule 类创建的。该规则使用 LinkExtractor 实例定义,后者指定蜘蛛应跟随的链接模式。LinkExtractor 的 allow 参数设置为 /catalogue/category/books/,这意味着蜘蛛应该只跟随 URL 中包含此字符串的链接。
要运行蜘蛛,请打开终端并运行以下命令:
scrapy crawl bookspider一旦运行此命令,Scrapy 将初始化蜘蛛类 BookCrawler,为 start_urls 属性中的每个 URL 创建一个请求,并将它们发送到 Scrapy 调度器。当调度器接收到请求时,它会检查请求是否被蜘蛛的 allowed_domains(如果指定)属性允许。如果允许该域名,则请求将传递给下载器,下载器会向服务器发出 HTTP 请求并检索响应。
此时,您应该能够在控制台窗口中看到蜘蛛抓取的每个 URL:
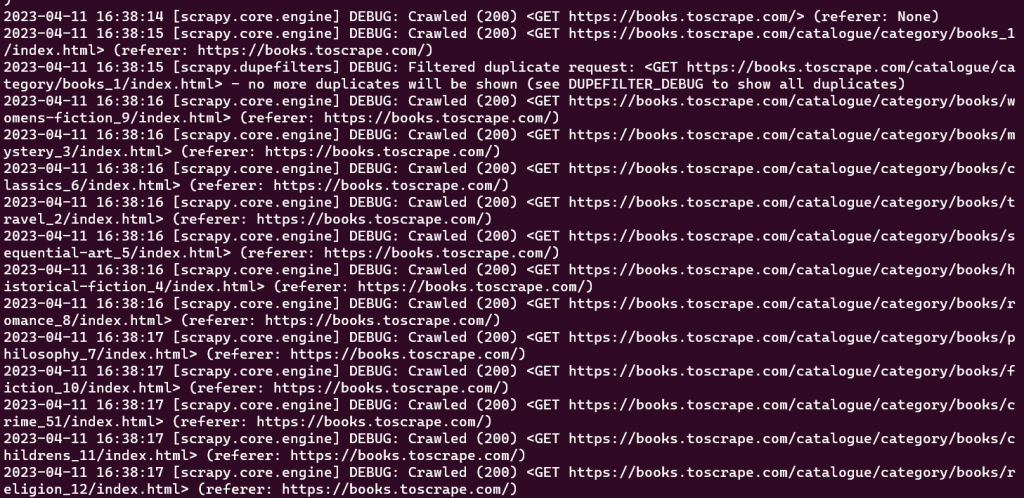
创建的初始爬虫仅执行抓取预定义 URL 集的任务,而不提取任何信息。要在抓取过程中检索数据,您需要在爬虫类中定义 parse_item 函数。parse_item 函数负责接收爬虫发出的每个请求的响应并返回从响应中获取的相关数据。
请注意:
parse_item函数仅在设置LinkExtractor中的callback属性后才能工作。
要从 Scrapy 中抓取的网页响应中提取数据,您需要使用 CSS 选择器。下一节简要介绍了 CSS 选择器。
关于 CSS 选择器的一点说明
CSS 选择器是一种通过指定标签、类和属性从网页中提取数据的方法。例如,以下是使用 scrapy shell books.toscrape.com 初始化的 Scrapy shell 会话:
# check if the response was successful
>>> response
<200 http://books.toscrape.com>
#extract the title tag
>>> response.css('title')
[<Selector xpath='descendant-or-self::title' data='<title>\n All products | Books to S...'>]在此会话中,css 函数接收一个标签(如 title)并返回 Selector 对象。要获取 title 标签内的文本,您需要编写以下查询:
>>> print(response.css('title::text').get())
All products | Books to Scrape - Sandbox在此代码段中,text 伪选择器用于去除包围的 title 标签并仅返回内部文本。get 方法用于显示数据值。
要获取元素的类,您需要通过右键单击并选择检查来查看页面的源代码:
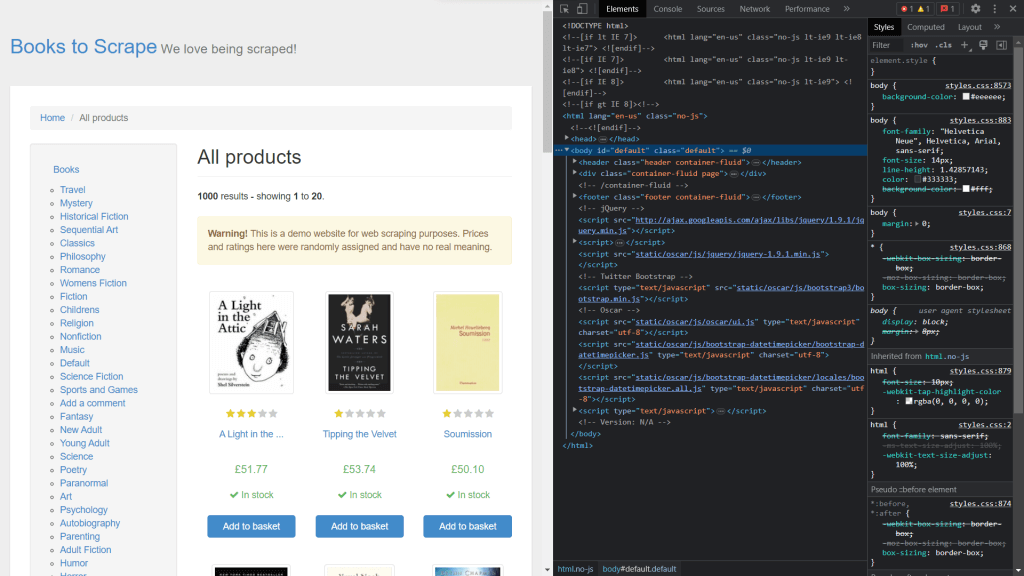
使用 Scrapy 提取数据
要从响应对象中提取元素,您需要定义一个回调函数并将其作为 Rule 类中的属性。
打开 bookspider.py 并运行以下代码:
from scrapy.spiders import CrawlSpider, Rule
from scrapy.linkextractors import LinkExtractor
class BookCrawler(CrawlSpider):
name = 'bookspider'
start_urls = [
'https://books.toscrape.com/',
]
rules = (
Rule(LinkExtractor(allow='/catalogue/category/books/'), callback="parse_item"),
)
def parse_item(self, response):
category = response.css('h1::text').get()
book_titles = response.css('article.product_pod').css('h3').css('a::text').getall()
book_prices = response.css('article.product_pod').css('p.price_color::text').getall()
yield {
"category": category,
"books":list(zip(book_titles,book_prices))
}BookCrawler 类中的 parse_item 函数包含用于提取数据并将其输出到控制台的逻辑。使用 yield 允许 Scrapy 以项目的形式处理数据,然后可以将其传递通过项目管道进行进一步处理或存储。
选择 category 的过程非常简单,因为它编码在一个简单的 <h1> 标签中。然而,选择 book_titles 的过程是通过多级选择过程实现的,第一步是选择带有类 product_pod 的 <article> 标签。之后,继续遍历过程以识别嵌套在 <h3> 标签中的 <a> 标签。同样的方法也用于选择 book_prices,从而从网页中获取所需的信息。
至此,您已经创建了一个抓取网站并检索数据的蜘蛛。要运行蜘蛛,请打开终端并运行以下命令:
scrapy crawl bookspider -o books.json执行后,爬虫抓取的网页及其对应的数据将显示在控制台上。使用 -o 标志指示 Scrapy 将所有检索到的数据存储在名为 books.json 的文件中。脚本完成后,将在项目目录中创建一个名为 books.json 的新文件。该文件包含爬虫检索到的所有与书籍相关的数据:
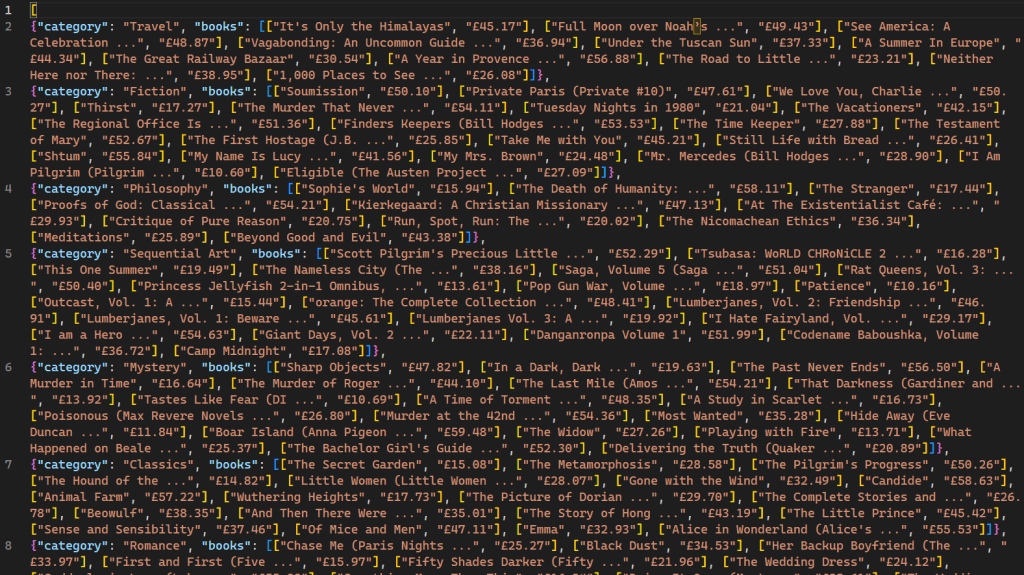
重要的是要注意,这个爬虫仅对不响应多个请求的 IP 阻止机制的网站有效。对于那些对网页机器人和爬虫不太友好的网站,需要使用像 Bright Data 这样的代理服务来大规模提取数据。Bright Data 的服务使用户能够从多个来源收集网页数据,同时避免 IP 阻止和检测。
结论
网页抓取与网页抓取相结合,是数据收集和数据科学中的一项非常有价值的技能。Scrapy 是一个为网页抓取设计的框架,通过提供内置的爬虫和抓取器简化了过程。
本文引导您构建一个网页抓取工具,然后使用 Scrapy 框架抓取数据。您学习了如何使用 CrawlSpider 进行轻松的网页抓取,并了解了 Rule 和 LinkExtractor 等概念,以抓取特定 URL 模式。此外,您还了解了使用 CSS 选择器选择 HTML 元素的概念。掌握这些技能后,您将能够应对数据科学及其他领域的网页抓取和网页抓取挑战。




