

Web scraping 是一种技术,通过使用专门的工具或程序自动从网站提取和收集数据。对于希望改进数据驱动决策过程的公司来说,这项技术特别有价值。
然而,由于大多数网站的复杂HTML结构、动态内容和多样化的数据格式,web scraping 的效果取决于您使用的工具。
Scrapy 和 Selenium 是两款用于促进 web scraping 的强大工具。Scrapy 用于从静态网站提取数据,而 Selenium 可以执行浏览器自动化并从动态网站提取数据。
在本文中,您将根据易用性、性能和可扩展性、对不同类型 web 内容的适用性以及集成能力来比较这两个工具。
易用性
Scrapy 是一个基于 Python 的 web scraping 工具,可以在 Linux、Windows、macOS 和 Berkeley Software Distribution (BSD) 上运行。Scrapy 不仅易于使用,还提供了一个 高级API 用于 web scraping 任务,这有助于进一步简化 web scraping 过程。
要设置 Scrapy,您只需安装它并使用 Python 代码配置一些爬虫(这需要一些 web scraping 概念的理解)。当您执行 Scrapy 命令来启动一个项目时,它会生成一个专用于您的项目的文件夹。在这个文件夹中,您会找到默认的 Python 文件,如 items.py、pipelines.py 和 settings.py。这些文件以简化的结构组织起来,使得开始 web scraping 变得容易。
Scrapy 提供了详细的 文档,包括精心编写的文章和视频,帮助解答您可能遇到的任何问题。Scrapy 还拥有一个活跃的 subreddit 和 Discord 社区,您可以在其中参与不同的讨论或话题。
相比之下,Selenium 支持多种编程语言,包括 Java、JavaScript、Python 和 C#,并且与 Scrapy 相同的许多操作系统兼容,包括 Windows、macOS 和 Linux。与 Scrapy 相比,Selenium 不那么容易学习,需要更多的时间、精力,有时还需要更多的资源才能熟练掌握。
要设置 Selenium,您需要安装 Selenium 库,然后配置处理浏览器自动化的 WebDrivers。如果您正在 从动态网站抓取数据,并且需要登录,您需要设置 web 自动化来处理登录过程,然后才能开始抓取任何数据。
Selenium 提供了一套丰富的导航方法,您可以自定义这些方法来轻松定位网页上的元素。此外,它还提供了交互动作链,包括点击、双击、拖拽、放下和滚动,使得与网页的交互变得毫不费力。
Selenium 的官方文档包括令人印象深刻的指南、分步说明和与 web 自动化和 web scraping 相关的教程。
由于 Selenium 是一种更通用的 web 自动化工具,它拥有一个更大且更多样化的社区。如果您在使用 Selenium 时有任何问题,它的官方用户组和 subreddit 社区 可以提供帮助。或者,如果您有一个需要立即解决的问题,可以利用他们的 IRC 聊天室。
性能和可扩展性
任何 web scraping 工具的性能有效性很大程度上依赖于其速度,因为目标是快速收集大量数据。
Scrapy 在从静态网页抓取内容方面表现出色,导致数据提取速度比 Selenium 更快。这是因为 Selenium 依赖于浏览器实例来执行不同的交互,如点击按钮或填写表单。
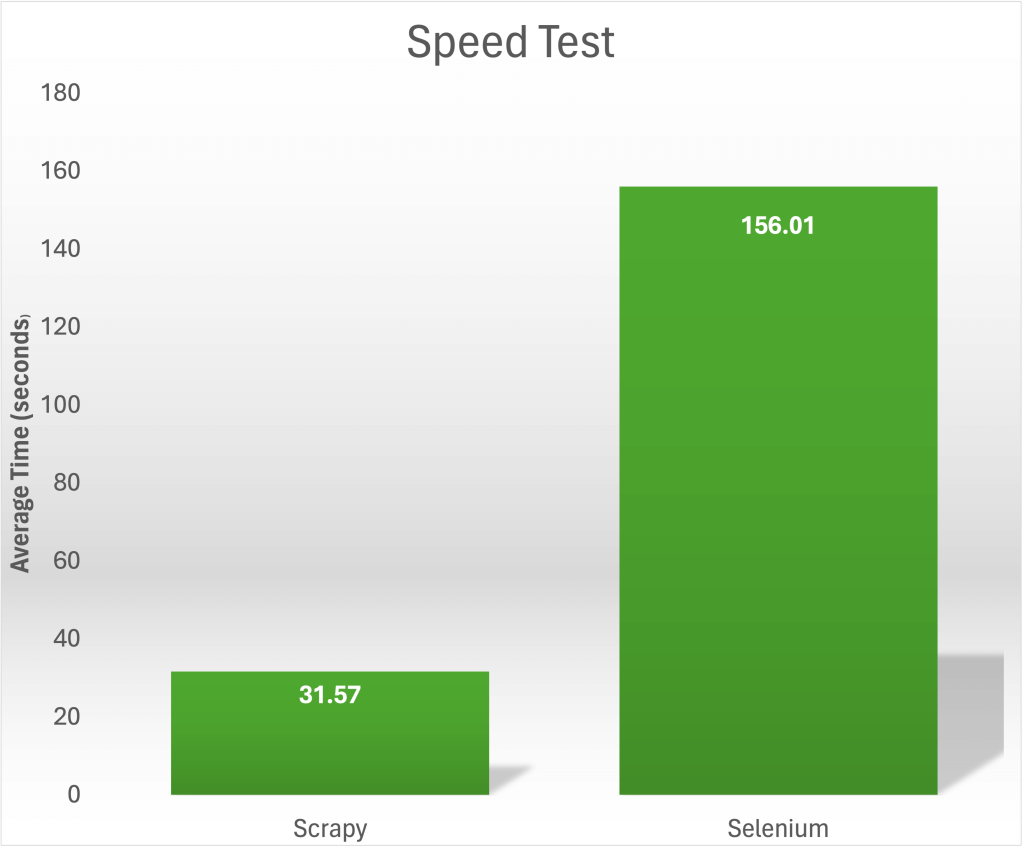
在一个 速度测试 中,从 https://books.toscrape.com/ 收集 1,000 本书的标题和价格,Scrapy 能在 31.57 秒内完成任务。相比之下,Selenium 平均需要 156.01 秒来抓取相同的内容:
Scrapy 架构通过在连续过程中处理响应和项目来高效处理内存,避免一次性将整个网页加载到内存中。Scrapy 还内置了缓存和增量抓取的支持,通过最小化冗余请求和仅处理新的或更新的内容来提高可扩展性。
此外,Scrapy 提供了通过设置如 并发请求、深度限制和项目管道来微调内存使用的选项。这些功能使您能够根据您的 web scraping 项目的具体要求优化内存消耗。
当与 JavaScript 密集的网站交互时,Selenium 通常会消耗大量内存,导致更高的内存消耗。这会对其可扩展性和性能产生负面影响,特别是在大规模抓取项目中。
Scrapy 的内置中间件 HTTPCacheMiddleware 缓存爬虫请求和相关响应。您可以通过在项目的 settings.py 文件中添加以下代码来启用缓存:
# Enable and configure HTTP caching (disabled by default)
HTTPCACHE_ENABLED = True要扩展 Selenium 以处理大规模数据抓取,需要在分布式系统上部署多个实例,导致对资源(如 RAM 和 CPU)的需求增加。
对不同类型 Web 内容的适用性
互联网上的大多数网站都包含动态或静态网页。让我们看看 Scrapy 和 Selenium 如何处理这两种类型的网页。
动态网页
大多数动态网页由 JavaScript 框架(如 Angular 和 React)驱动,以更新内容而不重新加载整个页面。
Selenium 可以从各种网站抓取动态内容,但 Scrapy 本身不支持抓取由 JavaScript 生成的动态内容。您可以将 Scrapy 与 Selenium 和 Splash 等工具集成,以获得此功能。
静态网页
静态网页通常与动态网页相比交互性有限,通常只允许用户查看内容或点击链接。
如前所述,Selenium 可以抓取静态页面,但它不是完成这项工作的最有效工具。相比之下,Scrapy 在抓取静态数据方面表现出色,为收 集所需信息提供了流畅高效的体验。
集成能力
Scrapy 可以轻松集成大多数 Python 工具,包括 MySQL、PostgreSQL 和 MongoDB 等数据库,以存储抓取的数据。您甚至可以使用对象关系映射器(ORM),如 SQLAlchemy,简化在关系数据库中存储数据的过程。如果您希望进一步处理和分析数据,可以使用 pandas,这是一个流行的 Python 数据操作和分析库。
Scrapy 还可以与 Django 和 Flask 等 web 框架集成,以构建包含 web scraping 功能的 web 应用程序。此外,与 FastAPI 集成,可以构建具有异步支持的高性能 web API,适合高效处理抓取请求。
相比之下,Selenium 提供了浏览器驱动程序,充当 Selenium WebDriver API 和浏览器之间的中介。您可以下载并安装一个 WebDriver,以与您选择的浏览器集成。Selenium 目前提供 Chrome、Edge、Firefox 和 Safari 的浏览器驱动程序。
Selenium 还可以用于自动测试 web 应用程序的功能;不过,请注意,它没有内置的测试框架。您可以将 Selenium 与其他流行的测试框架集成,包括 CodeceptJS、Helium 和 Selenide。
Selenium 曾经与 CI 工具(如 Jenkins 和 Travis CI)集成,以便在持续集成和持续交付(CI/CD)流水线中自动执行自动化脚本;但现在,它们通过 GitHub Actions 执行所有操作,支持持续测试和部署流程。
Scrapy 可以与不同的代理服务提供商(如 Bright Data) 集成,方法是将代理 IP 和端口作为请求参数传递。如果您希望为项目使用特定代理,推荐使用这种方法。
例如,如果您想与代理服务器集成,可以使用 pip 命令 pip3 install scrapy 来安装 Scrapy,如下所示:
#import scrapy module
import scrapy
class BookSpider(scrapy.Spider):
name = "books"
def start_requests(self):
start_urls = ["https://example.com/products"]
for url in start_urls:
yield scrapy.Request(
url=url,
callback=self.parse,
# connect with proxy
meta={"proxy": "http://USERNAME:[email protected]:22225"},
)
def parse(self, response):
for book in response.css(".book-card"):
yield {
"title": book.css(".title ::text").get(),
"price": book.css(".price-wrapper ::text").get(),
}这里,您导入 Scrapy 并定义一个名为 BookSpider 的类,该类继承自 Scrapy 的蜘蛛类,从网站上抓取书籍列表。 start_requests() 方法使用指定的 URL 和代理启动请求,parse() 方法使用 CSS 选择器提取书名和价格。
相比之下,Selenium 通过各种浏览器驱动程序(如 ChromeDriver 和 geckodriver)支持直接的代理集成。您只需配置 Selenium WebDriver,通过代理服务器路由其 HTTP 请求。
例如,您可以通过指定 Bright Data 提供的代理 IP 和端口 与 Selenium 集成,如下所示:
#import selenium modules
from selenium import webdriver
from selenium.webdriver.common.proxy import Proxy, ProxyType
# Proxy configuration
proxy_address = "http://USERNAME:[email protected]"
proxy_port = "22225"
# Selenium options : integrate with proxy credentials from Bright data
options = webdriver.ChromeOptions()
options.add_argument('--proxy-server=%s:%s' % (proxy_address, proxy_port))
# Selenium webdriver instantiation
driver = webdriver.Chrome(options=options)
# Example usage: scraping a webpage
url = "https://example.com"
driver.get(url)
print(driver.page_source)
# Close the driver
driver.quit()这里,您导入所需的 Selenium 模块并设置代理配置。然后配置 Chrome 使用 定义的代理服务器,实例化一个 WebDriver,抓取一个网页("https://example.com"),打印页面源代码,关闭 WebDriver 以完成流程。
结论
在本文中,您比较了两种流行的 web scraping 工具:Scrapy 和 Selenium。
Scrapy 是一种易于使用的基于 Python 的 scraping 工具,适用于静态网站的数据提取。相比之下,Selenium 提供多种编程语言的自动化和 scraping 功能,支持各种 web 浏览器,是抓取动态和 JavaScript 渲染内容的更佳选择。
无论您决定使用哪种工具,都建议您使用像 Bright Data 这样的数据平台。它可以帮助您为 web scraping 脚本添加功能,以避免地理限制、阻止和 解决 CAPTCHA。您还可以利用 Bright Data 的 API 和 SDK 以应对更广泛的抓取需求,确保您的 web scraping 项目的效率、速度、准确性和可扩展性。想要进一步提高数据收集能力? 购买自定义数据集(提供免费样本)。



