网页抓取 是一种通过编程方式从网站收集数据的方法,网页抓取有无限的用例,包括市场研究、价格监控、数据分析和潜在客户生成。
在本教程中,您将看到一个实际的用例,专注于一个常见的育儿难题:收集和整理学校发回的通知信息。在这里,您将重点关注家庭作业和学校午餐信息。
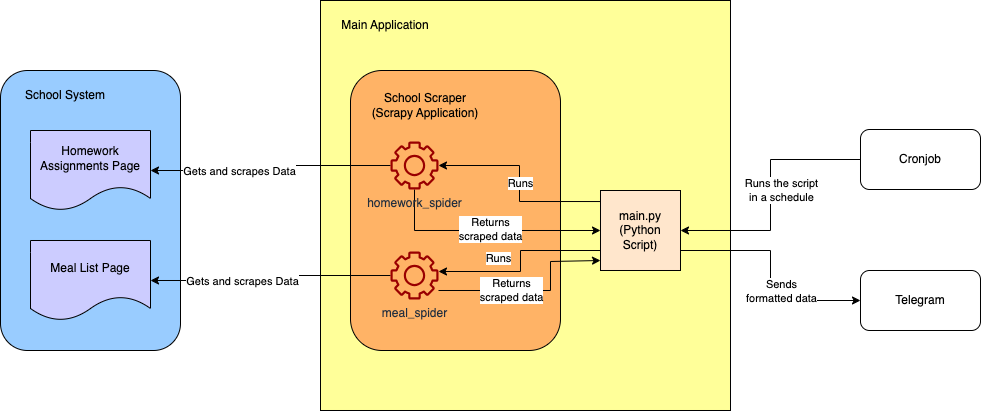
以下是最终项目的大致架构图:
前提条件
要跟随本教程,您需要以下内容:
- Python 3.10+。
- 已激活的虚拟环境。
- Scrapy CLI 2.11.1或更新版本。Scrapy是一个简单且可扩展的基于Python的网页抓取框架。
- 您选择的IDE(例如Visual Studio Code或PyCharm)。
为了隐私,您将使用这个虚拟的学校系统网站:https://systemcraftsman.github.io/scrapy-demo/website/。
创建项目
在终端中,创建您的基本项目目录(可以放在任何地方):
mkdir school-scraper导航到新创建的文件夹中,并通过运行以下命令创建一个新的Scrapy项目:
cd school-scraper &
scrapy startproject school_scraper项目结构应如下所示:
school-scraper
└── school_scraper
├── school_scraper
│ ├── __init__.py
│ ├── items.py
│ ├── middlewares.py
│ ├── pipelines.py
│ ├── settings.py
│ └── spiders
│ └── __init__.py
└── scrapy.cfg上一个命令创建了两层school_scraper目录。在内部目录中,有一组自动生成的文件:middlewares.py,您可以在其中定义Scrapy中间件;pipelines.py,您可以在其中定义自定义管道来修改您的数据;以及settings.py,您可以在其中定义抓取应用程序的一般设置。
最重要的是,有一个spiders文件夹,您的蜘蛛程序位于其中。蜘蛛程序是可以用于以特定方式抓取特定站点的Python类。它们遵循抓取系统内的关注点分离原则,允许为每个抓取任务创建专用的蜘蛛程序。
由于您还没有生成的蜘蛛程序,这个文件夹是空的,但在下一步中,您将生成第一个蜘蛛程序。
创建家庭作业蜘蛛程序
要从学校系统抓取家庭作业数据,您需要创建一个蜘蛛程序,首先登录系统,然后导航到家庭作业页面抓取数据:
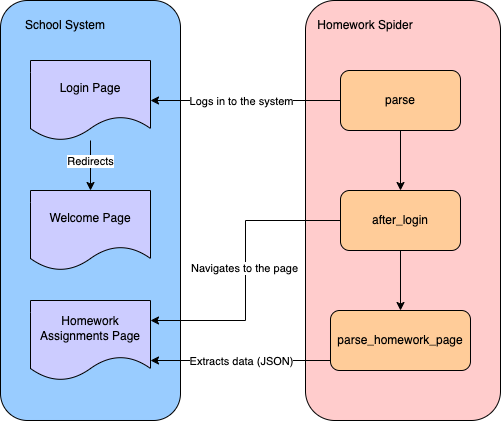
您将使用Scrapy CLI来创建一个用于网页抓取的蜘蛛程序。导航到项目的school-scraper/school_scraper目录,并运行以下命令在spiders文件夹中创建一个名为HomeworkSpider的蜘蛛程序:
scrapy genspider homework_spider systemcraftsman.github.io/scrapy-demo/website/index.html注意: 不要忘记在已激活的虚拟环境中运行所有与Python或Scrapy相关的命令。
scrapy genspider命令生成了蜘蛛。下一个参数是蜘蛛的名称(例如homework_spider),最后一个参数定义了蜘蛛的起始URL。通过这种方式,systemcraftsman.github.io被Scrapy识别为允许的域。
您的输出应如下所示:
Created spider 'homework_spider' using template 'basic' in module:
school_scraper.spiders.homework_spider一个名为homework_spider.py的文件必须在school_scraper/spiders目录下创建,并应如下所示:
class HomeworkSpiderSpider(scrapy.Spider):
name = "homework_spider"
allowed_domains = ["systemcraftsman.github.io"]
start_urls = ["https://systemcraftsman.github.io/scrapy-demo/website/index.html"]
def parse(self, response):
pass将类名重命名为HomeworkSpider,以去除类名中的冗余Spider。parse函数是开始抓取的初始函数。在这种情况下,这意味着登录系统。
注意:
https://systemcraftsman.github.io/scrapy-demo/index.html上的登录表单是一个虚拟登录表单,由几行JavaScript组成。由于页面是HTML,它不接受任何POST请求,而是使用HTTP GET请求模拟登录。
按如下方式更新parse函数:
...code omitted...
def parse(self, response):
formdata = {'username': 'student',
'password': '12345'}
return FormRequest(url=self.welcome_page_url, method="GET", formdata=formdata,
callback=self.after_login)在这里,您创建了一个表单请求,以在index.html页面中提交登录表单。提交的表单应重定向到定义的welcome_page_url,并应有一个回调函数以继续抓取过程。您将在后面添加after_login回调函数。
通过在类的顶部添加定义welcome_page_url:
...code omitted...
start_urls = ["https://systemcraftsman.github.io/scrapy-demo/website/index.html"]
welcome_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/welcome.html"
...code omitted...然后在类中parse函数之后添加after_login函数:
...code omitted...
def after_login(self, response):
if response.status == 200:
return Request(url=self.homework_page_url,
callback=self.parse_homework_page
)
...code omitted...after_login函数检查响应状态是否为200,这意味着成功。然后,它导航到家庭作业页面并调用parse_homework_page回调函数,您将在下一步中定义该函数。
通过在类的顶部添加定义homework_page_url:
...code omitted...
start_urls = ["https://systemcraftsman.github.io/scrapy-demo/website/index.html"]
welcome_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/welcome.html"
homework_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/homeworks.html"
...code omitted...在类中after_login函数之后添加parse_homework_page函数:
...code omitted...
def parse_homework_page(self, response):
if response.status == 200:
data = {}
rows = response.xpath('//*[@class="table table-file"]//tbody//tr')
for row in rows:
if self._get_item(row, 4) == self.date_str:
if self._get_item(row, 2) not in data:
data[self._get_item(row, 2)] = self._get_item(row, 3)
else:
data[self._get_item(row, 2) + "-2"] = self._get_item(row, 3)
return data
...code omitted...parse_homework_page函数检查响应状态是否为200(即成功);然后解析提供在HTML表格中的家庭作业数据。
该函数检查HTTP 200代码,然后使用XPath提取每一行数据。在提取每一行数据后,函数迭代数据并使用需要添加到您的Spider类中的私有函数_get_item提取特定项目。
_get_item函数应如下所示:
...code omitted...
def _get_item(self, row, col_number):
item_str = ""
contents = row.xpath(f'td[{col_number}]//text()').extract()
for content in contents:
item_str = item_str + content
return item_str_get_item函数使用XPath和行、列号获取每个单元格中的内容。如果一个单元格中有多个段落,函数会遍历它们并附加每个段落。
parse_homework_page函数还需要定义date_str,您应该将其定义为12.03.2024,因为这是您在静态网站中的日期数据。
注意: 在实际情况下,您应该动态定义日期,因为网站数据是动态的。
通过在类的顶部添加定义date_str:
...code omitted...
homework_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/homeworks.html"
date_str = "12.03.2024"
...code omitted...最终的homework_spider.py文件应如下所示:
import scrapy
from scrapy import FormRequest, Request
class HomeworkSpider(scrapy.Spider):
name = "homework_spider"
allowed_domains = ["systemcraftsman.github.io"]
start_urls = ["https://systemcraftsman.github.io/scrapy-demo/website/index.html"]
welcome_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/welcome.html"
homework_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/homeworks.html"
date_str = "12.03.2024"
def parse(self, response):
formdata = {'username': 'student',
'password': '12345'}
return FormRequest(url=self.welcome_page_url, method="GET", formdata=formdata,
callback=self.after_login)
def after_login(self, response):
if response.status == 200:
return Request(url=self.homework_page_url,
callback=self.parse_homework_page
)
def parse_homework_page(self, response):
if response.status == 200:
data = {}
rows = response.xpath('//*[@class="table table-file"]//tbody//tr')
for row in rows:
if self._get_item(row, 4) == self.date_str:
if self._get_item(row, 2) not in data:
data[self._get_item(row, 2)] = self._get_item(row, 3)
else:
data[self._get_item(row, 2) + "-2"] = self._get_item(row, 3)
return data
def _get_item(self, row, col_number):
item_str = ""
contents = row.xpath(f'td[{col_number}]//text()').extract()
for content in contents:
item_str = item_str + content
return item_str在您的school-scraper/school_scraper目录中,运行以下命令以验证它是否成功抓取了家庭作业数据:
scrapy crawl homework_spider您应在其他日志之间看到抓取的输出:
...output omitted...
2024-03-20 01:36:05 [scrapy.core.scraper] DEBUG: Scraped from <200 https://systemcraftsman.github.io/scrapy-demo/website/homeworks.html>
{'MATHS': "Matematik Konu Anlatımlı Çalışma Defteri-6 sayfa 13'ü yapınız.n", 'ENGLISH': 'Read the story "Manny and His Monster Manners" on pages 100-107 in your Reading Log and complete the activities on pages 108 and 109 according to the story.nnReading Log kitabınızın 100-107 sayfalarındaki "Manny and His Monster Manners" isimli hikayeyi okuyunuz ve 108 ve 109'uncu sayfalarındaki aktiviteleri hikayeye göre tamamlayınız.n'}
2024-03-20 01:36:05 [scrapy.core.engine] INFO: Closing spider (finished)
...output omitted...恭喜!您已实现了您的第一个蜘蛛程序。让我们创建下一个吧!
创建餐单蜘蛛程序
要创建一个抓取餐单页面的蜘蛛程序,请在您的school-scraper/school_scraper目录中运行以下命令:
scrapy genspider meal_spider systemcraftsman.github.io/scrapy-demo/website/index.html生成的蜘蛛类应如下所示:
class MealSpiderSpider(scrapy.Spider):
name = "meal_spider"
allowed_domains = ["systemcraftsman.github.io"]
start_urls = ["https://systemcraftsman.github.io/scrapy-demo/website/index.html"]
def parse(self, response):
pass餐单蜘蛛程序的创建过程与家庭作业蜘蛛程序非常相似。唯一的区别是HTML抓取页面。
为了节省时间,请将meal_spider.py中的所有内容替换为以下内容:
import scrapy
from datetime import datetime
from scrapy import FormRequest, Request
class MealSpider(scrapy.Spider):
name = "meal_spider"
allowed_domains = ["systemcraftsman.github.io"]
start_urls = ["https://systemcraftsman.github.io/scrapy-demo/website/index.html"]
welcome_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/welcome.html"
meal_page_url = "https://systemcraftsman.github.io/scrapy-demo/website/meal-list.html"
date_str = "13.03.2024"
def parse(self, response):
formdata = {'username': 'student',
'password': '12345'}
return FormRequest(url=self.welcome_page_url, method="GET", formdata=formdata,
callback=self.after_login)
def after_login(self, response):
if response.status == 200:
return Request(url=self.meal_page_url,
callback=self.parse_meal_page
)
def parse_meal_page(self, response):
if response.status == 200:
data = {"BREAKFAST": "", "LUNCH": "", "SALAD/DESSERT": "", "FRUIT TIME": ""}
week_no = datetime.strptime(self.date_str, '%d.%m.%Y').isoweekday()
rows = response.xpath('//*[@class="table table-condensed table-yemek-listesi"]//tr')
key = ""
try:
for row in rows[1:]:
if self._get_item(row, week_no) in data.keys():
key = self._get_item(row, week_no)
else:
data[key] = self._get_item(row, week_no, "n")
finally:
return data
def _get_item(self, row, col_number, seperator=""):
item_str = ""
contents = row.xpath(f'td[{col_number}]//text()').extract()
for i, content in enumerate(contents):
item_str = item_str + content + seperator
return item_str请注意,parse和after_login函数几乎相同。唯一的区别是回调函数parse_meal_page的名称,该回调函数使用不同的XPath逻辑解析餐单页面的HTML。该函数还借助一个名为_get_item的私有函数,该函数类似于为家庭作业创建的函数。
作业和餐单页面中使用表格的方式不同,因此解析和处理数据的方式也不同。
要验证meal_spider,请在您的school-scraper/school_scraper目录中运行以下命令:
scrapy crawl meal_spider您的输出应如下所示:
...output omitted...
2024-03-20 02:44:42 [scrapy.core.scraper] DEBUG: Scraped from <200 https://systemcraftsman.github.io/scrapy-demo/website/meal-list.html>
{'BREAKFAST': 'PANCAKE n KREM PEYNİR n SÜZME PEYNİR nnKAKAOLU FINDIK KREMASI n SÜTn', 'LUNCH': 'TARHANA ÇORBAnEKŞİLİ KÖFTEnERİŞTEn', 'SALAD/DESSERT': 'AYRANnKIRMIZILAHANA SALATAnROKALI GÖBEK SALATAn', 'FRUIT TIME': 'FINDIK& KURU ÜZÜMn'}
2024-03-20 02:44:42 [scrapy.core.engine] INFO: Closing spider (finished)
...output omitted...注意: 由于数据来自原始网站,所有数据均保留原始格式,没有翻译。
格式化数据
您创建的用于家庭作业和餐单页面的抓取器已准备好以JSON格式抓取数据。然而,您可能希望通过编程方式触发蜘蛛程序以格式化数据。
在Python应用程序中,main.py文件通常作为入口点,通过调用其关键组件来初始化应用程序。然而,在这个Scrapy项目中,您没有创建入口点,因为Scrapy CLI提供了一个预构建框架来实现蜘蛛程序,您可以通过同一个CLI运行蜘蛛程序。
在这种情况下,您将构建一个基本的Python命令行程序,该程序接收参数并根据需要进行抓取。
在您的school-scraper项目根目录中创建一个名为main.py的文件,内容如下:
import sys
from scrapy.crawler import CrawlerProcess
from scrapy.utils.project import get_project_settings
from school_scraper.school_scraper.spiders.homework_spider import HomeworkSpider
from school_scraper.school_scraper.spiders.meal_spider import MealSpider
results = []
class ResultsPipeline(object):
def process_item(self, item, spider):
results.append(item)
def _prepare_message(title, data_dict):
if len(data_dict.items()) == 0:
return None
message = f"===={title}====n----------------n"
for key, value in data_dict.items():
message = message + f"==={key}===n{value}n----------------n"
return message
def main(args=None):
if args is None:
args = sys.argv
settings = get_project_settings()
settings.set("ITEM_PIPELINES", {'__main__.ResultsPipeline': 1})
process = CrawlerProcess(settings)
if args[1] == "homework":
process.crawl(HomeworkSpider)
process.start()
print(_prepare_message("HOMEWORK ASSIGNMENTS", results[0]))
elif args[1] == "meal":
process.crawl(MealSpider)
process.start()
print(_prepare_message("MEAL LIST", results[0]))
if __name__ == "__main__":
main()main.py文件有一个main函数,是应用程序的入口点函数。当您运行main.py时,会调用main方法。main方法接收一个名为args的数组参数,您可以使用它向程序发送参数。
main.py首先检查args值,并通过定义一个名为ResultsPipeline的管道来配置Scrapy抓取器设置。如您所见,ResultsPipeline在这个文件中定义,但您应在pipelines包中定义管道。
ResultsPipeline简单地获取结果并将其追加到一个名为results的数组中。这意味着results数组可以用作私有函数_prepare_message的输入,该函数用于准备格式化消息。这在每个蜘蛛程序中完成,区分成为可能是因为args数组的第二个参数代表蜘蛛类型。如果蜘蛛类型是homework,则抓取过程调用HomeworkSpider并启动它。如果蜘蛛类型是meal,则抓取过程调用MealSpider并启动它。
当一个蜘蛛程序启动时,注入的ResultsPipeline会将数据追加到results数组中,而main函数可以通过调用_prepare_message为每个蜘蛛程序使用它,从而帮助格式化数据输出。
在您的主项目目录中,运行新实现的main.py,使用以下命令检索家庭作业:
python main.py homework您的输出应如下所示:
...output omitted...
====HOMEWORK ASSIGNMENTS====
----------------
===MATHS===
Matematik Konu Anlatımlı Çalışma Defteri-6 sayfa 13'ü yapınız.
----------------
===ENGLISH===
Read the story "Manny and His Monster Manners" on pages 100-107 in your Reading Log and complete the activities on pages 108 and 109 according to the story.
Reading Log kitabınızın 100-107 sayfalarındaki "Manny and His Monster Manners" isimli hikayeyi okuyunuz ve 108 ve 109'uncu sayfalarındaki aktiviteleri hikayeye göre tamamlayınız.
----------------
...output omitted...要获取当天的餐单,请运行python main.py meal命令。您的输出应如下所示:
...output omitted...
====MEAL LIST====
----------------
===BREAKFAST===
PANCAKE
KREM PEYNİR
SÜZME PEYNİR
KAKAOLU FINDIK KREMASI
SÜT
----------------
===LUNCH===
TARHANA ÇORBA
EKŞİLİ KÖFTE
ERİŞTE
----------------
===SALAD/DESSERT===
AYRAN
KIRMIZILAHANA SALATA
ROKALI GÖBEK SALATA
----------------
===FRUIT TIME===
FINDIK& KURU ÜZÜM
----------------
...output omitted...克服常见网页抓取障碍的提示
恭喜!如果您已经完成到这里,您已经正式创建了一个Scrapy抓取器。
虽然使用Scrapy创建网页抓取器很容易,但在实现过程中您可能会遇到一些障碍,例如CAPTCHA、IP封禁、会话或cookie管理以及动态网站。让我们来看看应对这些不同情况的一些提示:
动态网站
动态网站根据访问者的系统配置、位置、年龄和性别等因素提供不同的内容。例如,两个人访问同一个动态网站,可能会看到为他们量身定制的不同内容。
虽然Scrapy可以抓取动态网页内容,但它不是为此设计的。要抓取动态内容,您需要定期安排Scrapy运行 ,保存和比较结果,以跟踪网页随时间的变化。
在某些情况下,动态网页内容可能被视为静态,特别是当这些页面仅偶尔更新时。
CAPTCHA
通常,CAPTCHA是带有字母数字字符的动态图像。访问者必须输入与CAPTCHA图像匹配的值才能通过验证过程。
CAPTCHA用于确保访问页面的是人类(而不是蜘蛛或机器人),通常也是为了防止网页抓取。
您在这里使用的虚拟学校系统没有使用CAPTCHA系统,但如果您遇到一个,您可以创建一个Scrapy中间件,下载CAPTCHA并使用OCR库将其转换为文本。
会话和cookie管理
当您打开一个网页时,您会进入该页面系统内的一个会话。这个会话会保留您的登录信息和其他相关数据,以在整个系统中识别您。
同样,您可以使用cookie跟踪网页访问者的信息。然而,与会话数据不同,cookie存储在访问者的计算机上,而不是网站服务器上,用户可以删除它们。因此,您不能使用cookie保持会话,但可以将它们用于各种数据丢失不重要的支持任务。
可能会出现需要操作用户会话或更新cookie的情况。Scrapy可以通过其内置功能或兼容的第三方库处理这两种情况。
IP封禁
IP封禁,也称为IP地址阻止,是一种安全技术,网站会阻止特定的传入IP地址。通常用于防止机器人或蜘蛛访问敏感信息,确保只有人类用户可以访问和处理数据。公司还使用CAPTCHA和IP封禁来阻止网页抓取活动。
在这种情况下,学校系统没有使用IP封禁机制。然而,如果他们实施了,您需要采用一些策略,例如使用动态IP或将您的IP地址隐藏在代理墙后面,以继续抓取他们的网站。
总结
在本文中,您学习了如何创建用于登录和使用XPath解析表格的蜘蛛程序。此外,您还学习了如何编程触发蜘蛛程序以增强数据控制。
您可以在这个GitHub存储库中访问本教程的完整代码。
对于那些希望扩展Scrapy功能并克服抓取障碍的人来说,Bright Data提供了针对公共网络数据的解决方案。Bright Data的与Scrapy集成增强了抓取能力,代理 服务帮助避免IP封禁,Web Unlocker简化了处理CAPTCHA和动态内容的过程,使使用Scrapy的数据收集更加高效。
立即注册,并与我们的数据专家讨论我们的抓取解决方案。