

在本指南中,你将学习:
- 如何识别一个网站是否具有复杂导航
- 应对这些场景的最佳抓取工具
- 如何抓取最常见的复杂导航模式
让我们开始吧!
网站何时算是具有复杂导航?
作为开发者,在进行网页抓取时,我们经常会面对具有复杂导航结构的网站。但究竟什么是“复杂导航”呢?在网页抓取过程中,复杂导航通常指那些内容或页面不易直接获取的网站结构。
复杂导航的情况往往涉及动态元素、异步数据加载,或者需要用户进行交互。尽管这些因素可以提升用户体验,但也会显著增加数据提取的难度。
现在,我们先通过一些示例来了解何谓复杂导航:
- JavaScript 渲染的导航:依赖 React、Vue.js 或 Angular 等 JavaScript 框架在浏览器中直接生成内容的网站。
- 分页内容:数据分散在多个分页上,尤其当分页通过 AJAX 方式按数字加载时,要访问后续页面会更困难。
- 无限滚动:页面在用户滚动时动态加载更多内容,这在社交媒体动态和新闻网站上非常常见。
- 多级菜单:带有嵌套菜单,需要多次点击或鼠标悬停才能展开更深层级(如大型电商平台上的产品分类树)。
- 交互式地图界面:网站在地图或图表上展示信息,用户拖动或缩放时会动态加载数据点。
- 选项卡或手风琴:页面内容隐藏在动态渲染的选项卡或可折叠的手风琴组件里,服务端返回的 HTML 中并没有直接包含这些内容。
- 动态筛选和排序功能:带有复杂筛选系统的网站,通过多项过滤器组合会在不改变 URL 的情况下动态刷新内容列表。
应对复杂导航网站的最佳抓取工具
若要有效地抓取具有复杂导航结构的网站,你必须先了解需要使用哪些工具。由于这项任务本身就颇具难度,如果没有用对抓取库,只会让过程更复杂。
上面列出的许多交互形式都具有以下共性:
- 需要某种形式的用户交互,或
- 在浏览器客户端执行(JavaScript 执行)
换句话说,这些操作都需要 JavaScript 的运行环境,而只有浏览器才能做到。也就是说,你不能仅依赖简单的HTML 解析器来抓取这类页面,而必须使用像 Selenium、Playwright 或 Puppeteer 这样的浏览器自动化工具。
通过这些解决方案,你可以像用户一样在编程层面指示浏览器执行特定动作。我们通常将这些称为无头浏览器,因为它们可以在没有可视化界面的情况下渲染页面,从而节省系统资源。
查看最佳无头浏览器抓取工具。
如何抓取常见的复杂导航模式
在本教程部分,我们将使用 Python 中的 Selenium。不过,你也可以轻松将思路应用于 Playwright、Puppeteer 或其他浏览器自动化工具。我们假设你已经熟悉了使用 Selenium 进行网页抓取的基础知识。
我们将重点演示如何抓取以下常见的复杂导航场景:
- 动态分页:使用 AJAX 动态加载的分页数据。
- “加载更多”按钮:一种常见的基于 JavaScript 的导航示例。
- 无限滚动:页面在用户下拉时不断加载新数据。
现在,让我们开始写代码吧!
动态分页
此示例的目标页面是 “Oscar Winning Films: AJAX and Javascript” 抓取沙箱:
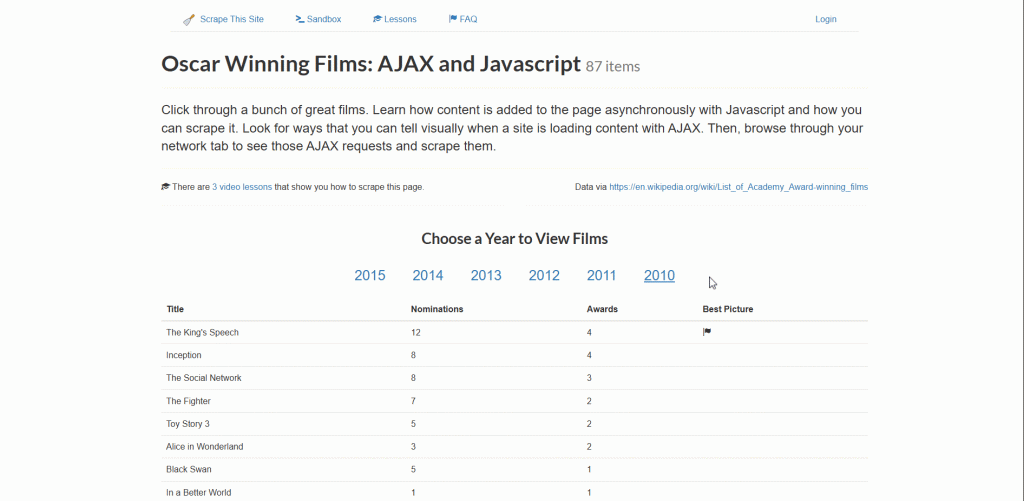
该网站会针对某一年份动态加载获奖电影数据,并进行分页。
想要处理这类复杂导航,思路是:
- 点击新的年份按钮以触发数据加载(页面会出现一个加载动画元素)。
- 等待加载动画元素消失(数据加载完成)。
- 确保数据表格已经完全渲染在页面上。
- 在数据可用后进行抓取。
下面是使用 Python 的 Selenium 实现该逻辑的示例:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.chrome.options import Options
# Set up Chrome options for headless mode
options = Options()
options.add_argument("--headless")
# Create a Chrome web driver instance
driver = webdriver.Chrome(service=Service(), options=options)
# Connect to the target page
driver.get("https://www.scrapethissite.com/pages/ajax-javascript/")
# Click the "2012" pagination button
element = driver.find_element(By.ID, "2012")
element.click()
# Wait until the loader is no longer visible
WebDriverWait(driver, 10).until(
lambda d: d.find_element(By.CSS_SELECTOR, "#loading").get_attribute("style") == "display: none;"
)
# Data should now be loaded...
# Wait for the table to be present on the page
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, ".table"))
)
# Where to store the scraped data
films = []
# Scrape data from the table
table_body = driver.find_element(By.CSS_SELECTOR, "#table-body")
rows = table_body.find_elements(By.CSS_SELECTOR, ".film")
for row in rows:
title = row.find_element(By.CSS_SELECTOR, ".film-title").text
nominations = row.find_element(By.CSS_SELECTOR, ".film-nominations").text
awards = row.find_element(By.CSS_SELECTOR, ".film-awards").text
best_picture_icon = row.find_element(By.CSS_SELECTOR, ".film-best-picture").find_elements(By.TAG_NAME, "i")
best_picture = True if best_picture_icon else False
# Store the scraped data
films.append({
"title": title,
"nominations": nominations,
"awards": awards,
"best_picture": best_picture
})
# Data export logic...
# Close the browser driver
driver.quit()上面代码的主要流程:
- 配置一个无头模式的 Chrome 实例。
- 脚本打开目标页面,并点击“2012”按钮来触发数据加载。
- Selenium 利用
WebDriverWait()等待加载动画消失。 - 等待动画消失后,再等待表格数据出现。
- 完成数据加载后,脚本抓取电影标题、提名数、获奖数,以及是否获得最佳影片,并以字典形式存储。
结果示例可能是:
[
{
"title": "Argo",
"nominations": "7",
"awards": "3",
"best_picture": true
},
// ...
{
"title": "Curfew",
"nominations": "1",
"awards": "1",
"best_picture": false
}
]需要注意的是,并没有单一的最佳方法来处理此类导航模式,实际情况可能要求不同的手段,例如:
- 结合
WebDriverWait()和等待条件(expected conditions)在特定 HTML 元素出现或消失后再操作。 - 监测 AJAX 请求来判断什么时候完成了新数据的获取,这可能需要使用浏览器的日志功能。
- 找出分页触发的 API 请求,直接用
requests库等方式进行请求获取数据。
“加载更多”按钮
为了演示在具有 JavaScript 复杂导航且需要用户交互的页面上抓取数据,我们用“加载更多”按钮举例。它的概念很简单:初始显示一批项目,点击按钮后再加载更多项目。
在本示例中,目标网站是 Scraping Course 提供的“加载更多”示例页面:
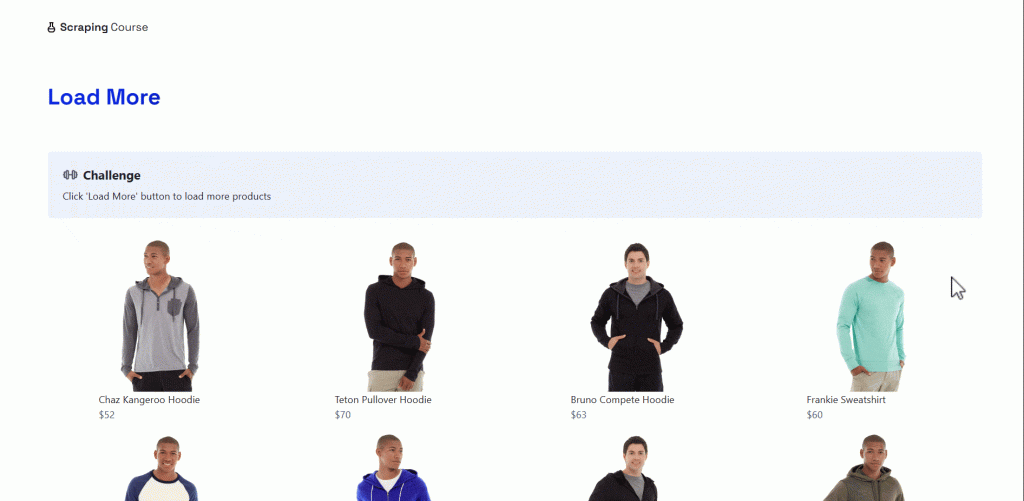
处理这种复杂导航抓取的步骤如下:
- 定位“加载更多”按钮并点击。
- 等待页面加载出新的元素。
下面是用 Selenium 的示例代码:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
# Set up Chrome options for headless mode
options = Options()
options.add_argument("--headless")
# Create a Chrome web driver instance
driver = webdriver.Chrome(options=options)
# Connect to the target page
driver.get("https://www.scrapingcourse.com/button-click")
# Collect the initial number of products
initial_product_count = len(driver.find_elements(By.CSS_SELECTOR, ".product-item"))
# Locate the "Load More" button and click it
load_more_button = driver.find_element(By.CSS_SELECTOR, "#load-more-btn")
load_more_button.click()
# Wait until the number of product items on the page has increased
WebDriverWait(driver, 10).until(lambda driver: len(driver.find_elements(By.CSS_SELECTOR, ".product-item")) > initial_product_count)
# Where to store the scraped data
products = []
# Scrape product details
product_elements = driver.find_elements(By.CSS_SELECTOR, ".product-item")
for product_element in product_elements:
# Extract product details
name = product_element.find_element(By.CSS_SELECTOR, ".product-name").text
image = product_element.find_element(By.CSS_SELECTOR, ".product-image").get_attribute("src")
price = product_element.find_element(By.CSS_SELECTOR, ".product-price").text
url = product_element.find_element(By.CSS_SELECTOR, "a").get_attribute("href")
# Store the scraped data
products.append({
"name": name,
"image": image,
"price": price,
"url": url
})
# Data export logic...
# Close the browser driver
driver.quit()在这段逻辑中,脚本:
- 先记录初始的产品数量
- 点击“加载更多”按钮
- 等待直到产品数量变多,确认加载了新项目
这种方法既巧妙又通用,因为无需事先知道会加载多少新元素。不过,请注意其他方法也能实现类似结果。
无限滚动
无限滚动是许多网站常用的交互方式,旨在提升用户体验(尤其在社交媒体和电商平台上)。在本示例中,我们使用与上一节相同的网站,但改用无限滚动代替“加载更多”按钮:

多数浏览器自动化工具(包括 Selenium)并未提供直接滚动页面的方法,需要通过在页面上执行一段 JavaScript 代码来完成滚动操作。
思路是编写自定义的 JS 脚本来下拉页面:
- 要么执行指定次数的滚动
- 要么滚动到没有更多数据可加载为止
注意:每次下拉都会加载新数据,从而增加页面上的元素数量。
之后,你就可以抓取新加载的内容。
下面是使用 Selenium 处理无限滚动的示例:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import WebDriverWait
# Set up Chrome options for headless mode
options = Options()
# options.add_argument("--headless")
# Create a Chrome web driver instance
driver = webdriver.Chrome(options=options)
# Connect to the target page with infinite scrolling
driver.get("https://www.scrapingcourse.com/infinite-scrolling")
# Current page height
scroll_height = driver.execute_script("return document.body.scrollHeight")
# Number of products on the page
product_count = len(driver.find_elements(By.CSS_SELECTOR, ".product-item"))
# Max number of scrolls
max_scrolls = 10
scroll_count = 1
# Limit the number of scrolls to 10
while scroll_count < max_scrolls:
# Scroll down
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
# Wait until the number of product items on the page has increased
WebDriverWait(driver, 10).until(lambda driver: len(driver.find_elements(By.CSS_SELECTOR, ".product-item")) > product_count)
# Update the product count
product_count = len(driver.find_elements(By.CSS_SELECTOR, ".product-item"))
# Get the new page height
new_scroll_height = driver.execute_script("return document.body.scrollHeight")
# If no new content has been loaded
if new_scroll_height == scroll_height:
break
# Update scroll height and increment scroll count
scroll_height = new_scroll_height
scroll_count += 1
# Scrape product details after infinite scrolling
products = []
product_elements = driver.find_elements(By.CSS_SELECTOR, ".product-item")
for product_element in product_elements:
# Extract product details
name = product_element.find_element(By.CSS_SELECTOR, ".product-name").text
image = product_element.find_element(By.CSS_SELECTOR, ".product-image").get_attribute("src")
price = product_element.find_element(By.CSS_SELECTOR, ".product-price").text
url = product_element.find_element(By.CSS_SELECTOR, "a").get_attribute("href")
# Store the scraped data
products.append({
"name": name,
"image": image,
"price": price,
"url": url
})
# Export to CSV/JSON...
# Close the browser driver
driver.quit() 此脚本首先获取当前页面的高度和产品数量,然后将滚动动作限制在最多 10 次。每次循环会:
- 滚动到底部
- 等待产品数量增加(确认加载新数据)
- 对比页面高度,判断是否还会继续加载新内容
如果一次滚动后页面高度未增加,则说明没有更多数据可供加载,循环便会终止。这就是应对复杂无限滚动的思路。
很好!现在你已经掌握了如何抓取具有复杂导航结构的网站。
总结
本文介绍了依赖复杂导航模式的网站,以及如何使用 Python 与 Selenium 来处理这些场景。这些技术挑战本身就不小,再加上网站可能采用了反抓取措施,就更为棘手。
许多网站深知其数据的价值,往往会不遗余力地进行保护,因此会采用各种屏蔽自动脚本的方式。这些方法可能包括频繁阻止 IP、要求输入 CAPTCHA 等等。
传统的浏览器自动化工具(如 Selenium)并不能绕过这些限制……
解决方案是使用像Scraping Browser这样专为抓取而打造的云端浏览器。该工具可与 Playwright、Puppeteer、Selenium 等库集成,并且会在每次请求时自动轮换 IP,能应对浏览器指纹检测、重试、自动识别 CAPTCHA等问题。让你在处理复杂网站时不必担心被封锁!


