

在本指南中,你将学到:
- 为什么 Gemini 是 AI 驱动网页抓取的优秀选择
- 如何通过一个完整的教程,在 Python 中使用它来抓取站点
- 这种抓取方式最大的局限是什么,以及如何解决
让我们开始吧!
为什么使用 Gemini 进行网页抓取?
Gemini 是由 Google 开发的一系列多模态 AI 模型,能够分析和解释文本、图像、音频、视频以及代码。将 Gemini 用于网页抓取,可以通过自动化方式来理解和结构化非结构化内容,从而简化数据提取的过程。这样就无需手动操作,尤其是在数据解析方面。
具体而言,以下是 Gemini 在网页抓取中一些常见的应用场景:
- 结构频繁变化的页面:Gemini 能够处理布局或数据元素经常变动的动态页面,例如类似亚马逊的电商网站。
- 包含大量非结构化数据的页面:它非常擅长从海量无组织文本中提取有用信息。
- 自定义解析逻辑编写难度大的页面:对于结构极其复杂或不可预测的页面,Gemini 可以自动完成解析,无需编写繁琐的规则。
Gemini 在网页抓取中的常见应用包括:
- RAG(检索增强生成):将实时数据抓取与 AI 洞察相结合。想要了解完整示例(使用类似的 AI 技术),可参考我们的教程:如何使用 SERP 数据创建 RAG 聊天机器人。
- 社交媒体抓取:从动态内容平台收集结构化数据。
- 内容聚合:从多个来源收集新闻、文章或博客帖子,以生成摘要或分析报告。
如需更多信息,请参阅我们关于使用 AI 进行网页抓取的指南。
在 Python 中使用 Gemini 进行网页抓取:分步指南
在本节中,我们将使用“Ecommerce Test Site to Learn Web Scraping”沙盒中的某个产品页面作为目标站点:
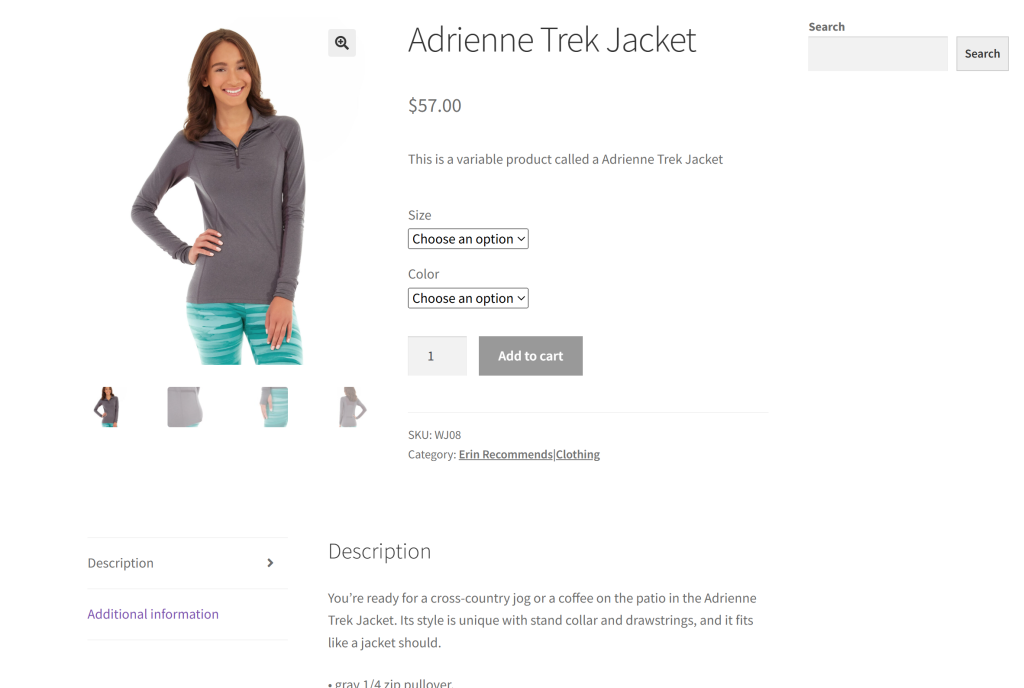
之所以选择这个示例,是因为大多数电商网站的产品页面通常会展示不同类型的数据或具有不尽相同的结构。这就是为什么电商网页抓取如此具有挑战性,而 AI 能在其中发挥重要作用。
我们这个基于 Gemini 的抓取器的目标是利用 AI 来抓取页面中的产品详情,而无需编写手动解析逻辑。通过 AI 获取的产品数据将包括:
- SKU
- 名称
- 图片
- 价格
- 描述
- 尺码
- 颜色
- 类别
请按照以下步骤来学习如何使用 Gemini 进行网页抓取!
步骤 #1:项目初始化
开始之前,请确保你已经在计算机上安装了 Python 3。如果尚未安装,可以下载并按照安装向导进行操作。
现在,运行以下命令来创建一个用于抓取项目的文件夹:
mkdir gemini-scrapergemini-scraper 代表了你的 Python Gemini 网页抓取项目文件夹。
进入该文件夹,并在其中初始化一个虚拟环境:
cd gemini-scraper
python -m venv venv在你喜欢的 Python IDE 中加载该项目文件夹。带有 Python 扩展的 Visual Studio Code 或 PyCharm Community Edition 都是不错的选择。
在项目文件夹中新建一个 scraper.py 文件,现在文件结构应如下所示:

目前,scraper.py 还是一个空白的 Python 脚本,但很快就会包含我们所需的 LLM 抓取逻辑。
在 IDE 的终端中,激活虚拟环境。对于 Linux 或 macOS,执行:
./venv/bin/activate在 Windows 上,执行:
venv/Scripts/activate太好了!你现在拥有了一个用于结合 Gemini 做网页抓取的 Python 环境。
步骤 #2:配置 Gemini
Gemini 提供了一个可通过任何 HTTP 客户端(包括 requests)调用的 API。不过,最好使用官方的Google AI Python SDK 来连接 Gemini API。要安装它,请在已激活的虚拟环境中运行:
pip install google-generativeai然后,在 scraper.py 中导入:
import google.generativeai as genai要使该 SDK 正常工作,你需要一个 Gemini API key。如果你还没有获取到自己的 API key,
请参阅 Google 官方文档。具体来说,使用你的 Google 账户登录并加入 Google AI Studio。转到“Get API Key”页面,你会看到如下弹窗:
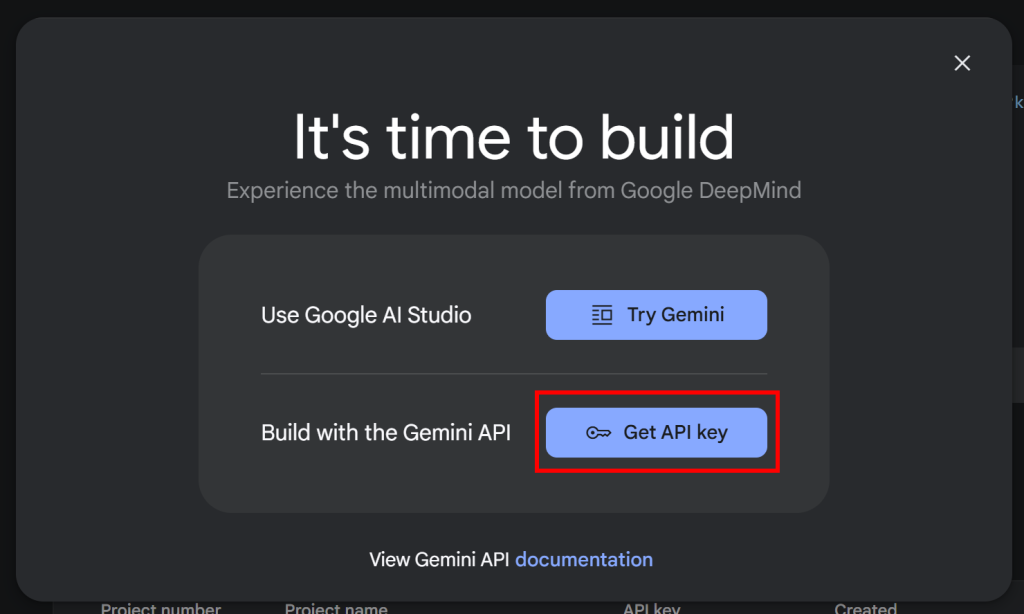
点击“Get API key”按钮后,会出现如下界面:
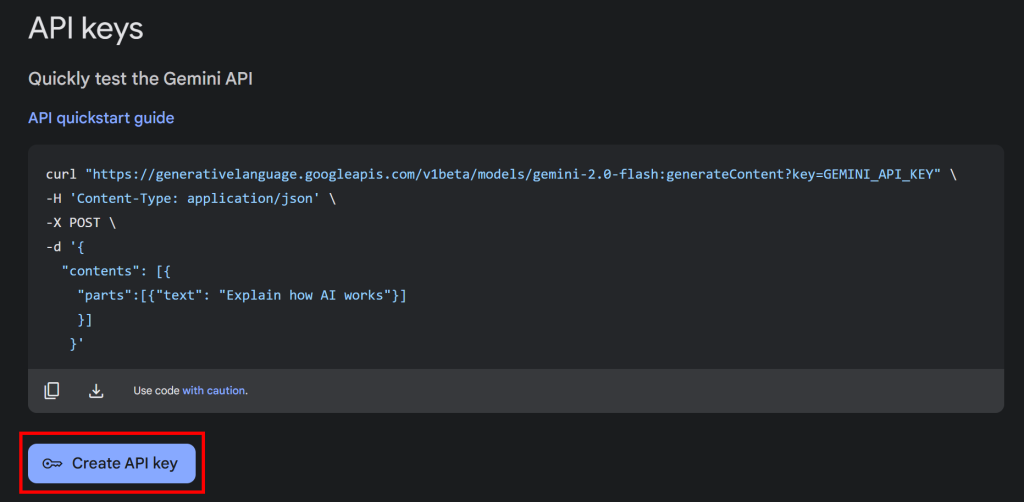
现在,按下“Create API key”按钮生成你的 Gemini API key:
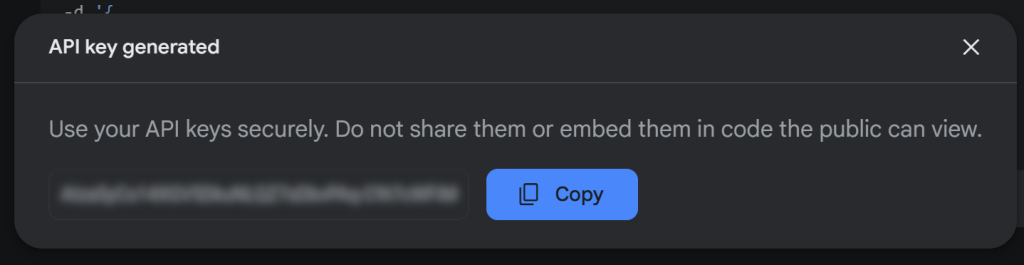
复制该密钥,并妥善保管。
注意:对于本示例,Gemini 的免费套餐已足够。如果需要更高的请求速率限制,或者不希望你的 prompt 与回复被用于改进 Google 产品,才需要付费套餐。具体参见Gemini 计费页面。
在 Python 中使用 Gemini API key,你可以将其设置为环境变量:
export GEMINI_API_KEY=<YOUR_GEMINI_API_KEY>或者,直接在脚本中定义一个常量:
GEMINI_API_KEY="<YOUR_GEMINI_API_KEY>"并像这样告诉 genai:
genai.configure(api_key=GEMINI_API_KEY)本示例将使用第二种方式。但需要注意的是,如果不手动传入,google-generativeai 会自动尝试从环境变量 GEMINI_API_KEY 中读取该密钥。
厉害!你现在可以在 Python 中使用 Gemini SDK 来发送 LLM 请求了。
步骤 #3:获取目标页面的 HTML
要连接目标服务器并获取其网页的 HTML,我们将使用 Requests——这是 Python 中最受欢迎的HTTP 客户端。在已激活的虚拟环境中,使用以下命令安装:
pip install requests然后,在 scraper.py 中导入:
import requests使用它向目标页面发送一个 GET 请求,并获取其 HTML 文档:
url = "https://www.scrapingcourse.com/ecommerce/product/adrienne-trek-jacket/"
response = requests.get(url)此时 response.content 将包含页面的原始 HTML。接下来,我们会解析这些文本,准备提取数据!
步骤 #4:将 HTML 转换为 Markdown
如果你对比过其他 AI 抓取技术(如 Crawl4AI),你会注意到它们通常允许使用 CSS 选择器来定位 HTML 元素,然后将这些元素对应的 HTML 转为 Markdown 文本,最后用 LLM 来解析。
为什么要这样做呢?主要有两个核心原因:
- 减少传递给 AI 的 tokens 数量,以帮助你节省开支(并非所有 LLM 提供商都像 Gemini 那样免费)。
- 让 AI 处理速度更快,因为输入数据越少,计算量就越低,响应越快。
详情可参见我们关于CrawlAI 和 DeepSeek 进行网页抓取的教程。
让我们尝试复制这个思路,并看看有没有意义。首先,在无痕模式下打开目标页面(即开始一个全新的会话)。然后,右键单击页面的任意位置,选择 “Inspect”。
观察页面结构,你会发现所有相关信息都在 CSS 选择器 #main 指定的 HTML 元素内:
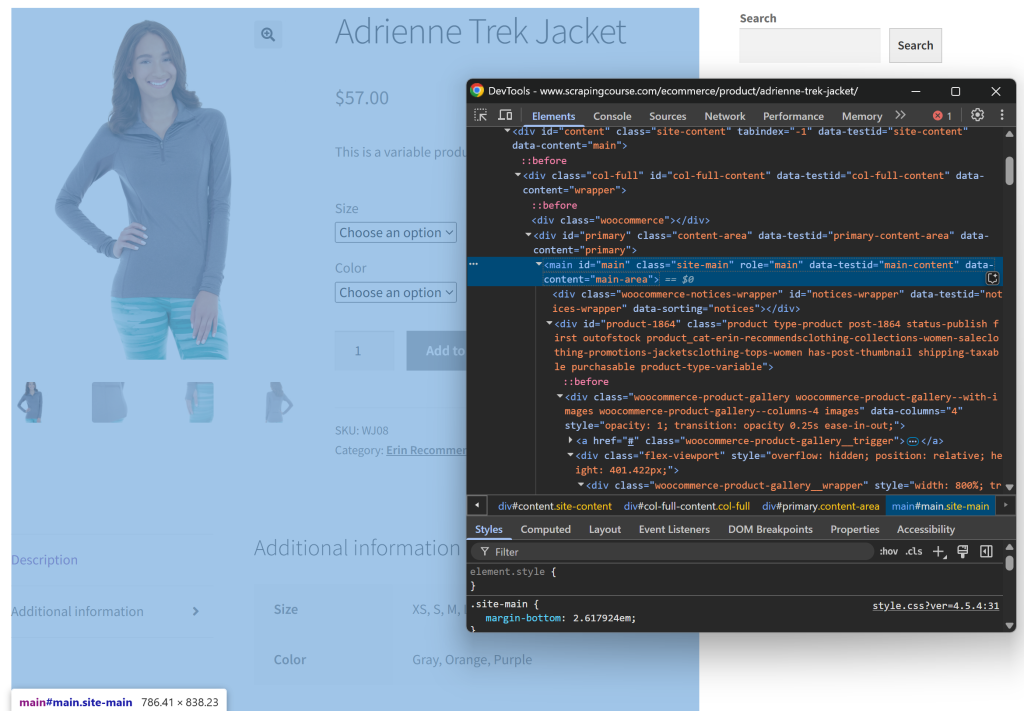
你可以将整个原生 HTML 都传给 Gemini,但这会带来不必要的信息(如页面的头部和尾部)。因此,仅传递 #main 的内容可以减少噪音,并避免 AI 出现幻觉式的生成。
要选中 #main,需要一个Python HTML 解析库,如 Beautiful Soup。先安装它:
pip install beautifulsoup4如果你对它的用法还不熟悉,可以看看我们的Beautiful Soup 网页抓取教程。
现在,在 scraper.py 中导入:
from bs4 import BeautifulSoup然后使用 Beautiful Soup 解析 Requests 获取的原始 HTML,选中 #main 元素,并提取它的 HTML:
# Parse the HTML with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Extract the #main element
main_element = soup.select_one("#main")
# Get its outer HTML
main_html = str(main_element)如果你打印 main_html,你会看到类似:
<main id="main" class="site-main" role="main" data-testid="main-content" data-content="main-area">
<!-- omitted for brevity... -->
</main>现在,你可以测算这段 HTML 在使用 Gemini 的付费版本时约会产生多少 tokens,并估算对应的花费。可以使用 Token Calculator 等工具:
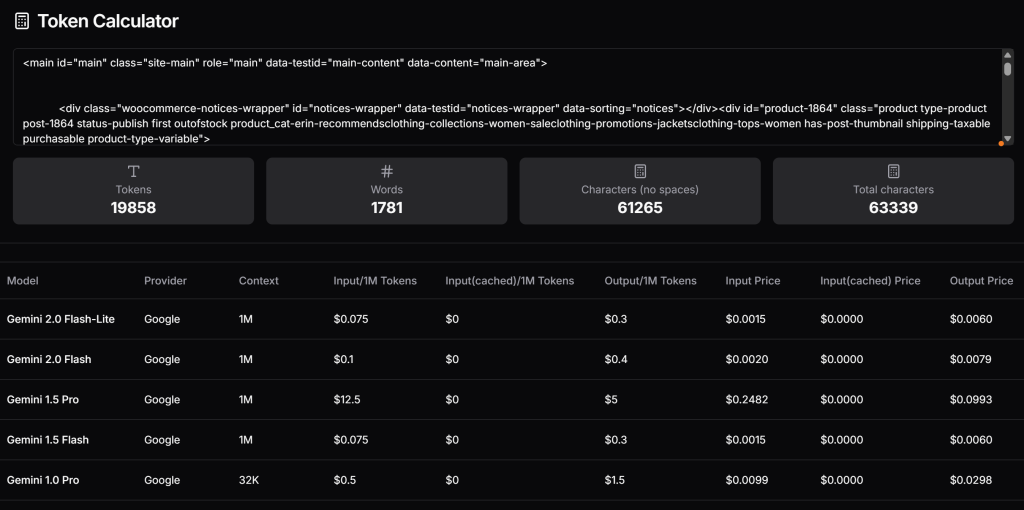
差不多要 2 万 tokens,按 Gemini 1.5 Pro 定价来算,每次请求约 0.25 美元。在大规模抓取场景下,这很容易成为巨大的成本压力!
让我们把抓取到的 HTML 转换成 Markdown,类似于 Crawl4AI 里的做法。首先,安装一个能将 HTML 转 Markdown 的库,比如 markdownify:
pip install markdownify在 scraper.py 中导入 markdownify:
from markdownify import markdownify然后,用 markdownify 将提取到的 HTML 转换为 Markdown:
main_markdown = markdownify(main_html)生成的 main_markdown 字符串可能如下:
[](https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_main.jpg)
[](https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_alt1.jpg)
[](https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_alternate.jpg)
[](https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_back.jpg)
Adrienne Trek Jacket
====================
$57.00
This is a variable product called a Adrienne Trek Jacket
| | |
| --- | --- |
| Size | Choose an optionXSSMLXL |
| Color | Choose an optionGrayOrangePurple[Clear](#) |
Adrienne Trek Jacket quantity
Add to cart
SKU: WJ08
Category: [Erin Recommends|Clothing](https://www.scrapingcourse.com/ecommerce/product-category/clothing/women/tops-women/jacketsclothing-tops-women/promotions-jacketsclothing-tops-women/women-saleclothing-promotions-jacketsclothing-tops-women/collections-women-saleclothing-promotions-jacketsclothing-tops-women/erin-recommendsclothing-collections-women-saleclothing-promotions-jacketsclothing-tops-women/)
* [Description](#tab-description)
* [Additional information](#tab-additional_information)
Description
-----------
You’re ready for a cross-country jog or a coffee on the patio in the Adrienne Trek Jacket. Its style is unique with stand collar and drawstrings, and it fits like a jacket should.
* gray 1/4 zip pullover.
* Comfortable, relaxed fit.
* Front zip for venting.
* Spacious, kangaroo pockets.
* 27″ body length.
* 95% Organic Cotton / 5% Spandex.
Additional information
----------------------
| | |
| --- | --- |
| Size | XS, S, M, L, XL |
| Color | Gray, Orange, Purple |相比于原来的 #main HTML 代码,这段 Markdown 体量要小得多,同时保留了所有关键信息。
再次使用 Token Calculator 来查看新的输入需要多少 tokens:

结果十分惊人——从 19,858 个 tokens 降到了 765 个,减少了 95%!
步骤 #5:使用 LLM 来提取数据
要用 Gemini 进行网页抓取,可按照以下流程:
- 编写一个结构良好的 Prompt,用来从 Markdown 中提取所需数据,并指定返回结果需要包含哪些字段。
- 使用
genai向 Gemini LLM 模型发送请求,并让返回结果以 JSON 格式输出。 - 解析返回的 JSON。
用如下代码实现:
# Extract structured data using Gemini
prompt = f"""Extract data from the content below. Respond with a raw string in JSON format containing the scraped data in the specified attributes:\n\n
JSON ATTRIBUTES: \n
sku, name, images, price, description, sizes, colors, category
CONTENT:\n
{main_markdown}
"""
model = genai.GenerativeModel("gemini-2.0-flash-lite", generation_config={"response_mime_type": "application/json"})
response = model.generate_content(prompt)
# Get the response and parse it from JSON
product_raw_string = response.text
product_data = json.loads(product_raw_string)prompt 变量告诉 Gemini 从 main_markdown 中提取指定的结构化数据。然后,genai.GenerativeModel() 设置 "gemini-2.0-flash-lite" 模型来完成 LLM 请求。最后,使用 json.loads() 将响应字符串解析成 Python 字典。
注意这里的 "application/json" 配置,告诉 Gemini 返回 JSON 格式的数据。
别忘了在脚本开头导入 json:
import json现在,你就能在 product_data 字典中访问各个字段,并进行后续的处理了,比如:
price = product_data["price"]
price_eur = price * USD_EUR
# ...太棒了!你已经使用 Gemini 完成了网页抓取,接下来只需要导出这些数据。
步骤 #6:导出抓取到的数据
目前,你所抓取的数据都在一个 Python 字典中。要将其导出为 JSON 文件,可执行:
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)这样会生成一个名为 product.json 的文件,包含以 JSON 格式输出的抓取数据。
恭喜!基于 Gemini 的网页抓取器已完成。
步骤 #7:整合所有代码
下面是完整的 Gemini 抓取脚本:
import google.generativeai as genai
import requests
from bs4 import BeautifulSoup
from markdownify import markdownify
import json
# Your Gemini API key
GEMINI_API_KEY = "<YOUR_GEMINI_API_KEY>"
# Set up the Google Gemini API
genai.configure(api_key=GEMINI_API_KEY)
# Fetch the HTML content of the target page
url = "https://www.scrapingcourse.com/ecommerce/product/adrienne-trek-jacket/"
response = requests.get(url)
# Parse the HTML of the target page with BeautifulSoup
soup = BeautifulSoup(response.content, "html.parser")
# Select the #main element
main_element = soup.select_one("#main")
# Get its outer HTML and convert it to Markdown
main_html = str(main_element)
main_markdown = markdownify(main_html)
# Extract structured data using Gemini
prompt = f"""Extract data from the content below. Respond with a raw string in JSON format containing the scraped data in the specified attributes:\n\n
JSON ATTRIBUTES: \n
sku, name, images, price, description, sizes, colors, category
CONTENT:\n
{main_markdown}
"""
model = genai.GenerativeModel("gemini-2.0-flash-lite", generation_config={"response_mime_type": "application/json"})
response = model.generate_content(prompt)
# Get the response and parse it from JSON
product_raw_string = response.text
product_data = json.loads(product_raw_string)
# Futher data processing... (optional)
# Export the scraped data to JSON
with open("product.json", "w", encoding="utf-8") as json_file:
json.dump(product_data, json_file, indent=4)使用以下命令运行脚本:
python scraper.py执行后,项目文件夹中会出现一个名为 product.json 的文件。打开它,你会看到类似以下格式的结构化数据:
{
"sku": "WJ08",
"name": "Adrienne Trek Jacket",
"images": [
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_main-416x516.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_alt1-416x516.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_alternate-416x516.jpg",
"https://www.scrapingcourse.com/ecommerce/wp-content/uploads/2024/03/wj08-gray_back-416x516.jpg"
],
"price": "$57.00",
"description": "You\u2019re ready for a cross-country jog or a coffee on the patio in the Adrienne Trek Jacket. Its style is unique with stand collar and drawstrings, and it fits like a jacket should.\n\n\u2022 gray 1/4 zip pullover. \n\u2022 Comfortable, relaxed fit. \n\u2022 Front zip for venting. \n\u2022 Spacious, kangaroo pockets. \n\u2022 27\u2033 body length. \n\u2022 95% Organic Cotton / 5% Spandex.",
"sizes": [
"XS",
"S",
"M",
"L",
"XL"
],
"colors": [
"Gray",
"Orange",
"Purple"
],
"category": "Erin Recommends|Clothing"
}完成!你从一个 HTML 页面中的非结构化数据开始,最终在获得了结构化的 JSON 文件,这一切都拜 Gemini 网页抓取所赐。
后续步骤
想要进一步完善你的 Gemini 抓取器,可考虑以下几点:
- 提升可复用性:修改脚本,让它能够通过命令行参数接收 Prompt 和目标 URL,从而使其成为通用、可扩展的抓取工具。
- 实现网页爬取:添加对多页面网站的抓取支持(例如翻页和爬虫逻辑)。
- 加强 API 凭证安全:将你的 Gemini API key 存放在
.env文件中,并使用python-dotenv进行加载,避免在代码中暴露你的 API key。
如何克服此网页抓取方法的主要局限
这种网页抓取方式最大的局限是什么?那就是我们用 requests 发出的这条 HTTP 请求!
在上面的示例里,它确实完美运行,但前提是目标网站只是一个抓取练习场。在现实场景中,各大公司和网站的所有者都知道公开数据的价值。他们往往会部署反抓取技术,很容易就能屏蔽你的自动化请求。
另外,对于依赖 JavaScript 渲染或异步获取数据的动态网站,上述方式也无法正常工作。事实上,此时网站甚至不用高级反抓取框架,仅仅通过 JavaScript 加载内容就足以阻止你的脚本拿到真正的数据。
要解决这些问题,网络解锁器 API 就登场了!
Web Unlocker API 是一个 HTTP 端点,你可以通过任何 HTTP 客户端发请求给它。不同之处在于,它能返回目标 URL 的完整 HTML,无论目标站点如何防抓取,都能一并规避。只要你发给它一个请求,Web Unlocker 就能帮你拿到正确的内容。
要开始使用这个工具并获取你的 API key,可以查看官方文档。然后,将“步骤 #3”中原本的请求代码替换为:
WEB_UNLOCKER_API_KEY = "<YOUR_WEB_UNLOCKER_API_KEY>"
# Set up authentication headers for Web Unlocker
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {WEB_UNLOCKER_API_KEY}"
}
# Define the request payload
payload = {
"zone": "unblocker",
"url": "https://www.scrapingcourse.com/ecommerce/product/adrienne-trek-jacket/", # Replace with your target URL
"format": "raw"
}
# Fetch the unlocked HTML of the target page
response = requests.post("https://api.brightdata.com/request", json=payload, headers=headers)这样一来,你就不用再担心被封锁或其它限制了!可以安心结合 Gemini 进行网页抓取。
总结
在本文中,我们展示了如何将 Gemini 与 Requests 等工具配合使用,构建一个 AI 驱动的抓取脚本。网页抓取过程中面临的主要挑战之一是在于很容易被封锁,但我们可以通过 Bright Data 的Web Unlocker API 来轻松解决。
正如文中所说,通过结合 Gemini 和 Web Unlocker API,你可以在无需编写自定义解析规则的情况下,从任何网站中获取结构化数据。这只是 Bright Data 产品和服务支持的众多 AI 驱动抓取场景之一,帮助你高效地实现网页抓取。
你也可以探索我们其他的网页抓取工具:
- 代理服务:四种不同类型的代理可用来绕过地域限制,包括超过 7200 万的住宅 IP
- 网络抓取 APIs:专门为 100 多个热门域名提供的抓取端点,获取新鲜和结构化的网络数据。
- 搜索引擎结果页 API:专为搜索引擎结果页面打造的 API,统一管理解除封锁并提取单页结果
- 抓取浏览器:与 Puppeteer、Selenium、Playwright 兼容的浏览器,并内置自动破解封锁策略
立即注册 Bright Data 免费试用我们的代理服务和抓取产品吧!




