

试着和一个大型语言模型(LLM)聊聊它从未接触过的东西。它能搞懂吗?这通常被认为是对智能的真正考验。当一个模型利用推理和泛化在没有训练数据的情况下进行学习时,这就叫做零样本学习(Zero-Shot Learning)。
传统上,AI 模型需要大量带有标注的样本数据。零样本学习期待模型在没有训练数据的情况下随时学会。零样本学习并不是对标准训练的替代,而是用来让预训练模型更上一个台阶。你可以把一个 AI 扔到它从未见过的场景中,它依然能表现不错。
跟随本文,学习零样本学习的来龙去脉。
零样本学习在哪些地方被使用?
你是否需要过某个人从不同的角度看你的工作?这就是零样本学习的用武之地。有了零样本学习,AI 模型接受输入、进行处理,然后在没有任何训练的情况下给出见解。这在各种行业都能产生可观的结果。当你让 AI 去处理未知的信息并得到结果时,这就是零样本学习在发挥作用。
- 医疗保健:在诊断罕见或从未见过的疾病时,模型使用零样本来诊断罕见和前所未有的医疗状况。在这样的情形下,数据非常稀少甚至不存在。
- 制药行业:模型可以分析之前从未见过的数据,去预测尚不存在化合物的有效性。
- 自然语言处理:大型语言模型(LLM)每天不停地和人交互。当新兴的俚语出现,或者有人谈到自己的个人问题,模型就会利用零样本来做出类似人类的推断和泛化。
- 计算机视觉与机器人学:几乎不可能让模型训练识别它在现实世界中可能遇到的每一张图片。模型需要辨认新的图像,并判断如何应对它们。比如,一辆自动驾驶汽车在它从未见过的路口停车;一台 Roomba 看到你的家具并绕开它。
- 娱乐和创意产业:零样本让模型能够即时生成独特的游戏角色。DALL-E 以及类似的模型可以创作从未见过的全新艺术作品。
零样本学习已经在全世界被广泛使用。随着 AI 的采用程度日益增长,零样本学习还会不断发展壮大。
零样本与其他范式

你有没有在一份工作中遭遇糟糕的管理,并且基本没什么培训?如果有,那你就用过零样本学习。零样本学习是一个更大范式的一部分,称为 “n-shot” 学习。“n” 代表有标注样本的数量。零样本学习意味着先前没有任何训练。传统的机器学习会使用大量带标注的输入数据。
- 一样本学习:模型在每个类别只有一个标注样本的情况下进行训练。
- 少样本学习:模型在少量标注样本上进行训练。
- 传统机器学习:在传统学习中,模型在包含大量标注示例的庞大数据集上进行训练。这与零样本学习正好相反。
- 零样本学习:模型会看到它从未见过、也从未被教过的东西。它会直接被扔进新的环境,并期望它能够自行弄明白并学到东西。
零样本学习就像随时随地的、面向现实世界的学习一样。你的老板把你扔进一堆任务里,希望你自己摸索解决。
传统零样本学习(ZSL)
想寻求某个能回答单一实用问题的无限信息源吗?LLM 可以帮到你。LLM 是传统零样本学习的经典例子。这些模型在预训练阶段,所见到的数据量比你我想象的都要大。比如整部维基百科、公司认可的社交媒体内容、成千上万本书以及更多。
当你正式训练一个 AI 时,你会给它一些预定义的类别。如果我们想训练 AI 识别马(horses),就能给它很多马的图片和文本资料。这样做时,我们在模型中创建了一个“马”类别(class)。接着,模型会为它的“马”类别内部生成处理相关信息的规则和泛化方式。
一旦模型完成了充分的预训练,就能接收新数据并自行创建新的类别。假如我们给这个识马的模型看一张斑马(Zebra)的图片,它能推断出:有条纹的马就是斑马。即便没有对斑马进行过训练,模型也足够聪明去内部创建一个“斑马”类别,并开始形成处理斑马的规则。
由于需要大量的预训练,ZSL 的代价其实是相当昂贵的。我们的模型或许能理解斑马,但要用半个世界的数据来训练它!因此,预训练在效率方面不是很理想。下次当你问 ChatGPT 一个不痛不痒的问题时,可以想想为了回答你的简短问题,这台机器经历了多少训练。
广义零样本学习(GZSL)
GZSL 从 ZSL 中提炼出一些概念,并进一步提高效率。在 GZSL 中,我们利用混乱(chaos)来简化学习过程。广义零样本学习会在训练过程中混入多个未知信息。然后,模型利用泛化能力,在这些未知当中创建内部的类别和规则。
与其预先训练我们的模型让它只认识马,不如给它一张同时含有几匹马和一只斑马的图片?我们还可以给它一点文本:“我给你的这张图片里有好几匹马和一只斑马。斑马就是带条纹的马。”
模型可以用这段简短描述和那张图片来同时创建“马”类别和“斑马”类别。
- 马类别:模型会创建一个“马”类别,并存储这张图片里那些无条纹马的信息。
- 斑马类别:模型会用我们提供的简短描述以及这张带条纹的马的图片,来创建“斑马”类别。
这极大地减少了我们对训练数据的需求量。现在,我们仅用一张图外加一些文字就训练模型去识别多匹马和一只斑马。如果一张图片平均大小约 4kb,训练四匹马就至少需要 16kb 数据。而如果我们把所有动物都包含在一张图片里,那么训练集只需要 4kb。借助 GZSL,我们能提供更简洁、高质量的训练数据,从而加快训练过程并减小模型规模。
零样本学习是如何运作的
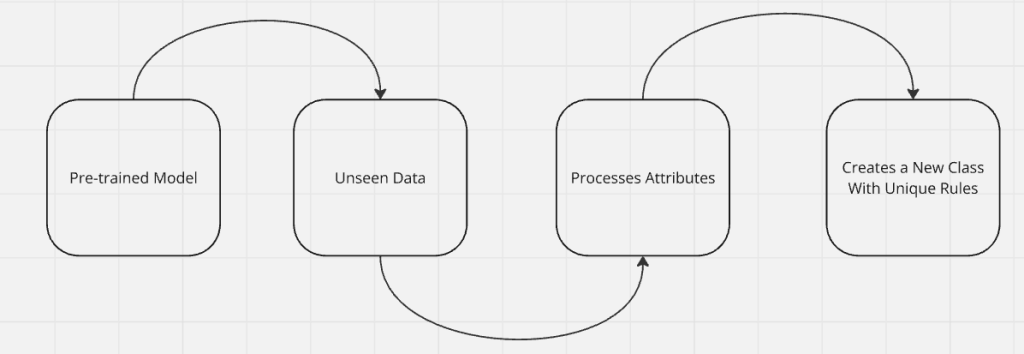
让我们来拆解一下我们这个假想 LLM 的大脑,看看里面到底发生了什么。我们知道模型会接收输入数据,然后自己创建新的规则和类别。我们来深入了解它是如何完成的。
标签
预训练有点像上学。在预训练阶段,模型学习如何处理信息以及“思考”的基础。等预训练结束,模型从我们这里学到了各种标注类别和规则。此时它已经“毕业”,学会了如何学习,我们无需再像最初那样一直喂它数据。
我们的模型并不会等我们去提供标签。还记得之前举的马和斑马的例子吗?模型会在没有我们帮助的情况下给新类别贴标签并创建类别。这为我们节省了宝贵的训练时间,并让模型可以自行保持一定程度的自主性。
迁移学习
模型会进行推断。当我们的马模型学会斑马时,它会把许多(甚至全部)“马”类别中现有的规则迁移到新的“斑马”类别。不同模块之间的学习结果也可以相互迁移。
举个例子:你先训练一个模型从 Google 抓取酒店数据(想了解手动实现方法可以点击这里)。然后,你再教会它从 Booking.com 抓取酒店数据(手动实现方法可点击这里)。当它开始在 Booking.com 抓取酒店数据时,它会利用此前从 Google 学到的酒店知识来帮助它抓取 Booking.com 上的新酒店。
推理
零样本学习的核心是推理能力。回想一下你接到那份没有培训也毫无经验的糟糕工作,你是怎么活下来的?很可能是靠推理和常识来摸索解决。想象我们给一个处于“AI 婴儿期”的模型一份“看与说”(See and Say)的数据集,我们会为每一个类别设置对应的规则。比如:“牛会说——哞(moo)。”我们会创建一个“牛”类别,并定义它的一个规则是“会说哞”。
等到这个 AI 长大后,我们无需再这么做。模型看到一只鸡的图片,以及一些不准确的描述词,比如“咯咯叫”(cluck)或“羽毛”(feathers)。有了这些简单的提示,预训练过的模型就能猜到这是只鸡,然后它会创建一个“鸡”类别并设置相应规则,比如“咯咯叫”和“羽毛”等。当模型进行推理时,会利用常识和经验来解决真实世界的问题(不管是不是和农场有关)。
预训练基础模型
实际上,我们的模型最初和新生儿很像——它完全无助,什么也做不了。预训练过程就像让模型慢慢学会独立思考的成长过程。在能进行零样本学习之前,模型需要先“学会如何学习”。
所有人类的成长过程都是类似的:我们先学会怎么进食,然后才能学会吃固体食物、学会坐。大约在一岁时,我们还学会了走路和说话。对于 AI 模型而言,先是学习基础的数学和语言处理,然后学习如何摄取(ingest)数据。
一旦模型知道如何处理数据,我们就不断地喂它数据,直到它学会如何访问自己的内部类别。一旦模型可以读写类别,它就会开始做出泛化,并随着时间的推移发展出推理能力。只要预训练到位,模型就能利用零样本学习自发地学习新知识。
零样本学习方法
从外部看,零样本学习就像魔法。但是,和所有的魔术一样,这其实都是幻象。AI 模型依赖一套非常特殊的技能。它会把原始数据转换成我们能阅读或聆听的真实答案。让我们看看在把兔子从帽子里变出来之前,模型到底在做些什么。
属性
我们的模型通过特征(或称作“属性”)来辨别不同的动物。属性非常直观,当模型看到一张包含多种动物的图像时,它会利用它们的特征来判断是什么动物。
- 马:嘶鸣(neigh)、4 条腿、有蹄子。
- 鸡:咯咯叫(cluck)、2 条腿、有翅膀。
- 牛:哞(moo)、4 条腿、有蹄子。
通过这些属性,模型就能和人类一样做出有根据的推断。
嵌入(Embeddings)
机器并不像人类那样直接看数据。它们内部存储的是数字矩阵。假设我们想用数字表示马、鸡、牛的属性,如下所示:
| 动物 | 叫声(Sound) | 腿数(Legs) | 特征(Features) |
|---|---|---|---|
| 马 | Neigh | 4 | Hooves |
| 鸡 | Cluck | 2 | Wings |
| 牛 | Moo | 4 | Hooves |
上面这张表中的每一行都可以表示成一个列表:
- 马:
[Neigh, 4, Hooves] - 鸡:
[Cluck, 2, Wings] - 牛:
[Moo, 4, Hooves]
但上述字符串并没有真正达到机器可读的程度。机器在理解数字上更在行。比如,为了表示“Neigh”、“Cluck”、“Moo”,我们分别编码为 1、2、3;至于特征(hooves、wings)可以类似地用 1 和 2 来表示。
下面是模型可能看到的数字形式:
- 马:
[1, 4, 1] - 鸡:
[2, 2, 2] - 牛:
[3, 4, 1]
通过将我们的数据以数字 embedding 的方式进行表示,AI 模型便可以高效地进行处理,以发现特征之间的关系并总结出规则。这正是它进行泛化和推理的基础。如需了解更多,可参见关于ML 中的嵌入。
生成式方法
模型可以凭空创造新的类别。当系统通过查看嵌入属性之间的联系来得出结论时,就是在使用生成式方法。当我们的模型在没有训练的情况下识别到斑马时,这就是生成式方法在起作用。它看到那是一匹带条纹的马,进而生成一个结论:带条纹的马就是斑马。
如果你在抓取酒店数据时缺少评分,AI 模型可能会根据提供的信息生成一个评分。比如它觉得,如果房间里有大床还有热水浴缸,那就该是五颗星。这种功能极其强大,但也可能导致“幻觉”(hallucination)。
使用生成式方法时,需要谨慎。能够给酒店打分当然好;但如果你问模型 “孔子在 2025 年写的最后一篇文章是啥?”,孔子已经去世数千年了,可是 AI 模型通常很少直接告诉你“我不知道”。它很可能给你产生一个类似下面的回答:

上面的输出其实更像是道家思想而不是儒家思想。现代 AI 已经针对此类幻觉做了更强的安全防护。事实上,我得事先告诉 ChatGPT “可以自由幻想一下” 它才会给我这么个答案。如果你想尝试模型的想象力,可以让它“天马行空”,看看它会如何陷入混乱。
对比学习(Contrastive Learning)
AI 如何在没有训练的情况下分清猫和狗?答案就在对比学习。下面,我们再次像之前那样,通过属性拆分狗和猫:
- 狗:汪汪叫(woof)、4 条腿、有爪子
- 猫:喵喵叫(meow)、4 条腿、有爪子
这两种动物几乎相同,但又有一点差别:它们发出的叫声不同。狗会“woof”,猫会“meow”。模型会把这些属性转化为数字,然后迅速找到二者之间相差的那一点。通过零样本学习,AI 模型会在它的嵌入中快速检索出这些对比特征。
提示工程(Prompt Engineering)
提示工程就是和 AI 对话的艺术。只要你知道该如何表达,就能让模型输出你想要的确切内容。在之前一篇关于使用 Claude 进行网页抓取的文章中,我使用了下面这个提示:
"""Hello, please parse this chunk of the HTML page and convert it to JSON. Make sure to strip newlines, remove escape characters, and whitespace: {response.text}"""这个提示很清晰,模型知道我要让它干什么。它会把页面中的名言列表提取出来作为 JSON 格式,这里仅贴出一部分:
"quotes": [
{
"text": "The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.",
"author": "Albert Einstein",
"tags": ["change", "deep-thoughts", "thinking", "world"]
},
{
"text": "It is our choices, Harry, that show what we truly are, far more than our abilities.",
"author": "J.K. Rowling",
"tags": ["abilities", "choices"]
},如果我没指定要 JSON 格式,它很可能会给出纯文本。纯文本看起来对人而言很友好,但如果你想编写程序,JSON 更适合处理。之所以能得到这样的 JSON,是因为我在提示时明确告诉模型要输出什么格式。提示工程通过约束生成式输出,让它既真实又井然有序。
零样本学习的挑战与限制
零样本学习也有代价。就像前面提到的,零样本可能会导致幻觉。AI 模型通常不喜欢说“我不知道”或承认自己错了。
为了尽量降低幻觉风险,我们往往依赖大量预训练数据。训练数据成本高昂,而且通常很杂乱。如果你自行采集数据,就需要搭建一个ETL 流程(ETL 代表 Extract, Transfer, Load)。在大规模场景下,这并不轻松。你得抓取 TB 级的相关数据,然后进行清洗和格式化(Transfer),最后再加载到模型里。想进一步了解可以看看开发 AI 模型时的数据陷阱。
在 Bright Data,我们提供干净的现成数据集,可以大幅提升你的预训练效果,同时节省你在数据提取、清洗和格式化上所需的时间。欢迎查看我们的结构化数据集。
结论
零样本学习正在革新 AI,使模型能够在没有先验训练的情况下处理新信息。随着 AI 采用度的不断增高,这项技术将在各行各业中变得更加重要。
准备好使用高质量数据为你的 AI 提供动力了吗?开始使用 Bright Data 的免费试用,获取顶级数据集吧!




