Google Travel 从网络上收集了各种旅行类别的数据(例如 机票、度假套餐和酒店客房等)。寻找酒店往往很困难,其中最大的痛点之一是要在众多广告赞助的列表和与搜索无关的随机房源中进行筛选。
如果你对自行爬取数据不感兴趣,可以看看我们的现成 旅行数据集。通过这些数据集,我们会帮你做好爬取工作。如果你准备自己动手获取数据,请继续阅读!
先决条件
要爬取旅行相关数据,你需要 Python,并且需要安装 Selenium、Requests 或 AIOHTTP 其中之一。使用 Selenium 时,我们会直接从 Google Travel 爬取酒店信息;而使用 Requests 和 AIOHTTP 时,我们将通过 Bright Data 的 Booking.com API 获取数据。
如果你使用 Selenium,必须确保已经安装了 webdriver。如果你对 Selenium 不熟悉,可以先阅读 这篇指南,让你快速上手。
安装 Selenium
pip install selenium安装 Requests
pip install requests安装 AIOHTTP
pip install aiohttp安装完你所选的工具后,就可以开始了。
从 Google Travel 中提取哪些数据
如果你决定手动爬取 Google Travel,就需要先深入了解自己希望获取的数据类型。我们的所有酒店结果都嵌入在 Google Travel 自定义的 c-wiz 元素中。
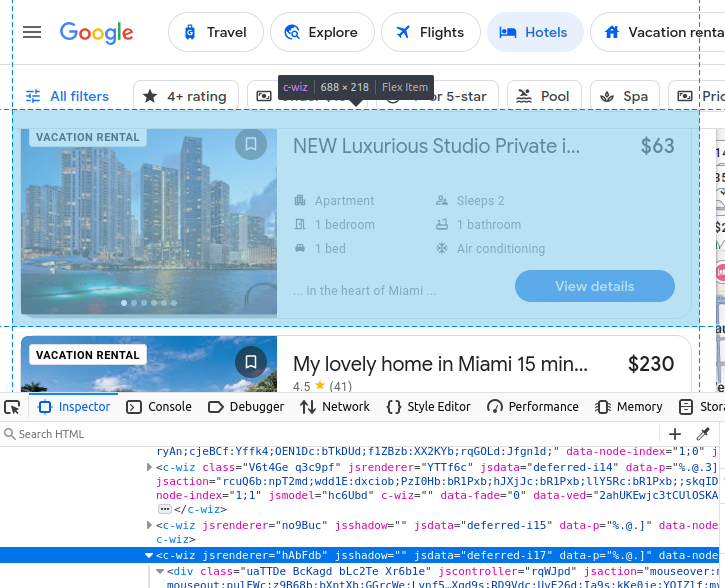
然而,页面上存在多个 c-wiz 元素。每个酒店卡片都包含一个从 div 和该 c-wiz 元素直接继承的 a 元素。我们可以通过编写一个 CSS 选择器来找到所有从这些元素继承的 a 标签:c-wiz > div > a。
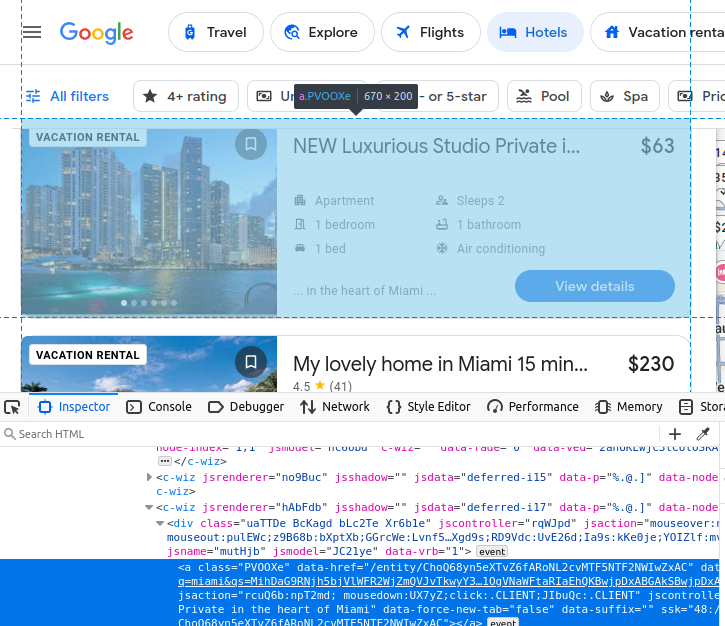
酒店名称嵌在 h2 元素中。
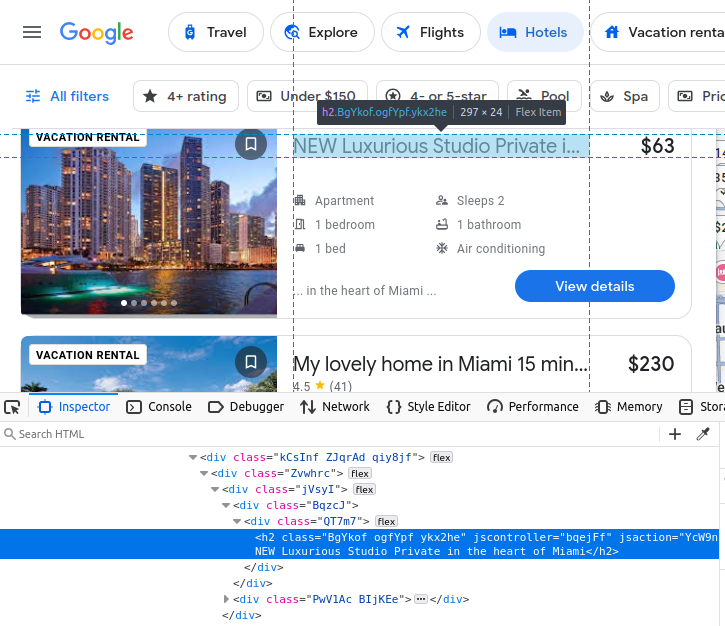
价格嵌在 span 元素中。
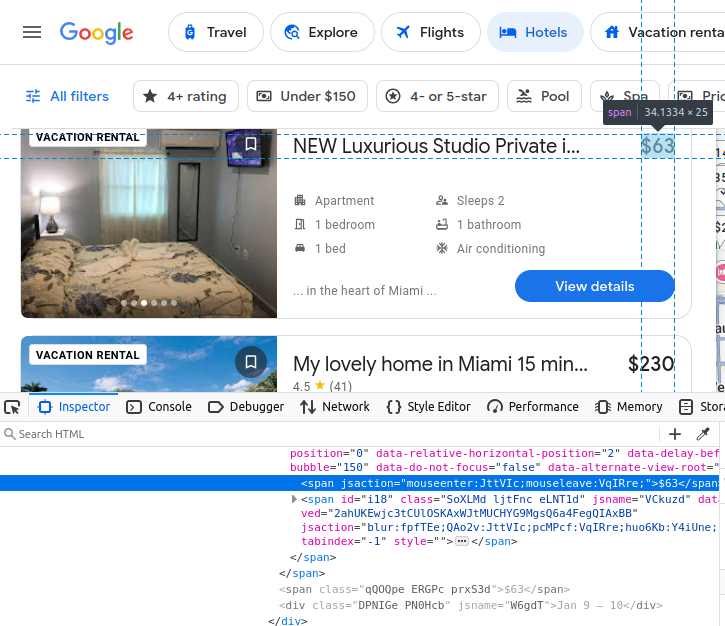
设施(amenities)信息嵌在 li(列表)元素中。
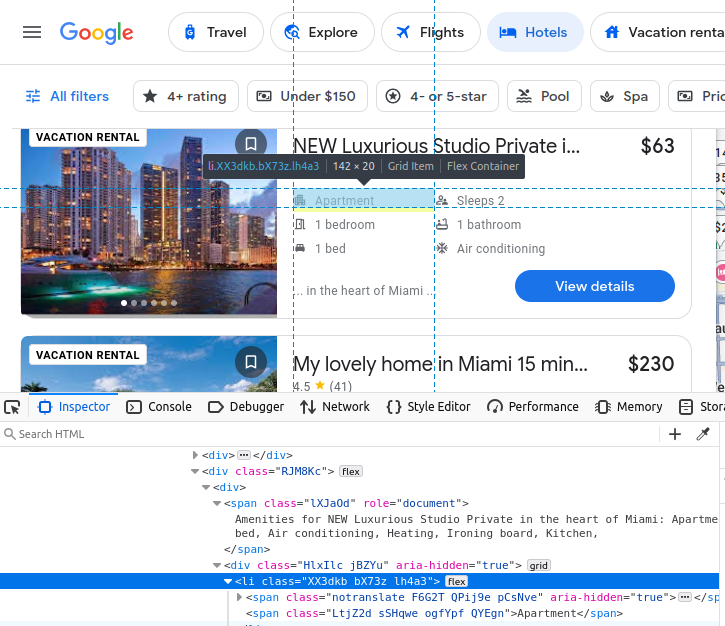
在找到酒店卡片后,就可以从中提取上述所有数据。
使用 Selenium 提取数据
一旦知道应该从哪里获取数据,使用 Selenium 来提取这些信息相对简单。不过,Google Travel 会动态加载结果,因此整个过程有点脆弱,需要预设等待时间、鼠标点击以及自定义窗口来配合。如果没有自定义窗口,页面结果就不会正确加载。
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.common.action_chains import ActionChains
import json
from time import sleep
OPTIONS = webdriver.ChromeOptions()
OPTIONS.add_argument("--headless")
OPTIONS.add_argument("--window-size=1920,1080")
def scrape_hotels(location, pages=5):
driver = webdriver.Chrome(options=OPTIONS)
actions = ActionChains(driver)
url = f"https://www.google.com/travel/search?q={location}"
driver.get(url)
done = False
found_hotels = []
page = 1
result_number = 1
while page <= pages:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
sleep(5)
hotel_links = driver.find_elements(By.CSS_SELECTOR, "c-wiz > div > a")
print(f"-----------------PAGE {page}------------------")
print("FOUND ITEMS: ", len(hotel_links))
for hotel_link in hotel_links:
hotel_card = hotel_link.find_element(By.XPATH, "..")
try:
info = {}
info["url"] = hotel_link.get_attribute("href")
info["rating"] = 0.0
info["price"] = "n/a"
info["name"] = hotel_card.find_element(By.CSS_SELECTOR, "h2").text
price_holder = hotel_card.find_elements(By.CSS_SELECTOR, "span")
info["amenities"] = []
amenities_holders = hotel_card.find_elements(By.CSS_SELECTOR, "li")
for amenity in amenities_holders:
info["amenities"].append(amenity.text)
if "DEAL" in price_holder[0].text or "PRICE" in price_holder[0].text:
if price_holder[1].text[0] == "$":
info["price"] = price_holder[1].text
else:
info["price"] = price_holder[0].text
rating_holder = hotel_card.find_elements(By.CSS_SELECTOR, "span[role='img']")
if rating_holder:
info["rating"] = float(rating_holder[0].get_attribute("aria-label").split(" ")[0])
info["result_number"] = result_number
if info not in found_hotels:
found_hotels.append(info)
result_number+=1
except:
continue
print("Scraped Total:", len(found_hotels))
next_button = driver.find_elements(By.XPATH, "//span[text()='Next']")
if next_button:
print("next button found!")
sleep(1)
actions.move_to_element(next_button[0]).click().perform()
page+=1
sleep(5)
else:
done = True
driver.quit()
with open("scraped-hotels.json", "w") as file:
json.dump(found_hotels, file, indent=4)
if __name__ == "__main__":
PAGES = 2
scrape_hotels("miami", pages=PAGES)
- 首先,我们创建了
ChromeOptions实例,并使用它来添加--headless和--window-size=1920,1080参数。- 如果不设置自定义窗口大小,页面结果无法正确加载,因此会一直重复爬取同样的结果。
- 当我们启动浏览器时,使用
options=OPTIONS这个关键字参数,让浏览器带着我们的自定义选项启动。 ActionChains(driver)给我们一个ActionChains实例。我们稍后用它来将鼠标移动到Next按钮上并执行点击操作。- 我们使用
while循环来管理脚本运行的页数。当我们完成爬取后,就会退出循环。 hotel_links = driver.find_elements(By.CSS_SELECTOR, "c-wiz > div > a")可以获取页面上所有的酒店链接。然后用hotel_link.find_element(By.XPATH, "..")来找到它们的父节点。- 接下来,我们提取之前分析过的每个数据点:
- url:
hotel_link.get_attribute("href") - name:
hotel_card.find_element(By.CSS_SELECTOR, "h2").text - 在查找价格时,卡片中可能还存在
DEAL或GREAT PRICE字样。为了确保能拿到正确的价格,我们把所有span元素提取到一个数组里。如果数组包含这些单词,就使用第二个元素(price_holder[1].text)而不是第一个(price_holder[0].text)。 - 查找评分时也使用
find_elements(),如果没有评分,就设置一个默认值n/a。 hotel_card.find_elements(By.CSS_SELECTOR, "li")获取我们的设施列表,通过amenity.text获取其中的文字。
- url:
- 这个循环会一直进行,直到我们爬完想要获取的所有页面。完成后,我们把
done设置为True并退出循环。 - 最后,我们关闭浏览器,并用
json.dump()将所有获取的数据保存到一个 JSON 文件里。
在爬取 Google Travel 酒店信息时,我们没有遇到任何阻拦,但任何情况都可能发生。如果你确实遇到问题,我们提供 住宅代理,以及内置代理的 Scraping Browser 来帮助你绕过可能的阻碍。
用 Selenium 来抓取这些结果既琐碎又容易出错,但可行。
使用 Bright Data 的 Travel API 来提取数据
有时,你可能并不想依赖一个爬虫,或者不想花整天时间来处理选择器。没问题!我们提供多种 旅行相关数据。你甚至可以使用我们的 Booking.com API 来获取酒店数据。只需要发几个 HTTP 请求,其余的事情都由我们来处理,你就能轻松获取数据。
Requests
下面的示例向你展示如何通过 Booking.com API 获取数据。只需要填写你的 API 密钥、目的地、入住和退房日期。它会先向 API 发起请求生成数据,然后每隔 10 秒轮询一次,直到报告准备就绪。数据准备好后,就会被保存为 JSON 文件。
import requests
import json
import time
def get_bookings(api_key, location, dates):
url = "https://api.brightdata.com/datasets/v3/trigger"
#booking.com dataset
dataset_id = "gd_m4bf7a917zfezv9d5"
endpoint = f"{url}?dataset_id={dataset_id}&include_errors=true"
auth_token = api_key
#
headers = {
"Authorization": f"Bearer {auth_token}",
"Content-Type": "application/json"
}
payload = [
{
"url": "https://www.booking.com",
"location": location,
"check_in": dates["check_in"],
"check_out": dates["check_out"],
"adults": 2,
"rooms": 1
}
]
response = requests.post(endpoint, headers=headers, json=payload)
if response.status_code == 200:
print("Request successful. Response:")
print(json.dumps(response.json(), indent=4))
return response.json()["snapshot_id"]
else:
print(f"Error: {response.status_code}")
print(response.text)
def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file="snapshot-data.json"):
#create the snapshot url
snapshot_url = f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"Polling snapshot for ID: {snapshot_id}...")
while True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("Snapshot is ready. Downloading...")
snapshot_data = response.json()
#write the snapshot to a new json file
with open(output_file, "w", encoding="utf-8") as file:
json.dump(snapshot_data, file, indent=4)
print(f"Snapshot saved to {output_file}")
break
elif response.status_code == 202:
print("Snapshot is not ready yet. Retrying in 10 seconds...")
else:
print(f"Error: {response.status_code}")
print(response.text)
break
time.sleep(10)
if __name__ == "__main__":
API_KEY = "your-bright-data-api-key"
LOCATION = "Miami"
CHECK_IN = "2026-02-01T00:00:00.000Z"
CHECK_OUT = "2026-02-02T00:00:00.000Z"
DATES = {
"check_in": CHECK_IN,
"check_out": CHECK_OUT
}
snapshot_id = get_bookings(API_KEY, LOCATION, DATES)
poll_and_retrieve_snapshot(API_KEY, snapshot_id)
get_bookings()函数接收API_KEY、LOCATION和DATES,向 API 发起数据请求并返回snapshot_id。snapshot_id非常重要,我们需要用它来检索快照数据。- 在成功生成
snapshot_id后,poll_and_retrieve_snapshot()函数每隔 10 秒检查一次数据是否就绪。 - 一旦数据就绪,我们使用
json.dump()将其保存到 JSON 文件中。
运行代码后,你应该能在终端里看到类似于以下的输出:
Request successful. Response:
{
"snapshot_id": "s_m5moyblm1wikx4ntot"
}
Polling snapshot for ID: s_m5moyblm1wikx4ntot...
Snapshot is not ready yet. Retrying in 10 seconds...
Snapshot is not ready yet. Retrying in 10 seconds...
Snapshot is not ready yet. Retrying in 10 seconds...
Snapshot is not ready yet. Retrying in 10 seconds...
Snapshot is ready. Downloading...
Snapshot saved to snapshot-data.json
然后,你会得到一个包含类似以下对象的 JSON 文件:
{
"input": {
"url": "https://www.booking.com",
"location": "Miami",
"check_in": "2026-02-01T00:00:00.000Z",
"check_out": "2026-02-02T00:00:00.000Z",
"adults": 2,
"rooms": 1
},
"url": "https://www.booking.com/hotel/us/ramada-plaze-by-wyndham-marco-polo-beach-resort.html?checkin=2025-02-01&checkout=2025-02-02&group_adults=2&no_rooms=1&group_children=",
"location": "Miami",
"check_in": "2026-02-01T00:00:00.000Z",
"check_out": "2026-02-02T00:00:00.000Z",
"adults": 2,
"children": null,
"rooms": 1,
"id": "55989",
"title": "Ramada Plaza by Wyndham Marco Polo Beach Resort",
"address": "19201 Collins Avenue",
"city": "Sunny Isles Beach (Florida)",
"review_score": 6.2,
"review_count": "1788",
"image": "https://cf.bstatic.com/xdata/images/hotel/square600/414501733.webp?k=4c14cb1ec5373f40ee83d901f2dc9611bb0df76490f3673f94dfaae8a39988d8&o=",
"final_price": 217,
"original_price": 217,
"currency": "USD",
"tax_description": null,
"nb_livingrooms": 0,
"nb_kitchens": 0,
"nb_bedrooms": 0,
"nb_all_beds": 2,
"full_location": {
"description": "This is the straight-line distance on the map. Actual travel distance may vary.",
"main_distance": "11.4 miles from downtown",
"display_location": "Miami Beach",
"beach_distance": "Beachfront",
"nearby_beach_names": []
},
"no_prepayment": false,
"free_cancellation": true,
"property_sustainability": {
"is_sustainable": false,
"level_id": "L0",
"facilities": [
"436",
"490",
"492",
"496",
"506"
]
},
"timestamp": "2026-01-07T16:43:24.954Z"
},
AIOHTTP
使用 AIOHTTP 可以大幅提升这种数据获取流程的效率。事实上,我们可以同时触发、轮询并下载多个数据集。下面的示例基于 Requests 中的概念,但使用强大的 aiohttp.ClientSession() 来进行异步请求。
import aiohttp
import asyncio
import json
async def get_bookings(api_key, location, dates):
url = "https://api.brightdata.com/datasets/v3/trigger"
dataset_id = "gd_m4bf7a917zfezv9d5"
endpoint = f"{url}?dataset_id={dataset_id}&include_errors=true"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
payload = [
{
"url": "https://www.booking.com",
"location": location,
"check_in": dates["check_in"],
"check_out": dates["check_out"],
"adults": 2,
"rooms": 1
}
]
async with aiohttp.ClientSession(headers=headers) as session:
async with session.post(endpoint, json=payload) as response:
if response.status == 200:
response_data = await response.json()
print(f"Request successful for location: {location}. Response:")
print(json.dumps(response_data, indent=4))
return response_data["snapshot_id"]
else:
print(f"Error for location: {location}. Status: {response.status}")
print(await response.text())
return None
async def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file):
snapshot_url = f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"Polling snapshot for ID: {snapshot_id}...")
async with aiohttp.ClientSession(headers=headers) as session:
while True:
async with session.get(snapshot_url) as response:
if response.status == 200:
print(f"Snapshot for {output_file} is ready. Downloading...")
snapshot_data = await response.json()
# Save snapshot data to a file
with open(output_file, "w", encoding="utf-8") as file:
json.dump(snapshot_data, file, indent=4)
print(f"Snapshot saved to {output_file}")
break
elif response.status == 202:
print(f"Snapshot for {output_file} is not ready yet. Retrying in 10 seconds...")
else:
print(f"Error polling snapshot for {output_file}. Status: {response.status}")
print(await response.text())
break
await asyncio.sleep(10)
async def process_location(api_key, location, dates):
snapshot_id = await get_bookings(api_key, location, dates)
if snapshot_id:
output_file = f"snapshot-{location.replace(' ', '_').lower()}.json"
await poll_and_retrieve_snapshot(api_key, snapshot_id, output_file)
async def main():
api_key = "your-bright-data-api-key"
locations = ["Miami", "Key West"]
dates = {
"check_in": "2026-02-01T00:00:00.000Z",
"check_out": "2026-02-02T00:00:00.000Z"
}
# Process all locations in parallel
tasks = [process_location(api_key, location, dates) for location in locations]
await asyncio.gather(*tasks)
if __name__ == "__main__":
asyncio.run(main())
get_bookings()和poll_and_retrieve_snapshot()都使用aiohttp.ClientSession对象来异步向服务器发送请求。process_location()用于处理某个地点的数据。main()则能够同时对多个地点调用process_location()。
借助 AIOHTTP,你可以同时触发、轮询并下载多个数据集,而无需等待一个报告完成后再去生成下一个。
看看输出日志,你可以看到我们同时触发了两个地点的数据获取。同时在等待的过程中,一个数据集完成后开始下载,而另一个还在等待。规模化运行时,这能大大节省时间。
Request successful for location: Miami. Response:
{
"snapshot_id": "s_m5mtmtv62hwhlpyazw"
}
Request successful for location: Key West. Response:
{
"snapshot_id": "s_m5mtmtv72gkkgxvdid"
}
Polling snapshot for ID: s_m5mtmtv62hwhlpyazw...
Polling snapshot for ID: s_m5mtmtv72gkkgxvdid...
Snapshot for snapshot-miami.json is not ready yet. Retrying in 10 seconds...
Snapshot for snapshot-key_west.json is not ready yet. Retrying in 10 seconds...
Snapshot for snapshot-key_west.json is not ready yet. Retrying in 10 seconds...
Snapshot for snapshot-miami.json is not ready yet. Retrying in 10 seconds...
Snapshot for snapshot-key_west.json is not ready yet. Retrying in 10 seconds...
Snapshot for snapshot-miami.json is not ready yet. Retrying in 10 seconds...
Snapshot for snapshot-miami.json is ready. Downloading...
Snapshot for snapshot-key_west.json is not ready yet. Retrying in 10 seconds...
Snapshot saved to snapshot-miami.json
Snapshot for snapshot-key_west.json is not ready yet. Retrying in 10 seconds...
Snapshot for snapshot-key_west.json is not ready yet. Retrying in 10 seconds...
Snapshot for snapshot-key_west.json is not ready yet. Retrying in 10 seconds...
Snapshot for snapshot-key_west.json is ready. Downloading...
Snapshot saved to snapshot-key_west.json
Bright Data 的其他解决方案
除了功能强大的 Web Scraper APIs,Bright Data 还提供多种现成数据集,可满足不同需求。在我们最受欢迎的 旅行数据集中,包含:
通过 Bright Data,你可以从完全托管或自定义管理模式中进行选择,自由地从任意公开网站中提取数据,并将数据定制成满足你确切需求的格式。
总结
在网站上进行数据爬取时,Google Travel 可以为你提供大量的酒店信息。无论你喜欢用 Selenium 自己动手,还是希望通过 Booking.com API 来快速获取数据,这些方式都能让你收集到有价值的信息。无论是想要分析历史价格,还是想更高效地订房,你现在都掌握了另一项很有用的技能!
立即注册,免费试用 Bright Data 的产品吧。



技术写作者
 6 years experience
6 years experience
Jacob Nulty 是一位常驻底特律的软件开发者和技术写作者,探索人工智能与人类哲学,具备 Python、Rust 和区块链方面的经验。