

Google 航班 是一项广泛使用的航班预订服务,可提供丰富的数据,包括航班价格、时刻表和航空公司详细信息。遗憾的是,Google 没有提供访问这些数据的公共 API。不过,网页抓取可以成为提取这些数据的不错选择。
在本文中,我将向您展示如何使用 Python 构建一个强大的 Google 航班抓取工具。我们将仔细检查每一个步骤,确保一切都清晰明了。
为什么要抓取 Google 航班数据?
抓取 Google 航班有多种好处,包括:
- 追踪航班价格的变化
- 分析价格趋势
- 确定预订航班的最佳时间
- 比较不同日期和航空公司的价格
对于旅行者来说,这样可以找到最实惠的价格并省钱。对于企业而言,它有助于市场分析、竞争情报和制定有效的定价策略。
构建 Google 航班抓取工具
我们构建的抓取工具将允许您输入详细信息,例如出发机场、目的地、旅行日期和机票类型(单程或往返)。如果您预订往返行程,则还需要提供回程日期。其余的工作将由抓取工具处理:它加载所有可用的航班,抓取数据,并将结果保存在 JSON 文件中以供进一步分析。
如果您是使用 Python 进行网页抓取的新手,可以查看本 教程 以开始使用。
1.您可以从 Google 航班中提取哪些数据?
Google 航班提供大量数据,包括航空公司名称、出发和到达时间、总时长、停靠次数、机票价格和环境影响数据(例如二氧化碳排放量)。
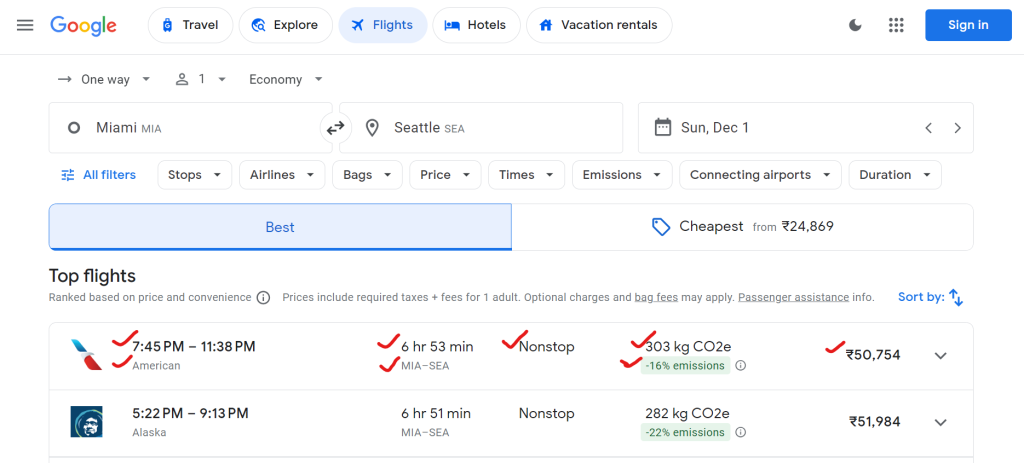
以下是可以抓取的数据示例:
{
"airline": "Alaska",
"departure_time": "5:22 PM",
"arrival_time": "9:13 PM",
"duration": "6 hr 51 min",
"stops": "Nonstop",
"price": "₹51,984",
"co2_emissions": "282 kg CO2e",
"emissions_variation": "-22% emissions"
}
2.设置环境
首先,让我们在系统中设置运行抓取工具的环境。
# Create a virtual environment (optional)
python -m venv flight-scraper-env
# Activate the virtual environment
# On Windows:
.\flight-scraper-env\Scripts\activate
# On macOS/Linux:
source flight-scraper-env/bin/activate
# Install required packages
pip install playwright tenacity asyncio
# Install Playwright browsers
playwright install chromium
Playwright 非常适合自动化浏览器以及与动态网页(例如 Google 航班)进行交互。我们使用 Tenacity 来实现重试机制。
如果您是 Playwright 新手,一定要查看 Playwright 网页抓取指南。
3.定义数据类
使用 Python的 数据类,您可以巧妙地组织搜索参数和航班数据。
from dataclasses import dataclass
from typing import Optional
@dataclass
class SearchParameters:
departure: str
destination: str
departure_date: str
return_date: Optional[str] = None
ticket_type: str = "One way"
@dataclass
class FlightData:
airline: str
departure_time: str
arrival_time: str
duration: str
stops: str
price: str
co2_emissions: str
emissions_variation: str
其中, SearchParameters (搜索参数)类存储航班搜索详细信息,如出发地、目的地、日期和机票类型,而 FlightData (航班数据)类存储有关每个航班的数据,包括航空公司、价格、二氧化碳排放量和其他相关详细信息。
4.FlightScraper 类中的抓取工具逻辑
主要的抓取逻辑封装在 FlightScraper 类中。以下是详细的分类:
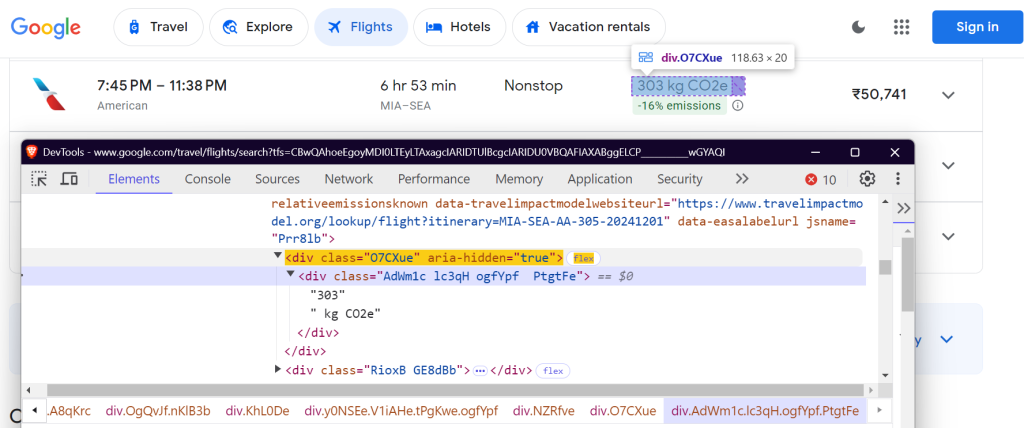
4.1 定义 CSS 选择器
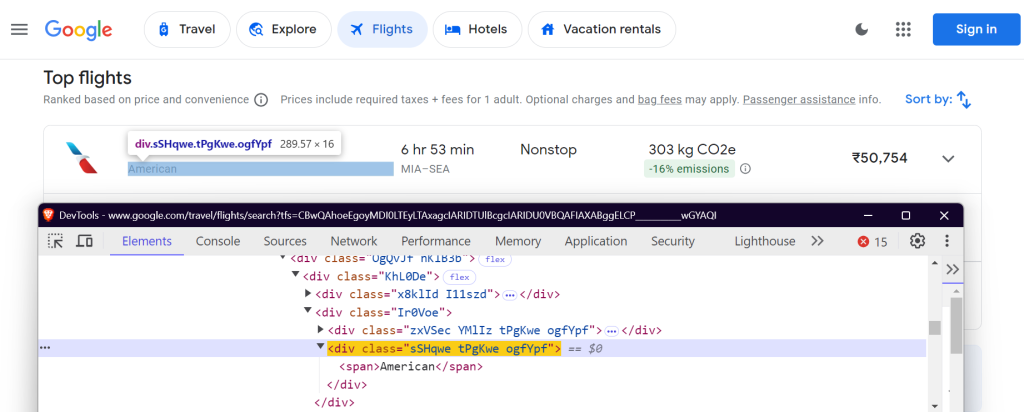
您需要在 Google 航班页面上找到特定元素才能提取数据。这是使用 CSS 选择器完成的。以下是 FlightScraper 类中选择器的定义方式:
class FlightScraper:
SELECTORS = {
"airline": "div.sSHqwe.tPgKwe.ogfYpf",
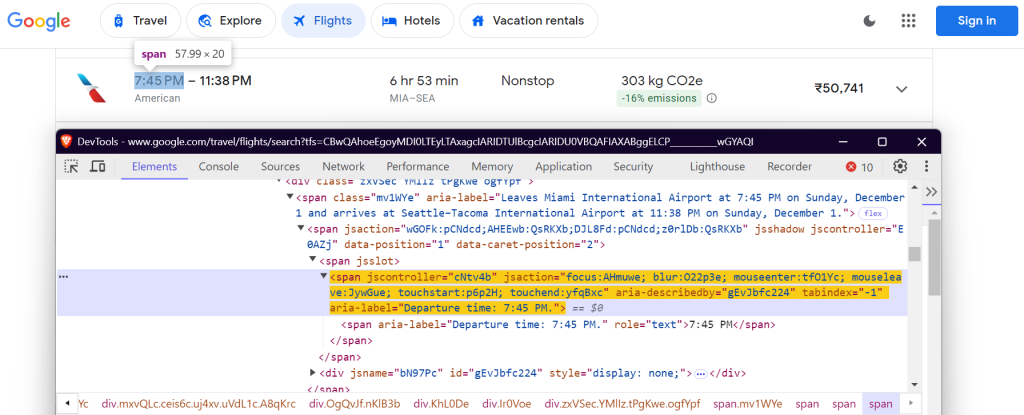
"departure_time": 'span[aria-label^="Departure time"]',
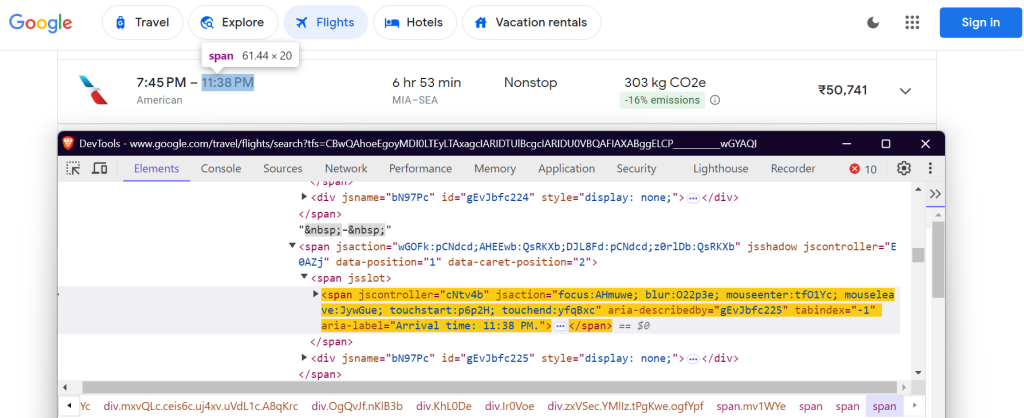
"arrival_time": 'span[aria-label^="Arrival time"]',
"duration": 'div[aria-label^="Total duration"]',
"stops": "div.hF6lYb span.rGRiKd",
"price": "div.FpEdX span",
"co2_emissions": "div.O7CXue",
"emissions_variation": "div.N6PNV",
}
这些选择器的目标是航空公司名称、航班时刻、时长、停靠点、价格和排放数据。
航空公司名称
出发时间:
到达时间:
航班时长:
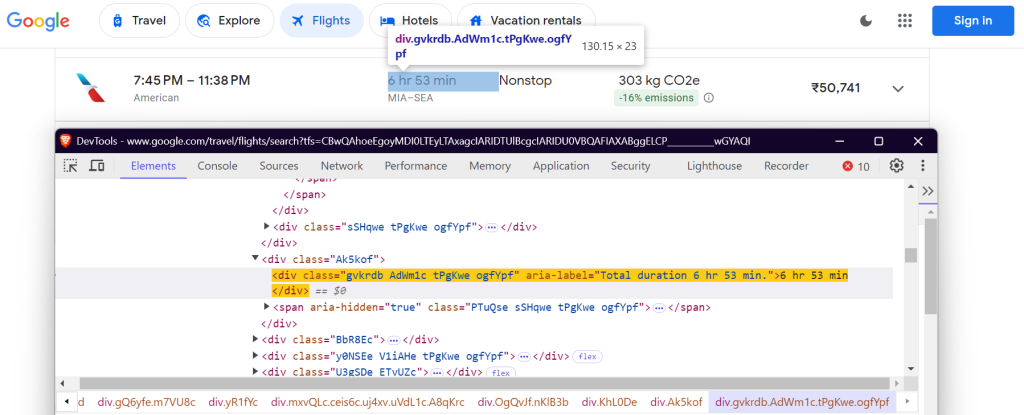
停靠次数:
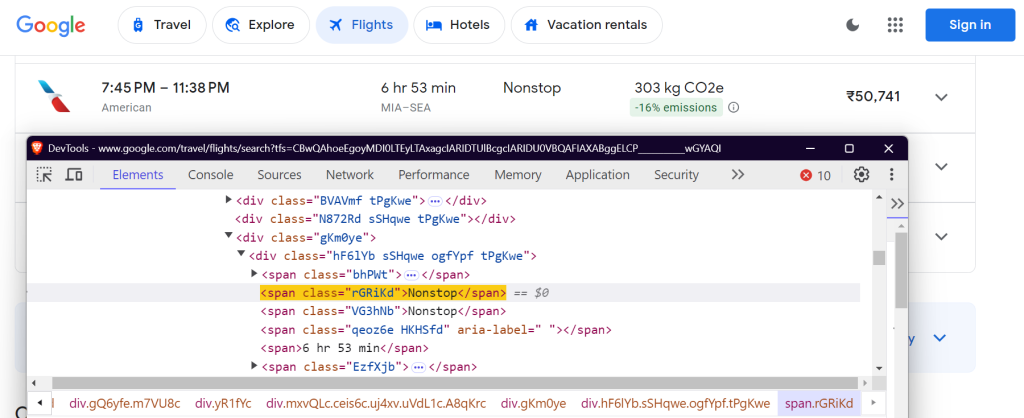
价格:
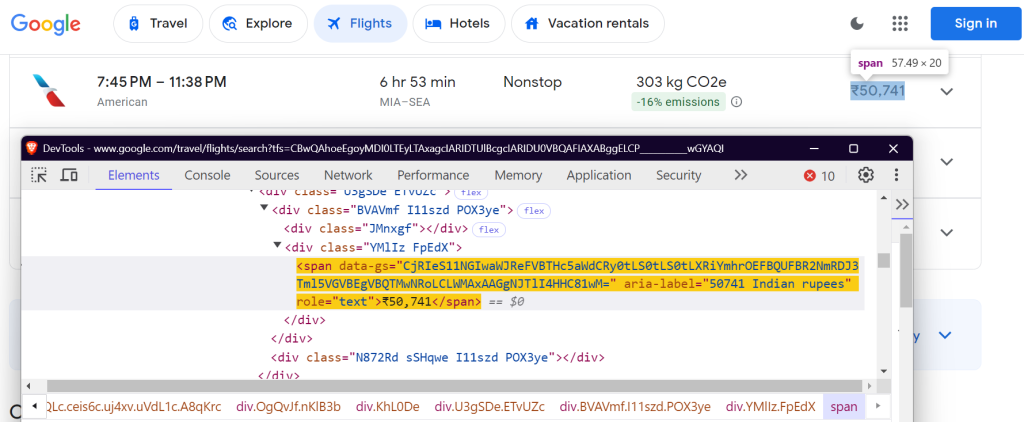
二氧化碳当量:
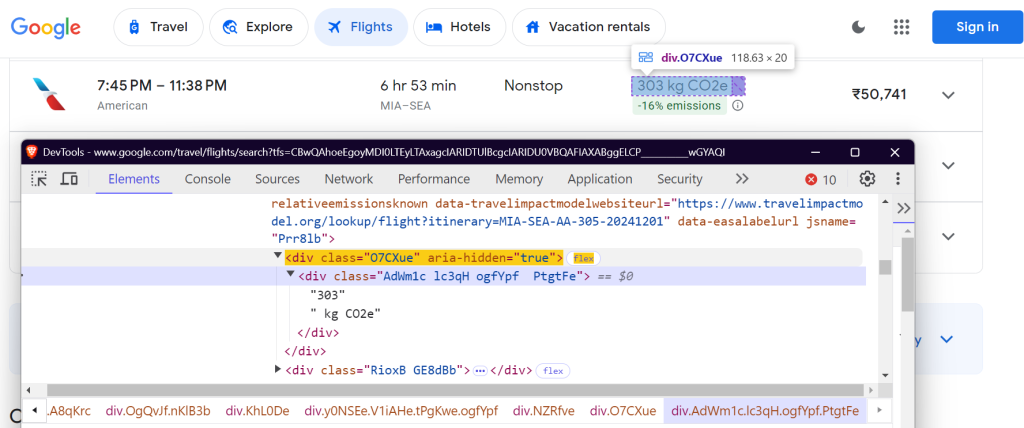
二氧化碳排放量变化:
4.2 填写搜索表单
_fill_search_form 方法模拟填写包含出发地、目的地和日期详细信息的搜索表单:
async def _fill_search_form(self, page, params: SearchParameters) -> None:
# First, let's pick our ticket type
ticket_type_div = page.locator("div.VfPpkd-TkwUic[jsname='oYxtQd']").first
await ticket_type_div.click()
await page.wait_for_selector("ul[aria-label='Select your ticket type.']")
await page.locator("li").filter(has_text=params.ticket_type).nth(0).click()
# Now, let's fill in our departure and destination
from_input = page.locator("input[aria-label='Where from?']")
await from_input.click()
await from_input.fill("")
await page.keyboard.type(params.departure)
# ... rest of the form filling code
4.3 加载所有结果
Google 航班使用分页来加载航班。您需要点击“显示更多航班”按钮来加载所有可用航班:
async def _load_all_flights(self, page) -> None:
while True:
try:
more_button = await page.wait_for_selector(
'button[aria-label*="more flights"]', timeout=5000
)
if more_button:
await more_button.click()
await page.wait_for_timeout(2000)
else:
break
except:
break
4.4 提取航班数据
航班加载完毕后,您可以抓取航班详细信息:
async def _extract_flight_data(self, page) -> List[FlightData]:
await page.wait_for_selector("li.pIav2d", timeout=30000)
await self._load_all_flights(page)
flights = await page.query_selector_all("li.pIav2d")
flights_data = []
for flight in flights:
flight_info = {}
for key, selector in self.SELECTORS.items():
element = await flight.query_selector(selector)
flight_info[key] = await self._extract_text(element)
flights_data.append(FlightData(**flight_info))
return flights_data
5.添加重试机制
为了使我们的抓取工具更可靠,请使用 tenacity 库添加重试逻辑:
@retry(stop=stop_after_attempt(3), wait=wait_fixed(5))
async def search_flights(self, params: SearchParameters) -> List[FlightData]:
async with async_playwright() as p:
browser = await p.chromium.launch(headless=False)
context = await browser.new_context(
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) ..."
)
# ... rest of the search implementation
6.保存抓取的结果
将抓取的航班数据保存到 JSON 文件中以供将来分析。
def save_results(self, flights: List[FlightData], params: SearchParameters) -> str:
timestamp = datetime.now().strftime("%Y%m%d_%H%M%S")
filename = (
f"flight_results_{params.departure}_{params.destination}_{timestamp}.json"
)
output_data = {
"search_parameters": {
"departure": params.departure,
"destination": params.destination,
"departure_date": params.departure_date,
"return_date": params.return_date,
"search_timestamp": timestamp,
},
"flights": [vars(flight) for flight in flights],
}
filepath = os.path.join(self.results_dir, filename)
with open(filepath, "w", encoding="utf-8") as f:
json.dump(output_data, f, indent=2, ensure_ascii=False)
return filepath
7.运行抓取工具
以下是运行 Google 航班抓取工具的方法:
async def main():
scraper = FlightScraper()
params = SearchParameters(
departure="MIA",
destination="SEA",
departure_date="2024-12-01",
# return_date="2024-12-30",
ticket_type="One way",
)
try:
flights = await scraper.search_flights(params)
print(f"Successfully found {len(flights)} flights")
except Exception as e:
print(f"Error during flight search: {str(e)}")
if __name__ == "__main__":
asyncio.run(main())
最终结果
运行抓取工具后,您的航班数据将保存在如下所示的 JSON 文件中:
{
"search_parameters": {
"departure": "MIA",
"destination": "SEA",
"departure_date": "2024-12-01",
"return_date": null,
"search_timestamp": "20241027_172017"
},
"flights": [
{
"airline": "American",
"departure_time": "7:45 PM",
"arrival_time": "11:38 PM",
"duration": "6 hr 53 min",
"stops": "Nonstop",
"price": "₹50,755",
"co2_emissions": "303 kg CO2e",
"emissions_variation": "-16% emissions"
},
{
"airline": "Alaska",
"departure_time": "5:22 PM",
"arrival_time": "9:13 PM",
"duration": "6 hr 51 min",
"stops": "Nonstop",
"price": "₹51,984",
"co2_emissions": "282 kg CO2e",
"emissions_variation": "-22% emissions"
},
{
"airline": "Alaska",
"departure_time": "9:00 AM",
"arrival_time": "12:40 PM",
"duration": "6 hr 40 min",
"stops": "Nonstop",
"price": "₹62,917",
"co2_emissions": "325 kg CO2e",
"emissions_variation": "-10% emissions"
}
]
}
您可以在我的 GitHub Gist中找到完整的代码。
扩大 Google 航班数据抓取规模时的常见挑战
在扩大 Google 航班数据抓取规模时,诸如 IP 封锁 和 验证码 之类的挑战很常见。例如,如果您使用抓取工具在短时间内发送过多请求,则网站可能会封锁您的 IP 地址。为避免这种情况,您可以使用手动 IP 轮换,也可以选择一项 顶级代理服务。如果您不确定哪种代理类型最适合您的用例,请查看我们关于 网页抓取最佳代理的指南。
另一个挑战是处理验证码。网站在怀疑有机器人流量时通常会使用验证码,在解析出验证码之前封锁您的抓取工具。手动处理此问题既耗时又复杂。
那么,解决方案是什么?接下来,我们深入探讨一下!
解决方案:Bright Data 网页抓取工具
Bright Data 提供了一系列解决方案,旨在高效简化和规模化您的网页抓取工作。让我们探讨 Bright Data 如何帮助您克服这些常见挑战。
1. 住宅代理
Bright Data 的 住宅代理 使您能够访问和抓取复杂的目标网站。住宅代理可通过合法的住宅连接传递网页抓取请求。目标网站会认为您的请求来自特定地区或区域的真实用户。因此,您可以使用此类代理有效访问受到基于 IP 的反抓取措施保护的页面。
2. 网页解锁器
Bright Data 的 网页解锁器 非常适合抓取出现验证码或限制的项目。网页解锁器并非手动处理这些问题,而是进行自动处理,适应不断变化的网站封锁,成功率很高(通常为 100%)。您只需发送一个请求,剩下的交由网页解锁器处理即可。
3. 抓取浏览器
Bright Data 的 抓取浏览器 对于使用 Puppeteer 或 Playwright等无头浏览器的开发人员来说是另一款强大的工具。与传统的无头浏览器不同,抓取浏览器可以自动处理验证码解析、浏览器指纹识别、重试等操作,因此您可以专注于收集数据,而不必担心网站限制。
结论
本文探讨了如何使用 Python 和 Playwright 抓取 Google 航班数据。尽管手动抓取可能有效,但它通常会带来诸如 IP 禁令和持续脚本维护之类的挑战。为了简化和增强您的数据收集工作,可以考虑利用 Bright Data 的解决方案,例如住宅代理、网页解锁器和抓取浏览器。
立即注册 即可免费试用 Bright Data!
此外,请浏览我们关于抓取其他 Google 服务的指南,例如 Google 搜索结果数据、 Google 趋势、 Google 学术和 Google 地图。


