

如果没有嵌入,AI 行业以及整个科技领域几乎会面目全非。大型语言模型(LLMs)将无法理解你的意图,搜索引擎也不知道你要查找什么,其他所有推荐系统只会输出随机的无用信息。
跟随本文的思路,我们将一起探索嵌入的工作原理以及它们在机器学习中的重要性。
什么是嵌入?
机器并不理解文字,但它们能理解数字。无论你使用何种编程语言编写代码,这些代码最终都会转化为机器可理解的二进制或十六进制数值格式。
在 AI(尤其是机器学习)领域,模型需要“理解”信息,而嵌入正是实现这一点的关键。通过嵌入,我们可以将文字、图像以及任何其他类型的信息转化为机器可读的数字形式,从而让 AI 能够发现模式、关系和含义。
机器理解数字而不是文字。嵌入就是在人与 AI 之间搭建的一座桥梁。
为什么嵌入很重要?
想象一下,如果你想搜索披萨店,却得到的是墨西哥卷饼的推荐;或者当你在做网络爬取时,想让ChatGPT或Claude提供 Python 提示,结果却得到如何照顾蚺蛇(python)宠物的指南!
嵌入让模型能够理解你的意图。没有它们,大部分系统只能依靠与数据库中完全匹配的文本来进行查询。
- 搜索引擎:嵌入可帮助谷歌准确理解你的搜索意图。
- LLMs:通过嵌入,这些模型能够理解你真正想表达的内容。否则它们无法捕捉你的意义—还记得那个 Python 示例吗?
- 推荐系统:Netflix 等公司会使用嵌入结合过滤和其他方法,为你推荐真正感兴趣的节目。
嵌入不仅让机器能够读取数据,还能真正理解数据。
向量:嵌入的语言
从最简单的形式来看,向量就是一个列表。想象一下,你想表示一系列笔记本电脑。每台笔记本都有操作系统(OS)、CPU 制造商、处理器核心数以及内存大小等信息。
如果我们有两台笔记本,它们可能像下面这样表示。
- Windows 笔记本:
["Windows", "Intel", 4, "8"] - Chromebook:
["ChromeOS", "Mediatek", 8, "4"]
矩阵:将向量组合成表格
矩阵是列表的列表。从严格的技术角度看,它是“向量的向量”,但就像我们之前所说,向量本质上就是一个列表。我们人类在查看矩阵时,会把它视作一个表格。
下面是我们人类可读的矩阵。
| 操作系统(OS) | CPU 制造商 | 处理器核心数 | 内存 (GB) |
|---|---|---|---|
| Windows | Intel | 4 | 8 |
| ChromeOS | Mediatek | 8 | 4 |
我们的矩阵是一个向量的向量(列表的列表)。可以看到,这种结构对人类阅读略显复杂,但仍可理解。对机器而言,这要比上面的表格更易读,不过还没有达到最佳的机器可读性。
[
["Windows", "Intel", 4, 8],
["ChromeOS", "Mediatek", 8, 4]
]要真正让机器可读,我们需要用数字来替换文字。将每个非数字特征都分配一个对应的数值标识。
操作系统(OS)
- Windows: 0
- ChromeOS: 1
CPU 制造商:
- Intel: 0
- Mediatek: 1
此时,我们的“表格”对人类而言几乎失去了可读性,但机器却能非常好地处理这些数据,并有效地寻找不同条目之间的关系。
[
[0, 0, 4, 8],
[1, 1, 8, 4]
]这对机器来说是再好不过的格式。机器不读取文字,但能在数字中发现模式。以这种形式,模型可以有效地分析数据并寻找模式。
嵌入的工作原理
嵌入远不止上面演示的简单数值编码。它可以把大规模数据转化成更加复杂的矩阵,人类若不进行深入分析,很难去理解这些矩阵表示的含义。
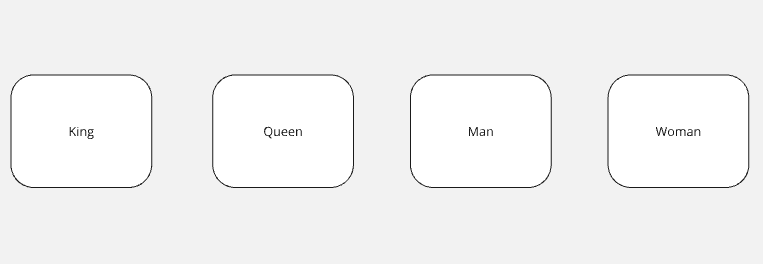
有了嵌入,AI 可以实际分析这些数据并使用各种公式来查找关系。例如,King(国王) 和 Queen(王后)是相似的概念,它们的向量也会彼此接近,因为它们含义几乎相同。
通过向量,我们甚至可以进行数学运算,而机器在这方面比人类要强得多。机器或许会用以下公式来表征它们之间的关系:
King - Man + Woman = Queen
有监督与无监督嵌入
嵌入主要有两种类型:有监督和无监督。
有监督嵌入

如果我们在带有标签与映射的结构化数据上训练模型,这称为有监督学习(Supervised Learning),它所生成的嵌入就是有监督嵌入。模型从人类那里得到明确指导。
常见用例
- 电子邮件:某些类型的邮件被标记为垃圾邮件或非垃圾邮件。
- 图像:模型在已标注的猫与狗的图片上进行了训练。
在有监督嵌入中,人类对模式已经有所了解,并将这些模式直接传授给机器。
无监督嵌入

无监督嵌入则是非结构化且无标签的数据。模型会扫描海量数据,然后将常常一起出现的文字或字符聚合到一起。这样,模型可以自主发现模式,而不是通过人类直接教授。随着对模式累积的理解,模型就能进行预测。
常见用例
- LLMs:大型语言模型会扫描大量文本数据,准确预测这些词汇如何组合。
- 自动补全和拼写检查:这是上述概念的更初级形式,旨在准确预测构成单词的字符。
嵌入是如何创建的
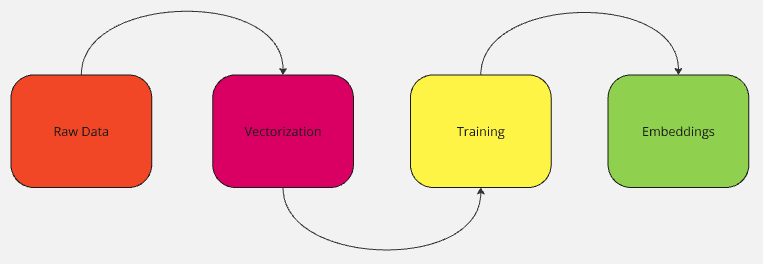
嵌入并不只是由人指定,而是通过“学习”得来的。要学习相似性、模式并最终发现关系,模型需要在大量数据上进行训练。
步骤 1:收集数据
模型需要一个庞大的训练数据集。如果你使用维基百科来训练模型,模型便会学习到维基百科中的知识点,并以类似维基百科的风格对话。我们的 网络抓取 API 能帮助你实时提取高质量数据。
你几乎可以用任何类型的数据来训练模型:
- 文本:书籍、PDF、网站等。
- 图像:带标签的图像、像素之间的关系。
- 用户交互:产品推荐、浏览器行为等。
步骤 2:将数据转化为向量
如前所述,机器并不擅长处理人类可读的数据。因此,之前收集到的数据需要转化为数值向量。
编码方式主要有两种:
- 独热编码(One-Hot Encoding):这是一种较为基础的方式,无法捕捉数据之间的关系。
- 密集嵌入(Dense Embeddings):这在现代 AI 中更为常见,彼此相关性较高的对象(如 King 和 Queen)会在向量空间中互相靠近。
步骤 3:训练模型
为了创建嵌入,模型会使用以下类似的方法来进行机器学习:
- 词共现(Word2Vec,GloVe)
- 模型会扫描海量文本以分析并学习词汇之间的关系。
- 在相似上下文中出现的词会在向量空间中彼此靠近。
- “Paris” 与 “France” 在向量空间中会比“Pizza”更接近。
- 上下文学习(BERT,GPT)
- Transformer 模型旨在理解完整句子的上下文。
- 模型可以根据上下文抓取单词的多重含义。
- “River bank” 跟 “money in the bank” 在含义上完全不同,Transformer 模型能理解这种差异。
步骤 4:微调
一旦模型训练完成,就需要进行微调。所谓微调,就是根据特定任务对嵌入进行进一步的调整:
- 搜索引擎会针对查询理解进行嵌入微调。
- 推荐系统通常会根据用户行为来调整其嵌入。
- LLMs 则需要定期微调,以便在新数据上更新其嵌入参数。
结论
嵌入不仅仅在当代 AI 行业中至关重要,更是整个科技行业的基石。从搜索结果到大型语言模型,都离不开它们。通过我们的数据集,你可以获取海量高质量数据来训练你的模型。
立即注册,开启你的免费试用,包括数据集示例。



