

维基百科是一个内容庞大且全面的信息来源,涵盖了数百万篇几乎关于所有主题的文章。对于研究人员、数据科学家以及开发者而言,这些数据蕴含了无数机会,从构建机器学习数据集到开展学术研究都可以使用。在本文中,我们将一步步向你展示如何抓取维基百科的数据。
使用 Bright Data Wikipedia Scraper API
如果你希望高效地从维基百科中提取数据,那么 Bright Data Wikipedia Scraper API 是一个比手动方式更好的选择。这个功能强大的 API 可以自动化整个爬取流程,从而更轻松地收集到海量信息。
主要使用场景:
- 收集各种主题的解释性文本
- 对比维基百科与其他数据源的信息
- 使用大规模数据集进行研究
- 从维基百科公有领域(Wikipedia Commons)抓取图片
你可以将数据导出为 JSON、CSV 或 .gz 等格式,并支持多种数据传输方式,包括 Amazon S3、Google Cloud Storage 及 Microsoft Azure 等。
只需 一次 API 调用,就能快速轻松获取到海量数据!
如何使用 Python 爬取维基百科
下面是使用 Python 爬取维基百科的分步骤教程。
1. 环境配置及先决条件
在开始之前,先确保你的开发环境配置妥当:
- 安装 Python:从Python 官网下载并安装最新版 Python。
- 选择一个 IDE:可以使用 PyCharm、Visual Studio Code 或 Jupyter Notebook 等作为开发环境。
- 基础知识:熟悉CSS 选择器,并且能熟练使用浏览器开发者工具(DevTools)来检查页面元素。
如果你是 Python 新手,可以阅读这篇如何用 Python 进行网页爬取的指南,其中包含详细的说明。
接下来,使用 Poetry 创建一个新项目。Poetry 是一个依赖管理工具,它能让你更轻松地管理 Python 包和虚拟环境。
poetry new wikipedia-scraper这条命令将生成以下项目结构:
wikipedia-scraper/
├── pyproject.toml
├── README.md
├── wikipedia_scraper/
│ └── __init__.py
└── tests/
└── __init__.py进入项目目录并安装所需依赖:
cd wikipedia-scraper
poetry add requests beautifulsoup4 pandas lxml首先,BeautifulSoup 用于解析 HTML 和 XML 文档,方便获取页面中所需的元素。requests 库用于发送 HTTP 请求并获取网页内容。Pandas 是一个功能强大的数据处理与分析工具,在处理表格类数据时非常有用。最后,lxml 能加速解析过程,从而提升 BeautifulSoup 的性能。
然后,激活虚拟环境,并用你喜欢的编辑器(这里以 VS Code 为例)打开项目文件夹:
poetry shell
code .打开 pyproject.toml 文件查看项目的依赖,文件内容应类似如下:
[tool.poetry.dependencies]
python = "^3.12"
requests = "^2.32.3"
beautifulsoup4 = "^4.12.3"
pandas = "^2.2.3"
lxml = "^5.3.0"最后,在 wikipedia_scraper 文件夹中创建一个 main.py 文件,用来编写爬虫逻辑。此时你的项目结构应更新为:
wikipedia-scraper/
├── pyproject.toml
├── README.md
├── wikipedia_scraper/
│ ├── __init__.py
│ └── main.py
└── tests/
└── __init__.py至此,环境已就绪,可以开始编写 Python 代码来爬取维基百科了。
2. 连接目标维基百科页面
首先,连接到你想要爬取的维基百科页面。以下示例中,我们将爬取这个 维基百科页面。
以下是一段使用 Python 连接到维基百科页面的简易示例:
import requests # For making HTTP requests
from bs4 import BeautifulSoup # For parsing HTML content
def connect_to_wikipedia(url):
response = requests.get(url) # Send a GET request to the URL
# Check if the request was successful
if response.status_code == 200:
return BeautifulSoup(response.text, "html.parser") # Parse and return the HTML
else:
print(f"Failed to retrieve the page. Status code: {response.status_code}")
return None # Return None if the request fails
wikipedia_url = "<https://en.wikipedia.org/wiki/Cristiano_Ronaldo>"
soup = connect_to_wikipedia(wikipedia_url) # Get the soup object for the specified在这段代码中,我们使用 Python 的 requests 库来向指定 URL 发送一个 HTTP 请求,并使用 BeautifulSoup 来解析页面的 HTML 内容。
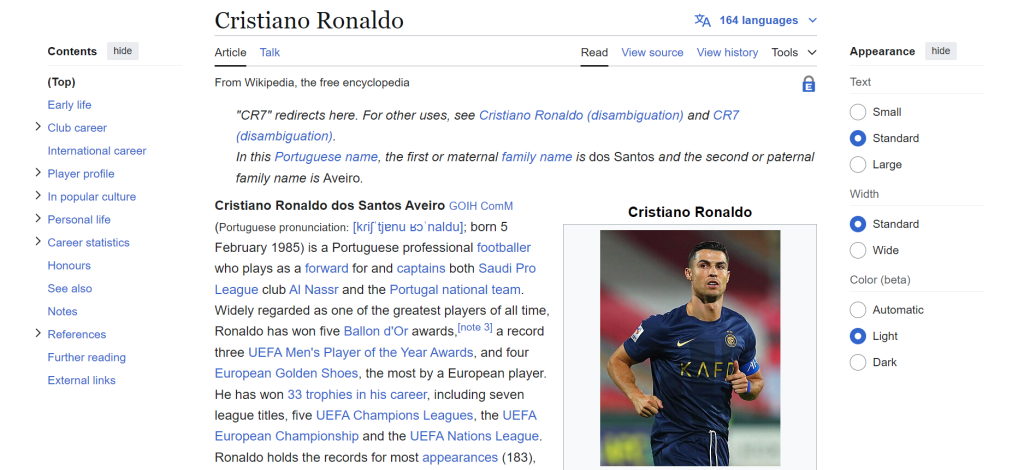
3. 检查页面结构
要有效地爬取数据,你需要了解网页的 DOM 结构。例如,如果你想提取该页面上所有的链接,可以定位到 <a> 标签:
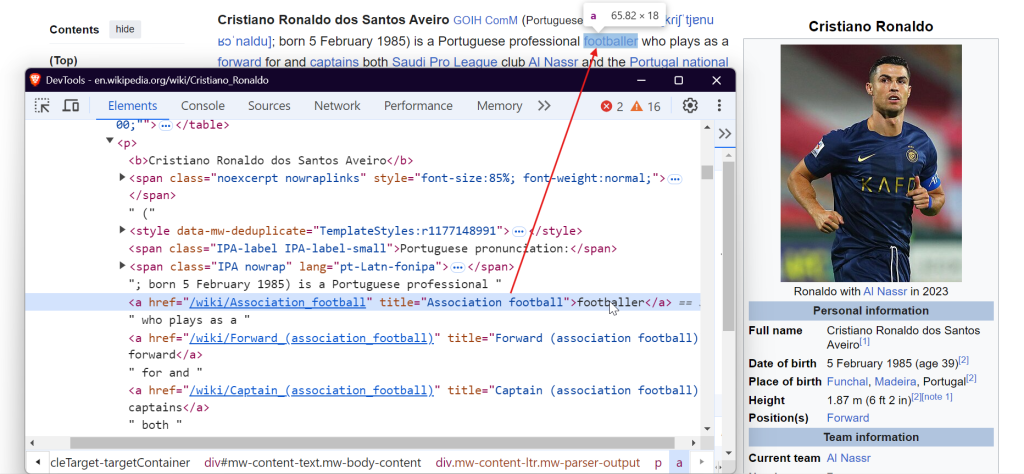
如果想爬取图片,则需要定位到 <img> 标签并获取 src 属性来得到图片的 URL。
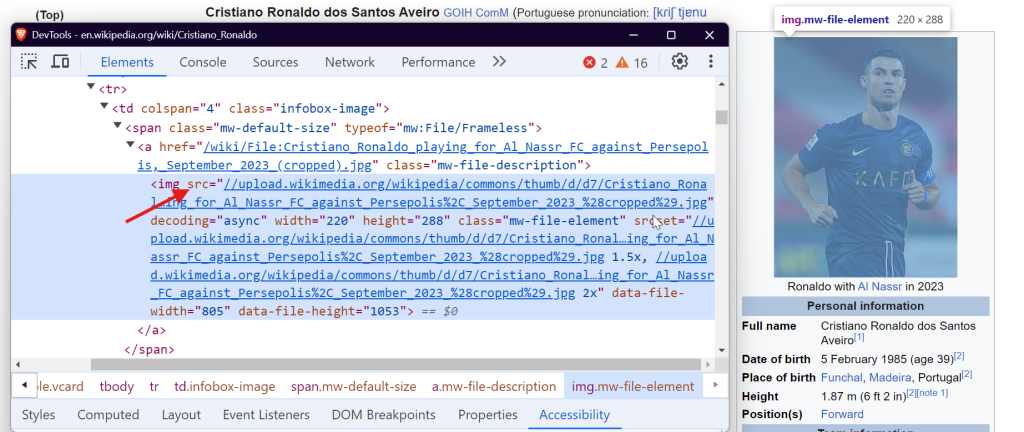
如果要提取表格中的数据,可以找到带有 wikitable 类的 <table> 标签,然后获取表格的行和列。
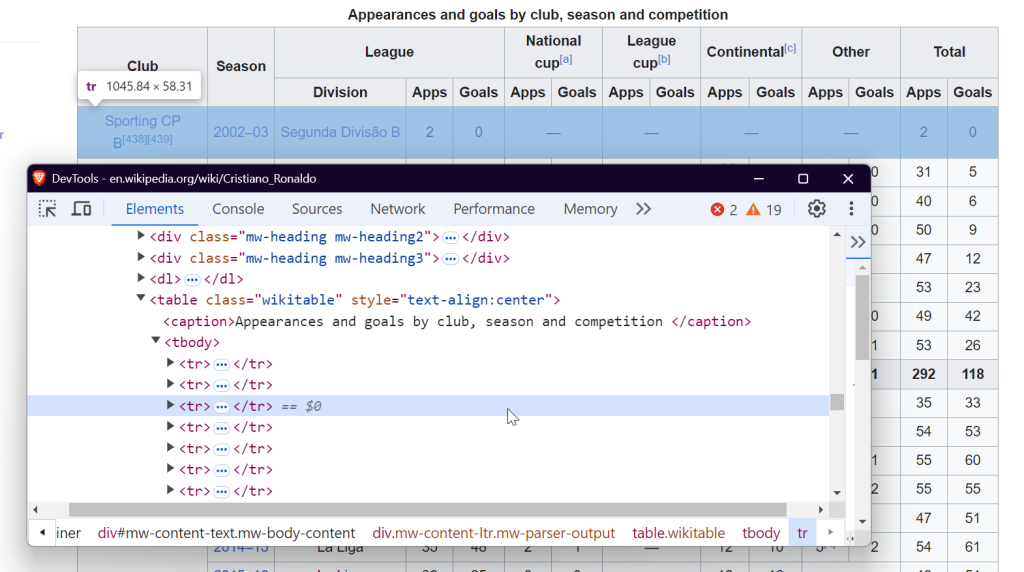
如果需要提取段落文本,则可以定位到 <p> 标签,这些标签里往往存放了页面主体文字内容。
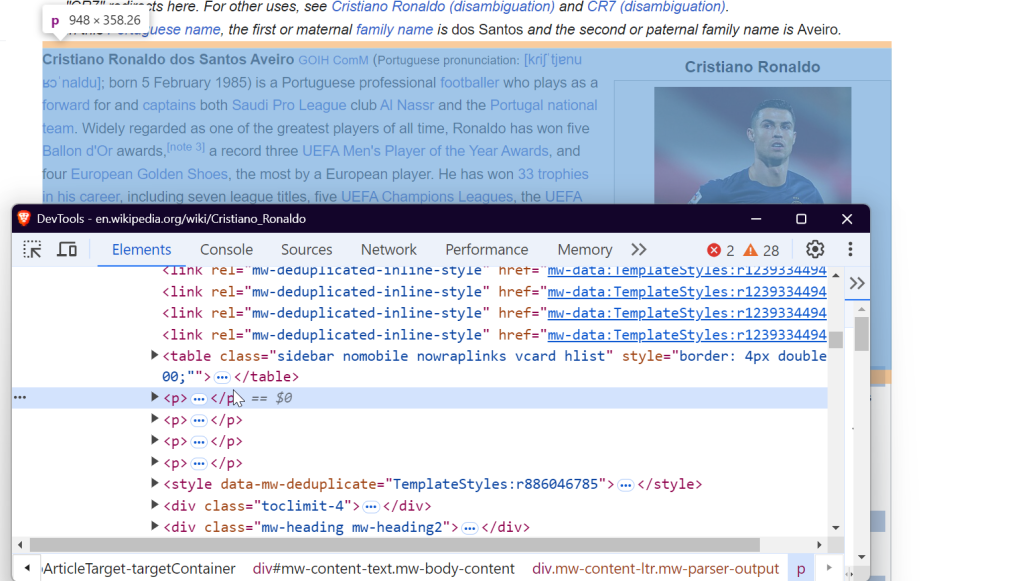
就这样,通过定位到这些特定元素,你就可以从任意一个维基百科页面中提取出所需数据。
4. 提取链接
维基百科文章中包含了内部和外部链接,用于跳转到相关主题、参考资料或外部资源。要提取页面中的所有链接,可以使用以下代码:
def extract_links(soup):
links = []
for link in soup.find_all("a", href=True): # Find all anchor tags with href attribute
url = link["href"]
if not url.startswith("http"): # Check if the URL is relative
url = "<https://en.wikipedia.org>" + url # Convert relative links to absolute URLs
links.append(url)
return links # Return the list of extracted linkssoup.find_all('a', href=True) 会找到页面上所有带 href 属性的 <a> 标签(涵盖了内部和外部链接)。同时,这段代码会把相对路径转换成绝对路径。
示例输出可能如下所示:
<https://en.wikipedia.org#Early_life>
<https://en.wikipedia.org#Club_career>
<https://en.wikipedia.org/wiki/Real_Madrid>
<https://en.wikipedia.org/wiki/Portugal_national_football_team>5. 提取段落
如果想抓取维基百科文章的文本内容,可以锁定 <p> 标签,这些标签里一般包含了文章的主体文字。以下是使用 BeautifulSoup 提取段落的示例:
def extract_paragraphs(soup):
paragraphs = [p.get_text(strip=True) for p in soup.find_all("p")] # Extract text from paragraph tags
return [p for p in paragraphs if p and len(p) > 10] # Return paragraphs longer than 10 characters
这个函数会获取页面中的所有段落,并过滤掉空段落或过短的段落,以避免提取到引用或单词等无用内容。
示例输出:
Cristiano Ronaldo dos Santos AveiroGOIHComM(Portuguese pronunciation:[kɾiʃˈtjɐnuʁɔˈnaldu]; born 5 February 1985) is a Portuguese professionalfootballerwho plays as aforwardfor andcaptainsbothSaudi Pro LeagueclubAl Nassrand thePortugal national team. Widely regarded as one of the greatest players of all time, Ronaldo has won fiveBallon d'Orawards,[note 3]a record threeUEFA Men's Player of the Year Awards, and fourEuropean Golden Shoes, the most by a European player. He has won33 trophies in his career, including seven league titles, fiveUEFA Champions Leagues, theUEFA European Championshipand theUEFA Nations League. Ronaldo holds the records for mostappearances(183),goals(140) andassists(42) in the Champions League,most appearances(30), assists (8),goals in the European Championship(14),international goals(133) andinternational appearances(215). He is one of the few players to have madeover 1,200 professional career appearances, the most by anoutfieldplayer, and has scoredover 900 official senior career goalsfor club and country, making him the top goalscorer of all time.6. 提取表格
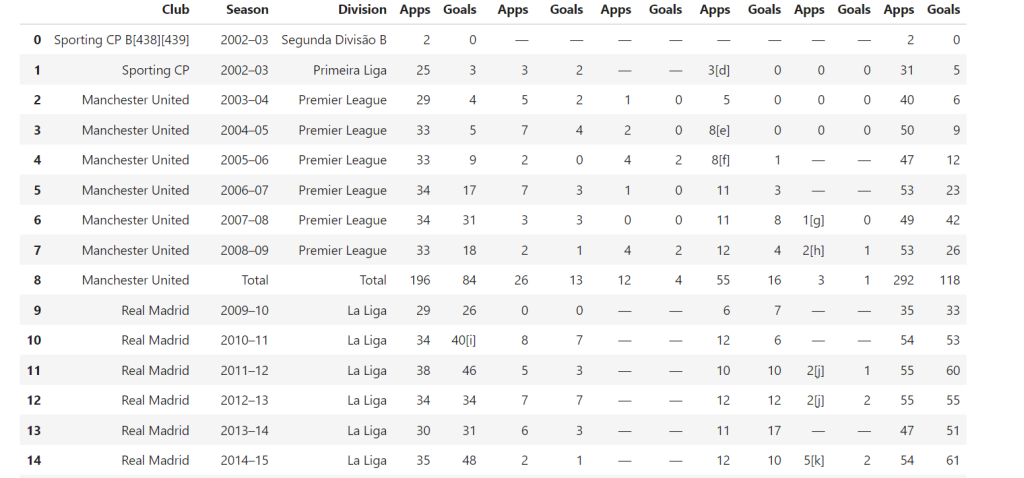
维基百科中通常会有带有结构化数据的表格。要提取这些表格,可以使用以下方法:
def extract_tables(soup):
tables = []
for table in soup.find_all("table", {"class": "wikitable"}): # Find tables with the 'wikitable' class
table_html = StringIO(str(table)) # Convert table HTML to string
df = pd.read_html(table_html)[0] # Read the HTML table into a DataFrame
tables.append(df)
return tables # Return list of DataFrames
该函数会找出所有 class 为 wikitable 的表格,并使用 pandas.read_html() 将其转换为可进一步处理的 DataFrame。
示例输出:
7. 提取图片
图片同样是维基百科中很有价值的资源,以下函数用来获取页面中的图片链接:
def extract_images(soup):
images = []
for img in soup.find_all("img", src=True): # Find all image tags with src attribute
img_url = img["src"]
if not img_url.startswith("http"): # Prepend 'https:' for relative URLs
img_url = "https:" + img_url
if "static/images" not in img_url: # Exclude static or non-relevant images
images.append(img_url)
return images # Return the list of image URLs该函数会找出页面内所有 <img> 标签,并为相对路径添加 https: 前缀,同时过滤掉无关的静态图片。
示例输出:
<https://upload.wikimedia.org/wikipedia/commons/d/d7/Cristiano_Ronaldo_2018.jpg>
<https://upload.wikimedia.org/wikipedia/commons/7/76/Cristiano_Ronaldo_Signature.svgb>8. 存储爬取到的数据
完成数据提取后,你需要将它们存储起来以备后续使用。下面的示例会分别将链接、图片、段落和表格数据分别保存:
def store_data(links, images, tables, paragraphs):
# Save links to a text file
with open("wikipedia_links.txt", "w", encoding="utf-8") as f:
for link in links:
f.write(f"{link}n")
# Save images to a JSON file
with open("wikipedia_images.json", "w", encoding="utf-8") as f:
json.dump(images, f, indent=4)
# Save paragraphs to a text file
with open("wikipedia_paragraphs.txt", "w", encoding="utf-8") as f:
for para in paragraphs:
f.write(f"{para}nn")
# Save each table as a separate CSV file
for i, table in enumerate(tables):
table.to_csv(f"wikipedia_table_{i+1}.csv", index=False, encoding="utf-8-sig")store_data 函数会做以下操作:
- 将链接保存在一个文本文件中。
- 将图片 URL 保存在一个 JSON 文件中。
- 将段落保存在另一个文本文件中。
- 将每个表格分别输出到 CSV 文件中。
这样就能方便后续访问和使用这些数据。
想进一步了解如何处理和序列化 JSON 数据?可以阅读我们的如何在 Python 中解析和序列化 JSON 的指南。
将所有步骤整合
现在,让我们把所有函数组合起来,打造一个完整的爬虫,能从维基百科页面中提取并保存数据:
import requests
from bs4 import BeautifulSoup
import pandas as pd
from io import StringIO
import json
# Extract all links from the page
def extract_links(soup):
links = []
for link in soup.find_all("a", href=True):
url = link["href"]
if not url.startswith("http"):
url = "<https://en.wikipedia.org>" + url
links.append(url)
return links
# Extract image URLs from the page
def extract_images(soup):
images = []
for img in soup.find_all("img", src=True):
img_url = img["src"]
if not img_url.startswith("http"):
img_url = "https:" + img_url
if "static/images" not in img_url: # Exclude unwanted static images
images.append(img_url)
return images
# Extract all tables from the page
def extract_tables(soup):
tables = []
for table in soup.find_all("table", {"class": "wikitable"}):
table_html = StringIO(str(table))
df = pd.read_html(table_html)[0] # Convert HTML table to DataFrame
tables.append(df)
return tables
# Extract paragraphs from the page
def extract_paragraphs(soup):
paragraphs = [p.get_text(strip=True) for p in soup.find_all("p")]
return [p for p in paragraphs if p and len(p) > 10] # Filter out empty or short paragraphs
# Store the extracted data into separate files
def store_data(links, images, tables, paragraphs):
# Save links to a text file
with open("wikipedia_links.txt", "w", encoding="utf-8") as f:
for link in links:
f.write(f"{link}n")
# Save images to a JSON file
with open("wikipedia_images.json", "w", encoding="utf-8") as f:
json.dump(images, f, indent=4)
# Save paragraphs to a text file
with open("wikipedia_paragraphs.txt", "w", encoding="utf-8") as f:
for para in paragraphs:
f.write(f"{para}nn")
# Save each table as a CSV file
for i, table in enumerate(tables):
table.to_csv(f"wikipedia_table_{i+1}.csv", index=False, encoding="utf-8-sig")
# Main function to scrape a Wikipedia page and save the extracted data
def scrape_wikipedia(url):
response = requests.get(url) # Fetch the page content
soup = BeautifulSoup(response.text, "html.parser") # Parse the content with BeautifulSoup
links = extract_links(soup)
images = extract_images(soup)
tables = extract_tables(soup)
paragraphs = extract_paragraphs(soup)
# Save all extracted data into files
store_data(links, images, tables, paragraphs)
# Example usage: scrape Cristiano Ronaldo's Wikipedia page
if __name__ == "__main__":
scrape_wikipedia("<https://en.wikipedia.org/wiki/Cristiano_Ronaldo>")当你运行脚本后,目录中会生成以下文件:
wikipedia_images.json:保存了所有的图片 URL。wikipedia_links.txt:保存了所有链接。wikipedia_paragraphs.txt:保存了提取到的段落文本。- 对于每一个表格,会生成对应的 CSV 文件(例如
wikipedia_table_1.csv、wikipedia_table_2.csv)。
最终结果类似如下:

到这里就完成了!你已经成功地爬取并将维基百科数据分别存储在不同的文件中。
使用 Bright Data Wikipedia Scraper API
若想更快、更轻松地提取维基百科的数据,Bright Data Wikipedia Scraper API 的设置和使用非常简单,几分钟内就能上手。下面步骤演示如何快速开始使用它来抓取维基百科。
第 1 步:创建 Bright Data 账户
访问 Bright Data 网站 并登录你的账户。如果你还没有帐号,可先免费注册。步骤如下:
- 进入 Bright Data 网站。
- 点击 Start Free Trial 并根据提示创建你的账户。
- 进入仪表盘后,在左侧边栏找到信用卡图标,进入 Billing 页面。
- 添加一个有效的支付方式以激活你的账户。
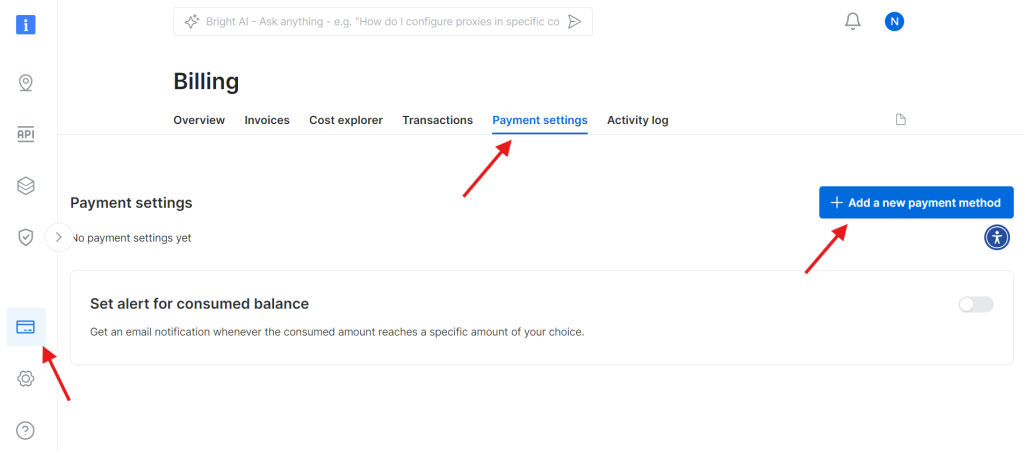
当账户成功激活后,进入仪表盘的 Web Scraper API 页面。在此你可以搜索任何需要使用的爬虫 API。本例中,搜索 Wikipedia。
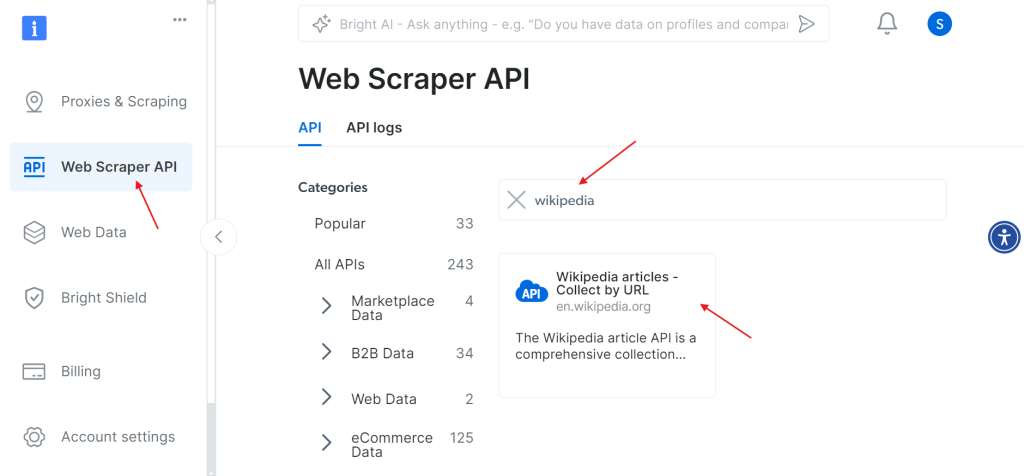
点击 Wikipedia articles – Collect by URL 选项后,即可直接通过提供维基百科页面 URL 的方式来采集文章。
第 2 步:开始配置 API 调用
点击后,你会进入设置 API 调用的页面。
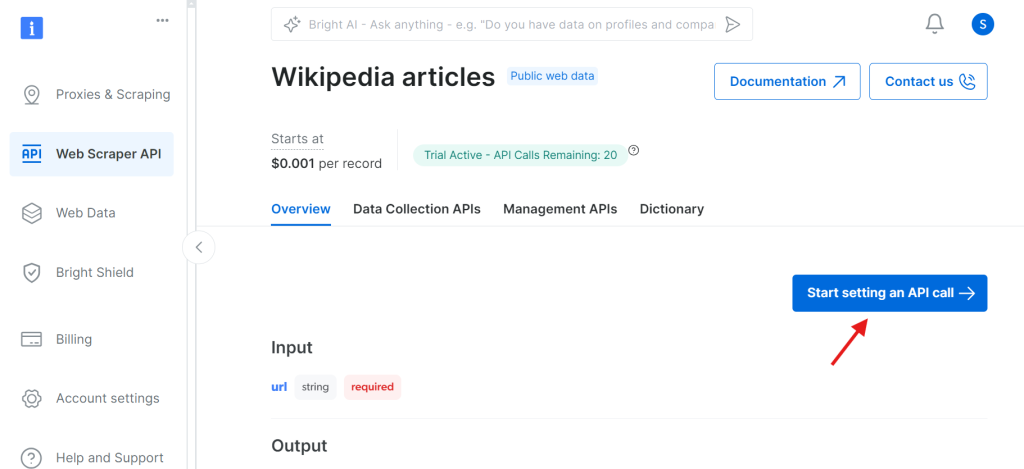
在下一步之前,你需要创建一个 API token 用于验证 API 调用。点击 Create Token 按钮获取 token,并复制保存。这个 token 非常重要,后面会用到。
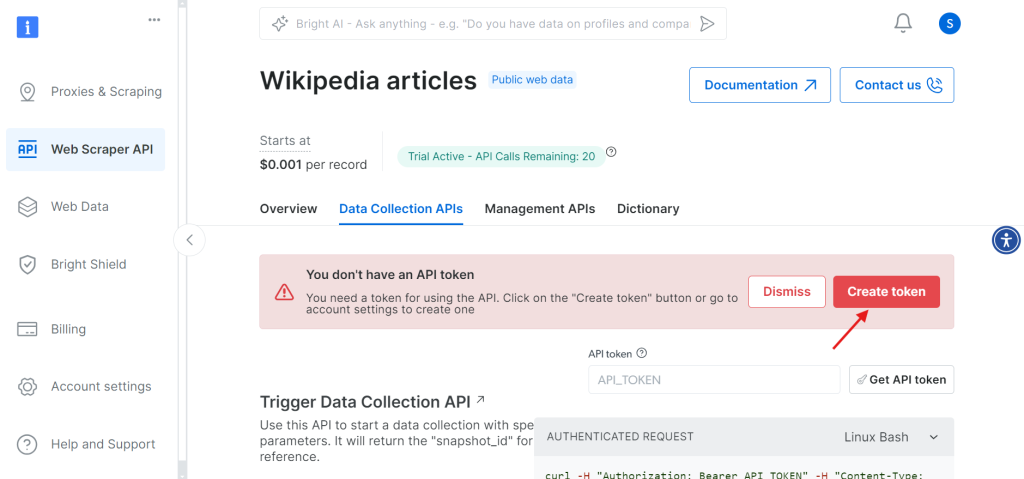
第 3 步:设置参数并生成 API 调用
获得 token 后,就可以配置 API 调用。在页面上输入想要爬取的维基百科 URL,右侧会根据你的输入生成 cURL 命令。
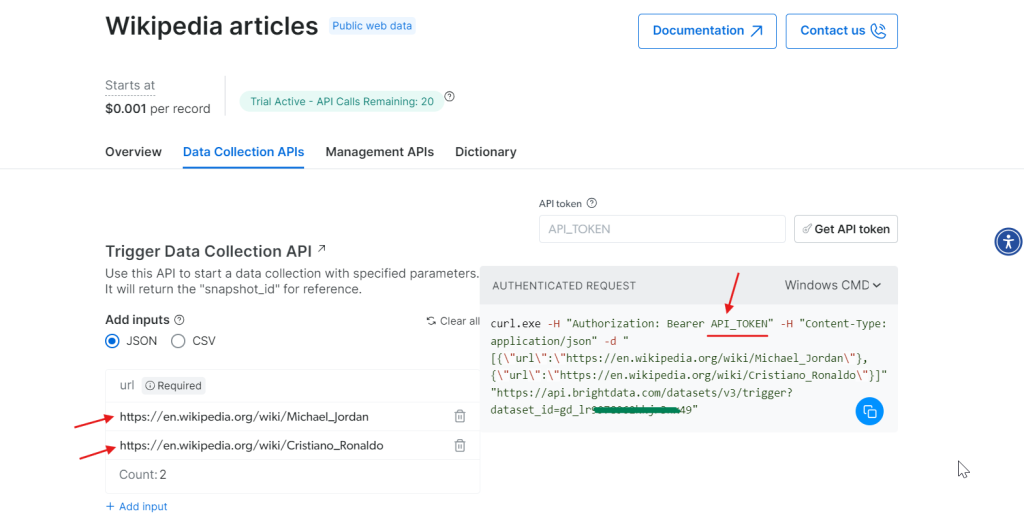
将 cURL 命令中的 API_Token 替换为你实际的 token,并在终端中运行。成功执行后会得到一个 snapshot_id,后面我们会用它来获取爬取到的结果。
第 4 步:获取数据
使用刚才生成的 snapshot_id,你便可获取数据。把此 ID 填写到 Snapshot ID 字段中。API 会自动在右侧生成一个新的 cURL 命令,用来拉取数据。你还可选择你想要的文件格式,如 JSON、CSV 等。
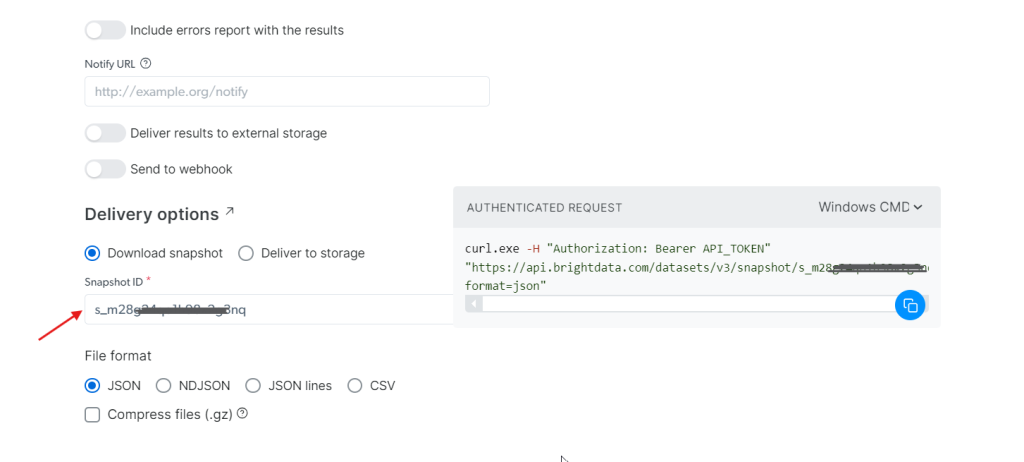
你还可以将数据存储到 Amazon S3、Google Cloud Storage 或 Microsoft Azure Storage 等云服务。
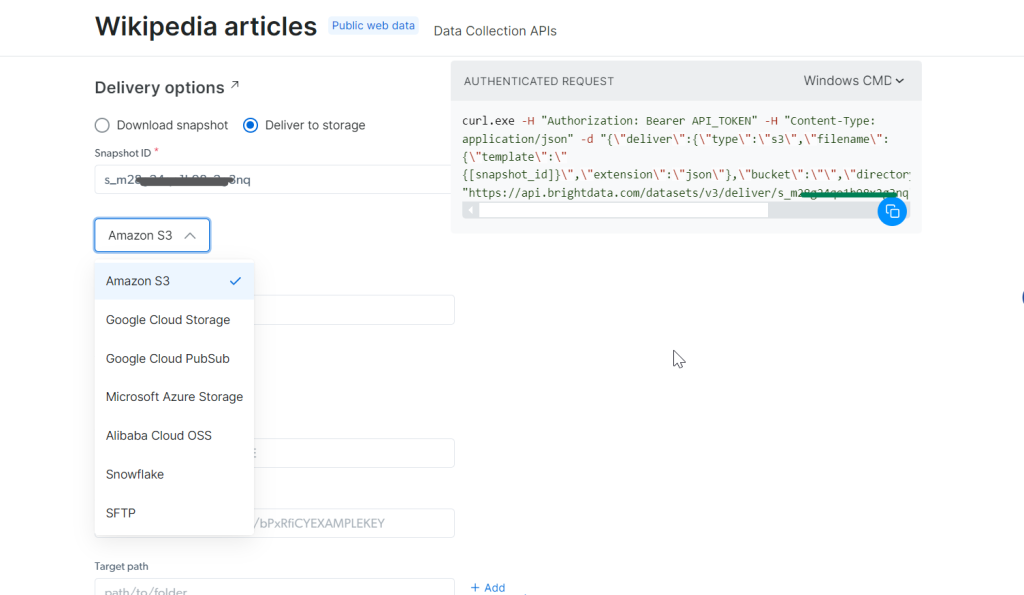
第 5 步:运行命令
假设你想要 JSON 格式的数据,可以选择 JSON 作为文件格式,复制生成的 cURL 命令,如果想直接写入文件,可在命令末尾添加 -o my_data.json。这样就能把数据存到本地了。
在终端运行该命令,即可在几秒内获取所有爬取到的数据!
curl.exe -H "Authorization: Bearer 50xxx52c-xxxx-xxxx-xxxx-2748xxxxx487" "https://api.brightdata.com/datasets/v3/snapshot/s_mxxg2xxxxx2g3nq?format=json" -o my_data.json
不想自己处理维基百科爬虫,但仍需要其中的数据?你也可以直接购买一份 维基百科数据集。
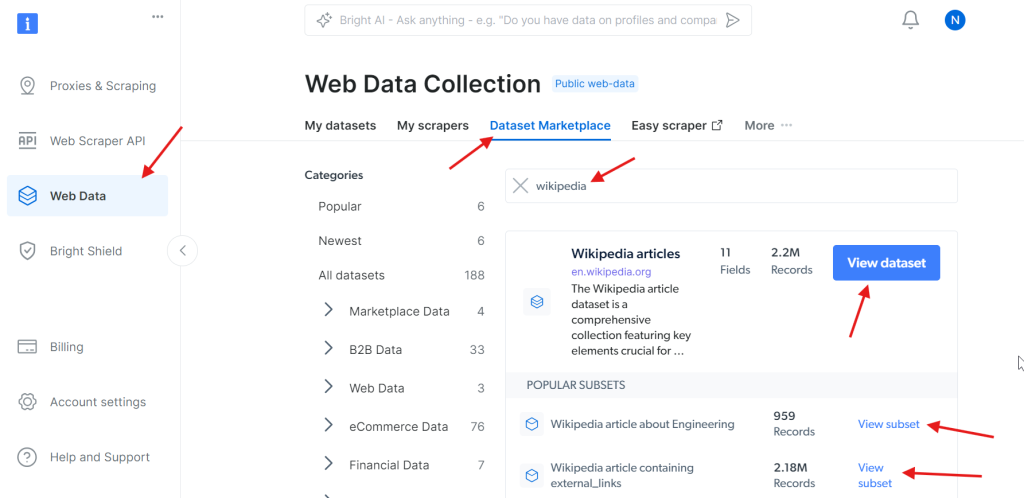
是的,就是这么简单!
总结
本文介绍了如何使用 Python 来爬取维基百科,包括如何提取图片 URL、文本内容、表格以及内部和外部链接。不过,如果想使用更快更便捷的方式获取海量数据,Bright Data 的 Wikipedia Scraper API 就非常值得一试。
还想抓取其它网站?欢迎注册并尝试我们的 Web Scraper API,立即开始你的免费试用吧!



技术写作者
 5 years experience
5 years experience
Satyam Tripathi 帮助 SaaS 和数据初创公司将复杂技术转化为可执行的内容,提升开发者采用度并增强用户理解。




