

在本教程中,您将学习:
- Booking爬取工具的定义
- 可以提取哪些数据
- 如何使用Python构建一个 Booking.com 爬取脚本
让我们开始吧!
什么是Booking爬取工具?
一个 Booking.com 爬取工具是一种可以自动从 Booking.com 页面提取数据的工具。它可以帮助您从酒店列表页面获取信息,例如酒店名称、价格、评论、评分、设施和可用性。这些数据可以用于多种用途,包括市场分析、价格比较以及构建与旅行相关的数据集。
可以从 Booking.com 爬取的数据
以下是您可以从 Booking.com 提取的数据点列表:
- 酒店详情:酒店名称、地址、与地标的距离(例如市中心、商业区等)
- 价格信息:常规价格、折扣价格(如果有)
- 评论和评分:评分、评论数量、住客反馈
- 可用性:可用房型、预订选项(例如免费取消、含早餐)、可用日期
- 媒体:酒店图片、房间图片
- 设施:提供的设施(例如Wi-Fi、停车场、游泳池)、房间特定设施
- 促销:特别优惠或折扣、限时优惠
- 政策:取消政策、入住和退房时间
- 其他详情:酒店描述、附近景点、特定日期的可用房间数量
使用Python爬取 Booking.com 的分步指南
在本部分中,您将学习如何构建一个 Booking.com 爬取工具。
目标是创建一个Python脚本,自动从酒店列表页面收集数据:
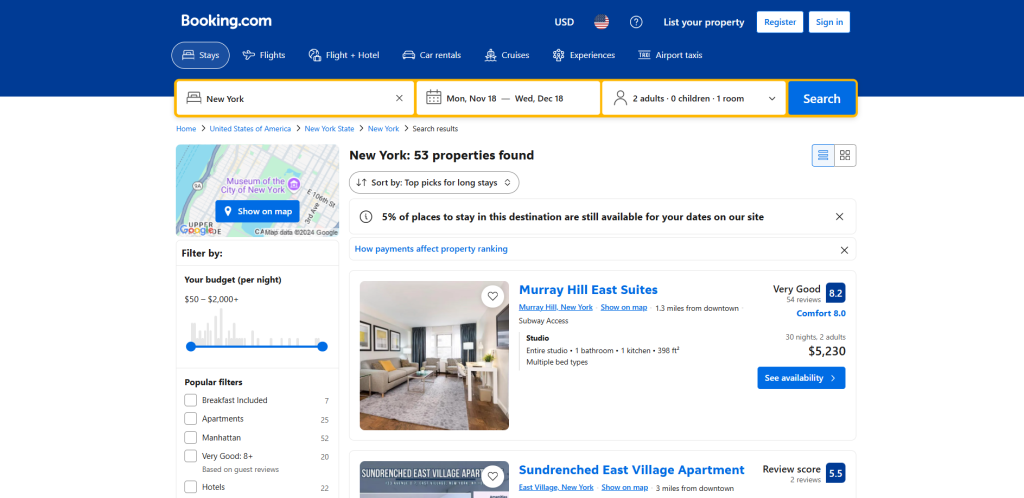
按照以下步骤操作!
步骤#1:项目设置
在开始之前,请确保您的计算机上已安装Python 3。如果尚未安装,请 下载,运行可执行文件并按照安装向导操作。
现在,使用以下命令为您的项目创建一个文件夹:
mkdir booking-scraperbooking-scraper 目录是您的Python Booking.com 爬取脚本的项目文件夹。
进入该目录,并在其中初始化一个 虚拟环境:
cd booking-scraper
python -m venv env在您喜欢的Python IDE中加载项目文件夹。 带有Python扩展的Visual Studio Code 和 PyCharm社区版 都是不错的选择。
在项目文件夹中创建一个 scraper.py 文件,文件结构如下:

scraper.py 现在是一个空白的Python脚本,但很快它将包含爬取逻辑。
在IDE的终端中,激活虚拟环境。在Linux或macOS中,执行以下命令:
./env/bin/activate在Windows上,运行以下命令:
env/Scripts/activate太棒了!您现在有了一个用于网络爬取的Python环境!
步骤#2:选择爬取库
现在是时候确定 Booking.com 是一个静态网站还是动态网站,并选择相应的爬取库。这可以通过检查网站的行为来完成。首先在浏览器中打开 Booking.com,执行搜索并导航到酒店页面:
注意,当您向下滚动时,页面会动态加载新数据:
这种模式被称为 无限滚动,是动态网站的标志。了解更多关于如何 爬取动态网站。
即使不深入研究服务器返回的HTML代码或检查DevTools中的 网络 选项卡(这是了解网站是否为静态的两个常见步骤),我们已经可以得出结论: Booking.com 是一个动态网站。
爬取动态内容网站的最佳方法是使用 浏览器自动化工具。这些解决方案允许您控制浏览器并在页面上执行特定交互以有效提取数据。
Python中最强大的浏览器自动化工具之一是 Selenium,这使其成为爬取 Booking.com 的绝佳选择。准备好安装它,因为它将是完成此任务的主要库!
步骤#3:安装和配置Selenium
在Python中,Selenium可以通过 selenium pip包获得。在激活的Python虚拟环境中,使用以下命令安装它:
pip install selenium关于如何使用该工具的指导,请阅读我们的 Selenium网络爬取教程。
在 scraper.py 中导入Selenium,并初始化一个 WebDriver 对象以控制Chrome实例:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# create a Chrome web driver instance
driver = webdriver.Chrome(service=Service())以上代码初始化了一个 Chrome WebDriver 实例以控制Chrome浏览器。注意, Booking.com 似乎使用了反爬技术来阻止无头浏览器。因此,请避免设置 --headless 标志。作为替代解决方案,请阅读我们的 Playwright Stealth指南。
作为爬取器的最后一行代码,请记得关闭WebDriver:
driver.quit()太棒了!您现在已完全配置好可以开始爬取 Booking.com。
步骤#4:访问目标页面
Booking.com 页面提供了许多交互功能来优化您的搜索:
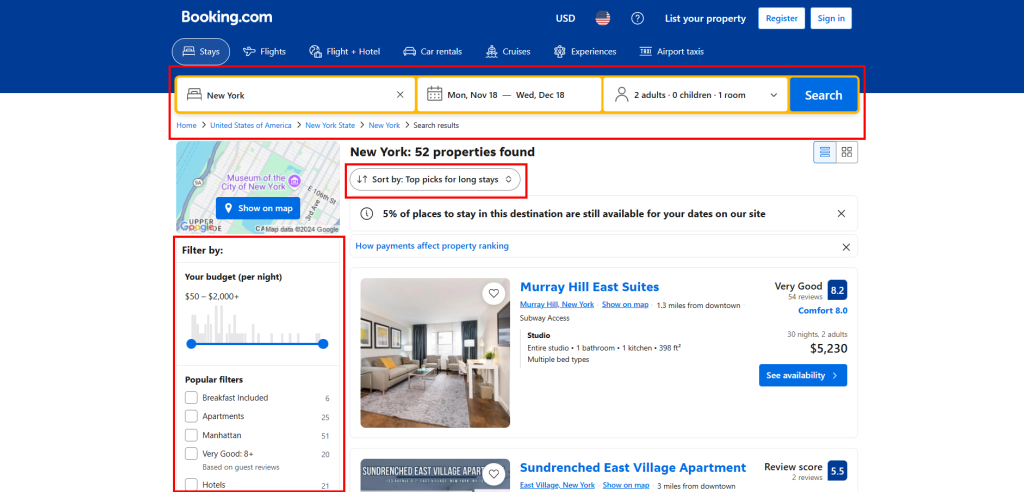
使用Selenium以编程方式模拟所有这些交互将非常复杂且耗时。因此,为了简化和加快速度,请首先在浏览器中手动执行这些交互。
一旦您配置了感兴趣的搜索查询,请从浏览器的地址栏中复制生成的页面URL。
例如,上述URL表示从11月18日到12月18日为两位成人搜索纽约的公寓。
复制URL并将其传递给Selenium提供的 get() 方法:
driver.get("https://www.booking.com/searchresults.html?ss=New+York&ssne=New+York&ssne_untouched=New+York&label=gen173nr-1FCAEoggI46AdIM1gEaHGIAQGYATG4ARfIAQzYAQHoAQH4AQKIAgGoAgO4Aof767kGwAIB0gIkNGE2MTI1MjgtZjJlNC00YWM4LWFlMmQtOGIxZjM3NWIyNDlm2AIF4AIB&sid=b91524e727f20006ae00489afb379d3a&aid=304142&lang=en-us&sb=1&src_elem=sb&src=index&dest_id=20088325&dest_type=city&checkin=2024-11-18&checkout=2024-12-18&group_adults=2&no_rooms=1&group_children=0")您的爬取脚本将自动连接到目标 Booking.com 页面。
scraper.py 文件现在将包含以下代码行:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
# create a Chrome web driver instance
driver = webdriver.Chrome(service=Service())
# connect to the target page
driver.get("https://www.booking.com/searchresults.html?ss=New+York&ssne=New+York&ssne_untouched=New+York&label=gen173nr-1FCAEoggI46AdIM1gEaHGIAQGYATG4ARfIAQzYAQHoAQH4AQKIAgGoAgO4Aof767kGwAIB0gIkNGE2MTI1MjgtZjJlNC00YWM4LWFlMmQtOGIxZjM3NWIyNDlm2AIF4AIB&sid=b91524e727f20006ae00489afb379d3a&aid=304142&lang=en-us&sb=1&src_elem=sb&src=index&dest_id=20088325&dest_type=city&checkin=2024-11-18&checkout=2024-12-18&group_adults=2&no_rooms=1&group_children=0")
# scraping logic...
# close the web driver and release its resources
driver.quit()在最后一行设置一个调试断点,然后运行脚本。以下是您应该看到的内容:
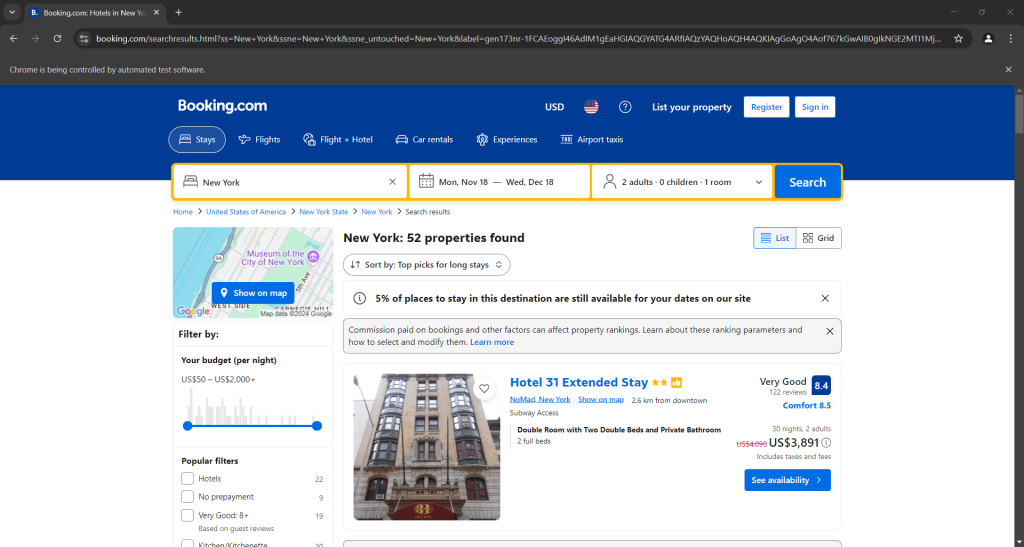
“Chrome正在被自动化测试软件控制”消息表明Selenium正在按预期操作Chrome。干得好!
步骤#5:处理登录弹窗
当您第一次在浏览器中访问 Booking.com 时,网站通常会在前20秒内显示一个登录弹窗。这会阻止访问页面内容,从而使网络爬取更加困难:
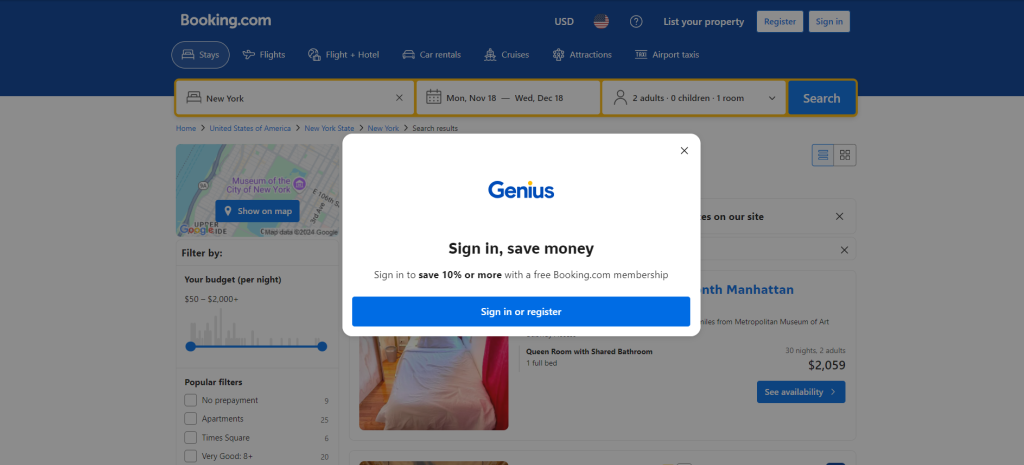
在您与其交互之前,您将无法访问页面上的内容。
要处理弹窗,请使用Selenium关闭它。右键单击关闭按钮并从上下文菜单中选择“检查”选项:
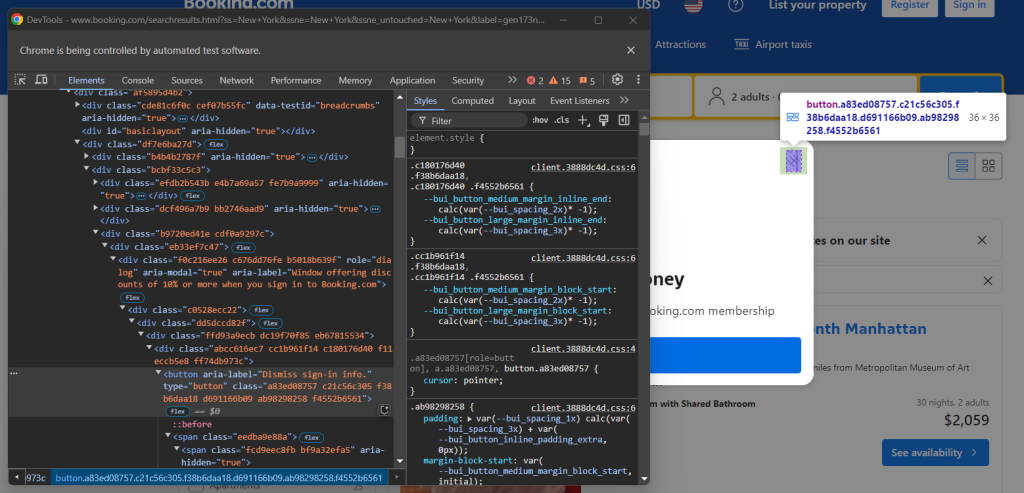
注意,您可以通过选择以下CSS选择器来关闭弹窗:
[role="dialog"] button[aria-label="Dismiss sign-in info."]现在,指示Selenium等待最多10秒以显示弹窗。一旦它出现,通过单击关闭按钮将其关闭。由于弹窗可能并不总是出现,因此将此逻辑包装在 try...except 块中是有意义的:
try:
# wait up to 20 seconds for the sign-in alert to appear
close_button = WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "[role="dialog"] button[aria-label="Dismiss sign-in info."]"))
)
# click the close button
close_button.click()
except TimeoutException:
print("Sign-in modal did not appear, continuing...")WebDriverWait 是一个专门的Selenium类,它会暂停脚本,直到页面上的指定条件满足。在上述示例中,它最多等待10秒以显示弹窗关闭按钮。
如果弹窗未出现,Selenium将引发 TimeoutException 异常。将其与 WebDriverWait、 EC 和 By 一起导入:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException太棒了!登录弹窗不再是问题。
步骤#6:选择 Booking.com 项目
注意,您要爬取的 Booking.com 页面包含多个项目。由于您想爬取所有项目,请初始化一个数组来存储爬取的数据:
items = []现在,您需要了解如何选择与这些项目相关的HTML元素。在浏览器中打开 Booking.com,执行搜索并检查其中一个酒店项目:

注意,HTML元素的类名似乎是随机生成的。这意味着它们可能会随着每次网站部署而更改,使其在元素选择中不可靠。相反,请关注更稳定的属性,例如 data-testid。
data-* 属性是网络爬取的绝佳目标。
使用Selenium的 find_elements() 方法在页面上应用CSS选择器并选择感兴趣的元素:
property_items = driver.find_elements(By.CSS_SELECTOR, "[data-testid="property-card"]")遍历酒店项目,并准备您的 Booking.com 爬取工具以提取一些数据:
for property_item in property_items:
# scraping logic...太棒了!下一步是从这些元素中爬取数据。
步骤#7:爬取 Booking.com 项目
请注意页面上的酒店项目,它们包含的元素并不一致:
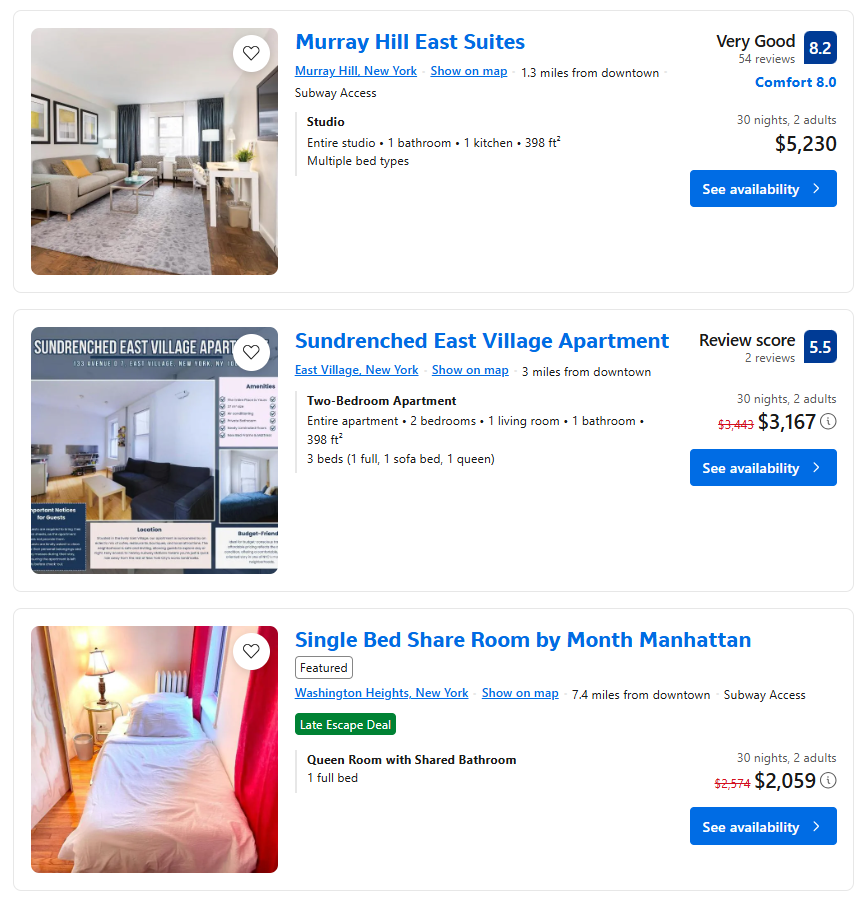
有些有评分,有些没有。同样,有些有折扣价格,有些没有。
这些差异使得为所有酒店项目编写一致的爬取逻辑变得困难。当您尝试选择页面上不存在的元素时,Selenium会引发 NoSuchElementException。因此,定义一个函数来处理这种情况是有意义的:
def handle_no_such_element_exception(data_extraction_task):
try:
return data_extraction_task()
except NoSuchElementException as e:
return None上述函数接受一个lambda函数并尝试执行它。如果引发 NoSuchElementException,它会捕获异常并返回 None。这允许您的 Booking.com 爬取脚本继续运行而不会中断。
导入 NoSuchElementException:
from selenium.common import NoSuchElementException检查包含所有元素(评分、折扣价格等)的酒店项目:
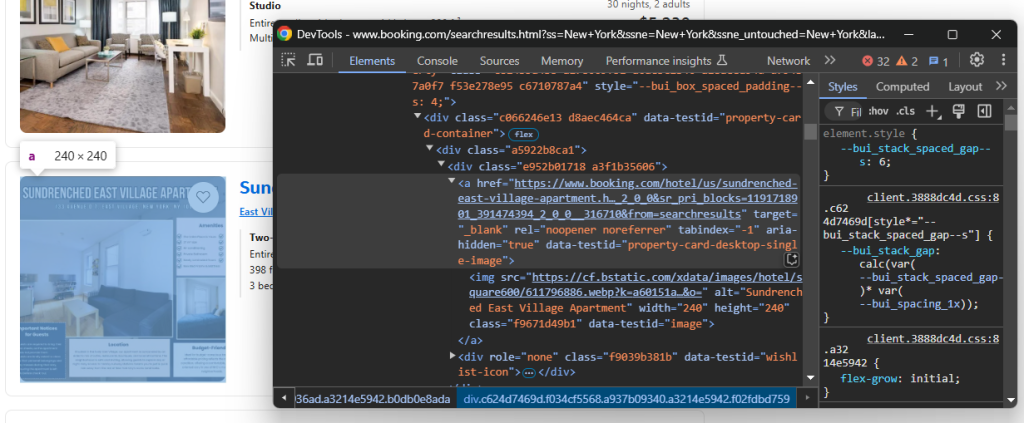
注意,您可以提取:
- 酒店链接:
a[data-testid="property-card-desktop-single-image"] - 酒店图片:
img[data-testid=image]
在 for 循环中,应用当前逻辑选择这些元素并从中提取数据:
url = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "a[data-testid="property-card-desktop-single-image"]").get_attribute("href"))
image = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "img[data-testid="image"]").get_attribute("src"))find_element() 选择页面上的单个节点,而 get_attribute() 获取指定HTML属性中的内容。注意,数据提取指令被 handle_no_such_element_exception 包装以处理 NoSuchElementException。
类似地,关注标题部分及其下方的信息:
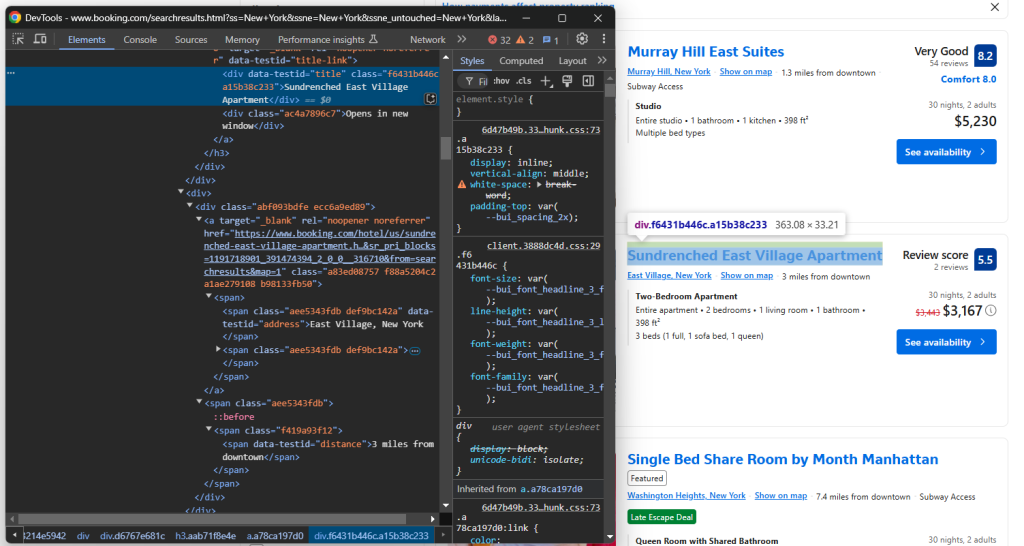
在这里,您可以获取:
- 酒店标题:
[data-testid="title"] - 酒店地址:
[data-testid="address"] - 酒店距离:
[data-testid="distance"]
爬取它们:
title = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="title"]").text)
address = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="address"]").text)
distance = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="distance"]").text)text 属性包含所选元素中的文本。
接下来,关注评分节点:
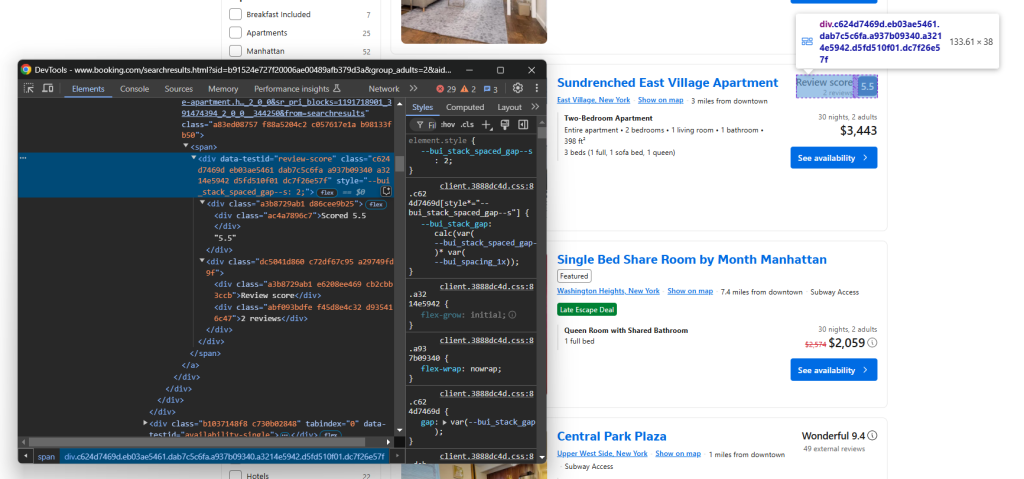
通过 data-testid="review-score" 选择它并提取其文本。注意,文本具有特殊格式,例如:
'评分 8.4n8.4n非常好n120 条评论'通过一些自定义逻辑,您可以从中提取评分和评论数量:
review_score = None
review_count = None
review_text = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="review-score"]").text)
if review_text is not None:
# split the review string by n
parts = review_text.split("n")
# process each part
for part in parts:
part = part.strip()
# check if this part is a number (potential review score)
if part.replace(".", "", 1).isdigit():
review_score = float(part)
# check if it contains the "reviews" string
elif "reviews" in part:
# extract the number before "reviews"
review_count = int(part.split(" ")[0].replace(",", ""))目标描述元素:
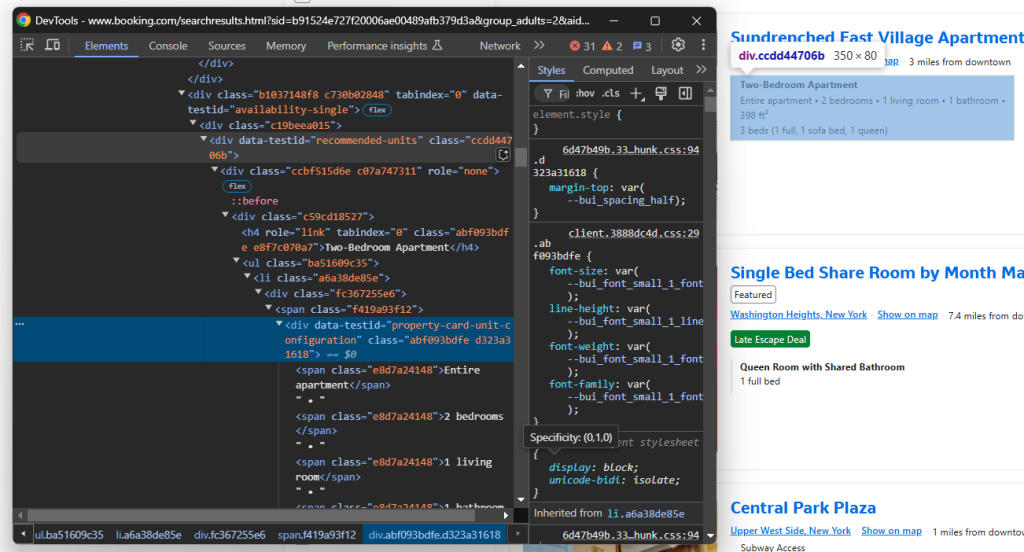
通过 data-testid="recommended-units" 选择它并爬取描述:
description = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="recommended-units"]").text)最后,关注价格元素:
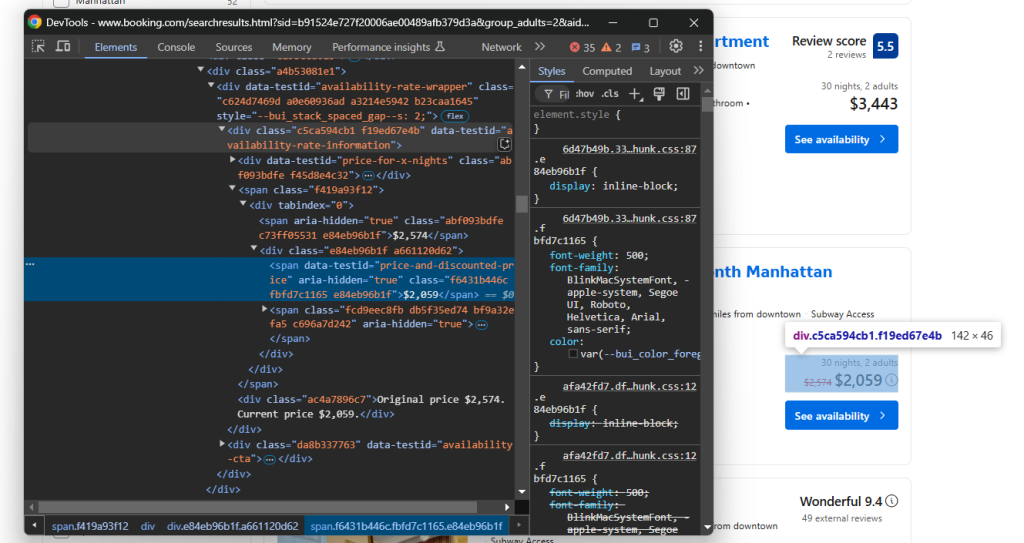
从 data-testid="availability-rate-information" 元素中选择:
- 原价:从具有
aria-hidden="true"属性且没有data-testid属性的节点中选择 - 折扣/当前价格:
data-testid="price-and-discounted-price"
编写价格提取逻辑如下:
price_element = handle_no_such_element_exception(lambda: (property_item.find_element(By.CSS_SELECTOR, "[data-testid="availability-rate-information"]")))
if price_element is not None:
original_price = handle_no_such_element_exception(lambda: (
price_element.find_element(By.CSS_SELECTOR, "[aria-hidden="true"]:not([data-testid])").text.replace(",", "")
))
price = handle_no_such_element_exception(lambda: (
price_element.find_element(By.CSS_SELECTOR, "[data-testid="price-and-discounted-price"]").text.replace(",", "")
))哇! Booking.com 爬取逻辑几乎完成了。
步骤#7:收集爬取的数据
现在,您已经在 for 循环中将爬取的数据分散到多个变量中。创建一个新的 item 对象,用这些数据填充它,并将其附加到 items 数组中:
item = {
"url": url,
"image": image,
"title": title,
"address": address,
"distance": distance,
"review_score": review_score,
"review_count": review_count,
"description": description,
"original_price": original_price,
"price": price
}
items.append(item)在 for 循环结束时,items 将包含所有爬取的数据。通过打印 items 来验证:
print(items)这将生成如下输出:
[{'url': 'https://www.booking.com/hotel/us/murray-hill-east-manhattan.html?label=gen173nr-1FCAEoggI46AdIM1gEaHGIAQGYATG4ARfIAQzYAQHoAQH4AQKIAgGoAgO4Aof767kGwAIB0gIkNGE2MTI1MjgtZjJlNC00YWM4LWFlMmQtOGIxZjM3NWIyNDlm2AIF4AIB&sid=b91524e727f20006ae00489afb379d3a&aid=304142&ucfs=1&arphpl=1&checkin=2024-11-18&checkout=2024-12-18&dest_id=20088325&dest_type=city&group_adults=2&req_adults=2&no_rooms=1&group_children=0&req_children=0&hpos=1&hapos=1&sr_order=popularity&srpvid=c6926559ebaa0862&srepoch=1731939905&all_sr_blocks=5604802_204869446_2_0_0&highlighted_blocks=5604802_204869446_2_0_0&matching_block_id=5604802_204869446_2_0_0&sr_pri_blocks=5604802_204869446_2_0_0__523000&from=searchresults', 'image': 'https://cf.bstatic.com/xdata/images/hotel/square600/84564452.webp?k=ff50b7387e08e01ba7a400effa788e668f894cabe4a295f60d6cd018ec9ac4d0&o=', 'title': 'Murray Hill East Suites', 'address': 'Murray Hill, New York', 'distance': '1.3 miles from downtown', 'review_score': 8.2, 'review_count': 54, 'description': 'StudionEntire studio • 1 bathroom • 1 kitchen • 398 ft²nMultiple bed types', 'original_price': None, 'price': '$5230'},
# omitted for brevity...
, {'url': 'https://www.booking.com/hotel/us/renaissance-times-square.html?label=gen173nr-1FCAEoggI46AdIM1gEaHGIAQGYATG4ARfIAQzYAQHoAQH4AQKIAgGoAgO4Aof767kGwAIB0gIkNGE2MTI1MjgtZjJlNC00YWM4LWFlMmQtOGIxZjM3NWIyNDlm2AIF4AIB&sid=b91524e727f20006ae00489afb379d3a&aid=304142&ucfs=1&arphpl=1&checkin=2024-11-18&checkout=2024-12-18&dest_id=20088325&dest_type=city&group_adults=2&req_adults=2&no_rooms=1&group_children=0&req_children=0&hpos=12&hapos=12&sr_order=popularity&srpvid=c6926559ebaa0862&srepoch=1731939905&all_sr_blocks=2315604_274565698_0_2_0&highlighted_blocks=2315604_274565698_0_2_0&matching_block_id=2315604_274565698_0_2_0&sr_pri_blocks=2315604_274565698_0_2_0__1805400&from_sustainable_property_sr=1&from=searchresults', 'image': 'https://cf.bstatic.com/xdata/images/hotel/square600/437371642.webp?k=d1a06036e365573e326e6b0f1b045f8f43b6ad0d18e119cfb92d92cc81fa5c88&o=', 'title': 'Renaissance New York Times Square by Marriott', 'address': 'Manhattan, New York', 'distance': '0.6 miles from downtown', 'review_score': 8.4, 'review_count': 2209, 'description': 'King Roomn1 king bed', 'original_price': '$20060', 'price': '$18054'}]太棒了!只剩下将这些信息导出到人类可读的文件(如CSV)中。
步骤#8:导出为CSV
从Python标准库中导入 csv:
import csv然后,使用它将 items 导出为CSV文件:
# specify the name of the output CSV file
output_file = "properties.csv"
# export the items list to a CSV file
with open(output_file, mode="w", newline="", encoding="utf-8") as file:
#create a CSV writer object
writer = csv.DictWriter(file, fieldnames=["url", "image", "title", "address", "distance", "review_score", "review_count", "description", "original_price", "price"])
# write the header row
writer.writeheader()
# write each item as a row in the CSV
writer.writerows(items)以上代码将使用 items 数组中的数据填充一个名为 properties.csv 的CSV文件。上面使用的关键函数包括:
open():以写入模式和UTF-8编码打开指定文件。csv.DictWriter():使用指定的字段名创建一个CSV写入器。writeheader():根据指定的字段名将标题行写入CSV文件。writer.writerow():将每个字典项作为CSV中的一行写入。
步骤#9:整合所有内容
scraper.py 现在应包含以下代码:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common.exceptions import TimeoutException
from selenium.common import NoSuchElementException
import csv
def handle_no_such_element_exception(data_extraction_task):
try:
return data_extraction_task()
except NoSuchElementException as e:
return None
# create a Chrome web driver instance
driver = webdriver.Chrome(service=Service())
# connect to the target page
driver.get("https://www.booking.com/searchresults.html?ss=New+York&ssne=New+York&ssne_untouched=New+York&label=gen173nr-1FCAEoggI46AdIM1gEaHGIAQGYATG4ARfIAQzYAQHoAQH4AQKIAgGoAgO4Aof767kGwAIB0gIkNGE2MTI1MjgtZjJlNC00YWM4LWFlMmQtOGIxZjM3NWIyNDlm2AIF4AIB&sid=b91524e727f20006ae00489afb379d3a&aid=304142&lang=en-us&sb=1&src_elem=sb&src=index&dest_id=20088325&dest_type=city&checkin=2024-11-18&checkout=2024-12-18&group_adults=2&no_rooms=1&group_children=0")
# handle the sign-in alert
try:
# wait up to 20 seconds for the sign-in alert to appear
close_button = WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "[role="dialog"] button[aria-label="Dismiss sign-in info."]"))
)
# click the close button
close_button.click()
except e:
print("Sign-in modal did not appear, continuing...")
# where to store the scraped data
items = []
# select all property items on the page
property_items = driver.find_elements(By.CSS_SELECTOR, "[data-testid="property-card"]")
# iterate over the property items and
# extract data from them
for property_item in property_items:
# scraping logic...
url = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "a[data-testid="property-card-desktop-single-image"]").get_attribute("href"))
image = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "img[data-testid="image"]").get_attribute("src"))
title = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="title"]").text)
address = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="address"]").text)
distance = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="distance"]").text)
review_score = None
review_count = None
review_text = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="review-score"]").text)
if review_text is not None:
# split the review string by n
parts = review_text.split("n")
# process each part
for part in parts:
part = part.strip()
# check if this part is a number (potential review score)
if part.replace(".", "", 1).isdigit():
review_score = float(part)
# check if it contains the "reviews" string
elif "reviews" in part:
# extract the number before "reviews"
review_count = int(part.split(" ")[0].replace(",", ""))
decription = handle_no_such_element_exception(lambda: property_item.find_element(By.CSS_SELECTOR, "[data-testid="recommended-units"]").text)
price_element = handle_no_such_element_exception(lambda: (property_item.find_element(By.CSS_SELECTOR, "[data-testid="availability-rate-information"]")))
if price_element is not None:
original_price = handle_no_such_element_exception(lambda: (
price_element.find_element(By.CSS_SELECTOR, "[aria-hidden="true"]:not([data-testid])").text.replace(",", "")
))
price = handle_no_such_element_exception(lambda: (
price_element.find_element(By.CSS_SELECTOR, "[data-testid="price-and-discounted-price"]").text.replace(",", "")
))
# populate a new item with the scraped data
item = {
"url": url,
"image": image,
"title": title,
"address": address,
"distance": distance,
"review_score": review_score,
"review_count": review_count,
"decription": decription,
"original_price": original_price,
"price": price
}
# add the new item to the list of scraped items
items.append(item)
# specify the name of the output CSV file
output_file = "properties.csv"
# export the items list to a CSV file
with open(output_file, mode="w", newline="", encoding="utf-8") as file:
#create a CSV writer object
writer = csv.DictWriter(file, fieldnames=["url", "image", "title", "address", "distance", "review_score", "review_count", "decription", "original_price", "price"])
# write the header row
writer.writeheader()
# write each item as a row in the CSV
writer.writerows(items)
# close the web driver and release its resources
driver.quit()难以置信吧?仅用大约110行代码,您就构建了一个Python Booking.com 爬取工具。
通过执行爬取脚本验证其是否正常工作。在Windows上,运行爬取器:
python scraper.py在Linux或macOS上,等效命令为:
python3 scraper.py等待脚本运行完成。一个名为 properties.csv 的文件将出现在您的项目根目录中。打开该文件以查看提取的数据:
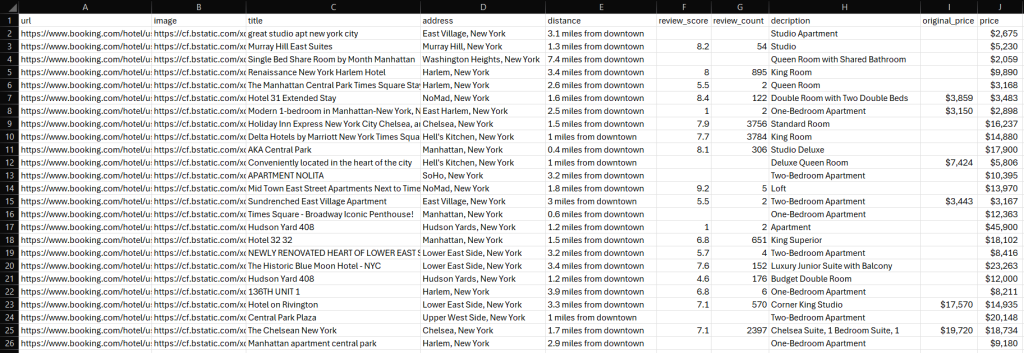
恭喜,任务完成!
总结
在本教程中,您学习了什么是 Booking.com 爬取工具以及如何使用Python构建一个。正如所示,创建一个基本脚本以自动从 Booking.com 检索数据只需几行代码。
然而,本示例并未解决您在爬取 Booking.com 时可能遇到的许多挑战。诸如反无头浏览器措施、处理用户交互以生成搜索结果以及处理无限滚动等问题可能会迅速使您的爬取操作复杂化。
寻找更简单、功能齐全且强大的爬取解决方案?试试 Bright Data的Booking爬取API!
Booking爬取API提供强大的端点以爬取公共酒店数据、评论、评分等。通过简单的API调用,您可以以JSON或HTML格式检索数据。
更喜欢预构建的解决方案?Bright Data还提供 现成的Booking.com数据集!
立即创建一个免费的Bright Data账户,试用我们的爬取API或探索我们的数据集。



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




