

在这篇关于 Scrapy Splash 的指南中,你将学习:
- Scrapy Splash 是什么
- 如何在 Python 中使用 Scrapy Splash(包含分步教程)
- 在 Scrapy 中配合 Splash 的高级爬虫技巧
- 使用该工具爬取网站时的局限性
让我们开始吧!
什么是 Scrapy Splash?
Scrapy Splash 指的是以下两个工具之间的集成:
你也许会想,为什么一个像 Scrapy 这样强大的工具还需要 Splash?其实原因在于,Scrapy 只能处理静态网站,因为它依赖 HTML 的解析能力(具体来说是 Parsel)。但是,当需要爬取动态网站时,就必须处理 JavaScript 渲染。常见的解决方案是使用自动化浏览器,而这正是 Splash 的用途。
通过 Scrapy Splash,你可以发送一种特殊的请求—即 SplashRequest—到一个 Splash 服务。此服务会完整执行页面中的 JavaScript,将其渲染完成后返回处理过的 HTML。这样,你的 Scrapy Spider 就能从动态页面中获取数据。
简而言之,如果出现以下情况,你就需要 Scrapy Splash:
- 网站使用大量 JavaScript,Scrapy 自身无法完成爬取。
- 你想要一个比 Selenium 或 Playwright 更轻量级的方案。
- 你想避免运行完整浏览器来进行爬虫带来的开销。
如果 Scrapy Splash 无法满足需求,可以考虑这些替代方案:
- Selenium:功能完备的浏览器自动化工具,可用于爬取 JavaScript 密集的网站,并支持类似 Selenium Wire 的扩展功能。
- Playwright:一个开源的浏览器自动化工具,提供一致的跨浏览器操作和强大的 API,支持多种编程语言。
- Puppeteer:一个开源的 Node.js 库,通过 DevTools Protocol(开发者工具协议)来高层次地自动化并操控 Chrome 浏览器。
在 Python 中使用 Scrapy Splash:分步教程
在本节中,你将了解如何使用 Scrapy Splash 从网站中获取数据。目标页面是著名的 “Quotes to Scrape” 网站的一个 JavaScript 渲染版本:
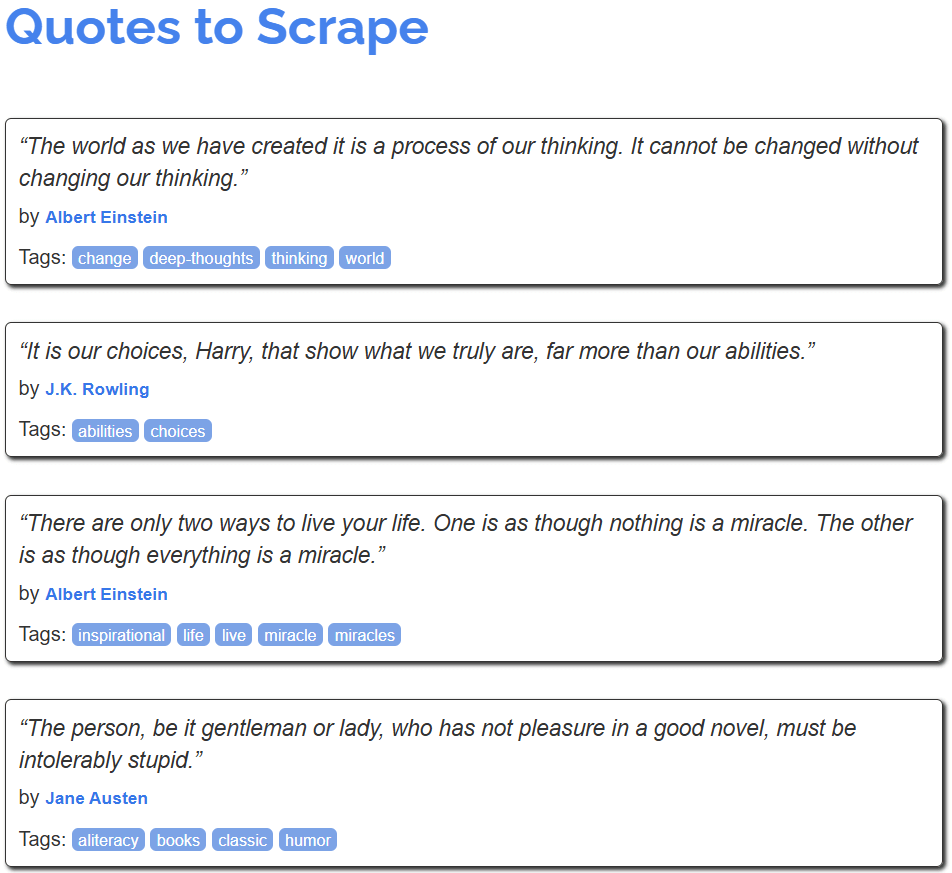
它类似常见的 “Quotes to Scrape”,但会通过无限滚动(infinite scrolling)的方式使用 AJAX 请求来动态加载数据,触发自 JavaScript 的操作。
环境需求
要在 Python 中使用 Scrapy Splash 并复现本教程,你的系统需要满足以下要求:
- Python 3.10.1 或更高版本。
- Docker 27.5.1 或更高版本。
如果这些工具尚未安装,可以参考上面的链接进行安装。
先决条件、依赖和 Splash 集成
假设你的项目主文件夹名为 scrapy_splash/。到本步骤结束时,该文件夹的结构应如下所示:
scrapy_splash/
└── venv/其中 venv/ 存放虚拟环境。可通过以下命令创建 venv/ 虚拟环境目录:
python -m venv venv在 Windows 上,激活虚拟环境的命令为:
venv\Scripts\activate在 macOS 和 Linux 上,执行:
source venv/bin/activate激活虚拟环境后,安装依赖:
pip install scrapy scrapy-splash最后一个准备步骤是通过 Docker 拉取 Splash 镜像(scrapinghub/splash):
docker pull scrapinghub/splash然后,请启动容器:
docker run -it -p 8050:8050 --rm scrapinghub/splash如需更多信息,可参考 基于不同操作系统的 Docker 集成指引。
在成功启动 Docker 容器后,等待日志输出类似下面的信息:
Server listening on http://0.0.0.0:8050这表示 Splash 服务已经可通过 http://0.0.0.0:8050 访问。用浏览器访问该 URL,应该能看到如下页面:
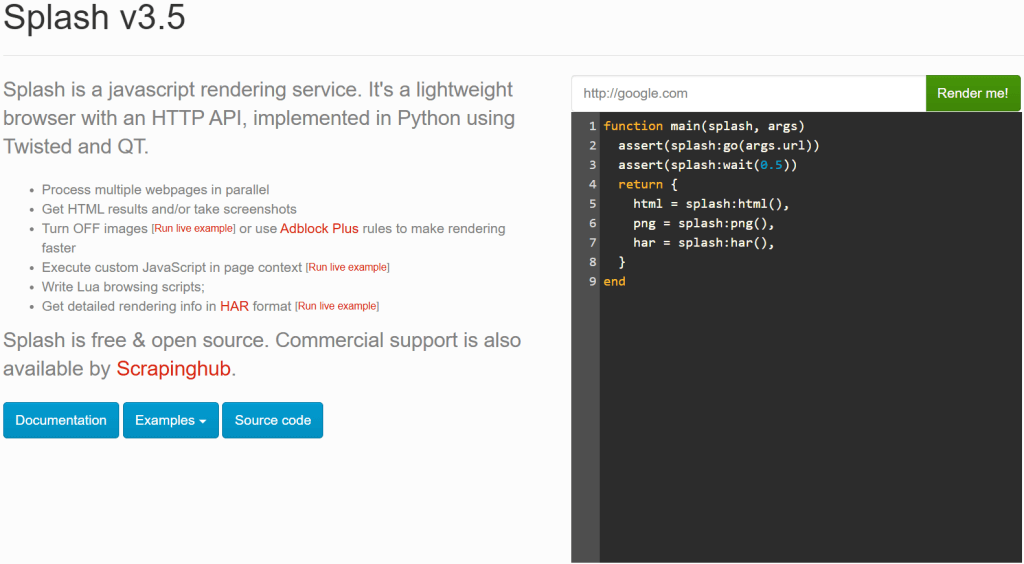
如果访问 http://0.0.0.0:8050 没显示 Splash 服务,可以尝试以下 URL:
http://localhost:8050http://127.0.0.1:8050
注意:在使用 Scrapy-Splash 的过程中,Splash 服务器的连接必须保持开启。换言之,如果你在命令行中启动了该 Docker 容器,就要保持那个终端窗口不关闭,然后在另一个终端中执行后续步骤。
现在,一切就绪,你可以开始搭配 Scrapy Splash 来爬取网页了。
第 1 步:新建一个 Scrapy 项目
在主文件夹 scrapy_splash/ 下,使用以下命令来新建一个 Scrapy 项目:
scrapy startproject quotes这样,Scrapy 会创建一个名为 quotes/ 的文件夹。里面会自动生成你所需的所有文件。最终的目录结构如下:
scrapy_splash/
├── quotes/
│ ├── quotes/
│ │ ├── spiders/
│ │ ├── __init__.py
│ │ ├── items.py
│ │ ├── middlewares.py
│ │ ├── pipelines.py
│ │ └── settings.py
│ │
│ └── scrapy.cfg
└── venv/很好,你已经成功创建了一个新的 Scrapy 项目。
第 2 步:生成 Spider
进入 quotes/ 文件夹:
cd quotes然后执行以下命令,创建一个新的 Spider 来爬取目标网站:
scrapy genspider words https://quotes.toscrape.com/scroll你会看到下面一行输出:
Created spider 'words' using template 'basic' in module:
quotes.spiders.words由此可知,Scrapy 自动在 spiders/ 文件夹里创建了一个名为 words.py 的文件,其中的初始代码如下:
import scrapy
class WordsSpider(scrapy.Spider):
name = "words"
allowed_domains = ["quotes.toscrape.com"]
start_urls = ["https://quotes.toscrape.com/scroll"]
def parse(self, response):
pass接下来,你会在其中加入从动态页面中获取数据的逻辑。
恭喜!你的 Spider 已成功生成。
第 3 步:配置 Scrapy 以使用 Splash
你需要对 Scrapy 进行设置,让它能使用 Splash 服务。为此,向 settings.py 文件中加入以下代码:
# Set the Splash local server endpoint
SPLASH_URL = "http://localhost:8050"
# Enable the Splash downloader middleware
DOWNLOADER_MIDDLEWARES = {
"scrapy_splash.SplashCookiesMiddleware": 723,
"scrapy_splash.SplashMiddleware": 725,
"scrapy.downloadermiddlewares.httpcompression.HttpCompressionMiddleware": 810,
}
# Enable the Splash deduplication argument filter
SPIDER_MIDDLEWARES = {
"scrapy_splash.SplashDeduplicateArgsMiddleware": 100,
}
上述配置中:
SPLASH_URL指定本地 Splash 服务器的端点,即 Scrapy 发送渲染请求的目标地址。DOWNLOADER_MIDDLEWARES開启特定的中间件,用于与 Splash 交互。具体地说:SplashCookiesMiddleware:让 Scrapy 在通过 Splash 请求时处理 Cookie。SplashMiddleware:让 Scrapy 使用 Splash 来进行动态内容的渲染。HttpCompressionMiddleware:调整 Scrapy 在下载内容时对 HTTP 压缩的处理方式。
SPIDER_MIDDLEWARES确保在具有相同 Splash 参数的情况下不会重复请求,有助于减少不必要的负载并提升效率。
想要了解这些配置的更多细节,可参考 Scrapy-Splash 官方文档。
现在,Scrapy 已可以连接到 Splash,并以编程方式使用它进行 JavaScript 渲染。
第 4 步:编写 Lua 脚本以渲染 JavaScript
Scrapy 已能与 Splash 集成,来渲染依赖 JavaScript 的网页(例如本教程的目标页面)。若想自定义渲染或交互逻辑,须使用 Lua 脚本。这是因为 Splash 依赖 Lua 脚本 来与页面 JavaScript 交互并以编程方式控制浏览器行为。
具体来说,在 words.py 中加入以下 Lua 脚本:
script = """
function main(splash, args)
splash:go(args.url)
-- custom rendering script logic...
return splash:html()
end
"""上述 script 变量中包含将由 Splash 在服务器执行的 Lua 逻辑,主要做了:
- 通过
splash:go()访问指定 URL。 - 通过
splash:html()返回渲染后的 HTML。
在 WordsSpider 类中调用这个 Lua 脚本,需要在 start_requests() 方法里这样写:
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(
url,
self.parse,
endpoint="execute",
args={"lua_source": script}
)上面重写了 Scrapy 默认的 start_requests() 方法,让 Scrapy Splash 可以执行 Lua 脚本并获取 JavaScript 渲染后的页面 HTML。Lua 脚本通过 "lua_source": script 参数被传给 SplashRequest()。而 endpoint="execute" 表示 Splash 会使用 “execute” 端点(稍后会详细介绍)。
别忘了先从 Scrapy Splash 中导入 SplashRequest:
from scrapy_splash import SplashRequest至此,你的 words.py 文件已拥有一个用来获取页面 JavaScript 渲染内容的正确 Lua 脚本!
第 5 步:定义数据解析逻辑
开始之前,先在目标页面中检查其中某个报价(quote)的 HTML 结构,以了解如何提取内容:

可以看到,每条引用(quote)都可通过 .quote 选取,选取后能获取:
- 从
.text获取引用文字 - 从
.author获取作者名字 - 从
.tags获取标签
以下是从目标页面提取所有引用(quote)的爬取逻辑,可通过 parse() 方法实现:
def parse(self, response):
# Retrieve CSS selectors
quotes = response.css(".quote")
for quote in quotes:
yield {
"text": quote.css(".text::text").get(),
"author": quote.css(".author::text").get(),
"tags": quote.css(".tags a.tag::text").getall()
}parse() 用于处理来自 Splash 的响应,具体做了:
- 通过 CSS 选择器
".quote"获取所有带有quote类的div元素。 - 遍历每个
quote元素,提取其文本、作者和标签信息。
干得好!Scrapy Splash 的爬取逻辑已经完成。
第 6 步:整合所有内容并运行
最终,words.py 文件应如下所示:
import scrapy
from scrapy_splash import SplashRequest
# Lua script for JavaScript rendering
script = """
function main(splash, args)
splash:go(args.url)
return splash:html()
end
"""
class WordsSpider(scrapy.Spider):
name = "words"
start_urls = ["https://quotes.toscrape.com/scroll"]
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(
url,
self.parse,
endpoint="execute",
args={"lua_source": script}
)
def parse(self, response):
quotes = response.css(".quote")
for quote in quotes:
yield {
"text": quote.css(".text::text").get(),
"author": quote.css(".author::text").get(),
"tags": quote.css(".tags a.tag::text").getall()
}通过以下命令运行该脚本:
scrapy crawl words预期的输出如下所示:
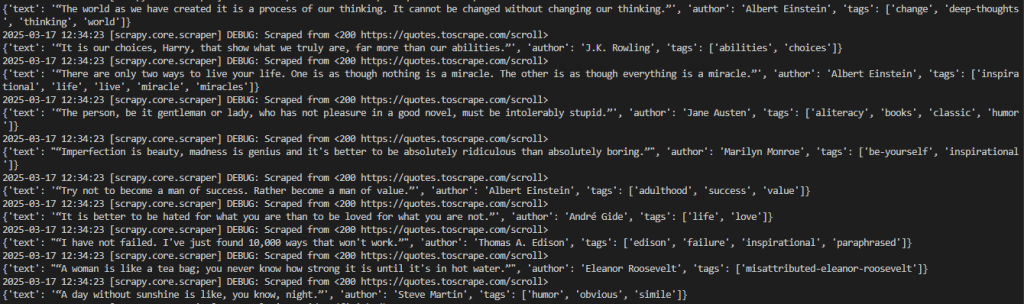
结果可更直观地呈现为:
2025-03-18 12:21:55 [scrapy.core.scraper] DEBUG: Scraped from <200 https://quotes.toscrape.com/scroll>
{'text': '“The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”', 'author': 'Albert Einstein', 'tags': ['change', 'deep-thoughts', 'thinking', 'world']}
2025-03-18 12:21:55 [scrapy.core.scraper] DEBUG: Scraped from <200 https://quotes.toscrape.com/scroll>
{'text': '“It is our choices, Harry, that show what we truly are, far more than our abilities.”', 'author': 'J.K. Rowling', 'tags': ['abilities', 'choices']}
# omitted for brevity...
2025-03-18 12:21:55 [scrapy.core.engine] INFO: Closing spider (finished)可以看到输出中包含了我们需要的数据。
注意,如果你移除 WordsSpider 类中的 start_requests() 方法,Scrapy 将不会返回任何数据。因为不使用 Splash 时,Scrapy 并不能爬取需要 JavaScript 渲染的页面。
恭喜!你完成了第一个 Scrapy Splash 项目。
关于 Splash 的一点说明
Splash 通过 HTTP 与外部通信,因此你也可以直接使用任意 HTTP 客户端来访问它提供的端点,从而进行网页渲染。常用的端点包括:
execute:执行自定义 Lua 渲染脚本并返回结果。render.html:返回 JavaScript 渲染后页面的 HTML。render.png:返回 JavaScript 渲染后页面的 PNG 格式图像。render.jpeg:返回 JavaScript 渲染后页面的 JPEG 格式图像。render.har:以 HAR 格式返回 Splash 与网站交互的信息。render.json:返回一个 JSON 格式的字典,包含对页面的 JavaScript 渲染信息。可在参数中指定是否包含 HTML、PNG 等。
为了更好理解这些端点的工作方式,以下例子演示 render.html 端点:
# pip install requests
import requests
import json
# URL of the Splash endpoint
url = "http://localhost:8050/render.html"
# Sending a POST request to the Splash endpoint
payload = json.dumps({
"url": "https://quotes.toscrape.com/scroll" # URL of the page to render
})
headers = {
"content-type": "application/json"
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)上述代码:
- 将本地 Splash 实例的
render.html端点设为目标。 - 把要爬取的页面地址放在
payload中。
运行这段代码,可得到整个页面渲染后的 HTML:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Quotes to Scrape</title>
<link rel="stylesheet" href="/static/bootstrap.min.css">
<link rel="stylesheet" href="/static/main.css">
</head>
<body>
<!-- omitted for brevity... -->
</body>
</html>
虽然 Splash 本身就能独立处理 JavaScript 渲染后的 HTML,但和 Scrapy Splash 一起配合 SplashRequest,会让我们在爬虫开发中更便捷。
Scrapy Splash:高级爬虫技巧
在前面的章节里,你已经完成了一个整合 Splash 的 Scrapy 基础示例。现在,让我们再来看看使用 Scrapy Splash 进行高级爬虫的一些技巧吧!
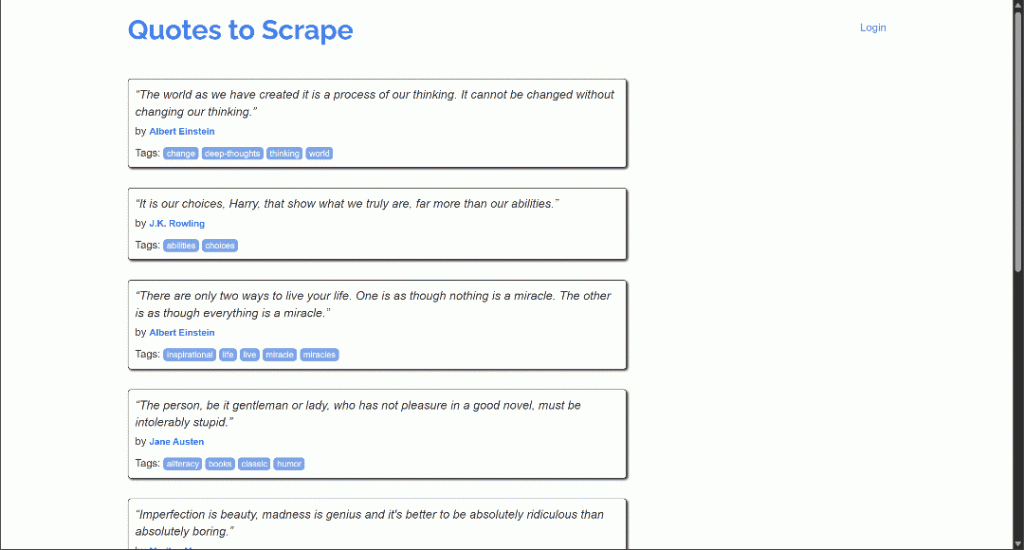
处理高级滚动场景
本教程的目标页面通过无限滚动(infinite scrolling)和 AJAX 方式来动态加载更多引用:
若要处理此类无限滚动,你需要修改 Lua 脚本,示例脚本如下:
script = """
function main(splash, args)
local scroll_delay = 1.0 -- Time to wait between scrolls
local max_scrolls = 10 -- Maximum number of scrolls to perform
local scroll_to = 1000 -- Pixels to scroll down each time
splash:go(args.url)
splash:wait(scroll_delay)
local scroll_count = 0
while scroll_count < max_scrolls do
scroll_count = scroll_count + 1
splash:runjs("window.scrollBy(0, " .. scroll_to .. ");")
splash:wait(scroll_delay)
end
return splash:html()
end
"""该脚本中:
max_scrolls决定滚动次数上限。实际应用中可根据想获取的内容量来调整。scroll_to指定每次向下滚动的像素值,也可根据页面的行为需要进行修改。splash:runjs()可以执行window.scrollBy()这个 JavaScript 函数,让浏览器窗口向下滚动。splash:wait()则是让脚本在获取新内容前先等待一段时间。这段时间(以秒为单位)由scroll_delay控制。
更直观地说,上面这段 Lua 脚本是在模拟若干次页面向下滚动的操作,以便在无限滚动页面场景中完整加载所有数据。
words.py 文件可以写成如下:
import scrapy
from scrapy_splash import SplashRequest
# Lua script for infinite scrolling
script = """
function main(splash, args)
local scroll_delay = 1.0 -- Time to wait between scrolls
local max_scrolls = 10 -- Maximum number of scrolls to perform
local scroll_to = 1000 -- Pixels to scroll down each time
splash:go(args.url)
splash:wait(scroll_delay)
local scroll_count = 0
while scroll_count < max_scrolls do
scroll_count = scroll_count + 1
splash:runjs("window.scrollBy(0, " .. scroll_to .. ");")
splash:wait(scroll_delay)
end
return splash:html()
end
"""
class WordsSpider(scrapy.Spider):
name = "words"
start_urls = ["https://quotes.toscrape.com/scroll"]
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(
url,
self.parse,
endpoint="execute",
args={"lua_source": script}
)
def parse(self, response):
# Retrieve CSS selectors
quotes = response.css("div.quote")
for quote in quotes:
yield {
"text": quote.css("span.text::text").get(),
"author": quote.css("span small.author::text").get(),
"tags": quote.css("div.tags a.tag::text").getall()
}
然后使用以下命令运行:
scrapy crawl words此时,爬虫会根据 max_scrolls 的设置滚动若干次,并得到更多数据。结果如下所示:
可以看到,这次的输出比之前要多了许多引用,说明页面已被成功滚动加载,而且数据也被正常爬取。
恭喜!你已经学会了如何在 Scrapy Splash 中处理无限滚动。
等待元素加载(Wait For Element)
一些网页会通过动态方式加载或渲染节点,这意味着最终的 DOM 可能需要一定时间才呈现到页面上。为了避免在节点尚未出现时就尝试抓取而导致出错,通常可以先等待特定元素加载。
例如,在此示例中,我们打算等待第一条引用的文本区域出现:

可以编写类似下面的 Lua 脚本:
script = """
function main(splash, args)
splash:go(args.url)
while not splash:select(".text") do
splash:wait(0.2)
print("waiting...")
end
return { html=splash:html() }
end
"""这个脚本里,while 循环判断是否存在 .text 元素,如果不存在就等待 0.2 秒再继续检测。判断是否存在该元素,可使用 splash:select() 方法。
固定时间等待(Wait For Time)
由于大量动态内容的页面往往需要一定时间来渲染,你也可以通过 splash:wait() 方法来让脚本先等待几秒再进行后续操作:
script = """
function main(splash, args)
splash:wait(args.wait)
splash:go(args.url)
return { html=splash:html() }
end
"""此处,脚本需要等待的秒数会通过 Lua script 参数指定。
例如,在调用 SplashRequest() 时传递 "wait": 2.0,表示等待 2 秒:
import scrapy
from scrapy_splash import SplashRequest
script = """
function main(splash, args)
splash:wait(args.wait)
splash:go(args.url)
return { html=splash:html() }
end
"""
class WordsSpider(scrapy.Spider):
name = "words"
start_urls = ["https://quotes.toscrape.com/scroll"]
def start_requests(self):
for url in self.start_urls:
yield SplashRequest(
url,
self.parse,
endpoint="execute",
args={"lua_source": script, "wait": 2.0} # Waiting for 2 seconds
)
# ...注意:在本地测试中,固定等待(splash:wait())可以保证页面加载完再执行下一步。但在生产环境中,这种方式会引入不必要的延迟,影响性能和可扩展性。此外,你也无法在事先确定需要等待多长时间才合适。
至此,你已掌握了在 Scrapy Splash 中如何实现固定时间等待。
使用 Scrapy Splash 的局限性
通过本教程,你了解了如何在不同场景下结合 Scrapy Splash 来抓取数据。虽然这种集成方式十分直观,但也存在一些缺陷。
例如,使用 Splash 需要额外运行一个 Docker 容器,增加了爬虫基础设施的复杂度。此外,Splash 的 Lua 脚本 API 相较于 Puppeteer 和 Playwright 这些现代化工具而言,功能相对有限。
另外,与所有 无头浏览器 一样,Splash 也可能被一些反爬机制识别到自动化浏览器的特征而被阻挡。
如果你想绕过这些麻烦,可以尝试 Scraping Browser——一种专为高并发大规模爬虫而设计的云端浏览器。它内置了验证码(CAPTCHA)处理、浏览器指纹管理和防反爬机制,可以帮助你免于因封禁而导致的烦恼。
总结
本文介绍了 Scrapy Splash 是什么以及它是如何工作的。我们先从基本示例入手,再逐步探索了更复杂的爬取场景。
同时,你也发现了该工具的一些局限性,尤其是容易受到反爬机制的监测和阻断。若需更强大的解决方案,可尝试使用 Scraping Browser,这是 Bright Data 提供的产品之一。除此之外,还有多种可选的 Bright Data 爬虫解决方案:
- 代理服务:四种不同类型的代理可帮助你绕过地理位置限制,包括超过 7200 万的住宅 IP。
- 网络抓取 API:针对 100 多个热门网站的专用端点,可提取新鲜且结构化的网页数据。
- 搜索引擎结果页 API:专门为搜索引擎结果页面(SERP)提供解锁管理、并抓取指定页面的解决方案。
立即注册 Bright Data 并开始免费试用,亲自体验我们的爬虫方案。




