

在本篇 Goutte 网页抓取指南中,你将学习:
- 什么是 PHP 库 Goutte
- 如何通过分步教程使用它进行网页抓取
- Goutte 在网页抓取方面的替代方案
- 此方法的局限性以及可能的解决办法
让我们开始吧!
什么是 Goutte?
Goutte 是一个用于屏幕抓取和网络爬虫的 PHP 库,提供了一个直观的 API 用于浏览网站并从 HTML/XML 响应中提取数据。它内置了 HTTP 客户端和 HTML 解析功能,允许你通过 HTTP 请求获取网页并对其进行处理以进行数据抓取。
注意:自 2023 年 4 月 1 日起,Goutte 不再维护,现在被视为已弃用。然而,就目前而言,它仍能可靠地运行。
如何使用 Goutte 进行网页抓取:分步指南
按照以下分步教程,看看如何使用 Goutte 从 “Hockey Teams” 站点提取数据:
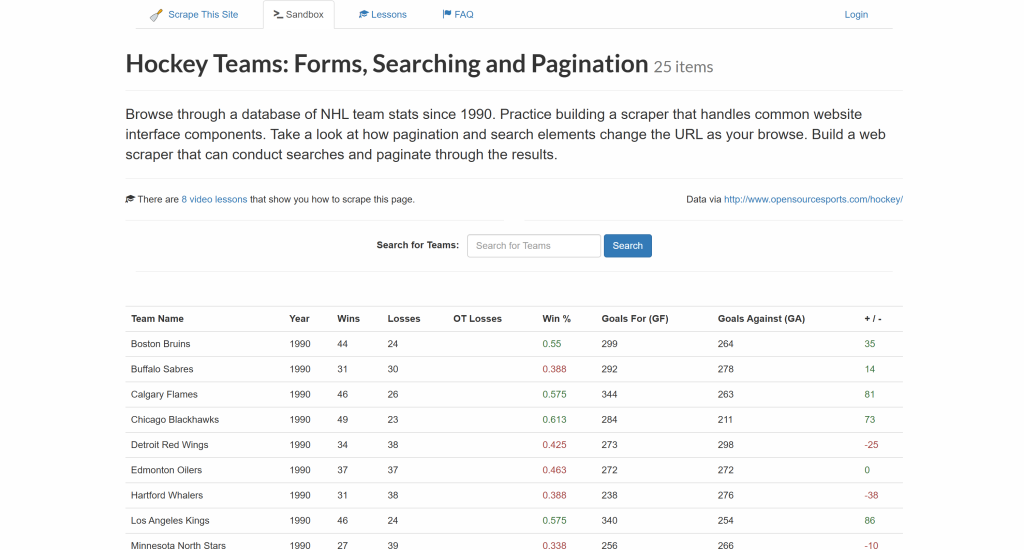
目标是从上方表格中提取数据,并将其导出到一个 CSV 文件中。
是时候来学习如何使用 Goutte 进行网页抓取了!
第 1 步:项目设置
在开始之前,请确保你的系统满足 Goutte 的要求——PHP 7.1 或更高版本。要检查当前的 PHP 版本,请运行以下命令:
php -v输出结果应类似于:
PHP 8.4.3 (cli) (built: Jan 19 2026 14:20:58) (NTS)
Copyright (c) The PHP Group
Zend Engine v4.4.3, Copyright (c) Zend Technologies
with Zend OPcache v8.4.3, Copyright (c), by Zend Technologies如果你的 PHP 版本低于 7.1,则需要在继续之前升级 PHP。
接下来要记住的是,Goutte 将通过 Composer(一个 PHP 的依赖管理工具)进行安装。如果系统还没有安装 Composer,请前往官方下载页面并按照安装说明进行操作。
现在,为你的 Goutte 项目创建一个新目录并在终端导航进去:
mkdir goutte-parser
cd goutte-parser然后使用 composer init 命令在该文件夹中初始化一个 Composer 项目:
composer initComposer 会提示你输入一些项目细节,比如包名和描述。可以使用默认选项,也可根据需求自由定制。
接下来,用你喜欢的 PHP IDE 打开该项目文件夹。可选工具包括安装 PHP 扩展的 Visual Studio Code或 IntelliJ WebStorm 等。
在项目文件夹中创建一个空的 index.php 文件,项目结构应如下所示:
php-html-parser/
├── vendor/
├── composer.json
└── index.php打开 index.php 并添加以下代码来导入 Composer 库:
<?php
require_once __DIR__ . "/vendor/autoload.php";
// scraping logic...后续的 Goutte 抓取逻辑将写在这个文件中。
现在,可以使用以下命令执行脚本:
php index.php很好!到这里,即可准备好在 PHP 中使用 Goutte 进行数据抓取。
第 2 步:安装并配置 Goutte
使用下面的 Composer 命令安装 Goutte:
composer require fabpot/goutte这条命令会将 fabpot/goutte 依赖添加到你的 composer.json 文件中,内容会变成:
"require": {
"fabpot/goutte": "^4.0"
}在 index.php 中,通过添加下面的代码导入 Goutte:
use GoutteClient;这样就能使用 Goutte 的 HTTP 客户端,你可以通过它连接到目标页面、解析其 HTML,并从中提取数据。下一步就来看看该怎么做吧!
第 3 步:获取目标页面的 HTML
首先,创建一个新的 Goutte HTTP 客户端:
$client = new Client();在底层,Goutte 的 Client 类实际上只是对 Symfony BrowserKitHttpBrowser 组件的封装。可参见我们关于使用 Laravel 进行网页抓取的文章。
随后,将目标网页 URL 存储到一个变量中,并使用 request() 方法来获取其内容:
$url = "https://www.scrapethissite.com/pages/forms/";
$crawler = $client->request("GET", $url);这会向网页发送一个 GET 请求,获取其 HTML 文档,并为你进行解析。具体来说,$crawler 对象提供了对 Symfony DomCrawler 组件所有方法的访问能力。你将使用 $crawler 来浏览并提取页面数据。
很好!现在你已经拥有了进行 Goutte 网页抓取所需的一切。
第 4 步:准备抓取所需数据
在提取数据之前,你必须先熟悉目标页面的 HTML 结构。
首先,记住我们关注的数据是放在表格行中的。由于这个表格含有多行,用数组来存储抓取到的数据是一个不错的选择:
$teams = [];然后,要了解该表格的 HTML 结构。打开目标页面,右键单击表格并选择“Inspect”(检查)选项:
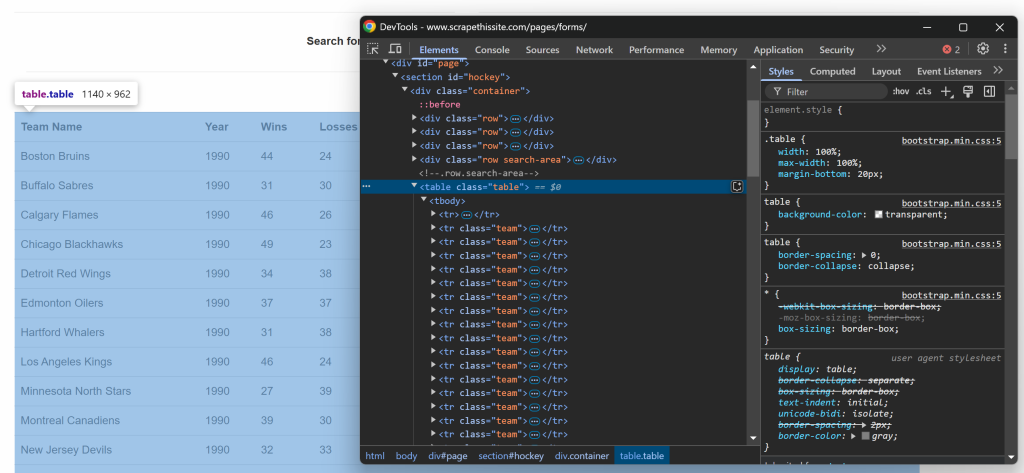
在浏览器开发者工具中,你可以看到表格有一个 table 的 class,且被放在一个 id=``"``hockey``" 的 <section> 元素里面。这表示你可以使用如下 CSS 选择器来定位表格:
#hockey .table利用 $crawler->filter() 方法并应用该 CSS 选择器获取表格节点:
$table = $crawler->filter("#hockey .table");接着,每一行由一个带有 team class 的 <tr> 元素表示。选择所有这些行并遍历它们,为提取数据做好准备:
$table->filter("tr.team")->each(function ($tr) use (&$teams) {
// data extraction logic...
});到这里就更好了!你已经实现了使用 Goutte 进行数据抓取的基本框架。
第 5 步:实现数据提取逻辑
像之前一样,这次要进一步检查表格中的每一行:
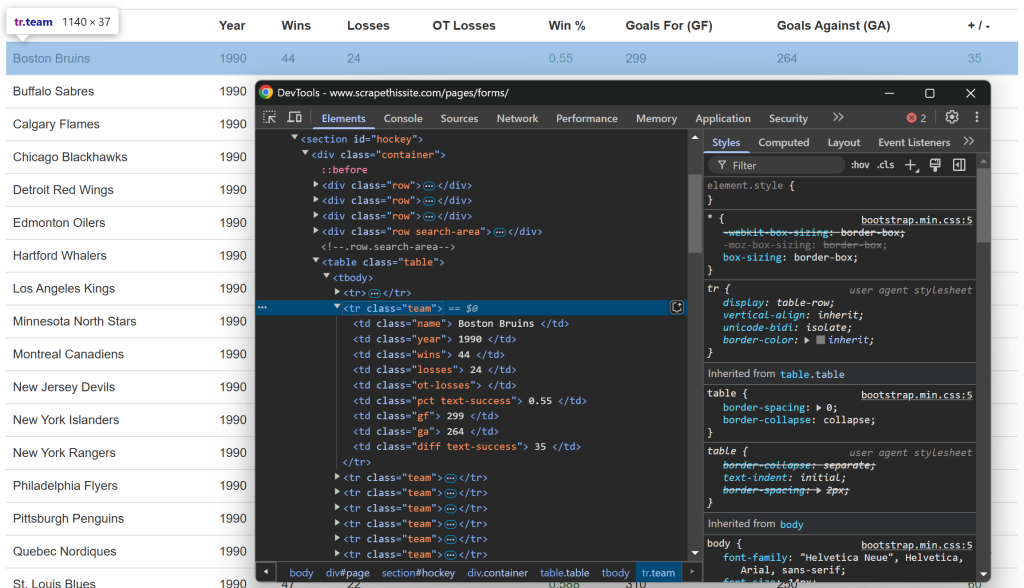
可以注意到,每一行包含以下信息,每个数据放在对应的列标签里:
- 球队名称 → 在
.name元素中 - 赛季年份 → 在
.year元素中 - 胜场数 → 在
.wins元素中 - 负场数 → 在
.losses元素中 - 加时赛负场数 → 在
.ot-losses元素中 - 胜率 → 在
.pct元素中 - 进球数(Goals For – GF)→ 在
.gf元素中 - 失球数(Goals Against – GA)→ 在
.ga元素中 - 净胜球数 → 在
.diff元素中
若要获取某项信息,需要执行以下两步:
- 使用
filter()选择相应的 HTML 元素 - 使用
text()方法提取其文本内容,并用trim()去除额外空格
例如,你可以用下面的代码抓取球队名称:
$teamElement = $tr->filter(".name");
$team = trim($teamElement->text());在此基础上,将这一逻辑扩展到其它列:
$yearElement = $tr->filter(".year");
$year = trim($yearElement->text());
$winsElement = $tr->filter(".wins");
$wins = trim($winsElement->text());
$lossesElement = $tr->filter(".losses");
$losses = trim($lossesElement->text());
$otLossesElement = $tr->filter(".ot-losses");
$otLosses = trim($otLossesElement->text());
$pctElement = $tr->filter(".pct");
$pct = trim($pctElement->text());
$gfElement = $tr->filter(".gf");
$gf = trim($gfElement->text());
$gaElement = $tr->filter(".ga");
$ga = trim($gaElement->text());
$diffElement = $tr->filter(".diff");
$diff = trim($diffElement->text());在从行中提取完所需数据之后,将这些数据存储到 $teams 数组中:
$teams[] = [
"team" => $team,
"year" => $year,
"wins" => $wins,
"losses" => $losses,
"ot_losses" => $otLosses,
"win_perc" => $pct,
"goals_for" => $gf,
"goals_against" => $ga,
"goal_diff" => $diff
];遍历所有行后,$teams 数组将会包含:
Array
(
[0] => Array
(
[team] => Boston Bruins
[year] => 1990
[wins] => 44
[losses] => 24
[ot_losses] =>
[win_perc] => 0.55
[goals_for] => 299
[goals_against] => 264
[goal_diff] => 35
)
// ...
[24] => Array
(
[team] => Chicago Blackhawks
[year] => 1991
[wins] => 36
[losses] => 29
[ot_losses] =>
[win_perc] => 0.45
[goals_for] => 257
[goals_against] => 236
[goal_diff] => 21
)
)非常好!使用 Goutte 进行数据抓取的过程已经完成。
第 6 步:实现爬虫逻辑
接下来,别忘了目标站点使用分页来展示数据,每次只显示一部分。在表格下方,有一个分页元素,提供了所有页面的链接:

因此,你可以用以下简单步骤在抓取脚本里处理分页:
- 选择分页链接元素
- 提取所有分页页面的 URL
- 访问每个页面并应用前面设计的抓取逻辑
先检查分页链接元素:
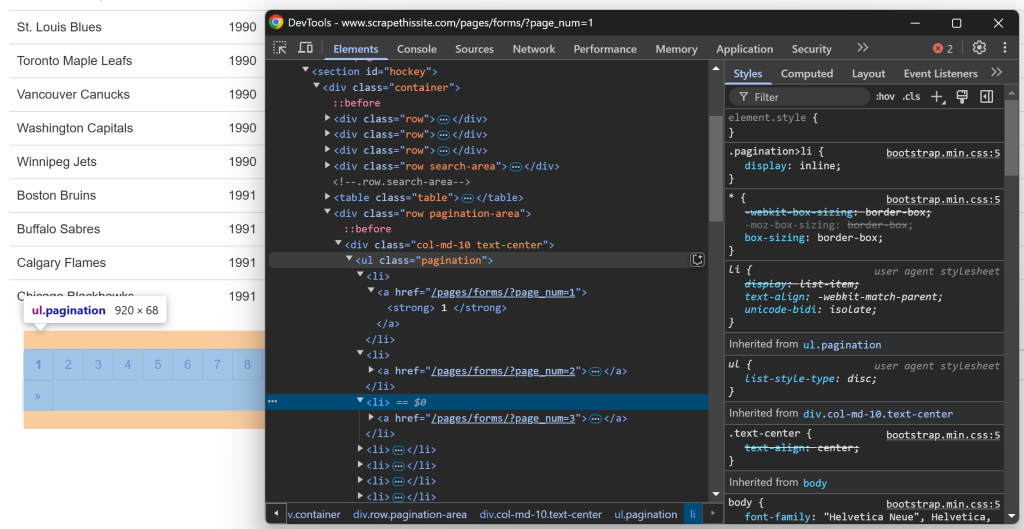
你可以使用下面的 CSS 选择器来选中所有分页链接:
.pagination li a为了实现第 2 步并收集所有分页的 URL,可以使用以下逻辑:
$urls = [$url];
// select the pagination link elements
$crawler->filter(".pagination li a")->each(function ($a) use (&$urls) {
// construct the absolute URL
$url = "https://www.scrapethissite.com" . $a->attr("href");
// add the pagination URL to the list only if it is not already present
if (!in_array($url, $urls)) {
$urls[] = $url;
}
});这里先初始化了要抓取页面链接列表,并将首页的 URL 存入 $urls。随后选择所有分页元素进行遍历,只将还不存在于 $urls 中的新链接添加进去。因为页面上使用的是相对链接,所以必须先转换成绝对链接再放到列表里。
由于分页处理只需要执行一次,并不直接与数据提取绑定,所以最好将以上逻辑封装在函数中:
function getPaginationUrls($client, $url)
{
// connect to the first page of the site
$crawler = $client->request("GET", $url);
// initialize the list of URLs to scrape with the current URL
$urls = [$url];
// select the pagination link elements
$crawler->filter(".pagination li a")->each(function ($a) use (&$urls) {
// construct the absolute URL
$url = "https://www.scrapethissite.com" . $a->attr("href");
// add the pagination URL to the list only if it is not already present
if (!in_array($url, $urls)) {
$urls[] = $url;
}
});
return $urls;
}可以像这样调用 getPaginationUrls() 函数:
$urls = getPaginationUrls($client, "https://www.scrapethissite.com/pages/forms/?page_num=1");执行完成后,$urls 将包含所有分页页面的 URL:
Array
(
[0] => https://www.scrapethissite.com/pages/forms/?page_num=1
[1] => https://www.scrapethissite.com/pages/forms/?page_num=2
[2] => https://www.scrapethissite.com/pages/forms/?page_num=3
[3] => https://www.scrapethissite.com/pages/forms/?page_num=4
[4] => https://www.scrapethissite.com/pages/forms/?page_num=5
[5] => https://www.scrapethissite.com/pages/forms/?page_num=6
[6] => https://www.scrapethissite.com/pages/forms/?page_num=7
[7] => https://www.scrapethissite.com/pages/forms/?page_num=8
[8] => https://www.scrapethissite.com/pages/forms/?page_num=9
[9] => https://www.scrapethissite.com/pages/forms/?page_num=10
[10] => https://www.scrapethissite.com/pages/forms/?page_num=11
[11] => https://www.scrapethissite.com/pages/forms/?page_num=12
[12] => https://www.scrapethissite.com/pages/forms/?page_num=13
[13] => https://www.scrapethissite.com/pages/forms/?page_num=14
[14] => https://www.scrapethissite.com/pages/forms/?page_num=15
[15] => https://www.scrapethissite.com/pages/forms/?page_num=16
[16] => https://www.scrapethissite.com/pages/forms/?page_num=17
[17] => https://www.scrapethissite.com/pages/forms/?page_num=18
[18] => https://www.scrapethissite.com/pages/forms/?page_num=19
[19] => https://www.scrapethissite.com/pages/forms/?page_num=20
[20] => https://www.scrapethissite.com/pages/forms/?page_num=21
[21] => https://www.scrapethissite.com/pages/forms/?page_num=22
[22] => https://www.scrapethissite.com/pages/forms/?page_num=23
[23] => https://www.scrapethissite.com/pages/forms/?page_num=24
)完美!这样你就用 Goutte 实现了网页爬取的功能。
第 7 步:从所有页面抓取数据
现在,所有页面的 URL 都存储在一个数组里,你可以通过以下操作实现对它们的依次抓取:
- 遍历这个 URL 列表
- 获取并解析每个 URL 对应的 HTML 内容
- 提取需要的数据
- 将抓取到的信息保存到
$teams数组中
可以按如下方式实现:
$teams = [];
// iterate over all pages and scrape them all
foreach ($urls as $_ => $url) {
// logging which page the scraper is currently working on
echo "Scraping webpage "$url"...n";
// retrieve the HTML of the current page and parse it
$crawler = $client->request("GET", $url);
// $table = $crawler-> ...
// data extraction logic
}注意,这里的 echo 用来记录当前脚本正在处理哪个页面,这对大规模执行时查看脚本进度很有帮助。
很好!只剩把抓取到的数据导出到人类可读的格式(比如 CSV)了。
第 8 步:将抓取到的数据导出到 CSV
现在,抓取的数据都在 $teams 数组里。为了让你的团队或其他人更方便地使用和分析,可以将其导出为 CSV 文件。
PHP 内置了用于导出 CSV 的函数 fputcsv()。可用它来将抓取到的数据写入名为 teams.csv 的文件:
// open the output file for writing
$file = fopen("teams.csv", "w");
// write the header row
fputcsv($file, ["Team Name", "Year", "Wins", "Losses", "OT Losses", "Win %","Goals For (GF)", "Goals Against (GA)", "+ / -"]);
// append each team as a new row
foreach ($teams as $team) {
fputcsv($file, [
$team["team"],
$team["year"],
$team["wins"],
$team["losses"],
$team["ot_losses"],
$team["win_perc"],
$team["goals_for"],
$team["goals_against"],
$team["goal_diff"]
]);
}
// close the file
fclose($file);大功告成!这段 Goutte 抓取器已经可以正常工作了。
第 9 步:整合所有内容
你的 Goutte 网页抓取脚本应当包含如下内容:
<?php
require_once __DIR__ . "/vendor/autoload.php";
use GoutteClient;
function getPaginationUrls($client, $url)
{
// connect to the first page of the site
$crawler = $client->request("GET", $url);
// initialize the list of URLs to scrape with the current URL
$urls = [$url];
// select the pagination link elements
$crawler->filter(".pagination li a")->each(function ($a) use (&$urls) {
// construct the absolute URL
$url = "https://www.scrapethissite.com" . $a->attr("href");
// add the pagination URL to the list only if it is not already present
if (!in_array($url, $urls)) {
$urls[] = $url;
}
});
return $urls;
}
// initialize a new Goutte HTTP client
$client = new Client();
// get the URLs of the pages to scrape
$urls = getPaginationUrls($client, "https://www.scrapethissite.com/pages/forms/?page_num=1");
// where to store the scraped data
$teams = [];
// iterate over all pages and scrape them all
foreach ($urls as $_ => $url) {
// logging which page the scraper is currently working on
echo "Scraping webpage "$url"...n";
// retrieve the HTML of the current page and parse it
$crawler = $client->request("GET", $url);
// select the table element with the data of interest
$table = $crawler->filter("#hockey .table");
// iterate over each row and extract data from them
$table->filter("tr.team")->each(function ($tr) use (&$teams) {
// data extraction logic
$teamElement = $tr->filter(".name");
$team = trim($teamElement->text());
$yearElement = $tr->filter(".year");
$year = trim($yearElement->text());
$winsElement = $tr->filter(".wins");
$wins = trim($winsElement->text());
$lossesElement = $tr->filter(".losses");
$losses = trim($lossesElement->text());
$otLossesElement = $tr->filter(".ot-losses");
$otLosses = trim($otLossesElement->text());
$pctElement = $tr->filter(".pct");
$pct = trim($pctElement->text());
$gfElement = $tr->filter(".gf");
$gf = trim($gfElement->text());
$gaElement = $tr->filter(".ga");
$ga = trim($gaElement->text());
$diffElement = $tr->filter(".diff");
$diff = trim($diffElement->text());
// add the scraped data to the array
$teams[] = [
"team" => $team,
"year" => $year,
"wins" => $wins,
"losses" => $losses,
"ot_losses" => $otLosses,
"win_perc" => $pct,
"goals_for" => $gf,
"goals_against" => $ga,
"goal_diff" => $diff
];
});
}
// open the output file for writing
$file = fopen("teams.csv", "w");
// write the header row
fputcsv($file, ["Team Name", "Year", "Wins", "Losses", "OT Losses", "Win %","Goals For (GF)", "Goals Against (GA)", "+ / -"]);
// append each team as a new row
foreach ($teams as $team) {
fputcsv($file, [
$team["team"],
$team["year"],
$team["wins"],
$team["losses"],
$team["ot_losses"],
$team["win_perc"],
$team["goals_for"],
$team["goals_against"],
$team["goal_diff"]
]);
}
// close the file
fclose($file);使用以下命令运行它:
php index.php抓取器会输出类似如下的日志:
Scraping webpage "https://www.scrapethissite.com/pages/forms/?page_num=1"...
// omitted for brevity..
Scraping webpage "https://www.scrapethissite.com/pages/forms/?page_num=24"...脚本执行完毕后,项目文件夹中会出现一个包含如下数据的 teams.csv 文件:
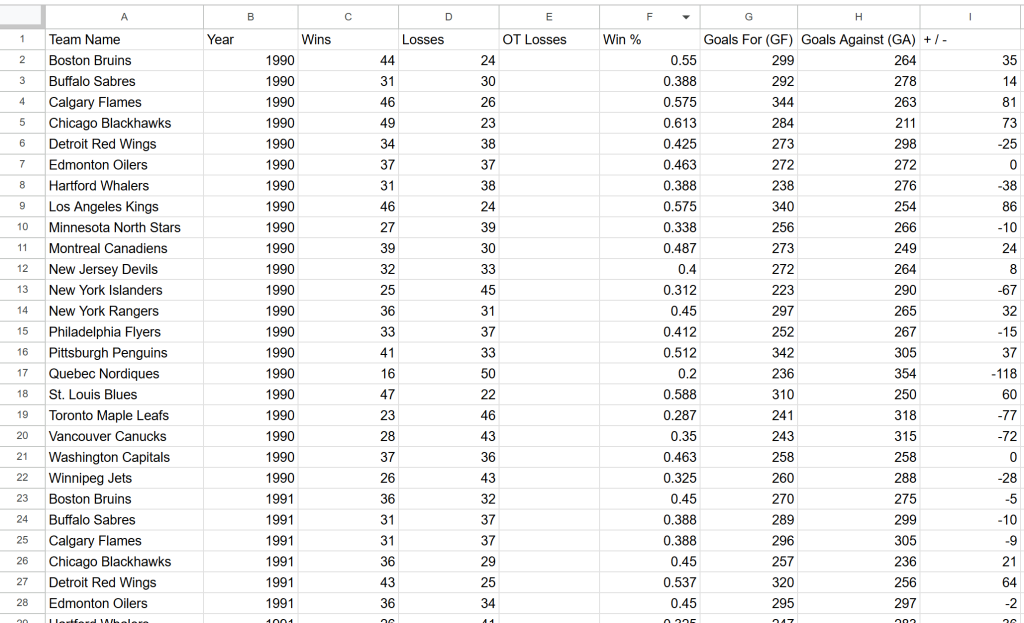
大功告成!目标站点中的数据已以结构化格式呈现。
PHP Goutte 库在网页抓取方面的替代方案
正如本文开头所述,Goutte 已弃用且不再维护。这意味着你应该考虑使用其他解决方案。
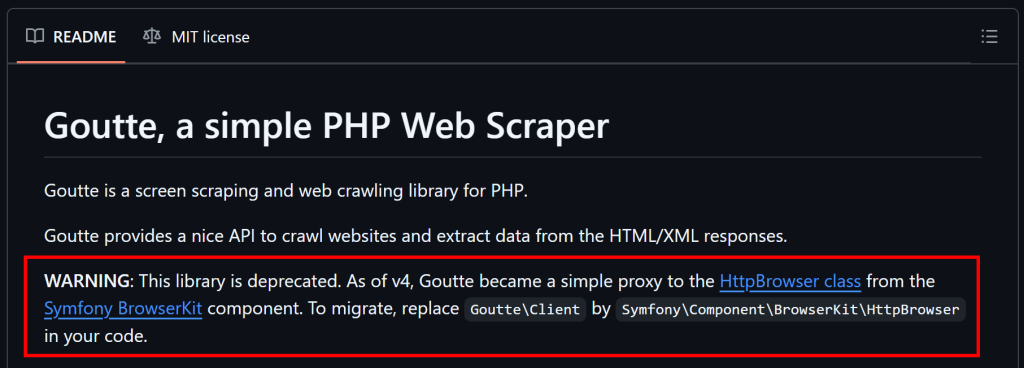
在 GitHub 上的说明显示,自从 Goutte v4 开始,功能本质上已经变成了对 Symfony 的 HttpBrowser 类的代理,因此最好迁移到此类上。要进行迁移,你只需安装以下库:
composer require symfony/browser-kit symfony/http-client然后,将:
use GoutteClient;替换为:
use SymfonyComponentBrowserKitHttpBrowser;最后,从项目中移除 Goutte 依赖即可。底层 API 与之前相同,因此你的脚本改动不会太大。
除了 Goutte,你也可以将 HTTP 客户端与 HTML 解析器配合使用,推荐的替代方案有:
- Guzzle 或 cURL 用于发送 HTTP 请求。
DomHTMLDocument、Simple HTML DOM Parser 或DomCrawler用于在 PHP 中解析 HTML。
这些替代方案可以为你提供更大的灵活性,并确保你的网页抓取脚本在将来更易维护。
此网页抓取方法的局限性
Goutte 虽然功能强大,但在使用它进行网页抓取时,也会碰到以下几个局限:
其中一些局限可通过使用替代库或其他方法来减轻,详情可查阅我们关于PHP 网页抓取的指南。但无论如何,在遇到反爬措施时,仅凭传统抓取方法仍可能无法突破,这时就需要使用 Web Unlocker API。
Web Unlocker API 是专门设计给爬虫使用的端点,可绕过反爬虫机制并获取网页的原始 HTML。它使用起来就像发起一个 API 调用,然后解析返回内容一样简单。该方案可以与 Goutte(或者 Symfony 近期更新的相关组件)无缝配合,正如本文所示。
总结
在本指南中,你了解了 Goutte 的功能以及使用它进行网页抓取的分步教程。由于该库已被弃用,你也了解了它的一些替代方案。
无论你选择哪一个 PHP 抓取库,最大的问题在于大多数网站使用了反机器人和反爬虫技术来保护它们的数据。这些机制可以检测并阻断自动化请求,从而使传统的抓取方法失效。
好在,Bright Data 提供了一系列解决方案来规避这些难题:
- 网络解锁器:可自动绕过各种反爬措施并返回干净的 HTML,只需最少的配置。
- 抓取浏览器:基于云端且可控制的浏览器,带有 JavaScript 渲染功能。它会自动处理验证码、浏览器指纹、重试等问题,可与 Panther 或 Selenium PHP 无缝集成。
- 网络抓取 API:提供对数十个热门域名的结构化数据进行编程访问的端点。
如果你并不想自己去编写爬虫,但仍然需要网络数据,不妨尝试我们的成品数据集!
现在就注册 Bright Data,开始免费试用,体验我们的网页抓取解决方案吧。



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。



