

在本指南中,你将了解:
- 为什么在 PHP 中解析 HTML 很有用
- 开始本文目标所需的前置条件
- 如何使用以下方式在 PHP 中解析 HTML:
Dom\HTMLDocument- Simple HTML DOM Parser
- Symfony 的
DomCrawler
- 这三种方法的对比表格
让我们开始吧!
为什么要在 PHP 中解析 HTML?
在 PHP 中进行 HTML 解析,意味着将 HTML 内容转换为其 DOM(文档对象模型)结构。一旦转换为 DOM 格式,你就可以轻松地遍历和操作 HTML 内容。
尤其是,在 PHP 中解析 HTML 的主要原因包括:
- 数据提取:从网页中获取特定内容,比如从 HTML 元素中提取文本或属性。
- 自动化:将内容抓取、生成报告,以及从 HTML 中聚合数据等任务自动化。
- 服务端 HTML 内容处理:在显示到应用之前,在服务器端解析、修改、清理或格式化网页内容。
前置条件
在开始编写代码之前,确保你的机器上已经安装了 PHP 8.4+。你可以运行以下命令进行验证:
php -v输出结果应类似这样:
PHP 8.4.3 (cli) (built: Jan 19 2025 14:20:58) (NTS)
Copyright (c) The PHP Group
Zend Engine v4.4.3, Copyright (c) Zend Technologies
with Zend OPcache v8.4.3, Copyright (c), by Zend Technologies接下来,你需要初始化一个 Composer 项目,方便管理依赖。如果你的系统还未安装 Composer,下载 Composer 并按照安装说明进行操作。
首先,为你的 PHP HTML 项目创建一个新文件夹:
mkdir php-html-parser在终端中切换到该文件夹,并使用 composer init 命令在其中初始化一个 Composer 项目:
composer init在此过程中,你将被问到一些问题。使用默认答案即可,但如果需要,你可以为项目添加更具体的信息。
然后,在你喜欢的 IDE 中打开此项目文件夹。带有 PHP 扩展的 Visual Studio Code 或 IntelliJ WebStorm 都是不错的选择。
现在,向项目文件夹中添加一个空的 index.php 文件。此时项目结构应如下所示:
php-html-parser/
├── vendor/
├── composer.json
└── index.php打开 index.php 文件,添加以下代码以初始化项目:
<?php
require_once __DIR__ . "/vendor/autoload.php";
// scraping logic...该文件稍后将包含解析 HTML 的逻辑。
现在,你可以使用以下命令来运行脚本:
php index.php很好!至此,你已经完成了在 PHP 中开始 HTML 解析的配置。接下来,你可以开始在脚本中添加所需的 HTML 获取和解析逻辑。
在 PHP 中获取 HTML 内容
在 PHP 中解析 HTML 之前,你需要先获取 HTML。本节将介绍两种在 PHP 中访问 HTML 的不同方法。
使用 CURL
PHP 原生支持 cURL,它是一个常用的 HTTP 客户端,用来执行 HTTP 请求。启用 cURL 扩展,或在 Linux 上安装:
sudo apt-get install php8.4-curl可以使用 cURL 发起 HTTP GET 请求 到在线服务器并获取服务器返回的 HTML 文档。
下面是一个示例脚本,用于发送简单的 GET 请求并获取 HTML 内容:
// initialize cURL session
$ch = curl_init();
// set the URL you want to make a GET request to
curl_setopt($ch, CURLOPT_URL, "https://www.scrapethissite.com/pages/forms/?per_page=100");
// return the response instead of outputting it
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
// execute the cURL request and store the result in $response
$html = curl_exec($ch);
// close the cURL session
curl_close($ch);
// output the HTML response
echo $html;将上述代码片段添加到 index.php 并执行后,就会输出如下所示的 HTML 代码:
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Hockey Teams: Forms, Searching and Pagination | Scrape This Site | A public sandbox for learning web scraping</title>
<link rel="icon" type="image/png" href="/static/images/scraper-icon.png" />
<!-- Omitted for brevity... -->
</html>可阅读我们的指南,了解更多关于 在 PHP 中使用 cURL GET 请求。
从文件中读取
另一种获取 HTML 的方式是将其存储到一个专用文件中。具体流程如下:
- 在浏览器中访问你想要的页面
- 右键点击页面
- 选择“查看页面源代码”选项
- 复制并粘贴 HTML 到一个文件里
或者,你也可以在文件中自行编写自己的 HTML 代码。
在本示例中,我们假设该文件名为 index.html。它包含了之前通过 cURL 获取的 Scrape This Site上 “Hockey Teams” 页面对应的 HTML:
在 PHP 中解析 HTML 的 3 种方法
本节你将学习如何使用三种不同的库在 PHP 中解析 HTML:
- 使用
Dom\HTMLDocument进行原生 PHP 解析 - 使用 Simple HTML DOM Parser 库
- 使用 Symfony 的
DomCrawler组件
在这三种情况下,你都会看到如何解析通过 cURL 获取的 HTML 字符串,或者从本地 index.html 文件读取的内容。
随后,你会学习如何利用各个 PHP HTML 解析库所提供的方法,来选择页面上的所有 hockey team 条目并从中提取数据:
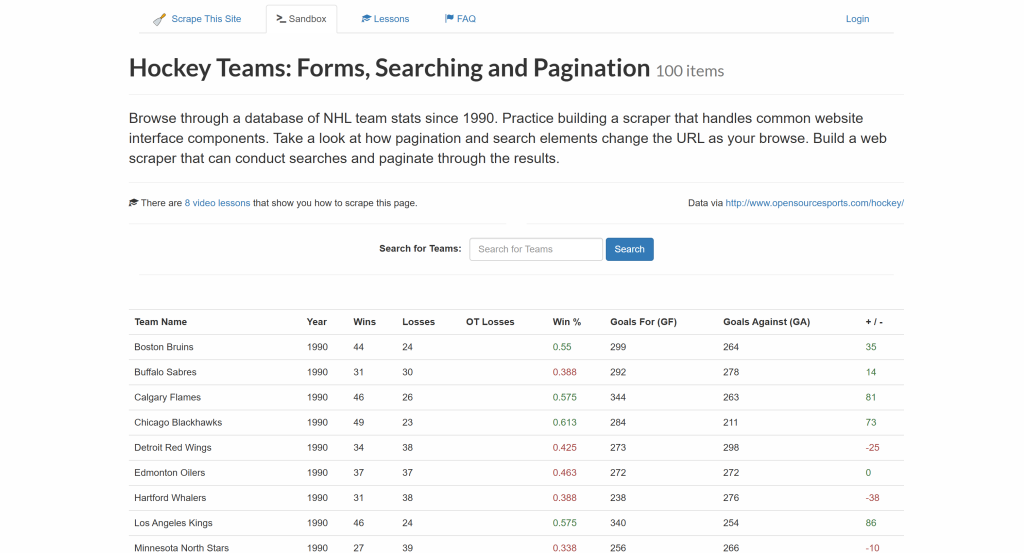
最终结果会是一个包含各个 hockey team 数据的列表,包括:
- Team Name
- Year
- Wins
- Losses
- Win %
- Goals For (GF)
- Goals Against (GA)
- Goal Difference
你可以从以下结构的 HTML 表格中提取它们:
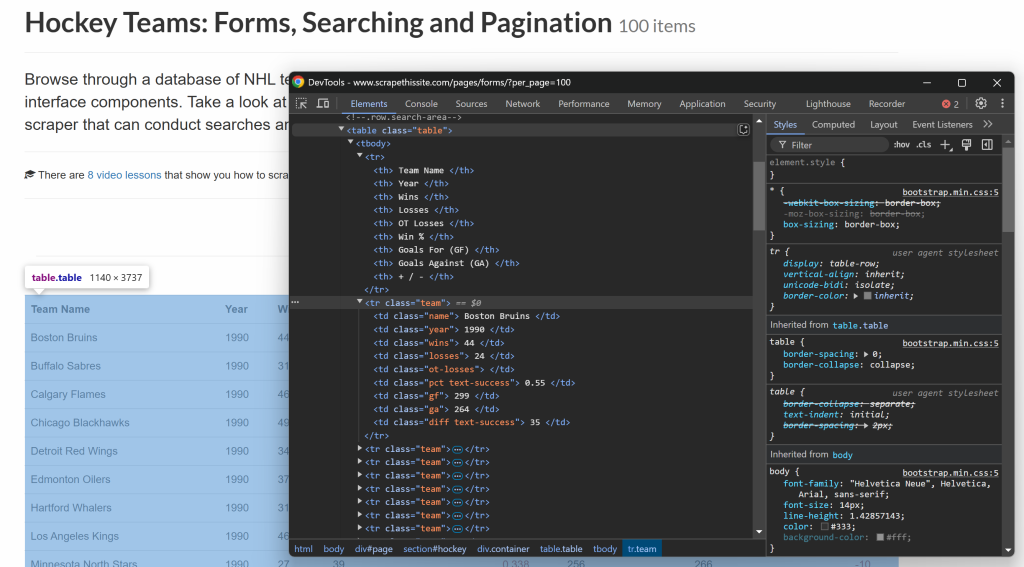
如你所见,表格中每一行的每一列都有特定的 class。你可以通过使用这些 class 来作为 CSS 选择器,然后获取其文本内容来提取相应的数据。
请注意,解析 HTML 只是编写网页爬虫脚本中的其中一步。若要更深入学习,请阅读我们的如何使用 PHP 进行网页爬取的教程。
现在,让我们来看看在 PHP 中进行 HTML 解析的三种不同方式。
方法一:使用 Dom\HTMLDocument
PHP 8.4+ 自带了一个内置的 Dom\HTMLDocument 类。它表示一个 HTML 文档,并允许你解析 HTML 内容并遍历 DOM 树。以下是关于如何使用它来进行 HTML 解析的说明!
步骤 1:安装和配置
Dom\HTMLDocument 属于 标准 PHP 库,但你需要启用 DOM 扩展,或在 Linux 上通过以下命令安装:
sudo apt-get install php-dom无需进一步操作。现在你已经可以使用 Dom\HTMLDocument 来进行 HTML 解析了。
步骤 2:解析 HTML
你可以通过下面的方式解析 HTML 字符串:
$dom = \DOM\HTMLDocument::createFromString($html);
或者,解析 index.html 文件:
$dom = \DOM\HTMLDocument::createFromFile("./index.html");
$dom 是一个 Dom\HTMLDocument 对象,你可以利用它来进行数据解析。
步骤 3:数据提取
可以使用 \DOM\HTMLDocument 并通过以下方式选择所有 hockey team 的条目:
// select each row on the page
$table = $dom->getElementsByTagName("table")->item(0);
$rows = $table->getElementsByTagName("tr");
// iterate through each row and extract data
foreach ($rows as $row) {
$cells = $row->getElementsByTagName("td");
// extracting the data from each column
$team = trim($cells->item(0)->textContent);
$year = trim($cells->item(1)->textContent);
$wins = trim($cells->item(2)->textContent);
$losses = trim($cells->item(3)->textContent);
$win_pct = trim($cells->item(5)->textContent);
$goals_for = trim($cells->item(6)->textContent);
$goals_against = trim($cells->item(7)->textContent);
$goal_diff = trim($cells->item(8)->textContent);
// create an array for the scraped team data
$team_data = [
"team" => $team,
"year" => $year,
"wins" => $wins,
"losses" => $losses,
"win_pct" => $win_pct,
"goals_for" => $goals_for,
"goals_against" => $goals_against,
"goal_diff" => $goal_diff
];
// print the scraped team data
print_r($team_data);
print ("\n");
}\DOM\HTMLDocument 不提供高级的查询方法,因此只能依靠类似 getElementsByTagName() 以及手动迭代等方法。
示例中使用的方法解析如下:
getElementsByTagName():获取文档中所有给定标签(如<table>、<tr>或<td>)的元素。item():从getElementsByTagName()返回的元素列表中,获取指定位置的元素。textContent:属性,可获取元素的原始文本内容,比如球队名、年份等可见数据。
另外,我们还使用了 trim() 来去除文本前后的多余空格,这样数据更加清爽。
将上述代码添加到 index.php 后,输出结果如下:
Array
(
[team] => Boston Bruins
[year] => 1990
[wins] => 44
[losses] => 24
[win_pct] => 0.55
[goals_for] => 299
[goals_against] => 264
[goal_diff] => 35
)
// omitted for brevity...
Array
(
[team] => Detroit Red Wings
[year] => 1994
[wins] => 33
[losses] => 11
[win_pct] => 0.688
[goals_for] => 180
[goals_against] => 117
[goal_diff] => 63
) 方法二:使用 Simple HTML DOM Parser
Simple HTML DOM Parser 是一个轻量级的 PHP 库,可让你轻松解析并操作 HTML 内容。该库仍在积极维护,在 GitHub 上有超过 880 颗星。
步骤 1:安装和配置
可通过 Composer 安装 Simple HTML Dom Parser:
composer require voku/simple_html_dom或者,你也可以手动下载并将 simple_html_dom.php 文件包含到项目中。
然后,在 index.php 中使用以下语句导入该库:
use voku\helper\HtmlDomParser;
步骤 2:解析 HTML
若要解析 HTML 字符串,可使用 file_get_html() 方法:
$dom = HtmlDomParser::str_get_html($html);
如果要解析 index.html 文件,则使用 file_get_html():
$dom = HtmlDomParser::file_get_html($str);
这样就会将 HTML 内容加载到 $dom 对象中,从而方便遍历。
步骤 3:数据提取
使用 Simple HTML DOM Parser,从 HTML 中提取 hockey team 数据:
// find all rows in the table
$rows = $dom->findMulti("table tr.team");
// loop through each row to extract the data
foreach ($rows as $row) {
// extract data using CSS selectors
$team_element = $row->findOne(".name");
$team = trim($team_element->plaintext);
$year_element = $row->findOne(".year");
$year = trim($year_element->plaintext);
$wins_element = $row->findOne(".wins");
$wins = trim($wins_element->plaintext);
$losses_element = $row->findOne(".losses");
$losses = trim($losses_element->plaintext);
$win_pct_element = $row->findOne(".pct");
$win_pct = trim($win_pct_element->plaintext);
$goals_for_element = $row->findOne(".gf");
$goals_for = trim($goals_for_element->plaintext);
$goals_against_element = $row->findOne(".ga");
$goals_against = trim(string: $goals_against_element->plaintext);
$goal_diff_element = $row->findOne(".diff");
$goal_diff = trim(string: $goal_diff_element->plaintext);
// create an array with the extracted team data
$team_data = [
"team" => $team,
"year" => $year,
"wins" => $wins,
"losses" => $losses,
"win_pct" => $win_pct,
"goals_for" => $goals_for,
"goals_against" => $goals_against,
"goal_diff" => $goal_diff
];
// print the scraped team data
print_r($team_data);
print("\n");
}上面使用的 Simple HTML DOM Parser 特性包括:
findMulti():选择与给定 CSS 选择器匹配的所有元素。findOne():获取与给定 CSS 选择器匹配的第一个元素。plaintext:属性,可获取元素内的原始文本内容。
此处通过更完整和强大的逻辑来使用 CSS 选择器,但最终结果和第一种方法的输出相同。
方法三:使用 Symfony 的 DomCrawler 组件
Symfony 的 DomCrawler 组件 为解析 HTML 文档、提取数据提供了简便方法。
注意:该组件属于 Symfony 框架,但可单独使用。我们在此将只使用它的独立组件。
步骤 1:安装和配置
通过 Composer 命令安装 Symfony 的 DomCrawler 组件:
composer require symfony/dom-crawler
然后在 index.php 文件中导入:
use Symfony\Component\DomCrawler\Crawler;
步骤 2:解析 HTML
要解析 HTML 字符串,可在创建 Crawler 实例时传入该字符串:
$crawler = new Crawler($html);
如果要解析文件,则可以使用 file_get_contents() 并创建 Crawler 实例:
$crawler = new Crawler(file_get_contents("./index.html"));
这样就能将 HTML 内容加载到 $crawler 对象中,然后借助它来遍历并提取数据。
步骤 3:数据提取
以下示例说明如何在 DomCrawler 中提取 hockey team 数据:
// select all rows within the table
$rows = $crawler->filter("table tr.team");
// loop through each row to extract the data
$rows->each(function ($row, $i) {
// extract data using CSS selectors
$team_element = $row->filter(".name");
$team = trim($team_element->text());
$year_element = $row->filter(".year");
$year = trim($year_element->text());
$wins_element = $row->filter(".wins");
$wins = trim($wins_element->text());
$losses_element = $row->filter(".losses");
$losses = trim($losses_element->text());
$win_pct_element = $row->filter(".pct");
$win_pct = trim($win_pct_element->text());
$goals_for_element = $row->filter(".gf");
$goals_for = trim($goals_for_element->text());
$goals_against_element = $row->filter(".ga");
$goals_against = trim($goals_against_element->text());
$goal_diff_element = $row->filter(".diff");
$goal_diff = trim($goal_diff_element->text());
// create an array with the extracted team data
$team_data = [
"team" => $team,
"year" => $year,
"wins" => $wins,
"losses" => $losses,
"win_pct" => $win_pct,
"goals_for" => $goals_for,
"goals_against" => $goals_against,
"goal_diff" => $goal_diff
];
// print the scraped team data
print_r($team_data);
print ("\n");
});上述代码中用到的 DomCrawler 方法包括:
each():遍历选定元素列表。filter():使用 CSS 选择器来选择元素。text():获取所选元素的文本内容。
太棒了!你现在已经熟悉了 PHP HTML 解析的多种方式。
在 PHP 中解析 HTML:对比表
下面的总结表格对比了本文介绍的三种 HTML 解析方式:
| \DOM\HTMLDocument | Simple HTML DOM Parser | Symfony 的 DomCrawler | |
|---|---|---|---|
| 类型 | 原生 PHP 组件 | 外部库 | Symfony 组件 |
| GitHub Stars | — | 880+ | 4000+ |
| XPath 支持 | ❌ | ✔️ | ✔️ |
| CSS 选择器支持 | ❌ | ✔️ | ✔️ |
| 学习曲线 | 低 | 低到中 | 中 |
| 使用简易度 | 中 | 高 | 高 |
| API 丰富度 | 基础 | 丰富 | 丰富 |
结论
在本文中,你学习了三种在 PHP 中解析 HTML 的方法,从内置原生扩展到第三方库。
需要注意的是,目标网页可能会使用 JavaScript 来进行渲染。在这种情况下,上面介绍的简单 HTML 解析方法都无法正常工作。你需要使用具有完整浏览器功能的高级爬虫解决方案(如 Scraping Browser)来处理此类场景。
你想直接使用现成数据,而无需自己解析 HTML?可以试试我们的 现成数据集,其中涵盖了数百个网站的数据!
赶快注册一个免费的 Bright Data 帐号,开始免费试用我们的数据与爬虫解决方案吧!


