

使用以下命令运行代码:由于其广泛的库和工具,PHP 是构建网页抓取器的绝佳语言。PHP 专为网页开发设计,能够轻松可靠地处理网页抓取任务。
使用 PHP 抓取网站有许多不同的方法,本文将介绍几种不同的方法。具体来说,您将学习如何使用 curl、file_get_contents、Symfony BrowserKit 和 Symfony 的 Panther 组件抓取网站。此外,您还将了解在网页抓取过程中可能遇到的一些常见挑战以及如何避免它们。
在本文中,我们将讨论:
使用 PHP 进行网页抓取
在本节中,您将学习几种常用的网页抓取方法,涵盖基本和复杂/动态网站。
请注意:虽然本教程涵盖了多种方法,但这并不是一个详尽的列表。
前提条件
要跟随本教程,您需要最新版本的 PHP 和 PHP 的依赖管理工具 Composer。本文测试使用的版本是 PHP 8.1.18 和 Composer 2.5.5。
设置好 PHP 和 Composer 后,创建一个名为 php-web-scraping 的目录,并进入该目录:
mkdir php-web-scraping
cd $_在整个教程中,您都将在此目录中工作。
curl
curl 是一个几乎无处不在的低级库和 CLI 工具,用 C 语言编写。它可以使用 HTTP 或 HTTPS 获取网页内容。在几乎所有平台上,PHP 都默认启用了 curl 支持。
在本节中,您将抓取一个非常基本的网页,该网页列出了根据联合国估计的人口国家列表。您将提取菜单中的链接及其文本。
首先,创建一个名为 curl.php 的文件,然后在该文件中使用 curl_init 函数初始化 curl:
<?php
$ch = curl_init();然后设置抓取网页的选项,包括设置 URL 和 HTTP 方法(GET、POST 等),使用 curl_setopt 函数:
curl_setopt($ch, CURLOPT_URL, 'https://en.wikipedia.org/wiki/List_of_countries_by_population_(United_Nations)');
curl_setopt($ch, CURLOPT_CUSTOMREQUEST, 'GET');
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);在此代码中,您将目标 URL 设置为网页,并将方法设置为 GET。CURLOPT_RETURNTRANSFER 告诉 curl 返回 HTML 响应。
curl 准备好后,您可以使用 curl_exec 进行请求:
$response = curl_exec($ch);获取 HTML 数据只是网页抓取的第一步。要从 HTML 响应中提取数据,您需要使用多种技术。最简单的方法是使用正则表达式进行非常基本的 HTML 提取。但请注意,您不能用正则表达式解析任意 HTML,但对于非常简单的解析,正则表达式是足够的。
例如,提取带有 href 和 title 属性并包含 <span> 的 <a> 标签:
if(! empty($ch)) {
preg_match_all(
'/<a href="([^"]*)" title="([^"]*)"><span>([^<]*)<\/span><\/a>/',
$response, $matches, PREG_SET_ORDER
);
foreach($matches as $link) {
echo $link[1] . " => " . $link[3] . "\n";
}
}然后使用 curl_close 函数释放资源:
curl_close($ch);使用以下命令运行代码:
php curl.php您应该看到它正确提取了链接:

curl 为您提供了通过 HTTP/HTTPS 获取网页的非常底层的控制。您可以微调不同的连接属性,甚至添加额外的措施,如代理服务器(稍后会详细介绍)、用户代理和超时。
此外,curl 在大多数操作系统中默认安装,这使它成为编写跨平台网页抓取器的绝佳选择。
然而,正如您所见,仅靠 curl 是不够的,您还需要一个 HTML 解析器来正确抓取数据。curl 也无法执行网页上的 JavaScript,这意味着您无法使用 curl 抓取动态网页和单页应用(SPA)。
file_get_contents
file_get_contents 函数主要用于读取文件内容。但是,通过传递一个 HTTP URL,您可以从网页获取 HTML 数据。这意味着 file_get_contents 可以替代前面的 curl 代码。
在本节中,您将抓取与前面相同的页面,但这次抓取器会更高级,您将能够从表格中提取所有国家的名称。
创建一个名为 file_get-contents.php 的文件,开始时传递一个 URL 给 file_get_contents:
<?php
$html = file_get_contents('https://en.wikipedia.org/wiki/List_of_countries_by_population_(United_Nations)');$html 变量现在保存了网页的 HTML 代码。
与前面的例子类似,获取 HTML 数据只是第一步。为了增加趣味性,使用libxml 选择器选择元素XPath 选择器。首先,您需要初始化 DOMDocument 并将 HTML 加载到其中:
$doc = new DOMDocument;
libxml_use_internal_errors(true);
$doc->loadHTML($html);
libxml_clear_errors();这里,您按以下顺序选择国家:第一个 tbody 元素、tbody 中的一个 tr 元素、tr 元素中的第一个 td 元素,以及 td 元素中的带有 title 属性的 a。
以下代码初始化 DOMXpath 类,并使用 evaluate 选择 XPath 选择器中的元素:
$xpath = new DOMXpath($doc);
$countries = $xpath->evaluate('(//tbody)[1]/tr/td[1]//a[@title=true()]');剩下的就是遍历这些元素并打印文本:
foreach($countries as $country) {
echo $country->textContent . "\n";
}使用以下命令运行代码:
php file_get_contents.php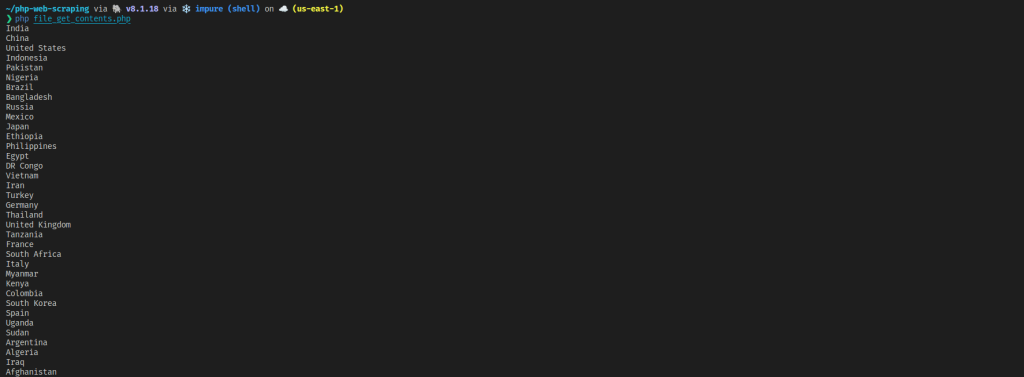
如您所见,file_get_contents 使用起来比 curl 更简单,通常用于快速获取网页的 HTML 代码。然而,它也有与 curl 相同的缺点——您需要额外的 HTML 解析器,并且无法抓取动态网页和 SPA。此外,您还失去了 curl 提供的精细控制。但它的简单性使其成为抓取基本静态站点的良好选择。
Symfony BrowserKit
Symfony BrowserKit 是 Symfony 框架的一个组件,模拟真实浏览器的行为。这意味着您可以像在实际浏览器中一样与网页进行交互,例如点击按钮/链接、提交表单、在历史记录中前进和后退。
在本节中,您将访问Bright Data 博客,在搜索框中输入 PHP 并提交搜索表单。然后,您将抓取结果中的文章名称:
要使用 Symfony BrowserKit,您必须使用 Composer 安装 BrowserKit 组件:
composer require symfony/browser-kit您还需要安装 HttpClient 组件来进行互联网 HTTP 请求:
composer require symfony/http-clientBrowserKit 默认支持使用 XPath 选择器选择元素。在本例中,您使用 CSS 选择器。为此,您还需要安装 CssSelector 组件:
composer require symfony/css-selector创建一个名为 symfony-browserkit.php 的文件。在此文件中,初始化 HttpBrowser:
<?php
require "vendor/autoload.php";
use Symfony\Component\BrowserKit\HttpBrowser;
$client = new HttpBrowser();使用 request 函数进行 GET 请求:
$crawler = $client->request('GET', 'https://brightdata.com/blog');要选择搜索按钮所在的表单,您需要选择按钮本身,并使用 form 函数获取包含的表单。可以通过传递按钮的 ID 使用 filter 函数选择按钮。一旦选择了表单,您可以使用 submit 函数提交它。
通过传递输入值的哈希,submit 函数可以在提交表单前填写表单。在以下代码中,名称为 q 的输入已被赋值 PHP,这与在搜索框中输入 PHP 相同:
$form = $crawler->filter('#blog_search')->form();
$crawler = $client->submit($form, ['q' => 'PHP']);submit 函数返回结果页面。从这里,您可以使用 CSS 选择器 .col-md-4.mb-4 h5 提取文章名称:
$crawler->filter(".col-md-4.mb-4 h5")->each(function ($node) {
echo $node->text() . "\n";
});使用以下命令运行代码:
php symfony-browserkit.php
虽然 Symfony BrowserKit 在与网页进行交互方面比前两种方法更进了一步,但它仍然有限,因为它无法执行 JavaScript。这意味着您无法使用 BrowserKit 抓取动态网站和 SPA。
Symfony Panther
Symfony Panther 是 Symfony 的 另一个组件,封装了 BrowserKit 组件。然而,Symfony Panther 提供了一个主要的优势:它不是模拟浏览器,而是使用 WebDriver 协议远程控制真实浏览器在实际浏览器中执行代码。这意味着您可以抓取任何网站,包括动态网站和 SPA。
在本节中,您将加载OpenWeather 首页,在搜索框中输入您的城市名称,进行搜索,并抓取您所在城市的当前天气:
首先,使用 Composer 安装 Symfony Panther:
composer require symfony/panther您还需要安装 dbrekelmans/browser-driver-installer,它可以自动检测系统上安装的浏览器并为其安装正确的驱动程序。确保您的系统中安装了 Firefox 或基于 Chromium 的浏览器:
composer require dbrekelmans/bdi使用 bdi 工具在 drivers 目录中安装相应的驱动程序:
vendor/bin/bdi detect drivers创建一个名为 symfony-panther.php 的文件,并首先初始化 Panther 客户端:
<?php
require 'vendor/autoload.php';
use Symfony\Component\Panther\Client;
$client = Client::createFirefoxClient();注意:根据您的浏览器,您可能需要使用 createChromeClient 或 createSeleniumClient 代替 createFirefoxClient。
由于 Panther 在后台使用 Symfony BrowserKit,接下来的代码与 Symfony BrowserKit 部分中的代码非常相似。
首先,使用 request 函数加载网页。当页面加载时,它最初被一个带有 owm-loader 类的 div 覆盖,该 div 显示加载进度条。在开始与页面交互之前,您需要等待此 div 消失。这可以使用 waitForStaleness 函数完成,该函数接受一个 CSS 选择器并等待它从 DOM 中移除。
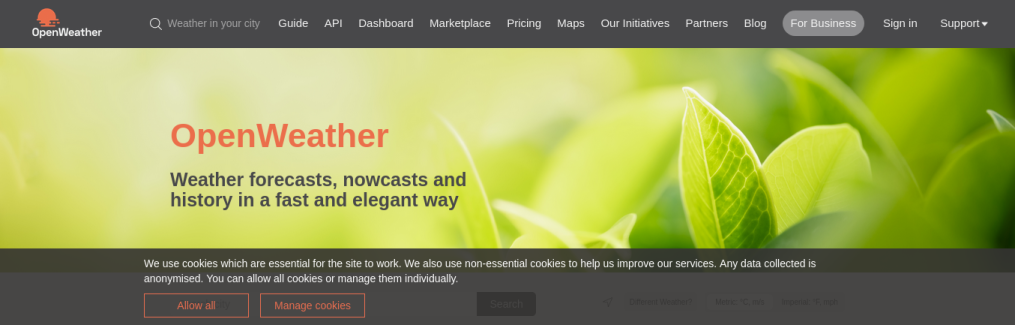
加载条被移除后,您需要接受 cookie 以便关闭 cookie 横幅。为此,selectButton 函数很有用,因为它可以按文本搜索按钮。一旦找到按钮,click 函数会对其执行点击操作:
$client->request('GET', 'https://openweathermap.org/');
try {
$crawler = $client->waitForStaleness(".owm-loader");
} catch (Facebook\WebDriver\Exception\NoSuchElementException $e) {
}
$crawler->selectButton('Allow all')->click();注意:根据页面加载速度,加载条可能在 waitForStaleness 函数运行之前消失。这会抛出一个异常。因此,这行代码被包装在 try-catch 块中。
现在是时候在搜索栏中输入 Kolkata 了。使用 filter 函数选择搜索栏,并使用 sendKeys 函数向搜索栏提供输入。然后点击搜索按钮:
$crawler->filter('input[placeholder="Search city"]')->sendKeys('Kolkata');
$crawler->selectButton('Search')->click();选择按钮后,会弹出一个自动完成建议框。您可以使用 waitForVisibility 函数等待列表可见,然后像之前一样使用 filter 和 click 组合点击第一个项目:
$crawler = $client->waitForVisibility(".search-dropdown-menu li");
$crawler->filter(".search-dropdown-menu li")->first()->click();
最后,使用 waitForElementToContain 等待结果加载,并使用 filter 提取当前温度:
$crawler = $client->waitForElementToContain(".orange-text+h2", "Kolkata");
$temp = $crawler->filter(".owm-weather-icon+span.orange-text+h2")->text();
echo $temp;在这里,您正在等待选择器为 .orange-text+h2 的元素包含 Kolkata。这表明结果已加载。
使用以下命令运行代码:
php symfony-panther.php您的输出如下所示:

网页抓取的挑战及可能的解决方案
尽管 PHP 使编写网页抓取器变得容易,但处理实际的抓取项目可能很复杂。可能会出现许多情况,提出需要解决的挑战。这些挑战可能源于数据结构(例如分页)或网站所有者采取的反机器人措施(例如蜜罐陷阱)。
在本节中,您将了解一些常见的挑战及其应对方法。
浏览分页网站
在抓取几乎任何实际网站时,您可能会遇到一种情况,即所有数据不会一次加载。换句话说,数据是分页的。可能有两种类型的分页:
- 所有页面位于不同的 URL。页面编号通过查询参数或路径参数传递。例如,
example.com?page=3或example.com/page/3。 - 当选择下一页按钮时,使用 JavaScript 加载新页面。
在第一种情况下,您可以循环加载页面,并将其视为单独的网页进行抓取。例如,使用 file_get_contents,以下代码抓取示例网站的前十页:
for($page = 1; $page <= 10; $page++) {
$html = file_get_contents('https://example.com/page/{$page}');
// DO the scraping
}在第二种情况下,您需要使用可以执行 JavaScript 的解决方案,例如 Symfony Panther。在本例中,您需要点击加载下一页的相应按钮。不要忘记稍等一会儿,等待新页面加载:
for($page = 1; $page <= 10; $page++>) {
// Do the scraping
// Load the next page
$crawler->selectButton("Next")->click();
$client->waitForElementToContain(".current-page", $page+1)
}注意:您应替换适合您正在抓取的网站的适当等待逻辑。
轮换代理
代理服务器充当您的计算机与目标 Web 服务器之间的中介。它可以防止 Web 服务器看到您的 IP 地址,从而保护您的匿名性。
但是,您不应依赖单个代理服务器,因为它可能会被禁止。相反,您需要使用多个代理服务器并轮换使用它们。以下代码提供了一个非常基本的解决方案,其中使用了一个代理数组,并随机选择一个代理:
$proxy = array();
$proxy[] = '1.2.3.4';
$proxy[] = '5.6.7.8';
// Add more proxies
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, "https://example.com");
curl_setopt($ch, CURLOPT_PROXY, $proxy[array_rand($proxy)]);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, 1);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 15);
$result = curl_exec($ch);
curl_close($ch);处理 CAPTCHA
许多网站使用 CAPTCHA 来确保用户是人类而不是机器人。不幸的是,这意味着您的网页抓取器可能会被捕获。
CAPTCHA 可以非常简单,例如一个简单的复选框,问“您是人类吗?”或者它们可以使用更高级的算法,例如 Google 的 reCAPTCHA 或 hCaptcha。使用基本的网页操作(例如勾选复选框),您可能可以通过基本的 CAPTCHA,但要对抗高级 CAPTCHA,您需要一个专用工具,如 2Captcha。2Captcha 使用人类解决 CAPTCHA。您只需将所需的详细信息传递给 2Captcha API,它就会返回已解决的 CAPTCHA。
要开始使用 2Captcha,您需要创建一个帐户并获取 API 密钥。
使用 Composer 安装 2Captcha:
composer require 2captcha/2captcha在代码中,创建 TwoCaptcha 的实例:
$solver = new \TwoCaptcha\TwoCaptcha('YOUR_API_KEY');然后使用 2Captcha 解决 CAPTCHA:
// Normal captcha
$result = $solver->normal('path/to/captcha.jpg');
// ReCaptcha
$result = $solver->recaptcha([
'sitekey' => '6Le-wvkSVVABCPBMRTvw0Q4Muexq1bi0DJwx_mJ-',
'url' => 'https://mysite.com/page/with/recaptcha',
'version' => 'v3',
]);
// hCaptcha
$result = $solver->hcaptcha([
'sitekey' => '10000000-ffff-ffff-ffff-000000000001',
'url' => 'https://www.site.com/page/',
]);或者,您可以查看Bright Data 的 CAPTCHA 解决工具。
避免蜜罐陷阱
蜜罐陷阱是一种反机器人措施,它模拟服务或网络来引诱抓取器和爬虫,使它们偏离实际目标。尽管蜜罐对于防止机器人攻击很有用,但对于网页抓取来说却可能是个问题。您不希望您的抓取器陷入蜜罐陷阱。
您可以采取各种措施来避免被蜜罐陷阱引诱。例如,蜜罐链接通常是隐藏的,这样真实用户看不到它们,但机器人可以拾取它们。为了避免陷阱,您可以尝试避免点击隐藏的链接(带有 display: none 或 visibility: none CSS 属性的链接)。
另一种选择是轮换代理,这样如果一个代理服务器 IP 地址被蜜罐抓住并禁止,您仍然可以通过其他代理连接。
结论
由于 PHP 出色的库和框架,制作网页抓取器非常容易。在本文中,您学会了如何:
- 使用
curl和正则表达式抓取静态网站 - 使用
file_get_contents和 libxml 抓取静态网站 - 使用 Symfony BrowserKit 抓取静态站点并提交表单
- 使用 Symfony Panther 抓取复杂的动态站点
不幸的是,在使用这些方法进行抓取时,您会发现使用 PHP 进行抓取存在一些复杂性。例如,您可能需要安排多个代理,并仔细构建抓取器以避免蜜罐陷阱。
而这正是 Bright Data 的用武之地……
关于 Bright Data 代理:
- 住宅代理:Bright Data 的住宅代理拥有超过 7200 万个来自 195 个国家的真实 IP,无论位置如何,都可以访问任何网站内容,同时避免 IP 禁令和 CAPTCHA。
- ISP 代理:Bright Data 的ISP IP超过 700,000 个,利用世界上任何城市的真实静态 IP,由 ISP 分配并租赁给 Bright Data,供您专用,只要您需要。
- 数据中心代理:Bright Data 的数据中心代理网络拥有超过 770,000 个数据中心 IP,建立在全球多个 IP 类型上,在共享 IP 池中或单独购买。
- 移动代理:Bright Data 的高级移动 IP 网络拥有超过 700 万个移动 IP,提供世界上最快和最大的真实对等 3G/4G/5G IP 网络。
加入最大的代理网络,并获取免费代理试用。



