

在本教程中,您将探索如何在 Laravel 中进行网络爬虫,并学习:
- 为什么 Laravel 是进行网络爬虫的绝佳技术
- 最佳的 Laravel 爬虫库有哪些
- 如何从头开始构建一个 Laravel 网络爬虫 API
让我们开始吧!
可以在 Laravel 中进行网络爬虫吗?
简而言之:是的,Laravel 是进行网络爬虫的可行技术。
Laravel 是一个以其优雅和富有表现力的语法而闻名的强大 PHP 框架。特别是,它使您能够动态创建用于从网络抓取数据的 API。这得益于许多爬虫库的支持,它们简化了从页面获取数据的过程。欲了解更多指导,请查看我们的文章《在 PHP 中进行网络爬虫》。
Laravel 因其可扩展性、易于与其他工具集成以及广泛的社区支持,而成为网络爬虫的绝佳选择。其强大的 MVC 架构有助于保持您的爬虫逻辑良好组织和可维护。这在构建复杂或大型的爬虫项目时非常有用。
最佳的 Laravel 网络爬虫库
以下是使用 Laravel 进行网络爬虫的最佳库:
- BrowserKit:Symfony 框架的一部分,它模拟了 Web 浏览器的 API,用于与 HTML 文档交互。它依赖于
DomCrawler来导航和抓取 HTML 文档。该库非常适合从 PHP 中的静态页面提取数据。 - HttpClient:Symfony 的一个组件,用于发送 HTTP 请求。它可以与
BrowserKit无缝集成。 - Guzzle:一个强大的 HTTP 客户端,用于向服务器发送 Web 请求并高效处理响应。它有助于检索与网页关联的 HTML 文档。了解如何在 Guzzle 中设置代理。
- Panther:Symfony 的一个组件,为网络爬虫提供了一个无头浏览器。它允许您与需要 JavaScript 进行渲染或交互的动态网站交互。
先决条件
要跟随本教程在 Laravel 中进行网络爬虫,您需要满足以下先决条件:
还推荐使用用于编写 PHP 代码的 IDE。带有 PHP 扩展的 Visual Studio Code 或 WebStorm 都是不错的选择。
如何在 Laravel 中构建一个网络爬虫 API
在这个逐步指南中,您将学习如何构建一个 Laravel 网络爬虫 API。目标站点是 Quotes 爬虫沙盒站点,爬虫端点将:
- 从页面中选择引用的 HTML 元素
- 从中提取数据
- 以 JSON 格式返回抓取的数据
目标站点如下所示:
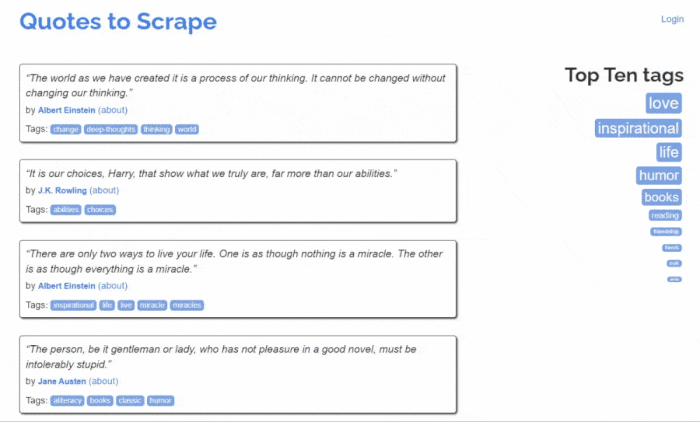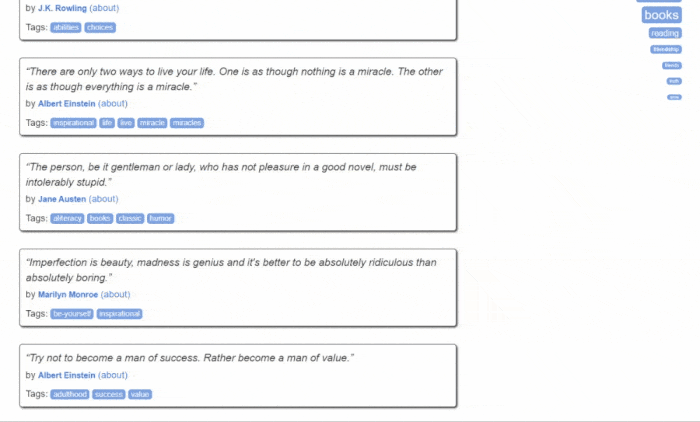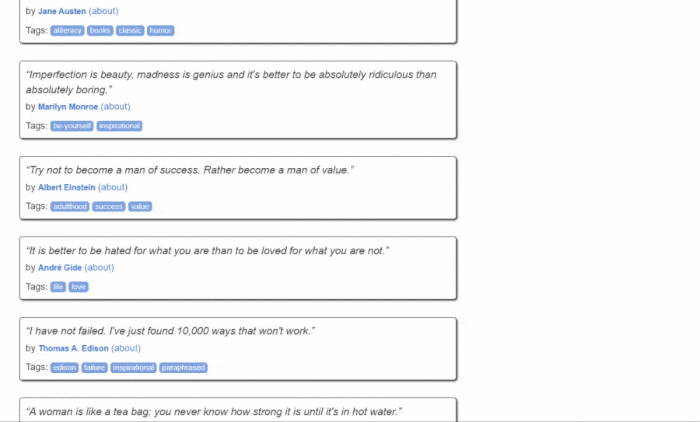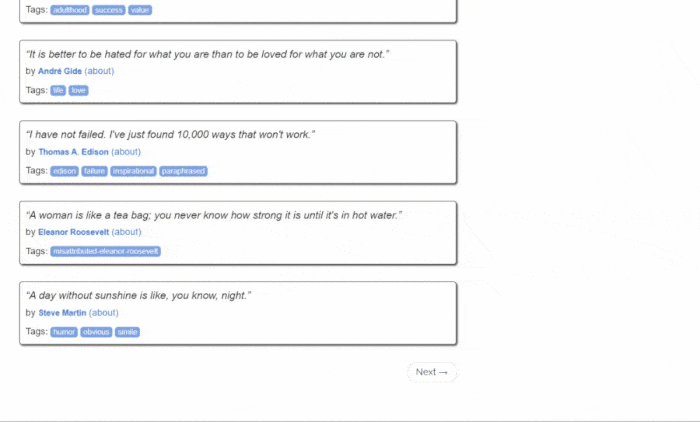
按照以下说明,学习如何在 Laravel 中进行网络爬虫!
步骤 1:设置 Laravel 项目
打开终端,然后运行以下 Composer create-project 命令来初始化您的 Laravel 网络爬虫应用程序:
composer create-project laravel/laravel laravel-scraperlaravel-scraper 文件夹现在将包含一个空白的 Laravel 项目。在您喜欢的 PHP IDE 中加载它。
这是您当前后端的文件结构:
太好了!您现在已经有了一个 Laravel 项目。
步骤 2:初始化您的爬虫 API
在项目目录中运行以下 Artisan 命令 来添加一个新的 Laravel 控制器:
php artisan make:controller ScrapingController这将在 /app/Http/Controllers 目录下创建以下 ScrapingController.php 文件:
<?php
namespace AppHttpControllers;
use IlluminateHttpRequest;
class ScrapingController extends Controller
{
//
}
在 ScrapingController 文件中,添加以下 scrapeQuotes() 方法:
public function scrapeQuotes(): JsonResponse
{
// scraping logic...
return response()->json('Hello, World!');
}目前,该方法返回一个占位符 'Hello, World!' 的 JSON 消息。很快,它将包含一些 Laravel 的爬虫逻辑。
别忘了添加以下导入:
use IlluminateHttpJsonResponse;通过在 routes/api.php 中添加以下行,将 scrapeQuotes() 方法关联到一个专用的端点:
use AppHttpControllersScrapingController;
Route::get('/v1/scraping/scrape-quotes', [ScrapingController::class, 'scrapeQuotes']);太好了!现在是验证 Laravel 爬虫 API 是否按预期工作的时间。请记住,Laravel 的 API 位于 /api 路径下。因此,完整的 API 端点是 /api/v1/scraping/scrape-quotes。
使用以下命令启动您的 Laravel 应用程序:
php artisan serve您的服务器现在应在本地监听端口 8000。
使用 cURL 向 /api/v1/scraping/scrape-quotes 端点发出 GET 请求:
curl -X GET 'http://localhost:8000/api/v1/scraping/scrape-quotes'注意:在 Windows 上,将 curl 替换为 curl.exe。在我们的cURL 网络爬虫指南中了解更多信息。
您应该获得以下响应:
"Hello, World!"太棒了!示例爬虫 API 工作正常。现在是使用 Laravel 定义一些爬虫逻辑的时候了。
步骤 3:安装爬虫库
在安装任何软件包之前,您需要确定哪些 Laravel 网络爬虫库最适合您的需求。为此,在浏览器中打开目标站点。右键点击页面并选择“检查”以打开开发者工具。然后,转到“网络”选项卡,重新加载页面,并访问“Fetch/XHR”部分:
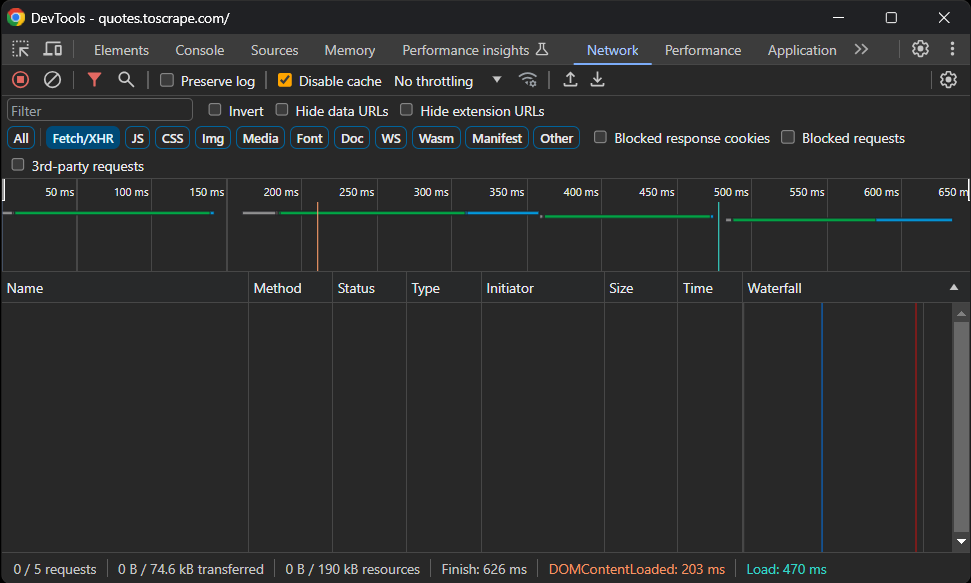
如您所见,网页未执行任何AJAX 请求。这意味着它未在客户端动态加载数据。因此,它是一个静态页面,所有数据都嵌入在 HTML 文档中。
由于页面是静态的,您无需使用无头浏览器库来抓取它。虽然您仍然可以使用浏览器自动化工具,但这只会引入不必要的开销。推荐的方法是使用 Symfony 的 BrowserKit 和 HttpClient 组件。
使用以下命令将 symfony/browser-kit 和 symfony/http-client 组件添加到您的项目依赖项中:
composer require symfony/browser-kit symfony/http-client做得好!您现在拥有在 Laravel 中进行数据爬取所需的一切。
步骤 4:下载目标页面
在 ScrapingController 中导入 BrowserKit 和 HttpClient:
use SymfonyComponentBrowserKitHttpBrowser;
use SymfonyComponentHttpClientHttpClient;在 scrapeQuotes() 中,初始化一个新的 HttpBrowser 对象:
$browser = new HttpBrowser(HttpClient::create());这使您能够通过模拟浏览器行为来发出 HTTP 请求。同时,请记住,它并未在真实浏览器中执行请求。HttpBrowser 只是提供类似浏览器的功能,例如 Cookie 和会话处理。
使用 request() 方法对目标页面的 URL 执行 HTTP GET 请求:
$crawler = $browser->request('GET', 'https://quotes.toscrape.com/');结果将是一个 Crawler 对象,它会自动解析服务器返回的 HTML 文档。该类还提供节点选择和数据提取功能。
您可以通过从爬虫中提取页面的 HTML 来验证上述逻辑是否有效:
$html = $crawler->outerHtml();为了测试,让您的 API 返回这些数据。
您的 scrapeQuotes() 函数现在将如下所示:
public function scrapeQuotes(): JsonResponse
{
// initialize a browser-like HTTP client
$browser = new HttpBrowser(HttpClient::create());
// download and parse the HTML of the target page
$crawler = $browser->request('GET', 'https://quotes.toscrape.com/');
// get the page outer HTML and return it
$html = $crawler->outerHtml();
return response()->json($html);
}太棒了!您的 API 现在将返回:
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="UTF-8">
<title>Quotes to Scrape</title>
<link rel="stylesheet" href="/static/bootstrap.min.css">
<link rel="stylesheet" href="/static/main.css">
</head>
<!-- omitted for brevity ... -->步骤 5:检查页面内容
要定义数据提取逻辑,检查目标页面的 HTML 结构至关重要。
因此,在浏览器中打开 Quotes To Scrape。然后,右键点击一个引用的 HTML 元素并选择“检查”选项。在浏览器的开发者工具中,展开 HTML 并开始研究它:
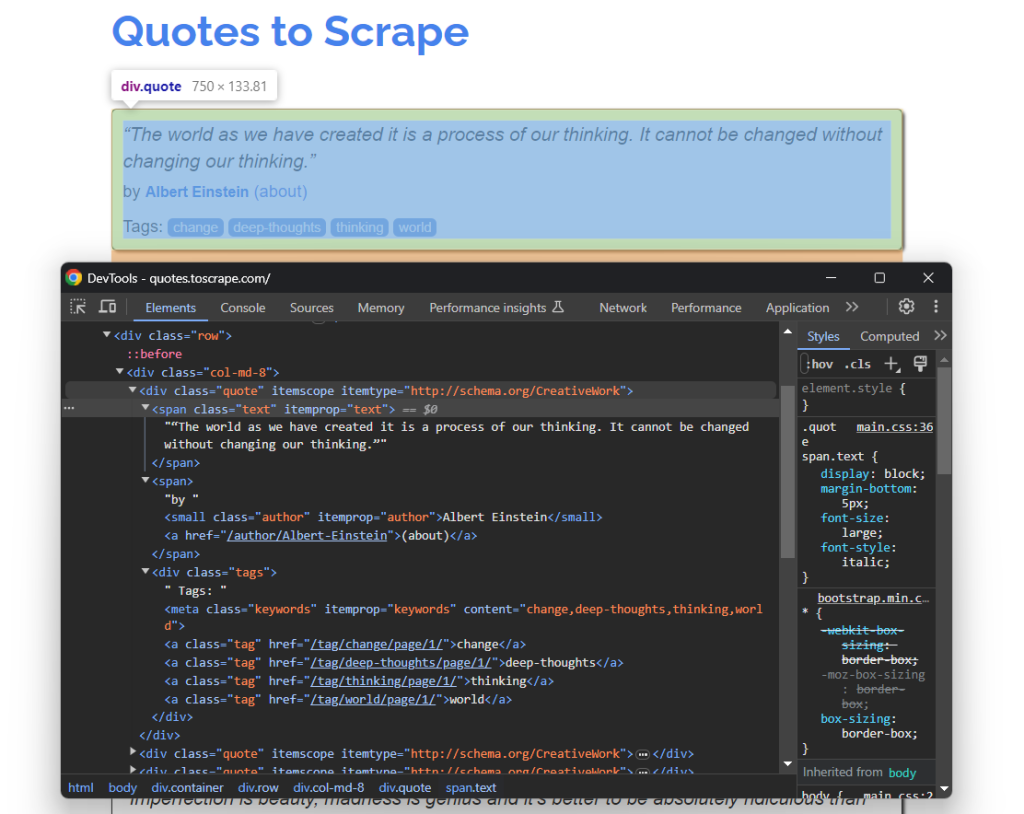
在这里,注意每个引用卡片都是一个 .quote HTML 节点,包含:
- 包含引用文本的
.text元素 - 带有作者姓名的
.author节点 - 多个
.tag元素,每个显示一个标签
使用上述 CSS 选择器,您拥有了在 Laravel 中执行网络爬虫所需的一切。使用这些选择器来定位感兴趣的 DOM 元素,并在下一步中从中提取数据!
步骤 6:准备进行网络爬虫
由于目标页面包含多个引用,创建一个数据结构来存储抓取的数据是必要的。数组将是理想的选择:
quotes = []然后,使用 Crawler 类的 filter() 方法选择所有引用元素:
$quote_html_elements = $crawler->filter('.quote');这将返回页面上与指定的 .quote CSS 选择器匹配的所有 DOM 节点。
接下来,迭代它们,并准备在每个节点上应用数据提取逻辑:
foreach ($quote_html_elements as $quote_html_element) {
// create a new quote crawler
$quote_crawler = new Crawler($quote_html_element);
// scraping logic...
}请注意,filter() 返回的 DOMNode 对象不提供节点选择的方法。因此,您需要创建一个仅限于特定 HTML 引用元素的本地 Crawler 实例。
为了使上述代码正常工作,添加以下导入:
use SymfonyComponentDomCrawlerCrawler;您无需手动安装 DomCrawler 包。这是因为它是 BrowserKit 组件的直接依赖项。
太棒了!您离 Laravel 网络爬虫的目标又近了一步。
步骤 7:实现数据爬取
在 foreach 循环中:
- 从
.text、.author和.tag元素中提取感兴趣的数据 - 使用它们填充一个新的
$quote对象 - 将新的
$quote对象添加到$quotes
首先,选择 HTML 引用元素内的 .text 元素。然后,使用 text() 方法从中提取内部文本:
$text_html_element = $quote_crawler->filter('.text');
$raw_text = $text_html_element->text();请注意,每个引用都被包含在 u201c 和 u201d 特殊字符中。您可以使用 PHP 的 str_replace() 函数将其删除,如下所示:
$text = str_replace(["u{201c}", "u{201d}"], '', $raw_text);同样,使用以下代码抓取作者信息:
$author_html_element = $quote_crawler->filter('.author');
$author = $author_html_element->text();抓取标签可能有点挑战性。由于单个引用可以有多个标签,您需要定义一个数组并逐个抓取每个标签:
$tag_html_elements = $quote_crawler->filter('.tag');
$tags = [];
foreach ($tag_html_elements as $tag_html_element) {
$tag = $tag_html_element->textContent;
$tags[] = $tag;
}请注意,filter() 返回的 DOMNode 元素不提供 text() 方法。相应地,它们提供了 textContent 属性。
整个 Laravel 数据爬取逻辑如下所示:
// create a new quote crawler
$quote_crawler = new Crawler($quote_html_element);
// perform the data extraction logic
$text_html_element = $quote_crawler->filter('.text');
$raw_text = $text_html_element->text();
// remove special characters from the raw text information
$text = str_replace(["u{201c}", "u{201d}"], '', $raw_text);
$author_html_element = $quote_crawler->filter('.author');
$author = $author_html_element->text();
$tag_html_elements = $quote_crawler->filter('.tag');
$tags = [];
foreach ($tag_html_elements as $tag_html_element) {
$tag = $tag_html_element->textContent;
$tags[] = $tag;
}好了!您离最终目标又近了一步。
步骤 8:返回抓取的数据
使用抓取的数据创建一个 $quote 对象,并将其添加到 $quotes:
$quote = [
'text' => $text,
'author' => $author,
'tags' => $tags
];
$quotes[] = $quote;接下来,使用 $quotes 列表更新 API 响应数据:
return response()->json(['quotes' => $quotes]);在爬虫循环结束时,$quotes 将包含:
array(10) {
[0]=>
array(3) {
["text"]=>
string(113) "The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking."
["author"]=>
string(15) "Albert Einstein"
["tags"]=>
array(4) {
[0]=>
string(6) "change"
[1]=>
string(13) "deep-thoughts"
[2]=>
string(8) "thinking"
[3]=>
string(5) "world"
}
}
// omitted for brevity...
[9]=>
array(3) {
["text"]=>
string(48) "A day without sunshine is like, you know, night."
["author"]=>
string(12) "Steve Martin"
["tags"]=>
array(3) {
[0]=>
string(5) "humor"
[1]=>
string(7) "obvious"
[2]=>
string(6) "simile"
}
}
}非常好!这些数据将被序列化为 JSON,并由 Laravel 爬虫 API 返回。
步骤 9:整合所有内容
以下是 Laravel 中 ScrapingController 文件的完整代码:
<?php
namespace AppHttpControllers;
use IlluminateHttpRequest;
use IlluminateHttpJsonResponse;
use SymfonyComponentBrowserKitHttpBrowser;
use SymfonyComponentHttpClientHttpClient;
use SymfonyComponentDomCrawlerCrawler;
class ScrapingController extends Controller
{
public function scrapeQuotes(): JsonResponse
{
// initialize a browser-like HTTP client
$browser = new HttpBrowser(HttpClient::create());
// download and parse the HTML of the target page
$crawler = $browser->request('GET', 'https://quotes.toscrape.com/');
// where to store the scraped data
$quotes = [];
// select all quote HTML elements on the page
$quote_html_elements = $crawler->filter('.quote');
// iterate over each quote HTML element and apply
// the scraping logic
foreach ($quote_html_elements as $quote_html_element) {
// create a new quote crawler
$quote_crawler = new Crawler($quote_html_element);
// perform the data extraction logic
$text_html_element = $quote_crawler->filter('.text');
$raw_text = $text_html_element->text();
// remove special characters from the raw text information
$text = str_replace(["u{201c}", "u{201d}"], '', $raw_text);
$author_html_element = $quote_crawler->filter('.author');
$author = $author_html_element->text();
$tag_html_elements = $quote_crawler->filter('.tag');
$tags = [];
foreach ($tag_html_elements as $tag_html_element) {
$tag = $tag_html_element->textContent;
$tags[] = $tag;
}
// create a new quote object
// with the scraped data
$quote = [
'text' => $text,
'author' => $author,
'tags' => $tags
];
// add the quote object to the quotes array
$quotes[] = $quote;
}
var_dump($quotes);
return response()->json(['quotes' => $quotes]);
}
}是时候测试了!
启动您的 Laravel 服务器:
php artisan serve然后,向 /api/v1/scraping/scrape-quotes 端点发出 GET 请求:
curl -X GET 'http://localhost:8000/api/v1/scraping/scrape-quotes'您将获得以下结果:
{
"quotes": [
{
"text": "The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.",
"author": "Albert Einstein",
"tags": [
"change",
"deep-thoughts",
"thinking",
"world"
]
},
// omitted for brevity...
{
"text": "A day without sunshine is like, you know, night.",
"author": "Steve Martin",
"tags": [
"humor",
"obvious",
"simile"
]
}
]
}瞧!不到 100 行代码,您就在 Laravel 中完成了网络爬虫。
下一步
您在此构建的 API 只是 Laravel 在网络爬虫方面所能实现的基本示例。要将您的项目提升到下一个水平,请考虑以下改进:
- 实现网络爬行:目标站点包含分布在多个页面上的多个引用。这是一个常见的情况,需要通过网络爬行来完整地检索数据。阅读我们的文章,了解什么是网络爬虫。
- 调度您的爬虫任务:添加一个调度程序,定期调用您的 API,将数据存储在数据库中,确保您始终拥有新鲜数据。
- 集成代理:从同一 IP 发出多个请求可能会被反爬虫措施阻止。为避免这种情况,请考虑在您的 PHP 爬虫中集成住宅代理。
保持您的 Laravel 网络爬虫操作道德且尊重他人
网络爬虫是为各种目的收集有价值数据的有效方法。然而,目标是负责任地检索数据,而不是损害目标站点。因此,以正确的预防措施进行爬虫非常重要。
请遵循以下提示,以确保负责任的 Laravel 网络爬虫:
- 检查并遵守站点的服务条款:在爬取站点之前,查看其服务条款。这些通常包含有关版权、知识产权和使用其数据的指南。
- 尊重 robots.txt 文件:站点的 robots.txt 文件定义了自动爬虫应如何访问其页面的规则。为了保持道德实践,请遵守这些指南。在我们的robots.txt 网络爬虫指南中了解更多信息。
- 仅针对公开可用的信息:专注于公开可访问的数据。避免抓取受登录凭据或其他形式授权保护的页面。未经适当许可,针对私人或敏感数据是不道德的,可能会导致法律后果。
- 限制请求的频率:在短时间内发出过多请求可能会使服务器过载,影响所有用户的站点性能。这也可能触发限速措施并导致您被阻止。通过在请求之间添加随机延迟,避免对目标服务器造成负担。
- 依赖可靠且最新的爬虫工具:偏好信誉良好的提供商,并选择维护良好且定期更新的工具。这可确保它们与最新的道德 Laravel 爬虫实践保持一致。如果您不确定,请查看我们的文章如何选择最佳的网络爬虫服务。
结论
在本指南中,您了解了为什么 Laravel 是构建网络爬虫 API 的良好框架。您还探索了一些最佳的爬虫库。然后,您学习了如何创建一个 Laravel 网络爬虫 API,以动态从目标页面提取数据。正如您所见,使用 Laravel 进行网络爬虫非常简单,只需几行代码。
问题是,大多数网站使用反机器人和反爬虫解决方案来保护其数据。这些技术可以检测并阻止您的自动请求。幸运的是,Bright Data 提供了一套使爬虫变得容易的解决方案:
- 抓取浏览器:一个基于云的可控浏览器,提供 JavaScript 渲染功能,同时为您处理 CAPTCHA、浏览器指纹、自动重试等。它可与最流行的自动化浏览器库(如 Playwright 和 Puppeteer)集成。
- 网络解锁器:一个解锁 API,可以无缝返回任何页面的干净 HTML,绕过任何反爬虫措施。
- 网络抓取API:用于以编程方式访问数十个流行域的结构化网络数据的端点。
不想处理网络爬虫但仍对在线数据感兴趣?探索 Bright Data 的现成数据集!
立即注册并开始您的免费试用。



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




