

在本指南中,您将了解到:
- 什么是机器学习?
- 为什么网页抓取对机器学习有用
- 如何为机器学习执行抓取
- 如何将机器学习用于处理抓取的数据
- 使用抓取的数据训练机器学习模型过程的详细介绍
- 抓取数据用于机器学习时如何设置 ETL
现在就来一探究竟吧!
什么是机器学习?
机器学习,也称 ML,是人工智能 (AI) 的一个子部分,致力于构建能够从数据中学习的系统。具体而言,将机器学习应用于软件和计算系统引发巨大革命,此后计算机无需明确编程即可解决机器学习问题。这都要归功于机器学习系统从数据中学习。
机器如何从数据中学习?您可以把机器学习看作是纯粹的应用数学。实际上,机器学习模型可以识别所接触底层数据的模式,进而能够在遇到新输入数据时预测输出内容。
为什么网页抓取对机器学习有用
机器学习系统——更笼统地说是任何 AI 系统——都需要数据来训练模型,因此网页抓取成为数据从业人员可以利用的机会。
以下是网页抓取对机器学习很重要的部分原因:
- 大规模数据收集:机器学习模型,尤其是深度学习模型,需要海量数据才能有效训练。网络抓取有助于收集其他地方可能无法获得的大规模数据集。
- 多样而丰富的数据来源:如果您已经拥有训练机器学习模型的数据,那么抓取网络可以扩大数据集,因为网络上有非常广泛的数据。
- 最新信息:有时,您掌握的数据没有根据最新趋势更新,这种情况下网页抓取可帮助您获取最新信息。实际上,对于依赖最新信息(例如,股票价格预测、新闻情绪分析等)的模型,网络抓取可以提供最新的数据源。
- 提升模型性能:您拥有的数据可能永远不够,具体取决于您正在处理的模型或项目。因此,使用网页抓取功能从网络中检索数据是获取更多数据的良好途径,目的在于提升模型的性能并验证模型。
- 市场分析:搜集评价、评论和评分有助于了解消费者情绪,这对企业很有价值。网页抓取还可以帮助收集新兴话题的相关数据,并有助于预测市场趋势或公众舆论。
先决条件
在本教程中,您将学习如何在 Python 中执行网络抓取用于机器学习。
要创建以下 Python 项目,您的系统必须满足以下先决条件:
- Python 3.6 或更高版本:3.6 以上的 Python 版本都可以。特别是,我们将通过
pip安装依赖项,而 3.4 以上的 Python 版本中都已经安装 pip。 - Jupyter Notebook 6.x:我们将使用 Jupiter Notebook 分析数据并利用机器学习做出预测。6.x 以上的版本都可以。
- IDE: VS CODE 或您选择的任何其他 Python IDE 都可以。
如何为机器学习执行抓取
在此逐步介绍部分,您将学习如何创建网页抓取项目。这类项目可检索数据,用于通过机器学习进一步分析。
详细来说,您将了解到如何抓取 Yahoo Finance 来获取 NVIDIA 的股价。然后,我们会将这些数据用于机器学习。
第 1 步:设置环境
首先,创建一个名为比如 scraping_project 的存储库,这个库中包含名为 data、notebooks 和 scripts 的子文件夹,如下所示:
scraping_project/
├── data/
│ └── ...
├── notebooks/
│ └── analysis.ipynb
├── scripts/
│ └── data_retrieval.py
└── venv/
位置:
data_retrieval.py将包含您的抓取逻辑。analysis.ipynb将包含机器学习逻辑。data/将包含抓取的数据,用于通过机器学习加以分析。
venv/ 文件夹包含虚拟环境。您可以按照下列步骤创建:
python3 -m venv venv
要激活它,在 Windows 上运行:
venvScriptsactivate
在 macOS/Linux 上,执行:
source venv/bin/activate
您现在可以安装所有需要的库:
pip install selenium requests pandas matplotlib scikit-learn tensorflow notebook
第 2 步:定义目标页面
要获取 NVIDIA 历史数据,您必须访问以下 URL:
https://finance.yahoo.com/quote/NVDA/history/
但是,该页面提供了一些筛选器,用于定义您想要的数据显示方式:

想要检索足够的数据用于机器学习,可以将筛选条件设置为 5 年。为方便起见,您可以使用以下 URL,该网址已经筛选了 5 年的数据:
https://finance.yahoo.com/quote/NVDA/history/?frequency=1d&period1=1574082848&period2=1731931014
在此页面中,您必须以下表为目标,从中检索数据:

定义表的 CSS 选择器是 .table,因此您可以在 data_retrieval.py 文件中编写以下代码:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common import NoSuchElementException
import pandas as pd
import os
# Configure Selenium
driver = webdriver.Chrome(service=Service())
# Target URL
url = "https://finance.yahoo.com/quote/NVDA/history/?frequency=1d&period1=1574082848&period2=1731931014"
driver.get(url)
# Wait for the table to load
try:
WebDriverWait(driver, 20).until(
EC.presence_of_element_located((By.CSS_SELECTOR, ".table"))
)
except NoSuchElementException:
print("The table was not found, verify the HTML structure.")
driver.quit()
exit()
# Locate the table and extract its rows
table = driver.find_element(By.CSS_SELECTOR, ".table")
rows = table.find_elements(By.TAG_NAME, "tr")
到目前为止,这段代码执行了以下操作:
- 设置 Selenium Chrome 驱动程序实例
- 定义目标 URL 并指示 Selenium 访问它
- 等待表加载:在这种情况下,目标表由 Javascript 加载,因此 Web 驱动程序等待 20 秒,以确保表已加载
- 使用专用 CSS 选择器截取整个表
第 3 步:检索数据并将其保存到 CSV 文件中
此时,您可以执行以下操作:
- 从表中提取标题(标题将按原样附加到 CSV 文件中)
- 检索表中的所有数据
- 将数据转换为 Numpy 数据框
您可以使用以下代码执行此操作:
# Extract headers from the first row of the table
headers = [header.text for header in rows[0].find_elements(By.TAG_NAME, "th")]
# Extract data from the subsequent rows
data = []
for row in rows[1:]:
cols = [col.text for col in row.find_elements(By.TAG_NAME, "td")]
if cols:
data.append(cols)
# Convert data into a pandas DataFrame
df = pd.DataFrame(data, columns=headers)
第 4 步:将 CSV 文件保存到 data/ 文件夹
如果您查看创建的文件夹结构,则应该记住 data_retrieval.py 文件位于 scripts/ 文件夹中。而 CVS 文件必须保存到 data/ 文件夹中,因此您必须在代码中考虑这一点:
# Determine the path to save the CSV file
current_dir = os.path.dirname(os.path.abspath(__file__))
# Navigate to the "data/" directory
data_dir = os.path.join(current_dir, "../data")
# Ensure the directory exists
os.makedirs(data_dir, exist_ok=True)
# Full path to the CSV file
csv_path = os.path.join(data_dir, "nvda_stock_data.csv")
# Save the DataFrame to the CSV file
df.to_csv(csv_path, index=False)
print(f"Historical stock data saved to {csv_path}")
# Close the WebDriver
driver.quit()
此代码使用 os.path.dirname() 方法确定(绝对)当前路径,使用 os.path.join() 方法导航到 data/ 文件夹,使用 os.makedirs(data_dir, exist_ok=True) 方法确保文件夹存在,使用 df.to_csv() 方法从 Pandas 库将数据保存到 CSV 文件,最后退出驱动程序。
第 5 步:整合所有代码
以下是 data_retrieval.py 文件的完整代码:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.webdriver.common.by import By
from selenium.common import NoSuchElementException
import pandas as pd
import os
# Configure Selenium
driver = webdriver.Chrome(service=Service())
# Target URL
url = "https://finance.yahoo.com/quote/NVDA/history/?frequency=1d&period1=1574082848&period2=1731931014"
driver.get(url)
# Wait for the table to load
try:
WebDriverWait(driver, 5).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "table.table.yf-j5d1ld.noDl"))
)
except NoSuchElementException:
print("The table was not found, verify the HTML structure.")
driver.quit()
exit()
# Locate the table and extract its rows
table = driver.find_element(By.CSS_SELECTOR, ".table")
rows = table.find_elements(By.TAG_NAME, "tr")
# Extract headers from the first row of the table
headers = [header.text for header in rows[0].find_elements(By.TAG_NAME, "th")]
# Extract data from the subsequent rows
data = []
for row in rows[1:]:
cols = [col.text for col in row.find_elements(By.TAG_NAME, "td")]
if cols:
data.append(cols)
# Convert data into a pandas DataFrame
df = pd.DataFrame(data, columns=headers)
# Determine the path to save the CSV file
current_dir = os.path.dirname(os.path.abspath(__file__))
# Navigate to the "data/" directory
data_dir = os.path.join(current_dir, "../data")
# Ensure the directory exists
os.makedirs(data_dir, exist_ok=True)
# Full path to the CSV file
csv_path = os.path.join(data_dir, "nvda_stock_data.csv")
# Save the DataFrame to the CSV file
df.to_csv(csv_path, index=False)
print(f"Historical stock data saved to {csv_path}")
# Close the WebDriver
driver.quit()
因此,您只需几行代码,即可检索到 NVIDIA 股票的 5 年历史数据并将其保存到 CSV 文件中。
在 Windows,通过以下命令启动上述脚本:
python data_retrieval.py
或者同样也可以在 Linux/macOS 上:
python3 data_retrieval.py
以下是抓取的数据输出的样子:
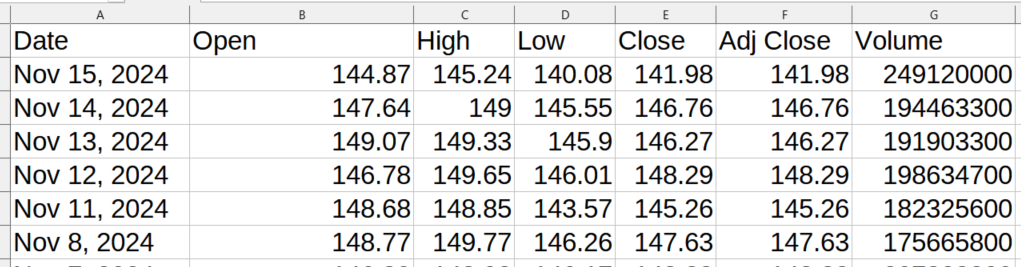
将机器学习用于处理抓取的数据
现在数据已保存到 CSV 文件中,您可以使用机器学习进行预测。
让我们了解一下如何通过以下步骤中做到这一点。
第 1 步:创建新的 Jupyter Notebook 文件
要创建新的 Jupyter Notebook 文件,请从主文件中导航到 notebooks/ 文件夹:
cd notebooks
然后,打开 Jupyter Notebook,如下所示:
jupyter notebook
打开浏览器后,单击新建 > Python3 (ipykernel),创建一个新的 Jupyter Notebook 文件:
重命名文件为,比如 analysis.ipynb。
第 2 步:打开 CSV 文件并显示前几行
现在您可以打开包含数据的 CSV 文件并显示数据框的前几行:
import pandas as pd
# Path to the CSV file
csv_path = "../data/nvda_stock_data.csv"
# Open the CVS file
df = pd.read_csv(csv_path)
# Show head
df.head()
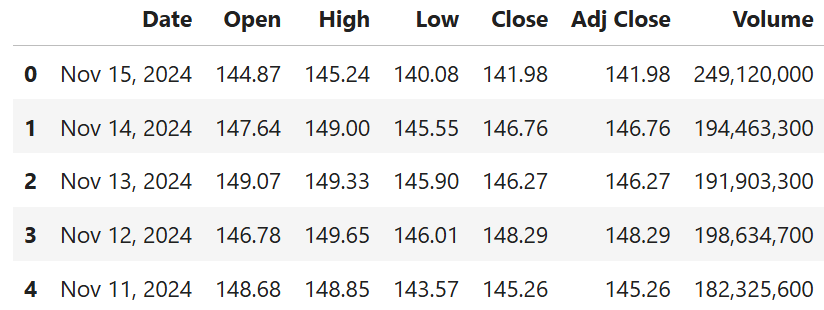
此代码通过 csv_path = "../data/nvda_stock_data.csv" 前往 data/ 文件夹。然后,它使用 pd.read_csv() 方法将 CSV 作为数据框打开,并使用 df.head() 方法显示前几行(前 5 行)。
以下为预期结果:
第 3 步:显示 **Adj Close 数值随时间推移的趋势
现在数据框已正确加载,您可以看到 Adj Close 数值的趋势,该值表示调整后的收盘价:
import matplotlib.pyplot as plt
# Ensure the "Date" column is in datetime forma
df["Date"] = pd.to_datetime(df["Date"])
# Sort the data by date (if not already sorted)
df = df.sort_values(by="Date")
# Plot the "Adj Close" values over time
plt.figure(figsize=(10, 6))
plt.plot(df["Date"], df["Adj Close"], label="Adj Close", linewidth=2)
# Customize the plot
plt.title("NVDA Stock Adjusted Close Prices Over Time", fontsize=16) # Sets title
plt.xlabel("Date", fontsize=12) # Sets x-axis label
plt.ylabel("Adjusted Close Price (USD)", fontsize=12) # Sets y-axis label
plt.grid(True, linestyle="--", alpha=0.6) # Defines styles of the line
plt.legend(fontsize=12) # Shows legend
plt.tight_layout()
# Show the plot
plt.show()
此代码片段执行以下操作:
df["Date"]使用pd.to_datetime()方法访问数据框的日期列,确保日期数据为日期格式df.sort_values()将日期列的日期排序。这样可以确保数据按时间顺序显示。plt.figure()设置图表的大小,而plt.plot()则显示图表# 自定义图表注释下的代码行可用于通过提供标题、轴标签和显示图例来自定义图表plt.show()方法真正可以用于显示图表
预期结果如下所示:
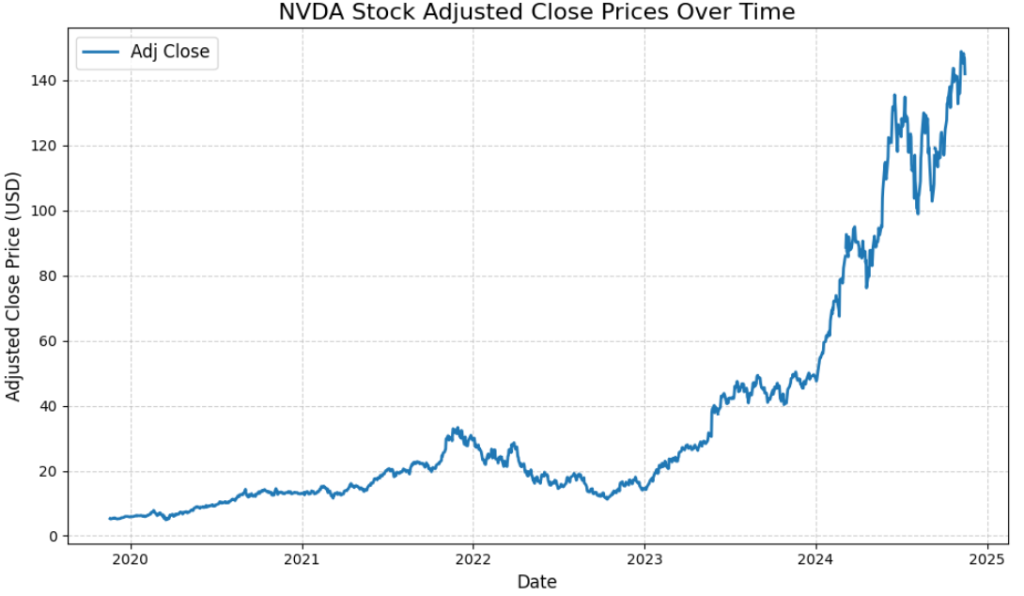
此图显示了一段时间内 NVIDIA 股票价值调整后的收盘价的实际趋势。您将要训练的机器学习模型必须尽可能地预测这些价格。
第 3 步:为机器学习准备数据
接下来该为机器学习准备数据了!
首先,您可以清洗并准备数据:
from sklearn.preprocessing import MinMaxScaler
# Convert data types
df["Volume"] = pd.to_numeric(df["Volume"].str.replace(",", ""), errors="coerce")
df["Open"] = pd.to_numeric(df["Open"].str.replace(",", ""), errors="coerce")
# Handle missing values
df = df.infer_objects().interpolate()
# Select the target variable ("Adj Close") and scale the data
scaler = MinMaxScaler(feature_range=(0, 1)) # Scale data between 0 and 1
data = scaler.fit_transform(df[["Adj Close"]])
此代码执行以下操作:
- 使用
to_numeric() 方法转换Volume和Open两个数值 - 使用插值来处理数值缺失问题,通过
interpolate()方法填充缺失数值 - 使用
MinMaxScaler()缩放数据 - 使用
fit_transform()方法选择并变换(缩放)目标变量Adj Close
第 4 步:创建训练数据集和测试数据集
本教程中使用的模型是 LSTM(长短期记忆网络),它是一个 RNN(循环神经网络),因此请创建步长序列帮助此模型学习数据:
import numpy as np
# Create sequences of 60 time steps for prediction
sequence_length = 60
X, y = [], []
for i in range(sequence_length, len(data)):
X.append(data[i - sequence_length:i, 0]) # Last 60 days
y.append(data[i, 0]) # Target value
X, y = np.array(X), np.array(y)
# Split into training and test sets
split_index = int(len(X) * 0.8) # 80% training, 20% testing
X_train, X_test = X[:split_index], X[split_index:]
y_train, y_test = y[:split_index], y[split_index:]
此代码:
- 创建包含 60 个时间步长的序列。
X是特征的数组,y是目标值的数组 - 按下列比例拆分初始数据框:80% 成为训练数据集,20% 成为测试数据集
第 5 步:训练模型
您现在可以利用训练数据集训练 RNN:
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM
# Reshape X for LSTM [samples, time steps, features]
X_train = X_train.reshape((X_train.shape[0], X_train.shape[1], 1))
X_test = X_test.reshape((X_test.shape[0], X_test.shape[1], 1))
# Build the Sequential Neural Network
model = Sequential()
model.add(LSTM(32, activation="relu", return_sequences=False))
model.add(Dense(1))
model.compile(loss="mean_squared_error", optimizer="adam")
# Train the Model
history = model.fit(X_train, y_train, epochs=20, batch_size=32, validation_data=(X_test, y_test), verbose=1)
此代码执行以下操作:
- 使用
reshape()方法,重新调整特征数组,为 LSTM 神经网络做好准备,此操作同时适用于训练数据集和测试数据集 - 通过设置其参数来构建 LSTM 神经网络
- 使用
fit() 方法将 LSTM 拟合到训练数据集
因此,该模型现已拟合训练数据集,可以开始预测。
第 6 步:执行预测并评估模型性能
该模型现在可以预测 Adj Close 数值,您按照下述方式评估其性能:
from sklearn.metrics import mean_squared_error, r2_score
# Make Predictions
y_pred = model.predict(X_test)
# Inverse scale predictions and actual values for comparison
y_test = scaler.inverse_transform(y_test.reshape(-1, 1))
y_pred = scaler.inverse_transform(y_pred)
# Evaluate the Model
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
# print results
print("nLSTM Neural Network Results:")
print(f"Mean Squared Error: {mse:.2f}")
print(f"R-squared Score: {r2:.2f}")
此代码执行以下操作:
考虑到机器学习模型的随机性质可能引发的统计误差,预期结果如下所示:

这些数值相当不错,表明考虑到模型特征,所选择的模型是预测 Adj Close 的理想模型。
第 7 步:通过图表比较实际值和预测值
对于机器学习,分析比较结果(就像我们在上一步中所做的那样)有时可能还不够。为了提高选到良好模型的概率,典型方法是同时绘制图表。
例如,一个常见方法是绘制能够将 Adj Close 的实际值与 LSTM 模型的预测值加以比较的图表:
# Visualize the Results
test_results = pd.DataFrame({
"Date": df["Date"].iloc[len(df) - len(y_test):], # Test set dates
"Actual": y_test.flatten(),
"Predicted": y_pred.flatten()
})
# Setting plot
plt.figure(figsize=(12, 6))
plt.plot(test_results["Date"], test_results["Actual"], label="Actual Adjusted Close", color="blue", linewidth=2)
plt.plot(test_results["Date"], test_results["Predicted"], label="Predicted Adjusted Close", color="orange", linestyle="--", linewidth=2)
plt.title("Actual vs Predicted Adjusted Close Prices (LSTM)", fontsize=16)
plt.xlabel("Date", fontsize=12)
plt.ylabel("Adjusted Close Price (USD)", fontsize=12)
plt.legend()
plt.grid(alpha=0.6)
plt.tight_layout()
plt.show()
此代码:
- 在测试数据集上设置实际值和预测值的对比,确保必须将实际值调整为匹配测试数据集的形状。此操作通过
iloc()和flatten()完成。 - 绘制图表,为轴和标题添加标签,并管理其他设置以改善显示效果。
预期结果如下所示:
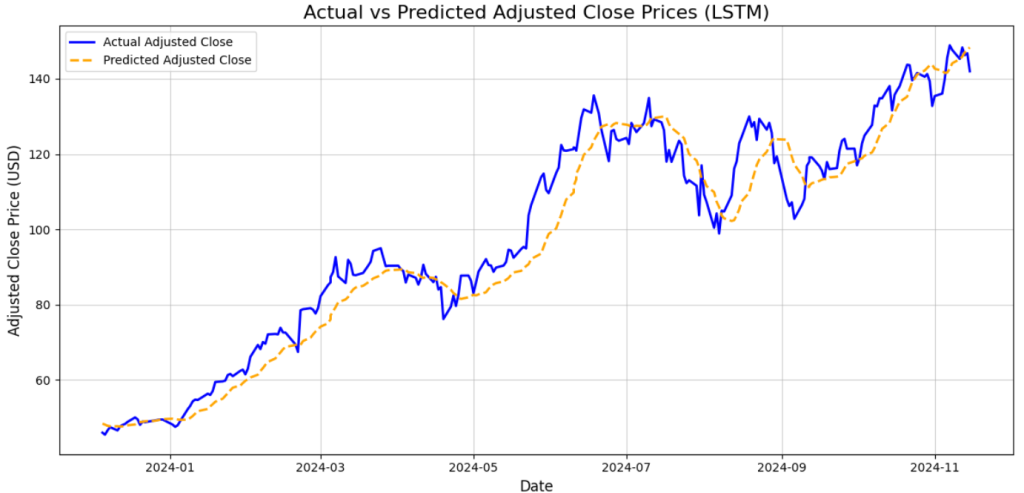
如图所示,LSTM 神经网络预测的数值(黄色虚线)很好地预测了实际值(蓝色实线)。由于分析结果很好,预测结果也很有价值,但是图表无疑有助于直观显示结果确实不错。
第 8 步:整合所有代码
以下是 analysis.ipynb notebook 的完整代码:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import MinMaxScaler
from sklearn.metrics import mean_squared_error, r2_score
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, LSTM
# Path to the CSV file
csv_path = "../data/nvda_stock_data.csv"
# Open CSV as data frame
df = pd.read_csv(csv_path)
# Convert "Date" to datetime format
df["Date"] = pd.to_datetime(df["Date"])
# Sort by date
df = df.sort_values(by="Date")
# Convert data types
df["Volume"] = pd.to_numeric(df["Volume"].str.replace(",", ""), errors="coerce")
df["Open"] = pd.to_numeric(df["Open"].str.replace(",", ""), errors="coerce")
# Handle missing values
df = df.infer_objects().interpolate()
# Select the target variable ("Adj Close") and scale the data
scaler = MinMaxScaler(feature_range=(0, 1)) # Scale data between 0 and 1
data = scaler.fit_transform(df[["Adj Close"]])
# Prepare the Data for LSTM
# Create sequences of 60 time steps for prediction
sequence_length = 60
X, y = [], []
for i in range(sequence_length, len(data)):
X.append(data[i - sequence_length:i, 0]) # Last 60 days
y.append(data[i, 0]) # Target value
X, y = np.array(X), np.array(y)
# Split into training and test sets
split_index = int(len(X) * 0.8) # 80% training, 20% testing
X_train, X_test = X[:split_index], X[split_index:]
y_train, y_test = y[:split_index], y[split_index:]
# Reshape X for LSTM [samples, time steps, features]
X_train = X_train.reshape((X_train.shape[0], X_train.shape[1], 1))
X_test = X_test.reshape((X_test.shape[0], X_test.shape[1], 1))
# Build the Sequential Neural Network
model = Sequential()
model.add(LSTM(32, activation="relu", return_sequences=False))
model.add(Dense(1))
model.compile(loss="mean_squared_error", optimizer="adam")
# Train the Model
history = model.fit(X_train, y_train, epochs=20, batch_size=32, validation_data=(X_test, y_test), verbose=1)
# Make Predictions
y_pred = model.predict(X_test)
# Inverse scale predictions and actual values for comparison
y_test = scaler.inverse_transform(y_test.reshape(-1, 1))
y_pred = scaler.inverse_transform(y_pred)
# Evaluate the Model
mse = mean_squared_error(y_test, y_pred)
r2 = r2_score(y_test, y_pred)
# Print results
print("nLSTM Neural Network Results:")
print(f"Mean Squared Error: {mse:.2f}")
print(f"R-squared Score: {r2:.2f}")
# Visualize the Results
test_results = pd.DataFrame({
"Date": df["Date"].iloc[len(df) - len(y_test):], # Test set dates
"Actual": y_test.flatten(),
"Predicted": y_pred.flatten()
})
# Setting plot
plt.figure(figsize=(12, 6))
plt.plot(test_results["Date"], test_results["Actual"], label="Actual Adjusted Close", color="blue", linewidth=2)
plt.plot(test_results["Date"], test_results["Predicted"], label="Predicted Adjusted Close", color="orange", linestyle="--", linewidth=2)
plt.title("Actual vs Predicted Adjusted Close Prices (LSTM)", fontsize=16)
plt.xlabel("Date", fontsize=12)
plt.ylabel("Adjusted Close Price (USD)", fontsize=12)
plt.legend()
plt.grid(alpha=0.6)
plt.tight_layout()
plt.show()
请注意,整段代码直接用于实现目标,跳过打开数据框时显示前几行的部分,只绘制 Adj Close 的实际值。
本段开头介绍了作为初始数据分析一部分的这些步骤,而这些步骤有助于理解在实际训练机器学习模型之前您用数据做了什么。
请注意:代码为逐段呈现,但考虑到机器学习的随机性质,建议完全运行整批代码,以便妥善训练和验证 LSTM 模型。否则,生成的最终图表可能会产生显著差异。
关于使用抓取的数据训练机器学习模型过程的注意事项
为简单起见,本文提供的分步指南直接介绍如何拟合 LSTM 神经网络。
实际上,机器学习模型并非如此。因此,当您尝试解决需要机器学习模型的问题时,过程如下:
- 初步数据分析:这是流程中最重要的部分,因为通过这个阶段您可以了解自己拥有的数据,通过删除 NaN 值开展数据清洗,管理最终的重复项,并解决与所掌握数据相关的其他数学问题。
- 训练机器学习模型:您永远不知道自己想到的第一个模型是否是解决机器学习所面临问题的最佳模型。典型方法是执行所谓的抽样检查,即:
- 在训练数据集上训练 3-4 个机器学习模型,并评估它们的学习表现。
- 选取在训练数据集上表现最好的 2-3 个机器学习模型,然后调整其超参数。
- 对比超参数调整后最佳模型学习测试数据集的表现。
- 选出测试数据集学习表现最好的模型。
- 部署:接着表现最好的模型将部署用于生产。
在为机器学习抓取数据时设置 ETL
在本文的开头,我们介绍了为什么网页抓取对机器学习有用。但是,您可能已经注意到已开发项目中存在不一致的情况,原因在于通过网页抓取检索的数据应已经保存到 CSV 文件中。
这是机器学习领域的常见做法,但您应该明白最好在机器学习项目一开始时就这样做,因为项目一开始的目的是找到可以预测未来目标值的最佳模型。
找到最佳模型后,后续的做法是设置 ETL(提取转换加载)途径,以便从网络检索新数据、清洗数据并将其加载到数据库中。
这个过程如下所示:
- 提取:此阶段从各种来源检索数据,包括通过抓取从网络检索数据
- 转换:收集的数据加以清洗和准备
- 加载:检索和转换后的数据经过处理,保存到数据库或数据仓库中
数据存储后,下一阶段将其集成入机器学习工作流程,此流程的主要功能是针对新数据重新训练模型,然后重新验证模型。
结论
本文介绍了如何通过抓取从网络检索数据以及如何将数据用于机器学习。我们还介绍了网络抓取对机器学习的重要性,并讨论了训练和设置 ETL 的过程。
虽然介绍的项目很简单,但底层流程,尤其是与设置 ETL 以持续从网络检索数据从而改进机器学习模型相关的流程,比较复杂,需要进一步分析。
在现实场景中抓取 Yahoo Finance 数据可能比此处展示的复杂得多。Yahoo Finance 网站采用了一些防抓取技术,需要额外注意。如需专业、功能齐全、多合一的解决方案,可以了解一下 Bright Data 的 Yahoo Finance 抓取工具!
如果抓取并非您的强项,但您仍然需要数据用于机器学习项目,不妨了解一下我们针对人工智能和机器学习需求量身定制的高效数据检索解决方案。
立即创建免费的 Bright Data 账户,试用我们的抓取工具 API 或了解我们的数据集。



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




