

训练 AI 模型涉及教它识别数据中的模式以进行决策。微调是一种将训练于大型数据集(如OpenAI 的 GPT-4)上的模型,适应较小的任务特定数据集,通过继续训练过程来实现的策略。
在接下来的部分中,我们将深入探讨使用 OpenAI 微调来训练自定义 AI 模型的过程,指导您完成微调过程的每一步。
理解 AI 和模型训练
人工智能(AI)涉及开发能够执行通常需要人类智能的任务的系统,例如学习、解决问题和决策。AI 模型的核心是一组基于输入数据进行预测的算法。机器学习(ML)是 AI 的一个子集,使机器能够从数据中学习并自主提高性能。
AI 模型的学习方式类似于儿童区分猫和狗,观察特征、进行猜测、纠正错误并重试。这一过程称为模型训练,涉及模型处理输入数据、分析和处理模式,并使用这些知识进行预测。通过将模型的输出与预期结果进行比较来评估模型的性能,并进行调整以提高性能。经过足够的训练,模型中的算法集将成为给定情况的准确数学预测器,能够处理不同的输入数据变体。
从头开始训练模型涉及在没有任何先验知识的情况下教模型学习数据中的模式。这需要大量数据和计算资源,并且在数据有限的情况下,模型的性能可能不好。
另一方面,微调从一个已预训练的模型开始,该模型已经从大型数据集中学习了一般模式。然后对模型进行进一步的训练,使用较小的特定数据集,使其能够将先前学到的知识应用于新任务,通常在较少的数据和计算资源下表现更好。微调特别适用于任务特定数据集相对较小的情况。
为微调做准备
虽然通过对精心策划的数据集进行额外训练来微调现有模型看起来是一个有吸引力的选择,但微调过程的成功取决于几个关键因素。
选择合适的模型
在选择微调的基础模型时,考虑以下几点:
任务对齐:明确定义问题范围和预期模型功能。选择在与您的任务相似的任务中表现出色的模型,因为在微调过程中源任务和目标任务之间的不相似性会导致性能下降。例如,对于文本生成任务,GPT-3 可能是合适的,而对于文本分类任务,BERT 或 RoBERTa 可能更好。
模型大小和复杂性:根据需要平衡性能和效率,因为较大的模型可以更好地捕捉复杂模式,但它们需要更多资源。
评估指标:选择与您的任务相关的评估指标。例如,对于分类任务,准确性可能很重要,而对于语言生成任务,BLEU 或 ROUGE 可能有用。
社区和资源:选择拥有大量社区和丰富资源的模型,以便于排障和实施。优先选择针对您的任务有明确微调指南的模型,并寻找可信的预训练模型检查点来源。
数据收集和准备
在微调过程中,数据的质量和多样性会显著影响模型的性能。以下是一些关键考虑:
所需数据类型:数据类型取决于您的具体任务和模型的预训练数据。对于 NLP 任务,您通常需要来自书籍、文章、社交媒体帖子或语音转录的文本数据。可以通过网络爬虫、调查或社交媒体平台的 API 收集数据。例如,当您需要大量多样化和更新的数据时,使用 AI 网络爬虫 特别有用。
数据清理和注释:数据清理涉及删除无关数据、处理缺失或不一致的数据并进行规范化。注释涉及标记数据以便模型可以从中学习。使用诸如 Bright data 之类的自动化工具可以简化这些过程并提高效率。
纳入多样化和代表性的数据集:在模型微调过程中,多样化和代表性的数据集可以确保模型从各种视角学习,从而得出更通用和可靠的预测。例如,如果您正在微调一个电影评论情感分析模型,您的数据集中应包括各种电影、类型和情感的评论,反映现实世界的类别分布。
设置训练环境
确保您拥有所选 AI 模型和框架所需的硬件和软件。例如,大型语言模型(LLMs)通常需要由 GPU 提供的巨大计算能力。
TensorFlow 或 PyTorch 等框架通常用于 AI 模型训练。安装相关库和工具以及任何额外的依赖项对于无缝集成到训练工作流中至关重要。例如,可能需要 OpenAI API 来微调 OpenAI 开发的特定模型。
微调过程
了解了微调的基础知识后,让我们通过自然语言处理中的一个应用来进行具体操作。
我将使用 OpenAI API 来微调一个预训练模型。当前可以微调的模型包括 gpt-3.5-turbo-0125(推荐)、gpt-3.5-turbo-1106、gpt-3.5-turbo-0613、babbage-002、davinci-002 和实验性的 gpt-4-0613。GPT-4 微调处于实验阶段,有资格的用户可以在微调 UI 中请求访问。
1. 数据集准备
根据一项研究,发现 GPT-3.5 缺乏分析推理能力。因此,让我们尝试使用 2022 年发布的法律学校入学考试(AR-LSAT)的分析推理问题数据集来微调 gpt-3.5-turbo 模型,以增强其分析推理能力。公开可用的数据集可以在这里找到。
微调模型的质量直接取决于用于微调的数据。数据集中的每个示例都应该是一个按照 OpenAI 的聊天补全 API 格式化的对话,包含一个消息列表,每个消息有角色、内容和可选名称,并存储为 JSONL 文件。
微调 gpt-3.5-turbo 所需 的对话聊天格式如下:
{"messages": [{"role": "system", "content": ""}, {"role": "user", "content": ""}, {"role": "assistant", "content": ""}]}
在此格式中,“messages” 是一个消息列表,形成一个包含三个 "roles":system, user, and assistant 的对话。“system” 角色的 “content” 应指定微调系统的行为。
以下是我们将在本指南中使用的 AR-LSAT 数据集中的格式化示例:

创建数据集时需要考虑的关键点如下:
- OpenAI 需要至少 10 个示例进行微调,并建议使用 50 到 100 个训练示例来训练
gpt-3.5-turbo。确切数量取决于具体用例。您还可以在训练文件之外创建一个验证文件,用于超参数调整。 - 模型微调和使用微调后的模型按 token 计费,区分基础模型。详细价格请见 OpenAI 的定价页面。
- Token 限制取决于所选模型。对于 gpt-3.5-turbo-0125,最大上下文长度为 16,385,每个训练示例限制为 16,385 个 token。较长的示例将被截断。Token 计数可以使用 OpenAI 手册中的 计数 token 笔记本 计算。
- OpenAI 提供了一个 Python 脚本,用于查找潜在错误并验证训练和验证文件的格式。
2. 生成 API 密钥并安装 OpenAI 库
为了微调 OpenAI 模型,您必须拥有一个OpenAI 开发者账户并且有足够的信用余额。
要生成 API 密钥并安装 OpenAI 库,请按照以下步骤操作:
1. 在 OpenAI 官方网站上注册。
2. 从“设置”下的“账单”选项卡中充值以启用微调。
3. 点击左上角的用户头像,选择“API 密钥”以访问密钥创建页面。
4. 提供一个名称生成新的密钥。
5. 安装用于微调的 Python OpenAI 库。
pip install openai
6. 使用 os 库将 token 设置为环境变量并建立 API 通信。
import os
from openai import OpenAI
# Set the OPENAI_API_KEY environment variable
os.environ['OPENAI_API_KEY'] = 'The key generated in step 4'
client = OpenAI(api_key=os.environ['OPENAI_API_KEY'])
3. 上传训练和验证文件
在验证数据后,使用 Files API 上传文件以进行微调作业。
training_file_id = client.files.create(
file=open(training_file_name, "rb"),
purpose="fine-tune"
)
validation_file_id = client.files.create(
file=open(validation_file_name, "rb"),
purpose="fine-tune"
)
print(f"Training File ID: {training_file_id}")
print(f"Validation File ID: {validation_file_id}")
成功执行后,将显示训练和验证数据的唯一标识符。

4. 创建微调作业
上传文件后,可以通过 UI 或编程方式创建微调作业。
以下是使用 OpenAI SDK 启动微调作业的方法:
response = client.fine_tuning.jobs.create(
training_file=training_file_id.id,
validation_file=validation_file_id.id,
model="gpt-3.5-turbo",
hyperparameters={
"n_epochs": 10,
"batch_size": 3,
"learning_rate_multiplier": 0.3
}
)
job_id = response.id
status = response.status
print(f'Fine-tunning model with jobID: {job_id}.')
print(f"Training Response: {response}")
print(f"Training Status: {status}")
model:微调的模型名称(gpt-3.5-turbo、babbage-002、davinci-002或现有微调模型)。training_file和validation_file:上传文件时返回的文件 ID。n_epochs、batch_size和learning_rate_multiplier:可定制的超参数。
有关设置额外微调参数,请参考微调 API 规范。
上面的代码生成了作业 ID (`ftjob-0EVPunnseZ6Xnd0oGcnWBZA7`) 的以下信息:
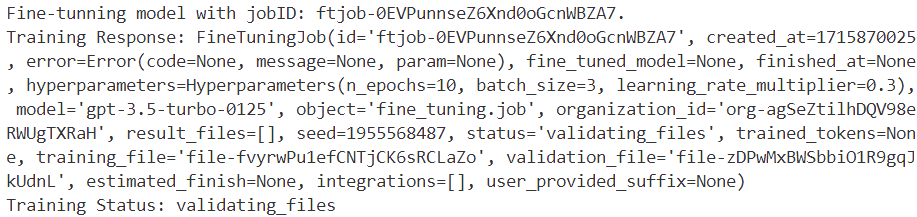
微调作业可能需要一些时间来完成。它可能排在其他作业后面,训练时间可能会因模型和数据集大小而异,从几分钟到几个小时不等。
一旦训练完成,发起微调作业的用户将收到电子邮件确认。
您可以通过微调 UI 监控微调作业的状态:
5. 分析微调后的模型
OpenAI 在训练期间计算以下指标:
- 训练损失
- 训练 token 准确率
- 验证损失
- 验证 token 准确率
验证损失和验证 token 准确率有两种计算方式:每个步骤的小数据批次和每个纪元结束时的完整验证集。完整的验证损失和完整的验证 token 准确率是跟踪模型性能的最准确指标,并作为确保训练顺利进行的合理性检查(损失应减少,token 准确率应增加)。
当微调作业处于活动状态时,您可以通过以下方式查看这些指标:
1. UI:
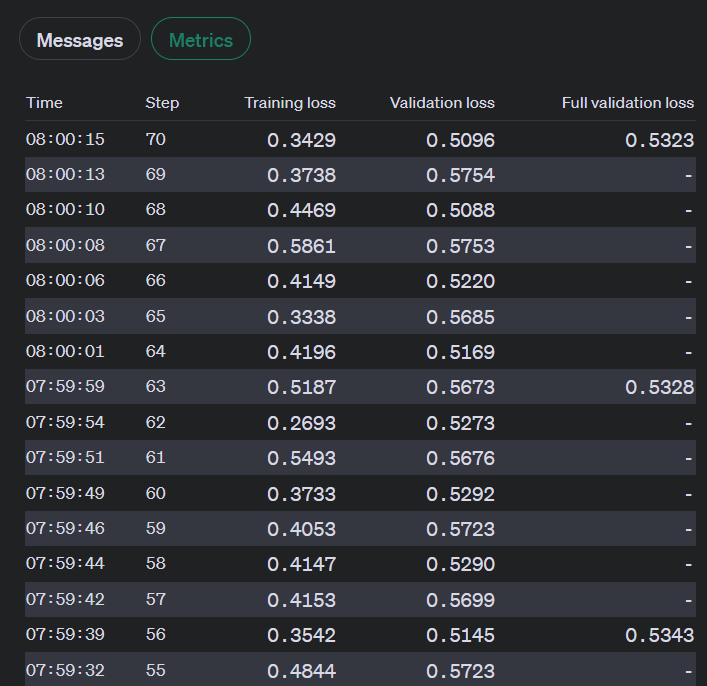
2. API:
import os
from openai import OpenAI
client = OpenAI(api_key=os.environ['OPENAI_API_KEY'],)
jobid = ‘jobid you want to monitor’
print(f"Streaming events for the fine-tuning job: {jobid}")
# signal.signal(signal.SIGINT, signal_handler)
events = client.fine_tuning.jobs.list_events(fine_tuning_job_id=jobid)
try:
for event in events:
print(
f'{event.data}'
)
except Exception:
print("Stream interrupted (client disconnected).")
上述代码将输出微调作业的流事件,包括步骤号、训练损失、验证损失、总步骤数以及训练和验证的平均 token 准确率:
Streaming events for the fine-tuning job: ftjob-0EVPunnseZ6Xnd0oGcnWBZA7
{'step': 67, 'train_loss': 0.30375099182128906, 'valid_loss': 0.49169286092122394, 'total_steps': 67, 'train_mean_token_accuracy': 0.8333333134651184, 'valid_mean_token_accuracy': 0.8888888888888888}
6. 调整参数和数据集以提高性能
如果微调作业的结果不如预期,可以考虑以下方法来提高性能:
1. 调整训练数据集:
- 为了改进您的训练数据集,请考虑添加解决模型弱点的示例,并确保您的数据中的响应分布与预期分布相匹配。
- 检查您的数据是否存在模型正在复制的问题,并确保您的示例包含响应所需的所有信息。
- 确保由多个人创建的数据的一致性,并将所有训练示例的格式标准化为推理时的预期格式。
- 一般来说,高质量的数据比大量低质量的数据更有效。
2. 调整超参数:
- OpenAI 允许您指定三个超参数;纪元、学习率乘数和批量大小。
- 从根据数据集大小由内置函数选择的默认值开始,然后根据需要进行调整。
- 如果模型没有按预期跟随训练数据,请增加纪元数。
- 如果模型的多样性低于预期,请减少纪元数 1 或 2。
- 如果模型没有收敛,请增加学习率乘数。
7. 使用检查点模型
目前,OpenAI 提供最近三个纪元的微调作业检查点。这些检查点是可用于推理和进一步微调的完整模型。
要访问这些检查点,请等待作业成功,然后使用您的微调作业 ID 查询 检查点端点。每个检查点对象将具有 fine_tuned_model_checkpoint 字段,填充了模型检查点名称。您还可以通过微调 UI 获取检查点模型名称。
您可以通过运行查询和模型名称使用 openai.chat.completions.create() 函数验证检查点模型结果:
completion = client.chat.completions.create(
model="ft:gpt-3.5-turbo-0125:personal::9PWZuZo5",
messages=[
{"role": "system", "content": "Instructions: You will be presented with a passage and a question about that passage. There are four options to be chosen from, you need to choose the only correct option to answer that question. If the first option is right, you generate the answer 'A', if the second option is right, you generate the answer 'B', if the third option is right, you generate the answer 'C', if the fourth option is right, you generate the answer 'D', if the fifth option is right, you generate the answer 'E'. Read the question and options thoroughly and select the correct answer from the four answer labels. Read the passage thoroughly to ensure you know what the passage entails"},
{"role": "user", "content": "Passage: For the school paper, five students\u2014Jiang, Kramer, Lopez, Megregian, and O'Neill\u2014each review one or more of exactly three plays: Sunset, Tamerlane, and Undulation, but do not review any other plays. The following conditions must apply: Kramer and Lopez each review fewer of the plays than Megregian. Neither Lopez nor Megregian reviews any play Jiang reviews. Kramer and O'Neill both review Tamerlane. Exactly two of the students review exactly the same play or plays as each other.Question: Which one of the following could be an accurate and complete list of the students who review only Sunset?\nA. Lopez\nB. O'Neill\nC. Jiang, Lopez\nD. Kramer, O'Neill\nE. Lopez, Megregian\nAnswer:"}
]
)
print(completion.choices[0].message)
从答案字典中检索到的结果如下:

您还可以在 OpenAI 的游乐场中将微调后的模型与其他模型进行比较,如下所示:
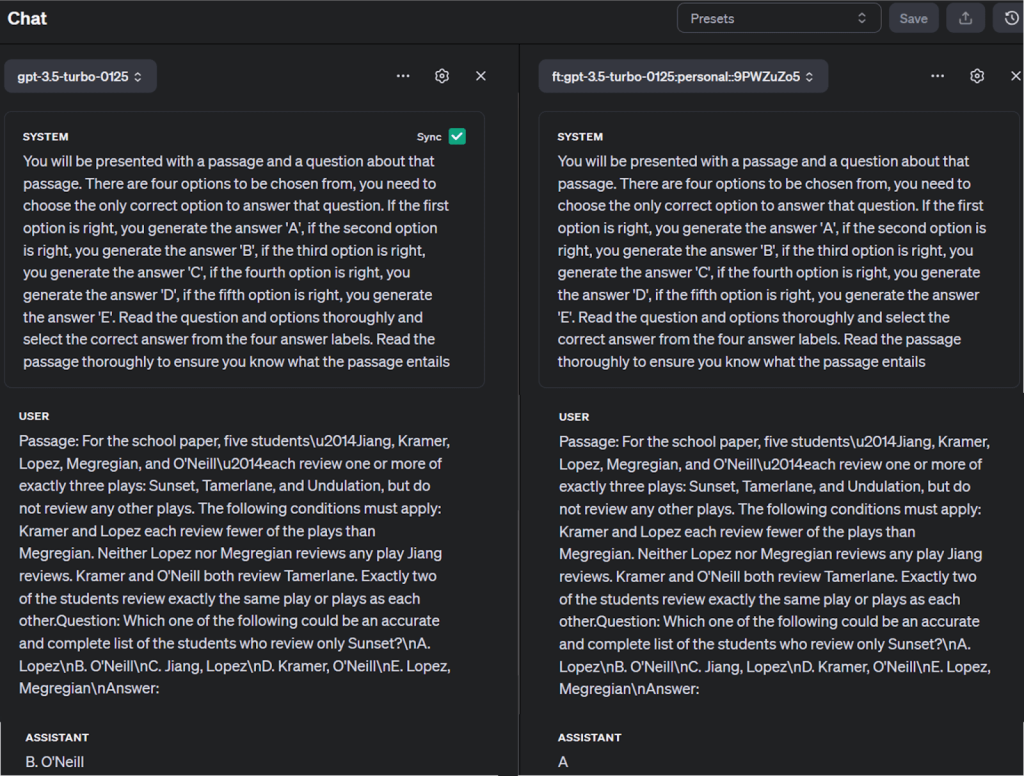
提示和最佳实践
为了成功微调,请考虑以下提示:
数据质量:确保您的任务特定数据干净、多样化和具有代表性,以避免过拟合,即模型在训练数据上表现良好但在未见数据上表现不佳。
超参数选择:选择适当的超参数以避免收敛缓慢或性能不佳。这可能很复杂且耗时,但对于有效训练至关重要。
资源管理:请注意,微调大型模型需要大量的计算资源和时间。
避免陷阱
过拟合和欠拟合:平衡模型的复杂性和训练量,以避免过拟合(高方差)和欠拟合(高偏差)。
灾难性遗忘:在微调过程中,模型可能会遗忘先前学到的一般知识。定期评估模型在各种任务上的性能,以减轻这种情况。
领域转移敏感性:如果您的微调数据与预训练数据差异显著,您可能会遇到领域转移问题。使用领域适应技术来弥合这一差距。
保存和重用模型
训练后,保存模型的状态以便以后重用。这包括模型参数和所用优化器的任何状态。这使您可以从相同的状态继续训练。
伦理考虑
偏见放大:预训练模型可能继承偏见,可能在微调过程中放大。如果需要无偏见的预测,请尽量选择经过偏见和公平性测试的预训练模型。
意外输出:微调模型可能会生成看似合理但不正确的输出。实施健全的后处理和验证机制来处理这一问题。
模型漂移:由于环境或数据分布的变化,模型性能可能会随着时间的推移而下降。定期监控模型的性能并在必要时重新微调。
高级技术和进一步学习
LLM 微调中的高级技术包括低秩适应(LoRA)和量化 LoRA(QLoRA),它们在保持性能的同时降低了计算和财务成本。参数高效微调(PEFT)通过最小的可训练参数高效地调整模型。DeepSpeed 和 ZeRO 优化大规模训练的内存使用。这些技术解决了如过拟合、灾难性遗忘和领域转移敏感性等挑战,提高了 LLM 微调的效率和效果。
除了微调之外,还有其他高级训练技术,例如迁移学习和强化学习。迁移学习涉及将从一个问题学到的知识应用到另一个相关问题,而强化学习是一种机器学习类型,代理通过在环境中采取行动以最大化奖励来学习决策。
对于那些有兴趣深入了解 AI 模型训练的人,以下资源可能会有所帮助:
- Attention is all you need by Ashish Vaswani et al.
- 《深度学习》书籍,由 Ian Goodfellow, Yoshua Bengio 和 Aaron Courville 撰写
- 《语音与语言处理》书籍,由 Daniel Jurafsky 和 James H. Martin 撰写
- 训练 LLMs 的不同方法
- 掌握 LLM 技术:训练
- Hugging Face 的 NLP 课程
结论
训练 AI 模型是一个迭代过程,涉及定义问题、准备数据、选择模型以及训练和评估模型。与从头开始训练相比,微调 OpenAI 模型是一个相对简单的过程。虽然您可能无法在第一次训练中获得理想结果,但请记住,AI 模型可以通过实验和实践不断改进。
经过良好训练的 AI 模型在各个行业都有变革性影响,从医疗到金融,从娱乐到教育。然而,真正带来不同的是数据的数量和质量。
您可以利用诸如 Bright Data 的 Web Scraping APIs 等工具无缝收集数据。这样,您可以在几分钟内访问数百万个数据点,从而帮助您更快、更高效地训练模型。此外,Bright Data 在其市场上提供大量数据集,并提供为您量身定制的自定义数据集选项。
现在注册并开始您的 Bright Data 爬虫基础设施免费试用。



