

Python 目前在全球范围内是最主要的网络爬虫编程语言。不过情况并非一直如此。在 20 世纪 90 年代末和 21 世纪初,几乎所有的网络爬虫都是由 Perl 和 PHP 来完成的。
今天,我们将让 Python 与过去的那位网络开发巨头——PHP 进行一场正面对决。我们会比较它们各自的特点,看哪个能带来更好的爬虫开发体验。
准备工作
如果你准备跟着一同实践,你需要先安装 Python 和 PHP。点击下面各自的下载链接,并根据你的操作系统进行安装。
你可以使用以下命令来检查它们是否已正确安装。
Python
python --version输出应类似如下:
Python 3.10.12PHP
php --version输出示例如下:
PHP 8.3.14 (cli) (built: Nov 25 2024 18:07:16) (NTS)
Copyright (c) The PHP Group
Zend Engine v4.3.14, Copyright (c) Zend Technologies
with Zend OPcache v8.3.14, Copyright (c), by Zend Technologies如果能够对这两门语言有基本了解会更好,但这并非硬性要求。事实上,我在写这篇文章之前从未用 PHP 写过任何代码!
比较:Python 与 PHP 在网络爬虫方面的表现
在正式开始项目之前,我们先来更详细地了解一下这两种语言。
- 语法(Syntax):Python 语法更加易读,并且在数据领域被广泛采用。
- 标准库(Standard Library):两种语言都提供了丰富的标准库。
- 爬虫框架(Scraping Frameworks):Python 拥有数量更多的爬虫框架。
- 性能(Performance):PHP 通常速度更快,因为它本身为 Web 环境而构建。
- 可维护性(Maintenance):Python 通常更易维护,语法清晰且社区支持强大。
| 特性 | Python | PHP |
|---|---|---|
| 易用性 | 对初学者友好,易于学习 | 对新开发者来说难度较高 |
| 标准库 | 丰富且功能全面 | 同样丰富且功能全面 |
| 爬虫工具 | 拥有大量第三方爬虫工具 | 生态系统较小 |
| 数据支持 | 在数据处理方面有先天优势 | 提供基础数据处理库和工具 |
| 社区 | 社区庞大,支持度高 | 社区规模更小,支持相对有限 |
| 可维护性 | 易于维护,使用广泛 | 难度更高,合格程序员相对难找 |
要爬取什么?
由于这只是一个示例,并且我们需要一个在基准测试过程中保持内容一致的网站,所以这里将使用 quotes.toscrape.com。这个网站始终提供相对固定的内容,而且不会屏蔽爬虫,完美适合用来做测试。
在下图中,你可以看到页面上的其中一个 quote(名言)条目。它是一个类名为 quote 的 div。我们首先需要找到页面上的所有这类条目。
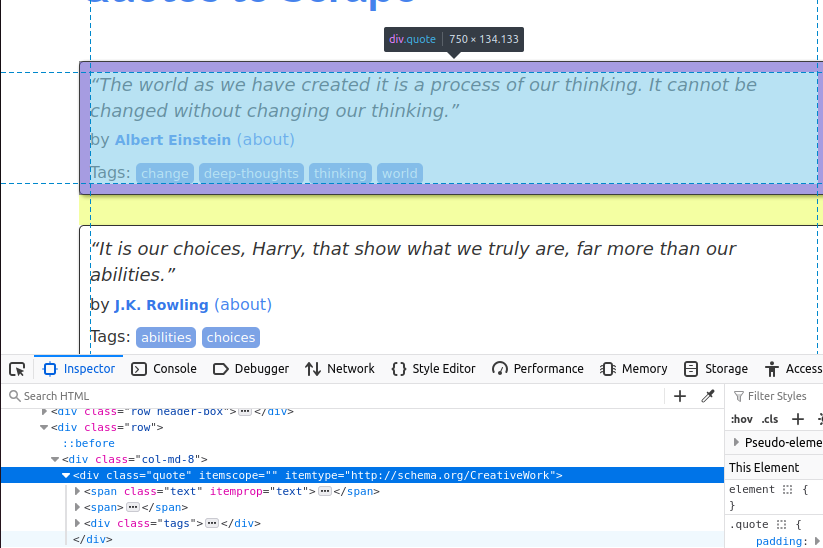
找到所有“quote”卡片后,我们需要从中提取各自的数据。
文本内容放在带有 class="text" 的 span 标签中。
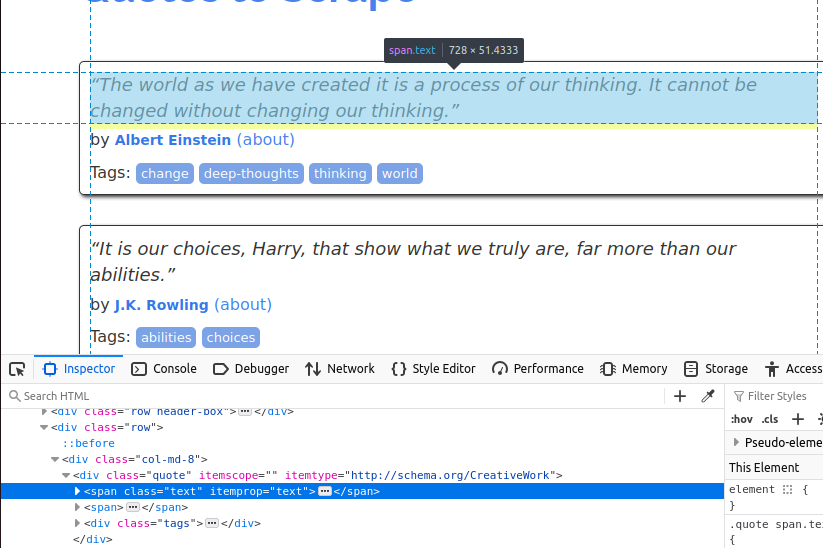
接下来,我们需要获取作者,该信息在带有 class="author" 的 small 标签里。
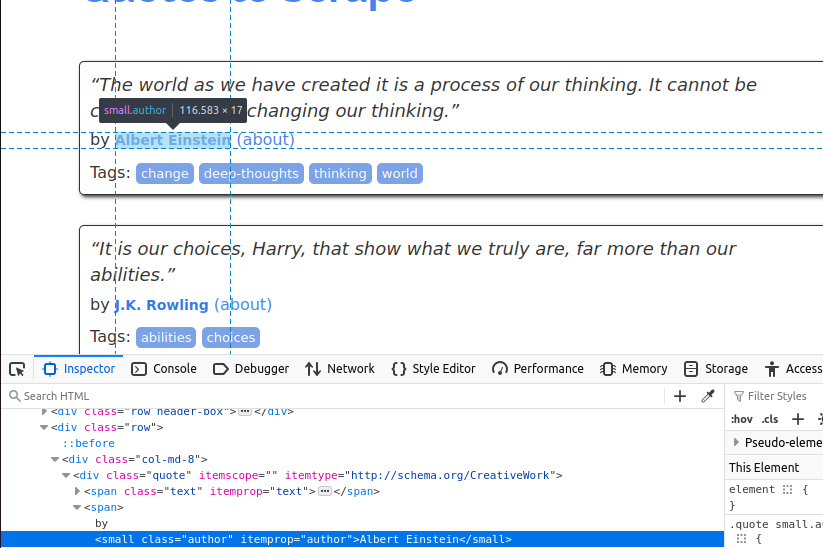
最后,我们需要提取标签(tags),它们位于带有 class="tag" 的 a 标签中。

至此,我们已经弄清了要获取的数据,下面就可以正式开始爬取。
开始动手
接下来,是环境配置阶段。无论是 Python 还是 PHP,都需要安装一些依赖。
Python
对于 Python,我们需要安装 Requests 和 BeautifulSoup。
使用 pip 可一次性完成这两个库的安装:
pip install requestspip install beautifulsoup4PHP
理论上,这些依赖在 PHP 中应当默认包含,但我的环境实际上并没有,所以我额外执行了以下命令:
sudo apt install php-curlsudo apt install php-xml在安装完所有依赖后,我们就可以开始写代码了。
开始爬取数据
我首先编写了一个 Python 爬虫。下面的代码会依次请求 quotes.toscrape.com,并且提取每个名言的文本、作者及标签。等全部爬完后,再把爬到的数据写入 JSON 文件。你可以复制并将其粘贴到你自己的 Python 文件中进行测试。
Python
import requests
from bs4 import BeautifulSoup
import json
page_number = 1
output_json = []
while page_number <= 5:
response = requests.get(f"https://quotes.toscrape.com/page/{page_number}")
soup = BeautifulSoup(response.text, "html.parser")
divs = soup.select("div[class='quote']")
for div in divs:
tags = []
quote_text = div.select_one("span[class='text']").text
author = div.select_one("small[class='author']").text
tag_holders = div.select("a[class='tag']")
for tag_holder in tag_holders:
tags.append(tag_holder.text)
quote_dict = {
"author": author,
"quote": quote_text.strip(),
"tags": tags
}
output_json.append(quote_dict)
page_number+=1
with open("quotes.json", "w") as file:
json.dump(output_json, file, indent=4)
print("Scraping complete. Quotes saved to quotes.json.")- 首先,定义了
page_number和output_json两个变量。 while page_number <= 5指定了我们要爬取前 5 页。response = requests.get(f"https://quotes.toscrape.com/page/{page_number}")通过请求获取页面内容。divs = soup.select("div[class='quote']")查找目标div元素。- 然后遍历
divs,提取具体内容:quote_text:div.select_one("span[class='text']").textauthor:div.select_one("small[class='author']").texttags: 查找所有带tag类的元素,然后循环取出文本。
- 最后,把
output_json保存到文件中,并打印一条提示信息。
下面是我们多次运行的截图——实际上跑了不止这些,为了简洁仅展示 3 次。
第 1 次运行耗时 11.642 秒。

第 2 次运行耗时 11.413 秒。

第 3 次运行耗时 10.258 秒。

Python 的平均运行时间约为 11.104 秒。
PHP
在写完 Python 脚本后,我让 ChatGPT 帮忙生成了 PHP 版本的代码。它最初没能正常工作,经过一些小的修改后才运行正常。
<?php
$pageNumber = 1;
$outputJson = [];
while ($pageNumber <= 5) {
$url = "https://quotes.toscrape.com/page/$pageNumber";
$ch = curl_init($url);
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
curl_setopt($ch, CURLOPT_FOLLOWLOCATION, true);
$response = curl_exec($ch);
curl_close($ch);
if ($response === false) {
echo "Error fetching page $pageNumber\n";
break;
}
$dom = new DOMDocument();
@$dom->loadHTML($response);
$xpath = new DOMXPath($dom);
$quoteDivs = $xpath->query("//div[@class='quote']");
foreach ($quoteDivs as $div) {
$quoteText = $xpath->query(".//span[@class='text']", $div)->item(0)->textContent ?? "";
$author = $xpath->query(".//small[@class='author']", $div)->item(0)->textContent ?? "";
$tagElements = $xpath->query(".//a[@class='tag']", $div);
$tags = [];
foreach ($tagElements as $tagElement) {
$tags[] = $tagElement->textContent;
}
$outputJson[] = [
"author" => trim($author),
"quote" => trim($quoteText),
"tags" => $tags
];
}
$pageNumber++;
}
$jsonData = json_encode($outputJson, JSON_PRETTY_PRINT | JSON_UNESCAPED_UNICODE);
file_put_contents("quotes.json", $jsonData);
echo "Scraping complete. Quotes saved to quotes.json.\n";
$jsonData = json_encode($outputJson, JSON_PRETTY_PRINT | JSON_UNESCAPED_UNICODE);
file_put_contents("quotes.json", $jsonData);
echo "Scraping complete. Quotes saved to quotes.json.\n";- 同 Python 版本类似,首先定义
$pageNumber与$outputJson。 - 通过
while ($pageNumber <= 5)控制要爬取的页面数。 $ch = curl_init($url);初始化 HTTP 请求,并通过curl_setopt()来配置跟随重定向。$response = curl_exec($ch);执行请求,拿到页面返回内容。$dom = new DOMDocument();用 DOMDocument 来解析 HTML;这与 Python 中使用BeautifulSoup类似。$quoteDivs = $xpath->query("//div[@class='quote']");使用 Xpath 而不是 CSS 选择器来获取所有目标div。$quoteText和$author分别通过 Xpath 获取。$tags则同样先获取所有标签节点,再循环取其文本。- 最后将所有数据以 JSON 格式写入文件,并打印提示信息。
以下是我们用 PHP 进行的运行结果:
第 1 次运行耗时 11.351 秒。

第 2 次运行耗时 9.846 秒。

第 3 次运行耗时 9.795 秒。

PHP 的平均运行时间约为 10.33 秒。
进行更多测试后,PHP 的确大多情况下要比 Python 更快,有时甚至仅需 7 秒左右!
考虑使用 Bright Data
如果上面那些内容让你觉得写爬虫很有趣,那就动手试试吧!当你开始从事数据采集工作时,你会发现自己会经常写些和上边类似的代码。
我们提供多种产品,能让你的爬虫功能更强大。Scraping Browser 为你提供了一台带有代理集成和 JavaScript 渲染功能的远程浏览器。如果你只需要代理和 验证码识别,可以使用 Web Unlocker。
当然,并不是所有人都需要自己写爬虫。
如果你只想拿到数据就完事,那就看看我们的数据集吧。我们来替你完成爬虫工作。浏览一下我们的 成品数据集。其中最受欢迎的有 LinkedIn、Amazon、Crunchbase、Zillow 和 Glassdoor。你可以免费查看示例数据,并以 CSV 或 JSON 格式下载。
结论
我们测试时,Python 平均速度大约是 11.104 秒,PHP 的平均速度则是 10.33 秒,PHP 在大多数测试中确实比 Python 更快。在更多的尝试中,PHP 几乎每次都能跑赢 Python,哪怕有一部分原因也许是网络时延误差。
PHP 在速度上略胜一筹,但在语法方面可能并没有那么友好。如今很多开发者并不熟悉 PHP 或 Perl 这样的“老牌”脚本语言。再加之团队对 PHP 可能并不熟练,因此需要一些熟悉这些语言的专门开发者来维护此类代码,这在当下并不算普遍。
想让你的爬虫操作更上一层楼?快来试试 Bright Data。立即注册并开始免费试用吧!



