
Perl 是最流行的编程语言之一,由于其广泛的模块集合,它是编写网页抓取程序的绝佳选择。
在本文中,我们将讨论以下内容:
- 使用 Perl 进行网页抓取的方法:
LWP::UserAgent和HTML::TreeBuilderWeb::ScraperMojo::UserAgent和Mojo::DOMXML::LibXML
- 使用 Perl 进行网页抓取的挑战
- 结论
使用 Perl 进行网页抓取
请确保你已安装最新版本的 Perl 来跟随本文进行操作。本文中的代码已在 Perl 5.38.2 版本中测试。本文假设你知道如何使用 cpanm 安装 Perl 模块。
在本文中,你将抓取 Quotes to Scrape 网站 来提取名言。在抓取数据之前,你需要了解 HTML 的结构。在浏览器中打开该网站,并按 CTRL + Shift + I (Windows) 或 Command + Shift + C (Mac) 来打开 检查元素 对话框。
当你检查元素时,可以看到每个名言都存储在一个 class 为 quote 的 div 中。每个名言包含一个 class 为 text 的 span 和一个 small 元素,分别存储文本和作者姓名:
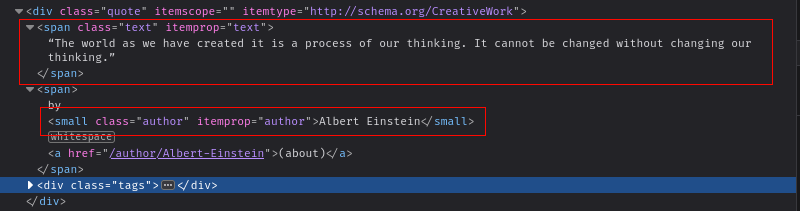
使用 LWP::UserAgent 和 HTML::TreeBuilder
LWP::UserAgent 是 LWP 模块的一部分,它们与网页进行交互。LWP::UserAgent 模块可以用来向网页发出 HTTP 请求并返回 HTML 内容。然后,你可以使用 HTML::TreeBuilder 模块从 HTML::Tree 解析 HTML 并提取信息。
要使用 LWP::UserAgent 和 HTML::TreeBuilder,请使用以下命令安装模块:
cpanm Bundle::LWP
cpanm HTML::Tree创建一个名为 lwp-and-tree-builder.pl 的文件。这是你将编写代码的地方。然后在该文件中粘贴以下两行代码:
use LWP::UserAgent;
use HTML::TreeBuilder;这段代码指示 Perl 解释器包含 LWP::UserAgent 和 HTML::TreeBuilder 模块。
定义一个 LWP::UserAgent 实例,并将 User-Agent 头设置为 Quotes Scraper:
my $ua = LWP::UserAgent->new;
$ua->agent("Quotes Scraper");定义目标网站的 URL 并创建一个 HTML::TreeBuilder 实例:
my $url = "https://quotes.toscrape.com/";
my $root = HTML::TreeBuilder->new();现在你可以发出 HTTP 请求:
my $request = $ua->get($url) or die "An error occurred $!n";粘贴以下 if-else 语句,检查请求是否成功:
if ($request->is_success) {
} else {
print "Cannot parse the result. " . $request->status_line . "n";
}如果请求成功,你可以开始抓取。
使用 HTML::TreeBuilder 的 parse 方法解析 HTML 响应。在 if 块中粘贴以下代码:
$root->parse($request->content);现在,使用 look_down 方法查找 class 为 quote 的 div 元素:
my @quotes = $root->look_down(
_tag => 'div',
class => 'quote'
);遍历名言数组,使用 look_down 查找文本和作者,并打印它们:
foreach my $quote (@quotes) {
my $text = $quote->look_down(
_tag => 'span',
class => 'text'
)->as_text;
my $author = $quote->look_down(
_tag => 'small',
class => 'author'
)->as_text;
print "$text: $authorn";
}完整的代码如下:
use LWP::UserAgent;
use HTML::TreeBuilder;
my $ua = LWP::UserAgent->new;
$ua->agent("Quotes Scraper");
my $url = "https://quotes.toscrape.com/";
my $root = HTML::TreeBuilder->new();
my $request = $ua->get($url) or die "An error occurred $!n";
if ($request->is_success) {
$root->parse($request->content);
my @quotes = $root->look_down(
_tag => 'div',
class => 'quote'
);
foreach my $quote (@quotes) {
my $text = $quote->look_down(
_tag => 'span',
class => 'text'
)->as_text;
my $author = $quote->look_down(
_tag => 'small',
class => 'author'
)->as_text;
print "$text: $authorn";
}
} else {
print "Cannot parse the result. " . $request->status_line . "n";
}使用 perl lwp-and-tree-builder.pl 运行此代码,你应该会看到以下输出:
"The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.": Albert Einstein
"It is our choices, Harry, that show what we truly are, far more than our abilities.": J.K. Rowling
"There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.": Albert Einstein
"The person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.": Jane Austen
"Imperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.": Marilyn Monroe
"Try not to become a man of success. Rather become a man of value.": Albert Einstein
"It is better to be hated for what you are than to be loved for what you are not.": André Gide
"I have not failed. I've just found 10,000 ways that won't work.": Thomas A. Edison
"A woman is like a tea bag; you never know how strong it is until it's in hot water.": Eleanor Roosevelt
"A day without sunshine is like, you know, night.": Steve Martin使用 Web::Scraper
Web::Scraper 是一个受 Ruby 的 ScrAPI 启发的网页抓取库。它提供了一个领域特定语言 (DSL) 用于抓取 HTML 和 XML 文档。查看此文章以了解更多关于 使用 Ruby 进行网页抓取 的信息。
要使用 Web::Scraper,请使用 cpanm Web::Scraper 安装模块。
创建一个名为 web-scraper.pl 的新文件,并包含以下必需模块:
use URI;
use Web::Scraper;
use Encode;接下来,你需要使用该模块的 DSL 定义一个 scraper 块。DSL 使得定义一个抓取器变得简单,只需要几行代码。首先定义一个名为 $quotes 的 scraper 块:
my $quotes = scraper {
};scraper 方法定义了抓取器的逻辑,当稍后调用 scrape 方法时,它会执行。在 scraper 块内,你可以使用 process 方法通过 CSS 选择器找到元素并执行一个函数。
首先找到所有 class 为 quote 的 div 元素:
# Parse all `div` with class `quote`
process 'div.quote', "quotes[]" => scraper {
};此代码找到所有 class 为 quote 的 div 元素,并将它们存储在 quotes 数组中。对于每个元素,它运行 scraper 方法,你可以使用以下代码定义:
# And, in each div, find `span` with class `text`
process_first "span.text", text => 'TEXT';
# get `small` with class `author`
process_first "small", author => 'TEXT';process_first 方法找到匹配 CSS 选择器的第一个元素。在这里,你找到第一个 class 为 text 的 span 元素,然后提取其文本并存储在 text 键中。对于作者姓名,你找到第一个 small 元素并提取文本存储在 author 键中。
完整的 scraper 块如下所示:
my $quotes = scraper {
# Parse all `div` with class `quote`
process 'div.quote', "quotes[]" => scraper {
# And, in each div, find `span` with class `text`
process_first "span.text", text => 'TEXT';
# get `small` with class `author`
process_first "small", author => 'TEXT';
};
};现在,调用 scrape 方法并传递 URL 开始抓取:
my $res = $quotes->scrape( URI->new("https://quotes.toscrape.com/") );最后,遍历 quotes 数组并打印结果:
# iterate over the array
for my $quote (@{$res->{quotes}}) {
print Encode::encode("utf8", "$quote->{text}: $quote->{author}n");
}完整的代码如下:
use URI;
use Web::Scraper;
use Encode;
my $quotes = scraper {
# Parse all `div` with class `quote`
process 'div.quote', "quotes[]" => scraper {
# And, in each div, find `span` with class `text`
process_first "span.text", text => 'TEXT';
# get `small` with class `author`
process_first "small", author => 'TEXT';
};
};
my $res = $quotes->scrape( URI->new("https://quotes.toscrape.com/") );
# iterate over the array
for my $quote (@{$res->{quotes}}) {
print Encode::encode("utf8", "$quote->{text}: $quote->{author}n");
}使用 perl web-scraper.pl 运行之前的代码,你应该会得到以下输出:
"The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.": Albert Einstein
"It is our choices, Harry, that show what we truly are, far more than our abilities.": J.K. Rowling
"There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.": Albert Einstein
"The person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.": Jane Austen
"Imperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.": Marilyn Monroe
"Try not to become a man of success. Rather become a man of value.": Albert Einstein
"It is better to be hated for what you are than to be loved for what you are not.": André Gide
"I have not failed. I've just found 10,000 ways that won't work.": Thomas A. Edison
"A woman is like a tea bag; you never know how strong it is until it's in hot water.": Eleanor Roosevelt
"A day without sunshine is like, you know, night.": Steve Martin使用 Mojo::UserAgent 和 Mojo::DOM
Mojo::UserAgent 和 Mojo::DOM 是 Mojolicious 框架的一部分,这是一款实时 Web 框架。在功能上,它们与 LWP::UserAgent 和 HTML::TreeBuilder 类似。
要使用 Mojo::UserAgent 和 Mojo::DOM,请使用以下命令安装模块:
cpanm Mojo::UserAgent
cpanm Mojo::DOM创建一个名为 mojo.pl 的新文件,并包含 Mojo::UserAgent 和 Mojo::DOM 模块:
use Mojo::UserAgent;
use Mojo::DOM;定义一个 Mojo::UserAgent 实例并发出 HTTP 请求:
my $ua = Mojo::UserAgent->new;
my $res = $ua->get('https://quotes.toscrape.com/')->result;类似于 LWP ::UserAgent,使用以下 if-else 块检查请求是否成功:
if ($res->is_success) {
} else {
print "Cannot parse the result. " . $res->message . "n";
}在 if 块中,初始化 Mojo::DOM 的一个实例:
my $dom = Mojo::DOM->new($res->body);使用 find 方法找到所有 class 为 quote 的 div 元素:
my @quotes = $dom->find('div.quote')->each;遍历 quotes 数组并提取文本和作者姓名:
foreach my $quote (@quotes) {
my $text = $quote->find('span.text')->map('text')->join;
my $author = $quote->find('small.author')->map('text')->join;
print "$text: $authorn";
}完整的代码如下:
use Mojo::UserAgent;
use Mojo::DOM;
my $ua = Mojo::UserAgent->new;
my $res = $ua->get('https://quotes.toscrape.com/')->result;
if ($res->is_success) {
my $dom = Mojo::DOM->new($res->body);
my @quotes = $dom->find('div.quote')->each;
foreach my $quote (@quotes) {
my $text = $quote->find('span.text')->map('text')->join;
my $author = $quote->find('small.author')->map('text')->join;
print "$text: $authorn";
}
} else {
print "Cannot parse the result. " . $res->message . "n";
}使用 perl mojo.pl 运行此代码,你应该会得到以下输出:
"The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.": Albert Einstein
"It is our choices, Harry, that show what we truly are, far more than our abilities.": J.K. Rowling
"There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.": Albert Einstein
"The person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.": Jane Austen
"Imperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.": Marilyn Monroe
"Try not to become a man of success. Rather become a man of value.": Albert Einstein
"It is better to be hated for what you are than to be loved for what you are not.": André Gide
"I have not failed. I've just found 10,000 ways that won't work.": Thomas A. Edison
"A woman is like a tea bag; you never know how strong it is until it's in hot water.": Eleanor Roosevelt
"A day without sunshine is like, you know, night.": Steve Martin使用 XML::LibXML
Perl 模块 XML::LibXML 是 libxml2 库的包装器。XML::LibXML 模块提供了一个强大的 XHTML 解析器,具有 XPath 功能。
使用 cpanm 安装该模块:
cpanm XML::LibXML然后创建一个名为 xml-libxml.pl 的新文件。与 HTML::TreeBuilder 一样,你需要使用类似 LWP::UserAgent 的库来向网站发出 HTTP 请求并获取 HTML 内容,然后将其传递给 XML::LibXML。
粘贴以下代码,设置 LWP::UserAgent 模块并获取网页的 HTML 内容:
use LWP::UserAgent;
use XML::LibXML;
use open qw( :std :encoding(UTF-8) );
my $ua = LWP::UserAgent->new;
$ua->agent("Quotes Scraper");
my $url = "https://quotes.toscrape.com/";
my $request = $ua->get($url) or die "An error occurred $!n";
if ($request->is_success) {
} else {
print "Cannot parse the result. " . $request->status_line . "n";
}在 if 块内,使用 load_html 方法解析 HTML 文档:
$dom = XML::LibXML->load_html(string => $request->content, recover => 1, suppress_errors => 1);recover 选项告诉解析器在发生错误时继续解析 HTML,而 suppress_errors 选项则阻止解析器将 HTML 解析错误打印到控制台。由于 HTML 文档不像 XHTML 文档那样严格验证,你可能会遇到非致命的解析错误。这些选项可确保代码在发生这些错误时继续运行。
一旦 HTML 解析完成,你可以使用 findnodes 方法根据 XPath 表达式查找元素:
my $xpath = '//div[@class="quote"]';
foreach my $quote ($dom->findnodes($xpath)) {
my ($text) = $quote->findnodes('.//span[@class="text"]')->to_literal_list;
my ($author) = $quote->findnodes('.//small[@class="author"]')->to_literal_list;
print "$text: $authorn";
}完整的代码如下:
use LWP::UserAgent;
use XML::LibXML;
use open qw( :std :encoding(UTF-8) );
my $ua = LWP::UserAgent->new;
$ua->agent("Quotes Scraper");
my $url = "https://quotes.toscrape.com/";
my $request = $ua->get($url) or die "An error occurred $!n";
if ($request->is_success) {
$dom = XML::LibXML->load_html(string => $request->content, recover => 1, suppress_errors => 1);
my $xpath = '//div[@class="quote"]';
foreach my $quote ($dom->findnodes($xpath)) {
my ($text) = $quote->findnodes('.//span[@class="text"]')->to_literal_list;
my ($author) = $quote->findnodes('.//small[@class="author"]')->to_literal_list;
print "$text: $authorn";
}
} else {
print "Cannot parse the result. " . $request->status_line . "n";
}使用 perl xml-libxml.pl 运行代码,你应该会看到以下输出:
"The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.": Albert Einstein
"It is our choices, Harry, that show what we truly are, far more than our abilities.": J.K. Rowling
"There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.": Albert Einstein
"The person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.": Jane Austen
"Imperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.": Marilyn Monroe
"Try not to become a man of success. Rather become a man of value.": Albert Einstein
"It is better to be hated for what you are than to be loved for what you are not.": André Gide
"I have not failed. I've just found 10,000 ways that won't work.": Thomas A. Edison
"A woman is like a tea bag; you never know how strong it is until it's in hot water.": Eleanor Roosevelt
"A day without sunshine is like, you know, night.": Steve Martin你可以在这个 GitHub 仓库 中找到本教程的所有代码。
使用 Perl 进行网页抓取的挑战
尽管 Perl 通过其强大的模块使得抓取网页变得容易,但开发人员经常会遇到一些常见的问题,这些问题可能会减慢或完全阻碍网页抓取。以下是你可能会面临的一些挑战。
处理分页
处理大量数据的网站通常不会一次性发送所有数据。通常,数据会分多个页面发送,你需要处理分页以确保提取所有数据。处理分页有两个步骤:
- 检查是否存在其他页面。通常,你可以在页面上寻找一个 下一页 按钮,或者尝试加载下一页并查找错误。
- 如果存在其他页面,加载下一页并抓取它。
对于静态网站,每个页面都有自己的 URL,你可以运行一个循环,通过增加 URL 中的页码参数来加载新页面。或者,如果你使用的是类似 WWW::Mechanize 的模块,你可以简单地跟随 下一页 URL。
以下是修改后的名言抓取器,使用 WWW::Mechanize 处理分页。注意 follow_link 的使用:
use WWW::Mechanize ();
use HTML::TreeBuilder;
use open qw( :std :encoding(UTF-8) );
my $mech = WWW::Mechanize->new();
my $url = "https://quotes.toscrape.com/";
my $root = HTML::TreeBuilder->new();
my $request = $mech->get($url);
my $next_page = $mech->find_link(text_regex => qr/Next/);
while ($next_page) {
$root->parse($mech->content);
my @quotes = $root->look_down(
_tag => 'div',
class => 'quote'
);
foreach my $quote (@quotes) {
my $text = $quote->look_down(
_tag => 'span',
class => 'text'
)->as_text;
my $author = $quote->look_down(
_tag => 'small',
class => 'author'
)->as_text;
print "$text: $authorn";
}
$mech->follow_link(url => $next_page->url);
$next_page = $mech->find_link(text_regex => qr/Next/);
}要处理使用 JavaScript 加载下一页的动态网站,请查看我们的指南 使用 Python 抓取动态网站,或继续阅读。
轮换代理
代理通常被网页抓取程序用来保护隐私和匿名性,并避免 IP 地址被封禁。类似 LWP::UserAgent 的模块可以设置代理进行抓取。然而,使用单个代理服务器仍然有被封禁的风险。因此,建议使用多个代理服务器并轮换它们。以下是如何使用 LWP::UserAgent 进行简单轮换的示例。
首先定义一个代理数组。然后随机选择一个并使用 proxy 方法设置代理:
my @proxies = ( 'https://proxy1.com', 'https://proxy2.com', 'http://proxy3.com' );
my $index = rand @proxies;
my $proxy = $proxies[$index];
$ua->proxy(['http', 'https'], $proxy);现在,你可以像往常一样发送请求。如果请求失败,很可能表示代理已被封禁,因此你可以将该代理从列表中删除,选择另一个代理并再次尝试:
if(request->is_success) {
# Continue with the scraping
} else {
# Remove the proxy from the list
splice(@proxies, $index, 1);
# Try again
}处理蜜罐陷阱
蜜罐陷阱 是网站管理员常用的技术,用来捕捉机器人和抓取程序。通常,它们会使用 display 属性设置为 none 的链接,使其对人类用户不可见。但机器人可以捕获并跟随这些链接,导致被引导到一个诱捕网页,而不是主要产品。
为了解决这个问题,在跟随链接之前检查其 display 属性。以下是使用 HTML::TreeBuilder 的一种方法:
my @links = $root->look_down(
_tag => 'a',
);
foreach my $link (@qlinks) {
my $style = $link->attr('style');
if(defined $style && $style =~ /dislay: none/) {
# Honeypot detected!
} else {
# Safe to proceed
}
}解决 CAPTCHAs
CAPTCHAs 有助于防止未经授权访问网站。然而,它们也可能阻止网页抓取程序抓取网页。
为了对抗 CAPTCHAs,你可以使用像 Bright Data Web Unlocker 这样的服务,它会 为你解决 CAPTCHAs。
以下是一个使用 Bright Data Web Unlocker 发出 HTTP 请求的示例:
use LWP::UserAgent;
my $agent = LWP::UserAgent->new();
$agent->proxy(['http', 'https'], "http://brd-customer-hl_6d74fc42-zone-residential_proxy4:[email protected]:22225");
print $agent->get('http://lumtest.com/myip.json')->content();当你使用 Web Unlocker 发出 HTTP 请求时,它会自动解决 CAPTCHAs,规避反机器人措施,并为你处理代理管理。
抓取动态网站
到目前为止,你学到的所有示例都抓取静态网站。然而,单页应用程序 (SPA) 和其他动态网站需要更高级的技术。
动态网站使用 JavaScript 加载页面内容,这意味着你需要能够运行 JavaScript 的抓取工具。Selenium 是一种这样的工具,它可以模拟浏览器来运行动态网站。以下是该模块的一个小示例代码片段:
use Selenium::Remote::Driver;
my $driver = Selenium::Remote::Driver->new;
$driver->get('http://example.com');
my $elem = $driver->find_element_by_id('foo');
print $elem->get_text();
$driver->quit();结论
得益于其强大的模块集合,Perl 是进行网页抓取的优秀语言。在本文中,你学会了如何使用以下方法抓取网页:
LWP::UserAgent和HTML::TreeBuilderWeb::ScraperMojo::UserAgent和Mojo::DOMXML::LibXML
然而,正如你所见,当网站所有者决心防止抓取时,网页抓取在现实生活中会面临许多挑战。本文介绍了一些常见的场景及其应对方法。然而,尝试自己解决这些挑战可能会很繁琐且容易出错。此时,Bright Data 可以提供帮助。通过 最佳代理服务、抓取浏览器、Web Unlocker 和 终极 Web 抓取 API,Bright Data 是一套全面的抓取解决方案。







