

总结:本教程将教您如何使用 Ruby 从网站提取数据,以及为什么它是爬取的最有效语言之一。
本指南将涵盖:
- Ruby 适合网页爬取吗?
- 最佳 Ruby 网页爬取宝石
- 用 Ruby 构建一个网页爬取器
Ruby 适合网页爬取吗?
Ruby 是一种解释性、开源、动态类型的编程语言,支持函数式、面向对象和过程式开发。它设计简单,语法优雅,易于编写,自然易读。由于其注重生产力,Ruby 在多个应用中广受欢迎,包括网页爬取。
特别是,由于有大量的第三方库可用,Ruby 是爬取的绝佳选择。这些库被称为“宝石”,几乎每个任务都有相应的宝石。在编程获取网页信息时,有用于下载页面、分析 HTML 内容和从中提取数据的宝石。
总之,使用 Ruby 进行网页爬取不仅可能,而且由于许多可用的库,这个过程也变得容易。让我们来看看哪些是最受欢迎的宝石吧!
最佳 Ruby 网页爬取宝石
以下是三种最佳的 Ruby 网页爬取库:
- Nokogiri(鋸):一个强大且灵活的 HTML 和 XML 解析库,具有完整的 API,用于遍历和操作 HTML/XML 文档,使得从中提取相关数据变得容易。
- Mechanize:一个具有无头浏览器功能的库,提供了用于自动化与网站交互的高级 API。它可以存储和发送 Cookie,处理重定向,跟随链接并提交表单。此外,它提供了一个历史记录来跟踪访问过的网站。
- Selenium:一个用于在网页上运行自动化测试的最流行框架的 Ruby 绑定。它可以指示浏览器像人类用户一样与网站交互。这项技术在绕过反机器人解决方案和爬取依赖于 JavaScript 渲染或检索数据的网站方面起着关键作用。
先决条件
在编写代码之前,您需要在您的机器上安装 Ruby。请按照下面与您的操作系统相关的指南进行操作。
在 macOS 上安装 Ruby
默认情况下,自 2015 年发布的 macOS 10.11(El Capitan)版本开始,macOS 中包含了 Ruby。考虑到 macOS 本身依赖于 Ruby 提供某些功能,因此不建议修改它。使用 brew install ruby 或 update ruby mac 更新本机 Ruby 版本可能会破坏某些内置功能。
在 Windows 上安装 Ruby
下载 RubyInstaller 软件包,启动它,并按照安装向导设置 Ruby。可能需要系统重启。从 Windows 10 开始,您还可以使用 Windows Subsystem for Linux 按照以下说明安装 Ruby。
在 Linux 上安装 Ruby
在 Linux 上设置 Ruby 环境的最佳方法是通过包管理器进行安装。
在 Debian 和 Ubuntu 中,运行以下命令:
sudo apt-get install ruby-full在其他发行版中,运行的终端命令会有所不同。请参阅 官方网站上的指南 查看所有支持的包管理系统。
无论您的操作系统是什么,您现在都可以验证 Ruby 是否正常工作:
ruby -v这应该会打印出类似以下内容的信息:
ruby 3.2.2 (2023-03-30 revision e51014f9c0)太好了!您现在可以开始使用 Ruby 进行网页爬取了!
用 Ruby 构建一个网页爬取器
在本节中,您将学习如何创建一个 Ruby 网页爬取器。这个自动化脚本将从 Bright Data 首页检索数据。具体来说,它将:
- 连接到目标网站
- 从 DOM 中选择感兴趣的 HTML 元素
- 从中提取数据
- 将爬取的数据转换为易于探索的格式,如 CSV 和 JSON
撰写本文时,用户访问目标网页时看到的内容如下所示:
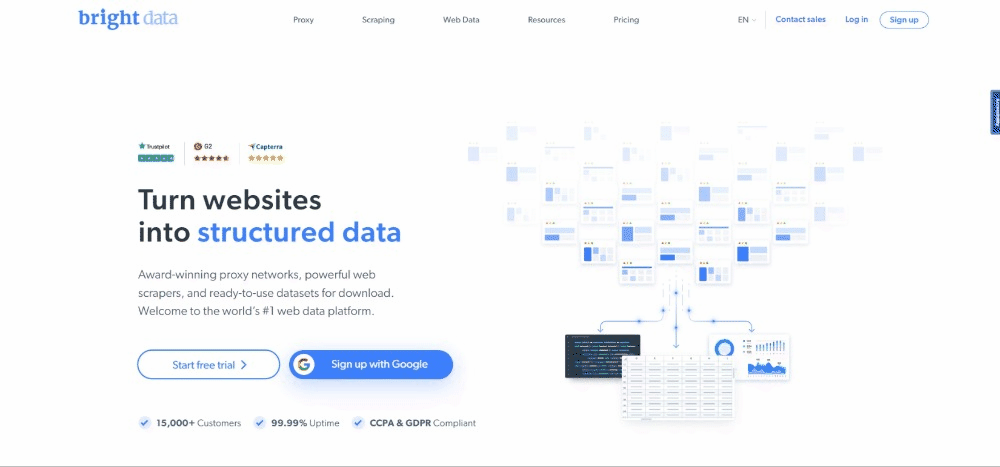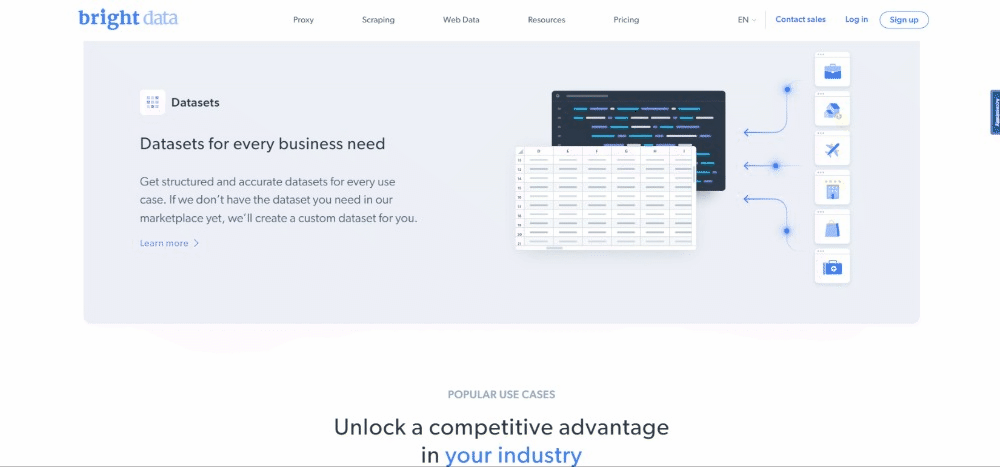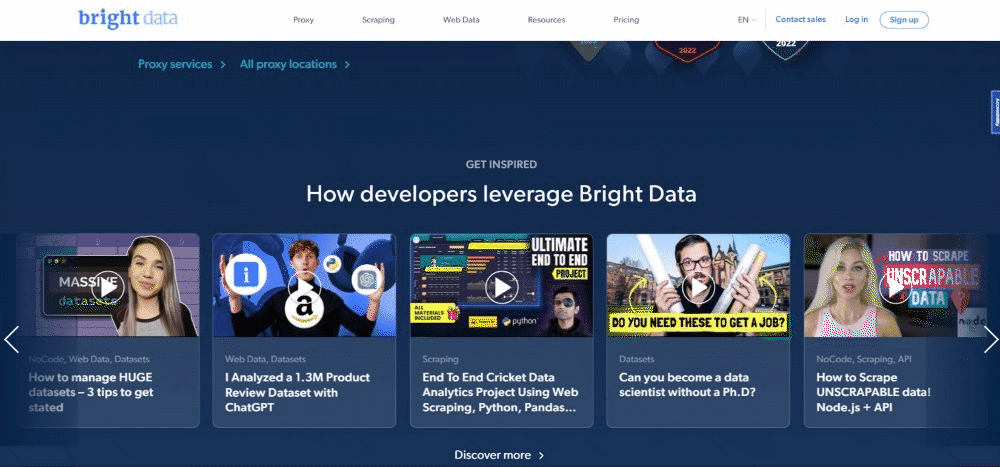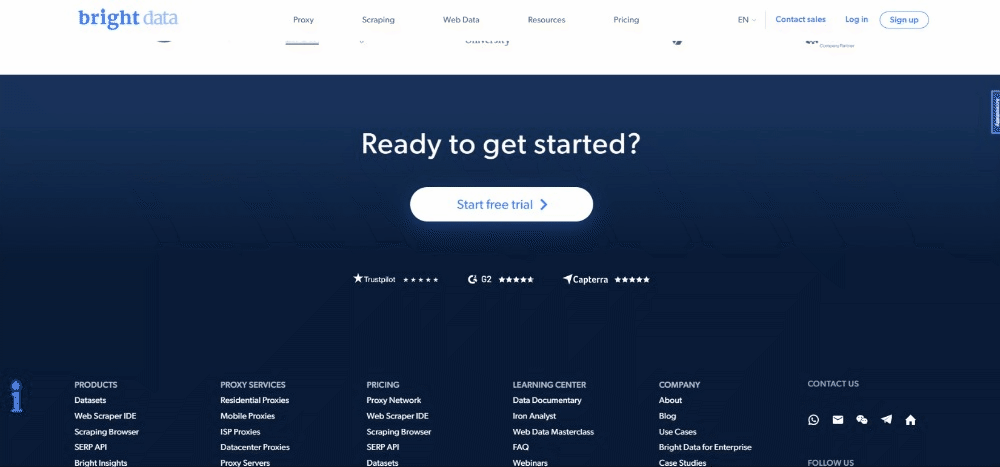
请注意,BrightData 首页经常变化,在您阅读本文时可能不再相同。
具体爬取目标是获取包含在以下卡片中的用例信息:
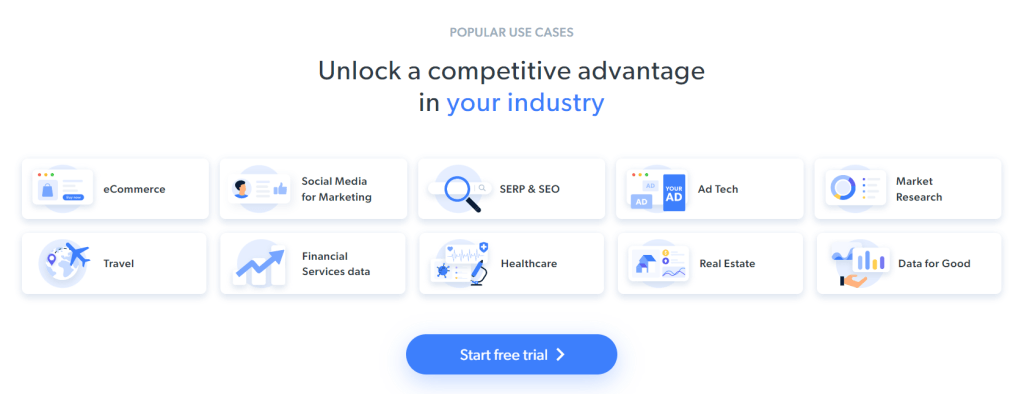
按照下面的分步教程,学习如何使用 Ruby 进行网页爬取!
步骤 1:初始化一个 Ruby 项目
在开始之前,您需要设置您的 Ruby 项目。启动终端,创建项目文件夹,并进入它:
mkdir ruby-web-scraper
cd ruby-web-scraperruby-web-scraper 目录将包含您的爬取器。
接下来,在项目文件夹中初始化一个 scraper.rb 文件,并添加以下内容:
puts "Hello, World!"上面的代码段是最简单的 Ruby 脚本。
通过在终端中运行以下命令验证它是否工作:
ruby scraper.rb这应该会打印出以下消息:
Hello, World!现在是时候在您的 IDE 中导入您的项目并开始定义一些高级的 Ruby 爬取逻辑了!在本指南中,您将学习如何设置 Visual Studio Code (VS Code) 以进行 Ruby 开发。同时,任何其他 Ruby IDE 都可以。
由于 VS Code 不原生支持 Ruby,您首先需要添加 Ruby 扩展。启动 Visual Studio Code,点击左侧栏中的“扩展”图标,并在顶部的搜索输入框中输入“Ruby”。
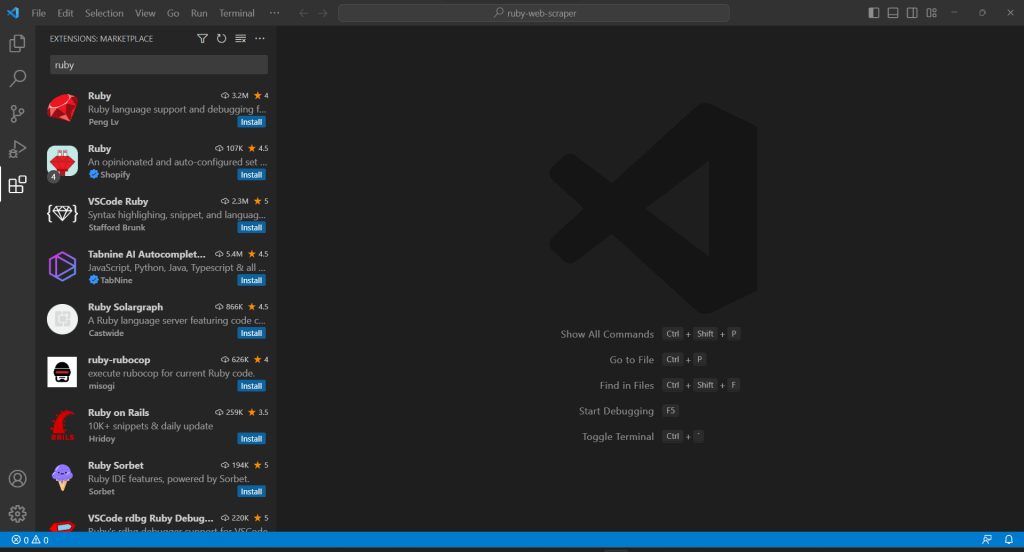
点击第一个元素上的“安装”按钮,以将 Ruby 高亮功能添加到 VS Code。等待插件添加到 IDE。然后,通过“文件”→“打开文件夹…”打开 ruby-web-scraper 文件夹。
点击“EXPLORER”栏下的 scraper.rb 文件,开始编辑文件:
步骤 2:选择爬取库
在 Ruby 中构建一个网页爬取器变得更容易有了正确的库。为此,您应该采用前面介绍的宝石之一。为了确定哪个 Ruby 网页爬取库最适合您的目标,您需要花些时间分析目标网站。
为此,请在浏览器中访问目标页面,在背景的空白处右键单击,然后点击“检查”选项。这将启动浏览器的开发者工具。在 Chrome 中,访问“网络”选项卡,探索“Fetch/XHR”部分。

如上图所示,只有七个 AJAX 请求。深入研究每个 XHR 调用,您会发现它们不涉及任何有意义的数据。这意味着目标页面在渲染时不会检索内容。换句话说,服务器返回的 HTML 文档已经包含了所有要显示给用户的数据。
这证明目标网页不使用 JavaScript 进行数据检索或渲染。因此,您不需要具有无头浏览器功能的宝石来执行网页爬取。您仍然可以使用 Mechanize 或 Selenium,但它们只会增加一些性能开销。毕竟,它们在后台运行一个浏览器实例,这需要资源。
总之,您应该选择一个简单的 HTML/XML 解析器,如 Nokogiri。通过 nokogiri 宝石进行安装:
gem install nokogiri然后,在 scraper.rb 文件的顶部添加以下行来导入库:
require "nokogiri"确保您的 Ruby IDE 不会报告任何错误,现在您可以用 Ruby 来爬取一些数据了!
步骤 3:使用 HTTParty 获取目标页面
要解析目标页面的 HTML 文档,您首先需要通过 HTTP GET 请求下载它。Ruby 附带了一个内置的 HTTP 客户端 Net::HTTP,但它的语法有点繁琐且不直观。您应该使用 HTTParty,这是最流行的用于执行 HTTP 请求的 Ruby 库。
通过 httparty 宝石安装它:
gem install httparty
Then, import it in the scraper.rb file:
require "httparty"
Use HTTParty to connect to the target page with:
response = HTTParty.get("https://brightdata.com/")get() 方法允许您对传递的 URL 执行 GET 请求。response.body 字段将包含服务器返回的 HTML 文档。
请注意,通过 get() 执行的 HTTP 请求可能会失败。当发生这种情况时,HTTParty 会引发异常并以错误停止脚本的执行。失败的原因可能有很多,但通常发生的是目标站点采用的反机器人技术拦截并阻止了您的自动化请求。最基本的反爬系统倾向于过滤掉没有有效 User-Agent HTTP 标头的请求。请查看我们的文章以了解更多有关 用于网页爬取的用户代理的信息。
与其他 HTTP 客户端一样,HTTParty 使用一个占位符用户代理。这通常与流行浏览器使用的代理非常不同,使得其请求很容易被反机器人解决方案识别。为避免因为这个原因被拦截,您可以在 HTTParty 中指定一个有效的用户代理,如下所示:
response = HTTParty.get("https://brightdata.com/", {
headers: { "User-Agent" => "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36"},
})通过 get() 执行的请求现在将向服务器显示为来自 Google Chrome 112。
这是scraper.rb 目前包含的内容:
require "nokogiri"
require "httparty"
# get the target page
response = HTTParty.get("https://brightdata.com/", {
headers: {
"User-Agent" => "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36",
},
})
# scraping logic...步骤 4:使用 Nokogiri 解析 HTML 文档
要解析与目标网页关联的 HTML 文档,请将其内容传递给 Nokogiri HTML() 函数:
doc = Nokogiri::HTML(response.body)现在,您可以利用通过 doc 变量提供的 DOM 操作和探索 API。特别是选择 HTML 元素的两个最重要的方法是:
两种方法都有效,但 CSS 查询通常是表达您正在寻找的内容的最简单方法。
步骤 5:为感兴趣的 HTML 元素定义 CSS 选择器
要了解如何在目标页面上选择所需的 HTML 元素,您需要分析 DOM。在浏览器中访问 Bright Data 首页,右键单击一个感兴趣的卡片,然后选择“检查”:
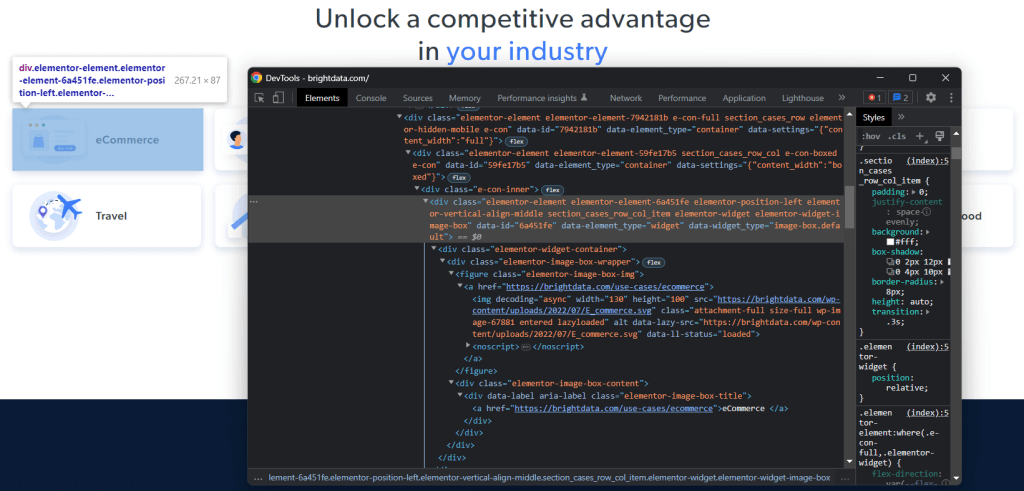
花一些时间在开发者工具部分中探索 HTML 代码。每个用例卡片都是一个 <div>,包含:
- 一个包含 <img> HTML 元素的 <figure>,显示与行业相关的图片和一个包含指向行业页面 URL 的 <a> 元素。
- 一个存储行业名称的 <div> HTML 元素,包含一个 <a> 标签。
Ruby 爬取器的数据提取目标是从每个卡片中获取图片 URL、页面 URL 和行业名称。
要定义好的 CSS 选择器,请将注意力转移到分配给目标 DOM 节点的 CSS 类。您会注意到,可以使用以下 CSS 选择器获取所有用例卡片:
.section_cases_row_col_item给定一个卡片,您可以通过其 <figure> 和 <div> 子节点选择存储相关数据的节点:
- figure img
- figure a
- .elementor-image-box-content a
步骤 6:使用 Nokogiri 从网页中爬取数据
现在,您需要使用 Nokogiri 从目标 HTML 网页中检索所需数据。
在深入研究数据爬取逻辑之前,不要忘记您需要一些数据结构来存储收集的数据。为此,您可以通过 Struct定义一个 UseCase 类:
UseCase = Struct.new(:image, :url, :name)在 Ruby 中,Struct 允许您将一个或多个属性捆绑在同一个数据类中。上述 struct 具有三个属性,对应于从每个用例卡片中检索到的信息。
初始化一个空的 UseCase 数组,并实现爬取逻辑来填充它:
# initialize the list of objects
# that will store all retrieved data
use_cases = []
# select all use case HTML elements
use_case_cards = doc.css(".section_cases_row_col_item")
# iterate over the HTML cards
use_case_cards.each do |use_case_card|
# extract the data of interest
image = use_case_card.at_css("figure img").attribute("data-lazy-src").value
url = use_case_card.at_css("figure a").attribute("href").value
name = use_case_card.at_css(".elementor-image-box-content a").text
# instantiate an UseCase object with the
# collected data
use_case = UseCase.new(url, image, name)
# add the UseCase instance to the array
# of scraped objects
use_cases.push(use_case)
end上面的代码段选择了所有用例卡片并遍历它们。然后,它使用 at_css() 从每个卡片中爬取图片 URL、行业页面 URL 和名称。这是一个返回第一个匹配 CSS 查询的元素的 Nokogiri 函数,是以下方法的快捷方式:
image = use_case_card.css("figure img").first.attribute("data-lazy-src").value最后,它使用检索到的数据实例化一个新的 UseCase 对象并将其添加到列表中。
使用 Ruby 和 Nokogiri 进行网页爬取非常简单。通过 attribute() ,您可以从当前 HTML 元素中选择一个属性。然后,value 字段使您能够获取其值。同样,text 字段直接将当前 HTML 节点中包含的所有文本作为纯字符串返回。
现在,您可以进一步爬取用例行业页面。您可以跟随在此处发现的链接并实现针对它们的新爬取逻辑。欢迎进入 网页爬取和网页抓取 的世界!
太棒了!您刚刚学习了如何使用 Ruby 实现您的爬取目标。不过,还有一些课程需要学习。
步骤 7:导出爬取的数据
在 each() 循环之后,use_cases 将包含以 Ruby 对象形式表示的爬取数据。这不是向其他团队提供数据的最佳格式。幸运的是,Ruby 内置了 CSV 和 JSON 转换功能。了解如何将检索到的数据导出为 CSV 和 JSON。
要导出为 CSV,请导入以下宝石:
import "csv"这是 Ruby 标准 API 的一部分,提供了一个完整的接口来处理 CSV 文件和数据。
您可以利用它将 use_cases 数组导出到 output.csv 文件,如下所示:
# populate the CSV output file
CSV.open("output.csv", "wb") do |csv|
# write the CSV header
csv << ["url", "image", "name"]
# transfrom each use case scraped info to a
# CSV record
use_cases.each do |use_case|
csv << use_case
end
end上面的代码段创建了 output.csv 文件。然后,它打开文件并初始化为头记录。接下来,它遍历 use_cases 数组并将其附加到 CSV 文件。当使用 << 运算符时,Ruby 将自动将每个 use_case 实例转换为字符串数组,以满足内置 CSV 类的要求。
尝试通过以下命令运行脚本:
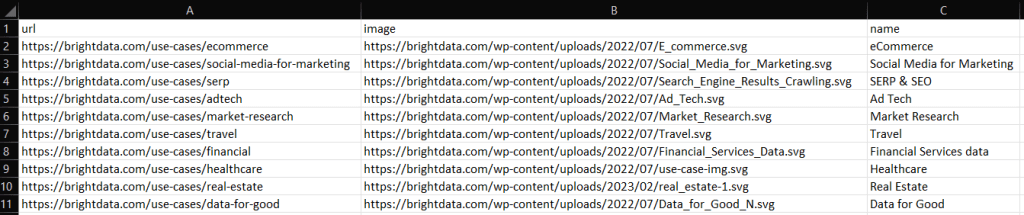
ruby scraper.rb将在您的项目根目录中生成一个包含以下数据的 output.csv 文件:
同样,您可以将 use_cases 导出到 output.json:
# propulate the JSON output file
File.open("output.json", "wb") do |json|
json << JSON.pretty_generate(use_cases.map { |u| Hash[u.each_pair.to_a] })
end这将生成以下 JSON 文件:
[
{
"image": "https://brightdata.com/use-cases/ecommerce",
"url": "https://brightdata.com/wp-content/uploads/2022/07/E_commerce.svg",
"name": "eCommerce "
},
// ...
{
"image": "https://brightdata.com/use-cases/data-for-good",
"url": "https://brightdata.com/wp-content/uploads/2022/07/Data_for_Good_N.svg",
"name": "Data for Good"
}
]瞧!现在您知道如何在 Ruby 中将结构体数组转换为 CSV 和 JSON!
步骤 8:将所有内容结合起来
以下是 Ruby 爬取器的完整代码:
# scraper.rb
require "nokogiri"
require "httparty"
require "csv"
# get the target page
response = HTTParty.get("https://brightdata.com/", {
headers: {
"User-Agent" => "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/112.0.0.0 Safari/537.36",
},
})
# parse the HTML document retrieved with the GET request
doc = Nokogiri::HTML(response.body)
# define a class where to keep the scraped data
UseCase = Struct.new(:image, :url, :name)
# initialize the list of objects
# that will store all retrieved data
use_cases = []
# select all use case HTML elements
use_case_cards = doc.css(".section_cases_row_col_item")
# iterate over the HTML cards
use_case_cards.each do |use_case_card|
# extract the data of interest
image = use_case_card.at_css("figure img").attribute("data-lazy-src").value
url = use_case_card.at_css("figure a").attribute("href").value
name = use_case_card.at_css(".elementor-image-box-content a").text
# instantiate an UseCase object with the
# collected data
use_case = UseCase.new(url, image, name)
# add the UseCase instance to the array
# of scraped objects
use_cases.push(use_case)
end
# populate the CSV output file
CSV.open("output.csv", "wb") do |csv|
# write the CSV header
csv << ["url", "image", "name"]
# transfrom each use case scraped info to a
# CSV record
use_cases.each do |use_case|
csv << use_case
end
end
# propulate the JSON output file
File.open("output.json", "wb") do |json|
json << JSON.pretty_generate(use_cases.map { |u| Hash[u.each_pair.to_a] })
end在大约 50 行代码中,您可以在 Ruby 中创建一个数据爬取脚本!
总结
在本教程中,您了解了为什么 Ruby 是一个出色的爬取互联网的语言。您还了解了哪些是最好的网页爬取 Ruby 宝石库、为什么以及它们提供了哪些功能。然后,您深入研究了如何使用 Nokogiri 和 Ruby 的标准 API 构建一个可以爬取真实世界目标的 Ruby 爬取器。正如您所见,使用 Ruby 进行数据爬取只需很少的代码行数。
然而,不要低估从网页中提取数据时的挑战。这就是为什么越来越多的网站实施了反机器人和反爬系统来保护他们的数据。这些技术能够检测到由您的 Ruby 爬取脚本执行的请求,并阻止访问网站。幸运的是,您可以使用 Bright Data 的下一代网页爬取 IDE 构建一个能够绕过这些拦截的网页爬取器。
不想处理网页爬取,但对网页数据感兴趣? 探索我们的现成数据集。


