

当你进行网络爬取时,无论使用哪种工具,HTML 解析都是至关重要的。使用 Java 进行网络爬取也不例外。在 Python 中,我们会使用像Requests和BeautifulSoup这样的工具。在 Java 中,我们可以通过jsoup来发送 HTTP 请求并解析 HTML。本教程中,我们将使用Books to Scrape作为示例。
开始之前
在本教程中,我们将使用 Maven 进行依赖管理。如果你还没有安装 Maven,可以在这里进行安装。
安装好 Maven 以后,就可以创建一个新的 Java 项目。下面的命令会创建一个名为jsoup-scraper的新项目:
mvn archetype:generate -DgroupId=com.example -DartifactId=jsoup-scraper -DarchetypeArtifactId=maven-archetype-quickstart -DinteractiveMode=false接下来,你需要添加相关的依赖。将 pom.xml 文件中的代码替换成以下内容。这与在Rust中使用 Cargo 进行依赖管理的方式类似。
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.example</groupId>
<artifactId>jsoup-scraper</artifactId>
<packaging>jar</packaging>
<version>1.0-SNAPSHOT</version>
<name>jsoup-scraper</name>
<url>http://maven.apache.org</url>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.jsoup</groupId>
<artifactId>jsoup</artifactId>
<version>1.16.1</version>
</dependency>
</dependencies>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
</properties>
</project>接下来,将以下代码粘贴到 App.java 中。虽然内容很少,但这是我们要基于其进行拓展的基础爬虫示例。
package com.example;
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class App {
public static void main(String[] args) {
String url = "https://books.toscrape.com";
int pageCount = 1;
while (pageCount <= 1) {
try {
System.out.println("---------------------PAGE "+pageCount+"--------------------------");
//connect to a website and get its HTML
Document doc = Jsoup.connect(url).get();
//print the title
System.out.println("Page Title: " + doc.title());
} catch (Exception e) {
e.printStackTrace();
}
}
System.out.println("Total pages scraped: "+(pageCount-1));
}
}Jsoup.connect("https://books.toscrape.com").get():这一行会获取页面内容,并返回一个可供我们操作的Document对象。doc.title()返回 HTML 文档中的标题,这里是:All products | Books to Scrape - Sandbox。
使用 jsoup 的 DOM 方法
jsoup 提供了多种查找 DOM(文档对象模型)元素的方法。我们可以使用以下方法轻松找出页面中的元素:
getElementById():根据id查找元素。getElementsByClass():根据元素的 CSS 类查找元素。getElementsByTag():根据 HTML 标签查找元素。getElementsByAttribute():根据特定属性查找元素。
getElementById
在目标网站的侧边栏中,有一个 id 为 promotions_left 的 div。可以在下图中看到:
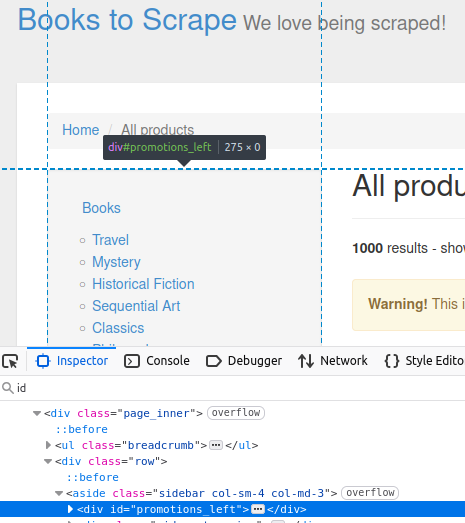
//get by Id
Element sidebar = doc.getElementById("promotions_left");
System.out.println("Sidebar: " + sidebar);上述代码会输出在「检查元素」中看到的 HTML 元素:
Sidebar: <div id="promotions_left">
</div>getElementsByTag
getElementsByTag() 可以找出页面上所有使用某一个标签的元素。让我们来查看页面上的书籍。
每本书都被放在一个独立的 article 标签里。
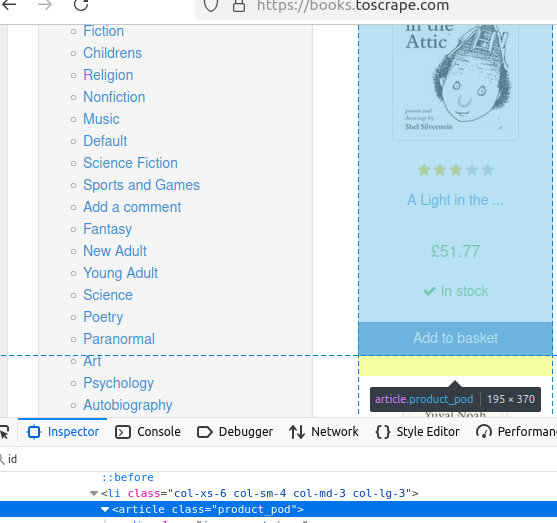
下面的代码不会打印任何信息,但它会返回包含这些书本内容的数组。后续的数据都将基于这些书籍。
//get by tag
Elements books = doc.getElementsByTag("article");getElementsByClass
下面是获取书本价格的示例。可以看出它使用的类名是 price_color。
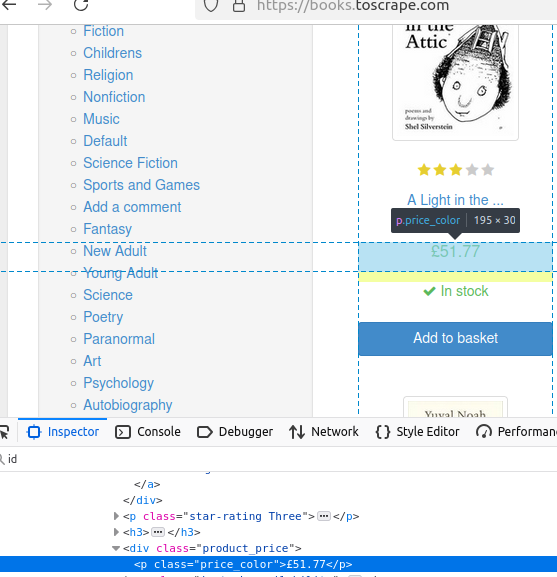
在下面的代码中,我们找到所有 price_color 类的元素。然后通过 .first().text() 打印其中第一个元素的文本。
System.out.println("Price: " + book.getElementsByClass("price_color").first().text());getElementsByAttribute
如你所知,所有的 a 元素都需要一个 href 属性。下面的代码使用 getElementsByAttribute("href") 找到所有含有 href 的元素。然后使用 .first().attr("href") 获取它的 href 属性值。
//get by attribute
Elements hrefs = book.getElementsByAttribute("href");
System.out.println("Link: https://books.toscrape.com/" + hrefs.first().attr("href"));进阶技巧
CSS 选择器
当需要使用多种条件来查找元素时,可以将CSS 选择器传进 select() 方法。这个方法返回一个包含所有匹配元素的数组。下面的示例中,我们使用 li[class='next'] 来查找带有 next 类的所有 li 元素。
Elements nextPage = doc.select("li[class='next']");处理分页
在处理分页时,我们调用 nextPage.first(),并对其使用 getElementsByAttribute("href").attr("href") 来获取 href。有意思的是,从第 2 页开始,链接中会去掉 catalogue 这个词,所以如果 href 中没有包含 catalogue,我们就再补上。然后我们将这个链接跟基础 URL 拼接起来,得到下一页的链接。
if (!nextPage.isEmpty()) {
String nextUrl = nextPage.first().getElementsByAttribute("href").attr("href");
if (!nextUrl.contains("catalogue")) {
nextUrl = "catalogue/"+nextUrl;
}
url = "https://books.toscrape.com/" + nextUrl;
pageCount++;
}整合所有代码
下面是最终完整的代码。如果想要抓取多页数据,只需将 while (pageCount <= 1) 里的 1 改成你想要的页数限制。如果想抓取 4 页,可以写成 while (pageCount <= 4)。
import org.jsoup.Jsoup;
import org.jsoup.nodes.Document;
import org.jsoup.nodes.Element;
import org.jsoup.select.Elements;
public class App {
public static void main(String[] args) {
String url = "https://books.toscrape.com";
int pageCount = 1;
while (pageCount <= 1) {
try {
System.out.println("---------------------PAGE "+pageCount+"--------------------------");
//connect to a website and get its HTML
Document doc = Jsoup.connect(url).get();
//print the title
System.out.println("Page Title: " + doc.title());
//get by Id
Element sidebar = doc.getElementById("promotions_left");
System.out.println("Sidebar: " + sidebar);
//get by tag
Elements books = doc.getElementsByTag("article");
for (Element book : books) {
System.out.println("------Book------");
System.out.println("Title: " + book.getElementsByTag("img").first().attr("alt"));
System.out.println("Price: " + book.getElementsByClass("price_color").first().text());
System.out.println("Availability: " + book.getElementsByClass("instock availability").first().text());
//get by attribute
Elements hrefs = book.getElementsByAttribute("href");
System.out.println("Link: https://books.toscrape.com/" + hrefs.first().attr("href"));
}
//find the next button using its CSS selector
Elements nextPage = doc.select("li[class='next']");
if (!nextPage.isEmpty()) {
String nextUrl = nextPage.first().getElementsByAttribute("href").attr("href");
if (!nextUrl.contains("catalogue")) {
nextUrl = "catalogue/"+nextUrl;
}
url = "https://books.toscrape.com/" + nextUrl;
pageCount++;
}
} catch (Exception e) {
e.printStackTrace();
}
}
System.out.println("Total pages scraped: "+(pageCount-1));
}
}运行这段代码之前,请先进行编译:
mvn package然后使用以下命令来运行:
mvn exec:java -Dexec.mainClass="com.example.App"下面是第一页的输出示例:
---------------------PAGE 1--------------------------
Page Title: All products | Books to Scrape - Sandbox
Sidebar: <div id="promotions_left">
</div>
------Book------
Title: A Light in the Attic
Price: £51.77
Availability: In stock
Link: https://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html
------Book------
Title: Tipping the Velvet
Price: £53.74
Availability: In stock
Link: https://books.toscrape.com/catalogue/tipping-the-velvet_999/index.html
------Book------
Title: Soumission
Price: £50.10
Availability: In stock
Link: https://books.toscrape.com/catalogue/soumission_998/index.html
------Book------
Title: Sharp Objects
Price: £47.82
Availability: In stock
Link: https://books.toscrape.com/catalogue/sharp-objects_997/index.html
------Book------
Title: Sapiens: A Brief History of Humankind
Price: £54.23
Availability: In stock
Link: https://books.toscrape.com/catalogue/sapiens-a-brief-history-of-humankind_996/index.html
------Book------
Title: The Requiem Red
Price: £22.65
Availability: In stock
Link: https://books.toscrape.com/catalogue/the-requiem-red_995/index.html
------Book------
Title: The Dirty Little Secrets of Getting Your Dream Job
Price: £33.34
Availability: In stock
Link: https://books.toscrape.com/catalogue/the-dirty-little-secrets-of-getting-your-dream-job_994/index.html
------Book------
Title: The Coming Woman: A Novel Based on the Life of the Infamous Feminist, Victoria Woodhull
Price: £17.93
Availability: In stock
Link: https://books.toscrape.com/catalogue/the-coming-woman-a-novel-based-on-the-life-of-the-infamous-feminist-victoria-woodhull_993/index.html
------Book------
Title: The Boys in the Boat: Nine Americans and Their Epic Quest for Gold at the 1936 Berlin Olympics
Price: £22.60
Availability: In stock
Link: https://books.toscrape.com/catalogue/the-boys-in-the-boat-nine-americans-and-their-epic-quest-for-gold-at-the-1936-berlin-olympics_992/index.html
------Book------
Title: The Black Maria
Price: £52.15
Availability: In stock
Link: https://books.toscrape.com/catalogue/the-black-maria_991/index.html
------Book------
Title: Starving Hearts (Triangular Trade Trilogy, #1)
Price: £13.99
Availability: In stock
Link: https://books.toscrape.com/catalogue/starving-hearts-triangular-trade-trilogy-1_990/index.html
------Book------
Title: Shakespeare's Sonnets
Price: £20.66
Availability: In stock
Link: https://books.toscrape.com/catalogue/shakespeares-sonnets_989/index.html
------Book------
Title: Set Me Free
Price: £17.46
Availability: In stock
Link: https://books.toscrape.com/catalogue/set-me-free_988/index.html
------Book------
Title: Scott Pilgrim's Precious Little Life (Scott Pilgrim #1)
Price: £52.29
Availability: In stock
Link: https://books.toscrape.com/catalogue/scott-pilgrims-precious-little-life-scott-pilgrim-1_987/index.html
------Book------
Title: Rip it Up and Start Again
Price: £35.02
Availability: In stock
Link: https://books.toscrape.com/catalogue/rip-it-up-and-start-again_986/index.html
------Book------
Title: Our Band Could Be Your Life: Scenes from the American Indie Underground, 1981-1991
Price: £57.25
Availability: In stock
Link: https://books.toscrape.com/catalogue/our-band-could-be-your-life-scenes-from-the-american-indie-underground-1981-1991_985/index.html
------Book------
Title: Olio
Price: £23.88
Availability: In stock
Link: https://books.toscrape.com/catalogue/olio_984/index.html
------Book------
Title: Mesaerion: The Best Science Fiction Stories 1800-1849
Price: £37.59
Availability: In stock
Link: https://books.toscrape.com/catalogue/mesaerion-the-best-science-fiction-stories-1800-1849_983/index.html
------Book------
Title: Libertarianism for Beginners
Price: £51.33
Availability: In stock
Link: https://books.toscrape.com/catalogue/libertarianism-for-beginners_982/index.html
------Book------
Title: It's Only the Himalayas
Price: £45.17
Availability: In stock
Link: https://books.toscrape.com/catalogue/its-only-the-himalayas_981/index.html
Total pages scraped: 1结论
现在你已经了解如何使用 jsoup 来提取 HTML 中的数据,你可以开始构建更加复杂的网络爬虫。不论是在爬取商品信息、新闻文章,还是研究数据时,处理动态内容与避免被封锁都是关键挑战。
如果想更加高效地扩大爬取规模,可以考虑使用 Bright Data 提供的工具:
通过将 jsoup 与合适的基础设施相结合,你能够在尽量避免被检测的情况下批量提取数据。准备好让你的网络爬取更上层楼了吗?立即注册并开始你的免费试用吧。
支持支付宝等多种支付方式




