

Rust 网页爬取终极指南
在本指南中,您将学习:
- Rust 是否适合网页爬取。
- 最佳 Rust 网页爬取库。
- 如何用 Rust 构建网页爬取器。
- 如何使您的爬取操作符合道德并尊重他人。
让我们开始吧!
Rust 适合进行网页爬取吗?
Rust 是一种静态类型编程语言,以其对安全性、性能和并发性的关注而闻名。近年来,它因其高效性而受到广泛欢迎,这使它成为各种应用的优秀选择,包括网页爬取。
Rust 为在线数据爬取提供了有价值的特性。特别是其强大的并发模型,能够同时执行多个网页请求。这一特性使它成为一种高效从不同网站提取大量数据的多功能语言。
此外,Rust 生态系统包含了 HTTP 客户端和 HTML 解析库,以简化网页检索和数据提取的过程。让我们来看一下最顶尖的一些库!
最佳 Rust 网页爬取库
最流行和广泛采用的 Rust 网页爬取库包括:
- reqwest:一个强大的 Rust HTTP 客户端,能够实现无缝的网页请求和交互。
- scraper:一个灵活的 Rust HTML 解析库,能够高效地从 HTML 文档中提取数据。
- rust-headless-chrome:使用 Rust 进行无头 Chrome 浏览器自动化,提供动态网页爬取的强大解决方案。
- thirtyfour:Rust 对 Selenium 的绑定,允许通过与浏览器交互进行自动化测试和网页爬取。
前提条件
按照以下说明准备编写一些 Rust 代码。
设置环境
开始之前,您必须在计算机上安装 Rust。要验证您是否已经安装,打开终端并输入以下命令:
rustc --version如果结果类似于以下内容,您就可以开始了:
rustc 1.75.0 (82e1608df 2023-12-21)使用以下命令更新 Rust 到最新版本:
rustup update如果该命令返回错误,则需要安装 Rust。从官方网站下载安装程序,启动它并按照向导进行操作。这将设置:
关闭所有打开的终端窗口,并重复本节开头的命令。这次您会得到所需的结果。
太好了!您现在已经安装好了 Rust!
创建一个 Rust 项目
假设您想创建一个名为 simple_rust_web_scraper 的新 Rust 项目。打开终端并执行以下cargo new命令:
cargo new simple_rust_web_scraper如果一切按预期进行,您将收到以下消息:
Created binary (application) `simple_rust_web_scraper` package具体来说,该命令将创建一个 simple_rust_web_scraper 文件夹。打开它,注意它包含:
- Cargo.toml:用于指定项目依赖项的清单文件。
- src/:用于放置 Rust 文件的文件夹。默认情况下,它为您初始化一个示例 main.rs 文件。
在您的 Rust IDE 中打开 simple_rust_web_scraper。例如,使用Rust 扩展的 Visual Studio Code 将非常适合:
导航到 src/ 文件夹,打开 main.rs 文件,您将看到这些行:
fn main() {
println!("Hello, world!");
}这只是一个简单的 Rust 脚本,在终端中打印“Hello, world!”。特别是,main() 函数代表任何 Rust 应用程序的入口点,您将在这里编写爬取逻辑。
太棒了!只需验证您的新 Rust 项目是否正常工作!
在您的 IDE 终端中打开终端,运行此命令以编译您的 Rust 应用程序:
cargo build在项目根文件夹中将出现一个存储二进制文件的 target/ 文件夹。
运行与您的代码关联的已编译二进制可执行文件:
cargo run这应该在终端中打印:
Finished dev [unoptimized + debuginfo] target(s) in 0.05s
Running `targetdebugsimple_rust_web_scraper.exe`
Hello, world!前两行只是日志信息,可以忽略。关注最后一行,看到项目按预期生成了“Hello, World!”消息。
完美!您现在有了一个 Rust 项目。是时候编写一些 Rust 网页爬取逻辑了!
如何在 Rust 中构建网页爬取器
在这个逐步教程部分,您将学习如何使用 Rust 进行网页爬取。具体来说,您将构建一个 Rust 网页爬取器,自动从Scrape This Site Country sandbox中收集数据。这是目标页面的样子:
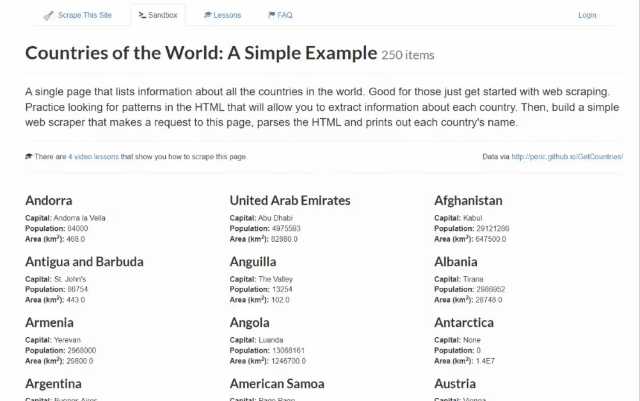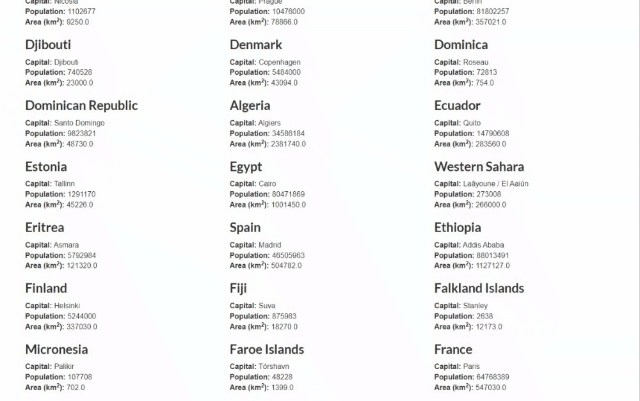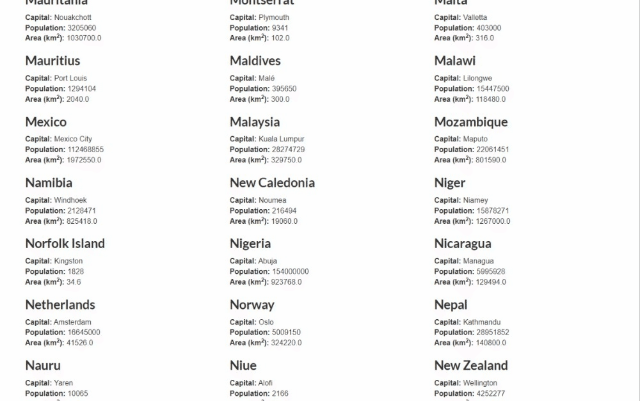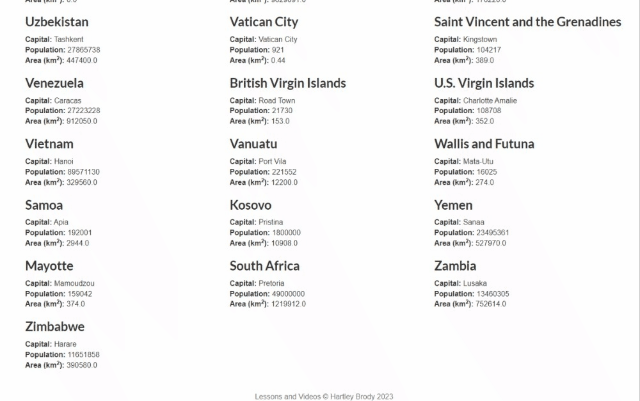
如您所见,它包含了世界上所有国家的列表和一些有趣的信息。
Rust 网页爬取脚本将执行以下操作:
- 连接到目标页面并解析其 HTML。
- 从页面中选择国家 HTML 元素。
- 从中提取数据并将其存储在 Rust 数据结构中。
- 将收集到的数据转换为人类可读的格式,如 CSV。
按照以下步骤实现您的爬取目标!
步骤 #1:检查目标站点
您需要安装一些库来在 Rust 中进行网页爬取,但哪些库最适合您的特定场景?要回答这个问题,您需要弄清楚目标站点是否有静态内容页面或动态内容页面。因此,在浏览器中访问该站点。
导航到目标页面,右键单击空白部分,选择“检查”选项以打开 DevTools。进入“网络”选项卡并重新加载页面。关注您在“Fetch/XHR”部分看到的内容:
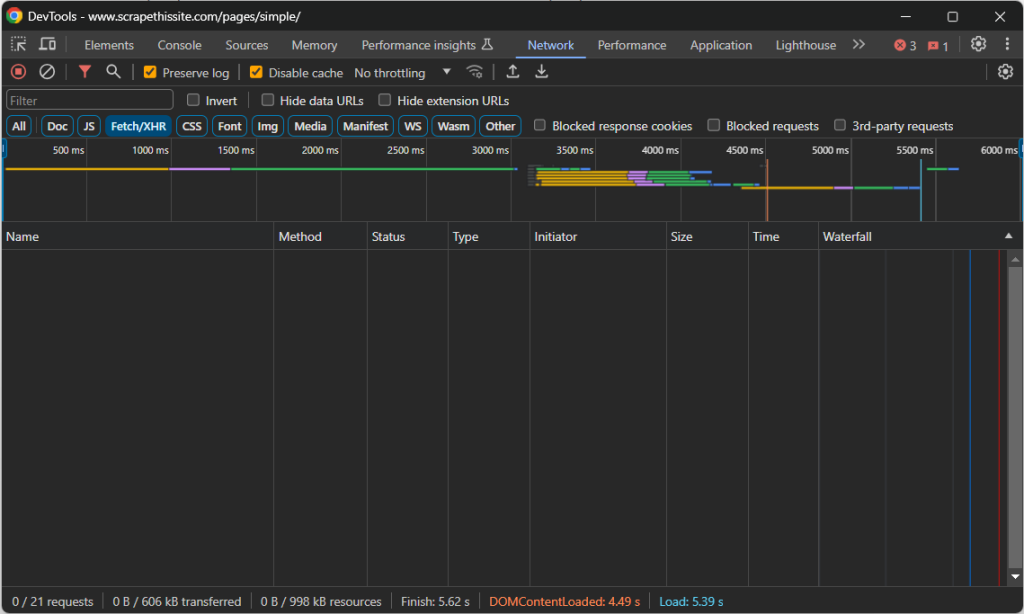
在页面加载和渲染时,该部分将保持为空。这意味着网页不会发出任何 AJAX 请求。换句话说,它不会在客户端通过 JavaScript 动态检索数据。因此,它是一个静态内容页面,其 HTML 文档已经包含了所有感兴趣的数据。
为了进一步确认,右键单击并选择“查看页面源代码”选项:
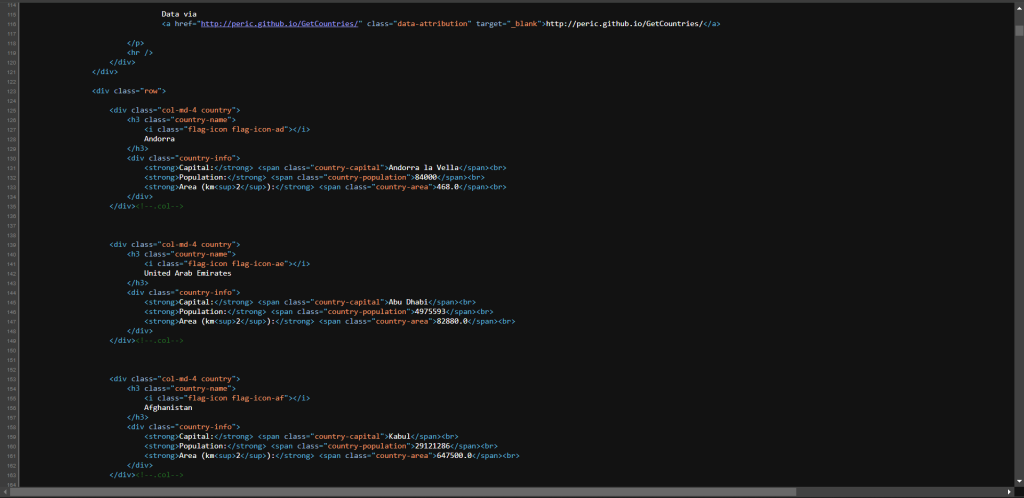
探索代码,您会注意到页面中的所有数据都嵌入在服务器返回的 HTML 中。
在包含多个页面的站点上,在所有感兴趣的页面上重复此过程。
由于目标页面不使用 JavaScript,因此您不需要浏览器自动化库如 rust-headless-chrome。您仍然可以使用它,但运行 Chrome 需要时间和资源,因此它只会引入性能开销而没有实际好处。
相反,您应该使用 HTTP 客户端库来检索与页面关联的 HTML 文档,并使用 HTML 解析库来从中提取数据。因此,reqwest 和 scraper 是您所需的两个 Rust 网页爬取库!
步骤 #2:安装爬取库
是时候安装 reqwest 和 scraper 了。
在项目根文件夹中打开终端或使用 IDE 的终端。运行以下命令将 reqwest 和 scraper 添加到项目依赖项中:
cargo add scraper reqwest --features "reqwest/blocking"注意:reqwest/blocking 特性允许 reqwest 执行同步 HTTP 调用,阻塞当前线程。在文档中了解更多。
cargo add 命令将相应地更新 Cargo.toml 文件,确保其包含:
[dependencies]
reqwest = { version = "0.11.23", features = ["blocking"] }
scraper = "0.18.1"此外,它还将安装这两个库及其所有依赖项。
太好了!您现在拥有了用 Rust 进行网页爬取所需的一切!
步骤 #3:连接到目标页面
使用 reqwest::blocking 的 get() 方法发出对给定 URL 的 GET 请求并下载关联的 HTML 文档:
let response = reqwest::blocking::get("https://www.scrapethissite.com/pages/simple/")?;请记住,这条指令是同步的,因此脚本的执行将被中断,直到服务器响应。
一旦得到响应,您可以使用以下代码访问目标页面的 HTML 代码:
let html = response.text()?;将这两行写入 main.rs 的 main() 函数中:
fn main() -> Result<(), Box<dyn std::error::Error>> {
// connect to the target page
let response = reqwest::blocking::get("https://www.scrapethissite.com/pages/simple/")?;
// extract the raw html and print it
let html = response.text()?;
println!("{html}");
Ok(())
}如果您想知道 Result<(), Box<dyn std::error::Error>> 是什么,因为我们要使用剩余类型。还请注意最后的 println() 函数,它记录了检索到的 HTML。
执行脚本,它将在终端中打印:
<!doctype html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Countries of the World: A Simple Example | Scrape This Site | A public sandbox for learning web scraping</title>
<!-- omitted for brevity... -->干得好!这正是目标页面的 HTML!
步骤 #4:解析 HTML 文档
您现在已将目标页面的源 HTML 存储在一个字符串变量中。将其传递给 scraper 的 parse_document() 函数进行解析:
let document = scraper::Html::parse_document(&html);返回的 document 对象公开了您需要使用的 DOM 探索 API,以便使用 Rust 进行网页爬取。
目前为止,您的 main.rs 文件应如下所示:
fn main() -> Result<(), Box<dyn std::error::Error>> {
// connect to the target page
let response = reqwest::blocking::get("https://www.scrapethissite.com/pages/simple/")?;
// extract the raw html and print it
let html = response.text()?;
// parse the HTML document
let document = scraper::Html::parse_document(&html);
Ok(())
}您已准备好编写数据解析逻辑。但首先,您必须研究目标页面的结构!
步骤 #5:检查页面
网页爬取涉及在页面上选择 HTML 节点并从中提取数据。CSS 选择器是选择 HTML 节点的最流行方法之一。如果您是网页开发人员,您可能已经熟悉它们。如果没有,请探索文档。
定义有效的 CSS 选择器的唯一方法是检查目标页面的 HTML。因此,在浏览器中打开Scrape This Site Country sandbox,右键单击一个国家元素,并选择“检查”:
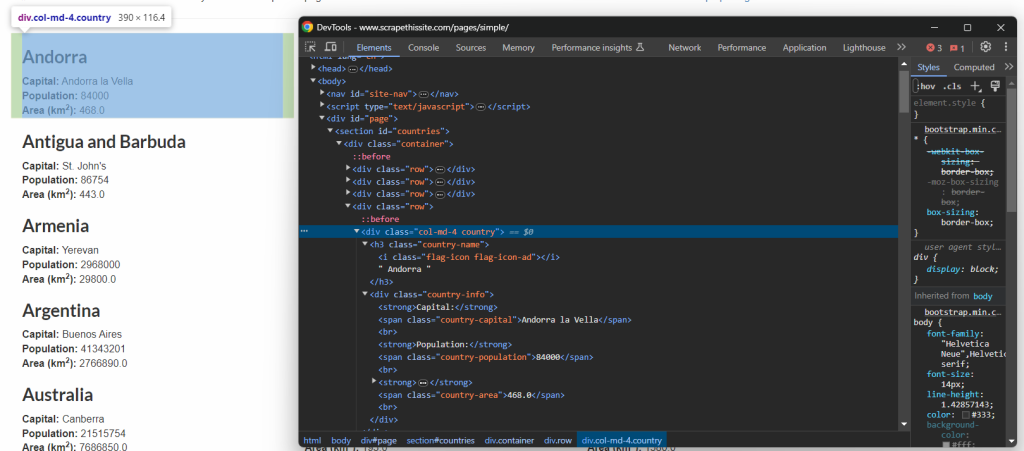
您可以看到,每个国家信息框是一个 .country HTML 节点,包含:
- 国家名称在 .country-name 元素中。
- 首都名称在 .country-capital 元素中。
- 人口信息在 .country-population 元素中。
- 国家占地面积(以平方公里为单位)在 .country-area 元素中。
上述段落中有所有选择所需的 CSS 选择器。在将选择器应用于页面上的所有元素之前,请先在国家信息框上测试选择器!
步骤 #6:从单个元素中检索数据
scraper::Selector 的 parse() 函数接受一个表示 CSS 选择器的字符串,并返回一个选择器对象。如下所示使用它:
let html_country_info_box_selector = scraper::Selector::parse(".country")?;然后,您可以将选择器传递给 document 暴露的 select() 方法:
let html_country_info_box_element = document
.select(&html_country_info_box_selector)
.next()
.ok_or("Country info box element not found!")?;这将应用 CSS 选择器到页面,并返回选定的 HTML 元素。由于 select() 始终返回一个迭代器,因此需要 .next() 调用以获取第一个国家信息框节点。
请注意 select() 返回的对象也公开了 select() 函数。在本例中,它只会在当前节点的子节点中搜索节点。因此,您可以按如下所示实现整个 Rust 网页爬取逻辑:
let country_name_selector = scraper::Selector::parse(".country-name")?;
let name = html_country_info_box_element
.select(&country_name_selector)
.next()
.map(|element| element.text().collect::<String>().trim().to_owned())
.ok_or("Country name not found")?;
let country_capital_selector = scraper::Selector::parse(".country-capital")?;
let capital = html_country_info_box_element
.select(&country_capital_selector)
.next()
.map(|element| element.text().collect::<String>().trim().to_owned())
.ok_or("Country capital not found")?;
let country_population_selector = scraper::Selector::parse(".country-population")?;
let population = html_country_info_box_element
.select(&country_population_selector)
.next()
.map(|element| element.text().collect::<String>().trim().to_owned())
.ok_or("Country population not found")?;
let country_area_selector = scraper::Selector::parse(".country-area")?;
let area = html_country_info_box_element
.select(&country_area_selector)
.next()
.map(|element| element.text().collect::<String>().trim().to_owned())
.ok_or("Country area not found")?;text() 方法使您可以访问选定 HTML 节点中的文本。对于其他数据提取方法,查看文档。由于提取的文本可能包含不需要的空格,请使用 trim() 删除它们。
打印爬取到的数据以验证爬取逻辑是否按预期工作:
println!("Country name: {name}");
println!("Country capital: {capital}");
println!("Country name: {population}");
println!("Country area: {area}");
That would produce:
Country name: Andorra
Country capital: Andorra la Vella
Country population: 84000
Country area: 468.0是的!您刚刚使用 Rust 进行网页爬取!
步骤 #7:爬取页面上的所有元素
这次,您将扩展上述代码,以遍历页面上的所有国家信息框节点。
首先,您需要定义一个自定义数据结构来存储收集到的数据。要指定一个新的struct以适应这一需求,在您的 main.rs 文件顶部添加以下行:
struct Country {
name: String,
capital: String,
population: String,
area: String,
}其次,在 main() 中实例化一个 Vec 的 Country 对象:
let mut countries: Vec = Vec::new();该向量将包含您所有爬取的数据。
接下来,删除 .next() 调用以获取所有国家信息框,迭代它们,并填充 countries:
// where to store the scraped data
let mut countries: Vec<Country> = Vec::new();
// select the country info box HTML elements
let html_country_info_box_selector = scraper::Selector::parse(".country")?;
let html_country_info_box_elements = document.select(&html_country_info_box_selector);
// iterate over the country HTML elements
// and scrape them all
for html_country_info_box_element in html_country_info_box_elements {
// scraping logic for a single country info box HTML element...
// create a new Country object and add it to the vector
let country = Country {
name,
capital,
population,
area,
};
countries.push(country);
}然后,您可以使用以下代码打印所有爬取的国家:
// 记录结果
for country in countries {
println!("Country name: {}", country.name);
println!("Country capital: {}", country.capital);
println!("Country population: {}", country.population);
println!("Country area: {}", country.area);
println!();
}
新的 main.rs Rust 网页爬取文件将包含:
// custom struct to store the scraping data
struct Country {
name: String,
capital: String,
population: String,
area: String,
}
fn main() -> Result<(), Box<dyn std::error::Error>> {
// connect to the target page
let response = reqwest::blocking::get("https://www.scrapethissite.com/pages/simple/")?;
// extract the raw html and print it
let html = response.text()?;
// parse the HTML document
let document = scraper::Html::parse_document(&html);
// where to store the scraped data
let mut countries: Vec<Country> = Vec::new();
// select the country info box HTML elements
let html_country_info_box_selector = scraper::Selector::parse(".country")?;
let html_country_info_box_elements = document.select(&html_country_info_box_selector);
// iterate over the country HTML elements
// and scrape them all
for html_country_info_box_element in html_country_info_box_elements {
// scraping logic for a single country info box HTML element
let country_name_selector = scraper::Selector::parse(".country-name")?;
let name = html_country_info_box_element
.select(&country_name_selector)
.next()
.map(|element| element.text().collect::<String>().trim().to_owned())
.ok_or("Country name not found")?;
let country_capital_selector = scraper::Selector::parse(".country-capital")?;
let capital = html_country_info_box_element
.select(&country_capital_selector)
.next()
.map(|element| element.text().collect::<String>().trim().to_owned())
.ok_or("Country capital not found")?;
let country_population_selector = scraper::Selector::parse(".country-population")?;
let population = html_country_info_box_element
.select(&country_population_selector)
.next()
.map(|element| element.text().collect::<String>().trim().to_owned())
.ok_or("Country population not found")?;
let country_area_selector = scraper::Selector::parse(".country-area")?;
let area = html_country_info_box_element
.select(&country_area_selector)
.next()
.map(|element| element.text().collect::<String>().trim().to_owned())
.ok_or("Country area not found")?;
// create a new Country object and add it to the vector
let country = Country {
name,
capital,
population,
area,
};
countries.push(country);
}
// log the results
for country in countries {
println!("Country name: {}", country.name);
println!("Country capital: {}", country.capital);
println!("Country name: {}", country.population);
println!("Country area: {}", country.area);
println!();
}
Ok(())
}
Launch it, and it will generate this output:
Country name: Andorra
Country capital: Andorra la Vella
Country population: 84000
Country area: 468.0
# omitted for brevity...
Country name: Zimbabwe
Country capital: Harare
Country name: 11651858
Country area: 390580.0任务完成!您刚刚从目标页面爬取了所有国家!
步骤 #8:将提取的数据导出为 CSV
收集到的数据现在存储在 Rust 向量中,如果您想与他人分享,这不是最佳格式。这就是为什么您需要将其导出为易于查看的格式,如 CSV。
要将数据导出为 CSV 文件,您应该使用 csv 库。通过以下命令安装它:
cargo add csv然后,您可以使用它来生成 CSV 导出文件:
// initialize the output CSV file
let mut writer = csv::Writer::from_path("countries.csv")?;
// write the CSV header
writer.write_record(&["name", "capital", "population", "area"])?;
// populate the file with each country
for country in countries {
writer.write_record(&[
country.name,
country.capital,
country.population,
country.area,
])?;
}该代码段创建一个 CSV 文件,用标题行初始化它,最后通过迭代 countries 向量来填充它。
步骤 #9:整合所有内容
这是您的网页爬取 Rust 脚本的完整代码:
// custom struct to store the scraping data
pub struct Country {
name: String,
capital: String,
population: String,
area: String,
}
fn main() -> Result<(), Box<dyn std::error::Error>> {
// connect to the target page
let response = reqwest::blocking::get("https://www.scrapethissite.com/pages/simple/")?;
// extract the raw html and print it
let html = response.text()?;
// parse the HTML document
let document = scraper::Html::parse_document(&html);
// where to store the scraped data
let mut countries: Vec<Country> = Vec::new();
// select the country info box HTML elements
let html_country_info_box_selector = scraper::Selector::parse(".country")?;
let html_country_info_box_elements = document.select(&html_country_info_box_selector);
// iterate over the country HTML elements
// and scrape them all
for html_country_info_box_element in html_country_info_box_elements {
// scraping logic for a single country info box HTML element
let country_name_selector = scraper::Selector::parse(".country-name")?;
let name = html_country_info_box_element
.select(&country_name_selector)
.next()
.map(|element| element.text().collect::<String>().trim().to_owned())
.ok_or("Country name not found")?;
let country_capital_selector = scraper::Selector::parse(".country-capital")?;
let capital = html_country_info_box_element
.select(&country_capital_selector)
.next()
.map(|element| element.text().collect::<String>().trim().to_owned())
.ok_or("Country capital not found")?;
let country_population_selector = scraper::Selector::parse(".country-population")?;
let population = html_country_info_box_element
.select(&country_population_selector)
.next()
.map(|element| element.text().collect::<String>().trim().to_owned())
.ok_or("Country population not found")?;
let country_area_selector = scraper::Selector::parse(".country-area")?;
let area = html_country_info_box_element
.select(&country_area_selector)
.next()
.map(|element| element.text().collect::<String>().trim().to_owned())
.ok_or("Country area not found")?;
// create a new Country object and add it to the vector
let country = Country {
name,
capital,
population,
area,
};
countries.push(country);
}
// initialize the output CSV file
let mut writer = csv::Writer::from_path("countries.csv")?;
// write the CSV header
writer.write_record(&["name", "capital", "population", "area"])?;
// populate the file with each country
for country in countries {
writer.write_record(&[
country.name,
country.capital,
country.population,
country.area,
])?;
}
Ok(())
}您相信吗?您可以在不到 100 行代码中构建一个 Rust 数据爬取器。
使用以下命令编译应用程序:
cargo build然后,使用以下命令启动它:
cargo run当脚本终止时,项目根文件夹中将出现一个 countries.csv 文件。打开它,您应该会看到以下数据:
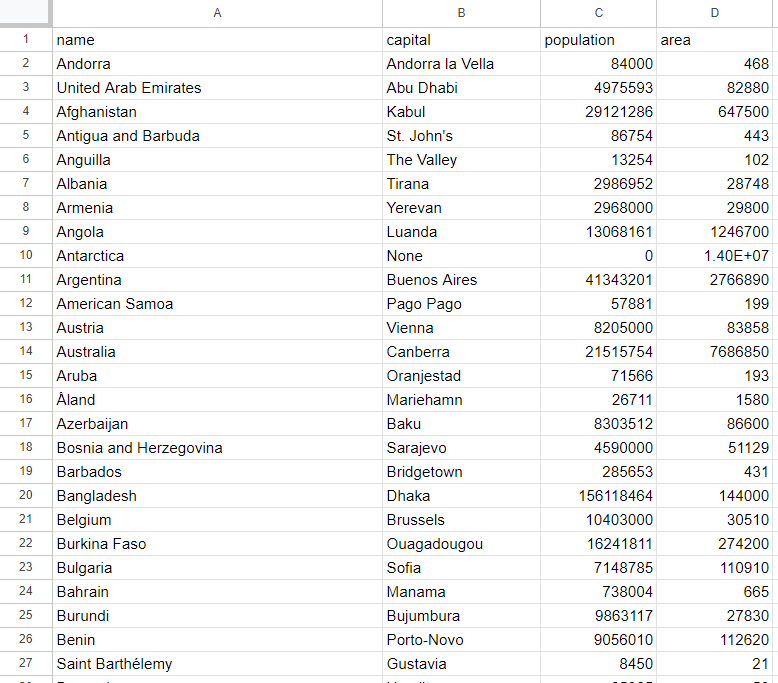
瞧!您现在知道 Rust 网页爬取的基础知识了!
保持您的网页爬取操作符合道德并尊重他人
自动从互联网检索数据是一种获取有用信息的有效方式。然而,您不希望在执行操作时对目标站点造成伤害。因此,您必须以正确的预防措施进行操作。
为了进行负责任的网页爬取,请考虑以下提示:
- 遵守 robots.txt 文件:每个站点都有一个 robots.txt 文件,指定了自动爬虫如何访问其页面的规则。为了保持道德的爬取实践,您必须遵守这些指南。了解更多信息,请阅读我们的robots.txt 网页爬取指南。
- 限制请求频率:在短时间内发出太多请求会导致服务器过载,影响所有用户的站点性能。这也可能触发速率限制措施并导致您被封禁。因此,请在请求之间添加随机延迟,以避免淹没目标服务器。
- 检查并遵守站点的服务条款:在爬取网站之前,请查看并遵守其服务条款。这些条款可能包含关于版权、知识产权以及如何何时使用其数据的指南。
- 仅爬取公开可用的信息:专注于提取站点上公开访问的数据,而不是通过登录凭证或其他形式授权保护的数据。未经适当许可,爬取私人或敏感数据是不道德的,可能会导致法律后果。
- 依赖可靠和最新的爬取工具:选择信誉良好的提供商,选择维护良好且定期更新的库和工具。只有这样,您才能确保它们符合最新的道德爬取原则和最佳实践。如果您有任何疑问,请阅读我们的文章,了解如何选择最佳的网页爬取服务。
结论
在本教程中,您看到了为什么 Rust 是网页爬取的好选择以及应使用哪些库来执行爬取。在这里,您学习了如何使用 reqwest 和 scraper 来构建一个可以从实际站点提取数据的 Rust 网页爬取器。只需几行代码即可实现!
然而,请记住,网页爬取并不总是那么容易。原因是反爬取和反机器人解决方案变得越来越普遍。这些技术可以检测到您的脚本的自动化性质并阻止它,对您的爬取操作构成严重挑战。
避免这些麻烦,使用 Bright Data 提供的下一代和高级网页爬取工具。如果您想了解更多关于如何避免被封锁的信息,请使用其中一个多种代理服务或开始使用高级 Web Unlocker。
不想处理网页爬取?探索我们的数据集。
不确定选择哪种产品?立即注册并找到适合您业务的解决方案。
支持支付宝等多种支付方式




