

市面上有各种各样很棒的解析工具可供选择。在 Python 中,你会觉得自己的选择几乎是无限的。然而,在 Go 中,我们可供选择的工具并不算太多。
Go 是一门在性能和内存管理方面都非常出色的语言,但我们的解析库相对有限。我们可以使用 Go 标准库中的 Node Parser 和 Tokenizer。如果你对网络爬虫的运作方式还完全不熟悉,可以先看看这篇指南。接下来我们一起看看这些工具应该在什么时候使用,或者什么时候选择第三方库来实现更完整的爬虫解决方案。
先决条件
具备对 Go 和网络爬虫的基本理解会有所帮助,但并不是必需的。如果你熟悉 Go,但想了解网络爬虫的过程,可以看看这篇指南。
首先,你需要确保你的电脑上安装了 Go。你可以在这里找到最新的发行版本。下载适用于你系统的最新版本,让我们开始吧!
创建一个新的项目文件夹并使用cd进入。
mkdir goparser
cd goparser初始化一个新的 Go 项目。
go mod init goparser测试你的环境配置
将下面的代码粘贴到新文件 main.go 中。
package main
import "fmt"
func main() {
fmt.Println("Hello, World!")
}你可以使用下面的命令运行这个文件:
go run main.go如果一切正常,你应该会看到如下输出:
Hello, World!安装我们唯一需要的依赖。
go get golang.org/x/net/html页面结构分析
Quotes to Scrape是特地为爬虫教程而建的一个网站。在本教程中,我们将从页面中提取每条名言以及它的作者。
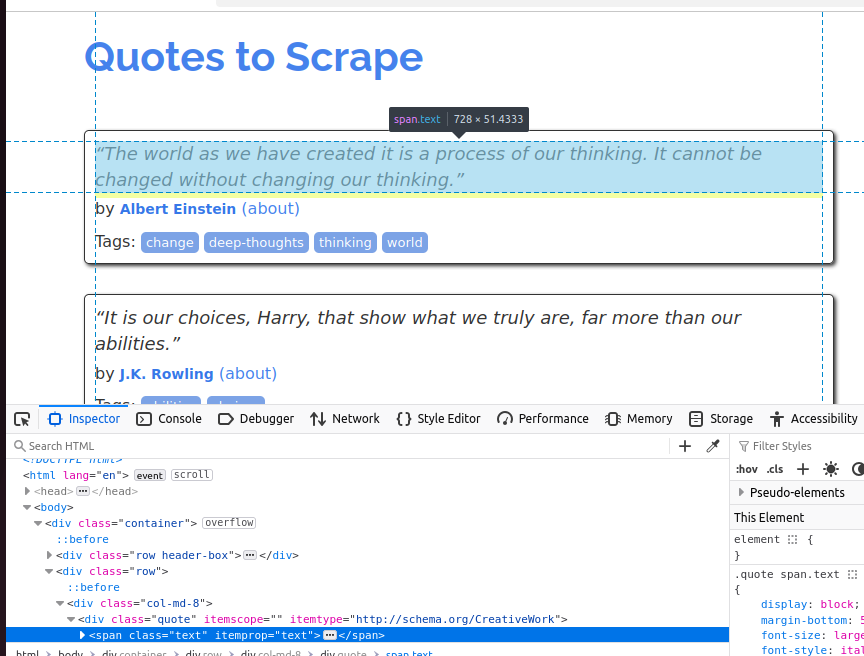
为了更好地理解每条名言对象,请看下面的截图。每条引文是一个span元素,且它的class是text。
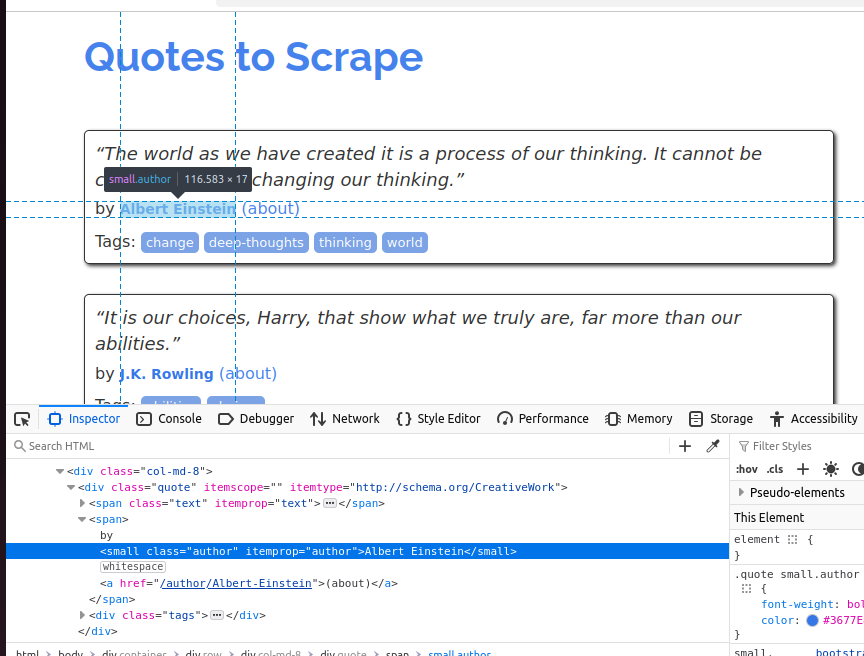
下一个截图中,我们可以看到作者部分。它是一个small元素,且它的class是author。
以下示例使用 Node Parser 和 Tokenizer 产生的输出都是相同的:
Quote: “The world as we have created it is a process of our thinking. It cannot be changed without changing our thinking.”
Author: Albert Einstein
Quote: “It is our choices, Harry, that show what we truly are, far more than our abilities.”
Author: J.K. Rowling
Quote: “There are only two ways to live your life. One is as though nothing is a miracle. The other is as though everything is a miracle.”
Author: Albert Einstein
Quote: “The person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.”
Author: Jane Austen
Quote: “Imperfection is beauty, madness is genius and it's better to be absolutely ridiculous than absolutely boring.”
Author: Marilyn Monroe
Quote: “Try not to become a man of success. Rather become a man of value.”
Author: Albert Einstein
Quote: “It is better to be hated for what you are than to be loved for what you are not.”
Author: André Gide
Quote: “I have not failed. I've just found 10,000 ways that won't work.”
Author: Thomas A. Edison
Quote: “A woman is like a tea bag; you never know how strong it is until it's in hot water.”
Author: Eleanor Roosevelt
Quote: “A day without sunshine is like, you know, night.”
Author: Steve Martin使用 Node Parser 提取数据
Go 的 Node Parser 允许我们以递归的方式遍历并操作 DOM(文档对象模型)。当我们使用 Node Parser 时,它会将整个 HTML 页面转换成类似树状结构的Node对象用于解析。
在下面的代码中,我们创建了一个递归函数:processNode()。它接收一个指向 HTML 节点的指针。如果节点是span并且它的class是text,我们就将这条引文打印到控制台;如果节点是small且它的class是author,就将作者打印到控制台。这些都是我们在检查页面时发现的对应属性。
import (
"fmt"
"net/http"
"golang.org/x/net/html"
)
func main() {
resp, _ := http.Get("http://quotes.toscrape.com")
defer resp.Body.Close()
doc, _ := html.Parse(resp.Body)
var processNode func(*html.Node)
processNode = func(n *html.Node) {
if n.Type == html.ElementNode && n.Data == "span" {
for _, a := range n.Attr {
if a.Key == "class" && a.Val == "text" {
fmt.Println("Quote:", n.FirstChild.Data)
}
}
}
if n.Type == html.ElementNode && n.Data == "small" {
for _, a := range n.Attr {
if a.Key == "class" && a.Val == "author" {
fmt.Println("Author:", n.FirstChild.Data)
}
}
}
for c := n.FirstChild; c != nil; c = c.NextSibling {
processNode(c)
}
}
processNode(doc)
}当你需要处理整个文档时,Node Parser 的 API 非常好用。为了节省内存,我们可以使用指针来指向原始文档,并在遍历时进行数据处理。
使用 Tokenizer 提取数据
Tokenizer 则是以另一种方式处理页面。调用html.NewTokenizer(resp.Body)是基于响应体创建一个 Tokenizer 对象。然后我们可以选择想从页面中提取哪些 Token(HTML 标签、文本内容或属性)。
在处理每个 Token 时,我们会用到两个布尔值:inQuote和inAuthor。如果 Token 在引文或作者的区域内,我们就去掉它前后的空格,并将其打印到控制台。虽然输出结果相同,但它的实际运行方式和 Node Parser 不一样。Node Parser 是用树的方式一次处理一个节点,而 Tokenizer 是一次处理一块数据。
在下面的代码中,我们指定了两个起始 Token:span和small。如果当前块是span元素,并且class为text,就把它打印出来;如果是small元素且class为author,我们也打印出来。页面上的其他 Token(HTML 标签)会被忽略。
package main
import (
"fmt"
"net/http"
"strings"
"golang.org/x/net/html"
)
func main() {
resp, _ := http.Get("http://quotes.toscrape.com")
defer resp.Body.Close()
tokenizer := html.NewTokenizer(resp.Body)
inQuote := false
inAuthor := false
for {
tt := tokenizer.Next()
switch tt {
case html.ErrorToken:
return
case html.StartTagToken:
t := tokenizer.Token()
if t.Data == "span" {
for _, a := range t.Attr {
if a.Key == "class" && a.Val == "text" {
inQuote = true
}
}
}
if t.Data == "small" {
for _, a := range t.Attr {
if a.Key == "class" && a.Val == "author" {
inAuthor = true
}
}
}
case html.TextToken:
if inQuote {
fmt.Println("Quote:", strings.TrimSpace(tokenizer.Token().Data))
inQuote = false
}
if inAuthor {
fmt.Println("Author:", strings.TrimSpace(tokenizer.Token().Data))
inAuthor = false
}
}
}
}Tokenizer 相比 Node Parser 更底层一些,但也更加高效。我们只需要处理相关的 Token(HTML 标签),而不必遍历整个文档。对于处理大型数据流来说,Tokenizer 非常适合。它只需处理与你相关的那部分数据,而无需管整页内容。
第三方替代方案
和 Python、JavaScript 中的工具相比,Node Parser 和 Tokenizer 都显得比较底层。下面是一些可以使爬虫工作更轻松的第三方工具。
Goquery
Goquery 是一个参考 Jquery 思路的 Go 版本,如果你想要一个更直观的解析工具,这是一个不错的选择。Goquery 支持 DOM 的遍历和 CSS 选择器,使用方式更接近其他语言中常见的解决方案。
htmlquery
htmlquery 与 Goquery 类似,也可进行 DOM 遍历及选择,但它使用 XPath 选择器而不是 CSS 选择器。你可以根据自己更偏好的选择器来决定用 Goquery 还是 htmlquery。
Colly
Colly 是一个功能更完整的 Go 爬虫框架。它支持 CSS 选择器、并发以及更多功能,你可以把它看作是 Go 领域的Scrapy。如果你对 Colly 感兴趣,我们有一篇非常不错的教程可以参考,链接在这里。
Bright Data Web Scraper
我们的Web Scraper能够帮助你完全绕过爬虫处理这一过程。使用 Web Scraper,我们会为你爬取页面,并将数据以 JSON 的形式返回。如果你只想通过一个简单的 API 请求就拿到数据,而不想去解析 DOM、写 Tokenizer 或者写选择器,那么它会是个很靠谱的选择。我们的 Web Scraper 并不是一个 Go 库,而是一种 API 服务。只要你懂得如何处理 REST API,你就能用它来简单地自动化爬虫流程。
总结
现在你已经知道了如何用 Go 来解析 HTML。如果你想让自己的技能更完善,可以看看我们关于在 Go 中使用代理的指南。如果你需要遍历整页,可以使用 Node Parser;如果你只想从页面中提取有用的数据,那就试试 Tokenizer。如果这两者都无法满足你的需求,还有各种第三方工具,比如 Bright Data 的 Web Scrapers。现在就注册并开始你的免费试用吧!



