

在本教程中,你将了解为什么 Go 是高效网络爬虫的最佳语言之一,并学习如何从头开始构建一个 Go 爬虫。
本文将涵盖:
可以用 Go 进行网络爬虫吗?
Go,也称为 Golang,是 Google 创建的一种静态类型编程语言。它被设计为高效、并发且易于编写和维护。这些特性使得 Go 近年来在多个应用中变得流行,包括网络爬虫。
具体来说,Go 提供了在网络爬虫任务中非常有用的强大功能。其中包括其内置的并发模型,支持对多个网络请求的并发处理。这使得 Go 成为高效从多个网站抓取大量数据的理想语言。此外,Go 的标准库包括可以用来获取网页、解析 HTML 和从网站提取数据的 HTTP 客户端和 HTML 解析包。
如果这些功能和默认包还不够或太难使用,还有几个 Go 网络爬虫库。让我们看看最流行的几个!
最佳的 Go 网络爬虫库
以下是一些最佳的 Go 网络爬虫库列表:
- Colly:一个强大的 Go 网络爬虫和爬网框架。它提供了一个功能性的 API,用于发出 HTTP 请求、管理头文件和解析 DOM。Colly 还支持并行爬取、速率限制和自动处理 Cookie。
- Goquery:一个基于 jQuery 语法的流行的 Go HTML 解析库。它允许你通过 CSS 选择器选择 HTML 元素、操作 DOM 并从中提取数据。
- Selenium:一个最流行的网络测试框架的 Go 客户端。它使你能够自动化浏览器以完成各种任务,包括网络爬虫。特别是,Selenium 可以控制浏览器并指示其像人类用户一样与页面互动。它还能够在使用 JavaScript 获取或呈现数据的网页上执行爬虫。
先决条件
在开始之前,你需要在你的机器上安装 Go。请注意,安装过程会根据操作系统的不同而有所变化。
在 macOS 上设置 Go
- 下载 Go。
- 打开下载的文件并按照安装提示进行操作。该包将 Go 安装到/usr/local/go,并将/usr/local/go/bin添加到你的PATH环境变量中。
- 重新启动任何打开的终端会话。
在 Windows 上设置 Go
- 下载 Go。
- 启动下载的 MSI 文件并按照安装向导进行操作。安装程序将 Go 安装到C:/Program Files 或C:/Program Files (x86) 并将bin文件夹添加到PATH环境变量中。
- 关闭并重新打开任何命令提示符。
在 Linux 上设置 Go
- 下载 Go。
- 确保你的系统中没有/usr/local/go文件夹。如果存在,请使用以下命令删除它:
rm -rf /usr/local/go- 将下载的归档文件解压到/usr/local中:
tar -C /usr/local -xzf goX.Y.Z.linux-amd64.tar.gz请确保将 X.Y.Z 替换为你下载的 Go 包的版本。
- 将/usr/local/go/bin添加到PATH环境变量中:
export PATH=$PATH:/usr/local/go/bin- 重新加载你的计算机。
无论你的操作系统是什么,请使用以下命令验证 Go 是否已成功安装:
go version这将返回类似于以下内容的信息:
go version go1.20.3好了,你现在可以开始学习 Go 网络爬虫了!
用 Go 构建网络爬虫
在这里,你将学习如何构建一个 Go 网络爬虫。这个自动化脚本将能够自动从Bright Data 主页中检索数据。Go 网络爬虫过程的目标是选择页面中的一些 HTML 元素,从中提取数据,并将收集到的数据转换为易于探索的格式。
在撰写本文时,目标站点看起来如下:
请按照分步教程学习如何用 Go 进行网络爬虫!
步骤 1:设置 Go 项目
是时候初始化你的 Go 网络爬虫项目了。打开终端并创建一个 go-web-scraper 文件夹:
mkdir go-web-scraper这个目录将包含 Go 项目。
接下来,运行以下init命令:
go mod init web-scraper这将在项目根目录中初始化一个 web-scraper 模块。
go-web-scraper 目录现在将包含以下 go.mod 文件:
module web-scraper
go 1.20请注意,最后一行会根据你的 Go 版本而变化。
现在你可以在你的 IDE 中开始编写一些 Go 代码了!在本教程中,我们将使用 Visual Studio Code。由于它本身不支持 Go,你首先需要安装 Go 扩展。
启动 VS Code,点击左侧栏中的“扩展”图标,然后输入“Go”。
点击第一个卡片上的“安装”按钮,添加Visual Studio Code 的 Go 扩展。
点击“文件”,选择“打开文件夹…”,然后打开 go-web-scraper 目录。
右键点击“资源管理器”部分,选择“新建文件…”,并按如下方式创建 scraper.go 文件:
// scraper.go
package main
import (
"fmt"
)
func main() {
fmt.Println("Hello, World!")
}请记住,main()函数代表任何 Go 应用的入口点。你需要在这里放置你的 Golang 网络爬虫逻辑。
Visual Studio Code 会提示你安装一些包以完成与 Go 的集成。安装它们。然后,在 VS 终端中运行以下命令来运行 Go 脚本:
go run scraper.go
这将输出:
Hello, World!步骤 2:开始使用 Colly
为了更容易地用 Go 构建一个网络爬虫,你应该使用前面介绍的一个包。但首先,你需要确定哪个 Golang 网络爬虫库最适合你的目标。为此,请访问目标网站,右键点击背景,然后选择“检查”选项。这将打开浏览器的开发者工具。在“网络”选项卡中,查看“Fetch/XHR”部分。

如上所示,目标网页只进行了一些AJAX 请求。如果你探索每个 XHR 请求,你会发现它们没有返回任何有意义的数据。换句话说,服务器返回的 HTML 文档已经包含了所有数据。这通常发生在静态内容站点上。
这表明目标站点不依赖 JavaScript 来动态检索数据或进行呈现。因此,你不需要一个具有无头浏览器功能的库来从目标网页获取数据。你仍然可以使用 Selenium,但这只会引入性能开销。因此,你应该优先选择像 Colly 这样简单的 HTML 解析器。
用以下命令将 Colly 添加到你的项目依赖项中:
go get github.com/gocolly/colly此命令会创建一个 go.sum 文件并相应更新 go.mod 文件。
在开始使用它之前,你需要了解一些关键的 Colly 概念。
Colly 的主要实体是Collector。这个对象允许你通过以下回调来执行 HTTP 请求和进行网络爬虫:
- OnRequest():在使用 Visit() 发出任何 HTTP 请求之前调用。
- OnError():在 HTTP 请求中发生错误时调用。
- OnResponse():在从服务器收到响应后调用。
- OnHTML():在 OnResponse() 后调用,如果服务器返回了有效的 HTML 文档。
- OnScraped():在所有 OnHTML() 调用结束后调用。
这些函数中的每一个都将一个回调作为参数。当与函数关联的事件被触发时,Colly 执行输入回调。因此,要在 Colly 中构建一个数据爬虫,你需要遵循基于回调的功能性方法。
你可以使用NewCollector()函数初始化一个Collector对象:
c := colly.NewCollector()通过更新 scraper.go 导入 Colly 并创建一个 Collector:
// scraper.go
package main
import (
// import Colly
"github.com/gocolly/colly"
)
func main() {
c := colly.NewCollector()
// scraping logic...
}步骤 3:连接到目标网站
使用 Colly 连接到目标页面:
c.Visit("https://brightdata.com/")在幕后,Visit()函数执行一个HTTP GET 请求,并从服务器检索目标 HTML 文档。具体来说,它触发 onRequest 事件并启动 Colly 功能生命周期。请注意,Visit() 必须在注册其他 Colly 回调之后调用。
请注意,Visit() 发出的 HTTP 请求可能会失败。当这种情况发生时,Colly 会触发 OnError 事件。失败的原因可能是任何事情,从暂时不可用的服务器到无效的 URL。同时,当目标网站采用反爬虫措施时,网络爬虫通常会失败。例如,这些技术通常会过滤掉没有有效User-Agent HTTP 头的请求。请查看我们的指南以了解更多关于网络爬虫的 User-Agent的信息。
默认情况下,Colly 设置了一个占位符User-Agent,它与流行浏览器使用的代理不匹配。这使得 Colly 的请求很容易被反爬虫技术识别。为了避免因这一原因被阻止,请在 Colly 中指定一个有效的User-Agent头,如下所示:
c.UserAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36"现在,任何 Visit() 调用都会使用该 HTTP 头执行请求。
你的 scraper.go 文件现在应如下所示:
// scraper.go
package main
import (
// import Colly
"github.com/gocolly/colly"
)
func main() {
// initialize the Collector
c := colly.NewCollector()
// set a valid User-Agent header
c.UserAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36"
// connect to the target site
c.Visit("https://brightdata.com/")
// scraping logic...
}步骤 4:检查 HTML 页面
让我们分析目标网页的 DOM,以定义有效的数据检索策略。
在浏览器中打开 Bright Data 主页。如果你仔细看一下,你会注意到一系列带有 Bright Data 服务可以提供竞争优势的行业的卡片。这是一个有趣的信息,可以进行爬取。
右键点击其中一个 HTML 卡片并选择“检查”:
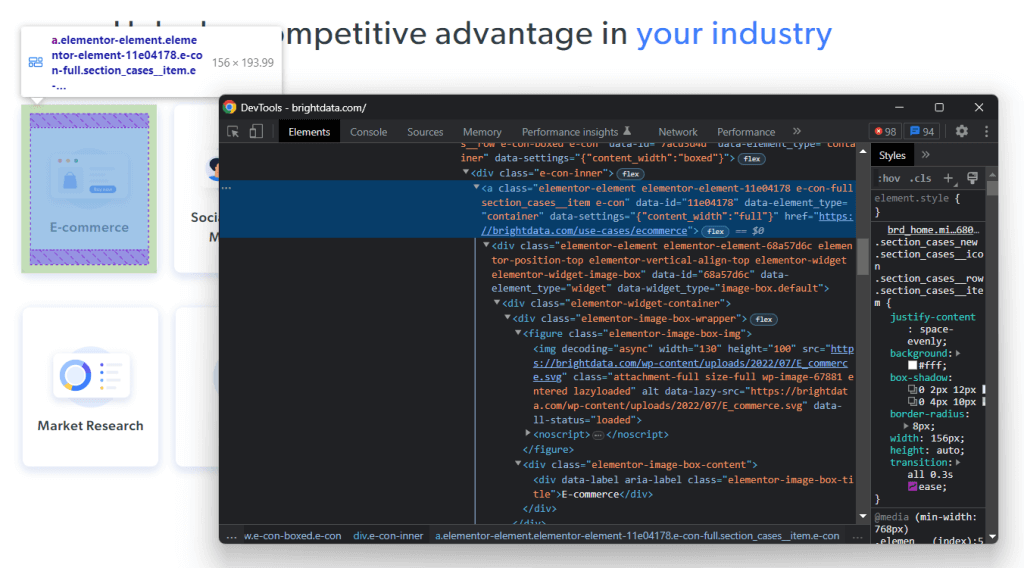
在开发者工具中,你可以看到所选节点在 DOM 中的 HTML 代码。请注意,每个行业卡片都是一个 <a> HTML 元素。具体来说,每个 <a> 都包含以下两个关键 HTML 元素:
- 一个 <figure>,存储在行业卡片中的图像。
- 一个 <div>,展示行业领域的名称。
现在,关注 HTML 元素及其父元素使用的 CSS 类。感谢它们,你将能够定义获取所需 DOM 元素的CSS 选择器策略。
具体来说,每个卡片都有section_cases__item类,并包含在.elementor-element-6b05593c <div>中。因此,你可以使用以下 CSS 选择器获取所有行业卡片:
.elementor-element-6b05593c .section_cases__item给定一个卡片,然后你可以使用以下选择器选择其相关子元素 <figure> 和 <div>:
.elementor-image-box-img img
.elementor-image-box-content .elementor-image-box-titleGo 爬虫的目标是从每个卡片中提取 URL、图像和行业名称。
步骤 5:使用 Colly 选择 HTML 元素
You can apply a CSS or XPath selector in Colly as follows:
c.OnHTML(".your-css-selector", func(e *colly.HTMLElement) {
// data extraction logic...
})Colly 将为每个匹配 CSS 选择器的 HTML 元素调用作为参数传递的函数。换句话说,它会自动迭代所有选定的元素。
请记住,Collector 可以有多个OnHTML()回调。这些回调将按照onHTML()指令在代码中的出现顺序运行。
步骤 6:使用 Colly 从网页爬取数据
了解如何使用 Cooly 从 HTML 网页中提取所需数据。
在编写爬虫逻辑之前,你需要一些数据结构来存储提取的数据。例如,你可以使用Struct来定义一个 Industry 数据类型,如下所示:
type Industry struct {
Url, Image, Name string
}在 Go 中,Struct 指定了一组可以实例化为对象的类型字段。如果你熟悉面向对象编程,可以将 Struct 视为一种类。
然后,你将需要一个类型为Industry的切片:
var industries []IndustryGo 切片不过是列表。
现在,你可以使用 OnHTML() 函数实现爬虫逻辑,如下所示:
// iterating over the list of industry card
// HTML elements
c.OnHTML(".elementor-element-6b05593c .section_cases__item", func(e *colly.HTMLElement) {
url := e.Attr("href")
image := e.ChildAttr(".elementor-image-box-img img", "data-lazy-src")
name := e.ChildText(".elementor-image-box-content .elementor-image-box-title")
// filter out unwanted data
if url!= "" || image != "" || name != "" {
// initialize a new Industry instance
industry := Industry{
Url: url,
Image: image,
Name: name,
}
// add the industry instance to the list
// of scraped industries
industries = append(industries, industry)
}
})上述 Go 爬虫代码选择 Bright Data 主页上的所有行业卡片,并对其进行迭代。然后,通过爬取与每个卡片关联的 URL、图像和行业名称来填充数据。最后,它实例化一个新的 Industry 对象并将其添加到 industries 切片中。
如你所见,在 Colly 中运行爬虫很简单。通过Attr()方法,你可以从当前元素中提取一个 HTML 属性。相反,ChildAttr()和ChildText()让你可以通过 CSS 选择器选择 HTML 子元素的属性值和文本。
请记住,你还可以从行业详情页中收集数据。你所要做的就是按照当前页面上发现的链接进行跟踪,并相应地实现新的爬虫逻辑。这就是网络爬虫和网络抓取的全部内容!
做得好!你刚刚学会了如何使用 Go 语言在网络爬虫中实现你的目标!
步骤 7:导出提取的数据
在OnHTML()指令之后,industries 将包含以 Go 对象形式存储的爬取数据。为了使从网络中提取的数据更易于访问,你需要将其转换为不同的格式。了解如何将爬取的数据导出为 CSV 和 JSON。
请注意,Go 的标准库带有高级数据导出功能。你不需要任何外部包即可将数据转换为 CSV 和 JSON。你只需确保你的 Go 脚本包含以下导入:
- 用于 CSV 导出:
import (
"encoding/csv"
"log"
"os"
)- 用于 JSON 导出:
import (
"encoding/json"
"log"
"os"
)你可以按如下所示将 industries 切片导出为 industries.csv 文件:
// open the output CSV file
file, err := os.Create("industries.csv")
// if the file creation fails
if err != nil {
log.Fatalln("Failed to create the output CSV file", err)
}
// release the resource allocated to handle
// the file before ending the execution
defer file.Close()
// create a CSV file writer
writer := csv.NewWriter(file)
// release the resources associated with the
// file writer before ending the execution
defer writer.Flush()
// add the header row to the CSV
headers := []string{
"url",
"image",
"name",
}
writer.Write(headers)
// store each Industry product in the
// output CSV file
for _, industry := range industries {
// convert the Industry instance to
// a slice of strings
record := []string{
industry.Url,
industry.Image,
industry.Name,
}
// add a new CSV record
writer.Write(record)
}上述代码段创建了一个 CSV 文件并使用标题行初始化它。然后,它迭代 Industry 对象的切片,将每个元素转换为字符串切片,并将其追加到输出文件中。Go 的CSV Writer会自动将字符串列表转换为 CSV 格式的新记录。
运行脚本:
go run scraper.go执行后,你会在 Go 项目的根文件夹中看到一个 industries.csv 文件。打开它,你应该会看到以下数据:
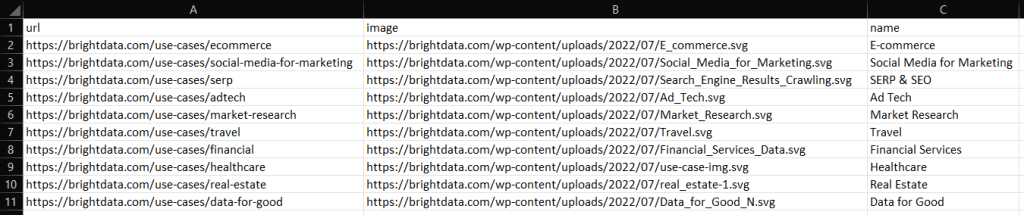
同样,你可以按如下所示将 industries 导出为 industry.json:
file, err:= os.Create("industries.json")
if err != nil {
log.Fatalln("Failed to create the output JSON file", err)
}
defer file.Close()
// convert industries to an indented JSON string
jsonString, _ := json.MarshalIndent(industries, " ", " ")
// write the JSON string to file
file.Write(jsonString)
This will produce the JSON file below:
[
{
"Url": "https://brightdata.com/use-cases/ecommerce",
"Image": "https://brightdata.com/wp-content/uploads/2022/07/E_commerce.svg",
"Name": "E-commerce"
},
// ...
{
"Url": "https://brightdata.com/use-cases/real-estate",
"Image": "https://brightdata.com/wp-content/uploads/2022/07/real_estate-1.svg",
"Name": "Real Estate"
},
{
"Url": "https://brightdata.com/use-cases/data-for-good",
"Image": "https://brightdata.com/wp-content/uploads/2022/07/Data_for_Good_N.svg",
"Name": "Data for Good"
}
]好了!现在你知道如何将收集到的数据转移到更有用的格式中!
步骤 8:将所有内容整合在一起
以下是 Golang 爬虫的完整代码:
// scraper.go
package main
import (
"encoding/csv"
"encoding/json"
"log"
"os"
// import Colly
"github.com/gocolly/colly"
)
// definr some data structures
// to store the scraped data
type Industry struct {
Url, Image, Name string
}
func main() {
// initialize the struct slices
var industries []Industry
// initialize the Collector
c := colly.NewCollector()
// set a valid User-Agent header
c.UserAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/111.0.0.0 Safari/537.36"
// iterating over the list of industry card
// HTML elements
c.OnHTML(".elementor-element-6b05593c .section_cases__item", func(e *colly.HTMLElement) {
url := e.Attr("href")
image := e.ChildAttr(".elementor-image-box-img img", "data-lazy-src")
name := e.ChildText(".elementor-image-box-content .elementor-image-box-title")
// filter out unwanted data
if url != "" && image != "" && name != "" {
// initialize a new Industry instance
industry := Industry{
Url: url,
Image: image,
Name: name,
}
// add the industry instance to the list
// of scraped industries
industries = append(industries, industry)
}
})
// connect to the target site
c.Visit("https://brightdata.com/")
// --- export to CSV ---
// open the output CSV file
csvFile, csvErr := os.Create("industries.csv")
// if the file creation fails
if csvErr != nil {
log.Fatalln("Failed to create the output CSV file", csvErr)
}
// release the resource allocated to handle
// the file before ending the execution
defer csvFile.Close()
// create a CSV file writer
writer := csv.NewWriter(csvFile)
// release the resources associated with the
// file writer before ending the execution
defer writer.Flush()
// add the header row to the CSV
headers := []string{
"url",
"image",
"name",
}
writer.Write(headers)
// store each Industry product in the
// output CSV file
for _, industry := range industries {
// convert the Industry instance to
// a slice of strings
record := []string{
industry.Url,
industry.Image,
industry.Name,
}
// add a new CSV record
writer.Write(record)
}
// --- export to JSON ---
// open the output JSON file
jsonFile, jsonErr := os.Create("industries.json")
if jsonErr != nil {
log.Fatalln("Failed to create the output JSON file", jsonErr)
}
defer jsonFile.Close()
// convert industries to an indented JSON string
jsonString, _ := json.MarshalIndent(industries, " ", " ")
// write the JSON string to file
jsonFile.Write(jsonString)
}在不到 100 行代码中,你可以在 Go 中构建一个数据爬虫!
结论
在本教程中,你看到了为什么 Go 是进行网络爬虫的好语言。你还了解了最佳的 Go 爬虫库及其提供的功能。然后,你学习了如何使用 Colly 和 Go 的标准库创建网络爬虫应用。本文构建的 Go 爬虫能够从实际目标中抓取数据。正如你所看到的,用 Go 进行网络爬虫只需几行代码。
同时,请记住,在从互联网上提取数据时有很多挑战需要考虑。这就是为什么许多网站采用反爬虫和反机器人解决方案来检测和阻止你的 Go 爬虫脚本。Bright Data 提供了不同的解决方案,请联系我们找到适合你用例的完美解决方案。
不想处理网络爬虫但对网络数据感兴趣?探索我们现成的数据集。


