

表面上看,Shopify 商店在数据提取方面似乎是最具挑战性的之一。下面展示的产品就是一个典型的 Shopify 列表。其数据结构相当嵌套。
<div class="site-box-content product-holder"><a href="/collections/ready-to-ship/products/the-eira-straight-leg" class="product-item style--one alt color--light with-secondary-image " data-js-product-item="">
<div class="box--product-image primary" style="padding-top: 120.00048000192001%"><img src="//hiutdenim.co.uk/cdn/shop/files/Hiut-EiraEcru-01_91c15dbe-7412-47b6-8f76-bdb434199203.jpg?v=1731517834&width=640" alt="The Eira - Organic Ecru" srcset="//hiutdenim.co.uk/cdn/shop/files/Hiut-EiraEcru-01_91c15dbe-7412-47b6-8f76-bdb434199203.jpg?v=1731517834&width=360 360w,//hiutdenim.co.uk/cdn/shop/files/Hiut-EiraEcru-01_91c15dbe-7412-47b6-8f76-bdb434199203.jpg?v=1731517834&width=420 420w,//hiutdenim.co.uk/cdn/shop/files/Hiut-EiraEcru-01_91c15dbe-7412-47b6-8f76-bdb434199203.jpg?v=1731517834&width=480 480w,//hiutdenim.co.uk/cdn/shop/files/Hiut-EiraEcru-01_91c15dbe-7412-47b6-8f76-bdb434199203.jpg?v=1731517834&width=640 640w,//hiutdenim.co.uk/cdn/shop/files/Hiut-EiraEcru-01_91c15dbe-7412-47b6-8f76-bdb434199203.jpg?v=1731517834&width=840 840w,//hiutdenim.co.uk/cdn/shop/files/Hiut-EiraEcru-01_91c15dbe-7412-47b6-8f76-bdb434199203.jpg?v=1731517834&width=1080 1080w,//hiutdenim.co.uk/cdn/shop/files/Hiut-EiraEcru-01_91c15dbe-7412-47b6-8f76-bdb434199203.jpg?v=1731517834&width=1280 1280w,//hiutdenim.co.uk/cdn/shop/files/Hiut-EiraEcru-01_91c15dbe-7412-47b6-8f76-bdb434199203.jpg?v=1731517834&width=1540 1540w,//hiutdenim.co.uk/cdn/shop/files/Hiut-EiraEcru-01_91c15dbe-7412-47b6-8f76-bdb434199203.jpg?v=1731517834&width=1860 1860w,//hiutdenim.co.uk/cdn/shop/files/Hiut-EiraEcru-01_91c15dbe-7412-47b6-8f76-bdb434199203.jpg?v=1731517834&width=2100 2100w,//hiutdenim.co.uk/cdn/shop/files/Hiut-EiraEcru-01_91c15dbe-7412-47b6-8f76-bdb434199203.jpg?v=1731517834&width=2460 2460w,//hiutdenim.co.uk/cdn/shop/files/Hiut-EiraEcru-01_91c15dbe-7412-47b6-8f76-bdb434199203.jpg?v=1731517834&width=2820 2820w" sizes="(max-width: 768px) 50vw, (max-width: 1024px) and (orientation: portrait) 50vw, 25vw " loading="lazy" class="lazy lazyloaded" data-ratio="0.8" width="3200" height="4000" onload="this.classList.add('lazyloaded')"><span class="lazy-preloader " aria-hidden="true"><svg class="circular-loader" viewBox="25 25 50 50"><circle class="loader-path" cx="50" cy="50" r="20" fill="none" stroke-width="4"></circle></svg></span></div><div class="box--product-image secondary" style="padding-top: 120.00048000192001%"><img src="//hiutdenim.co.uk/cdn/shop/files/Hiut-EiraEcru-02.jpg?v=1731517834&width=640" alt="The Eira - Organic Ecru" srcset="//hiutdenim.co.uk/cdn/shop/files/Hiut-EiraEcru-02.jpg?v=1731517834&width=360 360w,//hiutdenim.co.uk/cdn/shop/files/Hiut-EiraEcru-02.jpg?v=1731517834&width=420 420w,//hiutdenim.co.uk/cdn/shop/files/Hiut-EiraEcru-02.jpg?v=1731517834&width=480 480w,//hiutdenim.co.uk/cdn/shop/files/Hiut-EiraEcru-02.jpg?v=1731517834&width=640 640w,//hiutdenim.co.uk/cdn/shop/files/Hiut-EiraEcru-02.jpg?v=1731517834&width=840 840w,//hiutdenim.co.uk/cdn/shop/files/Hiut-EiraEcru-02.jpg?v=1731517834&width=1080 1080w,//hiutdenim.co.uk/cdn/shop/files/Hiut-EiraEcru-02.jpg?v=1731517834&width=1280 1280w,//hiutdenim.co.uk/cdn/shop/files/Hiut-EiraEcru-02.jpg?v=1731517834&width=1540 1540w,//hiutdenim.co.uk/cdn/shop/files/Hiut-EiraEcru-02.jpg?v=1731517834&width=1860 1860w,//hiutdenim.co.uk/cdn/shop/files/Hiut-EiraEcru-02.jpg?v=1731517834&width=2100 2100w,//hiutdenim.co.uk/cdn/shop/files/Hiut-EiraEcru-02.jpg?v=1731517834&width=2460 2460w,//hiutdenim.co.uk/cdn/shop/files/Hiut-EiraEcru-02.jpg?v=1731517834&width=2820 2820w" sizes="(max-width: 768px) 50vw, (max-width: 1024px) and (orientation: portrait) 50vw, 25vw " loading="lazy" class="lazy lazyloaded" data-ratio="0.8" width="3200" height="4000" onload="this.classList.add('lazyloaded')"></div><div class="caption">
<div>
<span class="title"><span class="underline-animation">The Eira - Organic Ecru</span></span>
<span class="price text-size--smaller"><span style="display:flex;flex-direction:row">$285.00</span></span>
</div><quick-view-product class="quick-add-to-cart">
<div class="quick-add-to-cart-button">
<button class="product__add-to-cart" data-href="/products/the-eira-straight-leg" tabindex="-1">
<span class="visually-hidden">Add to cart</span>
<span class="add-to-cart__text" style="height:26px" role="img"><svg width="22" height="26" viewBox="0 0 22 26" fill="none" xmlns="http://www.w3.org/2000/svg"><path d="M6.57058 6.64336H4.49919C3.0296 6.64336 1.81555 7.78963 1.7323 9.25573L1.00454 22.0739C0.914352 23.6625 2.17916 25 3.77143 25H18.2286C19.8208 25 21.0856 23.6625 20.9955 22.0739L20.2677 9.25573C20.1844 7.78962 18.9704 6.64336 17.5008 6.64336H15.4294M6.57058 6.64336H15.4294M6.57058 6.64336V4.69231C6.57058 2.6531 8.22494 1 10.2657 1H11.7343C13.775 1 15.4294 2.6531 15.4294 4.69231V6.64336" stroke="var(--main-text)" style="fill:none!important" stroke-width="1.75"></path><path d="M10.0801 12H12.0801V20H10.0801V12Z" fill="var(--main-text)" style="stroke:none!important"></path><path d="M15.0801 15V17L7.08008 17L7.08008 15L15.0801 15Z" fill="var(--main-text)" style="stroke:none!important"></path></svg></span><span class="lazy-preloader add-to-cart__preloader" aria-hidden="true"><svg class="circular-loader" viewBox="25 25 50 50"><circle class="loader-path" cx="50" cy="50" r="20" fill="none" stroke-width="4"></circle></svg></span></button>
</div>
</quick-view-product></div><div class="product-badges-holder"></div></a></div>从上面的 HTML 中提取数据并非不可能,只是有更简单的方式。
Shopify 的首页
在 https://hiutdenim.co.uk/,他们的首页包含了一些产品信息,但比较有限。一直向下滚动,你会在页面底部找到这些信息。
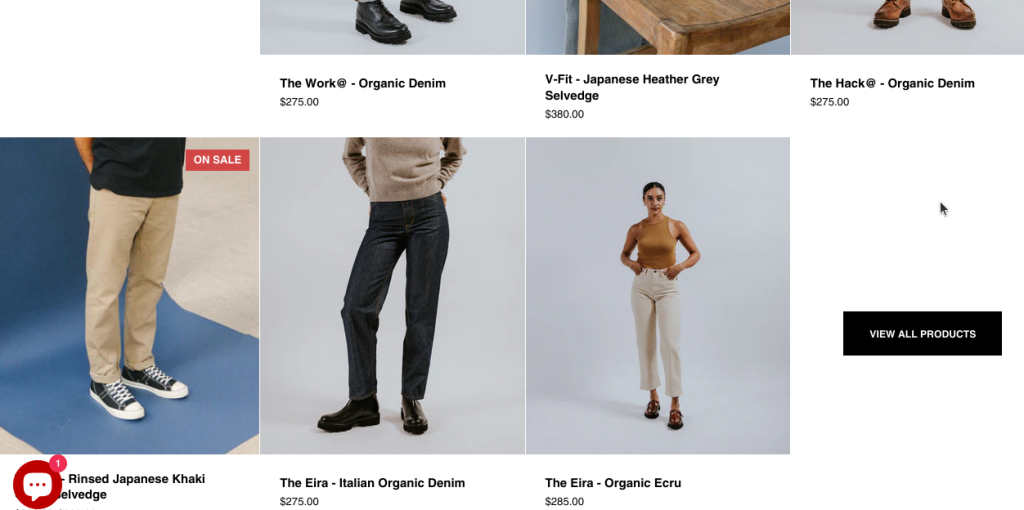
第一眼看起来,你似乎需要爬取每一个分类链接,然后依次获取并解析这些不同的网页。Shopify 商店在页面布局上并不遵循传统的电商爬虫方法。不过,还有另一种办法。
Shopify 的 JSON 页面
没看错,所有产品都可以作为 JSON 对象获取。我们甚至不需要BeautifulSoup或Selenium。
只要给我们的 URL 添加 /products.json 即可。每一个 Shopify 网站都是基于一个 products.json 文件构建的。
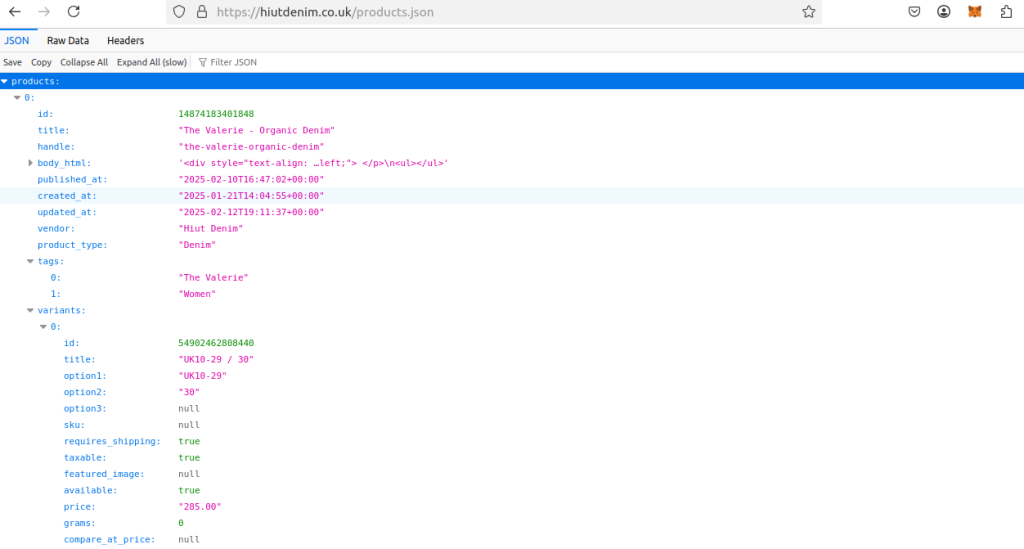
我们可以直接请求此内容(确实可行),从而获得所需的大部分数据。拿到数据之后,只需筛选想保留的部分即可。可以点击这里验证我们使用的示例站点。
在 Python 中爬取 Shopify
现在我们知道了目标数据在何处,原本看似繁琐的工作立刻变得简单许多。因为只需处理 JSON 数据,所以只需要一个依赖库:Python Requests。
pip install requests单独函数
让我们先看看代码的几个部分。我们的爬虫由三个部分组成。
下面这个函数非常重要,它实际执行爬取逻辑:
def scrape_shopify(url, retries=2):
"""scrape a shopify store"""
json_url = f"{url}products.json"
items = []
success = False
while not success and retries > 0:
response = requests.get(json_url)
try:
response.raise_for_status()
products = response.json()["products"]
for product in products:
product_data = {
"title": product["title"],
"tags": product["tags"],
"id": product["id"],
"variants": product["variants"],
"images": product["images"],
"options": product["options"]
}
items.append(product_data)
success = True
except requests.RequestException as e:
print(f"Error during request: {e}, failed to get {json_url}")
except KeyError as key_error:
print(f"Failed to parse json: {key_error}")
except json.JSONDecodeError as e:
print(f"json error: {e}")
except Exception as e:
print(f"Unforeseen error: {e}")
retries-=1
print(f"Retries left: ", retries)
return items- 首先,我们将
products.json附加到原始 URL:json_url = f"{url}products.json"。 - 初始化一个空列表
items,在爬取到的产品数据中,我们会将它们都加到这个列表中。最后会返回这个列表。 - 如果返回了正常的响应,我们就获取
"products"键来得到所有产品。 - 我们从每个产品中提取一些具体信息来创建
dict,即product_data。 product_data依次追加到items列表中。- 这样一直循环解析页面中的所有产品。
我们已经有了一个函数来执行爬取并返回产品列表。接下来,我们需要一个函数来处理这个产品列表并将其写入文件。我们可以使用 CSV,但是由于结构比较嵌套,这里使用 JSON 更合适,可以支持更灵活的数据结构,方便后续分析。
def json2file(json_data, filename):
"""save json data to a file"""
try:
with open(filename, "w", encoding="utf-8") as file:
json.dump(json_data, file, indent=4)
print(f"Data successfully saved: {filename}")
except Exception as e:
print(f"failed to write json data to {filename}, ERROR: {e}")以上就是我们需要的核心代码。接下来,我们在 main 部分来运行爬虫。
if __name__ == "__main__":
shop_url = "https://hiutdenim.co.uk/"
items = scrape_shopify(shop_url)
json2file(items, "output.json")整合所有代码
将所有代码放到一起,我们的爬虫就完成了。原本看似复杂的解析操作,通过这种方式,代码量也就大约 50 行左右。
import requests
import json
def json2file(json_data, filename):
"""save json data to a file"""
try:
with open(filename, "w", encoding="utf-8") as file:
json.dump(json_data, file, indent=4)
print(f"Data successfully saved: {filename}")
except Exception as e:
print(f"failed to write json data to {filename}, ERROR: {e}")
def scrape_shopify(url, retries=2):
"""scrape a shopify store"""
json_url = f"{url}products.json"
items = []
success = False
while not success and retries > 0:
response = requests.get(json_url)
try:
response.raise_for_status()
products = response.json()["products"]
for product in products:
product_data = {
"title": product["title"],
"tags": product["tags"],
"id": product["id"],
"variants": product["variants"],
"images": product["images"],
"options": product["options"]
}
items.append(product_data)
success = True
except requests.RequestException as e:
print(f"Error during request: {e}, failed to get {json_url}")
except KeyError as key_error:
print(f"Failed to parse json: {key_error}")
except json.JSONDecodeError as e:
print(f"json error: {e}")
except Exception as e:
print(f"Unforeseen error: {e}")
retries-=1
return items
if __name__ == "__main__":
shop_url = "https://hiutdenim.co.uk/"
items = scrape_shopify(shop_url)
json2file(items, "output.json")返回的数据
我们的数据会以 JSON 对象数组的形式返回。每个产品都包含 variants 和 images 列表。如果使用 CSV 来存储可能会比较麻烦。下面这个片段展示了一个完整产品的示例:
{
"title": "The Valerie - Organic Denim",
"tags": [
"The Valerie",
"Women"
],
"id": 14874183401848,
"variants": [
{
"id": 54902462808440,
"title": "UK10-29 / 30",
"option1": "UK10-29",
"option2": "30",
"option3": null,
"sku": null,
"requires_shipping": true,
"taxable": true,
"featured_image": null,
"available": true,
"price": "220.00",
"grams": 0,
"compare_at_price": null,
"position": 1,
"product_id": 14874183401848,
"created_at": "2025-01-21T14:04:58+00:00",
"updated_at": "2025-02-12T17:17:54+00:00"
},
{
"id": 54902462939512,
"title": "UK12-30 / 32",
"option1": "UK12-30",
"option2": "32",
"option3": null,
"sku": null,
"requires_shipping": true,
"taxable": true,
"featured_image": null,
"available": true,
"price": "220.00",
"grams": 0,
"compare_at_price": null,
"position": 2,
"product_id": 14874183401848,
"created_at": "2025-01-21T14:04:58+00:00",
"updated_at": "2025-02-12T17:17:54+00:00"
},
{
"id": 54902463070584,
"title": "UK14-32 / 28",
"option1": "UK14-32",
"option2": "28",
"option3": null,
"sku": null,
"requires_shipping": true,
"taxable": true,
"featured_image": null,
"available": true,
"price": "220.00",
"grams": 0,
"compare_at_price": null,
"position": 3,
"product_id": 14874183401848,
"created_at": "2025-01-21T14:04:58+00:00",
"updated_at": "2025-02-12T17:17:54+00:00"
},
{
"id": 54902463496568,
"title": "UK18-36 / 30",
"option1": "UK18-36",
"option2": "30",
"option3": null,
"sku": null,
"requires_shipping": true,
"taxable": true,
"featured_image": null,
"available": true,
"price": "220.00",
"grams": 0,
"compare_at_price": null,
"position": 4,
"product_id": 14874183401848,
"created_at": "2025-01-21T14:04:58+00:00",
"updated_at": "2025-02-12T17:17:54+00:00"
}
],
"images": [
{
"id": 31828166443078,
"created_at": "2024-06-17T12:05:49+01:00",
"position": 1,
"updated_at": "2024-06-17T12:05:50+01:00",
"product_id": 14874183401848,
"variant_ids": [],
"src": "https://cdn.shopify.com/s/files/1/0065/4242/files/HDC_0723_JapanInd_Valerie_45_3_c547ba8a-681b-4486-8cd7-884000e43302.jpg?v=1718622350",
"width": 4000,
"height": 4000
},
{
"id": 31828166541382,
"created_at": "2024-06-17T12:05:49+01:00",
"position": 2,
"updated_at": "2024-06-17T12:05:51+01:00",
"product_id": 14874183401848,
"variant_ids": [],
"src": "https://cdn.shopify.com/s/files/1/0065/4242/files/HDC_0723_JapanInd_Valerie_Back_2_5909adb3-c2ab-4810-8b66-a486e8d827a8.jpg?v=1718622351",
"width": 4000,
"height": 4000
},
{
"id": 31828166508614,
"created_at": "2024-06-17T12:05:49+01:00",
"position": 3,
"updated_at": "2024-06-17T12:05:51+01:00",
"product_id": 14874183401848,
"variant_ids": [],
"src": "https://cdn.shopify.com/s/files/1/0065/4242/files/HDC_0723_JapanInd_Valerie_Front_3_4316907a-9fd8-4649-894c-4028877370e1.jpg?v=1718622351",
"width": 4000,
"height": 4000
},
{
"id": 31828166475846,
"created_at": "2024-06-17T12:05:49+01:00",
"position": 4,
"updated_at": "2024-06-17T12:05:51+01:00",
"product_id": 14874183401848,
"variant_ids": [],
"src": "https://cdn.shopify.com/s/files/1/0065/4242/files/HDC_0723_JapanInd_Valerie_Side_2_ea21477b-c1ba-4c8a-b75e-75c6427b4977.jpg?v=1718622351",
"width": 4000,
"height": 4000
}
],
"options": [
{
"name": "Waist",
"position": 1,
"values": [
"UK10-29",
"UK12-30",
"UK14-32",
"UK18-36"
]
},
{
"name": "Leg Length",
"position": 2,
"values": [
"30",
"32",
"28"
]
}
]
},高级技巧
现实中并不总是一帆风顺,你可能在使用上述爬虫时遇到一些问题,比如需要翻多页或被网站屏蔽等。
分页
爬取大型商店时,经常会遇到分页问题。这时我们想要最大限度地获取每页结果。在 URL 上使用 page=<PAGE_NUMBER> 这个参数就能指定分页。
可以稍作改动,让爬虫函数接受一个分页参数。
def scrape_shopify(url, retries=2):
"""scrape a shopify store"""
json_url = f"{url}products.json"然后在 main 函数中相应修改:
if __name__ == "__main__":
shop_url = "https://www.allbirds.com/"
PAGES = 3
for page in range(PAGES):
items = scrape_shopify(shop_url, page=page+1)
json2file(items, f"page{page}output.json")代理集成
有时为了避免爬虫被封,你可能需要使用代理服务。在我们的Shopify 代理中,只需在请求时加上你的认证信息即可。
PROXY_URL = "http://brd-customer-<YOUR-USERNAME>-zone-<YOUR-ZONE>:<YOUR-PASSWORD>@brd.superproxy.io:33335"
proxies = {
"http": PROXY_URL,
"https": PROXY_URL
}
response = requests.get(json_url, proxies=proxies, verify="brd.crt")Bright Data 的其他解决方案
Bright Data 提供了成熟的现成方案,让你无需从零开始构建复杂的爬虫。使用我们的Shopify 专用爬虫,即可轻松提取数据,或者访问我们现成的数据集,这些数据以多种格式提供,可直接开始你的项目。
结论
爬取 Shopify 商店并非难如登天。通过简单添加 products.json 并利用其 API,你就能轻松获取大量详尽的产品数据。甚至不需要任何 HTML 解析器!如果想节省开发时间,可以使用我们现成的爬虫,或者立刻使用我们的数据集。
所有 Bright Data 的产品都提供免费试用,快来注册吧!



