

在本教程中,您将学习如何构建 Python 脚本来抓取 Google 的 “People Also Ask” 板块。此板块提供与您的搜索查询相关的常见问题,包含有价值的信息。
现在就来一探究竟吧!
了解 Google 的 “People Also Ask” 功能
“People Also Ask” (PAA) 是 Google 搜索引擎结果页面 (SERP) 中的一个板块,提供一系列与用户搜索查询相关的问题,问题清单会动态变化:
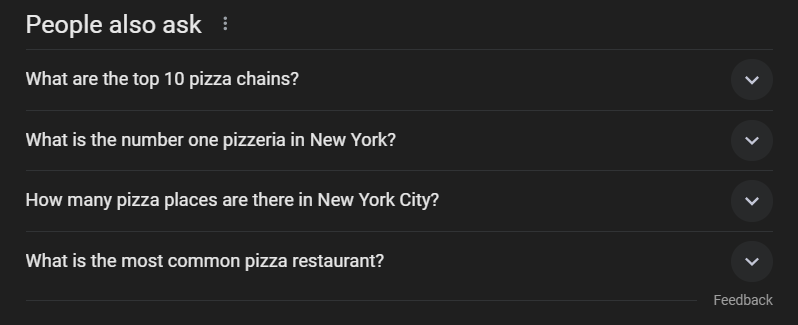
此板块有助于您更深入地了解与搜索查询相关的主题。PAA 于 2015 年左右首次推出,以一系列可扩展问题的形式出现在搜索结果中。每当点击其中的一个问题,PAA 会展开,显示来自相关网页的简短答案以及来源链接:
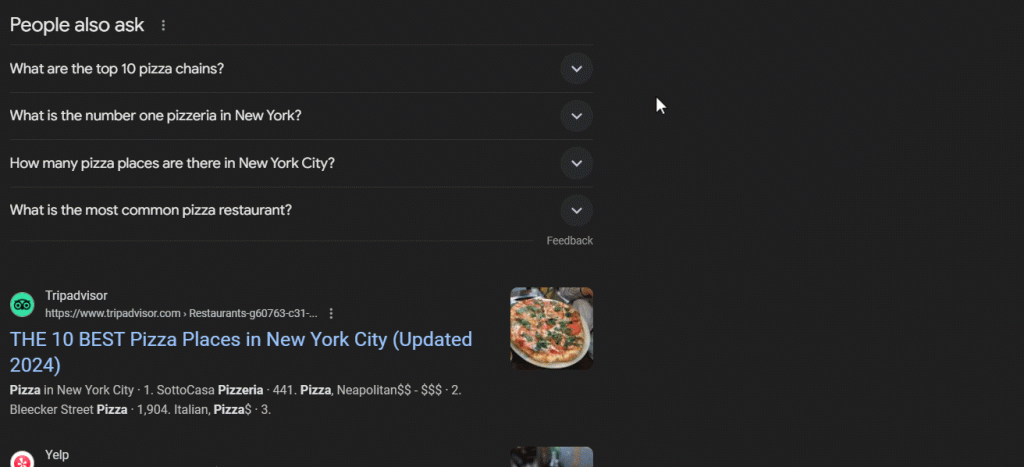
“People Also Ask” 板块根据用户搜索内容频繁更新、调整,提供最新的相关信息。当您打开下拉列表时,新问题会动态加载。
抓取 “People Also Ask” Google:分步指南
关注此指南,学习如何构建 Python 脚本从 Google SERP 抓取 “People also ask”。
最终目标是检索页面中 “People also ask” 板块的每个问题中包含的数据。如果您只对抓取 Google 感兴趣,请关注我们的 SERP 抓取教程。
第 1 步:项目设置
开始之前,请确认您的设备已安装 Python 3。如果未安装,请下载 Python 3,运行可执行文件,然后根据安装向导操作即可。
接着使用以下命令,通过虚拟环境初始化 Python 项目:
mkdir people-also-ask-scraper
cd people-also-ask-scraper
python -m venv env
people-also-ask-scraper 目录就是您的 Python PAA 抓取工具的项目文件夹。
在您收藏的 Python IDE 中加载项目文件夹。PyCharm Community Edition 或 Visual Studio Code(带有 Python 扩展)是两个很好的选择。
在项目的文件夹中,创建 scraper.py 文件。此文件现为空白脚本,但很快就会包含抓取逻辑:
在 IDE 的终端中,激活虚拟环境。在 Linux 或 macOS 中,执行以下命令:
./env/bin/activate
或者在 Windows 上运行:
env/Scripts/activate
很好,现在您的抓取工具有了 Python 环境!
第 2 步:安装 Selenium
Google 是一个需要用户交互的平台。而且伪造有效的 Google 搜索 URL 可能比较困难。因此,使用搜索引擎的最佳方法是在浏览器中使用。
换句话说,要抓取 “People Also Ask” 板块,您需要浏览器自动化工具。如果您不熟悉这个概念,浏览器自动化工具使您能够在可控的浏览器中呈现网页并与之交互。其中 Selenium 是个很好用的 Python 工具!
在激活的 Python 虚拟环境中运行以下命令来安装 Selenium:
pip install selenium
selenium pip 安装包将添加到您项目的依赖项中。添加操作可能需要一段时间,所以请耐心等待。
如需进一步了解如何使用此工具,请阅读我们的 利用 Selenium 抓取网页指南。
很好,您现在已做好一切准备,可以开始抓取 Google 页面了!
第 3 步:导航到 Google 首页
在 scraper.py 中导入 Selenium 并初始化 WebDriver 对象,以便在无界面模式下控制 Chrome 实例:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
# to control a Chrome window in headless mode
options = Options()
options.add_argument("--headless") # comment it while developing
# initialize a web driver instance with the
# specified options
driver = webdriver.Chrome(
service=Service(),
options=options
)
上面的代码片段创建了一个 Chrome WebDriver 实例,该对象用于以编程方式控制 Chrome 窗口。--headless 选项将 Chrome 配置为在无界面模式下运行。为了便于调试,请为该行添加注释,以便您可以实时观察自动脚本的操作。
然后,使用 get() 方法连接到 Google 首页:
driver.get("https://google.com/")
不要忘记在脚本末尾释放驱动程序资源:
driver.quit()
完成所有操作后,您会得到:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
# to control a Chrome window in headless mode
options = Options()
options.add_argument("--headless") # comment it while developing
# initialize a web driver instance with the
# specified options
driver = webdriver.Chrome(
service=Service(),
options=options
)
# connect to the Google home page
driver.get("https://google.com/")
# scraping logic...
# close the browser and free up the resources
driver.quit()
太棒了,您已准备好抓取动态网站!
第 4 步:处理 GDPR Cookie 对话框
注意:如果您不在欧盟境内,则可以跳过此步骤。
在有界面模式下运行 scraper.py 脚本。这将在 quit() 命令将其关闭之前,短暂地打开显示 Google 页面的 Chrome 浏览器窗口。如果您位于欧盟境内,您将看到:
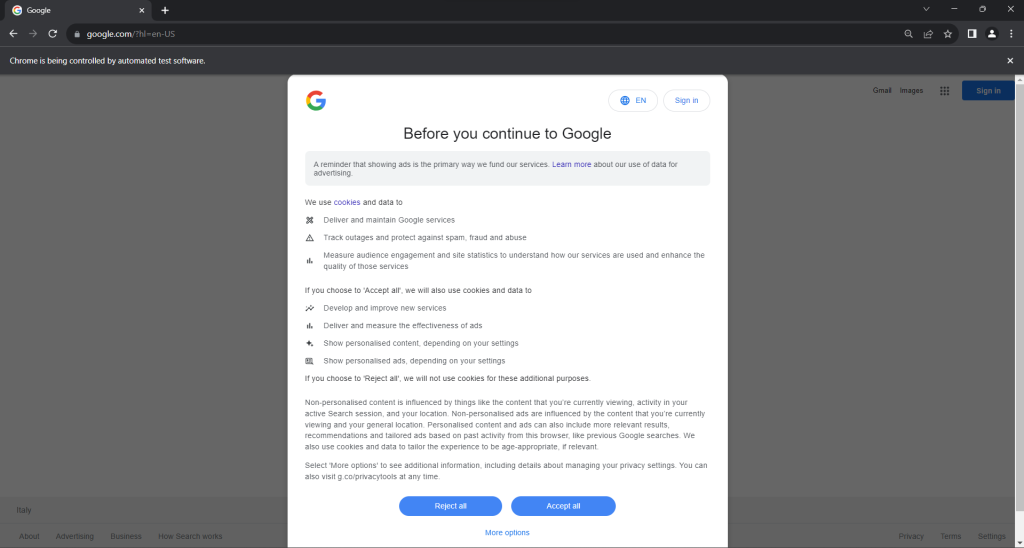
“Chrome 由自动测试软件控制。”——此消息确保 Selenium 如预期控制着 Chrome。
根据 GDPR 规定,这里会向欧盟用户显示 Cookie 政策对话框。您属于这种情况时,如果想与底层页面交互,则需要处理此对话框。否则,您可以跳到第 5 步。
以隐身模式打开 Google 页面,然后查看 GDPR Cookie 对话框。右键单击对话框并选择“查看”选项:
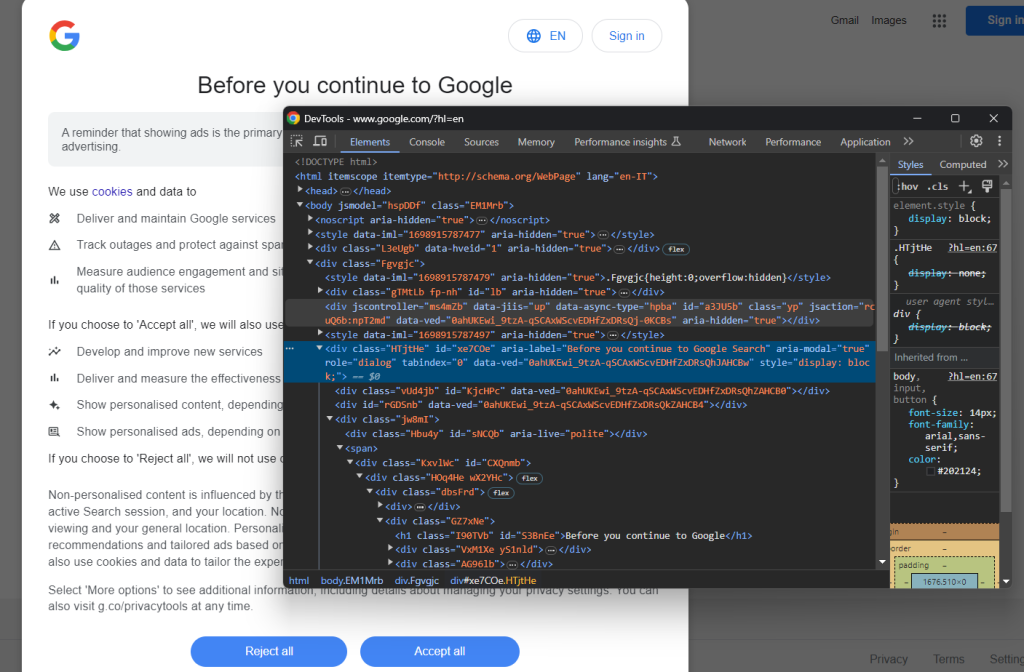
请注意,您可以通过以下方式找到对话框 HTML 元素:
cookie_dialog = driver.find_element(By.CSS_SELECTOR, "[role='dialog']")
find_element() 是 Selenium 提供的方法,用于通过不同策略找到页面上的 HTML 元素。这种情况下,我们使用 CSS 选择器。
别忘了按以下方式导入 By:
from selenium.webdriver.common.by import By
现在,关注“全部接受”按钮:
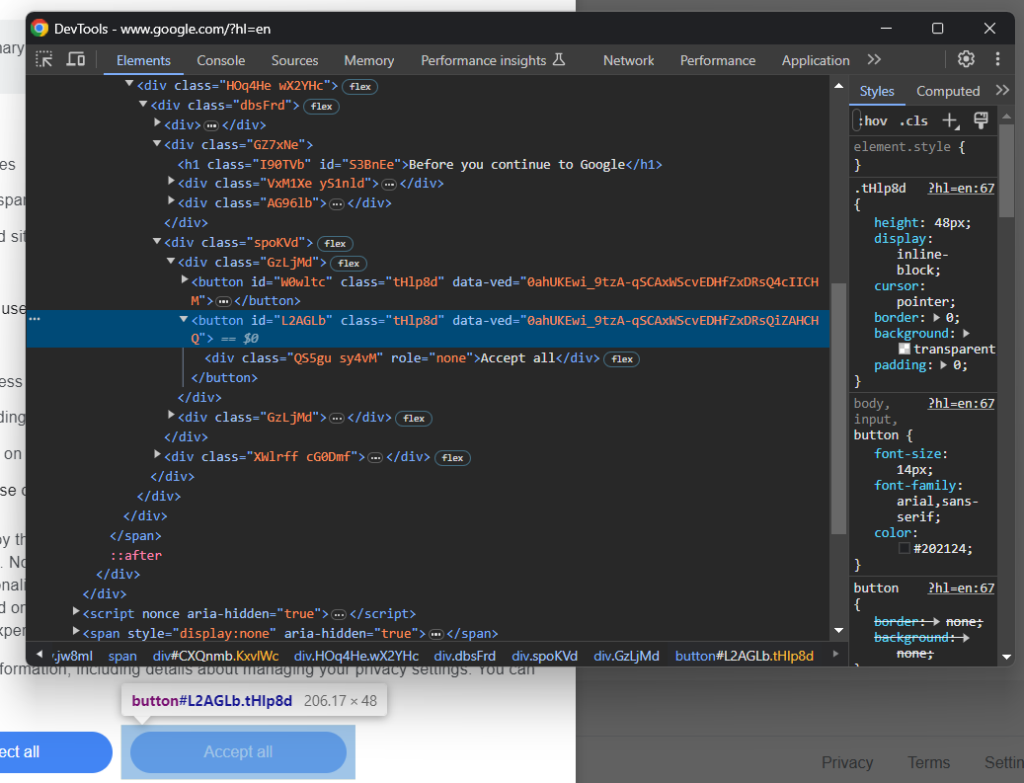
您可以看出,选择此按钮并不简单,因为它的 CSS 类似乎为随机生成。因此,您可以使用以其内容为目标的 XPath 表达式来检索:
accept_button = cookie_dialog.find_element(By.XPATH, "//button[contains(., 'Accept')]")
此指令将在对话框中找到文本包含“接受”字符串的第一个按钮。如需了解更多信息,请阅读我们的 XPath 与 CSS 选择器指南。
以下介绍如何多方配合来处理可选的 Google Cookie 对话框:
try:
# select the dialog and accept the cookie policy
cookie_dialog = driver.find_element(By.CSS_SELECTOR, "[role='dialog']")
accept_button = cookie_dialog.find_element(By.XPATH, "//button[contains(., 'Accept')]")
if accept_button is not None:
accept_button.click()
except NoSuchElementException:
print("Cookie dialog not present")
click() 指令点击“全部接受”按钮以关闭对话框并允许用户交互。如果没有出现 cookie 政策对话框,则会弹出 noSuchElementException。脚本将捕获此异常并继续操作。
记得导入 noSuchElementException:
from selenium.common import NoSuchElementException
干得好!您已做好准备,可以访问包含 “People also ask” 板块的页面。
第 5 步:提交搜索表单
使用浏览器访问 Google 首页并查看搜索表单。右键单击表单并选择“查看”选项:
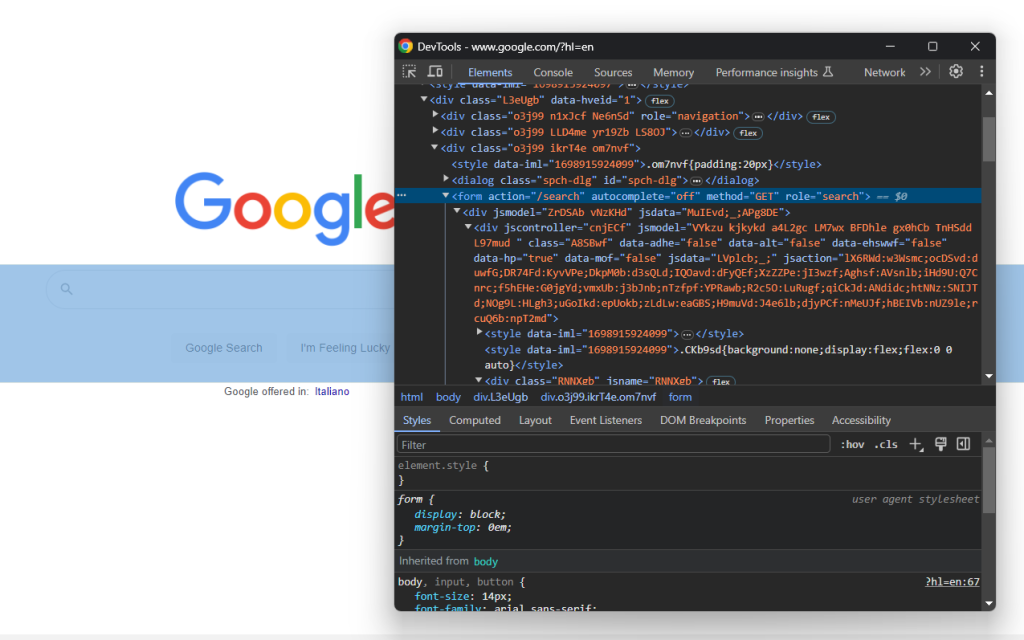
此元素没有 CSS 类,但您可以通过其 action 属性将其选中:
search_form = driver.find_element(By.CSS_SELECTOR, "form[action='/search']")
如果您跳过了第 4 步,请通过以下方式导入 By:
from selenium.webdriver.common.by import By
展开表单的 HTML 代码并查看搜索输入区:
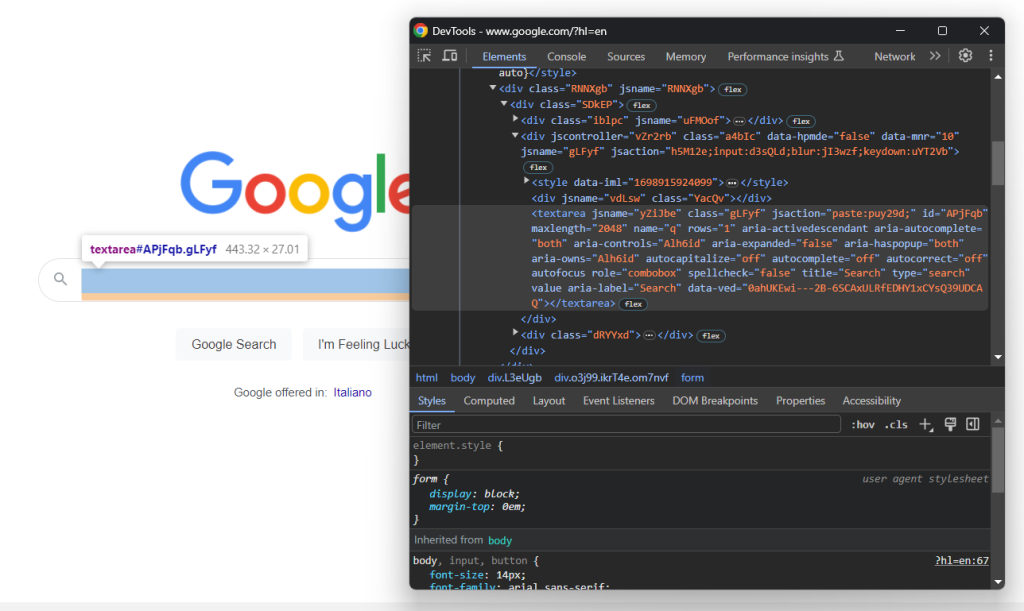
此节点的 CSS 类似乎为随机生成。因此,通过其 aria-label 属性将其选中。然后,使用 send_keys() 方法输入目标搜索查询:
search_textarea = search_form.find_element(By.CSS_SELECTOR, "textarea[aria-label='Search']")
search_query = "Bright Data"
search_textarea.send_keys(search_query)
在此示例中,搜索查询为 “Bright Data”,但任何其他搜索都可以。
提交表单以触发页面更改:
search_form.submit()
很好!现在,受控浏览器将被重定向到包含 “People also ask” 板块的 Google 页面。
如果您以有界面模式执行脚本,则在浏览器关闭之前您将看到:
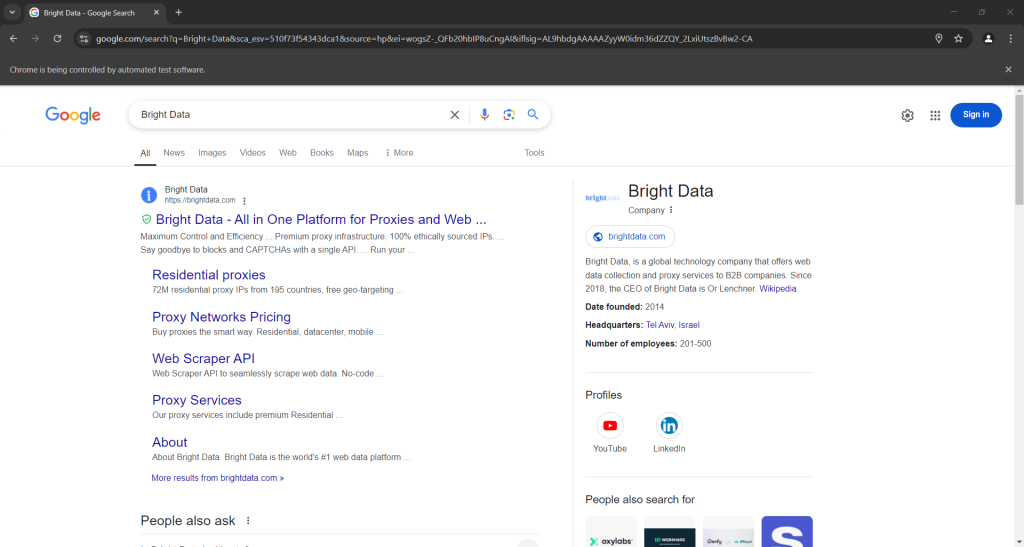
注意以上屏幕截图底部的 “People also ask” 板块。
第 6 步:选择 “People also ask” 节点
查看 “People also ask” HTML 元素:
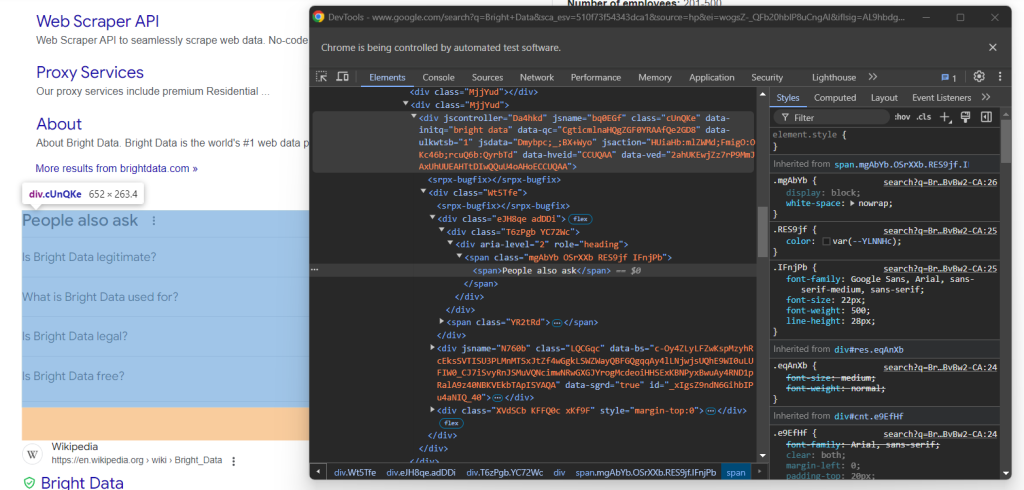
同样,此元素也没有简单的选择方法。此时您可以做的是在 “People also ask” 文本中检索具有 jscontroller、jsname 和 jsaction 属性的 <div> 元素,此元素中包含 role=heading 的 div:
people_also_ask_div = WebDriverWait(driver, 5).until(
EC.presence_of_element_located((
By.XPATH, "//div[@jscontroller and @jsname and @jsaction][.//div[@role='heading' and contains(., 'People also ask')]]"
))
)
WebdriverWait 属于特殊的 Selenium 类,会在页面上的特定条件得到满足之前暂停脚本。在上文示例中,它最多等待 5 秒,所需的 HTML 元素才会出现。提交表单后,想让页面完全加载,这是必需的操作。
presence_of_element_located() 中使用的 XPath 表达式比较复杂,但能准确地描述选择 “People also ask” 元素所需的标准。
别忘了添加所需的导入内容:
from selenium.webdriver.support.wait import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
该从 Google 的 “People also ask” 板块抓取数据了!
第 7 步:抓取 “People also ask”
首先,初始化一个数据结构来存储所抓取的数据:
people_also_ask_questions = []
此数据结构必须为数组,因为 “People also ask” 板块包含若干问题。
现在,查看 “People also ask” 节点中的第一个问题下拉列表:
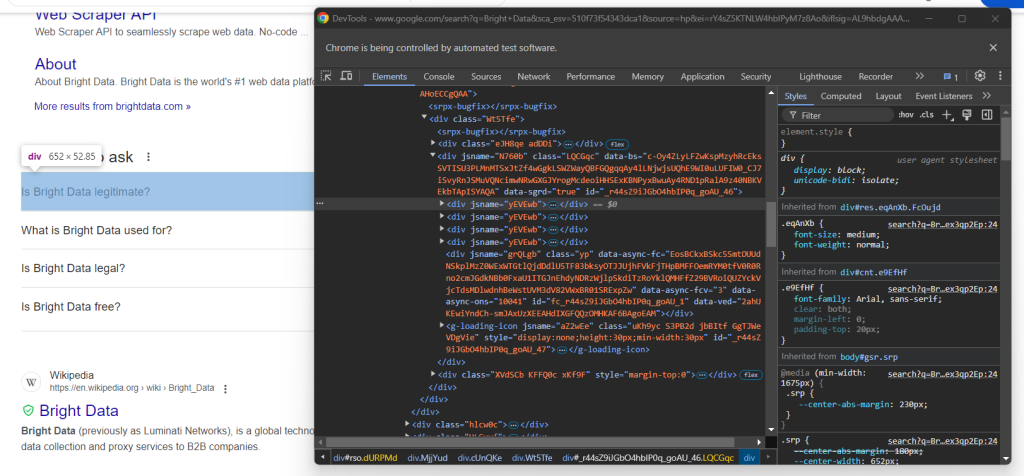
在此您会发现相关元素是只包含 jsname 属性的 “People also ask” 元素内 data-sgrd="true" <div> 的子元素。最后两个子元素被 Google 用作占位符,会在您打开下拉列表时动态填充。
使用以下逻辑选择问题下拉列表:
people_also_ask_inner_div = people_also_ask_div.find_element(By.CSS_SELECTOR, "[data-sgrd='true']")
people_also_ask_inner_div_children = people_also_ask_inner_div.find_elements(By.XPATH, "./*")
for child in people_also_ask_inner_div_children:
# if the current element is a question dropdown
if child.get_attribute("jsname") is not None and child.get_attribute("class") == '':
# scraping logic...
点击元素将其展开:
child.click()
接着关注问题元素中的内容:
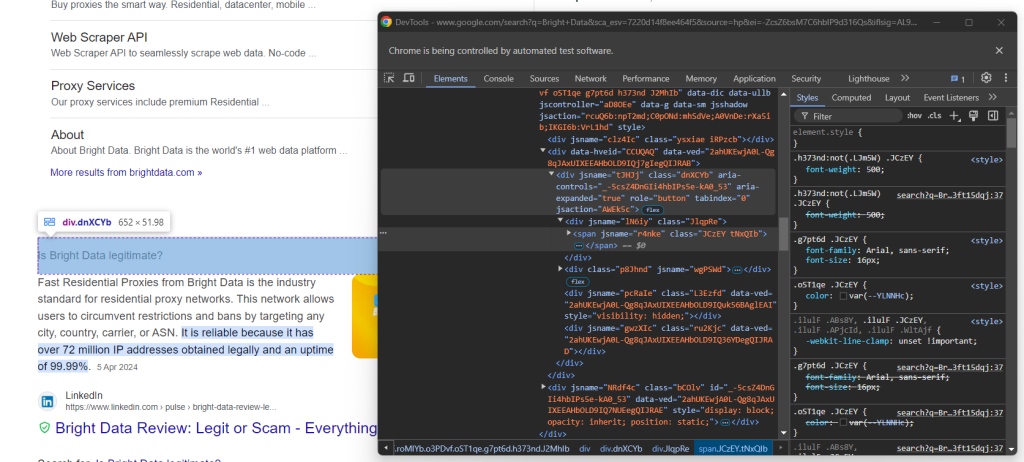
请注意,此问题包含于 aria-expanded="true" 节点内的 <span> 中。按照以下方式抓取:
question_title_element = child.find_element(By.CSS_SELECTOR, "[aria-expanded='true'] span")
question_title = question_title_element.text
然后,查看答案元素:
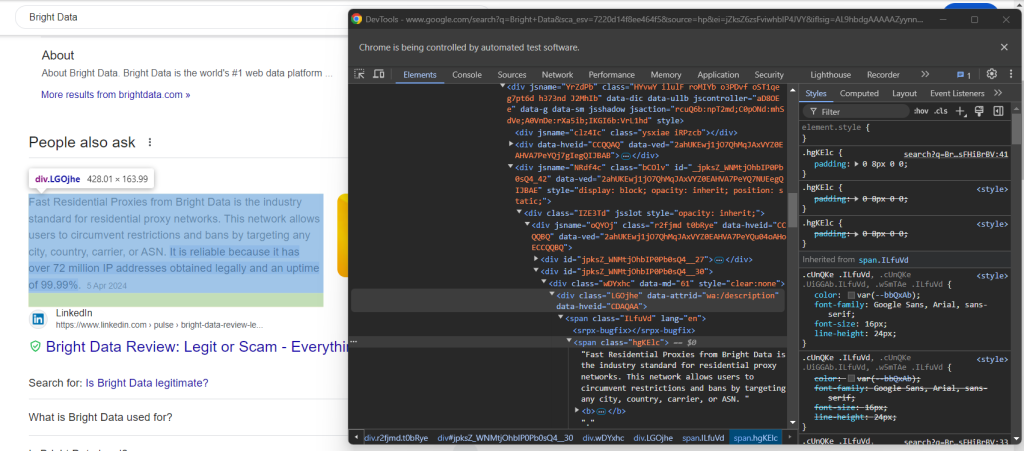
注意如何在 data-attrid="wa:/description" 元素中,通过收集 <span> 节点内具有 lang 属性的文本来检索答案元素:
question_description_element = child.find_element(By.CSS_SELECTOR, "[data-attrid='wa:/description'] span[lang]")
question_description = question_description_element.text
接着,查看答案框中的可选图片:
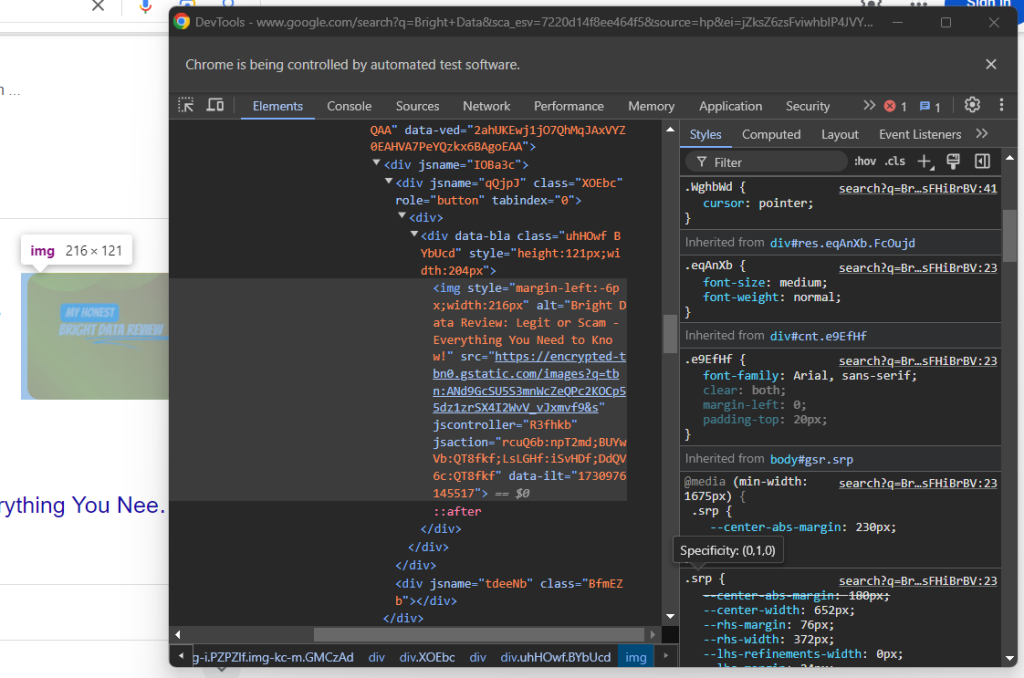
您可以从具有 data-ilt 属性的 <img> 元素中访问 src 属性来获取其 URL:
try:
question_image_element = child.find_element(By.CSS_SELECTOR, "img[data-ilt]")
question_image = question_image_element.get_attribute("src")
except NoSuchElementException:
question_image = None
由于图片元素为可选,因此您必须使用 try... except 块来包裹上述代码。如果当前问题中不存在该节点,find_element() 将抛出 noSuchElementException。代码会将其拦截然后继续操作,在这种情况下,
如果您跳过了第 4 步,请导入异常:
from selenium.common import NoSuchElementException
最后,查看检查源部分:
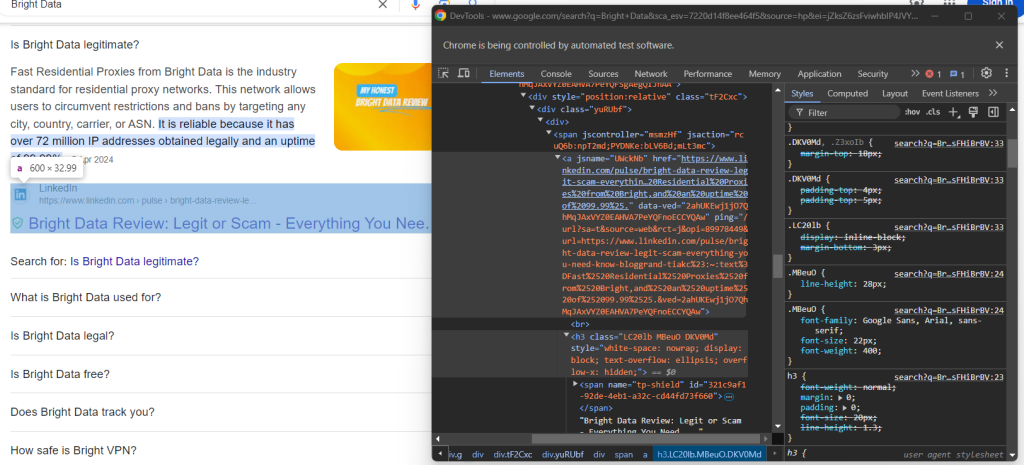
您可以通过选择 <h3> 元素的 <a> 父元素来获取源部分的 URL:
question_source_element = child.find_element(By.XPATH, ".//h3/ancestor::a")
question_source = question_source_element.get_attribute("href")
使用抓取的数据填充新对象并将其添加到 people_also_ask_questions 数组:
people_also_ask_question = {
"title": question_title,
"description": question_description,
"image": question_image,
"source": question_source
}
people_also_ask_questions.append(people_also_ask_question)
很棒!您刚刚从 Google 页面上抓取了 “People also ask” 板块。
第 8 步:将所抓取的数据导出为 CSV 格式
如果您打印了 people_also_ask_questions(其他人也搜索的问题),您将看到以下内容:
[{'title': 'Is Bright Data legitimate?', 'description': 'Fast Residential Proxies from Bright Data is the industry standard for residential proxy networks. This network allows users to circumvent restrictions and bans by targeting any city, country, carrier, or ASN. It is reliable because it has over 72 million IP addresses obtained legally and an uptime of 99.99%.', 'image': 'https://encrypted-tbn0.gstatic.com/images?q=tbn:ANd9GcSU5S3mnWcZeQPc2KOCp55dz1zrSX4I2WvV_vJxmvf9&s', 'source': 'https://www.linkedin.com/pulse/bright-data-review-legit-scam-everything-you-need-know-bloggrand-tiakc#:~:text=Fast%20Residential%20Proxies%20from%20Bright,and%20an%20uptime%20of%2099.99%25.'}, {'title': 'What is Bright Data used for?', 'description': "Bright Data is the world's #1 web data platform, supporting the public data needs of over 22,000 organizations in nearly every industry. Using our solutions, organizations research, monitor, and analyze web data to make better decisions.", 'image': None, 'source': "https://brightdata.com/about#:~:text=Bright%20Data%20is%20the%20world's,data%20to%20make%20better%20decisions."}, {'title': 'Is Bright Data legal?', 'description': "Bright Data's platform, technology, and network (collectively, “Services”) are meant for legitimate and legal purposes only and are subject to the Bright Data Master Service Agreement.", 'image': None, 'source': "https://brightdata.com/acceptable-use-policy#:~:text=Bright%20Data's%20platform%2C%20technology%2C%20and,Bright%20Data%20Master%20Service%20Agreement."}, {'title': 'Is Bright Data free?', 'description': 'Bright Data offers four free proxy solutions to meet various needs: Anonymous Proxies: These top-performing anonymous proxies let you access websites anonymously, routing traffic through a vast Residential IP Network of over 72 million IPs, concealing your true location.', 'image': None, 'source': 'https://brightdata.com/solutions/free-proxies#:~:text=Bright%20Data%20offers%20four%20free,IPs%2C%20concealing%20your%20true%20location.'}]
当然这样也很好,但如果采用能够轻松与其他团队成员共享的格式,那就更好了。因此,将 people_also_ask_questions 导出到 CSV 文件!
从 Python 标准库导入 csv 包:
import csv
接着,使用这个包在输出 CSV 文件中填充您的 SERP 数据:
csv_file = "people_also_ask.csv"
header = ["title", "description", "image", "source"]
with open(csv_file, "w", newline="", encoding="utf-8") as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=header)
writer.writeheader()
writer.writerows(people_also_ask_questions)
终于!您的 “People also ask” 抓取脚本已完成。
第 9 步:组合在一起
您的最终 scraper.py 脚本应包含以下代码:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.common.by import By
from selenium.common import NoSuchElementException
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
import csv
# to control a Chrome window in headless mode
options = Options()
options.add_argument("--headless") # comment it while developing
# initialize a web driver instance with the
# specified options
driver = webdriver.Chrome(
service=Service(),
options=options
)
# connect to the Google home page
driver.get("https://google.com/")
# deal with the optional Google cookie GDPR dialog
try:
# select the dialog and accept the cookie policy
cookie_dialog = driver.find_element(By.CSS_SELECTOR, "[role='dialog']")
accept_button = cookie_dialog.find_element(By.XPATH, "//button[contains(., 'Accept')]")
if accept_button is not None:
accept_button.click()
except NoSuchElementException:
print("Cookie dialog not present")
# select the search form
search_form = driver.find_element(By.CSS_SELECTOR, "form[action='/search']")
# select the textarea and fill it out
search_textarea = search_form.find_element(By.CSS_SELECTOR, "textarea[aria-label='Search']")
search_query = "Bright Data"
search_textarea.send_keys(search_query)
# submit the form to perform a Google search
search_form.submit()
# wait up to 5 seconds for the "People also ask" section
# to be on the page after page change
people_also_ask_div = WebDriverWait(driver, 5).until(
EC.presence_of_element_located((
By.XPATH, "//div[@jscontroller and @jsname and @jsaction][.//div[@role='heading' and contains(., 'People also ask')]]"
))
)
# where to store the scraped data
people_also_ask_questions = []
# select the question dropdowns and iterate over them
people_also_ask_inner_div = people_also_ask_div.find_element(By.CSS_SELECTOR, "[data-sgrd='true']")
people_also_ask_inner_div_children = people_also_ask_inner_div.find_elements(By.XPATH, "./*")
for child in people_also_ask_inner_div_children:
# if the current element is a question dropdown
if child.get_attribute("jsname") is not None and child.get_attribute("class") == '':
# expand the element
child.click()
# scraping logic
question_title_element = child.find_element(By.CSS_SELECTOR, "[aria-expanded='true'] span")
question_title = question_title_element.text
question_description_element = child.find_element(By.CSS_SELECTOR, "[data-attrid='wa:/description'] span[lang]")
question_description = question_description_element.text
try:
question_image_element = child.find_element(By.CSS_SELECTOR, "img[data-ilt]")
question_image = question_image_element.get_attribute("src")
except NoSuchElementException:
question_image = None
question_source_element = child.find_element(By.XPATH, ".//h3/ancestor::a")
question_source = question_source_element.get_attribute("href")
# populate the array with the scraped data
people_also_ask_question = {
"title": question_title,
"description": question_description,
"image": question_image,
"source": question_source
}
people_also_ask_questions.append(people_also_ask_question)
# export the scraped data to a CSV file
csv_file = "people_also_ask.csv"
header = ["title", "description", "image", "source"]
with open(csv_file, "w", newline="", encoding="utf-8") as csvfile:
writer = csv.DictWriter(csvfile, fieldnames=header)
writer.writeheader()
writer.writerows(people_also_ask_questions)
# close the browser and free up the resources
driver.quit()
您刚刚只用 100 行代码构建了一个 PAA 抓取工具!
执行此工具,验证是否有效。在 Windows 上,使用以下命令启动抓取工具:
python scraper.py
或者,在 Linux 或 macOS 上运行:
python3 scraper.py
等待抓取工具停止执行,然后您项目的根目录中将出现一个 people_also_ask.csv 文件。打开此文机,您会看到:
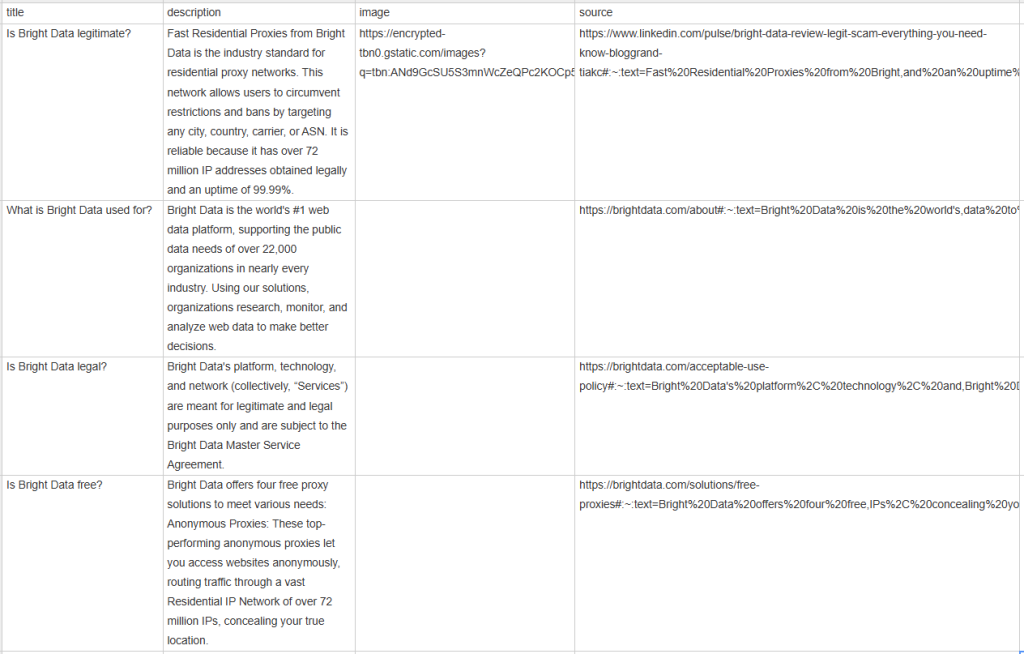
恭喜,任务完成!
结论
在本教程中,您了解了 Google 页面上 “People Also Ask” 板块的内容、其中包含的数据以及如何使用 Python 抓取。正如您在此学到的,构建简单脚本来自动从此板块检索数据只需要短短几行 Python 代码。
虽然提出的解决方案适用于小型项目,但却不适合大规模抓取。这里的问题在于,Google 拥有业内最先进的反机器人技术,因此可能会通过验证码或 IP 禁止来屏蔽您。此外,将抓取规模扩展到多个页面会增加基础架构成本。
这是否意味着不可能高效、可靠地抓取 Google 数据?肯定不是!您需要的只是能够解决这些困难的高级方案,比如 Bright Data 的 Google 搜索 API。
Google 搜索 API 提供了一个端点,用于检索 Google SERP 页面的数据,包括 “People also ask” 板块。通过简单调用 API,您可以获取 JSON 或 HTML 格式的所需数据。阅读官方文档,了解如何开始使用此工具。
立即注册,开始免费试用!



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。




