在本教程中,您将了解:
- 新闻抓取工具的定义及其用处
- 您可以使用工具抓取的数据类型
- 构建网络新闻抓取工具的两种最常用方法
- 如何使用 AI 构建新闻抓取流程
- 如何使用 Python 创建新闻抓取脚本
- 新闻文章抓取的挑战
现在就来一探究竟吧!
什么是新闻抓取工具?
新闻抓取器是一种自动工具,用于从新闻网站提取数据。它收集标题、发布日期、作者、标签和文章内容等信息。
新闻抓取工具可以使用 AI 和几种网络抓取编程语言来构建。它们广泛用于研究、趋势分析或构建新闻聚合器,与手动收集数据相比可以节省时间。
要从新闻文章中抓取的数据
您可以从新闻文章中提取的数据包括:
- 标题:文章的主标题和副标题。
- 发布日期:文章发布的日期。
- 作者:撰写文章内容的作家或记者的姓名。
- 内容:文章的正文。
- 标签/主题:与文章相关的关键词或类别。
- 多媒体附件:文章附带的视觉元素。
- 网址:相关文章或参考文献的链接。
- 相关文章:与当前文章有关或相似的其他新闻。
如何构建新闻抓取工具
在构建自动从新闻文章中提取数据的解决方案时,主要有两种方法:
- 使用 AI 提取数据
- 构建自定义抓取脚本
我们一起了解一下这两种方法并探讨它们的优缺点。详细的实施步骤参见本指南下文。
使用 AI
这种方法背后的思路是将新闻文章的 HTML 内容提供给 AI 模型以提取数据。或者,您可以向 LLM(大型语言模型)提供商提供新闻文章网址,让他们提取关键信息,例如标题和主要内容。
👍 优点:
- 适用于几乎所有新闻网站
- 自动执行整个数据提取过程
- 可以保留格式,例如原始缩进、标题结构、粗体和其他格式元素
👎 缺点:
- 高级 AI 模型属于专有产品,可能很昂贵
- 您无法完全控制抓取过程
- 结果可能包含“幻觉”(不准确或捏造的信息)
使用自定义抓取脚本
使用自定义抓取脚本的目标在于手动编码构建针对特定新闻来源网站的抓取机器人。这些脚本连接到目标网站,解析新闻页面的 HTML,并从中提取数据。
👍 优点:
- 您可以完全控制数据提取过程
- 可以量身定制以满足特定要求
- 不依赖第三方提供商,性价比高
👎 缺点:
- 需要技术知识来设计和维护
- 每个新闻网站都需要自己的专属抓取脚本
- 处理边缘案例(例如直播文章)可能比较困难
方法 1:使用 AI 抓取新闻
此方法的思路是让 AI 来为您处理繁重任务。为此可以直接使用高级 LLM 工具(例如具有爬取功能的最新版 ChatGPT)来完成,也可以将 AI 模型集成到您的脚本中。在后一种情况下,您也需要具备技术知识和基本脚本编写能力。
以下是 AI 支持的新闻抓取过程中通常涉及的步骤:
- 收集数据:使用 HTTP 客户端检索目标页面的 HTML。如果您使用是的具有爬取功能的 ChatGPT 等工具,则此步骤将自动执行,您只需提供新闻网址即可。
- 预处理数据:如果使用 HTML,请先清理内容,然后再将提供给 AI。其中可能涉及删除不必要的脚本、广告或样式。重点关注页面中有意义的部分,例如标题、作者姓名和文章正文。
- 向 AI 模型发送数据:对于具有浏览功能的 ChatGPT 等工具,只需提供文章的网址和精心撰写的提示词即可。AI 将分析页面并返回结构化数据。或者,将清理过的 HTML 内容提供给 AI 模型,并提供提取内容相关的具体指示。
- 处理 AI 输出:AI 的响应通常是非结构化或半结构化的。使用您的脚本处理输出并将其设置为所需的格式。
- 导出抓取的数据:以您的首选格式保存结构化数据,无论是数据库、CSV 文件还是其他存储解决方案。
如需了解更多信息,请阅读如何使用 AI 抓取网页这篇文章。
方法 2:构建新闻抓取脚本
想要手动构建新闻抓取工具,必须先熟悉目标网站。检查新闻页面,了解页面结构、可以抓取的数据以及使用的抓取工具。
如果是简单的新闻网站,下列组合应该就已足够:
- Requests:用于发送 HTTP 请求的 Python 库。它让您可以检索网页的原始 HTML 内容。
- Beautiful Soup:用于解析 HTML 和 XML 文件的 Python 库。它有助于在网页的 HTML 结构中导航并提取数据。请参阅 Beautiful Soup 抓取指南,了解更多信息。
您可以通过以下命令将其安装在 Python 中:
pip install requests beautifulsoup4
对于使用了反机器人技术或需要执行 JavaScript 的新闻网站,您必须使用浏览器自动化工具,例如 Selenium。如需更多指导,请参阅我们的 Selenium 抓取指南。
您可以通过以下命令在 Python 中安装 Selenium:
pip install selenium
此时流程如下:
- 连接到目标网站:检索页面的 HTML 并将其解析。
- 选择相关元素:识别页面上的特定元素(例如标题、内容)。
- 提取数据:从这些元素中提取所需的信息。
- 清洗抓取的数据:必要时处理数据以删除任何不必要的内容。
- 导出抓取的新闻文章数据:将数据保存为您的首选格式,例如 JSON 或 CSV。
以下章节将介绍使用 Python 新闻抓取脚本从 CNN、路透社和 BBC 提取数据的示例!
CNN 抓取
目标新闻文章:“北极寒流将于感恩节周末抵达,潮湿阴雨将笼罩寒冷的东北地区”
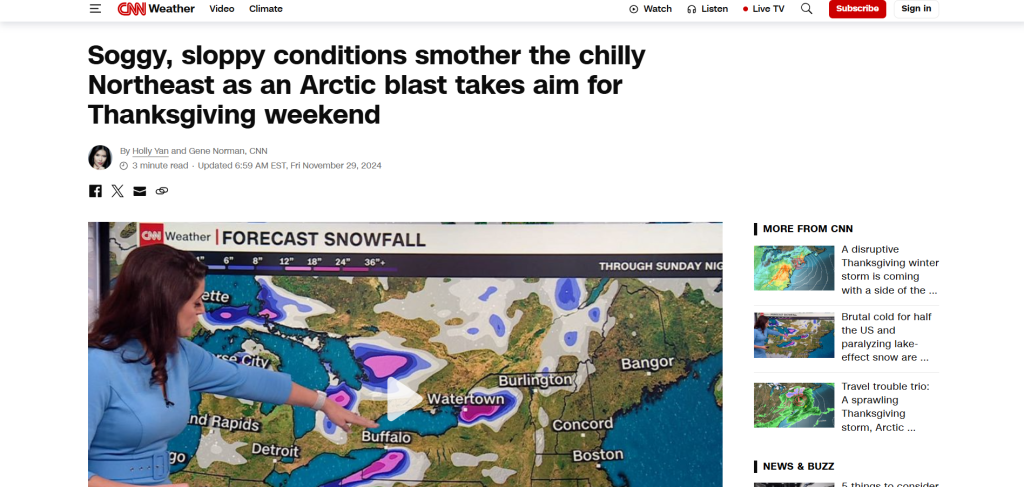
CNN 没有实施特定的防抓取措施。因此,使用 Requests 和 Beautiful Soup 的简单脚本就已足够:
import requests
from bs4 import BeautifulSoup
import json
# URL of the CNN article
url = "https://www.cnn.com/2024/11/28/weather/thanksgiving-weekend-weather-arctic-storm/index.html"
# Send an HTTP GET request to the article page
response = requests.get(url)
# Parse the HTML content of the page
soup = BeautifulSoup(response.content, "html.parser")
# Extract the title
title_element = soup.select_one("h1")
title = title_element.get_text(strip=True)
# Extract the article content
article_content = soup.select_one(".article__content")
content = article_content.get_text(strip=True)
# Prepare the data to be exported as JSON
article = {
"title": title,
"content": content
}
# Export data to a JSON file
with open("article.json", "w", encoding="utf-8") as json_file:
json.dump(article, json_file, ensure_ascii=False, indent=4)
运行脚本,它会生成一个 JSON 文件,内容为:
{
"title": "Soggy, sloppy conditions smother the chilly Northeast as an Arctic blast takes aim for Thanksgiving weekend",
"content": "CNN—After the Northeast was hammered by frigid rain or snow on Thanksgiving, a bitter blast of Arctic air is set to envelop much of the country by the time travelers head home this weekend. ... (omitted for brevity)"
}
哇!您刚刚抓取了 CNN 文章。
路透社抓取
目标新闻文章:“马克龙称赞修复巴黎圣母院的工匠”
请记住,路透社实施了一个特别的反机器人解决方案,可以屏蔽不是从浏览器发出的请求。如果您尝试使用 Requests 或任何其他 Python HTTP 客户端发出自动请求,您将看到以下错误页面:
<html><head><title>reuters.com</title><style>#cmsg{animation: A 1.5s;}@keyframes A{0%{opacity:0;}99%{opacity:0;}100%{opacity:1;}}</style></head><body style="margin:0"><p id="cmsg">Please enable JS and disable any ad blocker</p><script data-cfasync="false">var dd={'rt':'c','cid':'AHrlqAAAAAMAjfxsASop65YALVAczg==','hsh':'2013457ADA70C67D6A4123E0A76873','t':'fe','s':46743,'e':'da7ef98f4db57c2e85c7ae9df5bf374e4b214a77c73ee80d700757e60962367f','host':'geo.captcha-delivery.com','cookie':'lperXjdnamczWV5K~_ghwm4FDVstzxj76zglHEWJSBJjos3qpM2P8Ir0eNn5g9yh159oMTwy9UaWuWgflgV51uAJZKzO7JJuLN~xg2wken37VUTvL6GvZyl89SNuHrSF'}</script><script data-cfasync="false" src="https://ct.captcha-delivery.com/c.js"></script></body></html>
因此,您必须使用 Selenium 等浏览器自动化工具来抓取路透社的新闻文章。方法如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.chrome.options import Options
import json
# Initialize the WebDriver
driver = webdriver.Chrome(service=Service())
# URL of the Reuters article
url = "https://www.reuters.com/world/europe/excitement-relief-paris-notre-dame-cathedral-prepares-reopen-2024-11-29/"
# Open the URL in the browser
driver.get(url)
# Extract the title from the <h1> tag
title_element = driver.find_element(By.CSS_SELECTOR, "h1")
title = title_element.text
# Select all text elements
paragraph_elements = driver.find_elements(By.CSS_SELECTOR, "[data-testid^="paragraph-"]")
# Aggregate their text
content = " ".join(p.text for p in paragraph_elements)
# Prepare the data to be exported as JSON
article = {
"title": title,
"content": content
}
# Export data to a JSON file
with open("article.json", "w", encoding="utf-8") as json_file:
json.dump(article, json_file, ensure_ascii=False, indent=4)
如果您启动上述脚本并且没有被屏蔽,则会输出以下 article.json 文件:
{
"title": "Macron lauds artisans for restoring Notre-Dame Cathedral in Paris",
"content": "PARIS, Nov 29 (Reuters) - French President Emmanuel Macron praised on Friday the more than 1,000 craftspeople who helped rebuild Paris' Notre-Dame Cathedral in what he called "the project of the century", ... (omitted for brevity)"
}
太棒了!您刚刚抓取了路透社的文章。
BBC 抓取
目标新闻文章:“黑色星期五:如何发现真正的优惠且避免被骗”
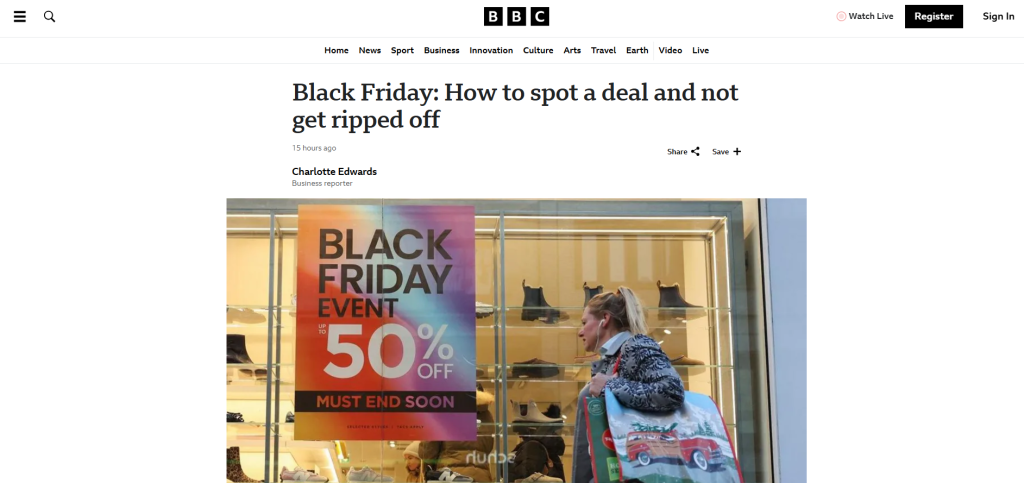
正如 CNN 一样,BBC 没有实施特定的反机器人解决方案。因此,使用 HTTP 客户端和 HTML 解析器这对组合的简单抓取脚本就已足够:
import requests
from bs4 import BeautifulSoup
import json
# URL of the BBC article
url = "https://www.bbc.com/news/articles/cvg70jr949po"
# Send an HTTP GET request to the article page
response = requests.get(url)
# Parse the HTML content of the page
soup = BeautifulSoup(response.content, "html.parser")
# Extract the title
title_element = soup.select_one("h1")
title = title_element.get_text(strip=True)
# Extract the article content
article_content_elements = soup.select("[data-component="text-block"], [data-component="subheadline-block"]")
# Aggregate their text
content = "n".join(ace.text for ace in article_content_elements)
# Prepare the data to be exported as JSON
article = {
"title": title,
"content": content
}
# Export data to a JSON file
with open("article.json", "w", encoding="utf-8") as json_file:
json.dump(article, json_file, ensure_ascii=False, indent=4)
执行此脚本,它将生成这个 article.json 文件:
{
"title": "Black Friday: How to spot a deal and not get ripped off",
"content": "The Black Friday sales are already in full swing and it can be easy to get swept up in the shopping frenzy and end up out of pocket - instead of bagging a bargain... (omitted for brevity)"
}
太棒了!您刚刚抓取了 BBC 的文章。
新闻抓取的挑战以及其克服方法
在上述示例中,我们以几个新闻网站为目标,仅从其中的文章里提取标题和主要内容。这样的简单操作让新闻抓取看起来很容易。实际上,新闻抓取比这复杂得多,因为大多数新闻网站都会主动检测和屏蔽机器人:
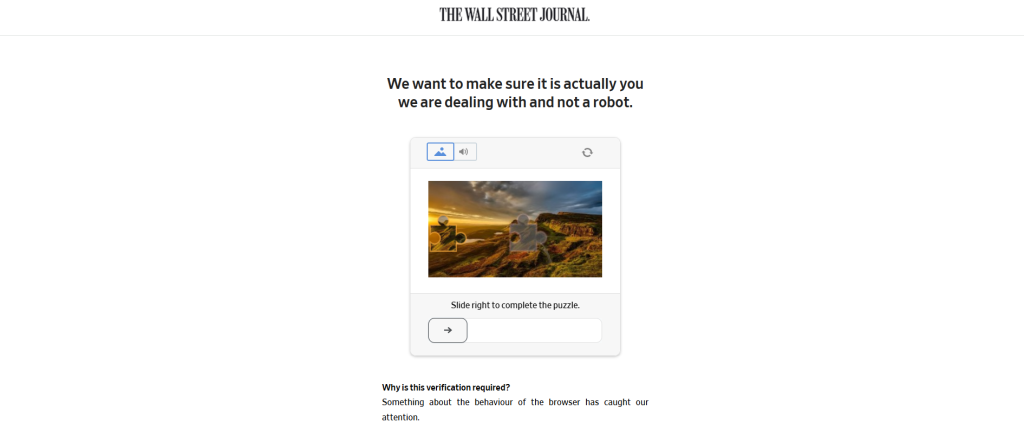
您需要考虑的部分挑战包括:
- 确保抓取的文章保持恰当的标题结构
- 除了标题和主要内容外,还要抓取标签、作者和发布日期等元数据
- 自动执行抓取过程,以高效处理不同网站上的多篇文章
想要解决这些挑战,您可以:
- 学习高级技巧:查看我们的使用 Python 避开验证码指南,并阅读抓取教程了解实用技巧。
- 使用高级自动化工具:使用 Playwright Stealth 等强大工具抓取实施了反机器人机制的网站。
但是最好的解决方案还是使用专门的新闻抓取工具 API。
Bright Data 的新闻抓取器 API 为抓取 BBC、CNN、路透社和 Google News 等热门新闻来源提供了多合一的高效解决方案。使用此 API,您可以:
- 提取结构化数据,例如 ID、网址、标题、作者、主题等等
- 扩展您的抓取项目,无需担心基础架构、代理服务器或网站屏蔽
- 不用担心屏蔽和中断
简化您的新闻抓取流程,专注于重要的事情——分析数据!
结论
在这篇文章中,您了解了什么是新闻抓取工具以及它可以从新闻文章中检索的数据类型。您也学习了如何使用基于 AI 的解决方案或人工脚本来构建新闻抓取工具。
无论您的新闻抓取脚本多么复杂,大多数网站仍然可以检测到自动化活动并阻止您访问。解决这一挑战的方法是使用专门的新闻抓取工具 API,以便从各种平台可靠地提取新闻数据。
这些 API 提供结构化的全面数据,针对每个新闻来源量身定制:
- CNN 抓取工具 API:提取标题、作者、主题、发布日期、内容、图片、相关文章等数据。
- Google News 抓取工具 API:收集标题、主题、类别、作者、发布日期、来源等信息。
- 路透社抓取工具 API:检索 ID、网址、作者、标题、主题、发布日期等数据。
- BBC 抓取工具 API:收集标题、作者、主题、发布日期、内容、图片、相关文章等详细信息。
如果您不喜欢构建抓取工具,不妨考虑一下我们的即用型新闻数据集。这些数据集是预先编制的,包含全面的记录:
- BBC 新闻:涵盖所有主要数据点而且包含数万条记录的数据集。
- CNN 新闻:包含所有关键数据点和数十万条记录的数据集。
- Google News:涵盖所有关键数据点而且包含数万条记录的数据集。
- 路透社新闻:涵盖所有主要数据点而且包含数十万条记录的数据集。
浏览我们所有的记者专用数据集。
立即创建免费的 Bright Data 账户,试用我们的抓取工具 API 或了解我们的数据集。



技术写作
 5.5 years experience
5.5 years experience
Antonello是一名软件工程师,但他更喜欢称自己为技术传教士。通过写作传播知识是他的使命。