

在本文中,你将学习:
- 什么是亚马逊价格追踪器,以及它为什么有用
- 如何通过 Python 的分步教程来构建一个价格追踪器
- 这种方法的局限性以及如何克服这些局限
让我们开始吧!
什么是亚马逊价格追踪器?
亚马逊价格追踪器是一种工具、服务或脚本,用于在一段时间内监控一个或多个亚马逊产品的价格。它可以定期提供价格变化的更新,帮助你发现价格下调、折扣或波动。
为什么要追踪亚马逊商品价格?
追踪亚马逊价格可以帮助你:
- 在商品处于最低价格时购买,从而省钱
- 在促销或折扣期间把握购买时机
- 如果你是卖家,可以用来设置有竞争力的商品定价
此外,追踪亚马逊价格对于监控季节性趋势和了解市场动态也至关重要。
创建亚马逊价格追踪器:分步指南
在本教学部分,你将学习如何使用 Python 构建一个亚马逊价格追踪器。只需按照以下步骤操作,即可 创建一个爬虫机器人,它可以:
- 连接到指定产品的亚马逊页面
- 从这些页面采集价格数据
- 随着时间推移追踪价格变化
如果你对采集其他数据也感兴趣,可以参考我们的 如何爬取亚马逊产品数据的指南。
现在就来实现一个亚马逊价格追踪脚本吧!
步骤 #1:项目设置
在开始之前,请确保你的电脑上已安装 Python 3+。如果没有, 从官网安装并按照安装说明操作。
然后,使用以下命令为你的亚马逊价格追踪项目创建一个目录:
mkdir amazon-price-tracker进入该目录,并在其中 创建一个虚拟环境:
cd amazon-price-tracker
python -m venv venv在你喜欢的 Python IDE 中打开这个项目文件夹。 安装了 Python 插件的 Visual Studio Code或 PyCharm Community Edition都是不错的选择。
在项目文件夹中创建一个scraper.py文件,此时项目文件夹结构应如下所示:
scraper.py将包含亚马逊价格追踪的所有逻辑。
在你的 IDE 终端中,激活虚拟环境。Linux 或 macOS 上可以使用:
./venv/bin/activateWindows 上等效的命令是:
venv/Scripts/activate很好!环境已经搭建完毕,可以开始了。
步骤 #2:配置爬取库
从我们 爬取电商网站的指南中可知,爬取亚马逊需要使用浏览器自动化工具。这不是因为该站点非常动态,而是因为亚马逊使用了反爬虫措施来检测并阻止自动化请求。
简单来说,你需要一个类似 Selenium的浏览器自动化工具来从亚马逊获取数据。首先,通过以下命令安装 Selenium:
pip install selenium如果你对这个库不太熟悉,可以参考我们关于 Selenium 爬取网页的教程。
在 scraper.py 脚本中导入 Selenium:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service接着,创建一个ChromeDriver对象来控制 Chrome 浏览器实例:
# Initialize the WebDriver to control Chrome
driver = webdriver.Chrome(service=Service())
# Scraping logic...
# Release the driver resources
driver.quit()driver将被用于与想要进行价格追踪的亚马逊商品页面进行交互。
记住,亚马逊会采用 反爬虫措施,可能会封锁无头浏览器。为了避免问题, 最好让 Selenium 控制的浏览器保持有头模式。
很好!现在可以开始自动化亚马逊爬取逻辑了。
步骤 #3:连接到目标页面
假设你想追踪亚马逊上 PS5 的价格:
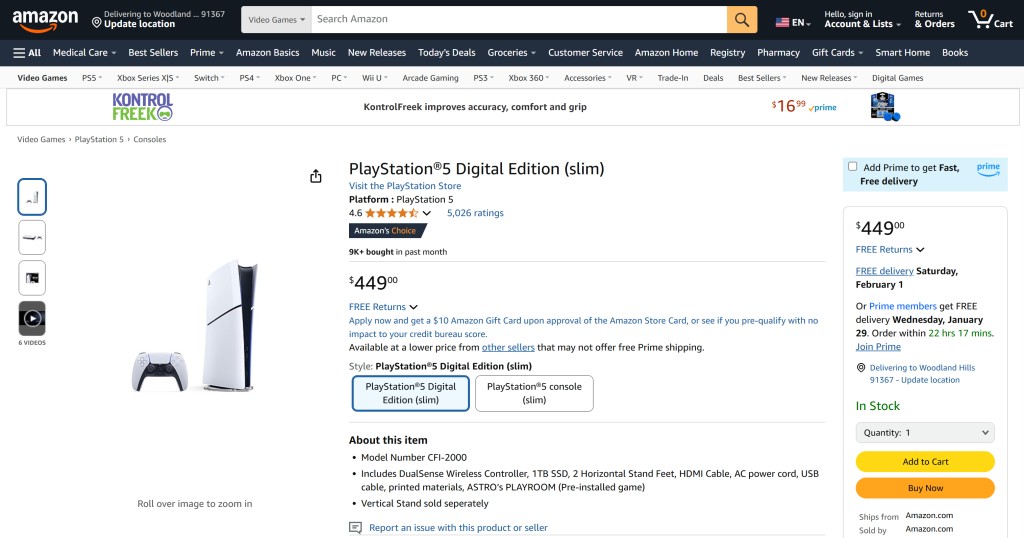
以下是这个商品页面的 URL:
https://www.amazon.com/PlayStation%C2%AE5-Digital-slim-PlayStation-5/dp/B0CL5KNB9M//amazon.com后面的部分只是为了可读性,但其中在/dp/之后的那段代码非常重要,这是 亚马逊 ASIN(亚马逊商品唯一标识符)。
换句话说,你可以直接使用 ASIN 按如下格式访问同样的商品页面:
https://www.amazon.com/product/dp/<AMAZON_ASIN>在这个示例里,PS5 的 ASIN 是B0CL5KNB9M。把这个 ASIN 存储到一个变量里,然后通过它来生成亚马逊商品页面 URL:
amazon_asin = "B0CL5KNB9M"
amazon_url = f"https://www.amazon.com/product/dp/{amazon_asin}"接着,使用 Selenium 的get()方法让浏览器前往此 URL:
driver.get(amazon_url)在driver.quit()之前设置一个断点,然后运行脚本。此时,你应该可以看到浏览器中打开了亚马逊商品页面:
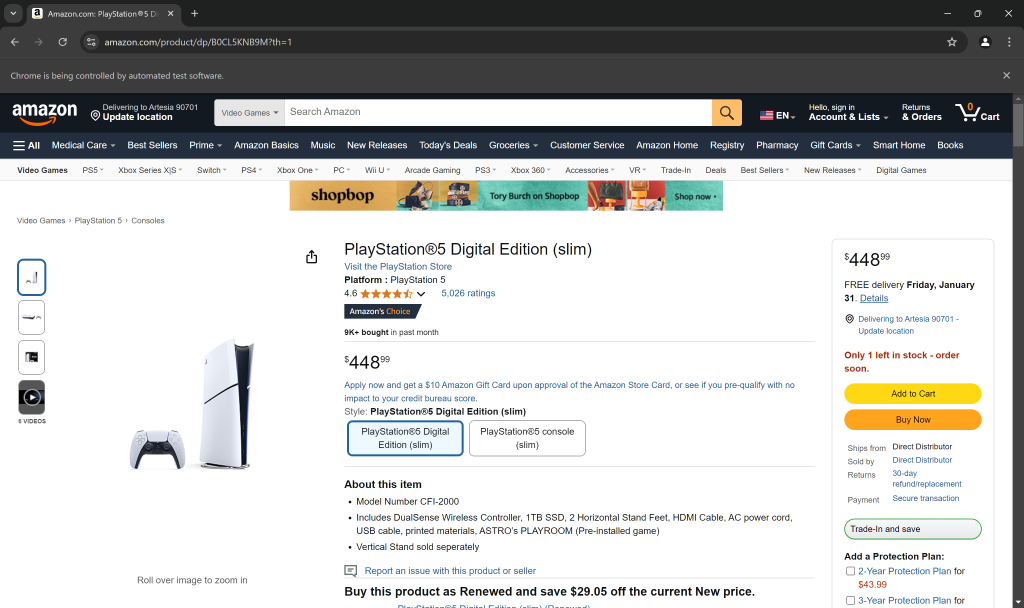
“Chrome 正在被自动测试软件控制”的提示说明 Selenium 正在按照预期对浏览器进行操作。
请注意,亚马逊使用了反爬虫措施, 可能会导致你遇到验证码验证或被封锁的情形。不用担心,稍后我们会在本文的后面讨论如何应对这些问题。
如果你想了解 Bright Data 提供的亚马逊 ASIN Scraper,可以 点击这里。
步骤 #4:爬取价格信息
在浏览器的隐身模式下打开目标商品页面。然后,右键点击页面上显示的价格,并选择“Inspect(检查)”选项:
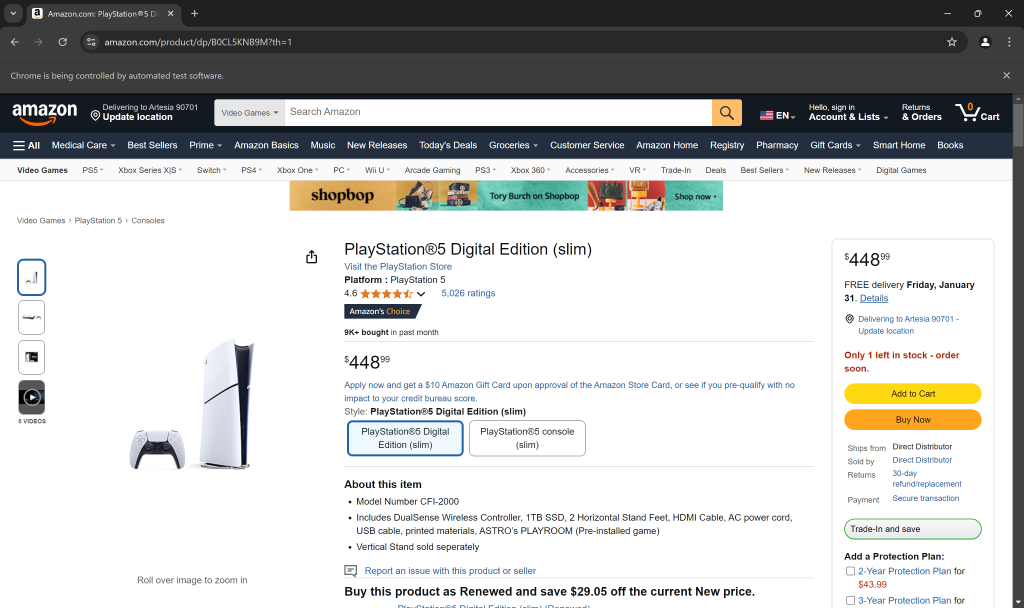
在 DevTools 中查看价格元素的 HTML,可以看到价格位于.a-price元素内。
可以使用 CSS 选择器来获取该元素,然后提取数据:
price_element = driver.find_element(By.CLASS_NAME, "a-price")
price = price_element.text.replace("\n", ".")这里用 replace() 函数把价格中的换行符替换成了“.”。
别忘了导入By:
from selenium.webdriver.common.by import By太好了!至此,你已经成功实现了亚马逊价格追踪脚本中最关键的功能——价格爬取。
步骤 #5:存储价格信息
亚马逊价格追踪器的核心功能是保存历史价格,这样你就可以评估价格变化的趋势。要实现这一点,需要把价格数据存储到某个地方,比如数据库或文件。
为了简单,我们这里用 JSON 文件来当数据库。该文件将存储商品的 ASIN 以及它的历史价格列表。
首先,确保 JSON 文件存在,并且结构如下:
{
"asin": "<AMAZON_ASIN>",
"prices": []
}在 Python 中,如果文件不存在,可以按如下方式初始化:
# JSON db file name and initial data
file_name = "price_history.json"
initial_data = {
"asin": amazon_asin,
"prices": []
}
# Write the JSON db file if it does not exist
if not os.path.exists(file_name):
with open(file_name, "w") as file:
json.dump(initial_data, file, indent=4)
# Selenium logic...以上内容需要先导入:
import os
import json在爬取逻辑开始之前,先加载该 JSON 文件获取它目前已有的数据:
# Open the JSON file for reading and writing
with open(file_name, "r+") as file:
# Load the current price data
price_data = json.load(file)
# Scraping logic...在完成价格爬取后,把新的价格和时间戳追加到prices列表中:
price = price_element.text.replace("\n", "")
# Current timestamp
timestamp = datetime.now().isoformat()
# Add a new price info point
price_data["prices"].append({
"price": price,
"timestamp": timestamp
})这里需要先导入:
from datetime import datetime最后,更新 JSON 文件:
# Move the file pointer to the beginning
file.seek(0)
# Override the scraped data
json.dump(price_data, file, indent=4)
# Truncate the file so if new content is shorter than the original, the extra data would be cleared
file.truncate()太好了!这样一来,把价格写回了存储文件,价格追踪的逻辑就算实现了。
步骤 #6:定时运行价格追踪脚本
目前,每次想追踪并保存亚马逊价格都需要手动运行脚本。对于偶尔使用来说也许够用,但如果你想更高效地持续追踪,可以让它定时在后台自动运行。
可使用 Python 的 schedule 库来定时运行任务。这个库提供了更直观的任务调度 API。
在虚拟环境里安装该库:
pip install schedule然后,把你的亚马逊价格追踪逻辑整个封装到一个函数里,并通过参数来接收 ASIN:
def track_price(amazon_asin):
# Entire Amazon price tracking logic...现在你就可以让它立即运行一次,然后每 12 小时运行一次:
# Run immediately
amazon_asin="B0CL5KNB9M"
track_price(amazon_asin)
# Then, schedule the job to run every 12 hours
schedule.every(12).hours.do(track_price, amazon_asin=amazon_asin)
while True:
schedule.run_pending()
time.sleep(1)这里的while循环保证脚本持续运行,用于执行定时任务。
记得导入:
import schedule
import time搞定!现在你的脚本完全自动化了,成为一个免人工干预的亚马逊价格追踪器。
步骤 #7:整合所有步骤
下面是你的 Python 亚马逊价格追踪脚本的完整示例:
from selenium import webdriver
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import json
import os
from datetime import datetime
import schedule
import time
def track_price(amazon_asin):
# Initialize the WebDriver to control Chrome
driver = webdriver.Chrome(service=Service())
# Amazon product URL generation
amazon_url = f"https://www.amazon.com/product/dp/{amazon_asin}"
# JSON db file name and initial data
file_name = "price_history.json"
initial_data = {
"asin": amazon_asin,
"prices": []
}
# Write the JSON db file if it does not exist
if not os.path.exists(file_name):
with open(file_name, "w") as file:
json.dump(initial_data, file, indent=4)
# Open the JSON file for reading and writing
with open(file_name, "r+") as file:
# Load the current price data
price_data = json.load(file)
# Navigate to the target page
driver.get(amazon_url)
# Scrape the price
price_element = driver.find_element(By.CSS_SELECTOR, ".a-price")
price = price_element.text.replace("\n", ".")
# Current timestamp
timestamp = datetime.now().isoformat()
# Add a new price info point
price_data["prices"].append({
"price": price,
"timestamp": timestamp
})
# Move the file pointer to the beginning
file.seek(0)
# Override the scraped data
json.dump(price_data, file, indent=4)
# Truncate the file so if new content is shorter than the original, the extra data would be cleared
file.truncate()
# Release the driver resources
driver.quit()
# Run immediately
amazon_asin="B0CL5KNB9M"
track_price(amazon_asin)
# Then, schedule the job to run every 12 hours
schedule.every(12).hours.do(track_price, amazon_asin=amazon_asin)
while True:
schedule.run_pending()
time.sleep(1)使用以下命令运行:
python3 scraper.py或者在 Windows 上:
python scraper.py让脚本运行数小时后,它会生成一个类似这样的price_history.json文件:
{
"asin": "B0CL5KNB9M",
"prices": [
{
"price": "$449.00",
"timestamp": "2025-01-27T08:02:20.333369"
},
{
"price": "$449.00",
"timestamp": "2025-01-27T20:02:20.935339"
},
{
"price": "$449.00",
"timestamp": "2025-01-28T08:02:21.109284"
},
{
"price": "$449.00",
"timestamp": "2025-01-28T20:02:21.385681"
},
{
"price": "$449.00",
"timestamp": "2025-01-29T08:02:22.123612"
}
]
}可以看到,每条记录之间正好相差 12 小时。
完成!
步骤 #8:下一步
你已经构建了一个功能正常的亚马逊价格追踪器,但若想进一步升级,还可以做很多改进:
- 添加日志:像所有无人值守进程一样,日志能帮你了解脚本都做了什么。因此你可以添加一些日志来记录脚本行为。
- 使用数据库:用数据库替换 JSON 文件来保存数据。在多台设备或应用访问时会更容易实现数据共享和访问。
- 实现错误处理:为反爬虫措施、网络超时、意外失败等情况加上健壮的错误处理。确保脚本能在出错时自动重试或安全跳过。
- 从命令行读取参数:让脚本能从命令行接受输入,比如 ASIN 和定时选项。这样灵活性更高。
- 通知系统:集成电子邮件或即时通讯应用提醒,当价格出现重大变化时,能够第一时间通知你。
这种方法的局限性及如何克服
上一章节中构建的亚马逊价格追踪脚本只是一个基础示例。如果你打算长期使用,需要添加一些改进措施。但这通常意味着更多的开发工作和更复杂的维护。
而且,无论脚本多么高级,亚马逊依然能够用验证码等手段进行拦截:
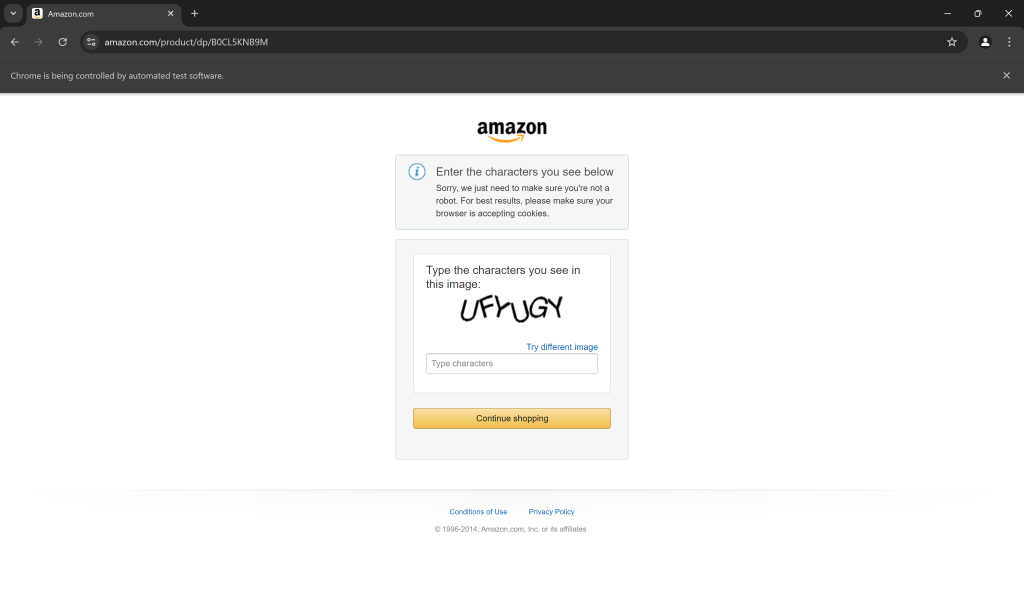
事实上,现在用 Selenium 爬取亚马逊就有很大概率会被 CAPTCHA 阻拦。第一步,可以参考我们的 如何在 Python 中绕过验证码的指南进行处理。
即便如此,你依然有可能因访问频率过高而遇到429 Too Many Requests错误。这种情况下, 在 Selenium 中集成代理以轮换出口 IP 是一种不错的选择。
这些挑战突显了在没有合适工具的情况下,爬取像亚马逊这样的网站会多么麻烦。并且使用浏览器自动化工具难免会让脚本速度变慢,也更消耗资源。
那是不是就此作罢?当然不!实际上,想要轻松解决这些问题,可以使用类似 Bright Insights这样的服务。Bright Insights 能提供可执行的、基于人工智能的电商洞察,为你:
- 挽回收入损失:发现并解决因商品下架、库存不足或曝光不足等造成的收入损失。
- 追踪销量及市场份额:快速识别空白机会,跟踪竞争对手销量,并提前发现市场趋势。
- 优化定价:实时监控竞争对手定价,及时进行定价调整。
- 最大化零售媒体表现:利用数据分析来优化广告投放,使投资回报率最大化,实现持续增长。
- 优化产品组合:通过追踪竞争对手动态来完善产品组合,并获得最大收益。
- 多渠道优化:整合多渠道情报,全方位管理商品销量,并在各平台上取胜。
Bright Insights 提供了电商所需的全部数据,其中也包括亚马逊价格追踪功能。
结论
在本文中,你了解了亚马逊价格追踪器是什么,它能带来哪些好处,以及如何使用 Python 和 Selenium 来构建一个价格追踪脚本。
最大的挑战在于亚马逊对自动化脚本实施的严格反爬虫措施,比如验证码、浏览器指纹识别以及 IP 封锁。但使用 我们的亚马逊价格追踪器,你可以不必再为这些难题操心,轻松获取亚马逊价格数据。
如果你对数据采集更感兴趣,也可以考虑我们的 亚马逊数据采集 API!
快去注册一个免费的 Bright Data 账户,探索我们的服务吧。


