

向量数据库可以存储和索引由机器学习模型生成的高维数据嵌入。它们是现代 AI 的基石,支持对上下文信息的存储以及有意义的语义搜索。
尽管人们常常将它们与检索增强型生成(RAG)联系在一起,但它们的应用范围远不止如此。具体而言,向量数据库为语义搜索、推荐系统、异常检测以及更多场景提供了支持。
请阅读本指南,深入了解向量数据库是什么、它们如何工作、如何在完整示例中使用它们,以及它们的未来发展方向!
什么是向量数据库?
向量数据库是专门用于存储向量数据的存储系统。在本文的上下文中,向量指的是一个数值嵌入,可以表示诸如文本、图像或音频等非结构化数据,通常由机器学习模型生成。
与传统数据库不同,向量数据库可以将高维数据存储为稠密的数值向量,并在 N 维空间中对其进行索引,以支持针对相似度的优化检索。
向量数据库在 AI/ML 中日益重要的原因
在大多数情况下,传统的 SQL 数据库并不适用于 AI 和机器学习任务。原因在于它们只能存储结构化数据,并且只支持精确匹配查询或有限的相似度搜索。因此,对于非结构化内容以及捕捉数据点之间的语义关系,它们往往无能为力。
如今,AI 应用需要对数据进行上下文理解。这可以通过 embeddings 来实现——但关系型数据库并不适合存储或查询此类 embeddings。向量数据库通过支持基于相似度的搜索来反映含义和上下文,从而克服了这些限制,为数据的语义理解打开了大门。
虽然最常见的场景是检索增强型生成 (RAG),但该技术还有其他潜在用例:
- 语义搜索引擎
- 推荐系统
- 时间序列数据中的异常检测
- 在计算机视觉中进行图像分类和搜索
- 自然语言处理(NLP)应用
向量数据库的工作原理
向量数据库以向量嵌入的形式管理数据,而这些向量存在于一个高维空间中。每个维度代表数据的一个特征,对应于由 ML 模型解释的原始数据(嵌入表示)中的某个特性。嵌入的维度越高,表示的细节就越丰富,从而可以更加深入地理解数据结构。
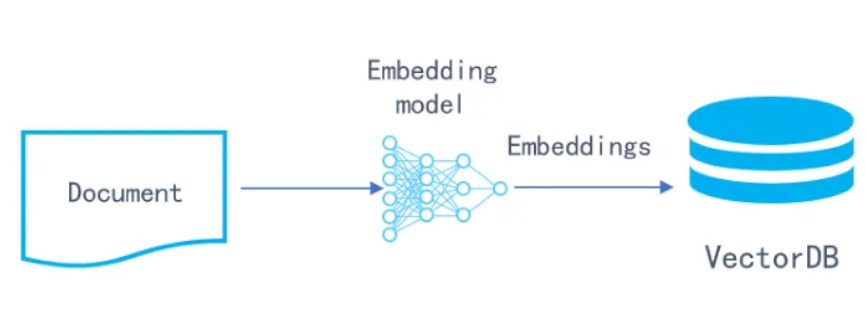
为了查找语义上相似的数据,向量数据库会使用如下相似度度量方法:
- 余弦相似度:测量两个向量之间夹角的余弦值,以评估它们方向上的相似程度。这在处理文本数据时最常使用。
- 欧几里得距离:测量两个向量之间的直线距离,适用于同时关注方向和幅度的空间数据。
- 点积相似度:计算对应向量分量的乘积,值越大则相似度越高。这在推荐系统和排序任务中很有用。
就像 SQL 和 NoSQL 数据库会使用索引来加速数据查询一样,向量数据库也会使用一些高级索引技术,例如:
- 近似最近邻(ANN):通过近似最邻近向量来加快相似度搜索,相比于精确搜索可降低计算成本。
- HNSW(Hierarchical Navigable Small World):将向量表示成图结构,以便在大型高维空间中更快地进行检索。
此外,还可以使用分区和聚类技术将向量数据组织成更小、更易管理的分组,从而提升存储效率和检索性能。
常见的向量数据库选项
现在您已经了解了向量数据库是什么以及它们的 AI 数据基础架构是如何工作的,接下来可以探索最受欢迎的向量数据库选项。我们将从以下几个方面对每个知识库进行分析:
- 架构
- 性能特点
- 集成能力
- 定价模式
- 最佳使用场景
如果您迫不及待想知道哪些向量数据库表现出色,可以先查看下方的总结表:
| Database Name | Open Source/Commercial | Hosting Options | Best For | Peculiar Aspects | Integration Complexity |
|---|---|---|---|---|---|
| Pinecone | Commercial | Fully managed serverless cloud | Semantic search, Q&A, chatbots | Parallel reads/writes, seamless OpenAI/Vercel integration, long-term memory support | Low – SDKs for many languages, plug-and-play integrations |
| Weaviate | Open source & commercial | Self-hosted, serverless cloud, managed enterprise cloud | Media/text search, classification, facial recognition | HNSW + flat vector indexing, inverted indexes, rich ecosystem integration | Medium – Broad integration surface, some learning curve |
| Milvus | Open source & commercial | Self-hosted, Zilliz Cloud | RAG, recommendation, media search, anomaly detection | Data sharding, streaming ingestion, multi-modal data indexing | Medium – Many SDKs, works with major AI/LLM frameworks |
| Chroma | Open source & commercial | Self-hosted, Chroma Cloud | Lightweight apps, CV search, AI chatbots | In-memory mode, REST APIs via Swagger, rich embedding integrations | Low – Python & TypeScript SDKs, built for ease of use |
| Qdrant | Open source & commercial | Self-hosted, managed cloud, hybrid cloud, private cloud | RAG, advanced search, analytics, AI agents | Modular payload/vector indexing, HNSW, fine-grained updates | Medium – Broad API/client support, scalable and modular |
接下来让我们更深入地了解这些精选的向量数据库!
Pinecone
- 架构:无服务器的全托管方案
- 性能特点:
- 高性能的 ANN 搜索
- 企业级可扩展性
- 并行读写
- 集成能力:
- REST API
- 多种 SDK(Python、Node.js、Java、Go、.NET、Rust)
- 与 OpenAI、Vercel、AWS、LangChain 等原生集成
- 定价模式:
- Starter:用于尝试和小规模应用(免费)
- Standard:面向任何规模的生产应用(起价 25 美元/月)
- Enterprise:适用于关键任务的生产级应用(起价 500 美元/月)
- 最佳使用场景:
- 语义搜索
- 具有长期记忆的生成式问答
- 聊天机器人
Weaviate
- 架构:模块化、云原生
- 性能特点:
- HNSW 索引
- 平面向量索引
- 传统的 倒排索引
- 集成能力:
- Python、Java 和 Go 客户端
- 与 AWS、Google 等云服务商集成
- 与 Modal、Replicate 等计算基础设施集成
- 与 Airbyte、Databricks、Firecrawl、IBM 等数据平台集成
- 与 CrewAI、LangChain、LlamaIndex、Semantic Kernel 等 LLM 和代理框架集成
- 与 DeepEval、LangWatch 等运维工具集成
- 定价模式:
- 由于其开源性质,自行部署免费
- Serverless Cloud:无服务器 SaaS 部署(起价 25 美元/月)
- Enterprise Cloud:在专用实例中全托管(价格从 2.64 美元/AI 单位起)
- 最佳使用场景:
- 图书/电影推荐系统
- 播客/视频字幕/文本搜索
- 人脸识别
- 音频类型分类
Milvus
- 架构:存储与计算分离的共享存储架构,可水平扩展
- 性能特点:
- 基于 ANN 的向量索引
- 支持数据分片
- 流式数据摄取
- 支持针对
VARCHAR、INT、FLOAT和DOUBLE等数据类型的可扩展倒排索引
- 集成能力:
- Python、Java、Go 和 Node.js SDK
- LlamaIndex、LangChain、Hugging Face、Haystack、OpenAI agents、VoyageAI、Kafka,以及更多
- 定价模式:
- 由于其开源性质,自行部署免费
- Zilliz Cloud 上提供从免费到 99 美元/月的无服务器或专用数据库服务器方案
- 最佳使用场景:
- 检索增强型生成(RAG)
- 推荐系统
- 媒体与语义搜索
- 异常与欺诈检测
Chroma

- 架构:可用于小型应用的单节点服务器,也可在云端分布式部署以支持大型应用
- 性能特点:
- 内存级的本地简单存储
- 云端的全托管服务
- 集成能力:
- Python 与 TypeScript SDK
- 使用 Swagger 编写的 REST API
- OpenAI、Google Gemini、Cohere、Baseten、Hugging Face、Instructor、Hugging Face Embedding Server、Jina AI、Roboflow、Ollama Embeddings
- AWS、Azure、Google Cloud 等云服务商
- 定价模式:
- 由于其开源性质,自行部署免费
- Chroma Cloud:提供快速、可扩展且无服务器的向量、全文和元数据搜索
- Starter:快速上手(0 美元/月 + 用量成本)
- Team:扩展生产用例(250 美元/月 + 用量成本)
- Enterprise:适用于注重安全、扩展性、支持与可靠性的组织(定制定价)
- 最佳使用场景:
- 推荐系统
- 计算机视觉中的图像检索
- AI 驱动的聊天机器人
Qdrant
- 架构:可在本地自行托管,也可在云端分布式部署以支持大型多租户应用
- 性能特点:
- HNSW 索引
- 可配置的模块化索引,可独立索引向量与有效载荷
- ANN 搜索
- 针对更新和删除向量进行了优化
- 集成能力:
- REST API,gRPC API
- Python、JavaScript/TypeScript、Rust、Go、.NET、Java 客户端
- 定价模式:
- 由于其开源性质,自行部署免费
- Qdrant Cloud:面向企业的托管解决方案
- Managed Cloud:无需部署和维护即可扩展生产解决方案(起价 0 美元/GB)
- Hybrid Cloud:可将您在任何云服务商、本地基础设施或边缘位置的集群与托管云连接(起价 0.014 美元/小时)
- Private Cloud:将 Qdrant 完全部署在本地,以获得最大程度的控制和数据主权(定制定价)
- 最佳使用场景:
- RAG
- 推荐系统
- 高级搜索
- 数据分析和异常检测
- AI 代理
通过 Bright Data 为向量数据库提供数据支持
影响向量嵌入质量的两大因素是:
- 用于生成嵌入的机器学习模型。
- 输入到该模型中的数据质量。
这说明向量数据库流水线的能力取决于为其提供数据的质量。如果嵌入是由低质量、不完整或噪声数据产生,即使使用再好的 ML 模型和向量数据库,结果也会大打折扣。
因此,收集干净、丰富且全面的数据至关重要——这正是 Bright Data 所擅长的!
Bright Data 是一家领先的网页爬取和数据收集平台,可帮助您合规、高效地大规模采集高质量的网络数据。其 数据采集解决方案可以从数百个站点抓取结构化的实时数据,且这些解决方案可直接集成到自有的工作流程中,以增强您自定义爬虫脚本的性能。
这种 数据源获取 方法的关键优势在于,Bright Data 处理了所有相关工作:管理基础设施、处理 IP 轮换、绕过反爬措施、解析 HTML 数据,并确保合规性。
这些 网页爬取工具可让您直接从网页获取最新的结构化数据。鉴于网络是最大的数据源之一,访问网络数据可帮助生成具有丰富上下文信息的向量嵌入。这些嵌入随后可为多种 AI 和搜索应用提供支持,例如:
- 用于电商推荐的商品信息
- 新闻文章的语义和上下文搜索
- 社交媒体内容的趋势检测和分析
- 基于位置服务的商业场景
从原始数据到向量嵌入:转换过程
将原始数据转换为向量嵌入一般需要两个主要步骤:
- 数据预处理
- 嵌入生成
下面将对这两个步骤进行分解,帮助您了解各个环节的工作原理和重点。
步骤 1:数据预处理
原始数据通常包含噪声、冗余或无结构的内容。将其转换为嵌入之前,首先要对其进行清理和规范化,从而提升输入数据的质量与一致性。
例如,当 利用网页数据进行机器学习时,常见的预处理步骤包括:
- 解析原始 HTML 以提取结构化内容。
- 修剪空白字符并标准化数据格式(例如价格、日期和货币符号)。
- 将文本统一为小写,去除标点符号,并处理特殊 HTML 字符。
- 去重以避免重复信息。
步骤 2:嵌入生成
在对数据进行清洗和预处理后,可将其传入 ML 嵌入模型以生成稠密的数值向量。
所选的嵌入模型取决于输入数据的类型以及所需的输出质量。以下是一些常见方式:
- OpenAI 嵌入模型:可生成高质量的通用向量,语义理解能力极佳。
- Sentence Transformers:一个开源的 Python 框架,可用于生成先进的句子、文本和图像嵌入。可本地运行并支持大量预训练模型。
- 领域专用的嵌入模型:在金融报告、法律文档或生物医学文本等特定领域数据上进行微调,以在特定场景中提供高性能。
以下示例展示了如何使用 OpenAI 的嵌入模型来生成嵌入:
# requirement: pip install openai
from openai import OpenAI
client = OpenAI() # Reading the OpenAI key from the "OPENAI_API_KEY" env
# Sample input data (replace it with your input data)
input_data = """
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.
"""
# Use an OpenAI embedding model for embedding generation
response = client.embeddings.create(
model="text-embedding-3-large",
input=input_data
)
# Get the embedding and print it
embedding = response.data[0].embedding
print(embedding)输出结果将会是一个 3072 维度的向量,例如:
[
-0.005813355557620525,
# other 3070 elements...,
-0.006388738751411438
]类似地,下面展示了使用 sentence-transformers 来生成嵌入的方法:
# requirement: pip install sentence_transformers
from sentence_transformers import SentenceTransformer
# Sample input data (replace it with your input data)
input_data = """
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua. Ut enim ad minim veniam, quis nostrud exercitation ullamco laboris nisi ut aliquip ex ea commodo consequat. Duis aute irure dolor in reprehenderit in voluptate velit esse cillum dolore eu fugiat nulla pariatur. Excepteur sint occaecat cupidatat non proident, sunt in culpa qui officia deserunt mollit anim id est laborum.
"""
# Load a pretrained Sentence Transformer model
model = SentenceTransformer("all-MiniLM-L6-v2")
# Embedding generation
embedding = model.encode(input_data)
# Print the resulting embedding
print(embedding)这一次会得到一个 384 维度的向量:
[
-0.034803513,
# other 381 elements...,
-0.046595078
]需要注意的是,在嵌入质量和计算效率之间需要权衡。OpenAI 提供的大型模型能够生成丰富且高精度的嵌入,但生成速度相对较慢,而且通常需要调用付费的云端模型;相反,SentenceTransformers 等本地模型是免费的且速度更快,但语义精度可能略有不足。
如何选择合适的嵌入策略取决于您的性能需求以及对语义精度的要求。
实践整合:分步骤指南
通过以下步骤,了解如何从网页上的原始数据到使用 Python 脚本实现语义搜索的整个流程。
本教程将按照以下步骤让您逐步完成:
- 使用 Bright Data 的 Web Scraper API 从 BBC 抓取新闻文章。
- 对爬取到的数据进行预处理,并准备好供嵌入生成。
- 使用 SentenceTransformers 生成文本嵌入。
- 搭建 Milvus。
- 将处理后的文本和嵌入数据加载到向量数据库中。
- 执行搜索以根据查询语句检索语义上相关的新闻文章。
让我们开始吧!
先决条件
在开始前,请确保您具备如下条件:
- 本地已安装 Python 3+
- 本地已安装 Docker
- 拥有一个 Bright Data 账户
如果还没有,请先在本机安装 Python 和 Docker,并 免费创建一个 Bright Data 账户。
步骤 1:使用 Bright Data 的 Web Scraper API 收集数据
爬取新闻文章并非易事,因为许多新闻门户拥有各类 反爬虫和反机器人措施。要可靠地绕过这些防护并从 BBC 获取最新数据,我们将使用 Bright Data 的 网络抓取 API。
该 API 为 120 多个热门网站提供了专门的端点,可用于以结构化方式获取数据(包括 BBC)。其工作原理如下:
- 对相应的端点发送 POST 请求,以触发对指定 BBC 域名下某些 URL 的抓取任务。
- Bright Data 会在云端执行抓取任务。
- 您可周期性地轮询另一端点,直到抓取的数据已准备就绪(可选择 JSON、CSV 或其他格式)。
在开始编写 Python 代码前,请先安装 Requests 库:
pip install requests接着,可参考 Bright Data 文档,熟悉 Web Scraper API 的使用方式,同时获取您的 API Key。
然后使用如下示例代码,从 BBC 新闻中抓取数据:
import requests
import json
import time
def trigger_bbc_news_articles_scraping(api_key, urls):
# Endpoint to trigger the Web Scraper API task
url = "https://api.brightdata.com/datasets/v3/trigger"
params = {
"dataset_id": "gd_ly5lkfzd1h8c85feyh", # ID of the BBC web scraper
"include_errors": "true",
}
# Convert the input data in the desired format to call the API
data = [{"url": url} for url in urls]
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
}
response = requests.post(url, headers=headers, params=params, json=data)
if response.status_code == 200:
snapshot_id = response.json()["snapshot_id"]
print(f"Request successful! Response: {snapshot_id}")
return response.json()["snapshot_id"]
else:
print(f"Request failed! Error: {response.status_code}")
print(response.text)
def poll_and_retrieve_snapshot(api_key, snapshot_id, output_file, polling_timeout=20):
snapshot_url = f"https://api.brightdata.com/datasets/v3/snapshot/{snapshot_id}?format=json"
headers = {
"Authorization": f"Bearer {api_key}"
}
print(f"Polling snapshot for ID: {snapshot_id}...")
while True:
response = requests.get(snapshot_url, headers=headers)
if response.status_code == 200:
print("Snapshot is ready. Downloading...")
snapshot_data = response.json()
# Write the snapshot to an output json file
with open(output_file, "w", encoding="utf-8") as file:
json.dump(snapshot_data, file, indent=4)
print(f"Snapshot saved to {output_file}")
return
elif response.status_code == 202:
print(F"Snapshot is not ready yet. Retrying in {polling_timeout} seconds...")
time.sleep(polling_timeout)
else:
print(f"Request failed! Error: {response.status_code}")
print(response.text)
break
if __name__ == "__main__":
BRIGHT_DATA_API_KEY = "<YOUR_BRIGHT_DATA_API_KEY>" # Replace it with your Bright Data's Web Scraper API key
# URLs of BBC articles to retrieve data from
urls = [
"https://www.bbc.com/sport/formula1/articles/c9dj0elnexyo",
"https://www.bbc.com/sport/formula1/articles/cgenqvv9309o",
"https://www.bbc.com/sport/formula1/articles/c78jng0q2dxo",
"https://www.bbc.com/sport/formula1/articles/cdrgdm4ye53o",
"https://www.bbc.com/sport/formula1/articles/czed4jk7eeeo",
"https://www.bbc.com/sport/football/articles/c807p94r41do",
"https://www.bbc.com/sport/football/articles/crgglxwge10o",
"https://www.bbc.com/sport/tennis/articles/cy700xne614o",
"https://www.bbc.com/sport/tennis/articles/c787dk9923ro",
"https://www.bbc.com/sport/golf/articles/ce3vjjq4dqzo"
]
snapshot_id = trigger_bbc_news_articles_scraping(BRIGHT_DATA_API_KEY, urls)
poll_and_retrieve_snapshot(BRIGHT_DATA_API_KEY, snapshot_id, "news-data.json")以上示例中,输入的 URL 都是 BBC 体育频道的文章链接。运行脚本后,您将看到类似如下输出:
Request successful! Response: s_m9in0ojm4tu1v8h78
Polling snapshot for ID: s_m9in0ojm4tu1v8h78...
Snapshot is not ready yet. Retrying in 20 seconds...
# ...
Snapshot is not ready yet. Retrying in 20 seconds...
Snapshot is ready. Downloading...
Snapshot saved to news-data.json脚本会不断轮询,直到数据准备就绪。最终将在项目文件夹中生成名为 news-data.json 的文件,其中包含了抓取到的结构化 BBC 文章数据。
步骤 2:对抓取到的数据进行清洗与准备
打开该输出 JSON 文件,您将看到一个类似这样的新闻项目数组:
[
{
"input": {
"url": "https://www.bbc.com/sport/football/articles/c807p94r41do",
"keyword": ""
},
"id": "c807p94r41do",
"url": "https://www.bbc.com/sport/football/articles/c807p94r41do",
"author": "BBC",
"headline": "Man City Women: What has gone wrong for WSL side this season?",
"topics": [
"Football",
"Women's Football"
],
"publication_date": "2025-04-13T19:35:45.288Z",
"content": "With their Women's Champions League qualification ...",
"videos": [],
"images": [
// ...
],
"related_articles": [
// ...
],
"keyword": null,
"timestamp": "2025-04-15T13:14:27.754Z"
}
// ...
]拿到数据之后,下一步就是导入此文件,清洗正文,并为后续的嵌入生成做好准备。
在本例中,Bright Data 已经为您完成了大部分处理——抓取得到的是解析后且结构化的数据,因此无需担心 HTML 数据解析。
但是,您仍需要:
- 对文本中的空白符、换行符和制表符进行归一化。
- 将文章标题与正文内容结合成一个适合生成嵌入的单一文本字符串。
为了简化数据处理,推荐使用 Pandas,通过如下命令安装:
pip install pandas加载上一步获取的 news-data.json 文件,并执行数据处理逻辑:
import pandas as pd
import json
import re
# Load your JSON array
with open("news-data.json", "r") as f:
news_data = json.load(f)
# Normalize whitespaces/newlines/tabs for better embedding quality
def clean_text(text):
text = re.sub(r"\s+", " ", text)
return text.strip()
# Create a DataFrame
df = pd.DataFrame(news_data)
# Combine headline and cleaned content for embedding input
df["text_for_embedding"] = df["headline"].map(clean_text) + ". " + df["content"].map(clean_text)
# Ensure ID is a string
df["id"] = df["id"].astype(str)这里,我们新建了一个 text_for_embedding 字段,将整理后的标题与正文合并,以便后续嵌入模型使用。
步骤 3:生成向量嵌入
使用 SentenceTransformer 根据 text_for_embedding 字段来生成嵌入:
from sentence_transformers import SentenceTransformer
# Step 2 ...
# Initialize a model for embedding generation
model = SentenceTransformer("all-MiniLM-L6-v2")
# Generate embeddings
texts = df["text_for_embedding"].tolist()
embeddings = model.encode(texts, show_progress_bar=True, batch_size=16)
# Store the resulting emebeddings in the DataFrame
df["embedding"] = embeddings.tolist()由于我们在 show_progress_bar 参数中选择了 True,sentence_transformers 会在生成嵌入时显示进度条。对于大数据集来说,这非常有用,因为这一步可能需要一些时间。
生成的向量嵌入会直接保存在 DataFrame 的 embedding 列中。
步骤 4:选择并设置向量数据库
在我们的示例中,Milvus 是一个不错的选择,因为它开源免费,且将语义搜索用例作为核心功能之一。
要在本地安装 Milvus,请参考官方文档:
安装后,您应该有一个在本地 19530 端口运行的 Milvus 实例。
接下来,安装 Python 版 Milvus 客户端——pymilvus:
pip install pymilvus注意:Milvus 服务器版本与 Python 客户端版本必须匹配,否则可能出现连接错误。可在 Milvus 的 GitHub releases 页面中查看受支持的版本组合。截稿时,以下组合可正常使用:
- Milvus 服务器版本:
2.5.9 pymilvus版本:2.5.6
步骤 5:将嵌入加载到向量数据库中
使用 pymilvus 连接到本地的 Milvus 服务,创建一个名为 news_articles 的集合,定义其模式和索引,然后插入我们生成的嵌入:
from pymilvus import connections, utility, CollectionSchema, FieldSchema, DataType, Collection
# Step 4...
# Connect to Milvus
connections.connect("default", host="localhost", port="19530")
# Drop the "news_articles" collection if it already exists
if utility.has_collection("news_articles"):
utility.drop_collection("news_articles")
# Define the collection's schema
fields = [
FieldSchema(name="id", dtype=DataType.VARCHAR, is_primary=True, max_length=64),
FieldSchema(name="url", dtype=DataType.VARCHAR, max_length=65535),
FieldSchema(name="text", dtype=DataType.VARCHAR, max_length=65535),
FieldSchema(name="embedding", dtype=DataType.FLOAT_VECTOR, dim=384),
]
schema = CollectionSchema(fields, description="News article embeddings for semantic search")
collection = Collection(name="news_articles", schema=schema)
# Create an index on the embedding field
index_params = {
"metric_type": "COSINE",
"index_type": "HNSW",
}
collection.create_index(field_name="embedding", index_params=index_params)
# Load the collection for the first time
collection.load()
# Prepare data for insertion
ids = df["id"].tolist()
urls = df["url"].tolist()
texts = df["text_for_embedding"].tolist()
vectors = df["embedding"].tolist()
# Insert the data into the Milvus collection
collection.insert([ids, urls, texts, vectors])
collection.flush()执行以上步骤后,名为 news_articles 的集合会创建在本地的 Milvus 服务中,并包含嵌入数据,随时可以进行语义搜索。
步骤 6:执行语义搜索
定义一个函数来对 news_articles 集合执行语义搜索:
# Step 5...
def search_news(query: str, top_k=3, score_threshold=0.5):
query_embedding = model.encode([query])
search_params = {"metric_type": "COSINE"}
results = collection.search(
data=query_embedding,
anns_field="embedding",
param=search_params,
limit=top_k,
output_fields=["id", "url", "text"]
)
for hits in results:
for hit in hits:
if hit.score >= score_threshold:
print(f"Score: {hit.score:.4f}")
print(f"URL: {hit.fields["url"]}")
print(f"Text: {hit.fields["text"][:300]}...\n")以上函数会检索与输入查询最相似的三条记录(top_k=3),并只返回相似度分数高于 0.5 的结果。由于我们使用的是余弦相似度,其分数范围是 -1(完全相反)到 1(完全匹配)。
现在,您可以通过以下语句来查询“红牛车队在一级方程式中的未来”:
search_news("Future of the Red Bull racing team in Formula 1")示例输出可能如下所示:
Score: 0.5736
URL: https://www.bbc.com/sport/formula1/articles/c9dj0elnexyo
Text: Max Verstappen: Red Bull adviser Helmut Marko has 'great concern' about world champion's future with team. Saudi Arabian Grand PrixVenue: Jeddah Dates: 18-20 April Race start: 18:00 BST on SundayCoverage: Live radio commentary of practice, qualifying and race online and BBC 5 Sports Extra; live text...
Score: 0.5715
URL: https://www.bbc.com/sport/formula1/articles/czed4jk7eeeo
Text: F1 engines: A return to V10 or hybrid - what's the future?. Christian Horner's phone rang. It was Bernie Ecclestone. Red Bull's team principal picked up, switched to speakerphone and placed it on the table in front of the assembled Formula 1 bosses.We're in the F1 Commission, Horner told Ecclestone....可以看到,查询中并未出现这些文章的原句,但检索结果的内容确实与“红牛车队在一级方程式中的未来”这个主题紧密相关——这正体现了向量嵌入的强大语义能力!
向量数据库的性能优化
若想最大化地利用向量数据库,建议先基于业务逻辑对数据进行合理划分,创建合适的集合。接着,可通过数据分片、聚类以及针对特定查询场景的索引策略来进一步提升性能。
需要注意的是,许多优化策略需要在对系统的实际使用情况有充分认识后再实施,也就是在向量数据库流程足够成熟、知道哪些数据被频繁查询时,再去做针对性的优化。
其他常见的性能瓶颈还包括嵌入漂移、不一致的向量维度,以及陈旧或重复的数据。可以通过定期重新生成嵌入、强制对高维数据进行统一的模式管理,以及设置自动化数据清理任务来应对这些问题。
对于持续接收新数据的场景,您需要支持实时向量更新或定期批量插入。在此过程中,请务必确保数据质量,以免由于注入了未经验证的数据而导致嵌入质量下降、搜索结果不可靠。
最后,对于单节点数据库,还可以根据需要调整索引精度、向量维度和分片数量等参数。如果业务量持续增长,水平扩展通常胜过纵向扩展,您可在云端搭建多节点的分布式集群。
向量数据库的未来趋势
现代 AI 系统仍处于快速发展阶段,而向量数据库作为众多 AI 应用的关键部件,其自身也在不断演进,以支持愈加复杂的业务场景与需求。
展望未来,以下趋势可能会塑造向量数据库的发展方向:
- 混合搜索集成:与传统关系型或 NoSQL 系统结合,实现跨结构化与非结构化数据的灵活查询。
- 原生多模态支持:统一存储和查询来自文本、图像、音频、视频等多模态源的嵌入。
- 更加智能的索引与调优:通过自动调参、降低存储成本,以及与 SQL 数据库的更深度融合来提升可扩展性与企业级支持。
结论
通过本指南,您已经了解到向量数据库在机器学习数据存储中的核心地位,了解了向量数据库的概念、工作原理、当下最流行的解决方案,以及它们在现代 AI 数据基础架构中的重要性。
同时,我们还演示了如何将原始数据转换为嵌入,并存储在向量数据库中以实现语义搜索的案例。这也凸显了获取丰富、可信和实时更新数据的重要性——而 Bright Data 的网页抓取解决方案正是满足这一需求的理想之选。
现在就开始使用 Bright Data 做免费试用,获取高质量的数据来驱动您的向量数据库应用吧!



