

在本文中,您将了解 RAG 的全部内容,包括它在增强大型语言模型(LLM)响应以及其组成部分中的作用。
RAG 的含义
RAG 是一种机器学习(ML)技术,它将传统的 LLM 向前推进了一步,通过将它们与搜索(又称检索)系统相连。RAG 驱动的模型不仅仅依赖其固定的训练数据,还可以利用外部资源(如数据库、文档,甚至网络)来查找相关信息,从而提高回复的质量。这种实时检索与语言生成的混合,使得模型生成的回复更加准确,并能及时更新。
检索 + 生成
RAG 的工作原理由三部分组成:搜索或检索系统、本身的语言模型,以及将两者结合的过程。当被问到一个问题时,RAG 系统首先使用检索组件在语言模型的训练数据之外寻找相关数据。然后,原始的提示(prompt)会被修改,以将这些新数据添加进来。更新后的提示会传递给生成组件(LLM),它利用自身学到的模式以及从外部获取的新内容来生成回答。这样一来,输出就不再只是依赖预先训练的数据,还与来自实际来源的真实信息相结合。
RAG 巧妙地将检索和生成功能结合在一起,为传统语言模型的不足提供了有效的解决方案。它可提供更可靠、准确的回答,并可根据不同主题灵活调整,使其非常适合需要获取最新或专业化信息的应用场景。
为什么 LLM 需要增强
尽管 LLM 在生成类人文本方面表现令人印象深刻,但它们也并非完美无缺。
幻觉风险
LLM 面临的最大挑战之一是“幻觉”风险,即模型会生成看似合理却不正确的信息。这是因为 LLM 仅依据庞大、静态的数据集进行训练,缺乏对训练时间窗口之外的信息或事实的实时访问。
此外,如果仔细观察,LLM 并不是真正的解题机器;它们主要是文本补全模型。它们的目标是尽量生成与给定提示最匹配的回复,并不一定保证“正确”。由于它们不是通过确定性算法来生成回答,它们在某些情况下难免会产生幻觉。
信息验证
另外,LLM 无法验证新的信息或与实时来源进行比对,因此很容易忽略或错误传递事实。
知识截止点
另一个局限在于知识截止点。LLM 只会被训练到特定时间之前的数据,对于其训练完成后才发生的事件或发现并不了解。
可信来源
LLM 也很难引用可信来源,导致用户可能会质疑生成内容的准确性。如果缺乏对实时信息的访问或无法对信息进行验证,这些模型的可信度就会大打折扣。
RAG:解决 LLM 局限性的方案
如前所述,RAG 通过在实际、最新数据的基础上生成答案,专门为克服 LLM 的局限性而设计。
从相关来源获取最新信息
当 LLM 收到一个查询时,RAG 不再只依赖静态训练数据,而是能够从与上下文相关的外部资源中获取最新信息。这种方式能有效降低幻觉的风险,因为回答是基于实际的文档和数据进行的。由于它可以主动检索外部来源,RAG 能回答与近期事件、新技术相关的问题;而传统 LLM 因知识截止点而无法面对这类问题。举例来说,在客户支持场景中,RAG 可以从知识库中检索最新的政策更新,确保回答符合公司当前的文档标准。
透明度提升
除了准确性外,RAG 还可提高回答对信息来源的透明度。它会从明确的、相关文档中提取数据,从而留下更清晰的推理过程痕迹,用户也能了解信息的来源。这种可验证性不仅能增强用户信任,也让 RAG 更有助于法律和金融领域等需要明确、可信证据的场景。
RAG 的主要应用场景
在对信息准确度和时效性要求极高、且领域变化迅速的情况下,RAG 的优势得以凸显。以下是 RAG 的一些热门应用:
客户支持自动化
RAG 利用企业知识库和帮助文档来改变客户支持体验。它能根据最新文档、产品信息和故障排查技巧,瞬时回答客户问题。这样不仅确保答案精准且与客户需求贴合,也能避免客服人员被大量重复问题所困扰。
法律和金融服务
这些领域对信息的准确性和可追溯性要求非常高。例如,法律从业者可借助 RAG 在发表意见时检索相关判例法或法规;而金融分析师也可以将当前的市场报告或数据整合进来,为客户提供及时且有依据的见解。
研究与内容创作
作家、记者以及研究人员可使用 RAG 从可信来源中提取准确的参考资料,从而简化并加速事实核查与信息收集。不论是在撰写文章还是整理研究数据,RAG 都可帮助快速获取相关且可信的材料,让内容创作者能更专注于高质量内容的产出。
对话式智能体和聊天机器人
通过集成 RAG,对话式智能体和聊天机器人能够提供更准确、更具上下文关联的回答,显著提升用户体验。例如,医疗保健领域的聊天机器人可检索最近的医学研究信息,技术支持领域则可获取最新的固件更新内容。RAG 将实时数据检索和语言生成相结合,增强了回复的质量和可靠性。
了解更多关于使用 GPT 模型构建 RAG 聊天机器人的信息。
RAG 面临的挑战和局限性
虽然 RAG 为语言模型带来了显著的价值,但它同时也有自身的挑战。
信息质量与准确性
首要问题在于用于增强提示的检索信息的质量与准确性。由于 RAG 依赖外部来源,因此模型生成的回答高度取决于它检索到的数据质量。如果检索系统召回了不相关或不准确的文档,生成的回答依旧可能存在不足。因此,确保高质量检索非常关键,往往需要对系统进行细调并定期更新,以保持数据的准确性与时效性。
计算成本与系统复杂性
其他挑战还包括 RAG 系统带来的计算成本和复杂性。与单纯的 LLM 不同,RAG 需要强大的检索系统和能够将检索信息与模型高效结合的功能,这往往十分消耗资源。在需要实时搜索或处理大量数据的情况下,这种较高的计算负荷会拖慢响应速度。对组织而言,部署 RAG 时要在准确性与性能之间取得平衡,既要确保检索效率,也要兼顾速度。
RAG 的成功还高度依赖于结构良好且可靠的数据源。如果外部数据库不可信或结构混乱,检索系统就难以获取有用信息。此外,并非所有数据源都可以轻松访问或负担得起,对于规模较小的组织而言,这可能会成为门槛。
尽管如此,如果能精心搭建并选择可靠的数据源,RAG 在众多应用场景中依然能带来颠覆性的价值。
RAG 在实践中的实现
要搭建一个 RAG 系统,需要将语言模型与强大的检索机制连接起来,以实现对外部数据的访问。
整个流程从搭建检索系统与语言模型的高层架构开始。当用户提交查询后,检索系统会在外部信息源中搜索相关信息,并将检索到的结果与提示一并发送给 LLM,LLM 则基于自身掌握的知识与检索到的数据生成回答。通过这种方式,回复不仅具有参考价值,还能结合最新、可靠的数据。
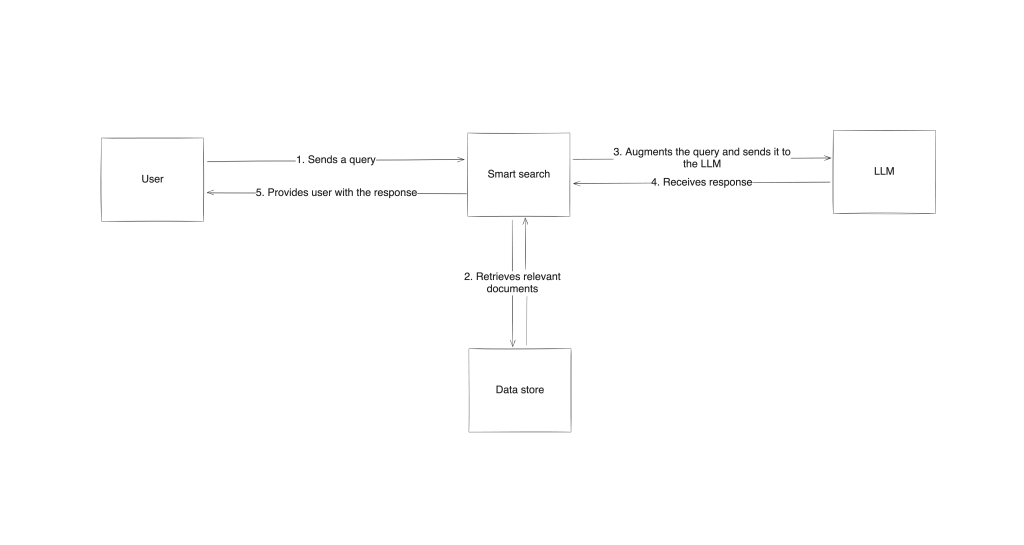
RAG 的实现需要特定的工具与框架
在实际层面上,RAG 的实现需要能处理信息检索、处理与生成的特定工具和框架。像 LangChain 和 Haystack 等库非常常见,它们提供了现成的模块用于在生成回答的流程中整合检索功能。
例如,LangChain 为 结构化提示、数据检索 以及 结果管线化 提供了相应的工具;Haystack 则专注于 高性能检索,可用于从数据库、文档或网络中获取信息。您可以根据不同的数据源对这些工具进行定制,从而适应各种 RAG 应用。
RAG 是在现有 LLM 之上构建的框架
如果从宏观来看,和 微调 这类技术不同,RAG 并不会改变或影响底层 LLM 的结构或构成。它只是在您现有 LLM 之上构建的一种框架,用于改进发送给模型的提示。如果有人 认为 RAG 只是高级的提示工程,您可能会在查看 RAG 系统输入的原始提示与生成最终回答前的“增强提示”时,理解这种观点。下面是一个快速(且高度简化)的示例,帮助您更好理解这一点:
- 原始提示
目前气候变化对珊瑚礁造成哪些最新影响?
- LLM(无 RAG)响应
珊瑚礁受到海水升温和海洋酸化的影响,导致珊瑚白化并破坏海洋生态系统。
- 使用 RAG 增强后的提示
使用检索到的数据:“美国国家海洋和大气管理局(NOAA)在 2024 年的报告中指出,由于海洋变暖,加勒比和太平洋地区出现了大规模珊瑚白化事件,受影响地区的珊瑚覆盖率下降了 40%。此外,海洋酸化也在削弱珊瑚骨骼,让它们更容易受到风暴破坏。”基于以上信息回答:目前气候变化对珊瑚礁造成哪些最新影响?
- LLM(使用 RAG)响应
最近的 NOAA 报告表明,海洋变暖导致了加勒比和太平洋的珊瑚大规模白化,部分区域的珊瑚覆盖率下降了 40%。酸化也在损害珊瑚骨骼,使其更加脆弱。
乍看之下,这似乎支持“RAG 只是高级提示工程”的说法,但需要强调的是,如何在“原始查询”场景下准确获取并与其匹配的数据,才是 RAG 的核心。根据数据存储方式,搜索组件可能只是一个简单的 SQL 查询,也可能是更复杂的谷歌搜索和网络爬虫。一旦拿到数据,还需要正确且有效地对其进行优先级排序、摘要,然后再将其追加到提示中。这两个步骤的复杂程度,往往超过了任何单纯的提示工程技术。
RAG 的实现需要大量高质量数据
就数据存储本身而言,大多数 RAG 系统往往需要一个数据源,如果这个数据能保证大规模、准确、及时且行业专属,那就再好不过了。不过,创建和维护这样的数据集既耗时又复杂。像 Bright Data 等提供公共数据的服务商,可提供海量的数据集,帮助确保检索系统使用的是最新且高质量的信息。
这些来源可包括从网络数据到结构化数据的广泛类型,大幅提升模型的相关性。如果 RAG 模型能与 Bright Data 的数据集集成,便能获取最新信息,不仅提高回答的准确度,也有助于在需要实时数据的领域(如天气系统或物流与供应链管理)进行应用。
Bright Data 如何帮助公共数据检索
作为一家从网络上获取高质量公共数据的厂商,Bright Data 可成为 RAG 系统的重要数据来源。由于 RAG 非常依赖优质、实时的信息,有了 Bright Data 提供的多样化数据集,模型就能从不同领域中快速获取相关内容,包括最新事件和特定研究场景。
覆盖多个行业的结构化数据
Bright Data 的数据集中含有来自电商、金融市场和新闻等多个行业的结构化数据,可融入 RAG 系统中,提升模型回答的准确度和相关性。这能确保 LLM 对需要最新或行业定制信息的问题做出准确回答,无论是客户支持还是竞争分析,皆能有所获益。
大规模获取并筛选公共数据
如果您想自行从互联网上收集数据,Bright Data 的 API 和 丰富的代理网络 能让您在保持合规的前提下,大规模获取并筛选公共数据。这在需要动态检索信息的 RAG 场景中十分有用。比如,金融服务领域的 RAG 系统可持续检索最新的股市数据或监管新闻,提高模型在实时分析方面的能力。
当把 Bright Data 用作 RAG 系统的数据源时,您无需自行维护大型数据存储,只需专注于完善提示增强与回答生成即可。
结论
RAG 是对 LLM 能力的一次重大提升,它能够通过引入实时的外部数据来克服 LLM 在知识截止与幻觉上的关键性限制。借助 RAG,模型能访问更新、更可验证的信息,使它们的回答更具相关性与可靠度。这一方法让语言模型从静态的知识库转变为动态、能感知上下文的交互式代理。
通过在 RAG 中整合高质量的实时数据,您可以显著提升 AI 应用的准确度、相关性和可信度。无论是在客户支持、金融分析、医疗保健还是其他行业,引入 RAG 都能大幅改善最终用户的使用体验。
Bright Data 让您更轻松地构建 RAG 系统,提供了一种可扩展、可靠的公共数据解决方案。通过其 多样化的数据集,Bright Data 可以为 RAG 系统提供准确、最新的回答,在各行各业发挥作用。
立即注册并开启免费试用,您可以下载免费的数据集样本,快速开始体验吧!



